







目录
1,二分查找
704. 二分查找 - 力扣(LeetCode)![]() https://leetcode.cn/problems/binary-search/
https://leetcode.cn/problems/binary-search/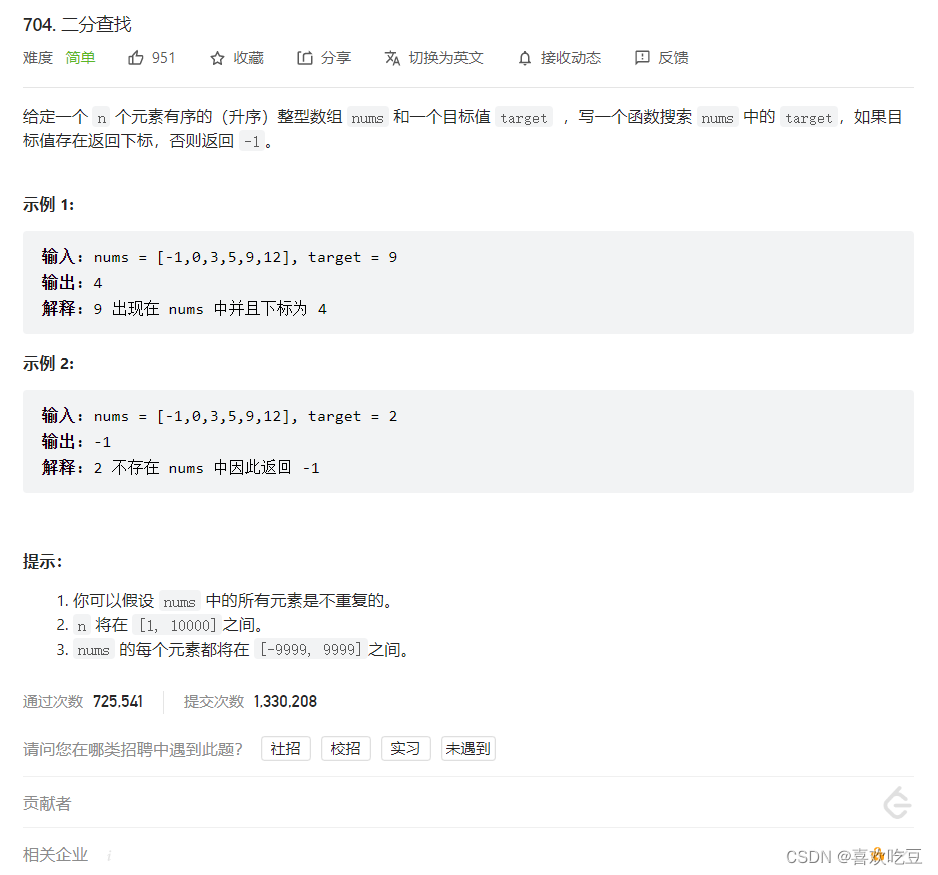
答案写到下面的函数里面:
class Solution {
public:
int search(vector<int>& nums, int target) {
}
};
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while(left <= right){
int mid = (right - left) / 2 + left;
int num = nums[mid];
if (num == target) {
return mid;
} else if (num > target) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return -1;
}
};复杂度分析
-
时间复杂度:O(logn),其中 n 是数组的长度。
-
空间复杂度:O(1)。
使用二分查找的前提是有序且无重复。
2,第一个错误的版本:
278. 第一个错误的版本 - 力扣(LeetCode)![]() https://leetcode.cn/problems/first-bad-version/
https://leetcode.cn/problems/first-bad-version/
思路及算法
因为题目要求尽量减少调用检查接口的次数,所以不能对每个版本都调用检查接口,而是应该将调用检查接口的次数降到最低。注意到一个性质:当-个版本为正确版本,则该版本之前的所有版本均为正确版本;当一个版本为错误版本,则该版本之后的所有版本均为错误版本。我们可以利用这个性质进行二分查找。具体地,将左右边界分别初始化为1和n,中n是给定的版本数量。设定左右边界之后,每次我们都依据左右边界找到其中间的版本,检查其是否为正确版本。如果该版本为正确版本,那么第一个错误的版本必然位于该版本的右侧,我们缩紧左边界;刮第一个错误的版本必然位于该版本及该版本的左侧,我们缩紧右边界。这样我们每判断一次都可以缩紧一次边界, 而每次缩紧时两边界距离将变为原来的一半,因此我们至多只需要缩紧O(logn)次。
class Solution {
public:
