







时间2022.6.23
一.认识Python
人生苦短,我用 Python —— Life is short, you need Python
章节简介:
-
Python 的起源
-
为什么要用 Python?
-
Python 的特点
-
Python 的优缺点
-
Python的主要应用领域
1. Python 的起源
Python 的创始人为吉多·范罗苏姆(Guido van Rossum)
Python 是由 Guido van Rossum 在八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的。
Python 本身也是由诸多其他语言发展而来的,这包括 ABC、Modula-3、C、C++、Algol-68、SmallTalk、Unix shell 和其他的脚本语言等等。
像 Perl 语言一样,Python 源代码同样遵循 GPL(GNU General Public License)协议。
现在 Python 是由一个核心开发团队在维护,Guido van Rossum 仍然占据着至关重要的作用,指导其进展。
Python 2.0 于 2000 年 10 月 16 日发布,增加了实现完整的垃圾回收,并且支持 Unicode。
Python 3.0 于 2008 年 12 月 3 日发布,此版不完全兼容之前的 Python 源代码。不过,很多新特性后来也被移植到旧的Python 2.6/2.7版本。
Python 3.0 版本,常被称为 Python 3000,或简称 Py3k。相对于 Python 的早期版本,这是一个较大的升级。
Python 2.7 被确定为最后一个 Python 2.x 版本,它除了支持 Python 2.x 语法外,还支持部分 Python 3.1 语法。
(1)解释器(科普)
计算机不能直接理解任何除机器语言以外的语言,所以必须要把程序员所写的程序语言翻译成机器语言,计算机才能执行程序。将其他语言翻译成机器语言的工具,被称为编译器
编译器翻译的方式有两种:一个是编译,另外一个是解释。两种方式之间的区别在于翻译时间点的不同。当编译器以解释方式运行的时候,也称之为解释器
-
编译型语言:程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如 C、C++
-
解释型语言:解释型语言编写的程序不进行预先编译,以文本方式存储程序代码,会将代码一句一句直接运行。在发布程序时,看起来省了道编译工序,但是在运行程序的时候,必须先解释再运行
编译型语言和解释型语言对比
-
速度 —— 编译型语言比解释型语言执行速度快
-
跨平台性 —— 解释型语言比编译型语言跨平台性好
(2)Python 的设计目标
1999 年,吉多·范罗苏姆向 DARPA 提交了一条名为 “Computer Programming for Everybody” 的资金申请,并在后来说明了他对 Python 的目标:
-
一门简单直观的语言并与主要竞争者一样强大
-
开源,以便任何人都可以为它做贡献
-
代码像纯英语那样容易理解
-
适用于短期开发的日常任务
这些想法中的基本都已经成为现实,Python 已经成为一门流行的编程语言
(3)Python 的设计哲学
-
优雅
-
明确
-
简单
<!-- > 在 Python 解释器内运行 `import this` 可以获得完整的列表 -->
-
Python 开发者的哲学是:用一种方法,最好是只有一种方法来做一件事
-
如果面临多种选择,Python 开发者一般会拒绝花俏的语法,而选择明确没有或者很少有歧义的语法
在 Python 社区,吉多被称为“仁慈的独裁者”
2. 为什么选择 Python?
-
代码量少
-
……
同一样问题,用不同的语言解决,代码量差距还是很多的,一般情况下
Python是Java的 1/5,所以说 人生苦短,我用 Python
3. Python 特点
-
1.易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
-
2.易于阅读:Python代码定义的更清晰。
-
3.易于维护:Python的成功在于它的源代码是相当容易维护的。
-
4.一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
-
5.互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
-
6.可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
-
7.可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
-
8.数据库:Python提供所有主要的商业数据库的接口。
-
9.GUI编程:Python支持GUI可以创建和移植到许多系统调用。
-
10.可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
4. Python 的优缺点
(1)优点
-
简单 -- Python 是一种代表简单主义思想的语言。阅读一个良好的 Python 程序就感觉像是在读英语一样,尽管这个英语的要求非常严格!Python 的这种伪代码本质是它最大的优点之一。它使你能够专注于解决问题而不是去搞明白语言本身。
-
易学 -- 就如同你即将看到的一样,Python 极其容易上手。前面已经提到了,Python 有极其简单的语法。
-
免费、开源 -- Python 是 FLOSS(自由/开放源码软件)之一。简单地说,你可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS 是基于一个团体分享知识的概念。这是为什么 Python 如此优秀的原因之一——它是由一群希望看到一个更加优秀的 Python 的人创造并经常改进着的。
-
高层语言 -- 当你用 Python 语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
-
可移植性 -- 由于它的开源本质,Python 已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有 Python 程序无需修改就可以在下述任何平台上面运行。这些平台包括 Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE 甚至还有 PocketPC、Symbian 以及 Google 基于 Linux 开发的 Android 平台!
-
解释性 -- 这一点需要一些解释。一个用编译性语言比如 C 或 C++ 写的程序可以从源文件(即 C 或 C++ 语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而 Python 语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程序。在计算机内部,Python 解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接转载正确的库等等,所有这一切使得使用 Python 更加简单。由于你只需要把你的 Python 程序拷贝到另外一台计算机上,它就可以工作了,这也使得你的 Python 程序更加易于移植。
-
面向对象 -- Python 既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。与其他主要的语言如 C++ 和 Java 相比,Python 以一种非常强大又简单的方式实现面向对象编程。
-
可扩展性 -- 如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用 C 或 C++ 编写,然后在你的 Python 程序中使用它们。
-
丰富的库 -- Python 标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV 文件、密码系统、GUI(图形用户界面)、Tk 和其他与系统有关的操作。记住,只要安装了 Python,所有这些功能都是可用的。这被称作 Python 的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如 wxPython、Twisted 和 Python 图像库等等。
-
规范的代码 -- Python 采用强制缩进的方式使得代码具有极佳的可读性。
(2)缺点
-
运行速度,有速度要求的话,用 C++ 改写关键部分吧。
-
国内市场较小(国内以 Python 来做主要开发的,目前只有一些 web2.0 公司)。但时间推移,目前很多国内软件公司,尤其是游戏公司,也开始规模使用他。
-
中文资料匮乏(好的 Python 中文资料屈指可数,现在应该变多了)。托社区的福,有几本优秀的教材已经被翻译了,但入门级教材多,高级内容还是只能看英语版。
-
构架选择太多(没有像 C# 这样的官方 .net 构架,也没有像 ruby 由于历史较短,构架开发的相对集中。Ruby on Rails 构架开发中小型web程序天下无敌)。不过这也从另一个侧面说明,python比较优秀,吸引的人才多,项目也多。
5.Python 的主要运用领域有:
-
云计算:云计算最热的语言,典型的应用OpenStack
-
WEB开发:许多优秀的 WEB 框架,许多大型网站是Python开发、YouTube、Dropbox、Douban……典型的Web框架包括Django
-
科学计算和人工智能:典型的图书馆NumPy、SciPy、Matplotlib、Enided图书馆、熊猫
-
系统操作和维护:操作和维护人员的基本语言
-
金融:定量交易、金融分析,在金融工程领域,Python 不仅使用最多,而且其重要性逐年增加。
-
图形 GUI:PyQT,WXPython,TkInter
Python 在一些公司的运用有:
-
谷歌:谷歌应用程序引擎,代码。Google.com、 Google 爬虫、Google 广告和其他项目正在广泛使用 Python。
-
CIA:美国中情局网站是用 Python 开发的。
-
NASA:美国航天局广泛使用 Python 进行数据分析和计算。
-
YouTube:世界上最大的视频网站 YouTube 是用 Python 开发的。
-
Dropbox:美国最大的在线云存储网站,全部用 Python 实现,每天处理 10 亿的文件上传和下载。
-
Instagram:美国最大的照片共享社交网站,每天有 3000 多万张照片被共享,所有这些都是用 Python 开发的。
-
Facebook:大量的基本库是通过 Python 实现的
-
Red Hat/Centos:世界上最流行的 Linux 发行版中的 Yum 包管理工具是用 Python 开发的
-
Douban:几乎所有公司的业务都是通过 Python 开发的。
-
知乎:中国最大的 Q&A 社区,通过 Python 开发(国外 Quora)
除此之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝、土豆、新浪、果壳等公司正在使用 Python 来完成各种任务。
二.第一个 Python 程序
1. 第一个HelloPython程序
(1)Python 源程序的基本概念
-
Python 源程序就是一个特殊格式的文本文件,可以使用任意文本编辑软件做
Python的开发 -
Python 程序的 文件扩展名 通常都是
.py
(2)演练步骤
目前的演示步骤是在Linux 终端 中实现的
-
在桌面下,新建
认识Python目录 -
在
认识Python目录下新建01-HelloPython.py文件 -
使用 gedit 编辑
01-HelloPython.py并且输入以下内容:

print("hello python")
print("hello world")
-
在终端中输入以下命令执行
01-HelloPython.py
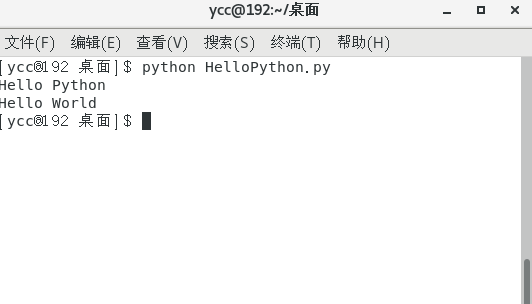
$ python 01-HelloPython.py
python中学习的第一个 函数
(3)BUG
关于错误
-
编写的程序不能正常执行,或者执行的结果不是我们期望的
-
俗称
BUG,是程序员在开发时非常常见的,初学者常见错误的原因包括:-
手误
-
对已经学习过的知识理解还存在不足
-
对语言还有需要学习和提升的内容
-
-
在学习语言时,不仅要学会语言的语法,而且还要学会如何认识错误和解决错误的方法
第一个演练中的常见错误
-
1> 手误,例如使用
pirnt("Hello world")
NameError: name 'pirnt' is not defined 名称错误:'pirnt' 名字没有定义
-
2> 将多条
print写在一行
SyntaxError: invalid syntax 语法错误:语法无效
每行代码负责完成一个动作
-
3> 缩进错误
IndentationError: unexpected indent 缩进错误:不期望出现的缩进
Python 是一个格式非常严格的程序设计语言
目前而言,记住每行代码前面都不要增加空格
-
4> python 2.x 默认不支持中文
目前市场上有两个 Python 的版本并存着,分别是 Python 2.x 和 Python 3.x
-
Python 2.x 默认不支持中文,具体原因,等到介绍 字符编码 时给大家讲解
-
Python 2.x 的解释器名称是 python
-
Python 3.x 的解释器名称是 python3

SyntaxError: Non-ASCII character '\xe4' in file 01-HelloPython.py on line 3, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details 语法错误: 在 01-HelloPython.py 中第 3 行出现了非 ASCII 字符 '\xe4',但是没有声明文件编码 请访问 http://python.org/dev/peps/pep-0263/ 了解详细信息
ASCII字符只包含256个字符,不支持中文
单词列表:
* error 错误 * name 名字 * defined 已经定义 * syntax 语法 * invalid 无效 * Indentation 索引 * unexpected 意外的,不期望的 * character 字符 * line 行 * encoding 编码 * declared 声明 * details 细节,详细信息 * ASCII 一种字符编码
2.Python 2.x与3.x版本简介
目前市场上有两个 Python 的版本并存着,分别是 Python 2.x 和 Python 3.x
新的 Python 程序建议使用
Python 3.0版本的语法
-
Python 2.x 是 过去的版本
-
解释器名称是 python
-
-
Python 3.x 是 现在和未来 主流的版本
-
解释器名称是 python3
-
相对于
Python的早期版本,这是一个 较大的升级 -
为了不带入过多的累赘,
Python 3.0在设计的时候 没有考虑向下兼容-
许多早期
Python版本设计的程序都无法在Python 3.0上正常执行
-
-
Python 3.0 发布于 2008 年
-
到目前为止,Python 3.0 的稳定版本已经有很多年了
-
Python 3.3 发布于 2012
-
Python 3.4 发布于 2014
-
Python 3.5 发布于 2015
-
Python 3.6 发布于 2016
-
-
-
为了照顾现有的程序,官方提供了一个过渡版本 —— Python 2.6
-
基本使用了
Python 2.x的语法和库 -
同时考虑了向
Python 3.0的迁移,允许使用部分Python 3.0的语法与函数 -
2010 年中推出的
Python 2.7被确定为 最后一个Python 2.x 版本
-
提示:如果开发时,无法立即使用 Python 3.0(还有极少的第三方库不支持 3.0 的语法),建议
先使用
Python 3.0版本进行开发然后使用
Python 2.6、Python 2.7来执行,并且做一些兼容性的处理
3.执行 Python 程序的三种方式
(1)解释器
Python 的解释器 python/python3
# 使用 python 2.x 解释器 $ python xxx.py # 使用 python 3.x 解释器 $ python3 xxx.py
其他解释器(知道)
Python 的解释器 如今有多个语言的实现,包括:
-
CPython—— 官方版本的 C 语言实现 -
Jython—— 可以运行在 Java 平台 -
IronPython—— 可以运行在 .NET 和 Mono 平台 -
PyPy—— Python 实现的,支持 JIT 即时编译
(2)交互式运行
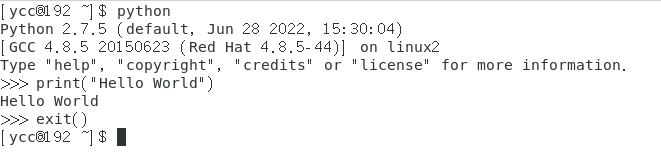
交互式运行Python程序
-
直接在终端中运行解释器,而不输入要执行的文件名
-
在 Python 的
Shell中直接输入 Python 的代码,会立即看到程序执行结果
(例如在Linux虚拟机的终端中:)
1.优缺点
优点:
-
适合于学习/验证 Python 语法或者局部代码
缺点:
-
代码不能保存
-
不适合运行太大的程序
2.退出
退出官方的解释器
1> 直接输入 exit()
>>> exit()
2> 使用热键退出
在 python 解释器中,按热键 ctrl + d 可以退出解释器
3.IPython
-
IPython 中 的 “I” 代表 交互 interactive
特点
-
IPython 是一个 python 的 交互式 shell,比默认的
python shell好用得多-
支持自动补全
-
自动缩进
-
支持
bash shell命令 -
内置了许多很有用的功能和函数
-
-
IPython 是基于 BSD 开源的
版本
-
Python 2.x 使用的解释器是 ipython
-
Python 3.x 使用的解释器是 ipython3
-
要退出解释器可以有以下两种方式:
1> 直接输入 exit
In [1]: exit
2> 使用热键退出
在 IPython 解释器中,按热键 ctrl + d,IPython 会询问是否退出解释器
IPython 的安装(在乌班图中适用)
$ sudo apt install ipython
(3)IDE-PyCharm
1.集成开发环境(IDE)
集成开发环境(IDE,Integrated Development Environment)—— 集成了开发软件需要的所有工具,一般包括以下工具:
-
图形用户界面
-
代码编辑器(支持 代码补全/自动缩进)
-
编译器/解释器
-
调试器(断点/单步执行)
-
……
2.PyCharm 介绍
-
PyCharm是 Python 的一款非常优秀的集成开发环境 -
PyCharm除了具有一般 IDE 所必备功能外,还可以在Windows、Linux、macOS下使用 -
PyCharm适合开发大型项目-
一个项目通常会包含 很多源文件
-
每个 源文件 的代码行数是有限的,通常在几百行之内
-
每个 源文件 各司其职,共同完成复杂的业务功能
-
3.PyCharm 快速体验
-
文件导航区域 能够 浏览/定位/打开 项目文件
-
文件编辑区域 能够 编辑 当前打开的文件
-
控制台区域 能够:
-
输出程序执行内容
-
跟踪调试代码的执行
-
-
右上角的 工具栏 能够 执行(SHIFT + F10) / 调试(SHIFT + F9) 代码
-
通过控制台上方的单步执行按钮(F8),可以单步执行代码
4.Pyc 文件(了解)
C是compiled编译过 的意思
字节码
-
Python在解释源程序时是分成两个步骤的-
首先处理源代码,编译 生成一个二进制 字节码
-
再对 字节码 进行处理,才会生成 CPU 能够识别的 机器码
-
-
有了模块的字节码文件之后,下一次运行程序时,如果在 上次保存字节码之后 没有修改过源代码,Python 将会加载 .pyc 文件并跳过编译这个步骤
-
当
Python重编译时,它会自动检查源文件和字节码文件的时间戳 -
如果你又修改了源代码,下次程序运行时,字节码将自动重新创建
提示:有关模块以及模块的其他导入方式,后续课程还会逐渐展开!
模块是 Python 程序架构的一个核心概念
三.PyCharm 的初始设置
目标(仅了解,一下内容为在linux中运行提供备用参考)
-
恢复 PyCharm 的初始设置
-
第一次启动 PyCharm
-
新建一个 Python 项目
-
设置 PyCharm 的字体显示
-
PyCharm 的升级以及其他
PyCharm 的官方网站地址是:PyCharm: the Python IDE for Professional Developers by JetBrains
1. 恢复 PyCharm 的初始设置
PyCharm 的 配置信息 是保存在 用户家目录下 的 .PyCharmxxxx.x 目录下的,xxxx.x 表示当前使用的 PyCharm 的版本号
如果要恢复 PyCharm 的初始设置,可以按照以下步骤进行:
-
-
关闭正在运行的
PyCharm
-
-
-
在终端中执行以下终端命令,删除
PyCharm的配置信息目录:
-
$ rm -r ~/.PyCharm2016.3
-
-
重新启动
PyCharm
-
2.第一次启动 PyCharm
-
导入配置信息
-
选择许可协议
-
配置初始界面
(1)导入配置信息
-
在第一次启动
PyCharm时,会首先提示用户是否导入 之前的配置信息 -
如果是第一次使用,直接点击 OK 按钮
(2)选择许可协议
-
PyCharm 是一个付费软件,购买费用为 199$ / 年 或者 19.90$ / 月
-
不过 PyCharm 提供了对 学生和教师免费使用的版本
-
商业版本会提示输入注册信息,或者选择免费评估
(3)PyCharm 的配置初始界面
-
在初始配置界面,可以通过
Editor colors and fonts选择 编辑器的配色方案
(4)欢迎界面
-
所有基础配置工作结束之后,就可以看到
PyCharm的 欢迎界面了,通过 欢迎界面 就可以开始开发 Python 项目了
3.新建/打开一个 Python 项目
(1)项目简介
-
开发 项目 就是开发一个 专门解决一个复杂业务功能的软件
-
通常每 一个项目 就具有一个 独立专属的目录,用于保存 所有和项目相关的文件
-
一个项目通常会包含 很多源文件
-
(2)打开 Python 项目
-
直接点击 Open 按钮,然后浏览到之前保存 Python 文件的目录,既可以打开项目
-
打开之后,会在目录下新建一个
.idea的目录,用于保存 项目相关的信息,例如:解释器版本、项目包含的文件等等 -
第一次打开项目,需要耐心等待
PyCharm对项目进行初始设置
设置项目使用的解释器版本
-
打开的目录如果不是由
PyCharm建立的项目目录,有的时候 使用的解释器版本是Python 2.x的,需要单独设置解释器的版本 -
通过 File / Settings... 可以打开设置窗口,如下图所示:
(3)新建项目
1.命名规则
-
以后 项目名 前面都以 数字编号,随着知识点递增,编号递增
-
例如:01_Python 基础、02_分支、03_循环...
-
-
每个项目下的 文件名 都以
hm_xx_知识点方式来命名-
其中 xx 是演练文件的序号
-
-
注意
-
-
命名文件名时建议只使用 小写字母、数字 和 下划线
-
-
-
文件名不能以数字开始
-
-
-
通过 欢迎界面 或者菜单 File / New Project 可以新建项目
2.演练步骤
-
新建
01_Python基础项目,使用 Python 3.x 解释器 -
在项目下新建
hm_01_hello.pyPython 文件 -
编写
print("Hello Python")代码
4.设置 PyCharm 的字体显示
5.PyCharm 的升级以及其他
PyCharm 提供了对 学生和教师免费使用的版本
(1)安装和启动步骤
-
-
执行以下终端命令,解压缩下载后的安装包
-
$ tar -zxvf pycharm-professional-2017.1.3.tar.gz
-
-
将解压缩后的目录移动到
/opt目录下,可以方便其他用户使用
-
/opt目录用户存放给主机额外安装的软件
$ sudo mv pycharm-2017.1.3/ /opt/
-
-
切换工作目录
-
$ cd /opt/pycharm-2017.1.3/bin
-
-
启动
PyCharm
-
$ ./pycharm.sh
(2)设置专业版启动图标
-
在专业版中,选择菜单 Tools / Create Desktop Entry... 可以设置任务栏启动图标
-
注意:设置图标时,需要勾选
Create the entry for all users
-
(3)卸载之前版本的 PyCharm
1.程序安装
-
-
程序文件目录
-
将安装包解压缩,并且移动到
/opt目录下 -
所有的相关文件都保存在解压缩的目录中
-
-
-
配置文件目录
-
启动
PyCharm后,会在用户家目录下建立一个.PyCharmxxx的隐藏目录 -
保存
PyCharm相关的配置信息
-
-
-
快捷方式文件
-
/usr/share/applications/jetbrains-pycharm.desktop
-
在
ubuntu中,应用程序启动的快捷方式通常都保存在/usr/share/applications目录下
2.程序卸载
-
要卸载
PyCharm只需要做以下两步工作: -
-
删除解压缩目录
-
$ sudo rm -r /opt/pycharm-2016.3.1/
-
-
删除家目录下用于保存配置信息的隐藏目录
-
$ rm -r ~/.PyCharm2016.3/
如果不再使用 PyCharm 还需要将
/usr/share/applications/下的jetbrains-pycharm.desktop删掉
(4)教育版安装演练
# 1. 解压缩下载后的安装包 $ tar -zxvf pycharm-edu-3.5.1.tar.gz # 2. 将解压缩后的目录移动到 `/opt` 目录下,可以方便其他用户使用 $ sudo mv pycharm-edu-3.5.1/ /opt/ # 3. 启动 `PyCharm` /opt/pycharm-edu-3.5.1/bin/pycharm.sh
后续课程都使用专业版本演练
设置启动图标
-
-
编辑快捷方式文件
-
$ sudo gedit /usr/share/applications/jetbrains-pycharm.desktop
-
-
按照以下内容修改文件内容,需要注意指定正确的
pycharm目录
-
[Desktop Entry] Version=1.0 Type=Application Name=PyCharm Icon=/opt/pycharm-edu-3.5.1/bin/pycharm.png Exec="/opt/pycharm-edu-3.5.1/bin/pycharm.sh" %f Comment=The Drive to Develop Categories=Development;IDE; Terminal=false StartupWMClass=jetbrains-pycharm
6.多文件项目的演练
-
开发 项目 就是开发一个 专门解决一个复杂业务功能的软件
-
通常每 一个项目 就具有一个 独立专属的目录,用于保存 所有和项目相关的文件
-
一个项目通常会包含 很多源文件
-
目标
-
在项目中添加多个文件,并且设置文件的执行
多文件项目演练
-
在
01_Python基础项目中新建一个hm_02_第2个Python程序.py -
在
hm_02_第2个Python程序.py文件中添加一句print("hello") -
点击右键执行
hm_02_第2个Python程序.py
提示
-
在
PyCharm中,要想让哪一个Python程序能够执行,必须首先通过 鼠标右键的方式执行 一下 -
对于初学者而言,在一个项目中设置多个程序可以执行,是非常方便的,可以方便对不同知识点的练习和测试
-
对于商业项目而言,通常在一个项目中,只有一个 可以直接执行的 Python 源程序
四.python基础学习
1.注释
目标
-
注释的作用
-
单行注释(行注释)
-
多行注释(块注释)
(1)注释的作用
使用用自己熟悉的语言,在程序中对某些代码进行标注说明,增强程序的可读性
(2)单行注释(行注释)
-
以
#开头,#右边的所有东西都被当做说明文字,而不是真正要执行的程序,只起到辅助说明作用 -
示例代码如下:
# 这是第一个单行注释
print("hello python")
为了保证代码的可读性,
#后面建议先添加一个空格,然后再编写相应的说明文字
在代码后面增加的单行注释
-
但是,需要注意的是,为了保证代码的可读性,注释和代码之间 至少要有 两个空格
-
示例代码如下:
print("hello python") # 输出 `hello python`
(3)多行注释(块注释)
-
要在 Python 程序中使用多行注释,可以用 一对 连续的 三个 引号(单引号和双引号都可以)
-
示例代码如下:
"""
这是一个多行注释
在多行注释之间,可以写很多很多的内容……
"""
print("hello python")
什么时候需要使用注释?
-
注释不是越多越好,对于一目了然的代码,不需要添加注释
-
对于 复杂的操作,应该在操作开始前写上若干行注释
-
对于 不是一目了然的代码,应在其行尾添加注释(为了提高可读性,注释应该至少离开代码 2 个空格)
-
绝不要描述代码,假设阅读代码的人比你更懂 Python,他只是不知道你的代码要做什么
在一些正规的开发团队,通常会有 代码审核 的惯例,就是一个团队中彼此阅读对方的代码
关于代码规范
-
Python官方提供有一系列 PEP(Python Enhancement Proposals) 文档 -
其中第 8 篇文档专门针对 Python 的代码格式 给出了建议,也就是俗称的 PEP 8
-
谷歌有对应的中文文档:Python风格规范 — Google 开源项目风格指南
2.运算符
-
算术运算符
-
比较(关系)运算符
-
赋值运算符
-
逻辑运算符
-
位运算符
-
成员运算符
-
身份运算符
-
运算符的优先级
(1)算数运算符
-
算数运算符是 运算符的一种
-
是完成基本的算术运算使用的符号,用来处理四则运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 10 + 20 = 30 |
| - | 减 | 10 - 20 = -10 |
| * | 乘 | 10 * 20 = 200 |
| / | 除 | 10 / 20 = 0.5 |
| // | 取整除 | 返回除法的整数部分(商) 9 // 2 输出结果 4 |
| % | 取余数 | 返回除法的余数 9 % 2 = 1 |
| ** | 幂 | 又称次方、乘方,2 ** 3 = 8 |
eg:
-
在 Python 中
*运算符还可以用于字符串,计算结果就是字符串重复指定次数的结果
In [1]: "-" * 50 Out[1]: '----------------------------------------'

算数运算符的优先级
-
和数学中的运算符的优先级一致,在 Python 中进行数学计算时,同样也是:
-
先乘除后加减
-
同级运算符是 从左至右 计算
-
可以使用
()调整计算的优先级
-
-
以下表格的算数优先级由高到最低顺序排列
| 运算符 | 描述 |
|---|---|
| ** | 幂 (最高优先级) |
| * / % // | 乘、除、取余数、取整除 |
| + - | 加法、减法 |
(2)比较(关系)运算符
| 运算符 | 描述 |
|---|---|
| == | 检查两个操作数的值是否 相等,如果是,则条件成立,返回 True |
| != | 检查两个操作数的值是否 不相等,如果是,则条件成立,返回 True |
| > | 检查左操作数的值是否 大于 右操作数的值,如果是,则条件成立,返回 True |
| < | 检查左操作数的值是否 小于 右操作数的值,如果是,则条件成立,返回 True |
| >= | 检查左操作数的值是否 大于或等于 右操作数的值,如果是,则条件成立,返回 True |
| <= | 检查左操作数的值是否 小于或等于 右操作数的值,如果是,则条件成立,返回 True |
Python 2.x 中判断 不等于 还可以使用
<>运算符
!=在 Python 2.x 中同样可以用来判断 不等于
(3)逻辑运算符
| 运算符 | 逻辑表达式 | 描述 |
|---|---|---|
| and | x and y | 只有 x 和 y 的值都为 True,才会返回 True 否则只要 x 或者 y 有一个值为 False,就返回 False |
| or | x or y | 只要 x 或者 y 有一个值为 True,就返回 True 只有 x 和 y 的值都为 False,才会返回 False |
| not | not x | 如果 x 为 True,返回 False 如果 x 为 False,返回 True |
(4)赋值运算符
-
在 Python 中,使用
=可以给变量赋值 -
在算术运算时,为了简化代码的编写,
Python还提供了一系列的 与 算术运算符 对应的 赋值运算符 -
注意:赋值运算符中间不能使用空格
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| %= | 取 模 (余数)赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c = a 等效于 c = c a |
(5)运算符的优先级
-
以下表格的算数优先级由高到最低顺序排列
| 运算符 | 描述 |
|---|---|
| ** | 幂 (最高优先级) |
| * / % // | 乘、除、取余数、取整除 |
| + - | 加法、减法 |
| <= < > >= | 比较运算符 |
| == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| not or and | 逻辑运算符 |
其他
身份运算符
身份运算符用于 比较 两个对象的 内存地址 是否一致 —— 是否是对同一个对象的引用
-
在
Python中针对None比较时,建议使用is判断
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用同一个对象 | x is y,类似 id(x) == id(y) |
| is not | is not 是判断两个标识符是不是引用不同对象 | x is not y,类似 id(a) != id(b) |
is 与 == 区别:
is 用于判断 两个变量 引用对象是否为同一个 == 用于判断 引用变量的值 是否相等
>>> a = [1, 2, 3] >>> b = [1, 2, 3] >>> b is a False >>> b == a True
3.变量
程序就是用来处理数据的,而变量就是用来存储数据的
(1)定义
-
在 Python 中,每个变量 在使用前都必须赋值,变量 赋值以后 该变量 才会被创建
-
等号(=)用来给变量赋值
-
=左边是一个变量名 -
=右边是存储在变量中的值
-
变量名 = 值
变量定义之后,后续就可以直接使用了
演练
1.演练—iPython(交互式)
# 定义 qq_number 的变量用来保存 qq 号码 In [1]: qq_number = "1234567" # 输出 qq_number 中保存的内容 In [2]: qq_number Out[2]: '1234567' # 定义 qq_password 的变量用来保存 qq 密码 In [3]: qq_password = "123" # 输出 qq_password 中保存的内容 In [4]: qq_password Out[4]: '123'

使用交互式方式,如果要查看变量内容,直接输入变量名即可,不需要使用
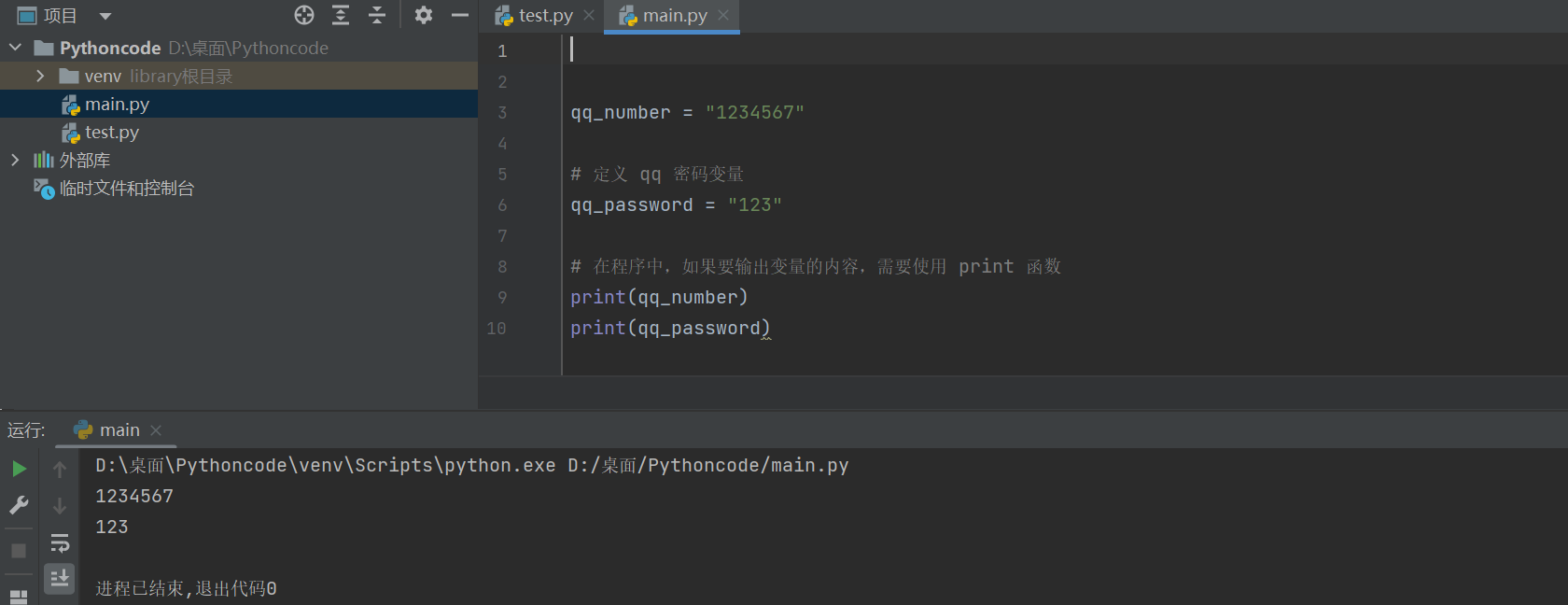
2.演练—PyCharm(解释器)
# 定义 qq 号码变量 qq_number = "1234567" # 定义 qq 密码变量 qq_password = "123" # 在程序中,如果要输出变量的内容,需要使用 print 函数 print(qq_number) print(qq_password)
使用解释器执行,如果要输出变量的内容,必须要要使用
3.变量—超市买苹果
可以用 其他变量的计算结果 来定义变量
变量定义之后,后续就可以直接使用了
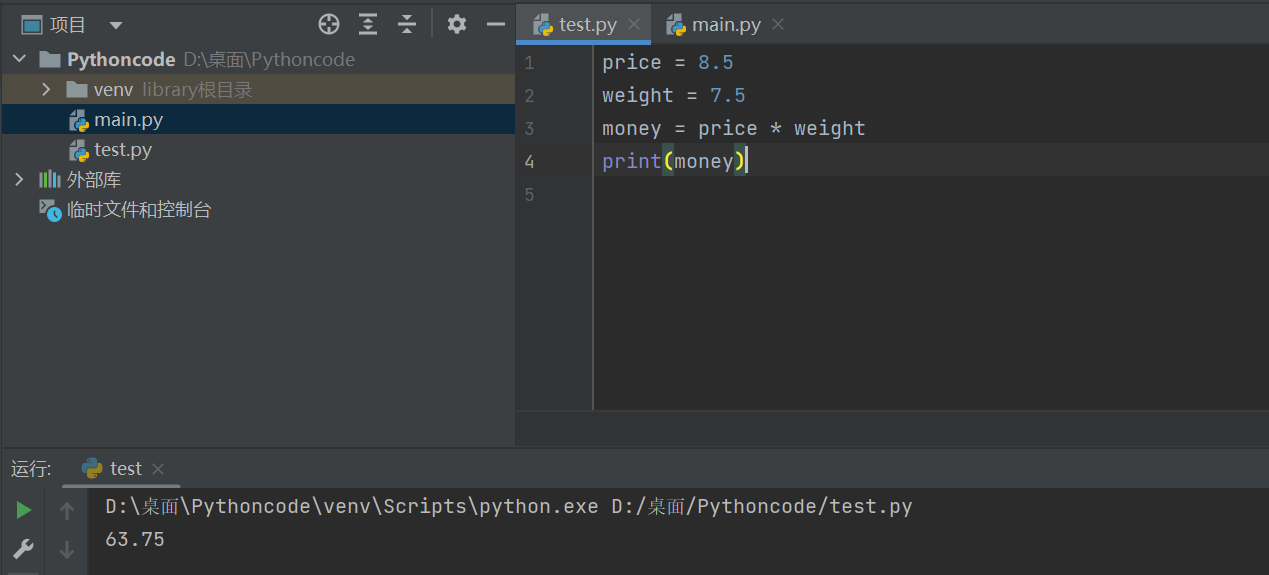
需求
-
苹果的价格是 8.5 元/斤
-
买了 7.5 斤 苹果
-
计算付款金额
# 定义苹果价格变量 price = 8.5 # 定义购买重量 weight = 7.5 # 计算金额 money = price * weight print(money)
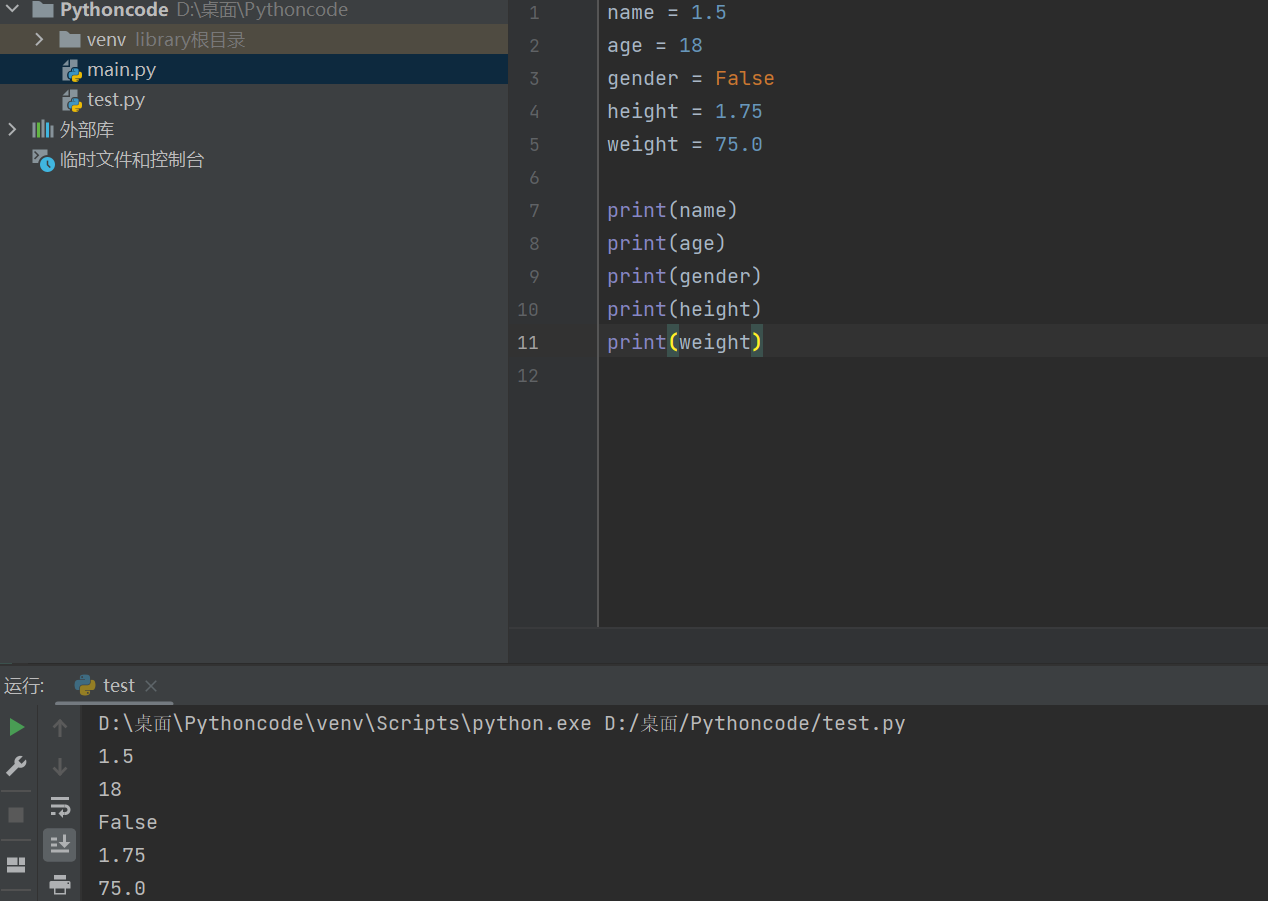
(2)变量的类型
1.变量类型
-
在
Python中定义变量是 不需要指定类型(在其他很多高级语言中都需要) -
数据类型可以分为 数字型 和 非数字型
提示:在 Python 2.x 中,整数 根据保存数值的长度还分为:
int(整数)
long(长整数)
-
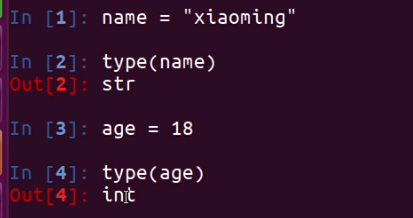
使用
type函数可以查看一个变量的类型(Linux终端)
In [1]: type(name)
eg:
2.不同类型变量之间的计算
(1)数字型变量之间可以直接计算
-
在 Python 中,两个数字型变量是可以直接进行 算数运算的
-
如果变量是
bool型,在计算时-
True对应的数字是1 -
False对应的数字是0
-
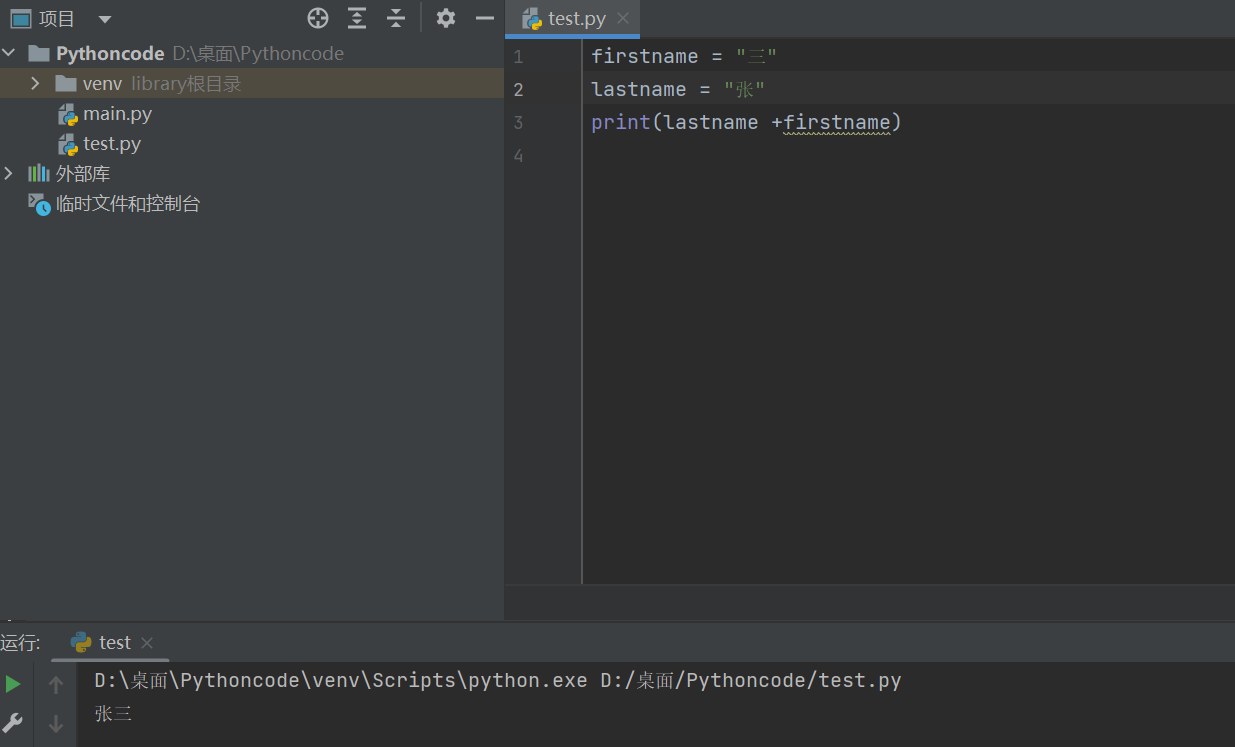
(2)字符串变量 之间使用 + 拼接字符串
-
在 Python 中,字符串之间可以使用
+拼接生成新的字符串
In [1]: first_name = "三" In [2]: last_name = "张" In [3]: first_name + last_name Out[3]: '三张'
(3)字符串变量可以和 整数 使用 * 重复拼接相同的字符串
In [1]: "-" * 50 Out[1]: '--------------------------------------------------'
(4)数字型变量和 字符串 之间 不能进行其他计算
In [1]: first_name = "zhang" In [2]: x = 10 In [3]: x + first_name --------------------------------------------------------------------------- TypeError: unsupported operand type(s) for +: 'int' and 'str' 类型错误:`+` 不支持的操作类型:`int` 和 `str`
(3)变量的输入
-
所谓 输入,就是 用代码 获取 用户通过 键盘 输入的信息
-
在 Python 中,如果要获取用户在 键盘 上的输入信息,需要使用到
input函数
1.input 函数实现键盘输入
-
在 Python 中可以使用
input函数从键盘等待用户的输入 -
用户输入的 任何内容 Python 都认为是一个 字符串
-
语法如下:
字符串变量 = input("提示信息:")
2.类型转换函数
| 函数 | 说明 |
|---|---|
| int(x) | 将 x 转换为一个整数 |
| float(x) | 将 x 转换到一个浮点数 |
演练
变量输入演练 —— 超市买苹果增强版
需求
-
收银员输入 苹果的价格,单位:元/斤
-
收银员输入 用户购买苹果的重量,单位:斤
-
计算并且 输出 付款金额
演练方式 1
# 1. 输入苹果单价
price_str = input("请输入苹果价格:")
# 2. 要求苹果重量
weight_str = input("请输入苹果重量:")
# 3. 计算金额
# 1> 将苹果单价转换成小数
price = float(price_str)
# 2> 将苹果重量转换成小数
weight = float(weight_str)
print("要支付的总金额为:")
print(price * weight)
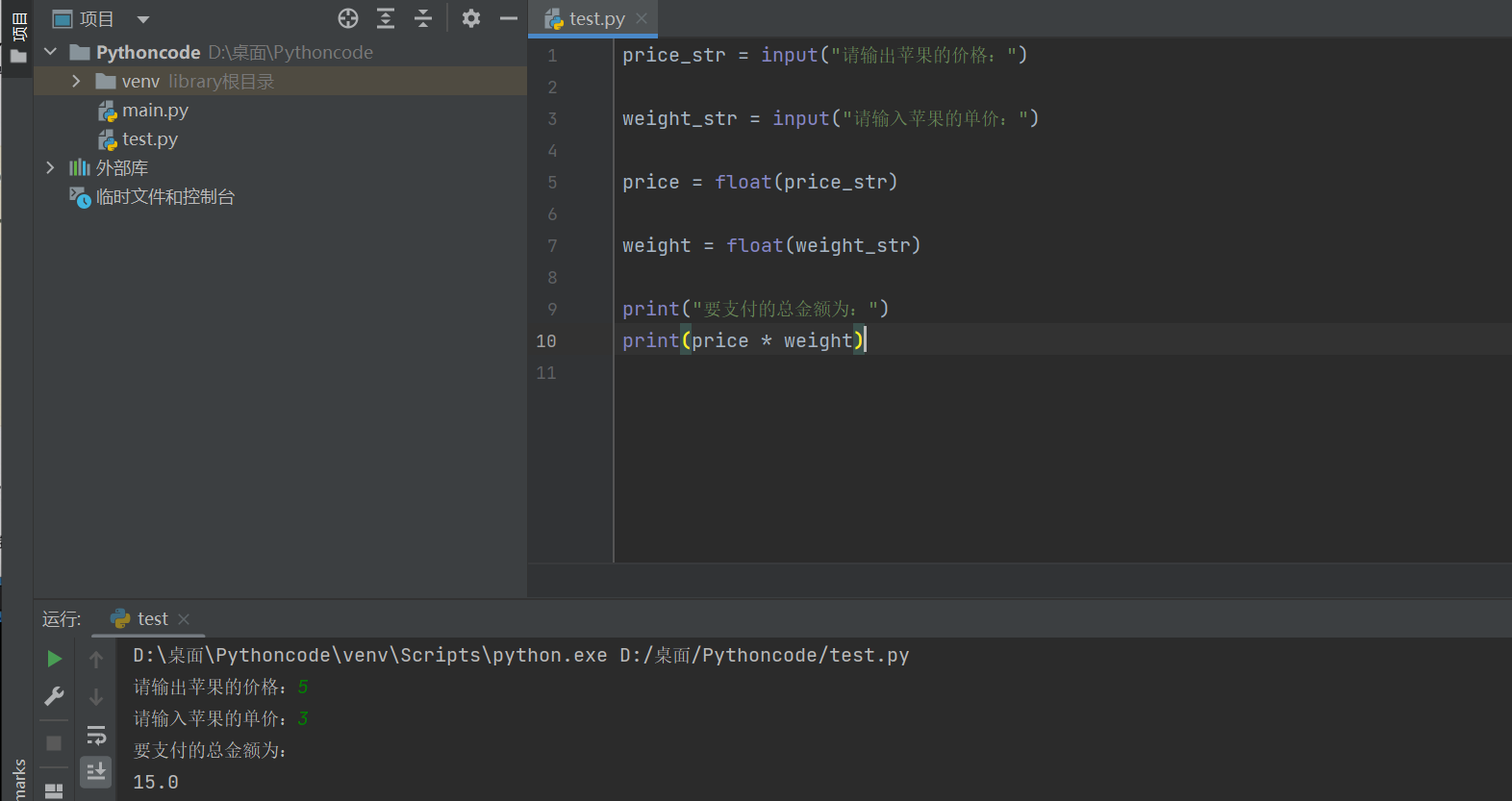
改进:
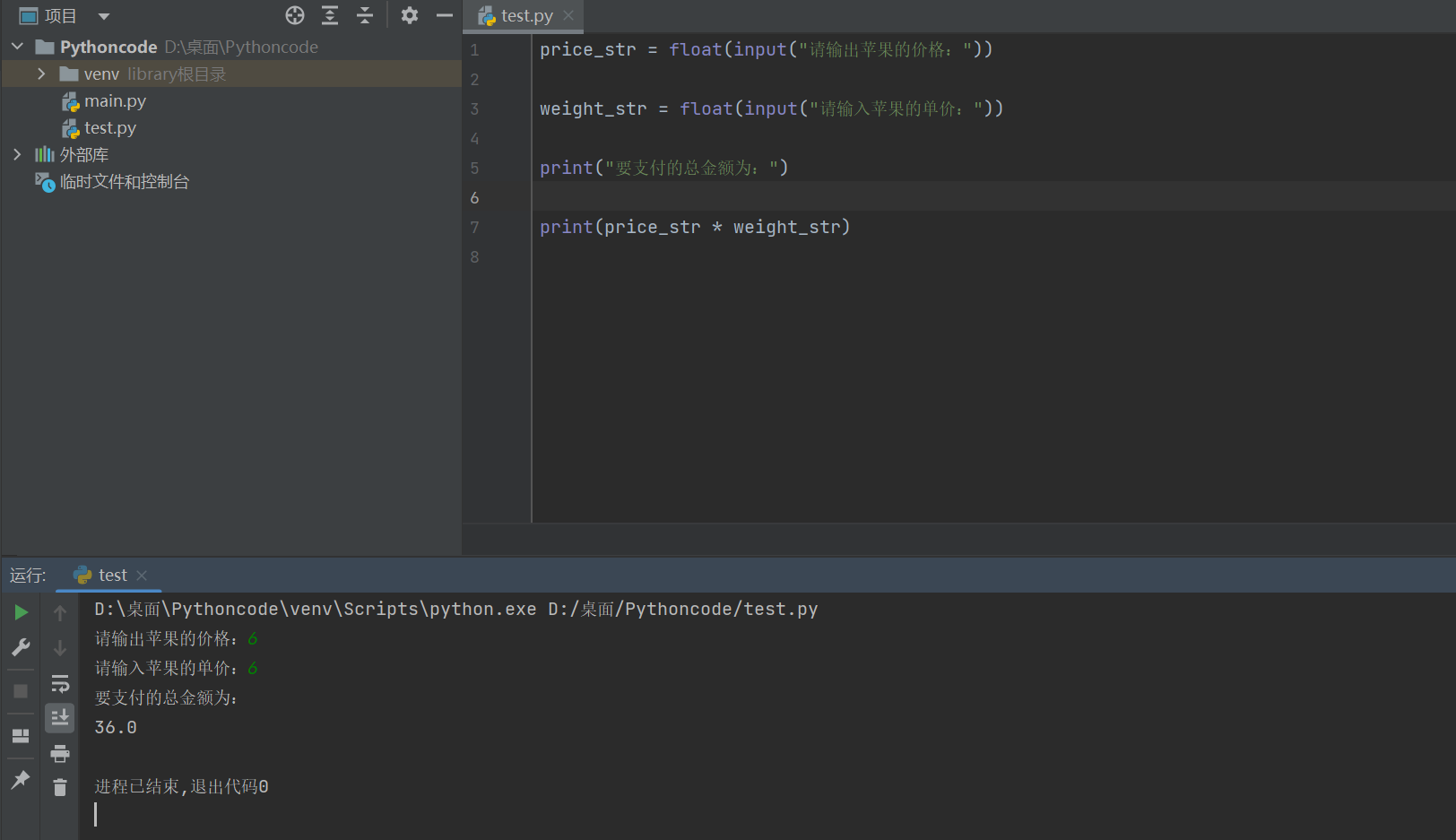
price_str = float(input("请输出苹果的价格:"))
weight_str = float(input("请输入苹果的单价:"))
print("要支付的总金额为:")
print(price_str * weight_str)
(4)变量的格式化输出
苹果单价
9.00元/斤,购买了5.00斤,需要支付45.00元
-
在 Python 中可以使用
print函数将信息输出到控制台 -
如果希望输出文字信息的同时,一起输出 数据,就需要使用到 格式化操作符
-
%被称为 格式化操作符,专门用于处理字符串中的格式-
包含
%的字符串,被称为 格式化字符串 -
%和不同的 字符 连用,不同类型的数据 需要使用 不同的格式化字符
-
| 格式化字符 | 含义 |
|---|---|
| %s | 字符串 |
| %d | 有符号十进制整数,%06d 表示输出的整数显示位数,不足的地方使用 0 补全 |
| %f | 浮点数,%.2f 表示小数点后只显示两位 |
| %% | 输出 % |
-
语法格式如下:
print("格式化字符串" % 变量1)
print("格式化字符串" % (变量1, 变量2...))
知识点 对 print 函数的使用做一个增强
-
在默认情况下,
print函数输出内容之后,会自动在内容末尾增加换行 -
如果不希望末尾增加换行,可以在
print函数输出内容的后面增加, end="" -
其中
""中间可以指定print函数输出内容之后,继续希望显示的内容 -
语法格式如下:
# 向控制台输出内容结束之后,不会换行
print("*", end="")
# 单纯的换行
print("")
end=""表示向控制台输出内容结束之后,不会换行
假设 Python 没有提供 字符串的 * 操作 拼接字符串
eg:
练习
-
定义字符串变量
name,输出 我的名字叫 小明,请多多关照! -
定义整数变量
student_no,输出 我的学号是 000001 -
定义小数
price、weight、money,输出 苹果单价 9.00 元/斤,购买了 5.00 斤,需要支付 45.00 元 -
定义一个小数
scale,输出 数据比例是 10.00%
name = "小明"
print("我的名字叫%s,请多多关照" % name)
student_no = 1
print("%06d" % student_no)
price = 9
weight = 5
money = 45
print("苹果单价%.2f元/斤,购买了%.2f斤,需要支付%.2f元" % (price, weight, money))
scale = 0.1
print("%.2f%%" % (scale*100))