int firstBadVersion(int n) {
int left = 1, right = n;
while (left < right) { // 循环直至区间左右端点相同
int mid = left + (right - left) / 2; // 防止计算时溢出
if (isBadVersion(mid)) {
right = mid; // 答案在区间 [left, mid] 中
} else {
left = mid + 1; // 答案在区间 [mid+1, right] 中
}
}
// 此时有 left == right,区间缩为一个点,即为答案
return left;
}
};
复杂度分析
-
时间复杂度:O(\log n)O(logn),其中 nn 是给定版本的数量。
-
空间复杂度:O(1)O(1)。我们只需要常数的空间保存若干变量。
什么是二分查找
二分查找是计算机科学中最基本、最有用的算法之一。 它描述了在有序集合中搜索特定值的过程。
二分查找中使用的术语:
目标 Target —— 你要查找的值
索引 Index —— 你要查找的当前位置
左、右指示符 Left,Right —— 我们用来维持查找空间的指标
中间指示符 Mid —— 我们用来应用条件来确定我们应该向左查找还是向右查找的索引
1,它是如何工作的?
在最简单的形式中,二分查找对具有指定左索引和右索引的连续序列进行操作。这就是所谓的查找空间。二分查找维护查找空间的左、右和中间指示符,并比较查找目标或将查找条件应用于集合的中间值;如果条件不满足或值不相等,则清除目标不可能存在的那一半,并在剩下的一半上继续查找,直到成功为止。如果查以空的一半结束,则无法满足条件,并且无法找到目标。
2,
二分查找是一种在每次比较之后将查找空间一分为二的算法。每次需要查找集合中的索引或元素时,都应该考虑二分查找。如果集合是无序的,我们可以总是在应用二分查找之前先对其进行排序。
3,
二分查找一般由三个主要部分组成:
预处理 —— 如果集合未排序,则进行排序。
二分查找 —— 使用循环或递归在每次比较后将查找空间划分为两半。
后处理 —— 在剩余空间中确定可行的候选者。
4,
3 个二分查找模板
当我们第一次学会二分查找时,我们可能会挣扎。我们可能会在网上研究数百个二分查找问题,每次我们查看开发人员的代码时,它的实现似乎都略有不同。尽管每个实现在每个步骤中都会将问题空间划分为原来的 1/2,但其中有许多问题:
为什么执行方式略有不同?
开发人员在想什么?
哪种方法更容易?
哪种方法更好?
经过许多次失败的尝试并拉扯掉大量的头发后,我们找到了三个主要的二分查找模板。为了防止脱发,并使新的开发人员更容易学习和理解,我们在接下来的章节中提供了它们。
1)模板一
int binarySearch(vector<int>& nums, int target){
if(nums.size() == 0)
return -1;
int left = 0, right = nums.size() - 1;
while(left <= right){
// Prevent (left + right) overflow
int mid = left + (right - left) / 2;
if(nums[mid] == target){ return mid; }
else if(nums[mid] < target) { left = mid + 1; }
else { right = mid - 1; }
}
// End Condition: left > right
return -1;
}关键属性
二分查找的最基础和最基本的形式。
查找条件可以在不与元素的两侧进行比较的情况下确定(或使用它周围的特定元素)。
不需要后处理,因为每一步中,你都在检查是否找到了元素。如果到达末尾,则知道未找到该元素。

例题:
1,x的平方根
69. x 的平方根 - 力扣(LeetCode)![]() https://leetcode.cn/problems/sqrtx/
https://leetcode.cn/problems/sqrtx/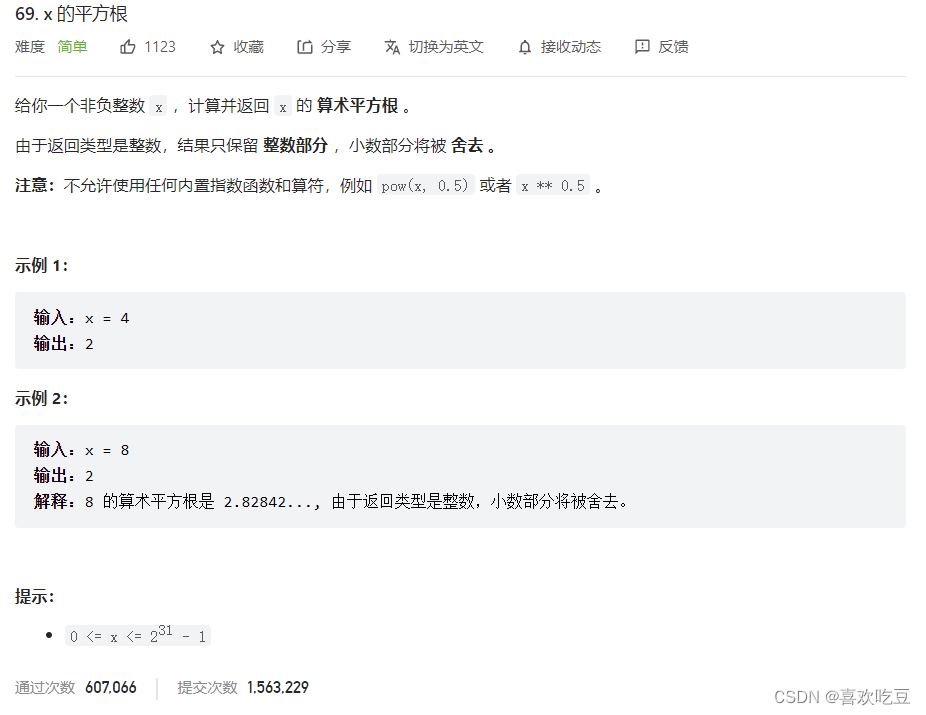
由于x平方根的整数部分ans是满足k2≤x的最大k值,因此我们可以对k进行二分查找,从而得
到答案。
二分查找的下界为0,上界可以粗略地设定为x。在二分查找的每一步中,我们只需要比较中间元素
mid的平方与x的大小关系,并通过比较的结果调整上下界的范围。于我们所有的运算都是整数运
算,不会存在误差,因此在得到最终的答案ans后,也就不需要再去尝试ans+1了。
class Solution {
public:
int mySqrt(int x) {
int l = 0, r = x, ans = -1;
while (l <= r) {
int mid = l + (r - l) / 2;
if ((long long)mid * mid <= x) {
ans = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
return ans;
}
};
复杂度分析
-
时间复杂度:O(logx),即为二分查找需要的次数。
-
空间复杂度:O(1)。
2,搜索旋转排序数组
33. 搜索旋转排序数组 - 力扣(LeetCode)![]() https://leetcode.cn/problems/search-in-rotated-sorted-array/
https://leetcode.cn/problems/search-in-rotated-sorted-array/

思路和算法
对于有序数组,可以使用二分查找的方法查找元素。
但是这道题中,数组本身不是有序的,进行旋转后只保证了数组的局部是有序的,这还能进行二份查找吗?答案是可以的。
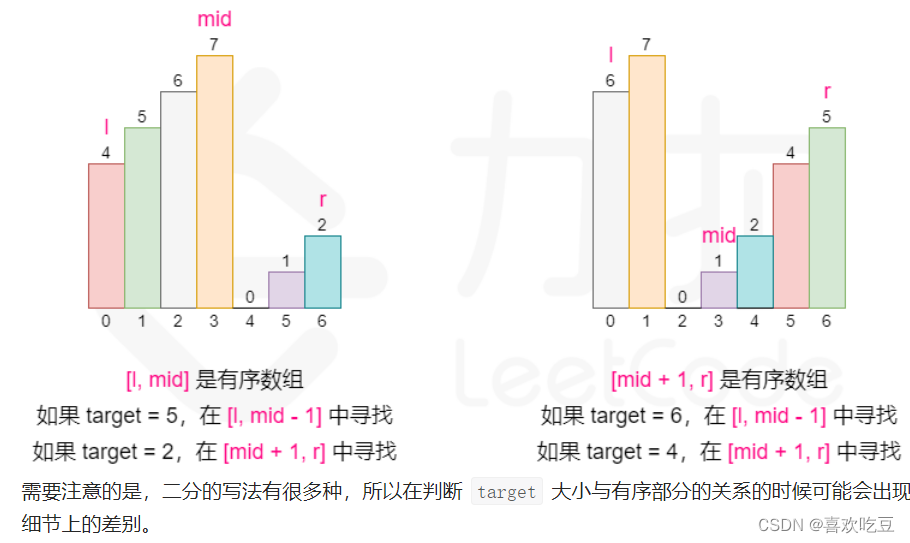
可以发现的是,我们将数组从中间分开成左右两部分的时候,-定有一部分的数组是有 序的。示例
来看,我们从6这个位置分开以后数组变成了[4, 5, 6]和[7, 0,1,2]两个部分,中左边[4, 5,6]这个部分的数组是有序的,其他也是如此。这启示我们可以在常规二分查找的时候查看当前mid 为分割位置分割出来的两个部分[1, mid] 和[mid + 1,r]哪个部分是有序的,并根据有序的那个部分确定我们该如何改变二分查找的上下界,因为我们能够根据有序的那部分判断出target 在不在这个部分:
●如果[1,mid一1]有序数组,且target 的大小满足[nums[l], nums[mid), 则我们应该将搜索范围缩小至[1,mid一1],否则在[mid+1,r]寻找。
●如果[mid, r]有序数组,且target 的大小满足(nums[mid + 1], nums[r],则我们应该将
搜索范围缩小至[mid + 1,r],否则在[1,mid 一1]寻找。
class Solution {
public:
int search(vector<int>& nums, int target) {
int n = (int)nums.size();
if (!n) {
return -1;
}
if (n == 1) {
return nums[0] == target ? 0 : -1;
}
int l = 0, r = n - 1;
while (l <= r) {
int mid = (l + r) / 2;
if (nums[mid] == target) return mid;
if (nums[0] <= nums[mid]) {
if (nums[0] <= target && target < nums[mid]) {
r = mid - 1;
} else {
l = mid + 1;
}
} else {
if (nums[mid] < target && target <= nums[n - 1]) {
l = mid + 1;
} else {
r = mid - 1;
}
}
}
return -1;
}
};
复杂度分析
时间复杂度: O(\log n)O(logn),其中 nn 为 \textit{nums}nums 数组的大小。整个算法时间复杂度即为二分查找的时间复杂度 O(\log n)O(logn)。
空间复杂度: O(1)O(1) 。我们只需要常数级别的空间存放变量。
2)模板二
int binarySearch(vector<int>& nums, int target){
if(nums.size() == 0)
return -1;
int left = 0, right = nums.size();
while(left < right){
// Prevent (left + right) overflow
int mid = left + (right - left) / 2;
if(nums[mid] == target){ return mid; }
else if(nums[mid] < target) { left = mid + 1; }
else { right = mid; }
}
// Post-processing:
// End Condition: left == right
if(left != nums.size() && nums[left] == target) return left;
return -1;
}模板 #2 是二分查找的高级模板。它用于查找需要访问数组中当前索引及其直接右邻居索引的元素或条件。
关键属性
一种实现二分查找的高级方法。
查找条件需要访问元素的直接右邻居。
使用元素的右邻居来确定是否满足条件,并决定是向左还是向右。
保证查找空间在每一步中至少有 2 个元素。
需要进行后处理。 当你剩下 1 个元素时,循环 / 递归结束。 需要评估剩余元素是否符合条件。
区分语法
初始条件:left = 0, right = length
终止:left == right
向左查找:right = mid
向右查找:left = mid+1
3)模板三
int binarySearch(vector<int>& nums, int target){