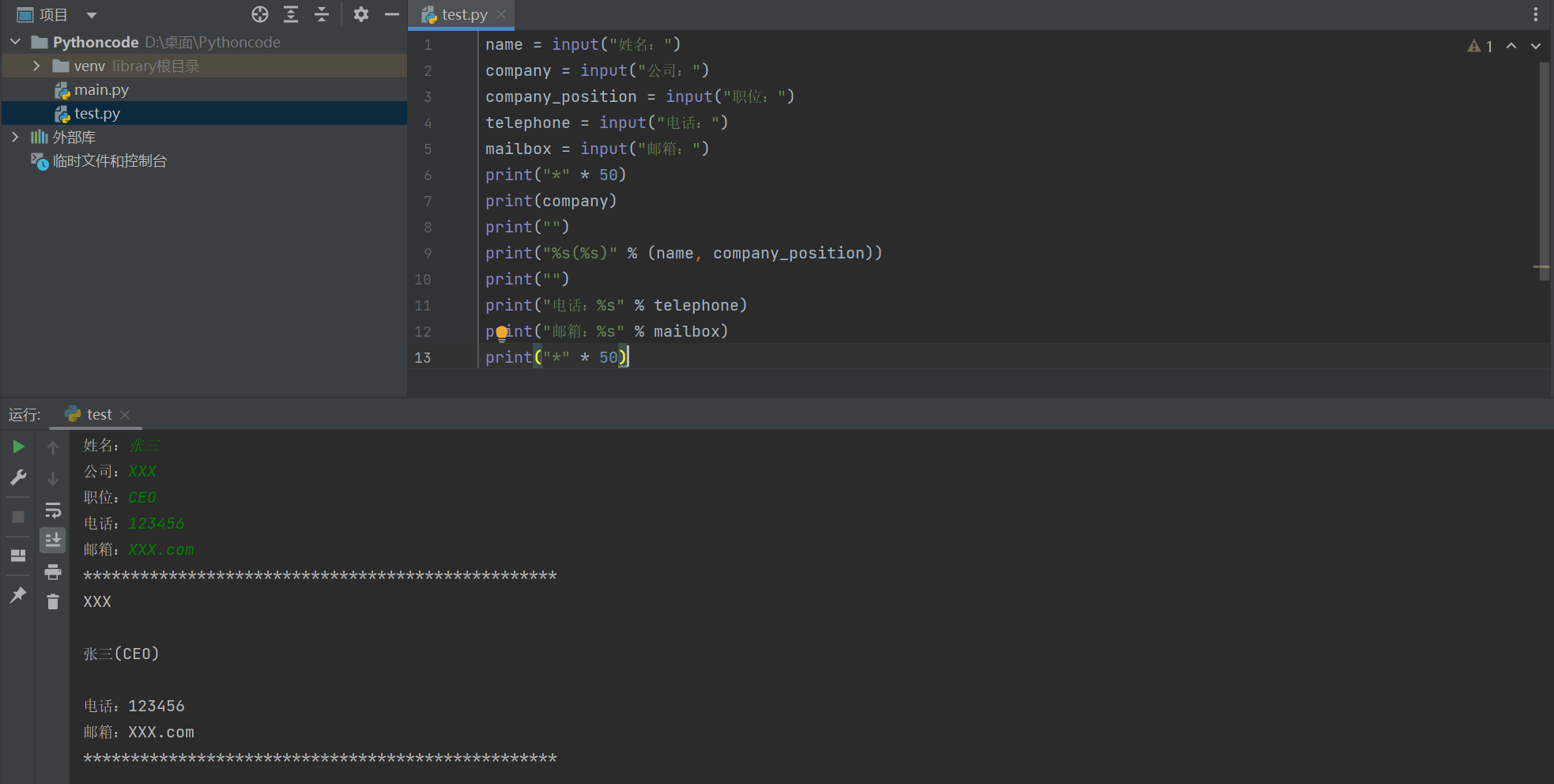
练习 —— 个人名片
-
在控制台依次提示用户输入:姓名、公司、职位、电话、邮箱
-
按照以下格式输出:
************************************************** 公司名称 姓名 (职位) 电话:电话 邮箱:邮箱 **************************************************
实现代码如下:
"""
在控制台依次提示用户输入:姓名、公司、职位、电话、电子邮箱
"""
name = input("姓名:")
company = input("公司:")
company_position = input("职位:")
telephone = input("电话:")
mailbox = input("邮箱:")
print("*" * 50)
print(company)
print("")
print("%s(%s)" % (name, company_position))
print("")
print("电话:%s" % telephone)
print("邮箱:%s" % mailbox)
print("*" * 50)
(5)变量的命名
1.标识符和关键字
标识符
标示符就是程序员定义的 变量名、函数名
名字 需要有 见名知义 的效果,见下图:
-
标示符可以由 字母、下划线 和 数字 组成
-
不能以数字开头
-
不能与关键字重名
eg:
fromNo12 1(1对0错) from#12 0 my_Boolean 1 my-Boolean 0 Obj2 1 2ndObj 0 myInt 1 My_tExt 1 _test 1 test!32 0 haha(da)tt 0 jack_rose 1 jack&rose 0 GUI 1 G.U.I 0
关键字
-
关键字 就是在
Python内部已经使用的标识符 -
关键字 具有特殊的功能和含义
-
开发者 不允许定义和关键字相同的名字的标示符
通过以下命令可以查看 Python 中的关键字
import keyword print(keyword.kwlist)
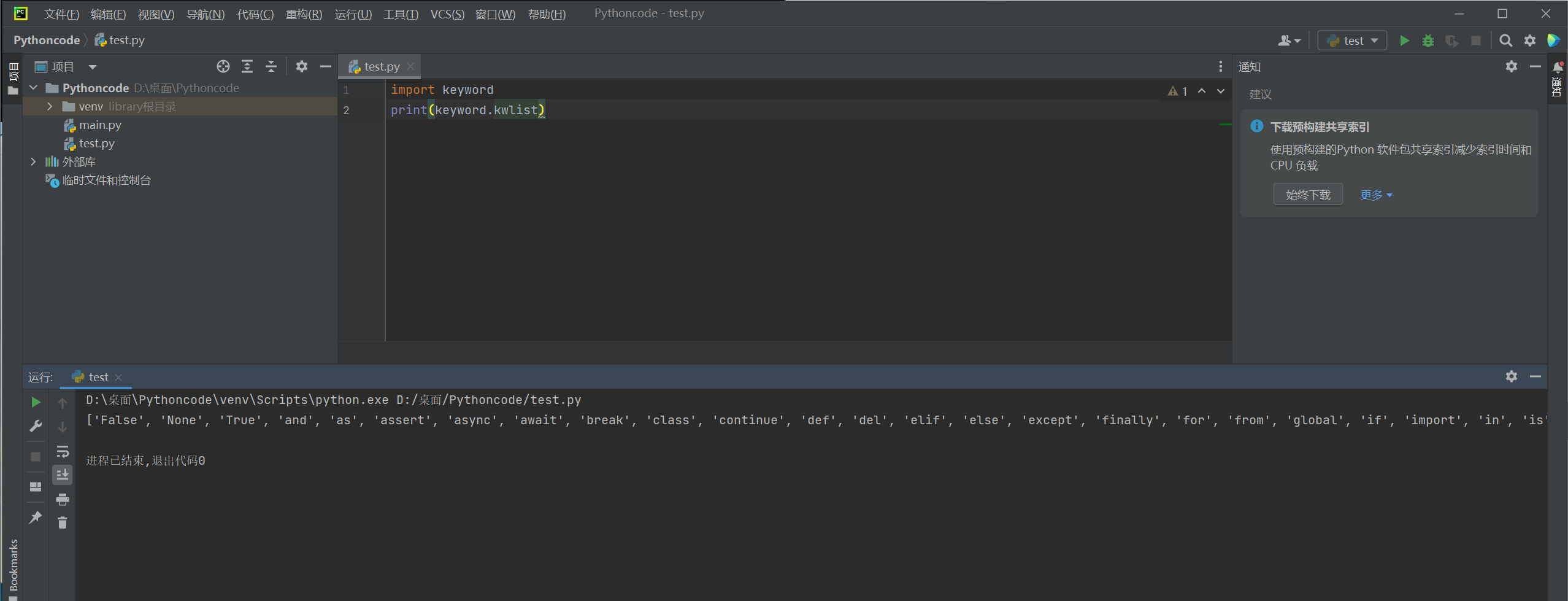
D:\桌面\Pythoncode\venv\Scripts\python.exe D:/桌面/Pythoncode/test.py ['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield'] 进程已结束,退出代码0
提示:关键字的学习及使用,会在后面的课程中不断介绍
import关键字 可以导入一个 “工具包”在
Python中不同的工具包,提供有不同的工具
2.变量的命名规则
命名规则 可以被视为一种 惯例,并无绝对与强制 目的是为了 增加代码的识别和可读性
注意 Python 中的 标识符 是 区分大小写的
-
在定义变量时,为了保证代码格式,
=的左右应该各保留一个空格 -
在
Python中,如果 变量名 需要由 二个 或 多个单词 组成时,可以按照以下方式命名-
每个单词都使用小写字母
-
单词与单词之间使用
_下划线 连接
-
例如:
first_name、last_name、qq_number、qq_password
-
3.驼峰命名法
-
当 变量名 是由二个或多个单词组成时,还可以利用驼峰命名法来命名
-
小驼峰式命名法
-
第一个单词以小写字母开始,后续单词的首字母大写
-
例如:
firstName、lastName
-
-
大驼峰式命名法
-
每一个单词的首字母都采用大写字母
-
例如:
FirstName、LastName、CamelCase
-
4.判断(if)语句
(1)基本语法
在 Python 中,if 语句 就是用来进行判断的,格式如下:
if 要判断的条件:
条件成立时,要做的事情
……
注意:代码的缩进为一个
tab键,或者 4 个空格 —— 建议使用空格
在 Python 开发中,Tab 和空格不要混用!
我们可以把整个 if 语句看成一个完整的代码块
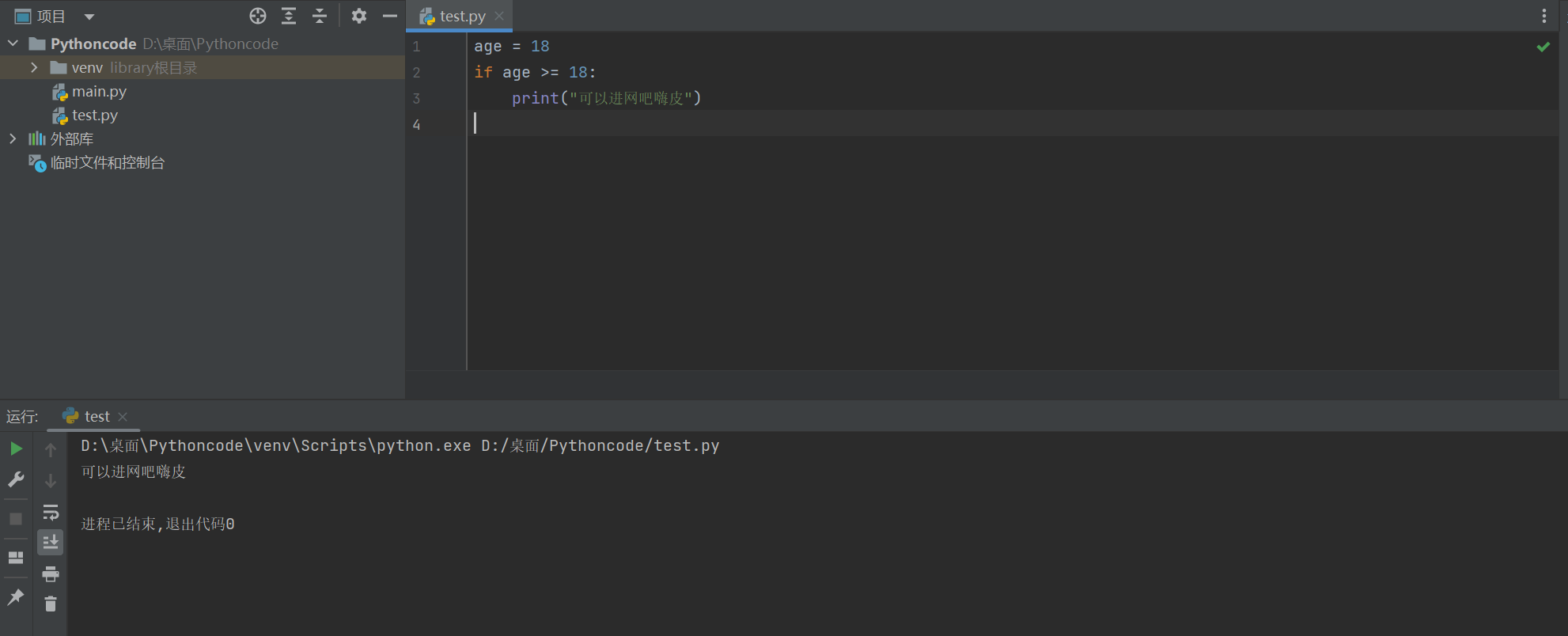
eg:
age = 18
if age >= 18:
print("可以进网吧嗨皮")
注意:
-
if语句以及缩进部分是一个 完整的代码块
(2)else
处理条件不满足的情况
else,格式如下:
if 要判断的条件:
条件成立时,要做的事情
……
else:
条件不成立时,要做的事情
……
注意:
-
if和else语句以及各自的缩进部分共同是一个 完整的代码块
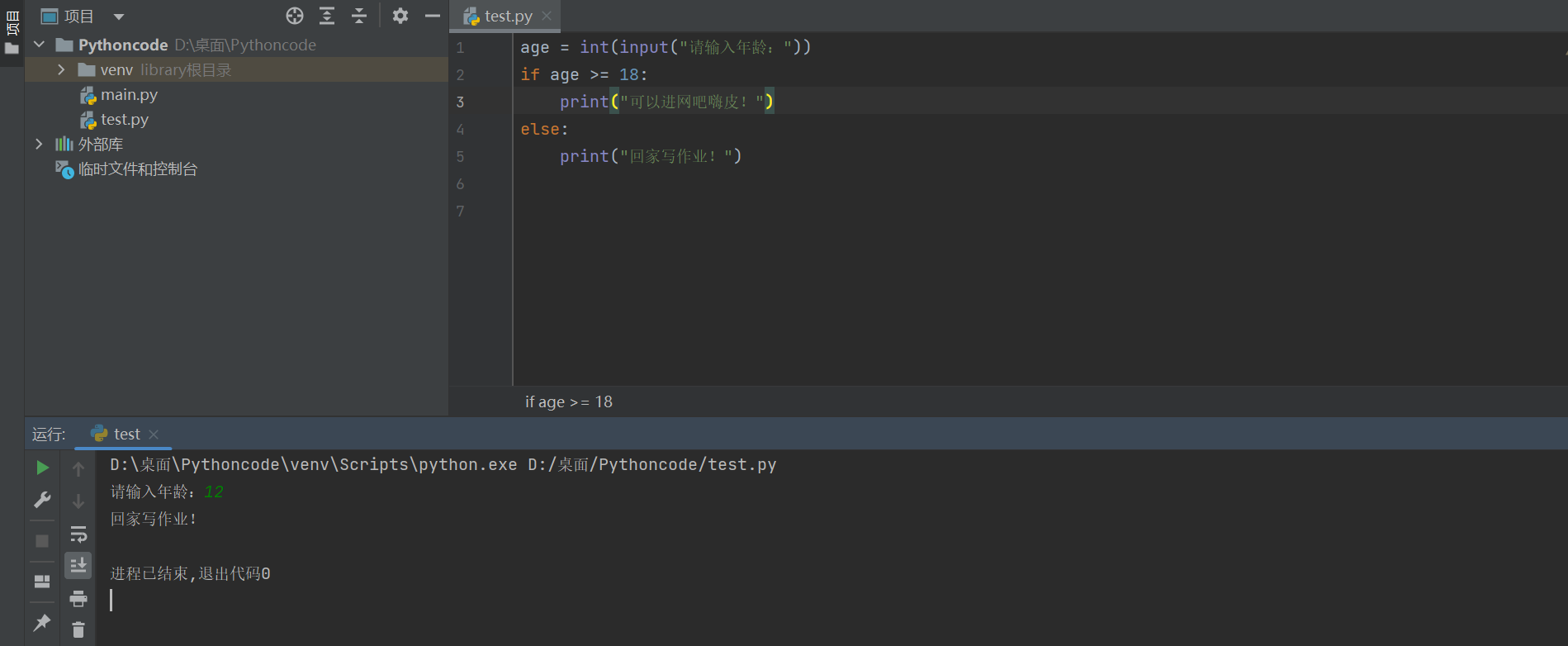
eg:
# 1. 输入用户年龄
age = int(input("今年多大了?"))
# 2. 判断是否满 18 岁
# if 语句以及缩进部分的代码是一个完整的语法块
if age >= 18:
print("可以进网吧嗨皮……")
else:
print("你还没长大,应该回家写作业!")
(3)elif
-
在开发中,使用
if可以 判断条件 -
使用
else可以处理 条件不成立 的情况 -
但是,如果希望 再增加一些条件,条件不同,需要执行的代码也不同 时,就可以使用
elif -
语法格式如下:
if 条件1:
条件1满足执行的代码
……
elif 条件2:
条件2满足时,执行的代码
……
elif 条件3:
条件3满足时,执行的代码
……
else:
以上条件都不满足时,执行的代码
……
注意
-
elif和else都必须和if联合使用,而不能单独使用 -
可以将
if、elif和else以及各自缩进的代码,看成一个 完整的代码块
演练
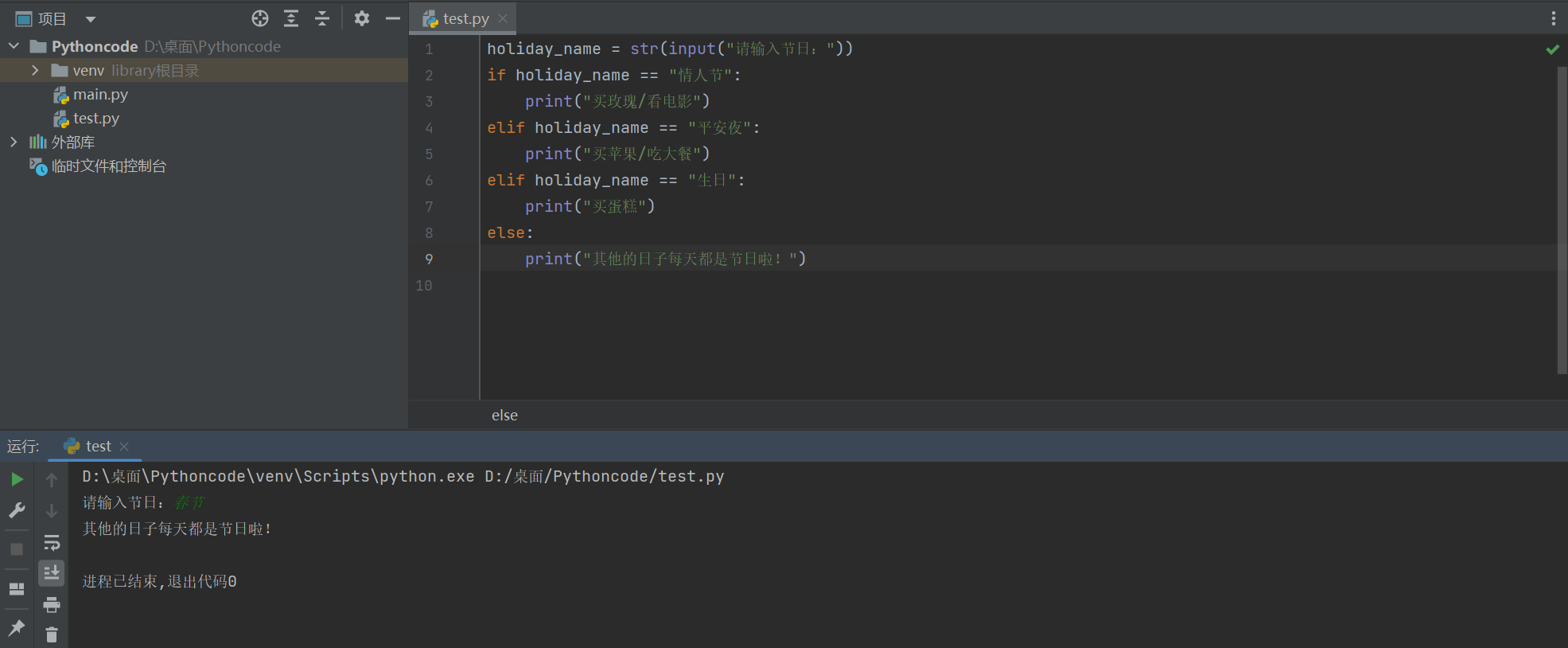
需求
-
定义
holiday_name字符串变量记录节日名称 -
如果是 情人节 应该 买玫瑰/看电影
-
如果是 平安夜 应该 买苹果/吃大餐
-
如果是 生日 应该 买蛋糕
-
其他的日子每天都是节日啊……
holiday_name = str(input("请输入节日:"))
if holiday_name == "情人节":
print("买玫瑰/看电影")
elif holiday_name == "平安夜":
print("买苹果/吃大餐")
elif holiday_name == "生日":
print("买蛋糕")
else:
print("其他的日子每天都是节日啦!")
(4)if 的嵌套
elif 的应用场景是:同时 判断 多个条件,所有的条件是 平级 的
-
在开发中,使用
if进行条件判断,如果希望 在条件成立的执行语句中 再 增加条件判断,就可以使用 if 的嵌套 -
if 的嵌套 的应用场景就是:在之前条件满足的前提下,再增加额外的判断
-
if 的嵌套 的语法格式,除了缩进之外 和之前的没有区别
-
语法格式如下:
if 条件 1:
条件 1 满足执行的代码
……
if 条件 1 基础上的条件 2:
条件 2 满足时,执行的代码
……
# 条件 2 不满足的处理
else:
条件 2 不满足时,执行的代码
# 条件 1 不满足的处理
else:
条件1 不满足时,执行的代码
……
演练
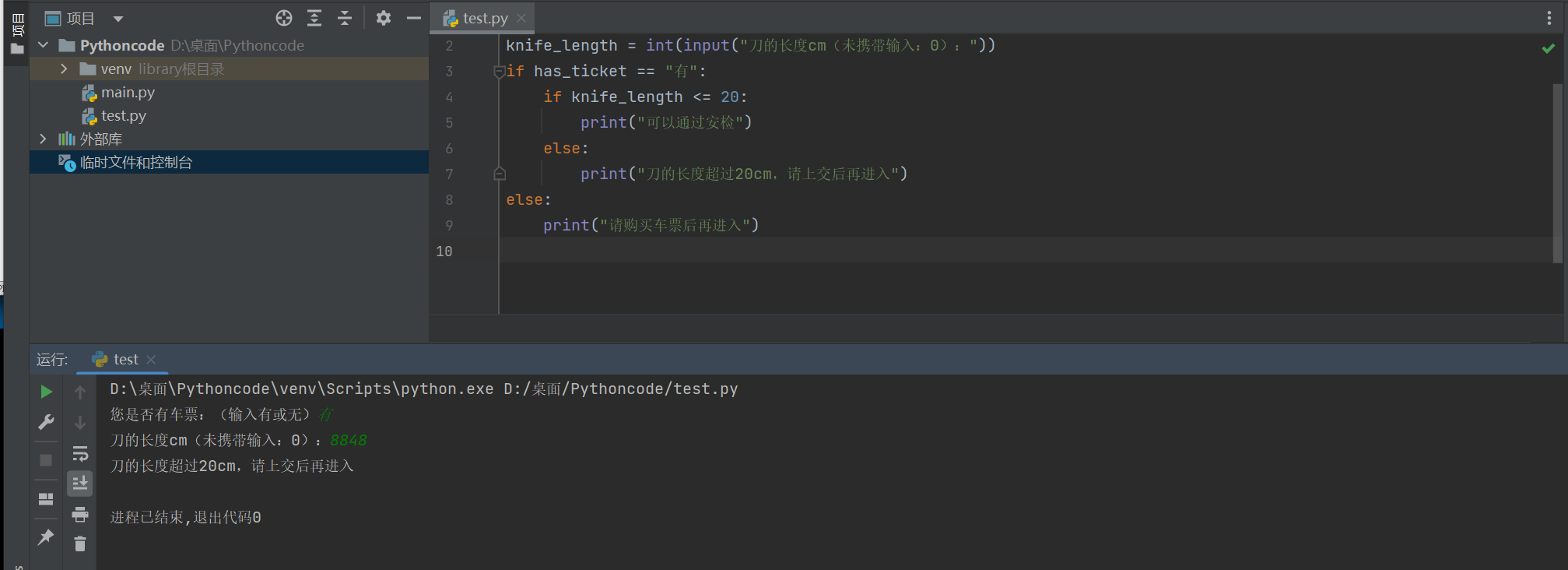
需求
-
定义布尔型变量
has_ticket表示是否有车票 -
定义整型变量
knife_length表示刀的长度,单位:厘米 -
首先检查是否有车票,如果有,才允许进行 安检
-
安检时,需要检查刀的长度,判断是否超过 20 厘米
-
如果超过 20 厘米,提示刀的长度,不允许上车
-
如果不超过 20 厘米,安检通过
-
-
如果没有车票,不允许进门
knife_length = int(input("刀的长度cm(未携带输入:0):"))
if has_ticket == "有":
if knife_length <= 20:
print("可以通过安检")
else:
print("刀的长度超过20cm,请上交后再进入")
else:
print("请购买车票后再进入")
5. 逻辑运算
-
在程序开发中,通常 在判断条件时,会需要同时判断多个条件
-
只有多个条件都满足,才能够执行后续代码,这个时候需要使用到 逻辑运算符
-
逻辑运算符 可以把 多个条件 按照 逻辑 进行 连接,变成 更复杂的条件
-
Python 中的 逻辑运算符 包括:与 and/或 or/非 not 三种
(1)and
条件1 and 条件2
-
与/并且
-
两个条件同时满足,返回
True -
只要有一个不满足,就返回
False
| 条件 1 | 条件 2 | 结果 |
|---|---|---|
| 成立 | 成立 | 成立 |
| 成立 | 不成立 | 不成立 |
| 不成立 | 成立 | 不成立 |
| 不成立 | 不成立 | 不成立 |
(2)or
条件1 or 条件2
-
或/或者
-
两个条件只要有一个满足,返回
True -
两个条件都不满足,返回
False
| 条件 1 | 条件 2 | 结果 |
|---|---|---|
| 成立 | 成立 | 成立 |
| 成立 | 不成立 | 成立 |
| 不成立 | 成立 | 成立 |
| 不成立 | 不成立 | 不成立 |
(3)not
not 条件
-
非/不是
| 条件 | 结果 |
|---|---|
| 成立 | 不成立 |
| 不成立 | 成立 |
演练
-
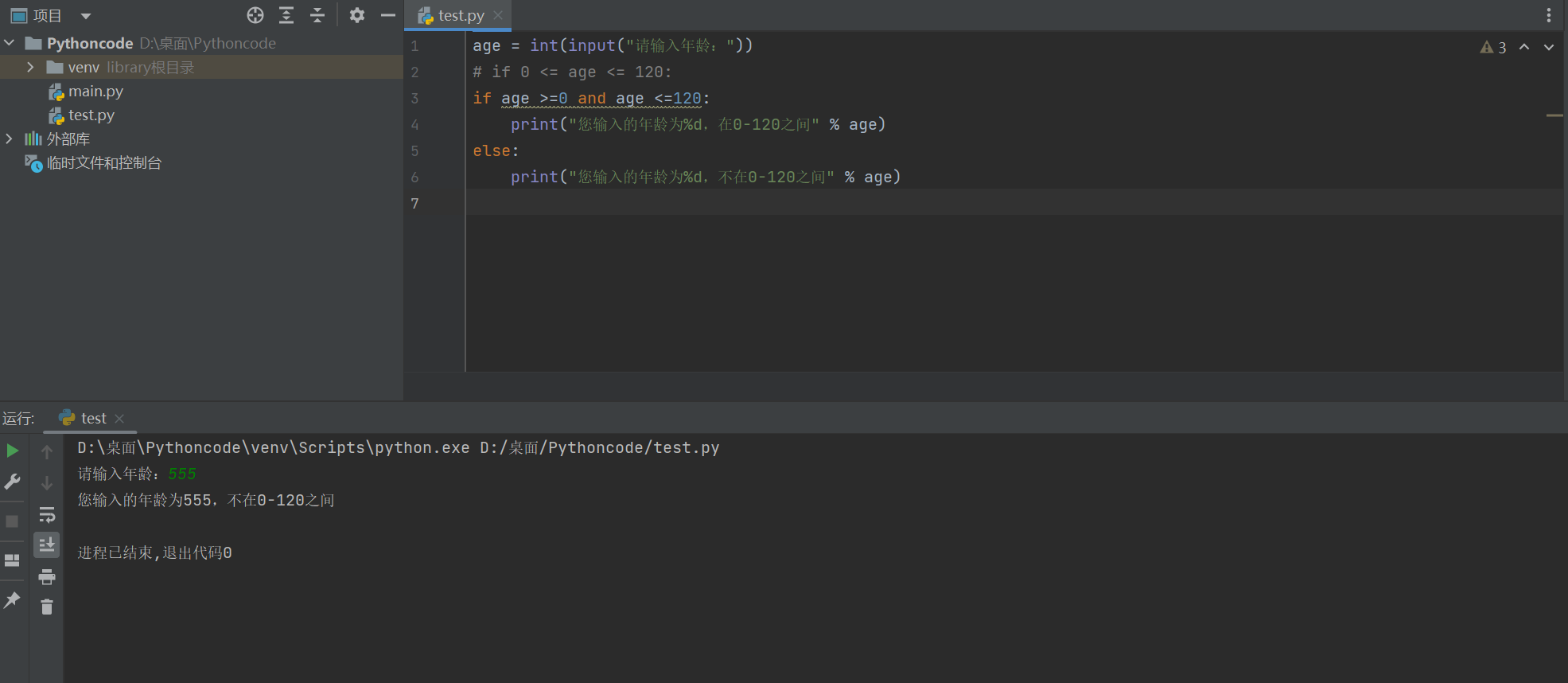
练习1: 定义一个整数变量
age,编写代码判断年龄是否正确-
要求人的年龄在 0-120 之间
-
-
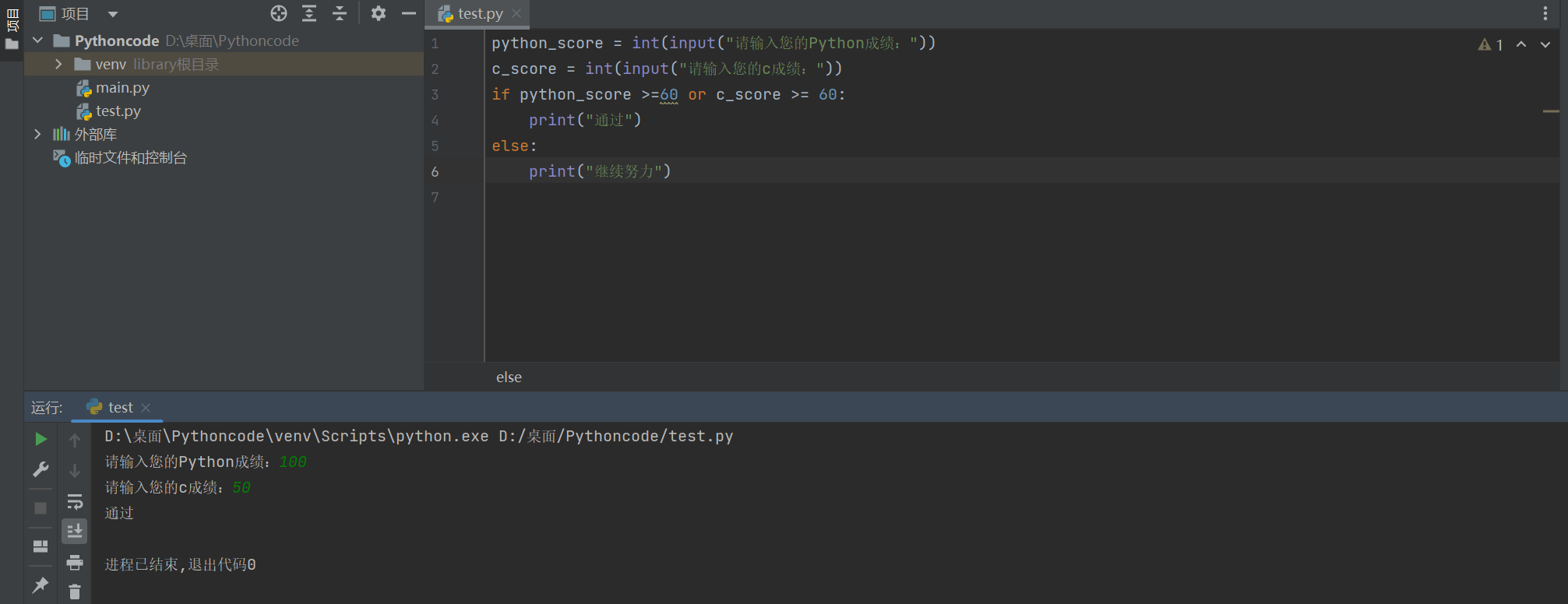
练习2: 定义两个整数变量
python_score、c_score,编写代码判断成绩-
要求只要有一门成绩 > 60 分就算合格
-
-
练习3: 定义一个布尔型变量
is_employee,编写代码判断是否是本公司员工-
如果不是提示不允许入内
-
答案 1:
# 练习1: 定义一个整数变量 age,编写代码判断年龄是否正确
age = int(input("请输入年龄:"))
# if 0 <= age <= 120:
if age >=0 and age <=120:
print("您输入的年龄为%d,在0-120之间" % age)
else:
print("您输入的年龄为%d,不在0-120之间" % age)
答案 2:
# 练习2: 定义两个整数变量 python_score、c_score,编写代码判断成绩
python_score = int(input("请输入您的Python成绩:"))
c_score = int(input("请输入您的c成绩:"))
if python_score >=60 or c_score >= 60:
print("通过")
else:
print("继续努力")
答案 3:
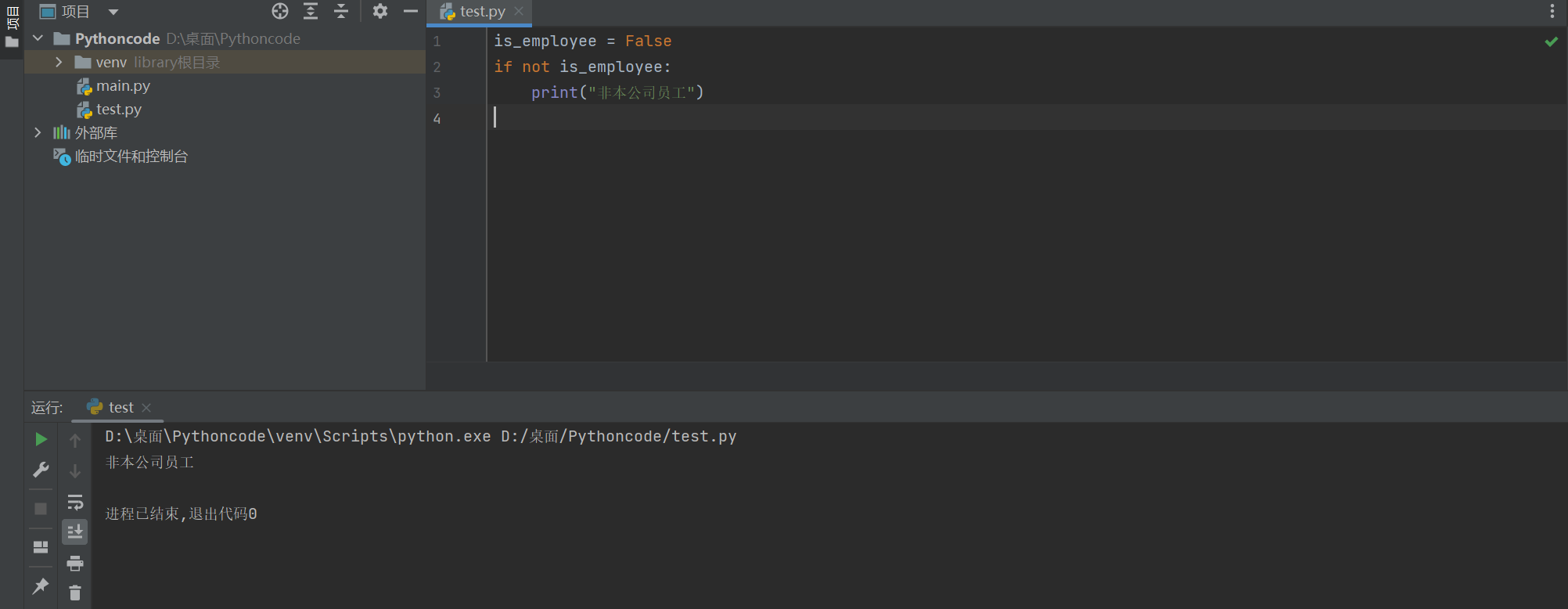
# 练习3: 定义一个布尔型变量 `is_employee`,编写代码判断是否是本公司员工
is_employee = True
# 如果不是提示不允许入内
if not is_employee:
print("非公勿内")
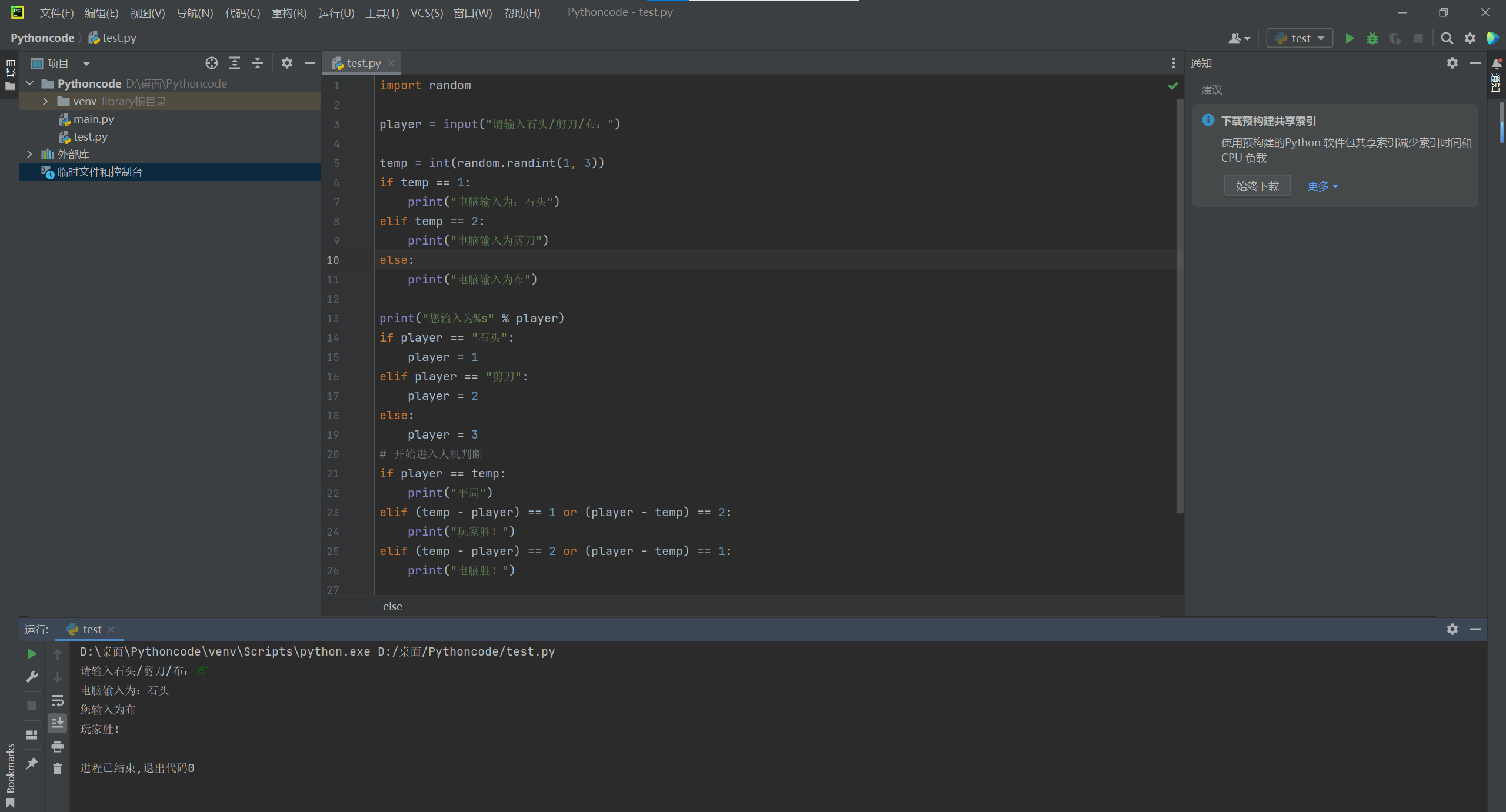
6.Random
演练---石头剪刀布
-
在
Python中,要使用随机数,首先需要导入 随机数 的 模块 —— “工具包”
import random
-
导入模块后,可以直接在 模块名称 后面敲一个
.然后按Tab键,会提示该模块中包含的所有函数 -
random.randint(a, b),返回[a, b]之间的整数,包含a和b -
例如:
random.randint(12, 20) # 生成的随机数n: 12 <= n <= 20 random.randint(20, 20) # 结果永远是 20 random.randint(20, 10) # 该语句是错误的,下限必须小于上限
import random
player = input("请输入石头/剪刀/布:")
temp = int(random.randint(1, 3))
if temp == 1:
print("电脑输入为:石头")
elif temp == 2:
print("电脑输入为剪刀")
else:
print("电脑输入为布")
print("您输入为%s" % player)
if player == "石头":
player = 1
elif player == "剪刀":
player = 2
else:
player = 3
# 开始进入人机判断
if player == temp:
print("平局")
elif (temp - player) == 1 or (player - temp) == 2:
print("玩家胜!")
elif (temp - player) == 2 or (player - temp) == 1:
print("电脑胜!")
7.循环语句
(1)程序的三大流程
-
在程序开发中,一共有三种流程方式:
-
顺序 —— 从上向下,顺序执行代码
-
分支 —— 根据条件判断,决定执行代码的 分支
-
循环 —— 让 特定代码 重复 执行
-
(2)while
初始条件设置 —— 通常是重复执行的 计数器
while 条件(判断 计数器 是否达到 目标次数):
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
处理条件(计数器 + 1)
注意:
-
while语句以及缩进部分是一个 完整的代码块
eg:打印 5 遍 Hello Python
i = 0
while i < 5:
i = i+1
print("Hello Python")
注意:循环结束后,之前定义的计数器条件的数值是依旧存在的
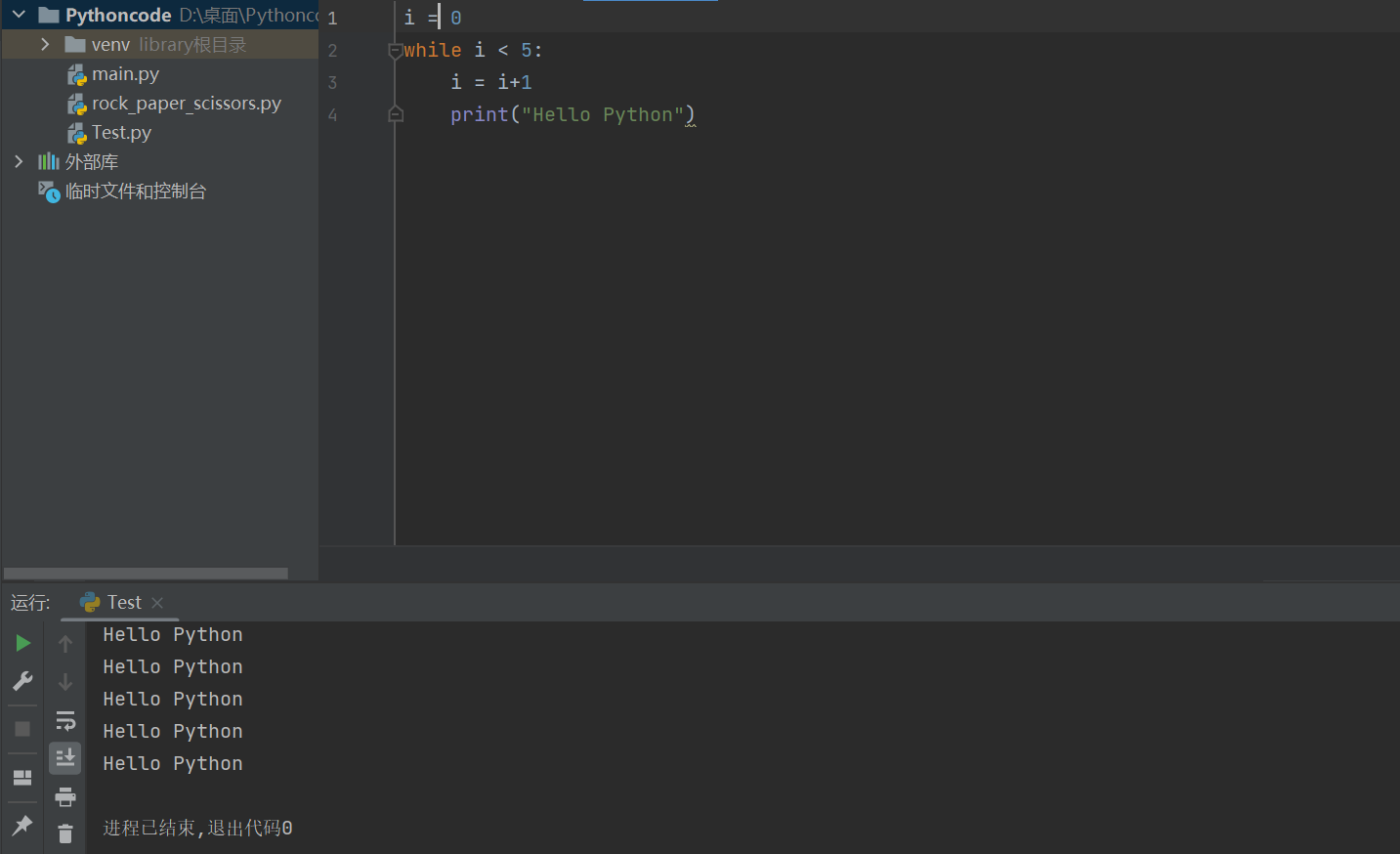
在编写程序时,应该尽量养成习惯:除非需求的特殊要求,否则 循环 的计数都从 0 开始
(3)循环计算
在程序开发中,通常会遇到 利用循环 重复计算 的需求
遇到这种需求,可以:
-
在
while上方定义一个变量,用于 存放最终计算结果 -
在循环体内部,每次循环都用 最新的计算结果,更新 之前定义的变量
需求
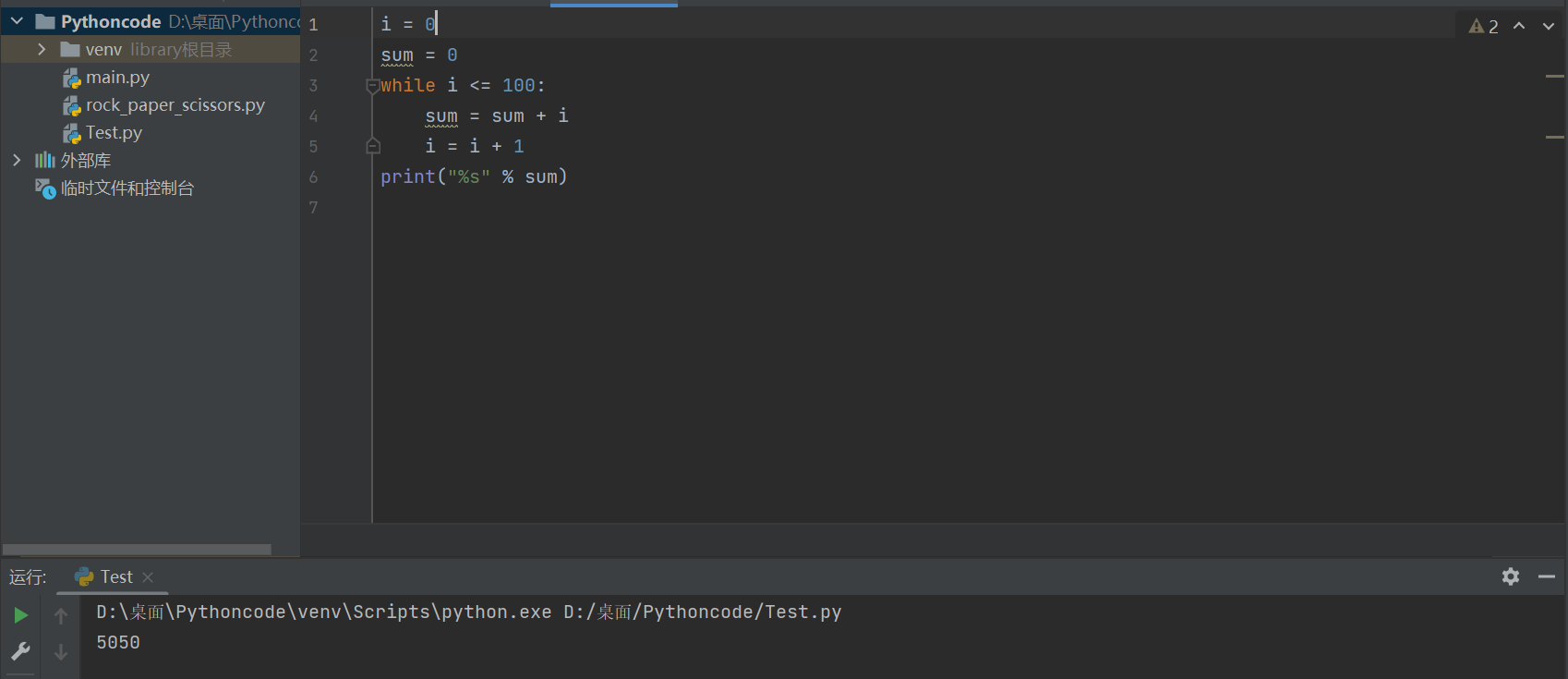
-
计算 0 ~ 100 之间所有数字的累计求和结果
# 计算 0 ~ 100 之间所有数字的累计求和结果
# 0. 定义最终结果的变量
result = 0
# 1. 定义一个整数的变量记录循环的次数
i = 0
# 2. 开始循环
while i <= 100:
# 每一次循环,都让 result 这个变量和 i 这个计数器相加
result += i
# 处理计数器
i += 1
print("0~100之间的数字求和结果 = %d" % result)
-
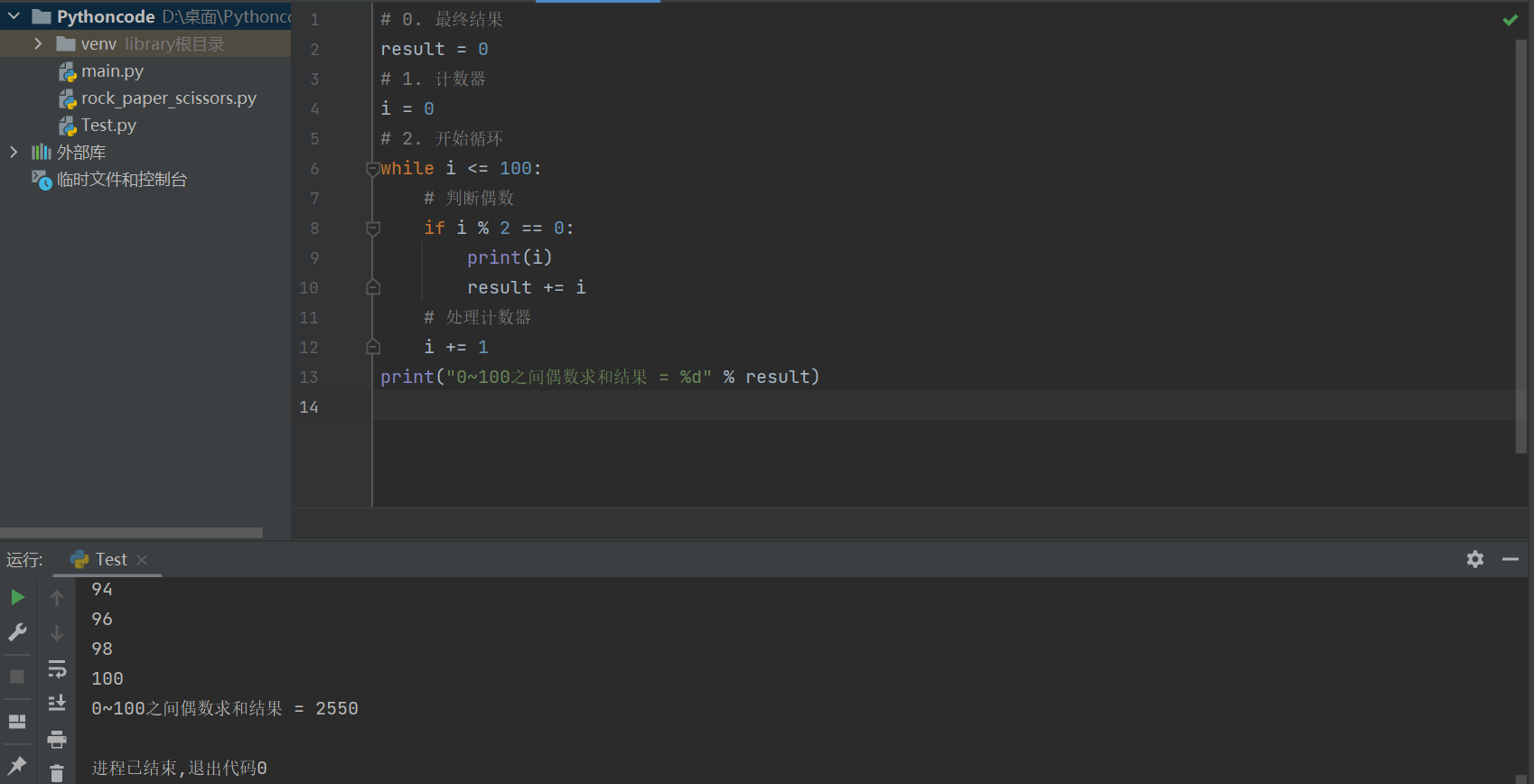
计算 0 ~ 100 之间 所有 偶数 的累计求和结果
开发步骤
-
编写循环 确认 要计算的数字
-
添加 结果 变量,在循环内部 处理计算结果
# 0. 最终结果
result = 0
# 1. 计数器
i = 0
# 2. 开始循环
while i <= 100:
# 判断偶数
if i % 2 == 0:
print(i)
result += i
# 处理计数器
i += 1
print("0~100之间偶数求和结果 = %d" % result)
(4)break/continue
break和continue是专门在循环中使用的关键字
-
break某一条件满足时,退出循环,不再执行后续重复的代码 -
continue某一条件满足时,不执行后续重复的代码
break和continue只针对 当前所在循环 有效
1.break
-
在循环过程中,如果 某一个条件满足后,不 再希望 循环继续执行,可以使用
break退出循环
i = 0
while i < 10:
# break 某一条件满足时,退出循环,不再执行后续重复的代码
# i == 3
if i == 3:
break
print(i)
i += 1
print("over")
break只针对当前所在循环有效
2.continue
-
在循环过程中,如果 某一个条件满足后,不 希望 执行循环代码,但是又不希望退出循环,可以使用
continue -
也就是:在整个循环中,只有某些条件,不需要执行循环代码,而其他条件都需要执行
i = 0
while i < 10:
# 当 i == 7 时,不希望执行需要重复执行的代码
if i == 7:
# 在使用 continue 之前,同样应该修改计数器
# 否则会出现死循环
i += 1
continue
# 重复执行的代码
print(i)
i += 1
-
需要注意:使用
continue时,条件处理部分的代码,需要特别注意,不小心会出现 死循环
continue只针对当前所在循环有效
(5)while循环嵌套
####
-
while嵌套就是:while里面还有while
while 条件 1:
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
while 条件 2:
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
...(省略)...
处理条件 2
处理条件 1
演练
1.用嵌套打印小星星
eg:
temp = 1
while temp <=5:
print("*"*temp)
temp = temp + 1
* ** *** **** *****
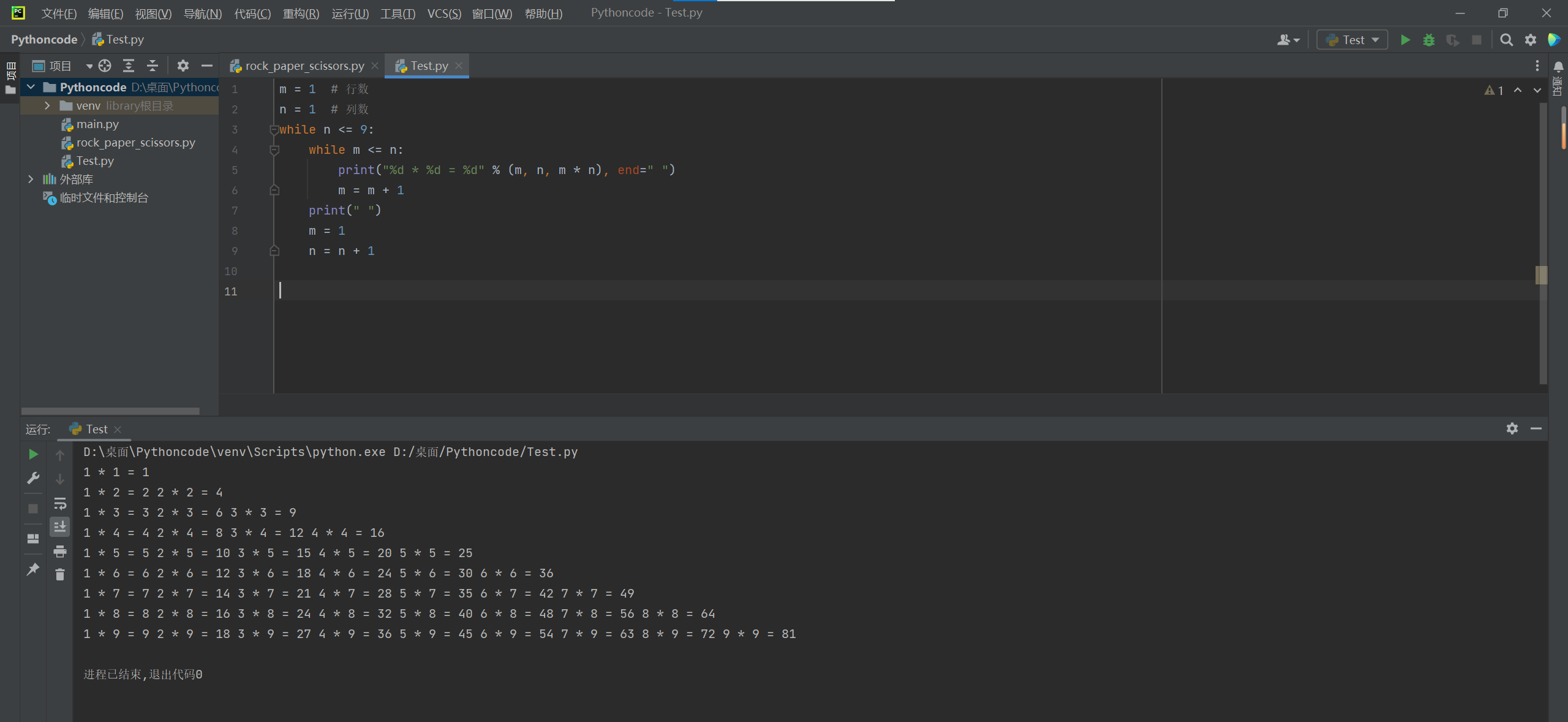
2.九九乘法表
m = 1 # 行数
n = 1 # 列数
while n <= 9:
while m <= n:
print("%d * %d = %d" % (m, n, m * n), end=" ")
m = m + 1
print(" ")
m = 1
n = n + 1
8.函数基础
(1)函数基本使用
1)定义
-
所谓函数,就是把 具有独立功能的代码块 组织为一个小模块,在需要的时候 调用
-
函数的使用包含两个步骤:
-
定义函数 —— 封装 独立的功能
-
调用函数 —— 享受 封装 的成果
-
-
函数的作用,在开发程序时,使用函数可以提高编写的效率以及代码的 重用
定义函数的格式如下:
def 函数名():
函数封装的代码
……
-
def是英文define的缩写 -
函数名称 应该能够表达 函数封装代码 的功能,方便后续的调用
-
函数名称 的命名应该 符合 标识符的命名规则
-
可以由 字母、下划线 和 数字 组成
-
不能以数字开头
-
不能与关键字重名
-
2)调用
通过 函数名() 即可完成对函数的调用
eg:
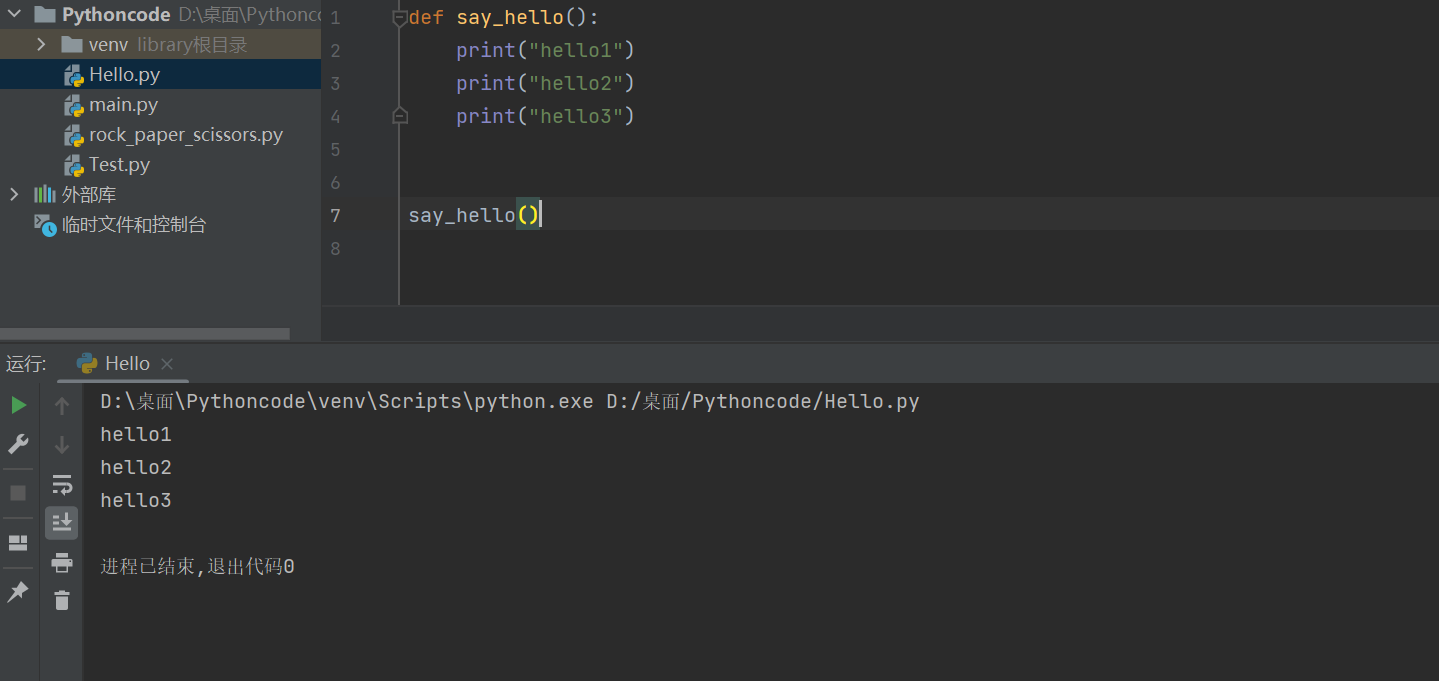
def say_hello():
print("hello1")
print("hello2")
print("hello3")
say_hello()
-
定义好函数之后,只表示这个函数封装了一段代码而已
-
如果不主动调用函数,函数是不会主动执行的
注意
-
能否将 函数调用 放在 函数定义 的上方?
-
不能!
-
因为在 使用函数名 调用函数之前,必须要保证
Python已经知道函数的存在 -
否则控制台会提示
NameError: name 'say_hello' is not defined(名称错误:say_hello 这个名字没有被定义)
-
(2)函数的参数
1)函数参数的使用
-
在函数名的后面的小括号内部填写 参数
-
多个参数之间使用
,分隔
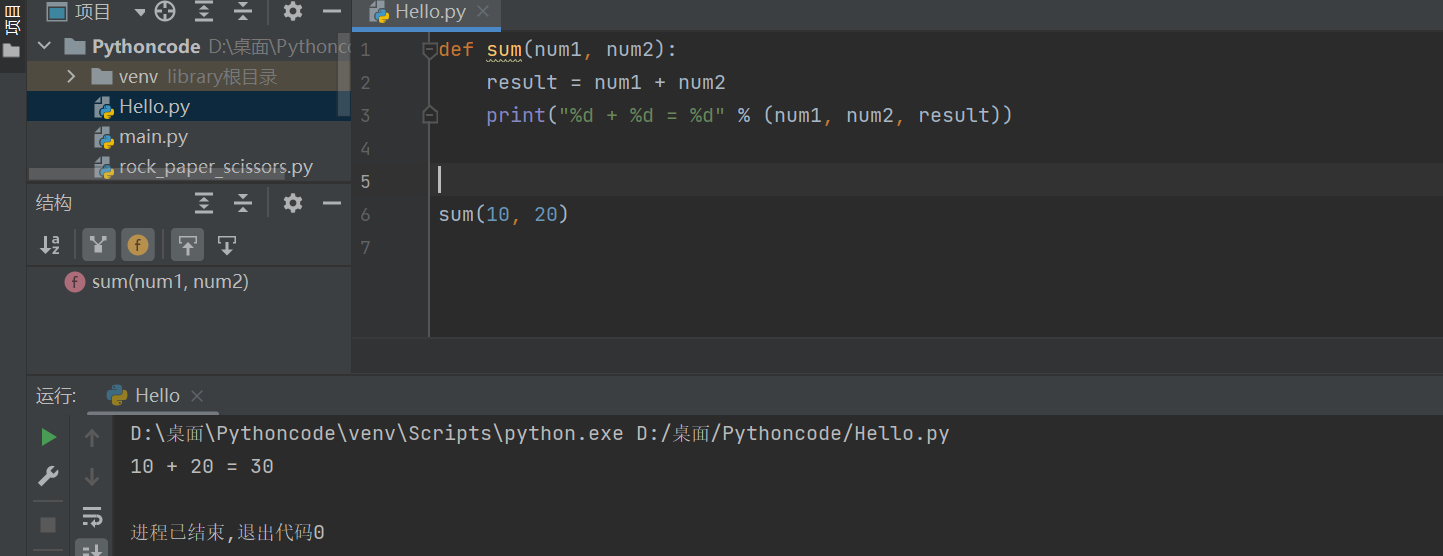
def sum(num1, num2):
result = num1 + num2
print("%d + %d = %d" % (num1, num2, result))
sum(10, 20)
2)参数的作用
-
函数,把 具有独立功能的代码块 组织为一个小模块,在需要的时候 调用
-
函数的参数,增加函数的 通用性,针对 相同的数据处理逻辑,能够 适应更多的数据
-
在函数 内部,把参数当做 变量 使用,进行需要的数据处理
-
函数调用时,按照函数定义的参数顺序,把 希望在函数内部处理的数据,通过参数 传递
-
3)形参和实参
-
形参:定义 函数时,小括号中的参数,是用来接收参数用的,在函数内部 作为变量使用
-
实参:调用 函数时,小括号中的参数,是用来把数据传递到 函数内部 用的

(3)函数的返回值
-
在程序开发中,有时候,会希望 一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理
-
返回值 是函数 完成工作后,最后 给调用者的 一个结果
-
在函数中使用
return关键字可以返回结果 -
调用函数一方,可以 使用变量 来 接收 函数的返回结果
注意:
return表示返回,后续的代码都不会被执行
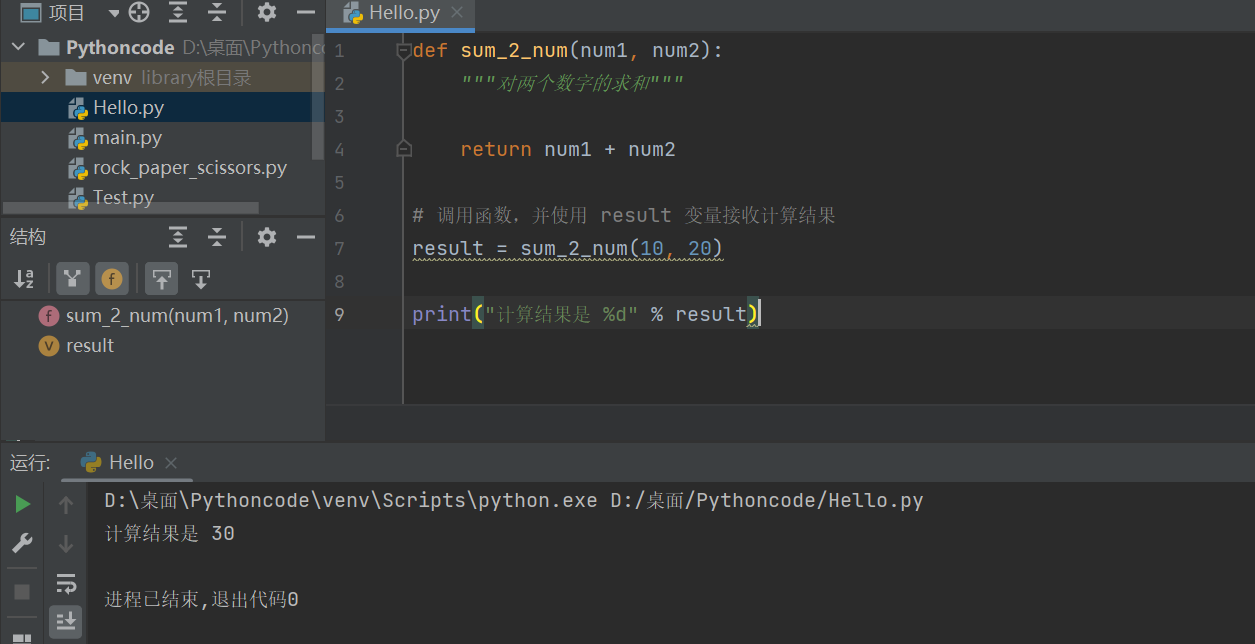
def sum_2_num(num1, num2):
"""对两个数字的求和"""
return num1 + num2
# 调用函数,并使用 result 变量接收计算结果
result = sum_2_num(10, 20)
print("计算结果是 %d" % result)
(4)函数的嵌套调用
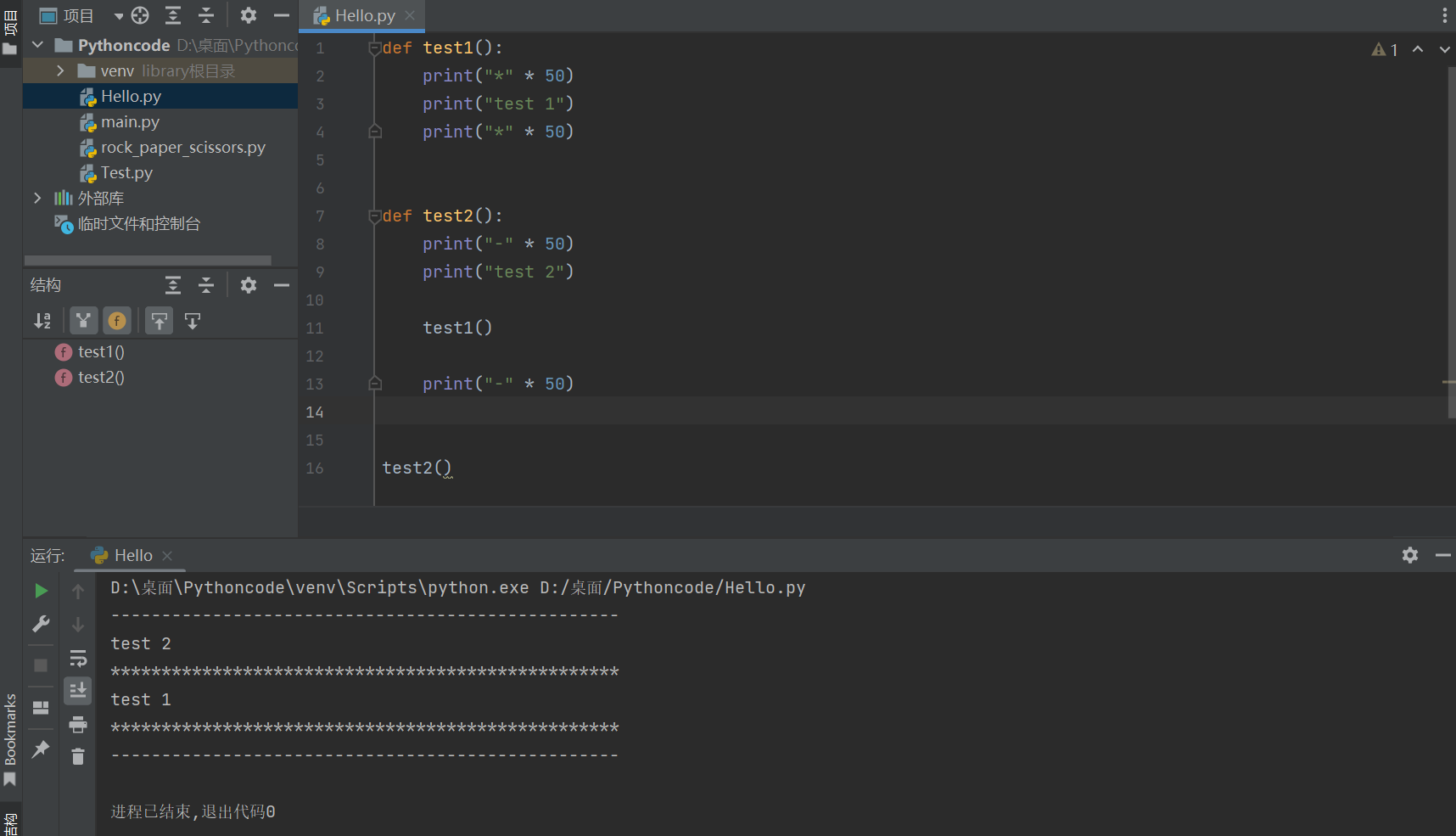
-
一个函数里面 又调用 了 另外一个函数,这就是 函数嵌套调用
-
如果函数
test2中,调用了另外一个函数test1!-
那么执行到调用
test1函数时,会先把函数test1中的任务都执行完 -
才会回到
test2中调用函数test1的位置,继续执行后续的代码
-
def test1():
print("*" * 50)
print("test 1")
print("*" * 50)
def test2():
print("-" * 50)
print("test 2")
test1()
print("-" * 50)
test2()
演练
需求 1
-
定义一个
print_line函数能够打印*组成的 一条分隔线
def print_line(char):
print("*" * 50)
需求 2
-
定义一个函数能够打印 由任意字符组成 的分隔线
def print_line(char):
print(char * 50)
需求 3
-
定义一个函数能够打印 任意重复次数 的分隔线
def print_line(char, times):
print(char * times)
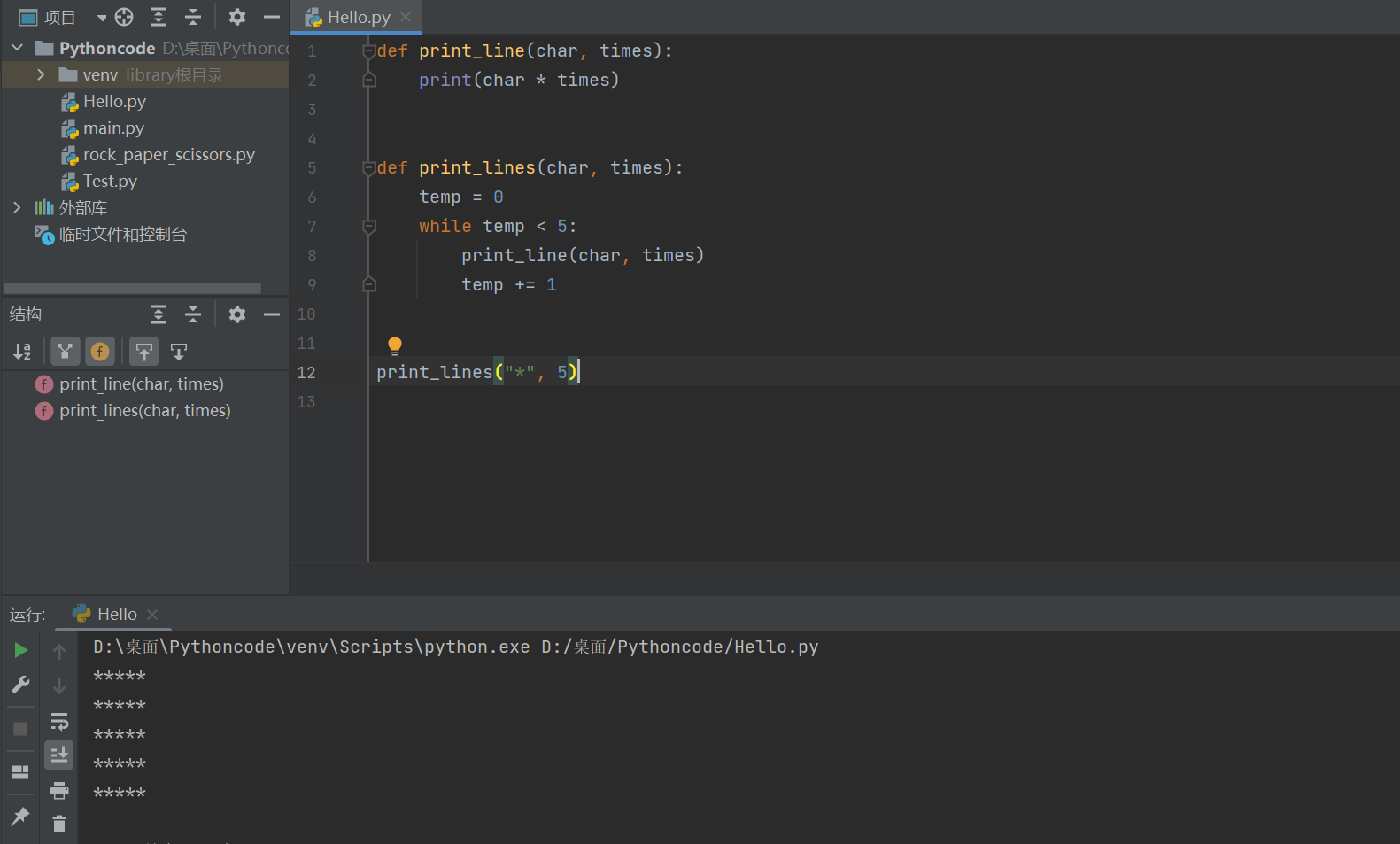
需求 4
-
定义一个函数能够打印 5 行 的分隔线,分隔线要求符合需求 3
提示:工作中针对需求的变化,应该冷静思考,不要轻易修改之前已经完成的,能够正常执行的函数!
def print_line(char, times):
print(char * times)
def print_lines(char, times):
temp = 0
while temp < 5:
print_line(char, times)
temp += 1
print_lines("*", 5)
(5)使用模块中的函数
模块是 Python 程序架构的一个核心概念
-
模块 就好比是 工具包,要想使用这个工具包中的工具,就需要 导入 import 这个模块
-
每一个以扩展名
py结尾的Python源代码文件都是一个 模块 -
在模块中定义的 全局变量 、 函数 都是模块能够提供给外界直接使用的工具
eg:
注意:模块名也是一个标识符
-
标示符可以由 字母、下划线 和 数字 组成
-
不能以数字开头
-
不能与关键字重名
注意:如果在给 Python 文件起名时,以数字开头 是无法在
PyCharm中通过导入这个模块的
9.列表
(1)定义
-
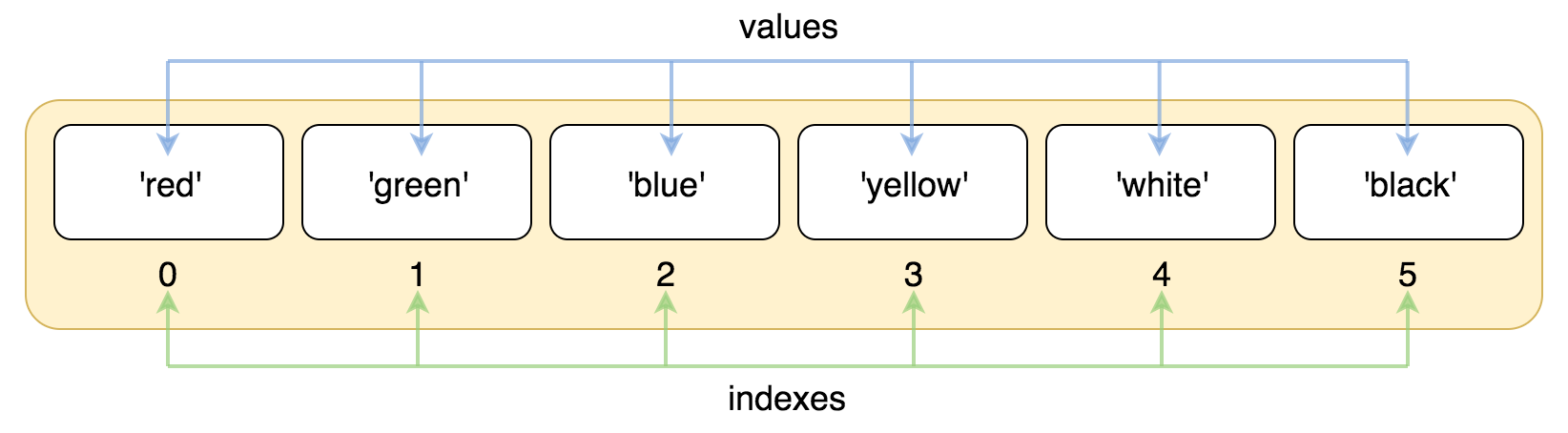
List(列表) 是Python中使用 最频繁 的数据类型,在其他语言中通常叫做 数组 -
专门用于存储 一串 信息
-
列表用
[]定义,数据 之间使用,分隔 -
列表的 索引 从
0开始-
索引 就是数据在 列表 中的位置编号,索引 又可以被称为 下标
-
注意:从列表中取值时,如果 超出索引范围,程序会报错
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'Runoob', 1997, 2000] list2 = [1, 2, 3, 4, 5 ] list3 = ["a", "b", "c", "d"] list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
name_list = ["zhangsan", "lisi", "wangwu"]
(2)访问列表的值
与字符串的索引一样,列表索引从 0 开始,第二个索引是 1,依此类推。
通过索引列表可以进行截取、组合等操作。
eg:
name = ['red', 'green', 'blue', 'yellow', 'white', 'black'] print(name[0]) print(name[1]) print(name[2])
以上实例输出结果:
red green blue
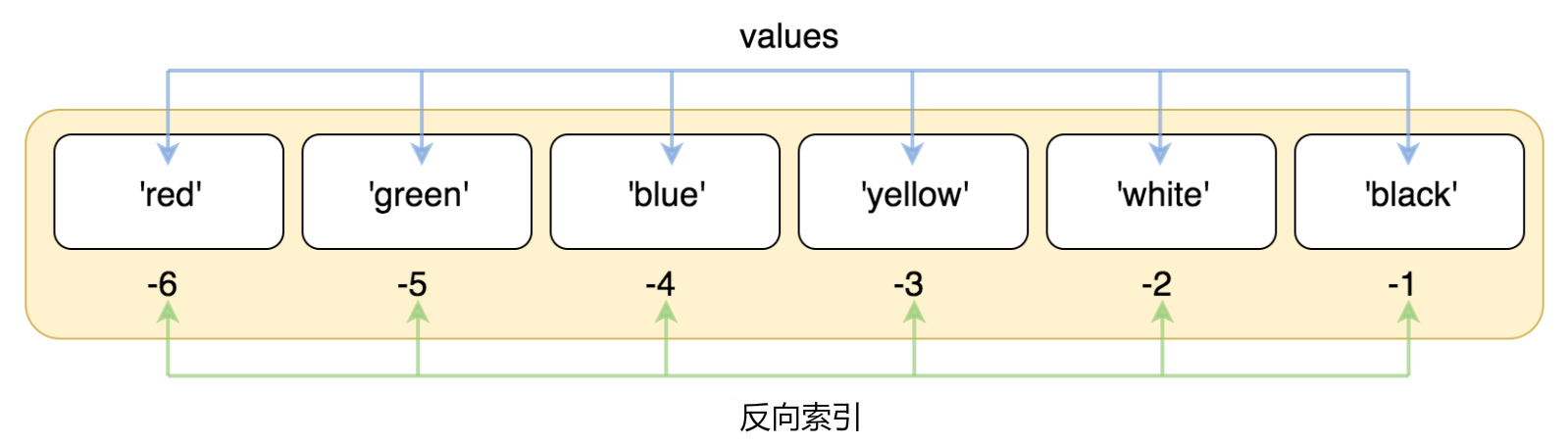
注意:索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。
eg:
name = ['red', 'green', 'blue', 'yellow', 'white', 'black'] print(name[-6]) print(name[-5]) print(name[-4])
以上实例输出结果:
black white yellow
使用下标索引来访问列表中的值,同样你也可以使用方括号 [] 的形式截取字符,如下所示:
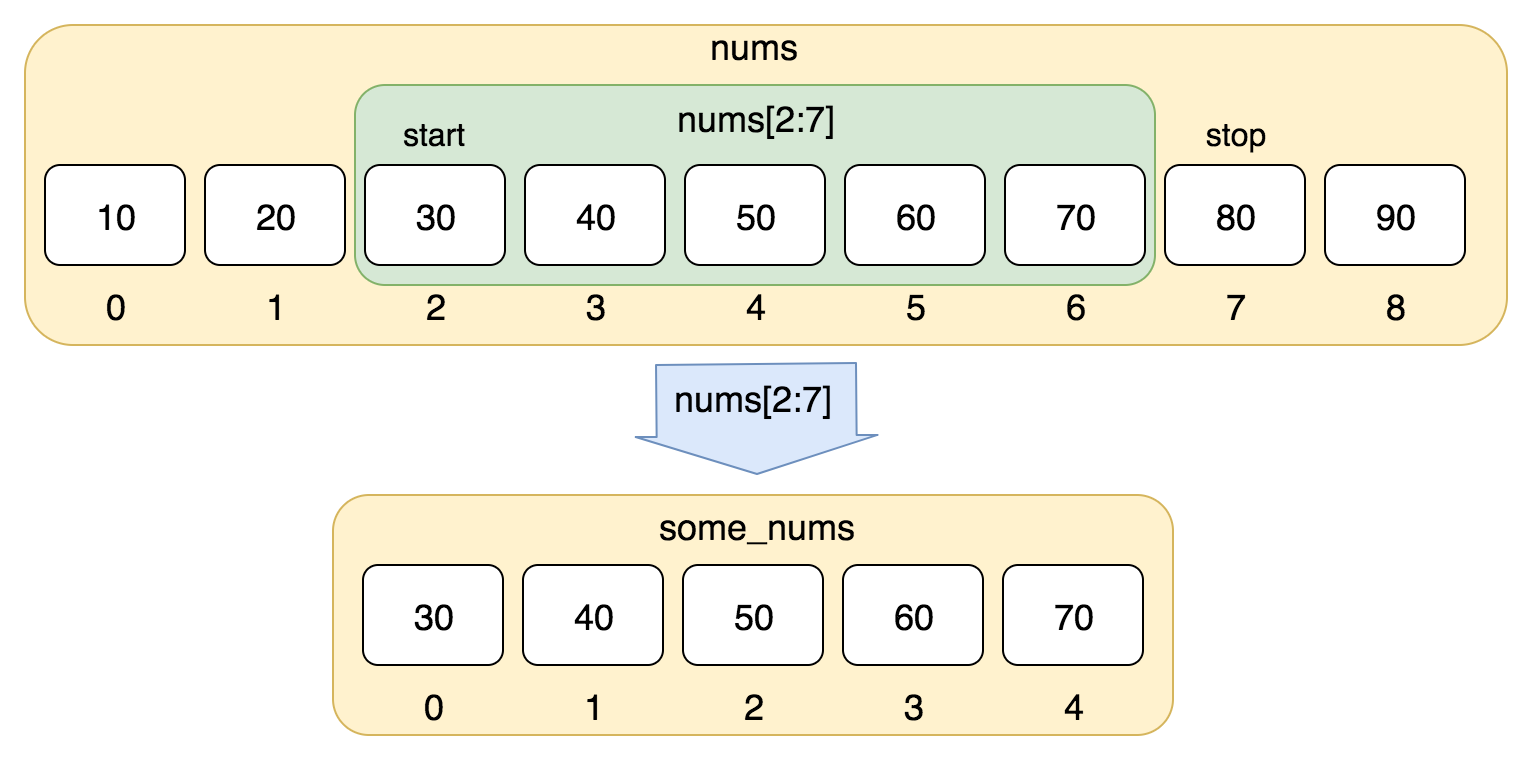
nums = [10, 20, 30, 40, 50, 60, 70, 80, 90] print(nums[0:4])
以上实例输出结果:
[10, 20, 30, 40]
使用负数索引值截取:
eg:
list = ['Google', 'Runoob', "Zhihu", "Taobao", "Wiki"]
# 读取第二位
print("list[1]: ", list[1])
# 从第二位开始(包含)截取到倒数第二位(不包含)
print("list[1:-2]: ", list[1:-2])
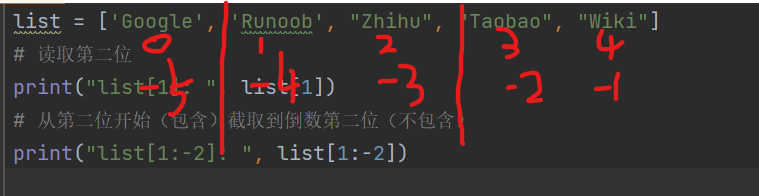
以上实例输出结果:
list[1]: Runoob list[1:-2]: ['Runoob', 'Zhihu']
(3)修改
你可以对列表的数据项进行修改或更新,你也可以使用 append() 方法来添加列表项,如下所示:
print("第三个元素为 : ", name[2])
name[2] = 2001
print("更新后的第三个元素为 : ", name[2])
第三个元素为 : 1997 更新后的第三个元素为 : 2001
(4)增加
1)append()
append() 方法用于在列表末尾添加新的对象,是指在列表末尾增加一个数据项。
append()方法语法:
list.append(obj)
-
obj -- 添加到列表末尾的对象。
-
该方法无返回值,但是会修改原来的列表。
eg:
list1 = ['Google', 'Runoob', 'Taobao'] list1.append('Baidu') print ("更新后的列表 : ", list1)
以上实例输出结果如下:
更新后的列表 : ['Google', 'Runoob', 'Taobao', 'Baidu']
在append中也可以添加列表
eg:
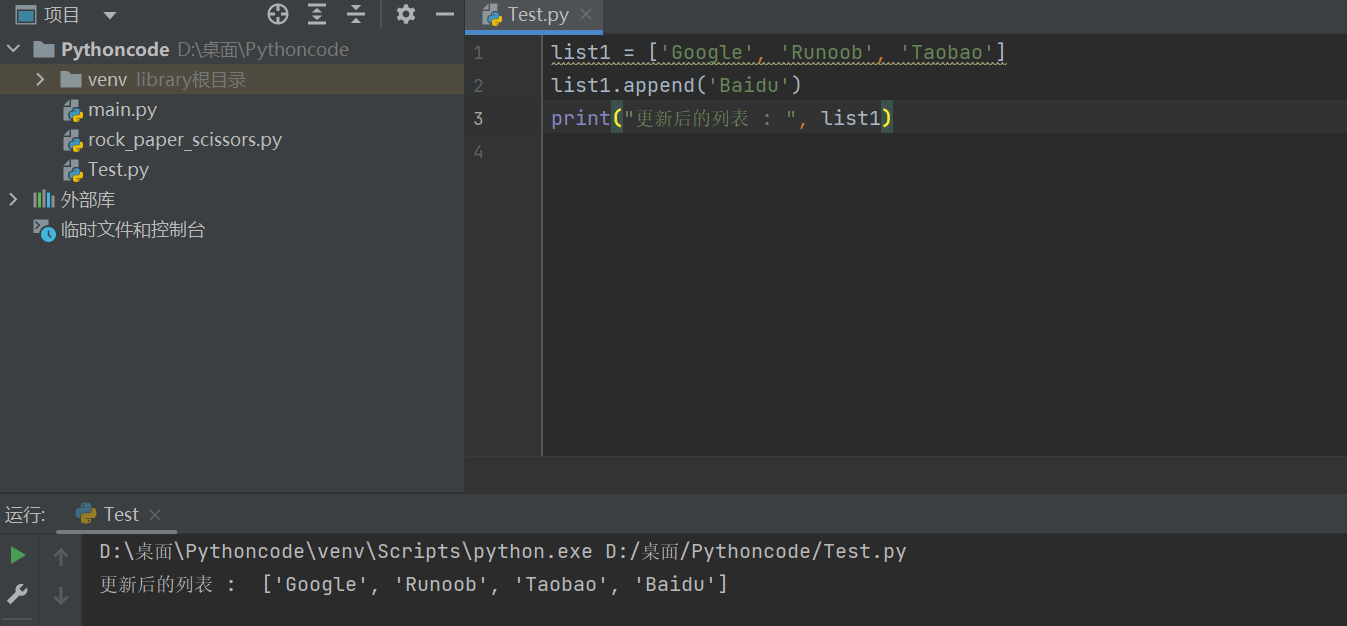
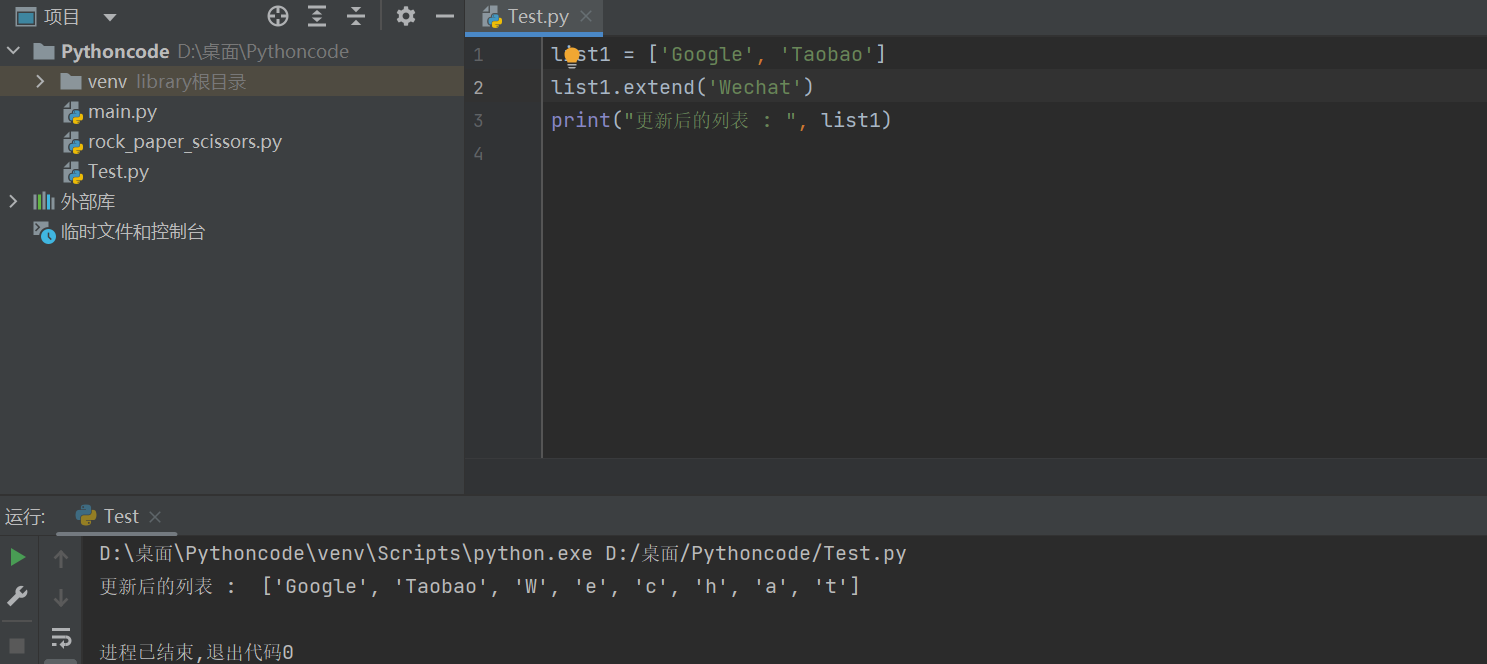
2)extend
extend()方法是指在列表末尾增加一个数据集合
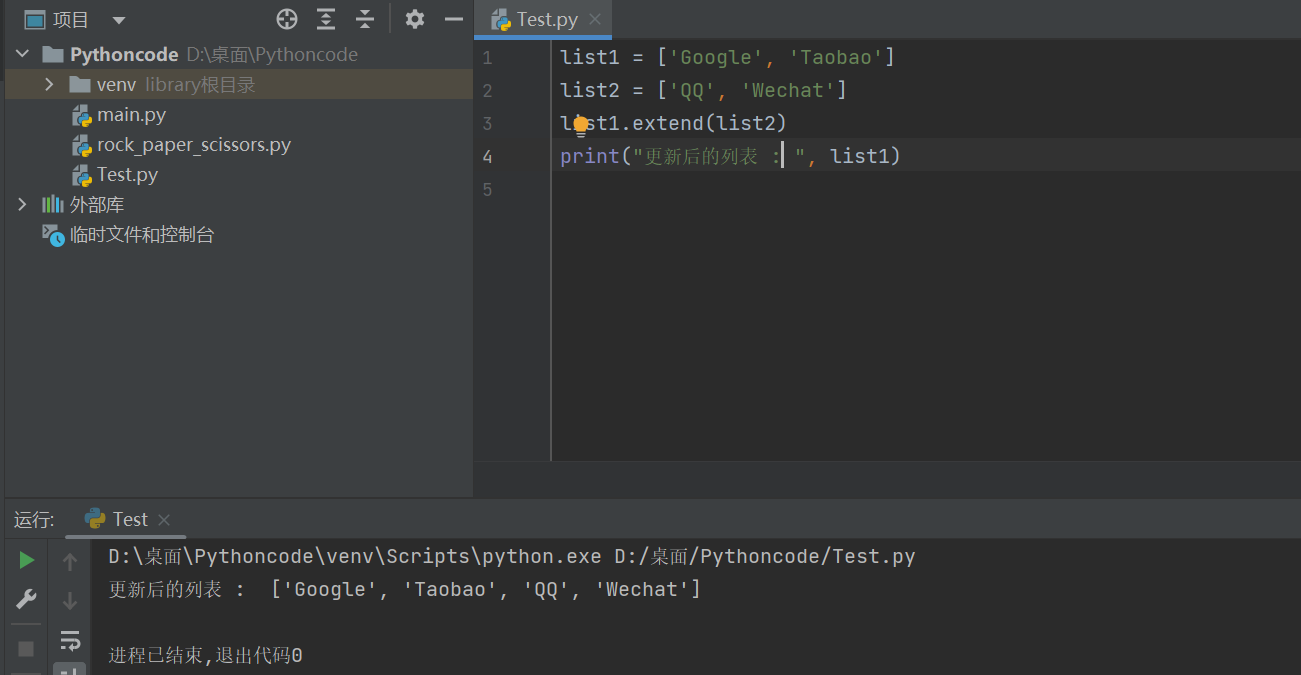
list1 = ['Google', 'Taobao']
list2 = ['QQ', 'Wechat']
list1.extend()
print("更新后的列表 : ", list1)
但是extend与append的主要区别是
eg1:
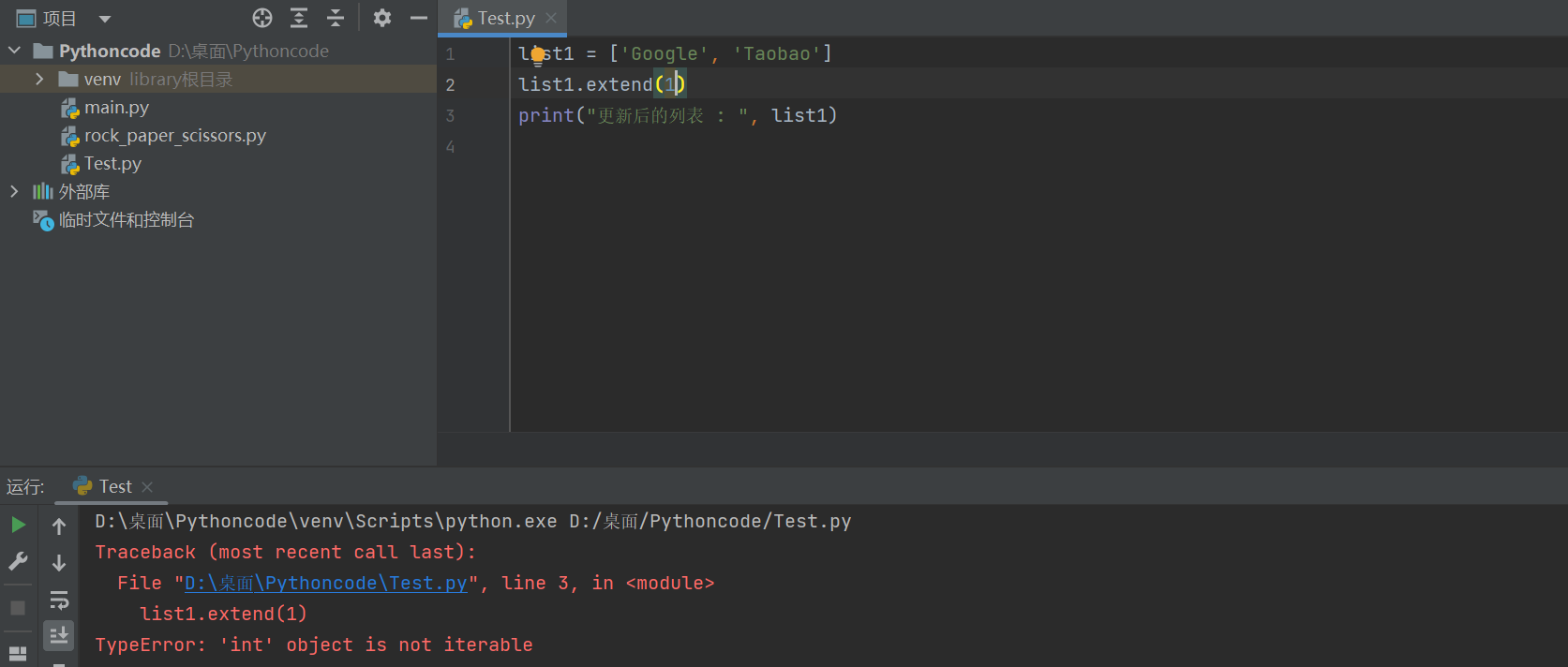
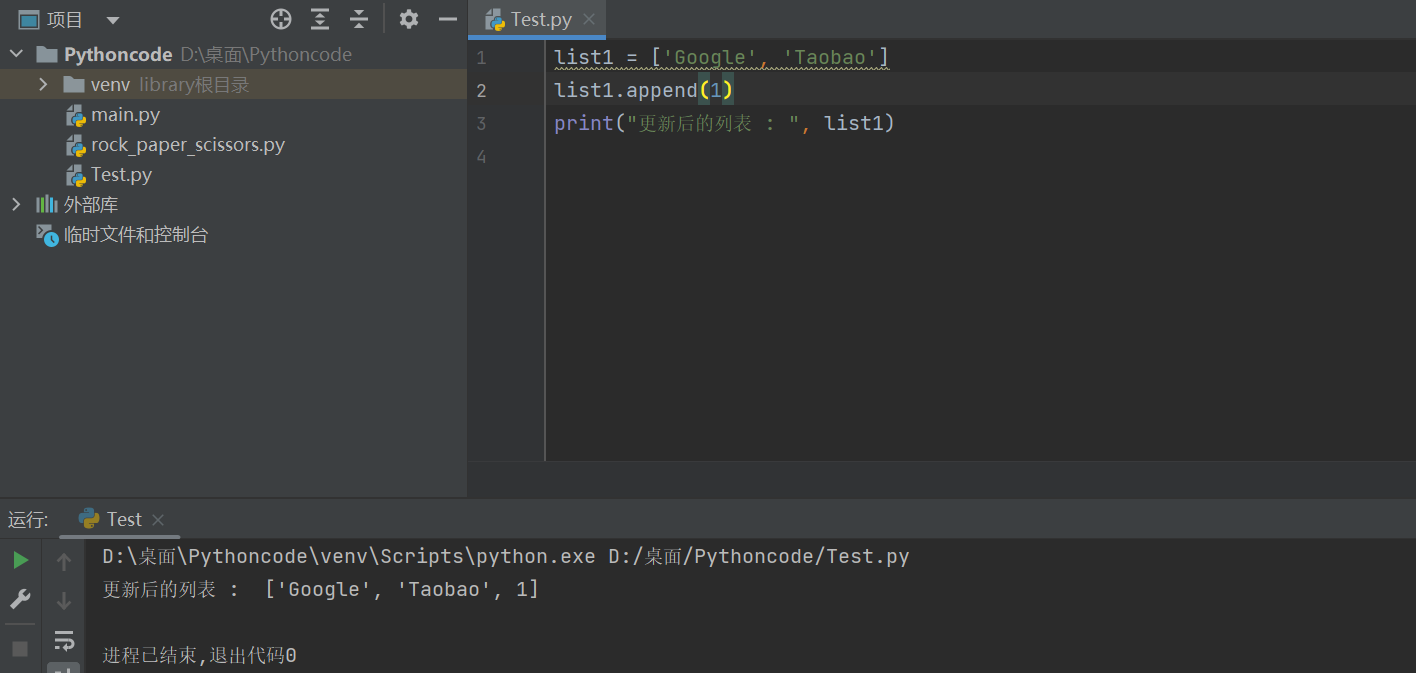
eg2:
3)insert
列表.insert(索引, 数据)---在指定位置插入数据
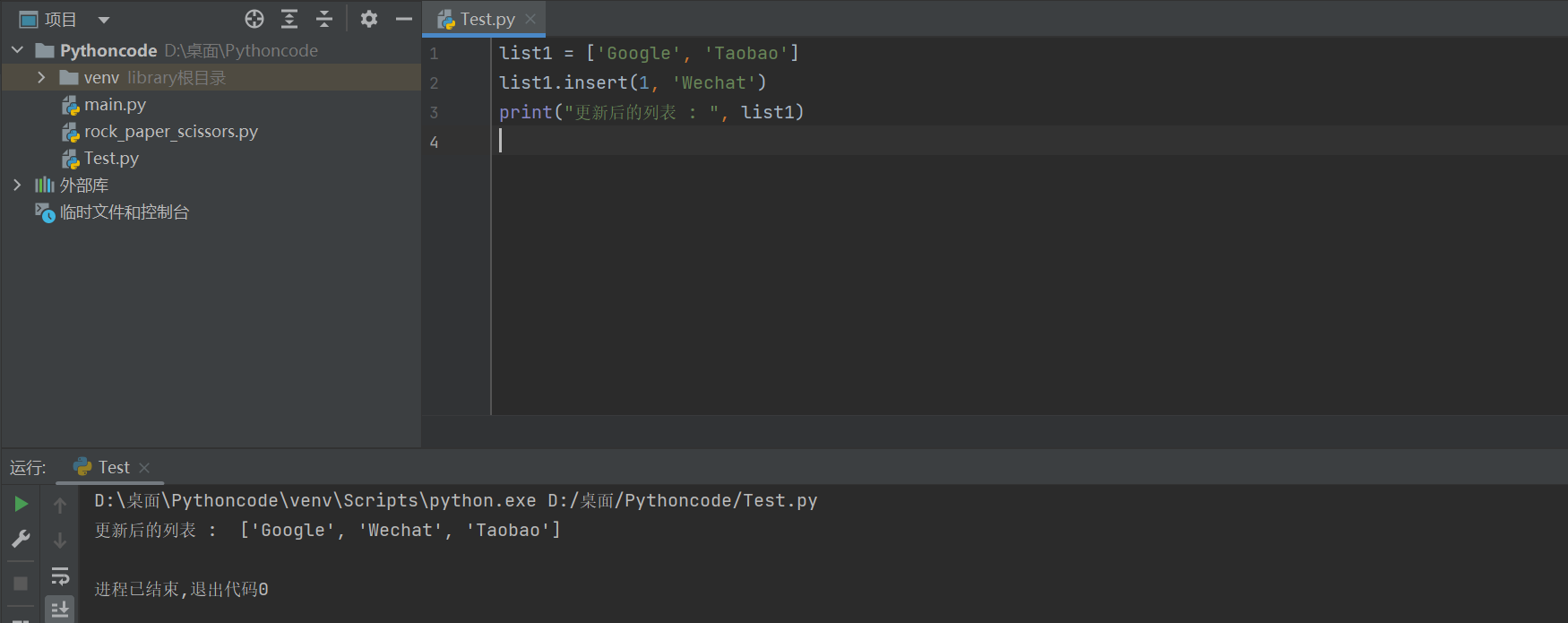
list1 = ['Google', 'Taobao']
list1.insert(1, 'Wechat')
print("更新后的列表 : ", list1)
更新后的列表 : ['Google', 'Wechat', 'Taobao']
(5)删除
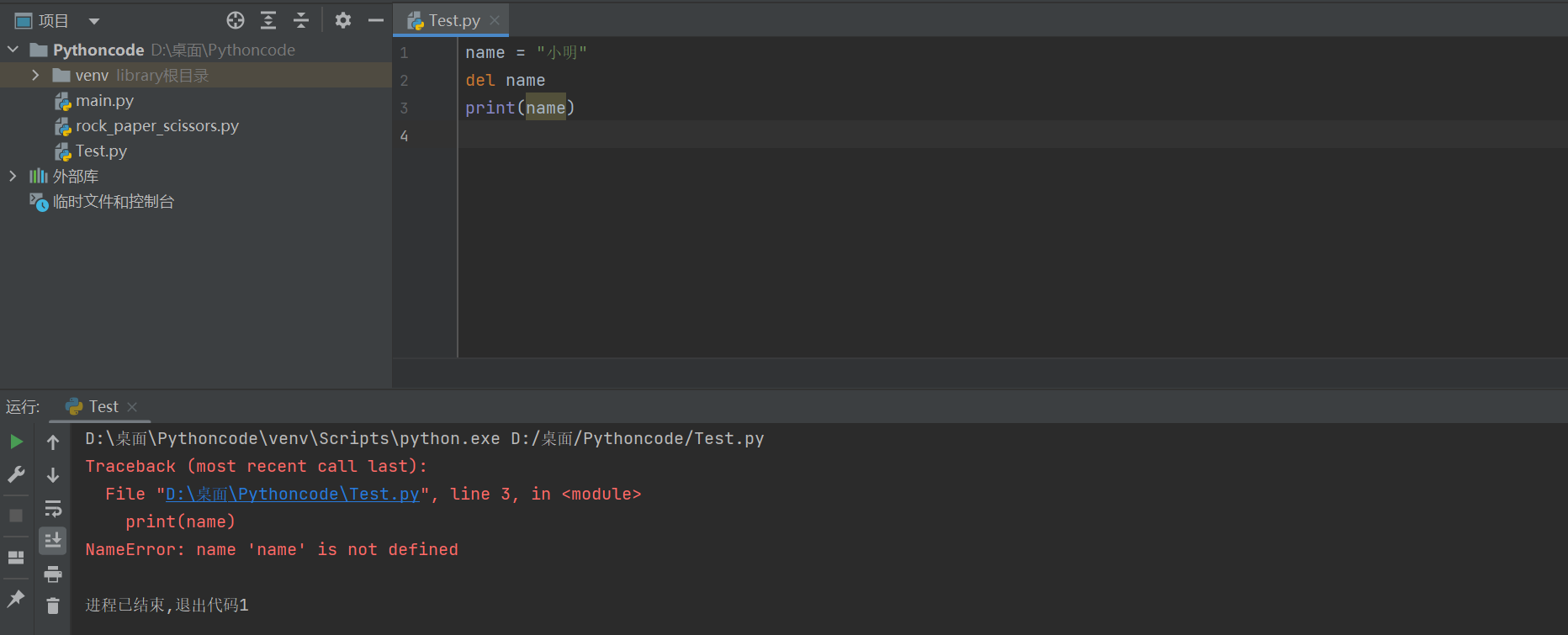
1)del
del(关键字)可以使用 del 语句来删除列表的的元素,如下实例:
list = ['张三', '李四', '王五', '赵六']
print("原始列表: ", list)
del list[2]
print("删除第三个元素: ", list)
以上实例输出结果:
原始列表 : ['Google', 'Runoob', 1997, 2000] 删除第三个元素 : ['Google', 'Runoob', 2000]
del的本质上是用来将一个变量从内存中删除
注意:del的本质上是用来将一个变量从内存中删除,在日常开发中删除列表中的数据建议使用列表提供的方法
如果使用del关键字删除一个变量,那么在后续的代码中就不能再使用这个变量了
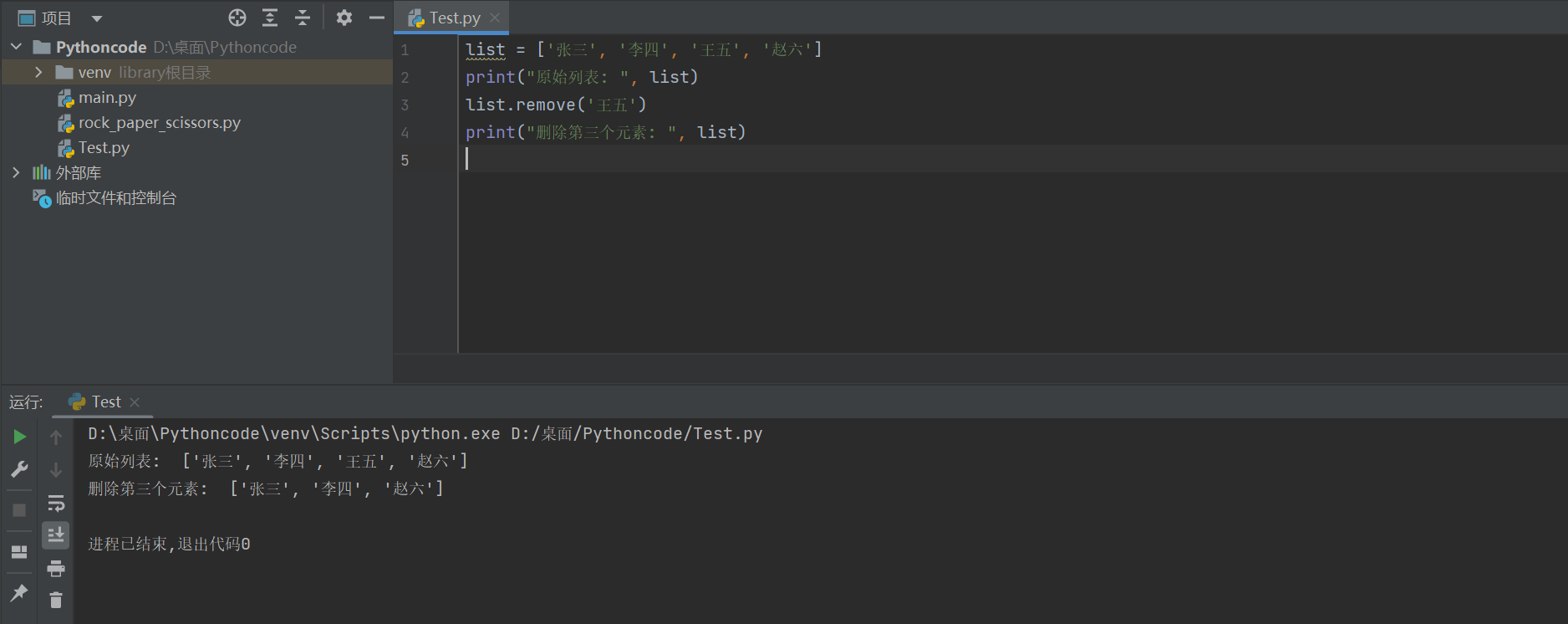
2)remove
remove可以删除列表中的指定数据
list = ['张三', '李四', '王五', '赵六']
print("原始列表: ", list)
list.remove('王五')
print("删除第三个元素: ", list)
3)pop
pop方法默认可以把列表中最后一个元素删除
list = ['张三', '李四', '王五', '赵六']
print("原始列表: ", list)
list.pop()
print("删除后: ", list)
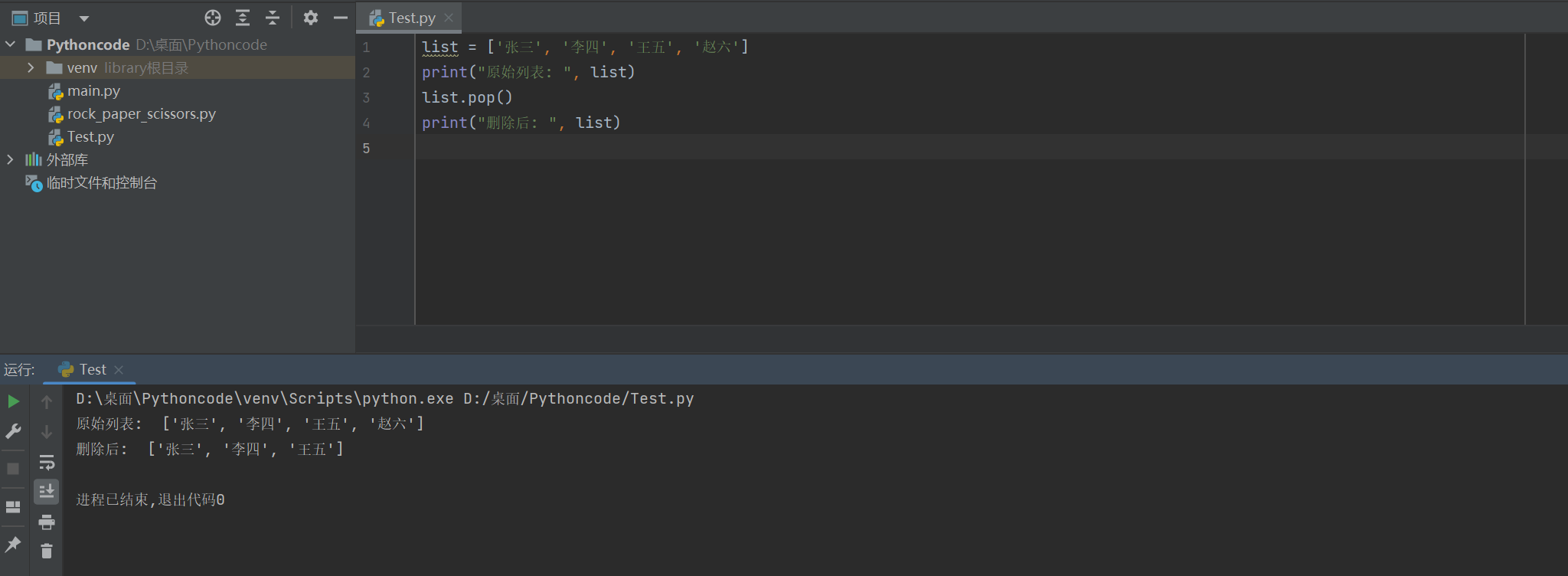
原始列表: ['张三', '李四', '王五', '赵六'] 删除后: ['张三', '李四', '王五']
也可以指定要删除元素的索引
list = ['张三', '李四', '王五', '赵六']
print("原始列表: ", list)
list.pop(3)
print("删除第三个元素: ", list)
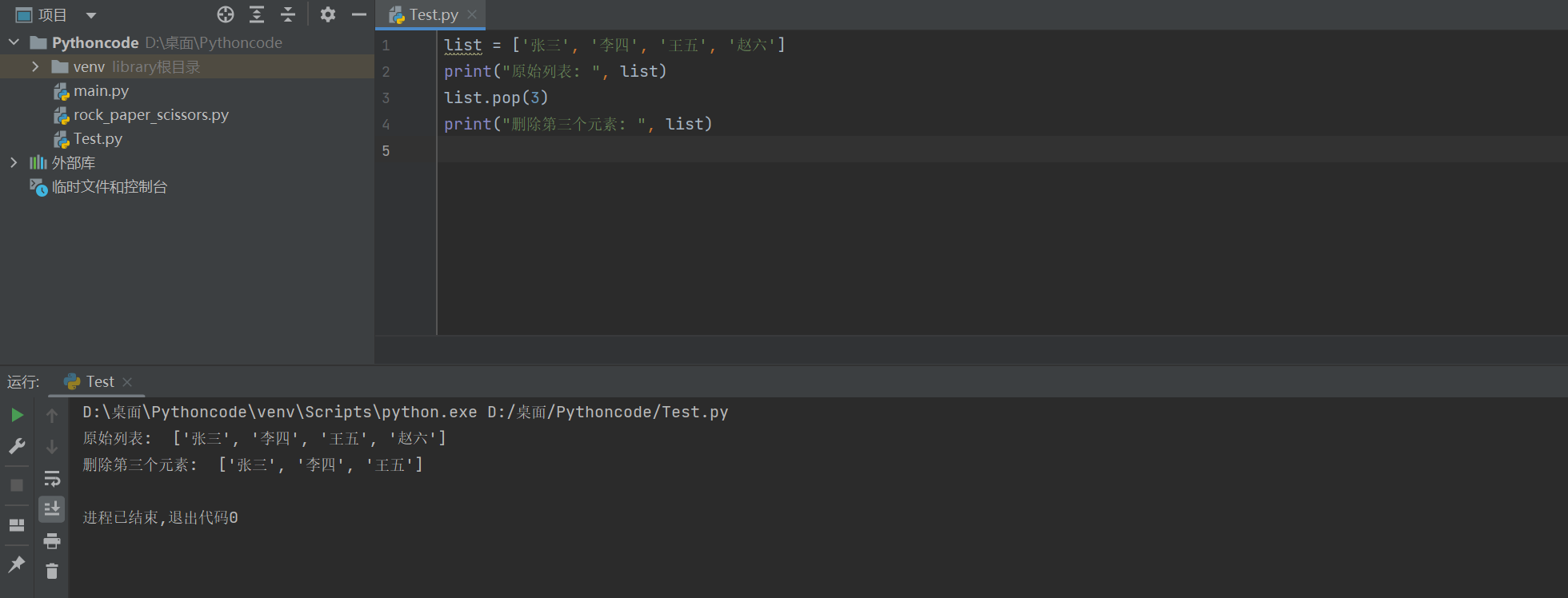
原始列表: ['张三', '李四', '王五', '赵六'] 删除第三个元素: ['张三', '李四', '王五']
4)clear
clear方法可以清空列表
list = ['张三', '李四', '王五', '赵六']
print("原始列表: ", list)
list.clear()
print("删除后: ", list)
原始列表: ['张三', '李四', '王五', '赵六'] 删除后: []
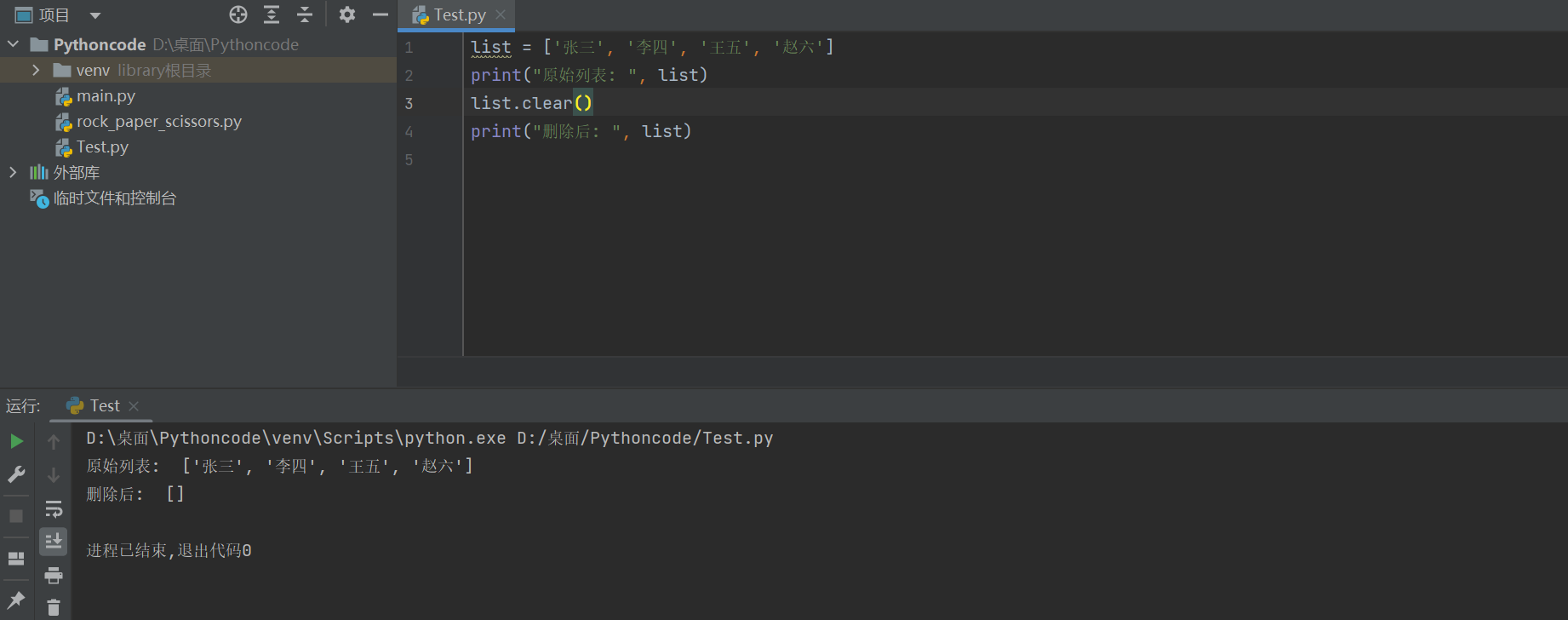
(6)统计
1)len
函数可以统计列表中元素的个数
list = ['张三', '李四', '王五', '赵六']
length = len(list)
print("列表中共有 %d 个元素" % len(list))
列表中共有 4 个元素
2)count
方法可以统计列表中某一个数据出现的次数
list = ['张三', '李四', '王五', '赵六', '张三', '张三']
print("列表中 张三 一共出现了 %d 次" % list.count("张三"))
列表中 张三 一共出现了 3 次
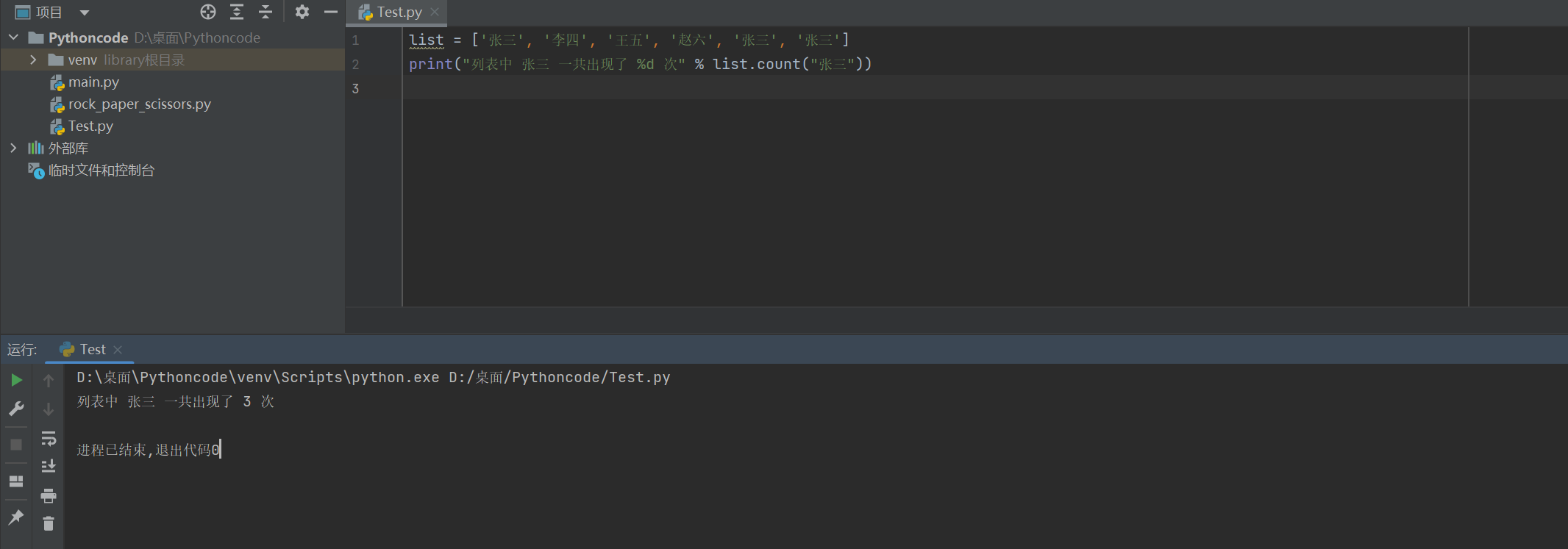
(7)排序
1)sort升序
name_list = ['zhangsan', 'lisi', 'wangwu', 'zhaoliv']
num_list = [6, 8, 4, 5, 1]
print("排序前:%s" % name_list)
print("排序前:%s" % num_list)
name_list.sort()
num_list.sort()
print("排序前:%s" % name_list)
print("排序后:%s" % num_list)
排序前:['zhangsan', 'lisi', 'wangwu', 'zhaoliv'] 排序前:[6, 8, 4, 5, 1] 排序前:['lisi', 'wangwu', 'zhangsan', 'zhaoliv'] 排序后:[1, 4, 5, 6, 8]
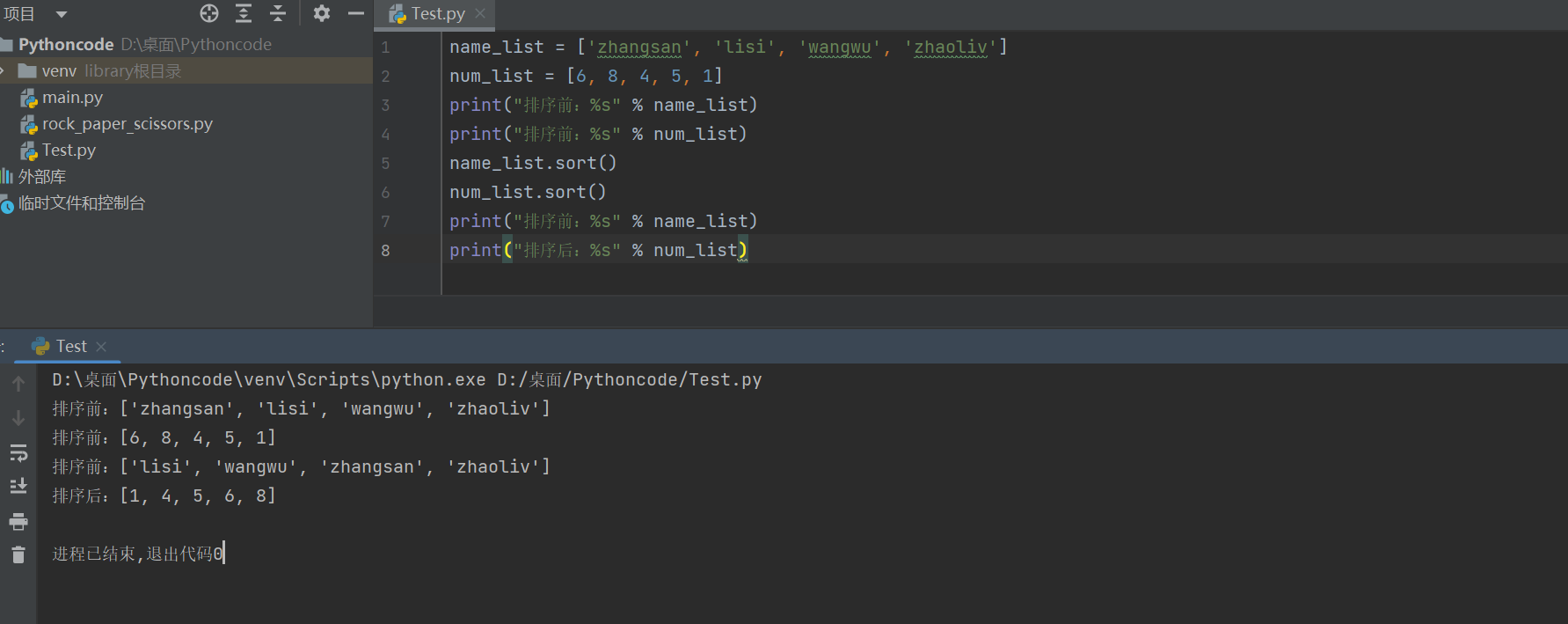
2)sort(reverse=True)降序
name_list = ['zhangsan', 'lisi', 'wangwu', 'zhaoliv']
num_list = [6, 8, 4, 5, 1]
print("排序前:%s" % name_list)
print("排序前:%s" % num_list)
name_list.sort(reverse=True)
num_list.sort(reverse=True)
print("排序前:%s" % name_list)
print("排序后:%s" % num_list)
排序前:['zhangsan', 'lisi', 'wangwu', 'zhaoliv'] 排序前:[6, 8, 4, 5, 1] 排序前:['zhaoliv', 'zhangsan', 'wangwu', 'lisi'] 排序后:[8, 6, 5, 4, 1]