if (nums.size() == 0)
return -1;
int left = 0, right = nums.size() - 1;
while (left + 1 < right){
// Prevent (left + right) overflow
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
left = mid;
} else {
right = mid;
}
}
// Post-processing:
// End Condition: left + 1 == right
if(nums[left] == target) return left;
if(nums[right] == target) return right;
return -1;
}模板 #3 是二分查找的另一种独特形式。 它用于搜索需要访问当前索引及其在数组中的直接左右邻居索引的元素或条件。
关键属性
实现二分查找的另一种方法。
搜索条件需要访问元素的直接左右邻居。
使用元素的邻居来确定它是向右还是向左。
保证查找空间在每个步骤中至少有 3 个元素。
需要进行后处理。 当剩下 2 个元素时,循环 / 递归结束。 需要评估其余元素是否符合条件。
区分语法
初始条件:left = 0, right = length-1
终止:left + 1 == right
向左查找:right = mid
向右查找:left = mid

这 3 个模板的不同之处在于:
左、中、右索引的分配。
循环或递归终止条件。
后处理的必要性。
模板 #1 和 #3 是最常用的,几乎所有二分查找问题都可以用其中之一轻松实现。模板 #2 更 高级一些,用于解决某些类型的问题。
这 3 个模板中的每一个都提供了一个特定的用例:
模板 #1 (left <= right)
二分查找的最基础和最基本的形式。
查找条件可以在不与元素的两侧进行比较的情况下确定(或使用它周围的特定元素)。
不需要后处理,因为每一步中,你都在检查是否找到了元素。如果到达末尾,则知道未找到该元素。
模板 #2 (left < right)
一种实现二分查找的高级方法。
查找条件需要访问元素的直接右邻居。
使用元素的右邻居来确定是否满足条件,并决定是向左还是向右。
保证查找空间在每一步中至少有 2 个元素。
需要进行后处理。 当你剩下 1 个元素时,循环 / 递归结束。 需要评估剩余元素是否符合条件。
模板 #3 (left + 1 < right)
实现二分查找的另一种方法。
搜索条件需要访问元素的直接左右邻居。
使用元素的邻居来确定它是向右还是向左。
保证查找空间在每个步骤中至少有 3 个元素。
需要进行后处理。 当剩下 2 个元素时,循环 / 递归结束。 需要评估其余元素是否符合条件。
时间和空间复杂度:
时间:O(log n) —— 算法时间
因为二分查找是通过对查找空间中间的值应用一个条件来操作的,并因此将查找空间折半,在更糟糕的情况下,我们将不得不进行 O(log n) 次比较,其中 n 是集合中元素的数目。
为什么是 log n?
二分查找是通过将现有数组一分为二来执行的。
因此,每次调用子例程(或完成一次迭代)时,其大小都会减少到现有部分的一半。
首先 N 变成 N/2,然后又变成 N/4,然后继续下去,直到找到元素或尺寸变为 1。
迭代的最大次数是 log N (base 2) 。
空间:O(1) —— 常量空间
虽然二分查找确实需要跟踪 3 个指标,但迭代解决方案通常不需要任何其他额外空间,并且可以直接应用于集合本身,因此需要 O(1) 或常量空间。
上述内容来自力扣,由本人亲自整理。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