如果把True改成False时便成了升序
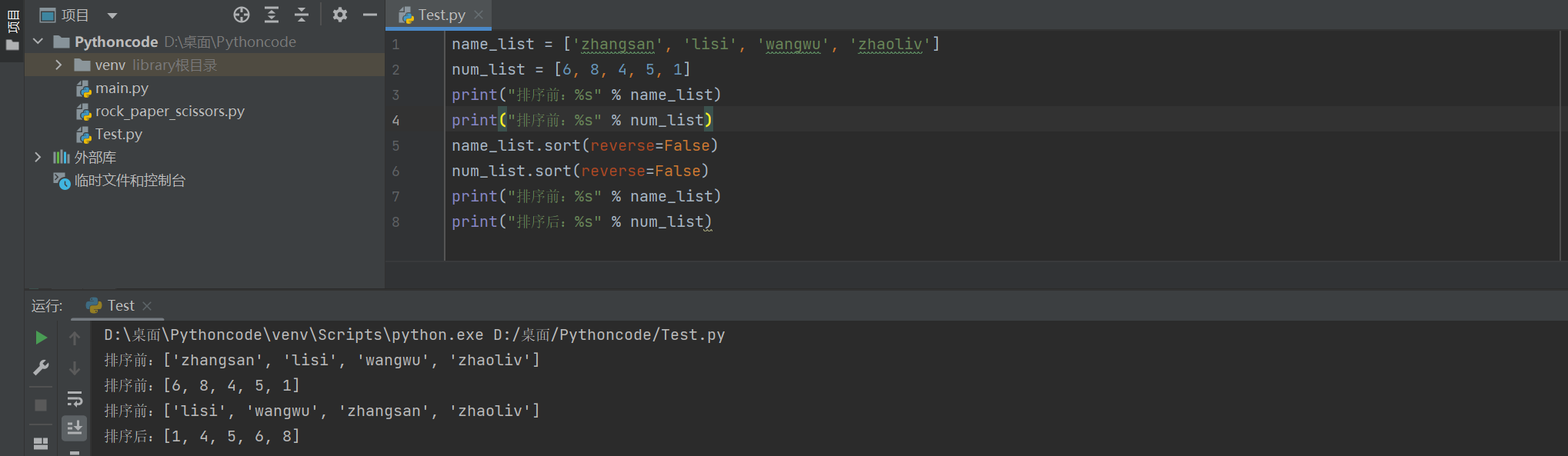
3)reverse
name_list = ['zhangsan', 'lisi', 'wangwu', 'zhaoliv']
num_list = [6, 8, 4, 5, 1]
print("排序前:%s" % name_list)
print("排序前:%s" % num_list)
name_list.reverse()
num_list.reverse()
print("排序前:%s" % name_list)
print("排序后:%s" % num_list)
排序前:['zhangsan', 'lisi', 'wangwu', 'zhaoliv'] 排序前:[6, 8, 4, 5, 1] 排序前:['zhaoliv', 'wangwu', 'lisi', 'zhangsan'] 排序后:[1, 5, 4, 8, 6]
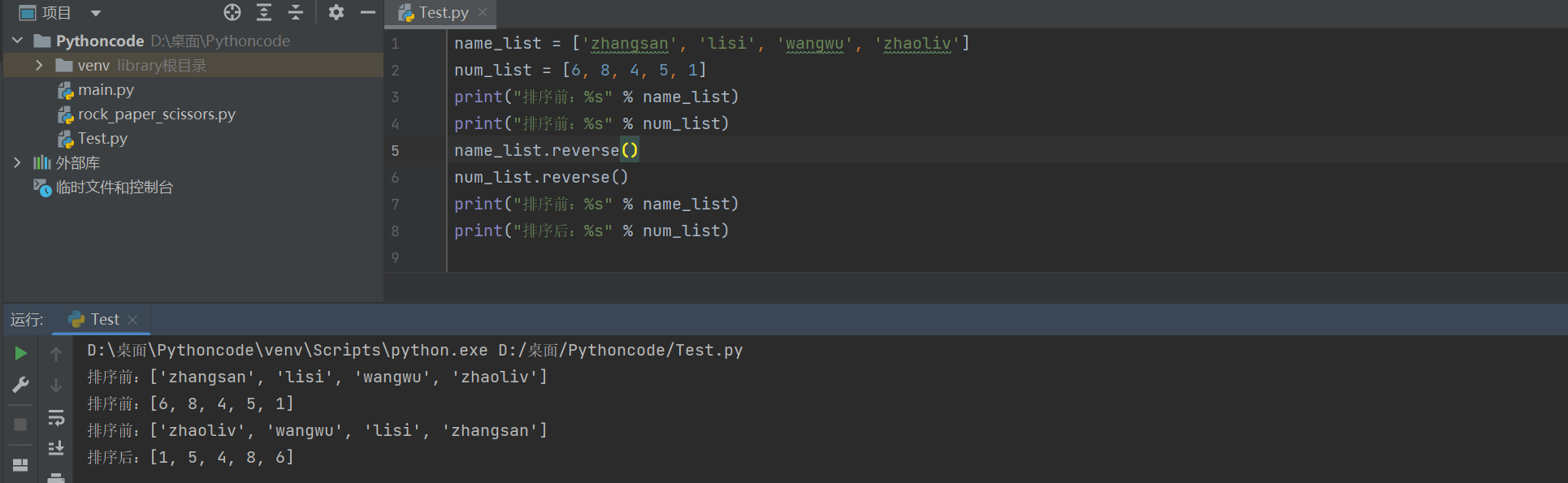
(8)列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
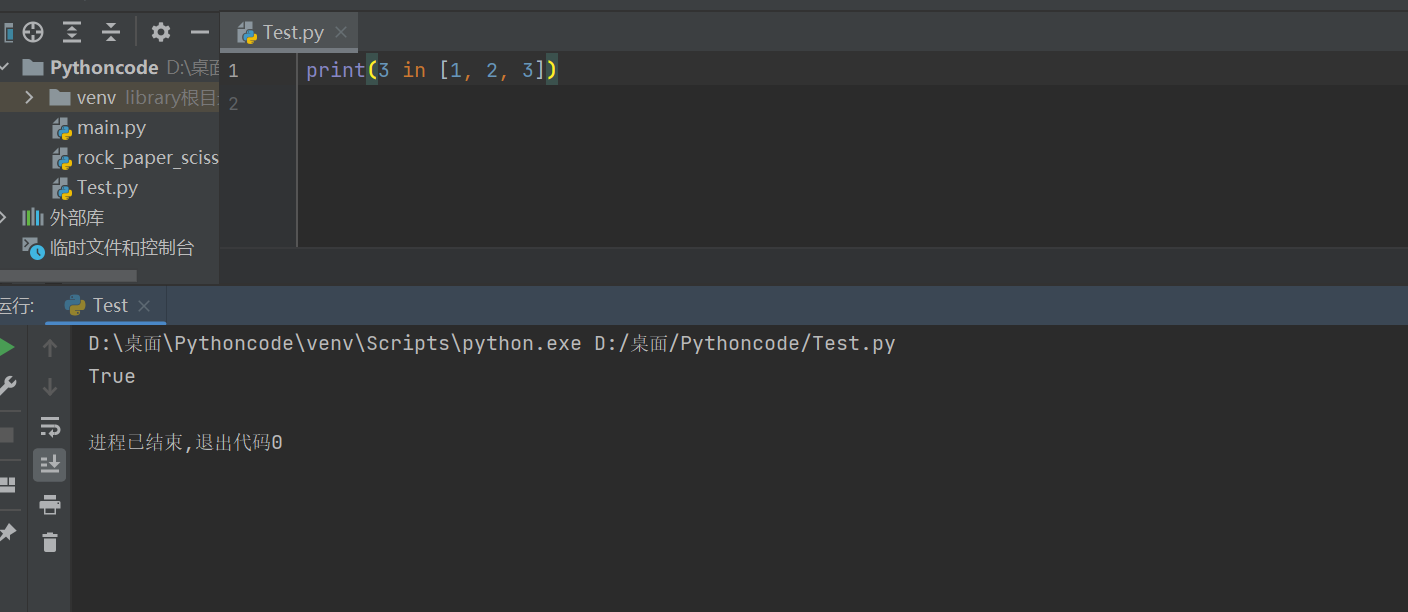
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
in
迭代遍历
-
遍历 就是 从头到尾 依次 从 列表 中获取数据
-
在 循环体内部 针对 每一个元素,执行相同的操作
-
-
在
Python中为了提高列表的遍历效率,专门提供的 迭代 iteration 遍历 -
使用
for就能够实现迭代遍历
格式如下:
# for 循环内部使用的变量 in 列表
for name in name_list:
循环内部针对列表元素进行操作
print(name)
方法一:
name_list = ['zhangsan', 'lisi', 'wangwu', 'zhaoliv']
for name in name_list:
print(name)
zhangsan lisi wangwu zhaoliv
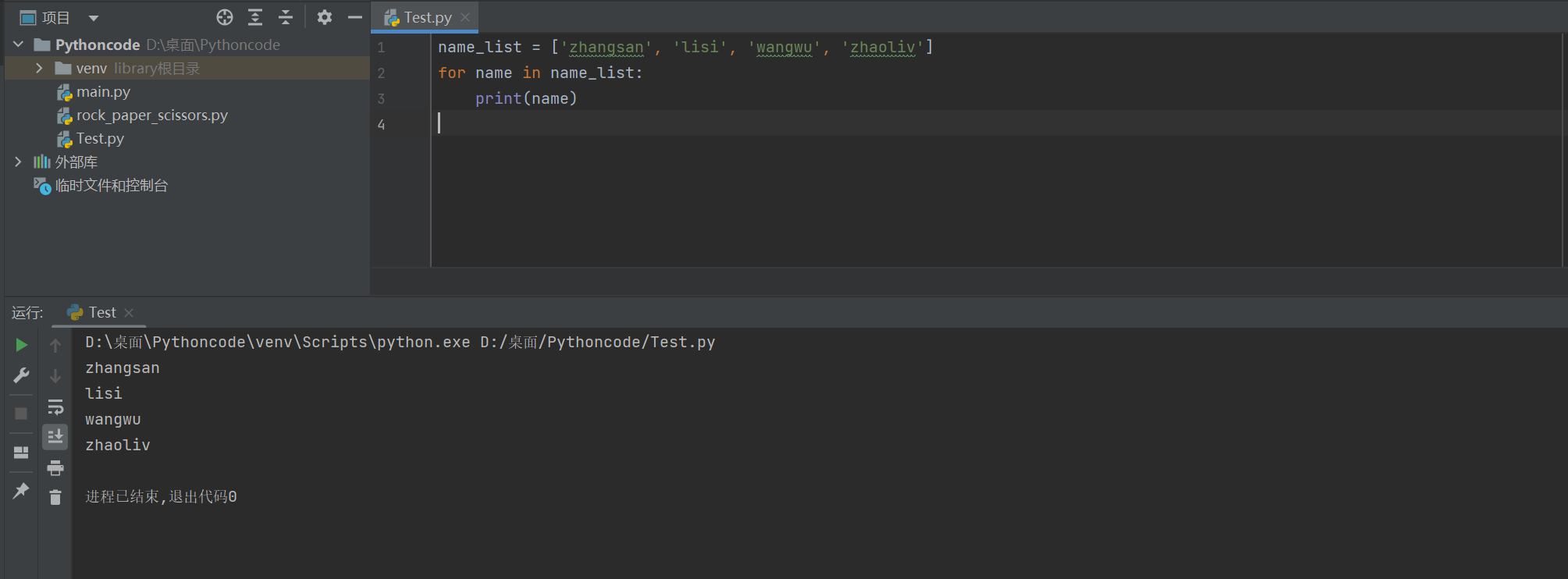
方法二:
for x in [1, 2, 3]:
print(x, end=" ")
1 2 3

(9)列表截取与拼接
Python的列表截取与字符串操作类型,如下所示:
L=['Google', 'Runoob', 'Taobao']
操作:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'Taobao' | 读取第三个元素 |
| L[-2] | 'Runoob' | 从右侧开始读取倒数第二个元素: count from the right |
| L[1:] | ['Runoob', 'Taobao'] | 输出从第二个元素开始后的所有元素 |
L=['Google', 'Runoob', 'Taobao'] print(L[2]) print(L[1:]) print(L[-2])
Taobao ['Runoob', 'Taobao'] Runoob
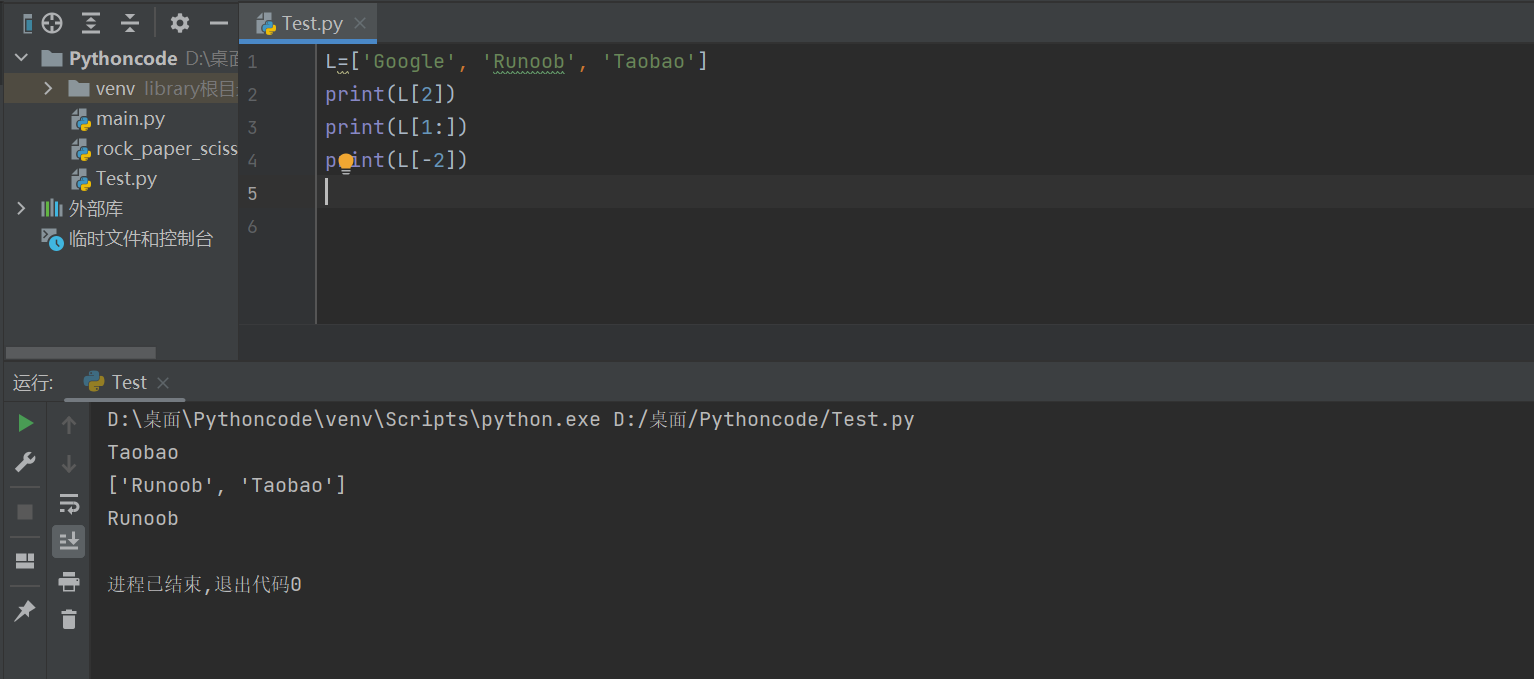
列表还支持拼接操作:
squares = [1, 4, 9, 16, 25] squares += [36, 49, 64, 81, 100] print(squares)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
(10)常用操作总结
-
在
ipython3中定义一个 列表,例如:name_list = [] -
输入
name_list.按下TAB键,ipython会提示 列表 能够使用的 方法 如下:
In [1]: name_list. name_list.append name_list.count name_list.insert name_list.reverse name_list.clear name_list.extend name_list.pop name_list.sort name_list.copy name_list.index name_list.remove
| 序号 | 分类 | 关键字 / 函数 / 方法 | 说明 |
|---|---|---|---|
| 1 | 增加 | 列表.insert(索引, 数据) | 在指定位置插入数据 |
| 列表.append(数据) | 在末尾追加数据 | ||
| 列表.extend(列表2) | 将列表2 的数据追加到列表 | ||
| 2 | 修改 | 列表[索引] = 数据 | 修改指定索引的数据 |
| 3 | 删除 | del 列表[索引] | 删除指定索引的数据 |
| 列表.remove[数据] | 删除第一个出现的指定数据 | ||
| 列表.pop | 删除末尾数据 | ||
| 列表.pop(索引) | 删除指定索引数据 | ||
| 列表.clear | 清空列表 | ||
| 4 | 统计 | len(列表) | 列表长度 |
| 列表.count(数据) | 数据在列表中出现的次数 | ||
| 5 | 排序 | 列表.sort() | 升序排序 |
| 列表.sort(reverse=True) | 降序排序 | ||
| 列表.reverse() | 逆序、反转 | ||
| 6 | 其他 | 列表.copy() | 复制列表 |
| max(列表) | 返回列表元素最大值 | ||
| min(列表) | 返回列表元素最小值 | ||
| list(seq) | 将元组转换为列表 | ||
10. 元组
(1)元组的定义
-
Tuple(元组)与列表类似,不同之处在于元组的 元素不能修改-
元组 表示多个元素组成的序列
-
元组 在
Python开发中,有特定的应用场景
-
-
用于存储 一串 信息,数据 之间使用
,分隔 -
元组的 索引 从
0开始 -
元组使用小括号
()定义,列表使用方括号 [ ]。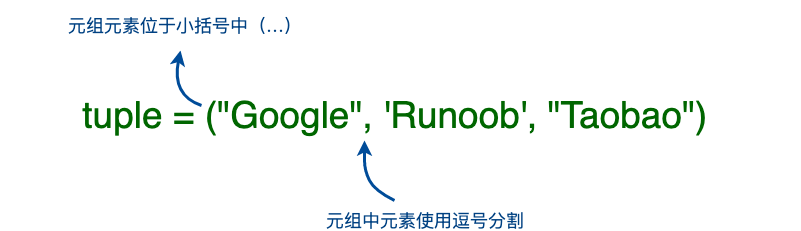
##
-
-
索引 就是数据在 元组 中的位置编号
-
info_tuple = ("zhangsan", 18, 1.75)
创建空元组
info_tuple = ()
元组中 只包含一个元素 时,需要 在元素后面添加逗号
info_tuple = (50, )
关于元组是不可变的
所谓元组的不可变指的是元组所指向的内存中的内容不可变。
从以上实例可以看出,重新赋值的元组 tup,绑定到新的对象了,不是修改了原来的对象。
(2)访问元组
元组可以使用下标索引来访问元组中的值,如下实例:
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7)
print("tup1[0]: ", tup1[0])
print("tup2[1:5]: ", tup2[1:5])
以上实例输出结果:
tup1[0]: Google tup2[1:5]: (2, 3, 4, 5)
(3)修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print(tup3)
以上实例输出结果:
(12, 34.56, 'abc', 'xyz')
(4)删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
tup = ('Google', 'Runoob', 1997, 2000)
print(tup)
del tup
print("删除后的元组 tup : ")
print(tup)
以上实例元组被删除后,输出变量会有异常信息,输出如下所示:
删除后的元组 tup :
Traceback (most recent call last):
File "test.py", line 8, in <module>
print (tup)
NameError: name 'tup' is not defined
(5)运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
len((1, 2, 3)) | 3 | 计算元素个数 |
(1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
3 in (1, 2, 3) | True | 元素是否存在 |
for x in (1, 2, 3): print (x, end=" ") | 1 2 3 | 迭代 |
(6)内置函数
Python元组包含了以下内置函数
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | len(tuple) | 计算元组元素个数。 |
| 2 | max(tuple) | 返回元组中元素最大值。 |
| 3 | min(tuple) 返回元组中元素最小值。 | 返回元组中元素最小值。 |
| 4 | tuple(iterable) | 将可迭代系列转换为元组。 |
(7)元组可以使用的函数
-
在
ipython3中定义一个 元组,例如:info = () -
输入
info.按下TAB键,ipython会提示 元组 能够使用的函数如下:
info.count info.index
有关 元组 的 常用操作 可以参照上图练习
(8)循环遍历
-
取值 就是从 元组 中获取存储在指定位置的数据
-
遍历 就是 从头到尾 依次 从 元组 中获取数据
# for 循环内部使用的变量 in 元组
for item in info:
循环内部针对元组元素进行操作
print(item)
tup = (1, 2, 3, 4, 5)
for item in tup:
print(item)
1 2 3 4 5
在
Python中,可以使用for循环遍历所有非数字型类型的变量:列表、元组、字典 以及 字符串提示:在实际开发中,除非 能够确认元组中的数据类型,否则针对元组的循环遍历需求并不是很多
(9)应用场景
-
尽管可以使用
for in遍历 元组 -
但是在开发中,更多的应用场景是:
-
函数的 参数 和 返回值,一个函数可以接收 任意多个参数,或者 一次返回多个数据
-
有关 函数的参数 和 返回值,在后续 函数高级 给大家介绍
-
-
格式字符串,格式化字符串后面的
()本质上就是一个元组 -
让列表不可以被修改,以保护数据安全
-
info = ("zhangsan", 18)
print("%s 的年龄是 %d" % info)
(10)元组和列表之间的转换
-
使用
list函数可以把元组转换成列表
list(元组)
-
使用
tuple函数可以把列表转换成元组
tuple(列表)
11.字典
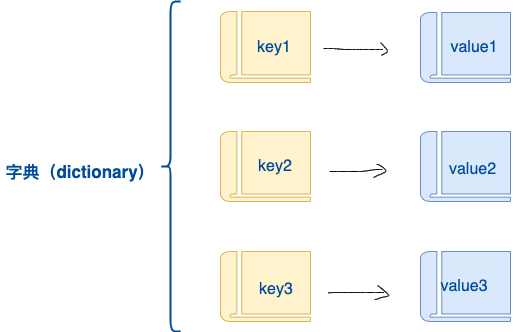
(1)定义
-
dictionary(字典) 是 除列表以外Python之中 最灵活 的数据类型 -
字典同样可以用来 存储多个数据
-
通常用于存储 描述一个
物体的相关信息
-
-
和列表的区别
-
列表 是 有序 的对象集合
-
字典 是 无序 的对象集合
-
-
字典用
{}定义 -
字典使用 键值对 存储数据,键值对之间使用
,分隔-
键
key是索引 -
值
value是数据 -
键 和 值 之间使用
:分隔 -
键必须是唯一的
-
值 可以取任何数据类型,但 键 只能使用 字符串、数字或 元组
-
d = {key1 : value1, key2 : value2, key3 : value3 }
eg:
xiaoming = {"name": "小明",
"age": 18,
"gender": True,
"height": 1.75}
{'name': '小明', 'age': 18, 'gender': True, 'height': 1.75}
注意: dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
(2)常用操作
-
定义一个 字典,例如:
xiaoming = {} -
使用大括号 { } 创建空字典:
-
输入
xiaoming.按下TAB键,ipython会提示 字典 能够使用的函数如下:
In [1]: xiaoming. xiaoming.clear xiaoming.items xiaoming.setdefault xiaoming.copy xiaoming.keys xiaoming.update xiaoming.fromkeys xiaoming.pop xiaoming.values xiaoming.get xiaoming.popitem
有关 字典 的 常用操作 可以参照上图练习
1)访问值
把相应的键放入到方括号中,如下实例:
xiaoming = {"name": "小明",
"age": 18,
"gender": True,
"height": 1.75}
print("xiaoming['name']: ", xiaoming['name'])
print("xiaoming['age']: ", xiaoming['age'])
以上实例输出结果:
xiaoming['name']: 小明 xiaoming['age']: 18
如果用字典里没有的键访问数据,会输出错误如下:
xiaoming = {"name": "小明",
"age": 18,
"gender": True,
"height": 1.75}
print("xiaoming['name']: ", xiaoming['name123'])
print("xiaoming['age']: ", xiaoming['age'])
以上实例输出结果:
Traceback (most recent call last):
File "D:\桌面\Pythoncode\Test.py", line 6, in <module>
print("xiaoming['name']: ", xiaoming['name123'])
KeyError: 'name123'
2)修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
(如果新内容键值不存在----新增,存在---修改)
新增:
xiaoming_dict = {"name": "小明"}
xiaoming_dict["age"] = 12, 18
print(xiaoming_dict)
以上实例输出结果:
{'name': '小明', 'age': (12, 18)}
修改:
xiaoming_dict = {"name": "小明"}
xiaoming_dict["age"] = 12
xiaoming_dict["name"] = "小小明"
print(xiaoming_dict)
以上实例输出结果:
{'name': '燕小明', 'age': 12}
3)删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显式删除一个字典用del命令,如下实例:
xiaoming_dict = {"name": "小明"}
del xiaoming_dict
print(xiaoming_dict)
但这会引发一个异常,因为用执行 del 操作后字典不再存在:
Traceback (most recent call last):
File "D:\桌面\Pythoncode\Test.py", line 4, in <module>
print(xiaoming_dict)
NameError: name 'xiaoming_dict' is not defined
删除指定键pop
xiaoming_dict = {"name": "小明",
"age":18}
xiaoming_dict.pop("name")
print(xiaoming_dict)
{'age': 18}
如果指定删除的键不存在程序会报错
4)内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数 | 描述 |
|---|---|---|
| 1 | len(dict) | 计算字典元素个数,即键的总数。 |
| 2 | str(dict) | 输出字典,可以打印的字符串表示。 |
| 3 | type(variable) | 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数 | 描述 |
|---|---|---|
| 1 | dict.clear() | 删除字典内所有元素 |
| 2 | dict.copy() | 返回一个字典的浅复制 |
| 3 | dict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) | 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict | 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() | 以列表返回一个视图对象 |
| 7 | dict.keys() | 返回一个视图对象 |
| 8 | dict.setdefault(key, default=None) | 与get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) | 把字典dict2的键/值对更新到dict里,如果合并的字典中包含已经存在的键值对,会覆盖原有的键值对 |
演示:
len计算字典元素个数
xiaoming_dict = {"name": "小明",
"age":18}
print(len(xiaoming_dict))
2
update合并字典
test_one = {"name": "小明"}
test_two = {"age": 16}
test_one.update(test_two)
print(test_one)
{'name': '小明', 'age': 16}
合并键值对中键值对重复,覆盖原有的键值对
test_one = {"name": "小明",
"age":18}
test_two = {"name": "小王",
"age":16}
test_one.update(test_two)
print(test_one)
{'name': '小王', 'age': 16}
5)字典键的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
(1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
test_one = {"name": "小明", "age": 18, "name": "小王" }
print(test_one)
{'name': '小王', 'age': 18}
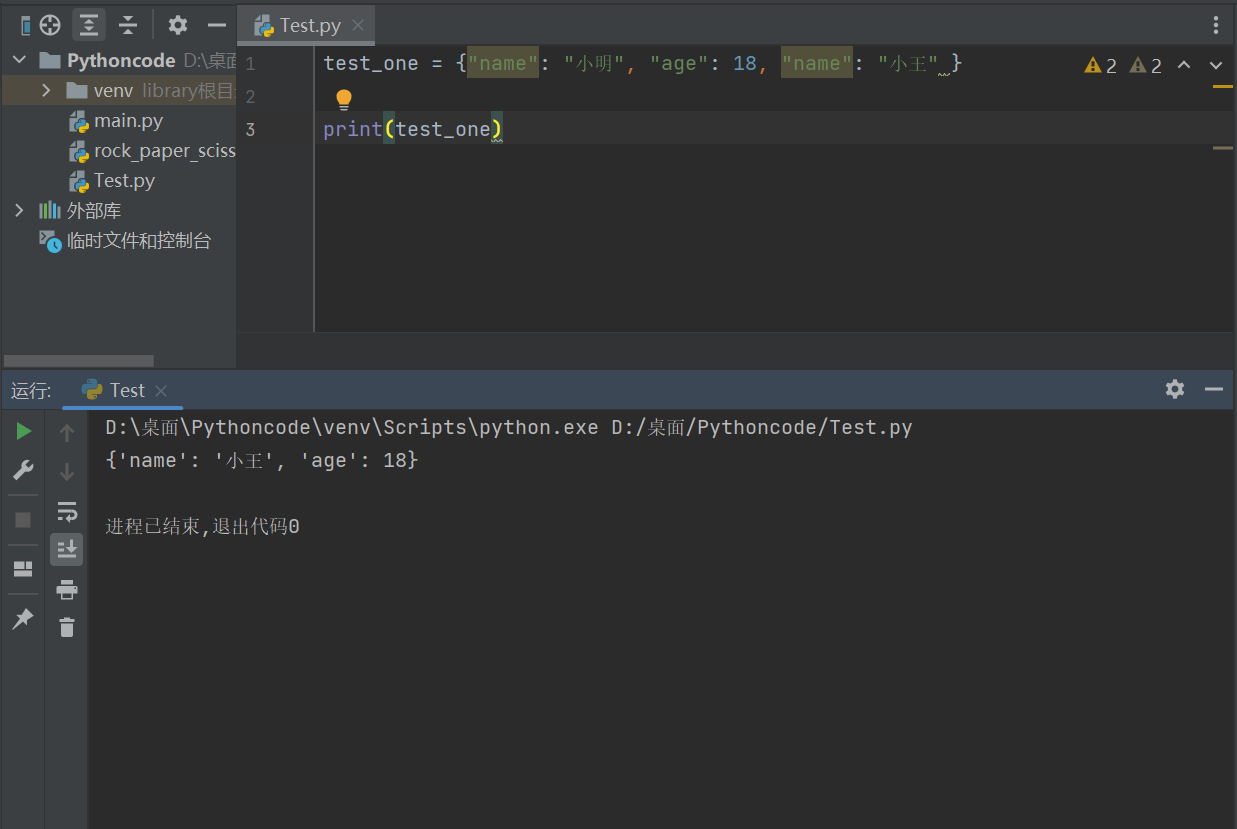
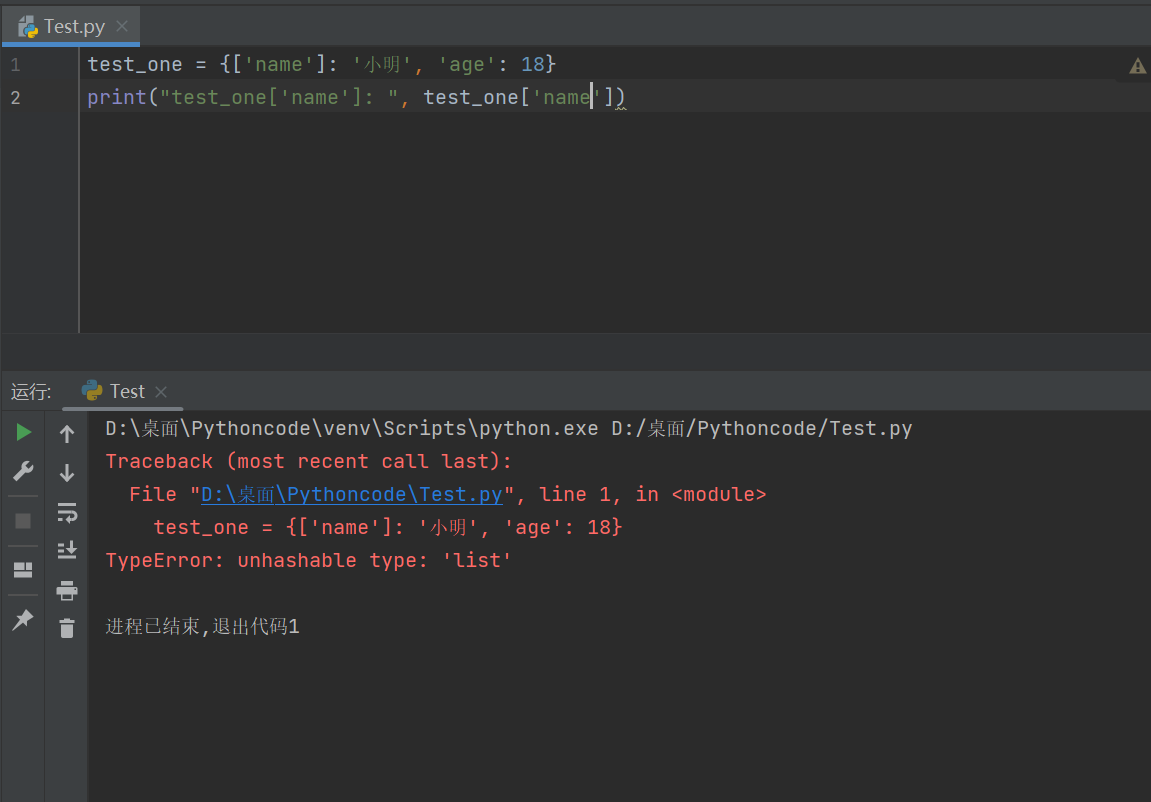
(2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
test_one = {['name']: '小明', 'age': 18}
print("test_one['name']: ", test_one['name'])
以上实例输出结果:
Traceback (most recent call last):
File "D:\桌面\Pythoncode\Test.py", line 1, in <module>
test_one = {['name']: '小明', 'age': 18}
TypeError: unhashable type: 'list'
6)循环遍历
-
遍历就是 依次 从 字典 中获取所有键值对
test_one = {"name": "小明",
"age": "18",
"phone": "10086"}
for k in test_one:
print("%s: %s" % (k, test_one[k]))
提示:在实际开发中,由于字典中每一个键值对保存数据的类型是不同的,所以针对字典的循环遍历需求并不是很多
7)应用场景
-
尽管可以使用
for in遍历 字典 -
但是在开发中,更多的应用场景是:
-
使用 多个键值对,存储 描述一个
物体的相关信息 —— 描述更复杂的数据信息 -
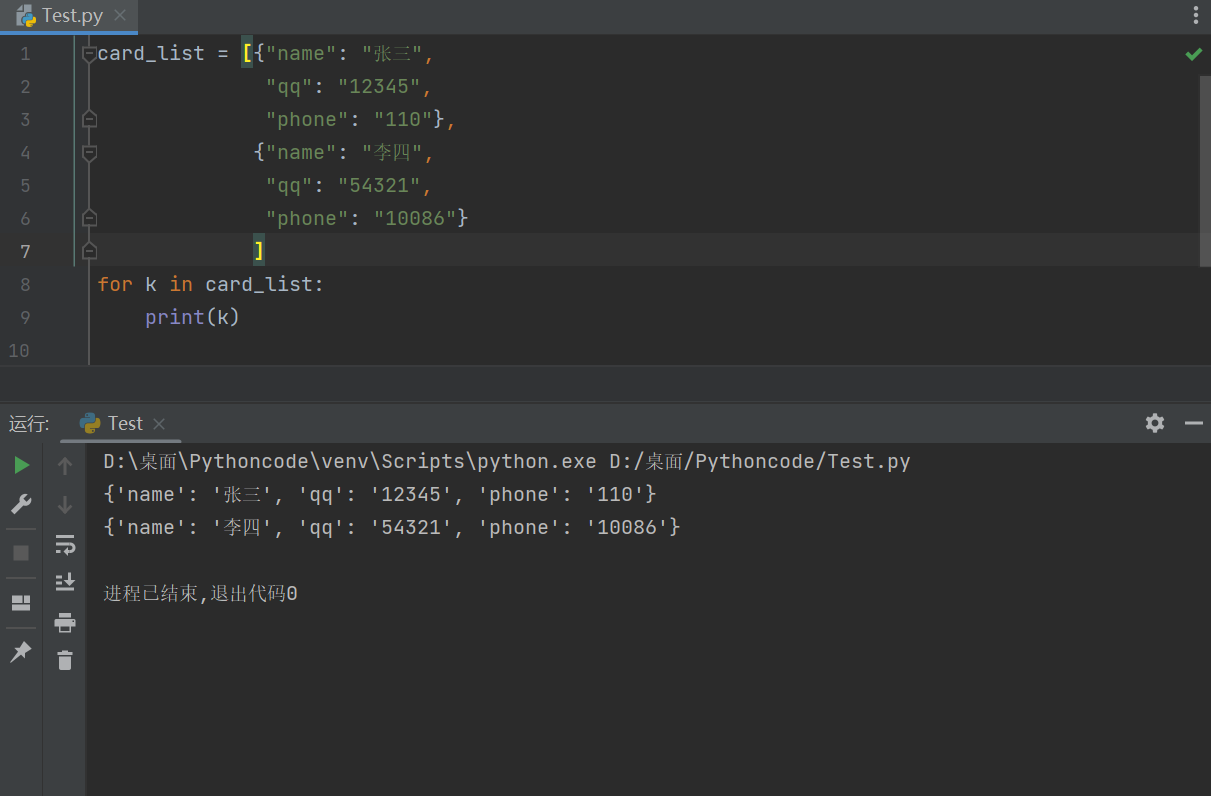
将 多个字典 放在 一个列表 中,再进行遍历,在循环体内部针对每一个字典进行 相同的处理
-
card_list = [{"name": "张三",
"qq": "12345",
"phone": "110"},
{"name": "李四",
"qq": "54321",
"phone": "10086"}
]
for k in card_list:
print(k)
{'name': '张三', 'qq': '12345', 'phone': '110'}
{'name': '李四', 'qq': '54321', 'phone': '10086'}
12.字符串
(1)定义
-
字符串 就是 一串字符,是编程语言中表示文本的数据类型
-
在 Python 中可以使用 一对双引号
"或者 一对单引号'定义一个字符串-
虽然可以使用
\"或者\'做字符串的转义,但是在实际开发中:-
如果字符串内部需要使用
",可以使用'定义字符串 -
如果字符串内部需要使用
',可以使用"定义字符串
-
-
-
可以使用 索引 获取一个字符串中 指定位置的字符,索引计数从 0 开始
-
也可以使用
for循环遍历 字符串中每一个字符
大多数编程语言都是用
"来定义字符串
string = "Hello Python"
for c in string:
print(c)
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串。
(2)转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 ** 转义字符。如下表:
| 转义字符 | 描述 | 实例 |
|---|---|---|
| (在行尾时) | 续行符 | >>> print("line1 \ ... line2 \ ... line3") line1 line2 line3 >>> |
| \ | 反斜杠符号 | >>> print("\\") \ |
| ' | 单引号 | >>> print('\'') ' |
| " | 双引号 | >>> print("\"") " |
| \a | 响铃 | >>> print("\a")执行后电脑有响声。 |
| \b | 退格(Backspace) | >>> print("Hello \b World!") Hello World! |
| \000 | 空 | >>> print("\000") >>> |
| \n | 换行 | >>> print("\n") >>> |
| \v | 纵向制表符 | >>> print("Hello \v World!") Hello World! >>> |
| \t | 横向制表符 | >>> print("Hello \t World!") Hello World! >>> |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | >>> print("Hello\rWorld!") World! >>> print('google runoob taobao\r123456') 123456 runoob taobao |
| \f | 换页 | >>> print("Hello \f World!") Hello World! >>> |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | >>> print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | >>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World! |
| \other | 其它的字符以普通格式输出 |
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
(3)常用操作
-
在
ipython3中定义一个 字符串,例如:hello_str = "" -
输入
hello_str.按下TAB键,ipython会提示 字符串 能够使用的 方法 如下:
In [1]: hello_str. hello_str.capitalize hello_str.isidentifier hello_str.rindex hello_str.casefold hello_str.islower hello_str.rjust hello_str.center hello_str.isnumeric hello_str.rpartition hello_str.count hello_str.isprintable hello_str.rsplit hello_str.encode hello_str.isspace hello_str.rstrip hello_str.endswith hello_str.istitle hello_str.split hello_str.expandtabs hello_str.isupper hello_str.splitlines hello_str.find hello_str.join hello_str.startswith hello_str.format hello_str.ljust hello_str.strip hello_str.format_map hello_str.lower hello_str.swapcase hello_str.index hello_str.lstrip hello_str.title hello_str.isalnum hello_str.maketrans hello_str.translate hello_str.isalpha hello_str.partition hello_str.upper hello_str.isdecimal hello_str.replace hello_str.zfill hello_str.isdigit hello_str.rfind
提示:正是因为 python 内置提供的方法足够多,才使得在开发时,能够针对字符串进行更加灵活的操作!应对更多的开发需求!
1)访问字符串中的值
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号 [] 来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
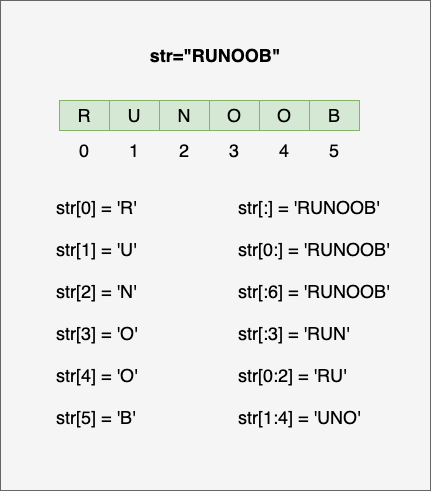
如下实例:
var1 = 'Hello World!'
var2 = "123456"
print("var1[0]: ", var1[0])
print("var2[1:5]: ", var2[1:5])
以上实例执行结果:
var1[0]: H var2[1:5]: 2345
2)统计长度/次数/位置
1.统计字符串长度
hello_str = "hello hello" print(len(hello_str))
11
2.统计某一个小字符串出现的次数
hello_str = "hello hello"
print(hello_str.count("llo"))
2
3.某一个子字符串出现的位置
hello_str = "hello hello"
print(hello_str.index("llo"))
2
如果使用index方法传递的子字符串不存在,程序会报错
3) 判断类型
| 方法 | 说明 |
|---|---|
| string.isspace() | 如果 string 中只包含空格,则返回 True |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| string.isdecimal() | 如果 string 只包含数字则返回 True,全角数字 |
| string.isdigit() | 如果 string 只包含数字则返回 True,全角数字、⑴、\u00b2 |
| string.isnumeric() | 如果 string 只包含数字则返回 True,全角数字,汉字数字 |
| string.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
(1)ispace
如果 string 中只包含空格,则返回 True
注意:这里的空格还包括:\n \v \t \r \f
hello_str = "\n \v \t \r \f" print(hello_str.isspace())
True
(2)isdecimal / isdigit / isnumeric
1.都不能判断小数
num_str = "1.1" print(num_str) print(num_str.isdecimal()) print(num_str.isdigit()) print(num_str.isnumeric())
1.1 False False False
2.特殊符号后两个可以判断
eg1:
num_str = "⑴" print(num_str) print(num_str.isdecimal()) print(num_str.isdigit()) print(num_str.isnumeric())
⑴ False True True
eg2:
num_str = "\u00b2" print(num_str) print(num_str.isdecimal()) print(num_str.isdigit()) print(num_str.isnumeric())
² False True True
3.中文汉字仅最后一个可以判断
num_str = "一千零一" print(num_str) print(num_str.isdecimal()) print(num_str.isdigit()) print(num_str.isnumeric())
一千零一 False False True
故在开发时建议使用isdecimal方法
4) 查找和替换
| 方法 | 说明 |
|---|---|
| string.startswith(str) | 检查字符串是否是以指定 str 开头,是则返回 True |
| string.endswith(str) | 检查字符串是否是以指定 str 结束,是则返回 True |
| string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1 |
| string.rfind(str,start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| string.index(str,start=0,end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| string.rindex(str,start=0,end=len(string)) | 类似于 index(),不过是从右边开始 |
| string.replace(old_str,new_str,num=string.count(old)) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 |
(1)startswith
检查字符串是否是以指定 str 开头,是则返回 True
hello_str = "hello"
print(hello_str.startswith("hello"))
True
在python中是区分大小写的
hello_str = "hello"
print(hello_str.startswith("hello"))
False
(2)endwith
检查字符串是否是以指定 str 结束,是则返回 True
hello_str = "hello world"
print(hello_str.endswith("world"))
True
同样也是区分大小写的
hello_str = "hello world"
print(hello_str.endswith("World"))
False
(3)find
检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1
hello_str = "hello world"
print(hello_str.find("llo"))
print(hello_str.find("abc"))
2 -1
index同样也可以查找指定的字符串在大字符中的索引,但是在index中指定字符串不存在会报错,而find中不存在会返回-1
(4)replace
把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次
replace方法执行完成之后,会返回一个新的字符串,但不会修改原有字符串的内容
hello_str = "hello world"
print(hello_str.replace("world", "python"))
print(hello_str)
hello python hello world
5) 大小写转换
| 方法 | 说明 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.title() | 把字符串的每个单词首字母大写 |
| string.lower() | 转换 string 中所有大写字符为小写 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.swapcase() | 翻转 string 中的大小写 |
6) 文本对齐
| 方法 | 说明 |
|---|---|
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
(1)ljust左对齐
poem = ["登鹳雀楼",
"王之涣 ",
"白日依山尽,",
"黄河入海流。",
"欲穷千里目,",
"更上一层楼。"]
for pome_str in poem:
print("|%s|" % pome_str.ljust(10, " "))
|登鹳雀楼 | |王之涣 | |白日依山尽, | |黄河入海流。 | |欲穷千里目, | |更上一层楼。 |
(2)rjust右对齐
poem = ["登鹳雀楼",
"王之涣 ",
"白日依山尽,",
"黄河入海流。",
"欲穷千里目,",
"更上一层楼。"]
for pome_str in poem:
print("|%s|" % pome_str.rjust(10, ""))
| 登鹳雀楼| | 王之涣 | | 白日依山尽,| | 黄河入海流。| | 欲穷千里目,| | 更上一层楼。|
(3)center居中
poem = ["登鹳雀楼",
"王之涣 ",
"白日依山尽,",
"黄河入海流。",
"欲穷千里目,",
"更上一层楼。"]
for pome_str in poem:
print("|%s|" % pome_str.center(10))
注:
print("|%s|" % pome_str.center(10, " "))
也可以这样输出,默认的是英文空格,也可以插入中文空格或者 \t
| 登鹳雀楼 | | 王之涣 | | 白日依山尽, | | 黄河入海流。 | | 欲穷千里目, | | 更上一层楼。 |
7) 去除空白字符
| 方法 | 说明 |
|---|---|
| string.lstrip() | 截掉 string 左边(开始)的空白字符 |
| string.rstrip() | 截掉 string 右边(末尾)的空白字符 |
| string.strip() | 截掉 string 左右两边的空白字符 |
poem = ["\t\n登鹳雀楼",
"王之涣 ",
"白日依山尽,\t\n",
"黄河入海流。",
"欲穷千里目,",
"更上一层楼。"]
for pome_str in poem:
print("|%s|" % pome_str.strip().center(10))
| 登鹳雀楼 | | 王之涣 | | 白日依山尽, | | 黄河入海流。 | | 欲穷千里目, | | 更上一层楼。 |
8) 拆分和连接
| 方法 | 说明 |
|---|---|
| string.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| string.split(str="",num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 '\r', '\t', '\n' 和空格 |
| string.splitlines() | 按照行('\r', '\n', '\r\n')分隔,返回一个包含各行作为元素的列表 |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
(1)拆分字符串
poem = "登鹳雀楼\t 王之涣 \t 白日依山尽 \t\n 黄河入海流 \t \t\n 欲穷千里目 \t 更上一层楼" poem_list = poem.split() print(poem_list)
['登鹳雀楼', '王之涣', '白日依山尽', '黄河入海流', '欲穷千里目', '更上一层楼']
(2)合并字符串
poem = "登鹳雀楼\t 王之涣 \t 白日依山尽 \t\n 黄河入海流 \t \t\n 欲穷千里目 \t 更上一层楼" poem_list = poem.split() print(poem_list) result = " ".join(poem_list) print(result)
['登鹳雀楼', '王之涣', '白日依山尽', '黄河入海流', '欲穷千里目', '更上一层楼'] 登鹳雀楼 王之涣 白日依山尽 黄河入海流 欲穷千里目 更上一层楼
(4)字符串的切片
-
切片 方法适用于 字符串、列表、元组
-
切片 使用 索引值 来限定范围,从一个大的 字符串 中 切出 小的 字符串
-
列表 和 元组 都是 有序 的集合,都能够 通过索引值 获取到对应的数据
-
字典 是一个 无序 的集合,是使用 键值对 保存数据
-
字符串[开始索引:结束索引:步长]
注意:
-
指定的区间属于 左闭右开 型
[开始索引, 结束索引)=>开始索引 >= 范围 < 结束索引-
从
起始位开始,到结束位的前一位 结束(不包含结束位本身)
-
-
从头开始,开始索引 数字可以省略,冒号不能省略
-
到末尾结束,结束索引 数字可以省略,冒号不能省略
-
步长默认为
1,如果连续切片,数字和冒号都可以省略
索引的顺序和倒序
-
在 Python 中不仅支持 顺序索引,同时还支持 倒序索引
-
所谓倒序索引就是 从右向左 计算索引
-
最右边的索引值是 -1,依次递减
-
演练
-
-
截取从 2 ~ 5 位置 的字符串
-
-
-
截取从 2 ~
末尾的字符串
-
-
-
截取从
开始~ 5 位置 的字符串
-
-
-
截取完整的字符串
-
-
-
从开始位置,每隔一个字符截取字符串
-
-
-
从索引 1 开始,每隔一个取一个
-
-
-
截取从 2 ~
末尾 - 1的字符串
-
-
-
截取字符串末尾两个字符
-
-
-
字符串的逆序(面试题)
-
答案
num_str = "0123456789" # 1.截取2-5位置的字符串 print(num_str[2:6]) # 2.截取2-末尾位置的字符串 print(num_str[2:]) # 3.截取从开始到5位置的字符串 print(num_str[:6]) print(num_str[0:6]) # 4.截取完整字符 print(num_str[:]) # 5.每隔一个字符串截取一个字符 print(num_str[::2]) # 6.索引从1开始每隔一个字符串截取一个字符 print(num_str[1::2]) # 7.截取从2到-1的字符串 print(num_str[2:-1]) # 8.截取末尾两个字符串 print(num_str[-2:]) # 9.通过切片获取字符串的逆序 print(num_str[-1::-1])
13.公共方法
公共方法------列表,元组,字符串(高级数据类型)都可以使用的方法为
1)Python 内置函数
内置函数------不需要通过使用import关键字导入任何模块就可以通过函数名直接调用的函数
Python 包含了以下内置函数:
| 函数 | 描述 | 备注 |
|---|---|---|
| len(item) | 计算容器中元素个数 | |
| del(item) | 删除变量 | del 有两种方式 |
| max(item) | 返回容器中元素最大值 | 如果是字典,只针对 key 比较 |
| min(item) | 返回容器中元素最小值 | 如果是字典,只针对 key 比较 |
| cmp(item1, item2) | 比较两个值,-1 小于/0 相等/1 大于 | Python 3.x 取消了 cmp 函数 |
eg:
num_list = [1, 2, 3, 4, 8, 9] print(len(num_list)) print(min(num_list)) print(max(num_list))
6 1 9
*注意**
-
字符串 比较符合以下规则: "0" < "A" < "a"
2)切片
| 描述 | Python 表达式 | 结果 | 支持的数据类型 |
|---|---|---|---|
| 切片 | "0123456789"[::-2] | "97531" | 字符串、列表、元组 |
-
切片 使用 索引值 来限定范围,从一个大的 字符串 中 切出 小的 字符串
-
列表 和 元组 都是 有序 的集合,都能够 通过索引值 获取到对应的数据
-
字典 是一个 无序 的集合,是使用 键值对 保存数据,故不可以切片
eg:
num_list = [1, 2, 3, 4, 8, 9] print(num_list[0::2]) num_lists = (1, 2, 3, 4, 8, 9) print(num_lists[0::2])
[1, 3, 8] (1, 3, 8)
3)运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | ["Hi!"] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
| > >= == < <= | (1, 2, 3) < (2, 2, 3) | True | 元素比较 | 字符串、列表、元组 |
+
print("Hello" + "Python")
HelloPython
*
print("Hello "*3)
Hello Hello Hello
in
print("a" in "abc")
True
not in
print("a" not in "abc")
False
注意
-
in在对 字典 操作时,判断的是 字典的键 -
in和not in被称为 成员运算符
成员运算符
成员运算符用于 测试 序列中是否包含指定的 成员
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | 3 in (1, 2, 3) 返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | 3 not in (1, 2, 3) 返回 False |
注意:在对 字典 操作时,判断的是 字典的键
4)完整的 for 循环语法
-
在
Python中完整的for 循环的语法如下:
for 变量 in 集合:
循环体代码
else:
没有通过 break 退出循环,循环结束后,会执行的代码
应用场景
-
在 迭代遍历 嵌套的数据类型时,例如 一个列表包含了多个字典
-
需求:要判断 某一个字典中 是否存在 指定的 值
-
如果 存在,提示并且退出循环
-
如果 不存在,在 循环整体结束 后,希望 得到一个统一的提示
-
eg:
for num in [1,2,3]:
print(num)
else:
print("会执行嘛")
print("循环结束")
1 2 3 会执行嘛 循环结束
eg:
for num in [1,2,3]:
print(num)
if num ==2:
break
else:
print("会执行嘛")
print("循环结束")
1 2 循环结束
students = [
{"name": "阿土",
"age": 20,
"gender": True,
"height": 1.7,
"weight": 75.0},
{"name": "小美",
"age": 19,
"gender": False,
"height": 1.6,
"weight": 45.0},
]
find_name = "阿土"
for stu_dict in students:
print(stu_dict)
# 判断当前遍历的字典中姓名是否为find_name
if stu_dict["name"] == find_name:
print("找到了")
# 如果已经找到,直接退出循环,就不需要再对后续的数据进行比较
break
else:
print("没有找到")
print("循环结束")
{'name': '阿土', 'age': 20, 'gender': True, 'height': 1.7, 'weight': 75.0}
找到了
循环结束
综合应用---名片管理系统
综合应用已经学习过的知识点:
-
变量
-
流程控制
-
函数
-
模块
开发 名片管理系统
系统需求:
-
-
程序启动,显示名片管理系统欢迎界面,并显示功能菜单
-
************************************************** 欢迎使用【名片管理系统】V1.0 1. 新建名片 2. 显示全部 3. 查询名片 0. 退出系统 **************************************************
-
-
用户用数字选择不同的功能
-
-
-
根据功能选择,执行不同的功能
-
-
-
用户名片需要记录用户的 姓名、电话、QQ、邮件
-
-
-
如果查询到指定的名片,用户可以选择 修改 或者 删除 名片
-
cards_main.py
import cards_tools
while True:
# 显示功能菜单
cards_tools.show_menu()
action_str = input("请您选择希望执行的操作:\n")
if action_str in ["1", "2", "3"]:
# 1. 新建名片
if action_str == "1":
cards_tools.new_card()
# 2. 显示全部
elif action_str == "2":
cards_tools.show_all()
# 3. 查询名片
elif action_str == "3":
cards_tools.search_card()
elif action_str == "0":
print("欢迎再次使用【名片管理系统】")
# 在开发时,不希望立即编写分支内部的代码
# 或者这里不输出提示语句时,应用到 pass 关键字,表示一个占位符,能保证程序代码的结构正确
# 程序运行时,pass关键字不会执行任何操作
break
else:
print("您输入的不正确,请重新输入")
cards_tools.py
# 记录所有名片字典
card_list = []
def show_menu():
"""显示菜单"""
print("*" * 50)
print("迎使用【名片管理系统】V1.0")
print("1. 新建名片")
print("2. 显示全部")
print("3. 查询名片")
print("0. 退出系统")
print("*" * 50)
def new_card():
"""新增名片"""
print("-" * 50)
print("新增名片")
# 1.提示用户输入名片的详细信息
name_str = input("请输入姓名:")
phone_str = input("请输入电话:")
qq_str = input("请输入QQ号码:")
email_str = input("请输入邮箱号码:")
# 2.使用用户输入的信息建立一个名片字典
card_dict = {"name": name_str,
"phone": phone_str,
"qq": qq_str,
"email": email_str}
# 3.将名片字典添加到列表中
card_list.append(card_dict)
print(card_list)
# 4.提示用户添加成功
print("添加 %s 的名片成功!" % name_str)
def show_all():
"""显示所有名片"""
print("-" * 50)
print("显示所有名片")
# 判断是否存在名片记录,如果没有,提示用户并且返回
if len(card_list) == 0:
print("当前没有任何名片记录,请使用新增功能添加名片!")
# return 可以反hi一个函数的执行结果
# 下方的代码不会执行
# 如果return后面没有任何内容,便是会返回到调用函数的位置,并且不能返回任何结果
return
# 打印表头
for name in ["姓名", "电话", "QQ ", "邮箱"]:
print(name, end="\u3000\t\t")
print("")
# 打印分割线
print("=" * 50)
# 遍历名片列表依次输出字典信息
for card_dict in card_list:
print("%s\u3000\t\t%s\u3000\t\t%s\u3000\t\t%s\u3000\t\t" % (card_dict["name"],
card_dict["phone"],
card_dict["qq"],
card_dict["email"]))
def search_card():
"""搜索名片"""
print("-" * 50)
print("搜索名片")
# 1.提示用户输入要搜索的姓名
find_name = input("请输入要搜素的姓名:")
# 2.遍历名片列表,查询要搜索的姓名,如果没有找到,需要提示用户
for card_dict in card_list:
if card_dict["name"] == find_name:
print("姓名\u3000\t\t电话\u3000\t\tQQ \u3000\t\t邮箱")
print("%s\u3000\t\t%s\u3000\t\t%s\u3000\t\t%s\u3000\t\t" % (card_dict["name"],
card_dict["phone"],
card_dict["qq"],
card_dict["email"]))
# 针对找到的字典信息进行修改和删除
deal_card(card_dict)
break
else:
print("抱歉没有找到 %s" % find_name)
# 修改和删除函数
def deal_card(find_dict):
"""处理查找到的名片
:param find_dict: 查找到的名片
"""
print(find_dict)
action_str = input("请选择要执行的操作 "
"【1】 修改 "
"【2】 删除 "
"【0】 返回上级")
if action_str == "1":
find_dict["name"] = input_card_info(find_dict["name"], "姓名:")
find_dict["phone"] = input_card_info(find_dict["phone"], "电话:")
find_dict["qq"] = input_card_info(find_dict["qq"], "qq号码:")
find_dict["email"] = input_card_info(find_dict["email"], "邮箱号码:")
print("修改名片")
elif action_str == "2":
card_list.remove(find_dict)
print("删除名片成功!")
def input_card_info(dic_value, tip_message):
"""输入名片信息
:param dic_value:字典中原有的值
:param tip_message:输入的提示文字
:return:如果用户输入了内容,就返回内容,否则返回字典中原有的值
"""
# 1.提示用户输入内容
result_str = input(tip_message)
# 2.针对用户输入进行判断,如果用户输入了内容,直接返回结果
if len(result_str) > 0:
return result_str
# 3.如果用户没有输入内容,返回’字符串中原有的值‘
else:
return dic_value
14.变量进阶(理解)
-
变量的引用
-
可变和不可变类型
-
局部变量和全局变量
(1)变量的引用
变量 和 数据 都是保存在 内存 中的
在
Python中 函数 的 参数传递 以及 返回值 都是靠 引用 传递的
1)引用的概念
在 Python 中
-
变量 和 数据 是分开存储的
-
数据 保存在内存中的一个位置
-
变量 中保存着数据在内存中的地址
-
变量 中 记录数据的地址,就叫做 引用
-
使用
id()函数可以查看变量中保存数据所在的 内存地址
注意:如果变量已经被定义,当给一个变量赋值的时候,本质上是 修改了数据的引用
变量 不再 对之前的数据引用
变量 改为 对新赋值的数据引用
2)变量引用的示例
在 Python 中,变量的名字类似于 便签纸 贴在 数据 上
-
定义一个整数变量
a,并且赋值为1
| 代码 | 图示 |
|---|---|
| a = 1 |
|

-
将变量
a赋值为2
| 代码 | 图示 |
|---|---|
| a = 2 |
|
-
定义一个整数变量
b,并且将变量a的值赋值给b
| 代码 | 图示 |
|---|---|
| b = a |
|

变量
b是第 2 个贴在数字2上的标签
3)函数的参数和返回值的传递
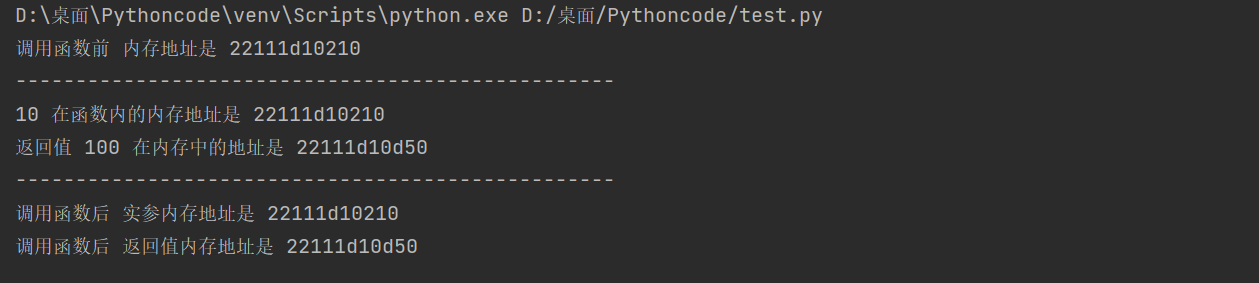
在 Python 中,函数的 实参/返回值 都是是靠 引用 来传递来的
def test(num):
print("-" * 50)
print("%d 在函数内的内存地址是 %x" % (num, id(num)))
result = 100
print("返回值 %d 在内存中的地址是 %x" % (result, id(result)))
print("-" * 50)
return result
a = 10
print("调用函数前 内存地址是 %x" % id(a))
r = test(a)
print("调用函数后 实参内存地址是 %x" % id(a))
print("调用函数后 返回值内存地址是 %x" % id(r))
(2)可变和不可变类型
-
不可变类型,内存中的数据不允许被修改:
-
数字类型
int,bool,float,complex,long(2.x) -
字符串
str -
元组
tuple
-
-
可变类型,内存中的数据可以被修改:
-
列表
list -
字典
dict
-
a = 1 a = "hello" a = [1, 2, 3] a = [3, 2, 1]
demo_list = [1, 2, 3]
print("定义列表后的内存地址 %d" % id(demo_list))
demo_list.append(999)
demo_list.pop(0)
demo_list.remove(2)
demo_list[0] = 10
print("修改数据后的内存地址 %d" % id(demo_list))
demo_dict = {"name": "小明"}
print("定义字典后的内存地址 %d" % id(demo_dict))
demo_dict["age"] = 18
demo_dict.pop("name")
demo_dict["name"] = "老王"
print("修改数据后的内存地址 %d" % id(demo_dict))

注意:字典的
key只能使用不可变类型的数据
注意
-
可变类型的数据变化,是通过 方法 来实现的
-
如果给一个可变类型的变量,赋值了一个新的数据,引用会修改
-
变量 不再 对之前的数据引用
-
变量 改为 对新赋值的数据引用
-
哈希 (hash)
-
Python中内置有一个名字叫做hash(o)的函数-
接收一个 不可变类型 的数据作为 参数
-
返回 结果是一个 整数
-
-
哈希是一种 算法,其作用就是提取数据的 特征码(指纹)-
相同的内容 得到 相同的结果
-
不同的内容 得到 不同的结果
-
-
在
Python中,设置字典的 键值对 时,会首先对key进行hash已决定如何在内存中保存字典的数据,以方便 后续 对字典的操作:增、删、改、查-
键值对的
key必须是不可变类型数据 -
键值对的
value可以是任意类型的数据
-
(3)局部变量和全局变量
-
局部变量 是在 函数内部 定义的变量,只能在函数内部使用
-
全局变量 是在 函数外部定义 的变量(没有定义在某一个函数内),所有函数 内部 都可以使用这个变量
提示:在其他的开发语言中,大多 不推荐使用全局变量 —— 可变范围太大,导致程序不好维护!
1)局部变量
-
局部变量 是在 函数内部 定义的变量,只能在函数内部使用
-
函数执行结束后,函数内部的局部变量,会被系统回收
-
不同的函数,可以定义相同的名字的局部变量,但是 彼此之间 不会产生影响
1.作用
-
在函数内部使用,临时 保存 函数内部需要使用的数据
def demo1():
num = 10
print(num)
num = 20
print("修改后 %d" % num)
def demo2():
num = 100
print(num)
demo1()
demo2()
print("over")
10 修改后 20 100 over
2.生命周期
-
所谓 生命周期 就是变量从 被创建 到 被系统回收 的过程
-
局部变量 在 函数执行时 才会被创建
-
函数执行结束后 局部变量 被系统回收
-
局部变量在生命周期 内,可以用来存储 函数内部临时使用到的数据
2)全局变量
-
全局变量 是在 函数外部定义 的变量,所有函数内部都可以使用这个变量
# 定义一个全局变量
num = 10
def demo1():
print(num)
def demo2():
print(num)
demo1()
demo2()
print("over")
注意:函数执行时,需要处理变量时 会:
-
首先 查找 函数内部 是否存在 指定名称 的局部变量,如果有,直接使用
-
如果没有,查找 函数外部 是否存在 指定名称 的全局变量,如果有,直接使用
-
如果还没有,程序报错!
1.函数不能直接修改全局变量的引用
-
全局变量 是在 函数外部定义 的变量(没有定义在某一个函数内),所有函数 内部 都可以使用这个变量
提示:在其他的开发语言中,大多 不推荐使用全局变量 —— 可变范围太大,导致程序不好维护!
-
在函数内部,可以 通过全局变量的引用获取对应的数据
-
但是,不允许直接修改全局变量的引用 —— 使用赋值语句修改全局变量的值
num = 10
def demo1():
print("demo1" + "-" * 50)
# 只是定义了一个局部变量,不会修改到全局变量,只是变量名相同而已
num = 100
print(num)
def demo2():
print("demo2" + "-" * 50)
print(num)
demo1()
demo2()
print("over")
demo1-------------------------------------------------- 100 demo2-------------------------------------------------- 10 over
注意:只是在函数内部定义了一个局部变量而已,只是变量名相同 —— 在函数内部不能直接修改全局变量的值
2.在函数内部修改全局变量的值
-
如果在函数中需要修改全局变量,需要使用
global进行声明
num = 10
def demo1():
print("demo1" + "-" * 50)
# global 关键字,告诉 Python 解释器 num 是一个全局变量
global num
# 只是定义了一个局部变量,不会修改到全局变量,只是变量名相同而已
num = 100
print(num)
def demo2():
print("demo2" + "-" * 50)
print(num)
demo1()
demo2()
print("over")
demo1-------------------------------------------------- 100 demo2-------------------------------------------------- 100 over
3.全局变量定义的位置
-
为了保证所有的函数都能够正确使用到全局变量,应该 将全局变量定义在其他函数的上方
a = 10
def demo():
print("%d" % a)
print("%d" % b)
print("%d" % c)
b = 20
demo()
c = 30
Traceback (most recent call last):
File "D:\桌面\Pythoncode\test.py", line 10, in <module>
demo()
File "D:\桌面\Pythoncode\test.py", line 7, in demo
print("%d" % c)
NameError: name 'c' is not defined
10
20
注意
-
由于全局变量 c,是在调用函数之后,才定义的,在执行函数时,变量还没有定义,所以程序会报错!
4.全局变量命名的建议
-
为了避免局部变量和全局变量出现混淆,在定义全局变量时,有些公司会有一些开发要求,例如:
-
全局变量名前应该增加
g_或者gl_的前缀
提示:具体的要求格式,各公司要求可能会有些差异
15.函数进阶
-
函数参数和返回值的作用
-
函数的返回值 进阶
-
函数的参数 进阶
-
递归函数
(1)函数参数和返回值的作用
函数根据 有没有参数 以及 有没有返回值,可以 相互组合,一共有 4 种 组合形式
-
无参数,无返回值
-
无参数,有返回值
-
有参数,无返回值
-
有参数,有返回值
定义函数时,是否接收参数,或者是否返回结果,是根据 实际的功能需求 来决定的!
-
如果函数 内部处理的数据不确定,就可以将外界的数据以参数传递到函数内部
-
如果希望一个函数 执行完成后,向外界汇报执行结果,就可以增加函数的返回值
1)无参数,无返回值
此类函数,不接收参数,也没有返回值,应用场景如下:
-
只是单纯地做一件事情,例如 显示菜单
-
在函数内部 针对全局变量进行操作,例如:新建名片,最终结果 记录在全局变量 中
注意:
-
如果全局变量的数据类型是一个 可变类型,在函数内部可以使用 方法 修改全局变量的内容 —— 变量的引用不会改变
-
在函数内部,使用赋值语句 才会 修改变量的引用
2)无参数,有返回值
此类函数,不接收参数,但是有返回值,应用场景如下:
-
采集数据,例如 温度计,返回结果就是当前的温度,而不需要传递任何的参数
3)有参数,无返回值
此类函数,接收参数,没有返回值,应用场景如下:
-
函数内部的代码保持不变,针对 不同的参数 处理 不同的数据
-
例如 名片管理系统 针对 找到的名片 做 修改、删除 操作
4)有参数,有返回值
此类函数,接收参数,同时有返回值,应用场景如下:
-
函数内部的代码保持不变,针对 不同的参数 处理 不同的数据,并且 返回期望的处理结果
-
例如 名片管理系统 使用 字典默认值 和 提示信息 提示用户输入内容
-
如果输入,返回输入内容
-
如果没有输入,返回字典默认值
-
(2)函数的返回值
-
在程序开发中,有时候,会希望 一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理
-
返回值 是函数 完成工作后,最后 给调用者的 一个结果
-
在函数中使用
return关键字可以返回结果 -
调用函数一方,可以 使用变量 来 接收 函数的返回结果
问题:一个函数执行后能否返回多个结果?
示例 —— 温度和湿度测量
-
假设要开发一个函数能够同时返回当前的温度和湿度
-
先完成返回温度的功能如下:
def measure():
"""返回当前的温度"""
print("开始测量...")
temp = 39
print("测量结束...")
return temp
result = measure()
print(result)
开始测量... 测量结束... 39
-
在利用 元组 在返回温度的同时,也能够返回 湿度
-
改造如下:
def measure():
"""返回当前的温度"""
print("开始测量...")
temp = 39
wetness = 10
print("测量结束...")
# 如果函数返回的类型是元组,小括号可以省略
# return (temp, wetness)
return temp, wetness
# 如果函数返回的类型是元组,同时希望单独处理元组中的元素
# 可以使用多个变量,一次接收函数的返回结果
# 注意:使用多个变量接受结果时,变量的个数应该和元素中的个数保持一致
gl_temp, gl_wetness = measure()
print(gl_temp)
print(gl_wetness)
开始测量... 测量结束... 39 10
提示:如果一个函数返回的是元组,括号可以省略
技巧
-
在
Python中,可以 将一个元组 使用 赋值语句 同时赋值给 多个变量 -
注意:变量的数量需要和元组中的元素数量保持一致
result = temp, wetness = measure()
面试题 —— 交换两个数字
题目要求
-
有两个整数变量
a = 6,b = 100 -
不使用其他变量,交换两个变量的值
解法 1 —— 使用其他变量
# 解法 1 - 使用临时变量 c = b b = a a = c
解法 2 —— 不使用临时变量
# 解法 2 - 不使用临时变量 a = a + b b = a - b a = a - b
解法 3 —— Python 专有,利用元组
a, b = b, a
(3)函数的参数 进阶
1)不可变和可变的参数
问题 1:在函数内部,针对参数使用 赋值语句,会不会影响调用函数时传递的 实参变量? —— 不会!
-
无论传递的参数是 可变 还是 不可变
-
只要 针对参数 使用 赋值语句,会在 函数内部 修改 局部变量的引用,不会影响到 外部变量的引用
-
def demo(num, num_list):
print("函数内部")
# 赋值语句
num = 200
num_list = [1, 2, 3]
print(num)
print(num_list)
print("函数代码完成")
gl_num = 99
gl_list = [4, 5, 6]
demo(gl_num, gl_list)
print(gl_num)
print(gl_list)
函数内部 200 [1, 2, 3] 函数代码完成 99 [4, 5, 6]
问题 2:如果传递的参数是 可变类型,在函数内部,使用 方法 修改了数据的内容,同样会影响到外部的数据
def mutable(num_list):
print("函数内部代码")
num_list.append(9)
print(num_list)
print("函数执行完成")
gl_list = [1, 2, 3]
mutable(gl_list)
print(gl_list)
函数内部代码 [1, 2, 3, 9] 函数执行完成 [1, 2, 3, 9]
def mutable(num_list):
# num_list = [1, 2, 3]
num_list.extend([1, 2, 3])
print(num_list)
gl_list = [6, 7, 8]
mutable(gl_list)
print(gl_list)
[6, 7, 8, 1, 2, 3] [6, 7, 8, 1, 2, 3]
面试题 —— +=
-
在
python中,列表变量调用+=本质上是在执行列表变量的extend方法,不会修改变量的引用
def demo(num, num_list):
print("函数内部代码")
# num = num + num
num += num
# num_list.extend(num_list) 由于是调用方法,所以不会修改变量的引用
# 函数执行结束后,外部数据同样会发生变化
num_list += num_list
print(num)
print(num_list)
print("函数代码完成")
gl_num = 9
gl_list = [1, 2, 3]
demo(gl_num, gl_list)
print(gl_num)
print(gl_list)
2)缺省参数
-
定义函数时,可以给 某个参数 指定一个默认值,具有默认值的参数就叫做 缺省参数
-
调用函数时,如果没有传入 缺省参数 的值,则在函数内部使用定义函数时指定的 参数默认值
-
函数的缺省参数,将常见的值设置为参数的缺省值,从而 简化函数的调用
-
例如:对列表排序的方法
gl_num_list = [6, 3, 9] # 默认就是升序排序,因为这种应用需求更多 gl_num_list.sort() print(gl_num_list) # 只有当需要降序排序时,才需要传递 `reverse` 参数 gl_num_list.sort(reverse=True) print(gl_num_list)
指定函数的缺省参数
-
在参数后使用赋值语句,可以指定参数的缺省值
def print_info(name, gender=True):
gender_text = "男生"
if not gender:
gender_text = "女生"
print("%s 是 %s" % (name, gender_text))
提示
-
缺省参数,需要使用 最常见的值 作为默认值!
-
如果一个参数的值 不能确定,则不应该设置默认值,具体的数值在调用函数时,由外界传递!
缺省参数的注意事项:
1. 缺省参数的定义位置
-
必须保证 带有默认值的缺省参数 在参数列表末尾
-
所以,以下定义是错误的!
def print_info(name, gender=True, title):
2.调用带有多个缺省参数的函数
-
在 调用函数时,如果有 多个缺省参数,需要指定参数名,这样解释器才能够知道参数的对应关系!
def print_info(name, title="", gender=True):
"""
:param title: 职位
:param name: 班上同学的姓名
:param gender: True 男生 False 女生
"""
gender_text = "男生"
if not gender:
gender_text = "女生"
print("%s%s 是 %s" % (title, name, gender_text))
# 提示:在指定缺省参数的默认值时,应该使用最常见的值作为默认值!
print_info("小明")
print_info("老王", title="班长")
print_info("小美", gender=False)
小明 是 男生 班长老王 是 男生 小美 是 女生
3)多值参数(知道)
1.定义支持多值参数的函数
-
有时可能需要 一个函数 能够处理的参数 个数 是不确定的,这个时候,就可以使用 多值参数
-
python中有 两种 多值参数:-
参数名前增加 一个
*可以接收 元组 -
参数名前增加 两个
*可以接收 字典
-
-
一般在给多值参数命名时,习惯使用以下两个名字
-
*args—— 存放 元组 参数,前面有一个* -
**kwargs—— 存放 字典 参数,前面有两个*
-
-
args是arguments的缩写,有变量的含义 -
kw是keyword的缩写,kwargs可以记忆 键值对参数
def demo(num, *args, **kwargs):
print(num)
print(args)
print(kwargs)
demo(1, 2, 3, 4, 5, name="小明", age=18, gender=True)
1
(2, 3, 4, 5)
{'name': '小明', 'age': 18, 'gender': True}
提示:多值参数 的应用会经常出现在网络上一些大牛开发的框架中,知道多值参数,有利于我们能够读懂大牛的代码
2.多值参数案例 —— 计算任意多个数字的和
需求
-
定义一个函数
sum_numbers,可以接收的 任意多个整数 -
功能要求:将传递的 所有数字累加 并且返回累加结果
def sum_numbers(*args):
num = 0
# 遍历 args 元组顺序求和
for n in args:
num += n
return num
print(sum_numbers(1, 2, 3))
3.元组和字典的拆包(知道)
-
在调用带有多值参数的函数时,如果希望:
-
将一个 元组变量,直接传递给
args -
将一个 字典变量,直接传递给
kwargs
-
-
就可以使用 拆包,简化参数的传递,拆包 的方式是:
-
在 元组变量前,增加 一个
* -
在 字典变量前,增加 两个
*
-
如果不进行拆包:
def demo(*args, **kwargs):
print(args)
print(kwargs)
# 需要将一个元组变量/字典变量传递给函数对应的参数
gl_nums = (1, 2, 3)
gl_xiaoming = {"name": "小明", "age": 18}
# 会把 num_tuple 和 xiaoming 作为元组传递个 args
# demo(gl_nums, gl_xiaoming)
demo(gl_nums, gl_xiaoming)
((1, 2, 3), {'name': '小明', 'age': 18})
{}
进行拆包:
def demo(*args, **kwargs):
print(args)
print(kwargs)
# 需要将一个元组变量/字典变量传递给函数对应的参数
gl_nums = (1, 2, 3)
gl_xiaoming = {"name": "小明", "age": 18}
# 会把 num_tuple 和 xiaoming 作为元组传递个 args
# demo(gl_nums, gl_xiaoming)
demo(*gl_nums, **gl_xiaoming)
(1, 2, 3)
{'name': '小明', 'age': 18}
(4)函数的递归
函数调用自身的 编程技巧 称为递归
1)递归函数的特点
特点
-
一个函数 内部 调用自己
-
函数内部可以调用其他函数,当然在函数内部也可以调用自己
-
代码特点
-
函数内部的 代码 是相同的,只是针对 参数 不同,处理的结果不同
-
当 参数满足一个条件 时,函数不再执行
-
这个非常重要,通常被称为递归的出口,否则 会出现死循环!
-
示例代码
def sum_numbers(num):
print(num)
# 递归的出口很重要,否则会出现死循环
if num == 1:
return
sum_numbers(num - 1)
sum_numbers(3)
3 2 1
2)递归案例 —— 计算数字累加
需求
-
定义一个函数
sum_numbers -
能够接收一个
num的整数参数 -
计算 1 + 2 + ... num 的结果
def sum_numbers(num):
if num == 1:
return 1
# 假设 sum_numbers 能够完成 num - 1 的累加
temp = sum_numbers(num - 1)
# 函数内部的核心算法就是 两个数字的相加
return num + temp
print(sum_numbers(100))
5050
提示:递归是一个 编程技巧,初次接触递归会感觉有些吃力!在处理 不确定的循环条件时,格外的有用,例如:遍历整个文件目录的结构
五.面向对象
1.基本概念
面向对象编程 —— Object Oriented Programming 简写 OOP
-
我们之前学习的编程方式就是 面向过程 的
-
面相过程 和 面相对象,是两种不同的 编程方式
-
对比 面向过程 的特点,可以更好地了解什么是 面向对象

1)过程和函数(科普)
-
过程 是早期的一个编程概念
-
过程 类似于函数,只能执行,但是没有返回值
-
函数 不仅能执行,还可以返回结果
2)面相过程 和 面相对象 基本概念
1.面相过程 —— 怎么做?
-
把完成某一个需求的
所有步骤从头到尾逐步实现 -
根据开发需求,将某些 功能独立 的代码 封装 成一个又一个 函数
-
最后完成的代码,就是顺序地调用 不同的函数
特点
-
注重 步骤与过程,不注重职责分工
-
如果需求复杂,代码会变得很复杂
-
开发复杂项目,没有固定的套路,开发难度很大!
2.面向对象 —— 谁来做?
相比较函数,面向对象 是 更大 的 封装,根据 职责 在 一个对象中 封装 多个方法
-
在完成某一个需求前,首先确定 职责 —— 要做的事情(方法)
-
根据 职责 确定不同的 对象,在 对象 内部封装不同的 方法(多个)
-
最后完成的代码,就是顺序地让 不同的对象 调用 不同的方法
特点
-
注重 对象和职责,不同的对象承担不同的职责
-
更加适合应对复杂的需求变化,是专门应对复杂项目开发,提供的固定套路
-
需要在面向过程基础上,再学习一些面向对象的语法

2.类和对象
-
类和对象的概念
-
类和对象的关系
-
类的设计
(1)类和对象的概念
类 和 对象 是 面向对象编程的 两个 核心概念
1.类
-
类 是对一群具有 相同 特征 或者 行为 的事物的一个统称,是抽象的,不能直接使用
-
特征 被称为 属性
-
行为 被称为 方法
-
-
类 就相当于制造飞机时的图纸,是一个 模板,是 负责创建对象的
2.对象
-
对象 是 由类创建出来的一个具体存在,可以直接使用
-
由 哪一个类 创建出来的 对象,就拥有在 哪一个类 中定义的:
-
属性
-
方法
-
-
对象 就相当于用 图纸 制造 的飞机
在程序开发中,应该 先有类,再有对象
(2)类和对象的关系
-
类是模板,对象 是根据 类 这个模板创建出来的,应该 先有类,再有对象
-
类 只有一个,而 对象 可以有很多个
-
不同的对象 之间 属性 可能会各不相同
-
-
类 中定义了什么 属性和方法,对象 中就有什么属性和方法,不可能多,也不可能少
(3)类的设计
在使用面相对象开发前,应该首先分析需求,确定一下,程序中需要包含哪些类!
在程序开发中,要设计一个类,通常需要满足一下三个要素:
-
类名 这类事物的名字,满足大驼峰命名法
-
属性 这类事物具有什么样的特征
-
方法 这类事物具有什么样的行为
大驼峰命名法
CapWords
-
每一个单词的首字母大写
-
单词与单词之间没有下划线
1.类名的确定
名词提炼法 分析 整个业务流程,出现的 名词,通常就是找到的类
2.属性和方法的确定
-
对 对象的特征描述,通常可以定义成 属性
-
对象具有的行为(动词),通常可以定义成 方法
提示:需求中没有涉及的属性或者方法在设计类时,不需要考虑
练习 1
需求
-
小明 今年 18 岁,身高 1.75,每天早上 跑 完步,会去 吃 东西
-
小美 今年 17 岁,身高 1.65,小美不跑步,小美喜欢 吃 东西

练习 2
需求
-
一只 黄颜色 的 狗狗 叫 大黄
-
看见生人 汪汪叫
-
看见家人 摇尾巴

3.基础语法
-
dir内置函数 -
定义简单的类(只包含方法)
-
方法中的
self参数 -
初始化方法
-
内置方法和属性
(1)dir内置函数(知道)
-
在
Python中 对象几乎是无所不在的,我们之前学习的 变量、数据、函数 都是对象
在 Python 中可以使用以下两个方法验证:
-
在 标识符 / 数据 后输入一个
.,然后按下TAB键,iPython会提示该对象能够调用的 方法列表 -
使用内置函数
dir传入 标识符 / 数据,可以查看对象内的 所有属性及方法
提示 __方法名__ 格式的方法是 Python 提供的 内置方法 / 属性,稍后会给大家介绍一些常用的 内置方法 / 属性
| 序号 | 方法名 | 类型 | 作用 |
|---|---|---|---|
| 01 | __new__ | 方法 | 创建对象时,会被 自动 调用 |
| 02 | __init__ | 方法 | 对象被初始化时,会被 自动 调用 |
| 03 | __del__ | 方法 | 对象被从内存中销毁前,会被 自动 调用 |
| 04 | __str__ | 方法 | 返回对象的描述信息,print 函数输出使用 |
提示 利用好 dir() 函数,在学习时很多内容就不需要死记硬背了
(2)定义简单的类
面向对象 是 更大 的 封装,在 一个类中 封装 多个方法,这样 通过这个类创建出来的对象,就可以直接调用这些方法了!
1.定义只包含方法的类
-
在
Python中要定义一个只包含方法的类,语法格式如下:
class 类名:
def 方法1(self, 参数列表):
pass
def 方法2(self, 参数列表):
pass
-
方法 的定义格式和之前学习过的函数 几乎一样
-
区别在于第一个参数必须是
self,大家暂时先记住,稍后介绍self
注意:类名 的 命名规则 要符合 大驼峰命名法
2.创建对象
-
当一个类定义完成之后,要使用这个类来创建对象,语法格式如下:
对象变量 = 类名()
3.第一个面向对象程序
需求
-
小猫 爱 吃 鱼,小猫 要 喝 水
分析
-
定义一个猫类
Cat -
定义两个方法
eat和drink -
按照需求 —— 不需要定义属性
class Cat:
"""这是一个猫类"""
def eat(self):
print("小猫爱吃鱼")
def drink(self):
print("小猫在喝水")
tom = Cat()
tom.drink()
tom.eat()
小猫爱吃鱼 小猫要喝水
引用概念的强调
在面向对象开发中,引用的概念是同样适用的!
-
在
Python中使用类 创建对象之后,tom变量中 仍然记录的是 对象在内存中的地址 -
也就是
tom变量 引用 了 新建的猫对象 -
使用
print输出 对象变量,默认情况下,是能够输出这个变量 引用的对象 是 由哪一个类创建的对象,以及 在内存中的地址(十六进制表示)
提示:在计算机中,通常使用 十六进制 表示 内存地址
十进制 和 十六进制 都是用来表达数字的,只是表示的方式不一样
十进制 和 十六进制 的数字之间可以来回转换
-
%d可以以 10 进制 输出数字 -
%x可以以 16 进制 输出数字
案例进阶
使用 Cat 类再创建一个对象
class Cat:
def eat(self):
print("小猫爱吃鱼")
def drink(self):
print("小猫要喝水")
# 创建一个猫对象
tom = Cat()
tom.eat()
tom.drink()
# 再创建一个猫对象
lazy_cat = Cat()
lazy_cat.eat()
lazy_cat.drink()
print(tom)
print(lazy_cat)
提问:
tom和lazy_cat是同一个对象吗?
小猫爱吃鱼 小猫要喝水 小猫爱吃鱼 小猫要喝水 <__main__.Cat object at 0x0000015B34C77FD0> <__main__.Cat object at 0x0000015B34C77FA0>
通过结果可以观察出两个对象的内存地址不一样
故tom 和 lazy_cat 不是同一个对象
(3)方法中的self参数
1.案例改造 —给对象增加属性
-
在
Python中,要 给对象设置属性,非常的容易,但是不推荐使用-
因为:对象属性的封装应该封装在类的内部
-
-
只需要在 类的外部的代码 中直接通过
.设置一个属性即可
注意:这种方式虽然简单,但是不推荐使用!
class Cat:
def eat(self):
print("小猫爱吃鱼")
def drink(self):
print("小猫要喝水")
# 创建一个猫对象
tom = Cat()
tom.name = "Tom"
tom.eat()
tom.drink()
# 再创建一个猫对象
lazy_cat = Cat()
lazy_cat.name = "大懒猫"
lazy_cat.eat()
lazy_cat.drink()
print(tom)
print(lazy_cat)
2.使用self在方法内部输出每一只猫的名字
由 哪一个对象 调用的方法,方法内的
self就是 哪一个对象的引用
-
在类封装的方法内部,
self就表示 当前调用方法的对象自己 -
调用方法时,程序员不需要传递
self参数 -
在方法内部
-
可以通过
self.访问对象的属性 -
也可以通过
self.调用其他的对象方法
-
-
改造代码如下:
class Cat:
def eat(self):
print("%s 爱吃鱼" % self.name)
tom = Cat()
tom.name = "Tom"
tom.eat()
lazy_cat = Cat()
lazy_cat.name = "大懒猫"
lazy_cat.eat()
Tom 爱吃鱼 大懒猫 爱吃鱼
-
在 类的外部,通过
变量名.访问对象的 属性和方法 -
在 类封装的方法中,通过
self.访问对象的 属性和方法
(4)初始化方法
1. 在类的外部给对象增加属性
-
将案例代码进行调整,先调用方法 再设置属性,观察一下执行效果
class Cat:
def eat(self):
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 爱吃鱼" % self.name)
tom = Cat()
tom.drink()
tom.eat()
tom.name = "Tom"
-
程序执行报错如下:
AttributeError: 'Cat' object has no attribute 'name' 属性错误:'Cat' 对象没有 'name' 属性
提示
-
在日常开发中,不推荐在 类的外部 给对象增加属性
-
如果在运行时,没有找到属性,程序会报错
-
-
对象应该包含有哪些属性,应该 封装在类的内部
2.初始化方法
-
当使用
类名()创建对象时,会 自动 执行以下操作:-
为对象在内存中 分配空间 —— 创建对象
-
为对象的属性 设置初始值 —— 初始化方法(
init)
-
-
这个 初始化方法 就是
__init__方法,__init__是对象的内置方法
__init__方法是 专门 用来定义一个类 具有哪些属性的方法!
在 Cat 中增加 __init__ 方法,验证该方法在创建对象时会被自动调用
class Cat:
"""这是一个猫类"""
def __init__(self):
print("初始化方法")
3.初始化方法内部定义属性
-
在
__init__方法内部使用self.属性名 = 属性的初始值就可以 定义属性 -
定义属性之后,再使用
Cat类创建的对象,都会拥有该属性
class Cat:
def __init__(self):
print("这是一个初始化方法")
# 定义用 Cat 类创建的猫对象都有一个 name 的属性
self.name = "Tom"
def eat(self):
print("%s 爱吃鱼" % self.name)
# 使用类名()创建对象的时候,会自动调用初始化方法 __init__
tom = Cat()
tom.eat()
4.初始化的同时设置初始值
-
在开发中,如果希望在 创建对象的同时,就设置对象的属性,可以对
__init__方法进行 改造-
把希望设置的属性值,定义成
__init__方法的参数 -
在方法内部使用
self.属性 = 形参接收外部传递的参数 -
在创建对象时,使用
类名(属性1, 属性2...)调用
-
class Cat:
def __init__(self, name):
print("初始化方法 %s" % name)
self.name = name
def eat(self):
print("%s 爱吃鱼" % self.name)
tom = Cat("Tom")
tom.eat()
lazy_cat = Cat("大懒猫")
lazy_cat.eat()
初始化方法 Tom Tom 爱吃鱼 初始化方法 大懒猫 大懒猫 爱吃鱼
(5)内置方法和属性
| 序号 | 方法名 | 类型 | 作用 |
|---|---|---|---|
| 01 | __del__ | 方法 | 对象被从内存中销毁前,会被 自动 调用 |
| 02 | __str__ | 方法 | 返回对象的描述信息,print 函数输出使用 |
1. __del__ 方法(知道)
-
在
Python中-
当使用
类名()创建对象时,为对象 分配完空间后,自动 调用__init__方法 -
当一个 对象被从内存中销毁 前,会 自动 调用
__del__方法
-
-
应用场景
-
__init__改造初始化方法,可以让创建对象更加灵活 -
__del__如果希望在对象被销毁前,再做一些事情,可以考虑一下__del__方法
-
-
生命周期
-
一个对象从调用
类名()创建,生命周期开始 -
一个对象的
__del__方法一旦被调用,生命周期结束 -
在对象的生命周期内,可以访问对象属性,或者让对象调用方法
-
class Cat:
def __init__(self, new_name):
self.name = new_name
print("%s 来了" % self.name)
def __del__(self):
print("%s 去了" % self.name)
# tom 是一个全局变量
tom = Cat("Tom")
print(tom.name)
# del 关键字可以删除一个对象
del tom
print("-" * 50)
Tom 来了 Tom Tom 去了 --------------------------------------------------
2.__str__ 方法
-
在
Python中,使用print输出 对象变量,默认情况下,会输出这个变量 引用的对象 是 由哪一个类创建的对象,以及 在内存中的地址(十六进制表示) -
如果在开发中,希望使用
print输出 对象变量 时,能够打印 自定义的内容,就可以利用__str__这个内置方法了
注意:
__str__方法必须返回一个字符串
class Cat:
def __init__(self, new_name):
self.name = new_name
print("%s 来了" % self.name)
def __del__(self):
print("%s 去了" % self.name)
def __str__(self):
return "我是小猫:%s" % self.name
tom = Cat("Tom")
print(tom)
Tom 来了 我是小猫:Tom Tom 去了
(6)封装案例
-
封装
-
小明爱跑步
-
存放家具
1.封装
-
封装 是面向对象编程的一大特点
-
面向对象编程的 第一步 —— 将 属性 和 方法 封装 到一个抽象的 类 中
-
外界 使用 类 创建 对象,然后 让对象调用方法
-
对象方法的细节 都被 封装 在 类的内部
2.小明爱跑步
需求
-
小明 体重
75.0公斤 -
小明每次 跑步 会减肥
0.5公斤 -
小明每次 吃东西 体重增加
1公斤

提示:在 对象的方法内部,是可以 直接访问对象的属性 的!
-
代码实现:
class Person:
def __init__(self, name, weight):
self.name = name
self.weight = weight
def __str__(self):
return "我的名字是 %s 体重是 %.2f公斤" % (self.name, self.weight)
def run(self):
print("%s 爱跑步,跑步锻炼身体" % self.name)
self.weight -= 0.5
def eat(self):
print("%s 爱吃零食,吃饱了再减肥" % self.name)
self.weight += 1
xiaoming = Person("小明", 61.6)
xiaoming.run()
xiaoming.eat()
xiaoming.eat()
print(xiaoming.weight)
扩展
需求
-
小明 和 小美 都爱跑步
-
小明 体重
75.0公斤 -
小美 体重
45.0公斤 -
每次 跑步 都会减少
0.5公斤 -
每次 吃东西 都会增加
1公斤
提示
-
在 对象的方法内部,是可以 直接访问对象的属性 的
-
同一个类 创建的 多个对象 之间,属性 互不干扰!
class Person:
def __init__(self, name, weight):
self.name = name
self.weight = weight
def __str__(self):
return "我的名字是 %s 体重是 %.2f公斤" % (self.name, self.weight)
def run(self):
print("%s 爱跑步,跑步锻炼身体" % self.name)
self.weight -= 0.5
def eat(self):
print("%s 爱吃零食,吃饱了再减肥" % self.name)
self.weight += 1
xiaoming = Person("小明", 75.0)
xiaoming.run()
xiaoming.eat()
xiaoming.eat()
print(xiaoming.weight)
xiaomei = Person("小美", 45.0)
xiaomei.run()
xiaomei.eat()
xiaomei.eat()
print(xiaomei.weight)
3.摆放家具
需求
-
房子(House) 有 户型、总面积 和 家具名称列表
-
新房子没有任何的家具
-
-
家具(HouseItem) 有 名字 和 占地面积,其中
-
席梦思(bed) 占地
4平米 -
衣柜(chest) 占地
2平米 -
餐桌(table) 占地
1.5平米
-
-
将以上三件 家具 添加 到 房子 中
-
打印房子时,要求输出:户型、总面积、剩余面积、家具名称列表
剩余面积
-
在创建房子对象时,定义一个 剩余面积的属性,初始值和总面积相等
-
当调用
add_item方法,向房间 添加家具 时,让 剩余面积 -= 家具面积
class HouseItem:
def __init__(self, name, area):
self.name = name
self.area = area
def __str__(self):
return "【%s】,占用 %.2f 平方米" % (self.name, self.area)
class House:
def __init__(self, house_type, area):
self.house_type = house_type
self.area = area
# 剩余面积
self.free_area = area
# 家具名称列表
self.item_list = []
def __str__(self):
return "户型:%s\n总面积:%.2f【剩余:%.2f】\n家具:%s" % (self.house_type, self.area, self.free_area, self.item_list)
def add_item(self, item):
print("要添加 %s" % item)
# 1. 判断家具面积是否大于剩余面积
if item.area > self.free_area:
print("%s 的面积太大,不能添加到房子中" % item.name)
return
# 2. 将家具的名称追加到名称列表中
self.item_list.append(item.name)
# 3. 计算剩余面积
self.free_area -= item.area
bed = HouseItem("席梦思", 4)
cheat = HouseItem("衣柜", 2)
table = HouseItem("餐桌", 1.5)
print(bed)
print(cheat)
print(table)
my_house = House("两室一厅", 60)
my_house.add_item(bed)
my_house.add_item(cheat)
my_house.add_item(table)
print(my_house)
小结
-
主程序只负责创建 房子 对象和 家具 对象
-
让 房子 对象调用
add_item方法 将家具添加到房子中 -
面积计算、剩余面积、家具列表 等处理都被 封装 到 房子类的内部
4.士兵突击
需求
-
士兵 许三多 有一把 AK47
-
士兵 可以 开火
-
枪 能够 发射 子弹
-
枪 装填 装填子弹 —— 增加子弹数量
-
创建了一个 士兵类,使用到
__init__内置方法 -
在定义属性时,如果 不知道设置什么初始值,可以设置为
None -
在 封装的 方法内部,还可以让 自己的 使用其他类创建的对象属性 调用已经 封装好的方法
class Gun: def __init__(self, model, count): self.model = model self.bullet_count = 0 def add_bullet(self, count): if self.bullet_count == 0: self.bullet_count = self.bullet_count + count def shoot(self): # 1.判断子弹数量 if self.bullet_count <= 0: print("[%s]没有子弹了..." % self.model) return # 2.发射子弹,-1 self.bullet_count = self.bullet_count - 1 print("[%s]突突突...[%d]" % (self.model, self.bullet_count)) class Soldier: def __init__(self, name): # 1.姓名 self.name = name # 2.枪-新兵没有枪 self.gun = None def fire(self): # 1.判断士兵是否有枪 if self.gun is None: print("[%s]还没有枪" % self.name) return # 2.高喊口号 print("冲啊...[%s]" % self.name) # 3.让枪装填子弹 self.gun.add_bullet(50) # 4.让枪发射子弹 self.gun.shoot() # 1.创建枪对象 ak47 = Gun("AK47", 0) # 2.创建许三多 xusanduo = Soldier("许三多") print(xusanduo.gun) # 给哥们发枪 xusanduo.gun = ak47 # 让士兵开火 xusanduo.fire() xusanduo.fire() xusanduo.fire()
4.私有属性和私有方法
(1)应用场景
-
在实际开发中,对象 的 某些属性或方法 可能只希望 在对象的内部被使用,而 不希望在外部被访问到
-
私有属性 就是 对象 不希望公开的 属性
-
私有方法 就是 对象 不希望公开的 方法
(2)定义方式
-
在 定义属性或方法时,在 属性名或者方法名前 增加 两个下划线,定义的就是 私有 属性或方法
class Women:
def __init__(self, name):
self.name = name
# 不要问女生的年龄
self.__age = 18
def __secret(self):
# 在对象的方法内部是可以访问对象的私有属性的
print("我的年龄是 %d" % self.__age)
xiaofang = Women("小芳")
# 私有属性,外部不能直接访问
# print(xiaofang.__age)
# 私有方法,外部不能直接调用
# xiaofang.__secret()
(3)伪私有属性和私有方法
提示:在日常开发中,不要使用这种方式,访问对象的 私有属性 或 私有方法
Python 中,并没有 真正意义 的 私有
-
在给 属性、方法 命名时,实际是对 名称 做了一些特殊处理,使得外界无法访问到
-
处理方式:在 名称 前面加上
_类名=>_类名__名称
class Women:
def __init__(self, name):
self.name = name
# 不要问女生的年龄
self.__age = 18
def __secret(self):
# 在对象的方法内部是可以访问对象的私有属性的
print("我的年龄是 %d" % self.__age)
xiaofang = Women("小芳")
# 私有属性,外部不能直接访问到
print(xiaofang._Women__age)
# 私有方法,外部不能直接调用
xiaofang._Women__secret()
18 我的年龄是 18
5.继承
面向对象三大特性
-
封装 根据 职责 将 属性 和 方法 封装 到一个抽象的 类 中
-
继承 实现代码的重用,相同的代码不需要重复的编写
-
多态 不同的对象调用相同的方法,产生不同的执行结果,增加代码的灵活度
(1)单继承
1.概念、语法和特点
继承的概念:子类 拥有 父类 的所有 方法 和 属性
1) 继承的语法
class 类名(父类名):
pass
-
子类 继承自 父类,可以直接 享受 父类中已经封装好的方法,不需要再次开发
-
子类 中应该根据 职责,封装 子类特有的 属性和方法
2) 专业术语
-
Dog类是Animal类的子类,Animal类是Dog类的父类,Dog类从Animal类继承 -
Dog类是Animal类的派生类,Animal类是Dog类的基类,Dog类从Animal类派生
3) 继承的传递性
-
C类从B类继承,B类又从A类继承 -
那么
C类就具有B类和A类的所有属性和方法
子类 拥有 父类 以及 父类的父类 中封装的所有 属性 和 方法
提问
哮天犬 能够调用 Cat 类中定义的 catch 方法吗?
答案
不能,因为 哮天犬 和 Cat 之间没有 继承 关系
2.方法的重写
-
子类 拥有 父类 的所有 方法 和 属性
-
子类 继承自 父类,可以直接 享受 父类中已经封装好的方法,不需要再次开发
应用场景
-
当 父类 的方法实现不能满足子类需求时,可以对方法进行 重写(override)
重写 父类方法有两种情况:
-
覆盖 父类的方法
-
对父类方法进行 扩展
1) 覆盖父类的方法
-
如果在开发中,父类的方法实现 和 子类的方法实现,完全不同
-
就可以使用 覆盖 的方式,在子类中 重新编写 父类的方法实现
具体的实现方式,就相当于在 子类中 定义了一个 和父类同名的方法并且实现
重写之后,在运行时,只会调用 子类中重写的方法,而不再会调用 父类封装的方法
2) 对父类方法进行 扩展
-
如果在开发中,子类的方法实现 中 包含 父类的方法实现
-
父类原本封装的方法实现 是 子类方法的一部分
-
-
就可以使用 扩展 的方式
-
在子类中 重写 父类的方法
-
在需要的位置使用
super().父类方法来调用父类方法的执行 -
代码其他的位置针对子类的需求,编写 子类特有的代码实现
-
关于 super
-
在
Python中super是一个 特殊的类 -
super()就是使用super类创建出来的对象 -
最常 使用的场景就是在 重写父类方法时,调用 在父类中封装的方法实现
调用父类方法的另外一种方式(知道)
在
Python 2.x时,如果需要调用父类的方法,还可以使用以下方式:
父类名.方法(self)
-
这种方式,目前在
Python 3.x还支持这种方式 -
这种方法 不推荐使用,因为一旦 父类发生变化,方法调用位置的 类名 同样需要修改
提示
-
在开发时,
父类名和super()两种方式不要混用 -
如果使用 当前子类名 调用方法,会形成递归调用,出现死循环
3.父类的 私有属性 和 私有方法
-
子类对象 不能 在自己的方法内部,直接 访问 父类的 私有属性 或 私有方法
-
子类对象 可以通过 父类 的 公有方法 间接 访问到 私有属性 或 私有方法
私有属性、方法 是对象的隐私,不对外公开,外界 以及 子类 都不能直接访问
私有属性、方法 通常用于做一些内部的事情
示例
class A:
def __init__(self):
self.num1 = 100
self.__num2 = 200
def __test(self):
print("私有方法 %d %d" % (self.num1, self.__num2))
class B(A):
def demo(self):
# 1.访问父类的私有属性
# print("访问父类的私有属性 %d " % self.__num2)
# 2.调用父类的私有方法
# self.__test()
b = B()
print(b)
-
B的对象不能直接访问__num2属性 -
B的对象不能在demo方法内访问__num2属性 -
B的对象可以在demo方法内,调用父类的test方法 -
父类的
test方法内部,能够访问__num2属性和__test方法
class A:
def __init__(self):
self.num1 = 100
self.__num2 = 200
def __test(self):
print("私有方法 %d %d" % (self.num1, self.__num2))
def test(self):
print("公有方法")
print("父类的公有方法 %d" % self.__num2)
self.__test()
class B(A):
def demo(self):
# 1.访问父类的私有属性
# print("访问父类的私有属性 %d " % self.__num2)
# 2.调用父类的私有方法
# self.__test()
# 3.访问父类的公有属性
print("公有属性:%d" % self.num1)
# 4.调用父类的公有方法
self.test()
b = B()
print(b)
# 在外界访问父类的公有属性/调用公有方法
b.test()
print(b.num1)
b.demo()
a = A()
a.test()
(2)多继承
概念
-
子类 可以拥有 多个父类,并且具有 所有父类 的 属性 和 方法
-
例如:孩子 会继承自己 父亲 和 母亲 的 特性
-
语法
class 子类名(父类名1, 父类名2...)
pass
class A:
def test(self):
print("test")
class B:
def demo(self):
print("demo")
class C(A, B):
pass
c = C()
c.test()
c.demo()
test demo
1.注意事项
-
如果 不同的父类 中存在 同名的方法,子类对象 在调用方法时,会调用 哪一个父类中的方法呢?
提示:开发时,应该尽量避免这种容易产生混淆的情况! —— 如果 父类之间 存在 同名的属性或者方法,应该 尽量避免 使用多继承
class A:
def test(self):
print("A-test")
def demo(self):
print("A-demo")
class B:
def test(self):
print("B-test")
def demo(self):
print("B-demo")
class C(A, B):
pass
c = C()
c.test()
c.demo()
A-test A-demo
当调换顺序后:
class C(A, B):------->
class A:
def test(self):
print("A-test")
def demo(self):
print("A-demo")
class B:
def test(self):
print("B-test")
def demo(self):
print("B-demo")
class C(B, A):
pass
c = C()
c.test()
c.demo()
B-test B-demo
对于上述情况基于Python中的MRO
Python 中的 MRO —— 方法搜索顺序(知道)
-
Python中针对 类 提供了一个 内置属性__mro__可以查看 方法 搜索顺序 -
MRO 是
method resolution order,主要用于 在多继承时判断 方法、属性 的调用 路径
print(C.__mro__)
输出结果
(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>)
-
在搜索方法时,是按照
__mro__的输出结果 从左至右 的顺序查找的 -
如果在当前类中 找到方法,就直接执行,不再搜索
-
如果 没有找到,就查找下一个类 中是否有对应的方法,如果找到,就直接执行,不再搜索
-
如果找到最后一个类,还没有找到方法,程序报错
2.新式类与旧式(经典)类
object是Python为所有对象提供的 基类,提供有一些内置的属性和方法,可以使用dir函数查看
-
新式类:以
object为基类的类,推荐使用 -
经典类:不以
object为基类的类,不推荐使用 -
在
Python 3.x中定义类时,如果没有指定父类,会 默认使用object作为该类的 基类 ——Python 3.x中定义的类都是 新式类 -
在
Python 2.x中定义类时,如果没有指定父类,则不会以object作为 基类
新式类 和 经典类 在多继承时 —— 会影响到方法的搜索顺序
为了保证编写的代码能够同时在 Python 2.x 和 Python 3.x 运行! 今后在定义类时,如果没有父类,建议统一继承自 object
class 类名(object):
pass
6.多态
多态 不同的对象调用相同的方法,产生不同的执行结果,增加代码的灵活度
-
多态可以增加代码的灵活度
-
以继承和重写父类方法为前提
-
是调用方法的技巧,不会影响到类的设计
(1)案例演练
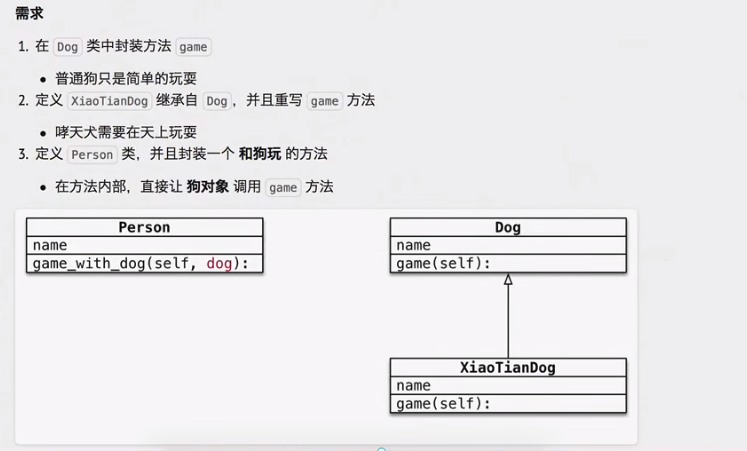
class Dog(object):
def __init__(self, name):
self.name = name
def game(self):
print("%s 蹦蹦跳跳的玩耍..." % self.name)
class XiaoTianDog(Dog):
def game(self):
print("%s飞到天上去玩耍..." % self.name)
class Person(object):
def __init__(self, name):
self.name = name
def game_with_dog(self, dog):
print("%s 和 %s 快乐的玩耍..." % (self.name, dog.name))
# 让狗玩耍
dog.game()
# 1.创建一个狗对象
# wangcai = Dog("旺财")
wangcai = XiaoTianDog("飞天旺财")
# 2.创建一个小明对象
xiaoming = Person("小明")
# 3.让小明调用和狗玩的方法
xiaoming.game_with_dog(wangcai)
(2)类的结构
1.术语-实例
-
使用面向对象开发,第一步是设计类
-
使用类名()c创建对象,创建对象的动作有两步:
one:在内存中为对象分配空间
two:调用初始化方法___init____为对象初始化
-
对象创建后,内存中就有了一个对象的实实在在的存在——实例
因此,也通常会把:
-
创建出来的对象叫做类的实例
-
创建对象的动作叫做实例
-
对象的属性叫做实例属性
-
对象调用的方法叫做实例方法
在程序执行时:
-
对象各自拥有自己的属性实例
-
调用对象方法,可以通过self
访问自己的属性
调用自己的方法
结论:
每一个对象都拥有自己独立的内存空间,保存各自不同的属性
多个对象的方法,在内存中只有一份,在调用方法时,需要把对象的引用传递到方法内部
2.类是特殊的对象

(3)类属性和实例属性
概念和使用:

class Tool(object):
# 使用赋值语句定义类属性,记录所有工具对象的数量
count = 0
def __init__(self, name):
self.name = name
# 让类属性的值+1
Tool.count += 1
# 1.创建工具对象
tool1 = Tool("斧头")
tool2 = Tool("榔头")
tool3 = Tool("水桶")
# 2.输出工具对象的总数
print(Tool.count)
3
属性获取机制:
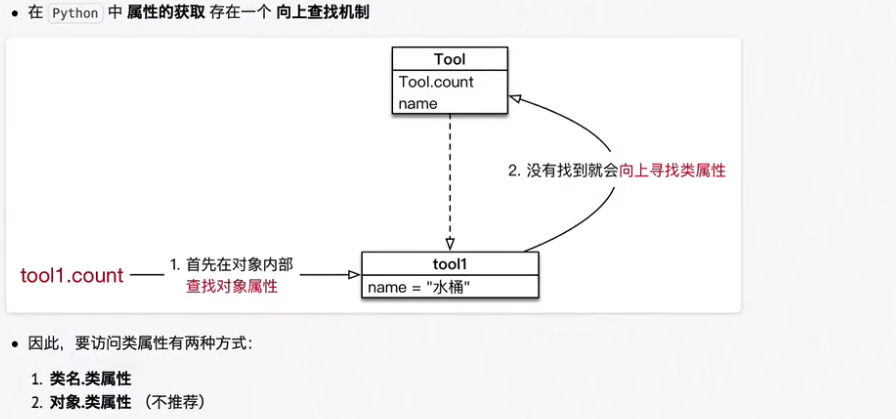

(4)类方法和静态方法
1.类方法
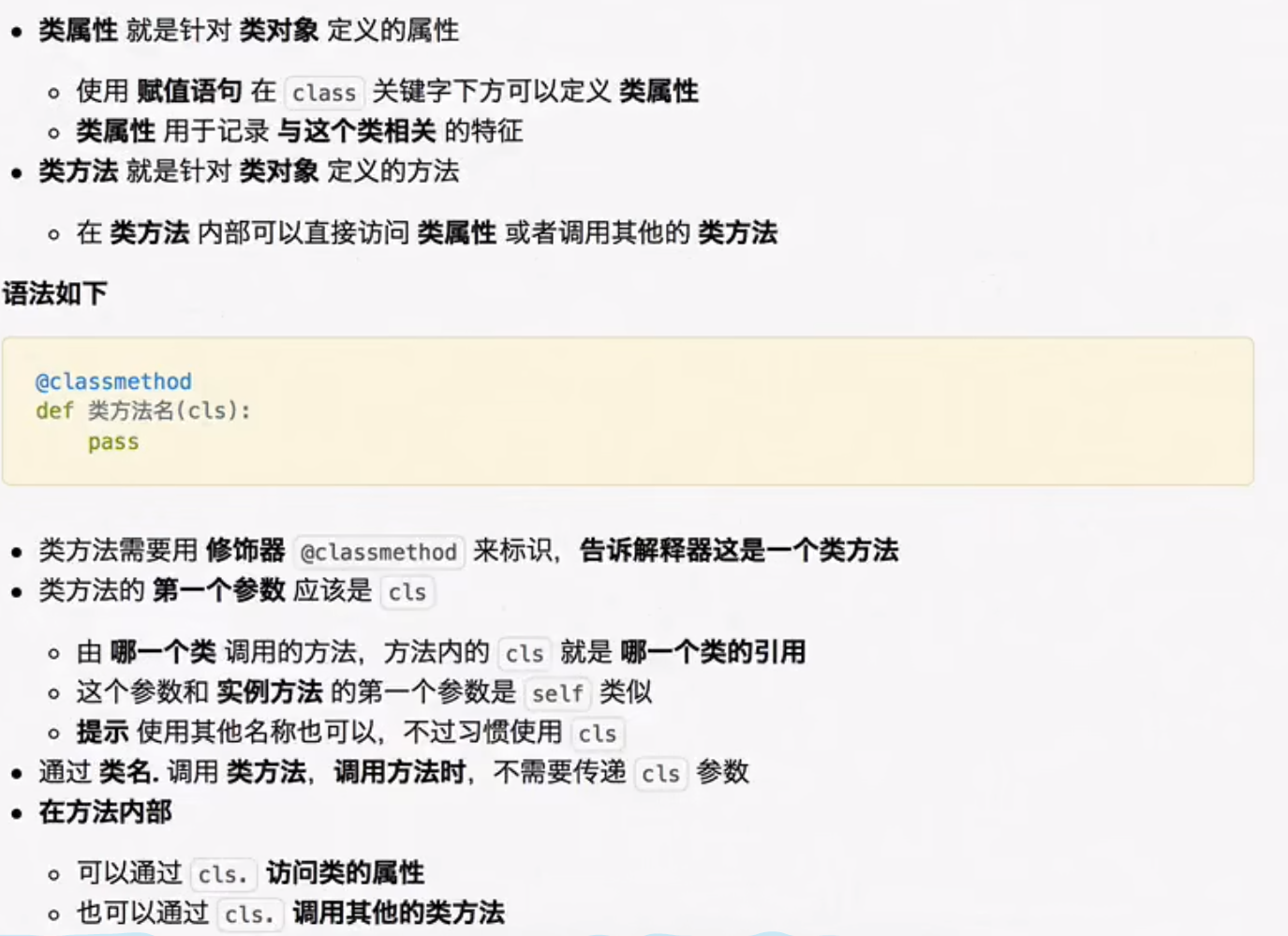
实例需求:

@classmethod
def show_tool_count(cls):
"""显示工具对象的总数"""
print("工具对象的总数 %d " % cls.count)
class Tool(object):
# 使用赋值语句定义类属性,记录所有工具对象的数量
count = 0
@classmethod
def show_tool_count(cls):
print("工具对象的数量 %d " % cls.count)
def __init__(self, name):
self.name = name
# 让类属性的值+1
Tool.count += 1
# 创建工具对象
tool1 = Tool("斧头")
tool2 = Tool("榔头")
# 调用类方法
Tool.show_tool_count()
2.静态方法

class Dog(object):
@staticmethod
def run():
# 不访问实例属性/类属性
print("小狗要跑...")
# 通过类名,调用静态方法 - 不需要创建对象
Dog.run()
小狗要跑...
(5)方法综合案例

class Game(object):
# 历史最高分
top_score = 0
def __init__(self, player_name):
self.player_name = player_name
@staticmethod
def show_help():
print("帮助信息:让僵尸进入大门")
@classmethod
def show_top_score(cls):
print("历史记录 %d " % cls.top_score)
def start_game(self):
print("%s 开始游戏啦..." % self.player_name)
# 1.查看游戏的帮助信息
Game.show_help()
# 2.查看历史最高分
Game.show_top_score()
# 3.创建游戏对象
player = Game("小明")
player.start_game()

六.单例
1.单例设计模式
-
设计模式
-
设计模式 是 前人工作的总结和提炼,通常,被人们广泛流传的设计模式都是针对 某一特定问题 的成熟的解决方案
-
使用 设计模式 是为了可重用代码、让代码更容易被他人理解、保证代码可靠性
-
-
单例设计模式
-
目的 —— 让 类 创建的对象,在系统中 只有 唯一的一个实例
-
每一次执行
类名()返回的对象,内存地址是相同的
-
单例设计模式的应用场景:
-
音乐播放 对象
-
回收站 对象
-
打印机 对象
-
……
2.__new__ 方法
-
使用 类名() 创建对象时,
Python的解释器 首先 会 调用__new__方法为对象 分配空间 -
__new__是一个 由object基类提供的 内置的静态方法,主要作用有两个:-
1) 在内存中为对象 分配空间
-
2) 返回 对象的引用
-
-
Python的解释器获得对象的 引用 后,将引用作为 第一个参数,传递给__init__方法
重写
__new__方法 的代码非常固定!
-
重写
__new__方法 一定要return super().__new__(cls) -
否则 Python 的解释器 得不到 分配了空间的 对象引用,就不会调用对象的初始化方法
-
注意:
__new__是一个静态方法,在调用时需要 主动传递cls参数
示例代码
class MusicPlayer(object):
def __new__(cls, *args, **kwargs):
# 如果不返回任何结果,
return super().__new__(cls)
def __init__(self):
print("初始化音乐播放对象")
player = MusicPlayer()
print(player)
3.Python 中的单例
-
单例 —— 让 类 创建的对象,在系统中 只有 唯一的一个实例
-
定义一个 类属性,初始值是
None,用于记录 单例对象的引用 -
重写
__new__方法 -
如果 类属性
is None,调用父类方法分配空间,并在类属性中记录结果 -
返回 类属性 中记录的 对象引用
-
class MusicPlayer(object):
# 定义类属性记录单例对象引用
instance = None
def __new__(cls, *args, **kwargs):
# 1. 判断类属性是否已经被赋值
if cls.instance is None:
cls.instance = super().__new__(cls)
# 2. 返回类属性的单例引用
return cls.instance
只执行一次初始化工作
-
在每次使用
类名()创建对象时,Python的解释器都会自动调用两个方法:-
__new__分配空间 -
__init__对象初始化
-
-
在上一小节对
__new__方法改造之后,每次都会得到 第一次被创建对象的引用 -
但是:初始化方法还会被再次调用
需求
-
让 初始化动作 只被 执行一次
解决办法
-
定义一个类属性
init_flag标记是否 执行过初始化动作,初始值为False -
在
__init__方法中,判断init_flag,如果为False就执行初始化动作 -
然后将
init_flag设置为True -
这样,再次 自动 调用
__init__方法时,初始化动作就不会被再次执行 了
class MusicPlayer(object):
# 记录第一个被创建对象的引用
instance = None
# 记录是否执行过初始化动作
init_flag = False
def __new__(cls, *args, **kwargs):
# 1. 判断类属性是否是空对象
if cls.instance is None:
# 2. 调用父类的方法,为第一个对象分配空间
cls.instance = super().__new__(cls)
# 3. 返回类属性保存的对象引用
return cls.instance
def __init__(self):
if not MusicPlayer.init_flag:
print("初始化音乐播放器")
MusicPlayer.init_flag = True
# 创建多个对象
player1 = MusicPlayer()
print(player1)
player2 = MusicPlayer()
print(player2)
初始化音乐播放器 <__main__.MusicPlayer object at 0x0000019AE8EC7CD0> <__main__.MusicPlayer object at 0x0000019AE8EC7CD0>

七.异常
(1)概念
-
程序在运行时,如果
Python 解释器遇到 到一个错误,会停止程序的执行,并且提示一些错误信息,这就是 异常 -
程序停止执行并且提示错误信息 这个动作,我们通常称之为:抛出(raise)异常
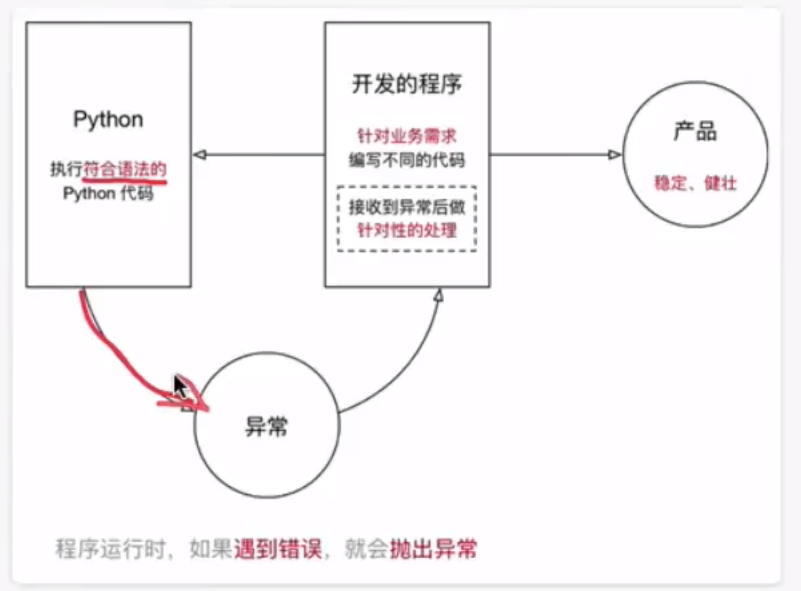
程序开发时,很难将 所有的特殊情况 都处理的面面俱到,通过 异常捕获 可以针对突发事件做集中的处理,从而保证程序的 稳定性和健壮性
(2)捕获异常
1.语法
-
在程序开发中,如果 对某些代码的执行不能确定是否正确,可以增加
try(尝试)来 捕获异常 -
捕获异常最简单的语法格式:
try: 尝试执行的代码 except: 出现错误的处理
-
try尝试,下方编写要尝试代码,不确定是否能够正常执行的代码 -
except如果不是,下方编写尝试失败的代码
简单异常捕获演练 —— 要求用户输入整数
try:
# 提示用户输入一个数字
num = int(input("请输入数字:"))
except:
print("请输入正确的数字")
请输入数字:emm 请输入正确的数字 --------------------------------------------------
请输入数字:10 --------------------------------------------------
2.错误类型捕获
-
在程序执行时,可能会遇到 不同类型的异常,并且需要 针对不同类型的异常,做出不同的响应,这个时候,就需要捕获错误类型了
-
语法如下:
try:
# 尝试执行的代码
pass
except 错误类型1:
# 针对错误类型1,对应的代码处理
pass
except (错误类型2, 错误类型3):
# 针对错误类型2 和 3,对应的代码处理
pass
except Exception as result:
print("未知错误 %s" % result)
-
当
Python解释器 抛出异常 时,最后一行错误信息的第一个单词,就是错误类型
异常类型捕获演练 —— 要求用户输入整数
需求
-
提示用户输入一个整数
-
使用
8除以用户输入的整数并且输出
try:
num = int(input("请输入整数:"))
result = 8 / num
print(result)
except ValueError:
print("请输入正确的整数")
except ZeroDivisionError:
print("除 0 错误")
请输入整数:0 除 0 错误
请输入整数:emm 请输入正确的整数
请输入整数:15 0.5333333333333333
捕获未知错误
-
在开发时,要预判到所有可能出现的错误,还是有一定难度的
-
如果希望程序 无论出现任何错误,都不会因为
Python解释器 抛出异常而被终止,可以再增加一个except
语法如下:
try:
num = int(input("请输入整数:"))
result = 8 / num
print(result)
except ValueError:
print("请输入正确的整数")
except Exception as result:
print("未知错误 %s" % result)
请输入整数:0 未知错误 division by zero
3.完整语法
-
在实际开发中,为了能够处理复杂的异常情况,完整的异常语法如下:
提示:
有关完整语法的应用场景,在后续学习中,结合实际的案例会更好理解
现在先对这个语法结构有个印象即可
try:
# 尝试执行的代码
pass
except 错误类型1:
# 针对错误类型1,对应的代码处理
pass
except 错误类型2:
# 针对错误类型2,对应的代码处理
pass
except (错误类型3, 错误类型4):
# 针对错误类型3 和 4,对应的代码处理
pass
except Exception as result:
# 打印错误信息
print(result)
else:
# 没有异常才会执行的代码
pass
finally:
# 无论是否有异常,都会执行的代码
print("无论是否有异常,都会执行的代码")
-
else只有在没有异常时才会执行的代码 -
finally无论是否有异常,都会执行的代码 -
之前一个演练的 完整捕获异常 的代码如下:
# 使用while语句为了更好的观察
while True:
try:
num = int(input("请输入整数:"))
result = 8 / num
print(result)
except ValueError:
print("请输入正确的整数")
except ZeroDivisionError:
print("除 0 错误")
except Exception as result:
print("未知错误 %s" % result)
else:
print("正常执行")
finally:
print("执行完成,但是不保证正确-----------------")
请输入整数:8 1.0 正常执行 执行完成,但是不保证正确----------------- 请输入整数:0 除 0 错误 执行完成,但是不保证正确----------------- 请输入整数:3 2.6666666666666665 正常执行 执行完成,但是不保证正确----------------- 请输入整数:emm 请输入正确的整数 执行完成,但是不保证正确----------------- 请输入整数:
(3)异常的传递
-
异常的传递 —— 当 函数/方法 执行 出现异常,会 将异常传递 给 函数/方法 的 调用一方
-
如果 传递到主程序,仍然 没有异常处理,程序才会被终止
提示
-
在开发中,可以在主函数中增加 异常捕获
-
而在主函数中调用的其他函数,只要出现异常,都会传递到主函数的 异常捕获 中
-
这样就不需要在代码中,增加大量的 异常捕获,能够保证代码的整洁
def demo1():
return int(input("请输入一个整数:"))
def demo2():
return demo1()
print(demo2())
请输入一个整数:0.5
Traceback (most recent call last):
File "D:\桌面\Pythoncode\test.py", line 9, in <module>
print(demo2())
File "D:\桌面\Pythoncode\test.py", line 6, in demo2
return demo1()
File "D:\桌面\Pythoncode\test.py", line 2, in demo1
return int(input("请输入一个整数:"))
ValueError: invalid literal for int() with base 10: '0.5'
需求
-
定义函数
demo1()提示用户输入一个整数并且返回 -
定义函数
demo2()调用demo1() -
在主程序中调用
demo2()
def demo1():
return int(input("请输入一个整数:"))
def demo2():
return demo1()
try:
print(demo2())
except ValueError:
print("请输入正确的整数")
except Exception as result:
print("未知错误 %s" % result)
(4)抛出 raise 异常
1.应用场景
-
在开发中,除了 代码执行出错
Python解释器会 抛出 异常之外 -
还可以根据 应用程序 特有的业务需求 主动抛出异常
示例
-
提示用户 输入密码,如果 长度少于 8,抛出 异常
注意
-
当前函数 只负责 提示用户输入密码,如果 密码长度不正确,需要其他的函数进行额外处理
-
因此可以 抛出异常,由其他需要处理的函数 捕获异常
2.抛出异常
-
Python中提供了一个Exception异常类 -
在开发时,如果满足 特定业务需求时,希望 抛出异常,可以:
-
创建 一个
Exception的 对象 -
使用
raise关键字 抛出 异常对象
-
需求
-
定义
input_password函数,提示用户输入密码 -
如果用户输入长度 < 8,抛出异常
-
如果用户输入长度 >=8,返回输入的密码
def input_password():
# 1. 提示用户输入密码
pwd = input("请输入密码:")
# 2. 判断密码长度,如果长度 >= 8,返回用户输入的密码
if len(pwd) >= 8:
return pwd
# 3. 密码长度不够,需要抛出异常
# 1> 创建异常对象 - 使用异常的错误信息字符串作为参数
ex = Exception("密码长度不够")
# 2> 抛出异常对象
raise ex
try:
user_pwd = input_password()
print(user_pwd)
except Exception as result:
print("发现错误:%s" % result)
请输入密码:aaaaaaaaaaaaaa aaaaaaaaaaaaaa
请输入密码:a 发现错误:密码长度不够
八.模块和包
(1)模块
1.概念
模块是 Python 程序架构的一个核心概念
-
每一个以扩展名
py结尾的Python源代码文件都是一个 模块 -
模块名 同样也是一个 标识符,需要符合标识符的命名规则
-
在模块中定义的 全局变量 、函数、类 都是提供给外界直接使用的 工具
-
模块 就好比是 工具包,要想使用这个工具包中的工具,就需要先 导入 这个模块
2.两种导入方式
1)import 导入
import 模块名1, 模块名2
提示:在导入模块时,每个导入应该独占一行
import 模块名1 import 模块名2
-
导入之后
-
通过
模块名.使用 模块提供的工具 —— 全局变量、函数、类
-
使用 as 指定模块的别名
如果模块的名字太长,可以使用
as指定模块的名称,以方便在代码中的使用
import 模块名1 as 模块别名
注意:模块别名 应该符合 大驼峰命名法
2)from...import 导入
-
如果希望 从某一个模块 中,导入 部分 工具,就可以使用
from ... import的方式 -
import 模块名是 一次性 把模块中 所有工具全部导入,并且通过 模块名/别名 访问
# 从 模块 导入 某一个工具 from 模块名1 import 工具名
-
导入之后
-
不需要 通过
模块名. -
可以直接使用 模块提供的工具 —— 全局变量、函数、类
-
注意
如果 两个模块,存在 同名的函数,那么 后导入模块的函数,会 覆盖掉先导入的函数
-
开发时
import代码应该统一写在 代码的顶部,更容易及时发现冲突 -
一旦发现冲突,可以使用
as关键字 给其中一个工具起一个别名
from...import *(知道)
# 从 模块 导入 所有工具 from 模块名1 import *
注意
这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
3.模块的搜索顺序
Python 的解释器在 导入模块 时,会:
-
搜索 当前目录 指定模块名的文件,如果有就直接导入
-
如果没有,再搜索 系统目录
在开发时,给文件起名,不要和 系统的模块文件 重名
Python 中每一个模块都有一个内置属性 __file__ 可以 查看模块 的 完整路径
示例
import random # 生成一个 0~10 的数字 rand = random.randint(0, 10) print(rand)
注意:如果当前目录下,存在一个
random.py的文件,程序就无法正常执行了!
-
这个时候,
Python的解释器会 加载当前目录 下的random.py而不会加载 系统的random模块
4.__name__ 属性
原则:
每一个文件都应该是可以被导入的
-
一个 独立的
Python文件 就是一个 模块 -
在导入文件时,文件中 所有没有任何缩进的代码 都会被执行一遍!
实际开发场景
-
在实际开发中,每一个模块都是独立开发的,大多都有专人负责
-
开发人员 通常会在 模块下方 增加一些测试代码
-
仅在模块内使用,而被导入到其他文件中不需要执行
-
__name__ 属性:
__name__属性可以做到,测试模块的代码 只在测试情况下被运行,而在 被导入时不会被执行!
-
__name__是Python的一个内置属性,记录着一个 字符串 -
如果 是被其他文件导入的,
__name__就是 模块名 -
如果 是当前执行的程序
__name__是__main__
在很多 Python 文件中都会看到以下格式的代码:
# 导入模块
# 定义全局变量
# 定义类
# 定义函数
# 在代码的最下方
def main():
# ...
pass
# 根据 __name__ 判断是否执行下方代码
if __name__ == "__main__":
main()
eg:
test1.py
# 全局变量,函数,类,注意:直接执行的代码不是向外界提供的工具
def say_heelo():
print("你好你好,我是say_hello")
# 文件被导入时,能够直接执行的代码不需要被直接执行
print("小明开发的模块")
say_heelo()
# 根据 __name__ 判断是否执行下方代码
if __name__ == "__main__":
print("小明开发的模块")
say_heelo()
test2.py
import test1
print("*" * 50)
小明开发的模块 你好你好,我是say_hello **************************************************
(2)包 Package
概念
-
包 是一个 包含多个模块 的 特殊目录
-
目录下有一个 特殊的文件
__init__.py -
包名的 命名方式 和变量名一致,小写字母 +
_
好处
-
使用
import 包名可以一次性导入 包 中 所有的模块
创建时:
-
可以新建Python包(可以自动生成
__init__.py文件) -
可以新建目录后再新建
__init__.py文件
__init__.py
-
要在外界使用 包 中的模块,需要在
__init__.py中指定 对外界提供的模块列表
# 从 当前目录 导入 模块列表 from . import send_message from . import receive_message
案例演练
-
新建一个
hm_message的 包 -
在目录下,新建两个文件
send_message和receive_message -
在
send_message文件中定义一个send函数 -
在
receive_message文件中定义一个receive函数 -
在外部直接导入
hm_message的包
send_message.py
def send():
print("发送消息...")
receive_message.py
def receive():
print("接收消息...")
__init__.py
from . import send_message from . import receive_message
test.py
import hm_message hm_message.send_message.send() hm_message.receive_message.receive()
(3)发布模块
-
如果希望自己开发的模块,分享 给其他人,可以按照以下步骤操作
1.制作发布压缩包步骤
1) 创建 setup.py
-
setup.py的文件
from distutils.core import setup
setup(name="hm_message", # 包名
version="1.0", # 版本
description="itheima's 发送和接收消息模块", # 描述信息
long_description="完整的发送和接收消息模块", # 完整描述信息
author="itheima", # 作者
author_email="itheima@itheima.com", # 作者邮箱
url="www.itheima.com", # 主页
py_modules=["hm_message.send_message",
"hm_message.receive_message"])
有关字典参数的详细信息,可以参阅官方网站:
10. API Reference — Python 2.7.18 documentation
2) 构建模块
$ python3 setup.py build
3) 生成发布压缩包
$ python3 setup.py sdist
注意:要制作哪个版本的模块,就使用哪个版本的解释器执行!
2.安装模块
$ tar -zxvf hm_message-1.0.tar.gz $ sudo python3 setup.py install
卸载模块
直接从安装目录下,把安装模块的 目录 删除就可以
$ cd /usr/local/lib/python3.5/dist-packages/ $ sudo rm -r hm_message*
3.pip 安装第三方模块
-
第三方模块 通常是指由 知名的第三方团队 开发的 并且被 程序员广泛使用 的
Python包 / 模块-
例如
pygame就是一套非常成熟的 游戏开发模块
-
-
pip是一个现代的,通用的Python包管理工具 -
提供了对
Python包的查找、下载、安装、卸载等功能
安装和卸载命令如下:
# 将模块安装到 Python 2.x 环境 $ sudo pip install pygame $ sudo pip uninstall pygame # 将模块安装到 Python 3.x 环境 $ sudo pip3 install pygame $ sudo pip3 uninstall pygame
在 Mac 下安装 iPython
$ sudo pip install ipython
在 Linux 下安装 iPython
$ sudo apt install ipython $ sudo apt install ipython3
九.文件
(1)文件的概念
1.概念和作用
-
计算机的 文件,就是存储在某种 长期储存设备 上的一段 数据
-
长期存储设备包括:硬盘、U 盘、移动硬盘、光盘...
文件的作用
将数据长期保存下来,在需要的时候使用
2.存储方式
-
在计算机中,文件是以 二进制 的方式保存在磁盘上的
文本文件和二进制文件
-
文本文件
-
可以使用 文本编辑软件 查看
-
本质上还是二进制文件
-
例如:python 的源程序
-
-
二进制文件
-
保存的内容 不是给人直接阅读的,而是 提供给其他软件使用的
-
例如:图片文件、音频文件、视频文件等等
-
二进制文件不能使用 文本编辑软件 查看
-
(2)文件的基本操作
1.操作文件的套路
在 计算机 中要操作文件的套路非常固定,一共包含三个步骤:
-
打开文件
-
读、写文件
-
读 将文件内容读入内存
-
写 将内存内容写入文件
-
-
关闭文件
2.操作文件的函数/方法
-
在
Python中要操作文件需要记住 1 个函数和 3 个方法
| 序号 | 函数/方法 | 说明 |
|---|---|---|
| 01 | open | 打开文件,并且返回文件操作对象 |
| 02 | read | 将文件内容读取到内存 |
| 03 | write | 将指定内容写入文件 |
| 04 | close | 关闭文件 |
-
open函数负责打开文件,并且返回文件对象 -
read/write/close三个方法都需要通过 文件对象 来调用
3.read 方法
-
open函数的第一个参数是要打开的文件名(文件名区分大小写)-
如果文件 存在,返回 文件操作对象
-
如果文件 不存在,会 抛出异常
-
-
read方法可以一次性 读入 并 返回 文件的 所有内容 -
close方法负责 关闭文件-
如果 忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
-
-
注意:
read方法执行后,会把 文件指针 移动到 文件的末尾
# 1. 打开 - 文件名需要注意大小写
file = open("README.txt")
# 2. 读取
text = file.read()
print(text)
# 3. 关闭
file.close()
提示
-
在开发中,通常会先编写 打开 和 关闭 的代码,再编写中间针对文件的 读/写 操作!
文件指针(知道)
-
文件指针 标记 从哪个位置开始读取数据
-
第一次打开 文件时,通常 文件指针会指向文件的开始位置
-
当执行了
read方法后,文件指针 会移动到 读取内容的末尾-
默认情况下会移动到 文件末尾
-
思考
-
如果执行了一次
read方法,读取了所有内容,那么再次调用read方法,还能够获得到内容吗?
答案
-
不能
-
第一次读取之后,文件指针移动到了文件末尾,再次调用不会读取到任何的内容
# 1. 打开 - 文件名需要注意大小写
file = open("README.txt")
# 2. 读取
text = file.read()
print(text)
print("-"*50)
text = file.read()
print(text)
# 3. 关闭
file.close()
hello world --------------------------------------------------
4.打开文件的方式
-
open函数默认以 只读方式 打开文件,并且返回文件对象
语法如下:
f = open("文件名", "访问方式")
| 访问方式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。如果文件不存在,抛出异常 |
| w | 以只写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a | 以追加方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
| r+ | 以读写方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常 |
| w+ | 以读写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a+ | 以读写方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
提示
-
频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候会以 只读、只写 的方式来操作文件
写入文件示例
# 打开文件
f = open("README.txt", "w")
f.write("hello python!\n")
f.write("今天天气真好\n")
# 关闭文件
f.close()
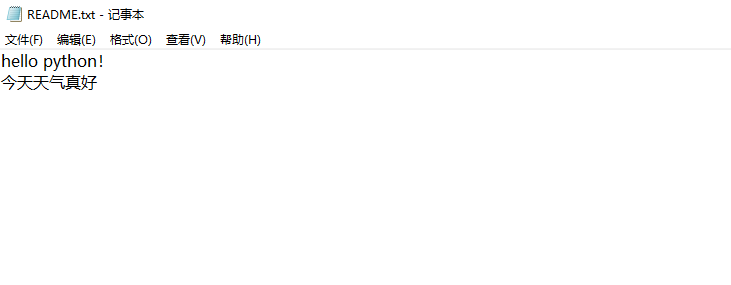
5.按行读取文件内容
-
read方法默认会把文件的 所有内容 一次性读取到内存 -
如果文件太大,对内存的占用会非常严重
readline 方法
-
readline方法可以一次读取一行内容 -
方法执行后,会把 文件指针 移动到下一行,准备再次读取
读取大文件的正确姿势
# 打开文件
file = open("README.txt")
while True:
# 读取一行内容
text = file.readline()
# 判断是否读到内容
if not text:
break
# 每读取一行的末尾已经有了一个 `\n`
print(text, end="")
# 关闭文件
file.close()
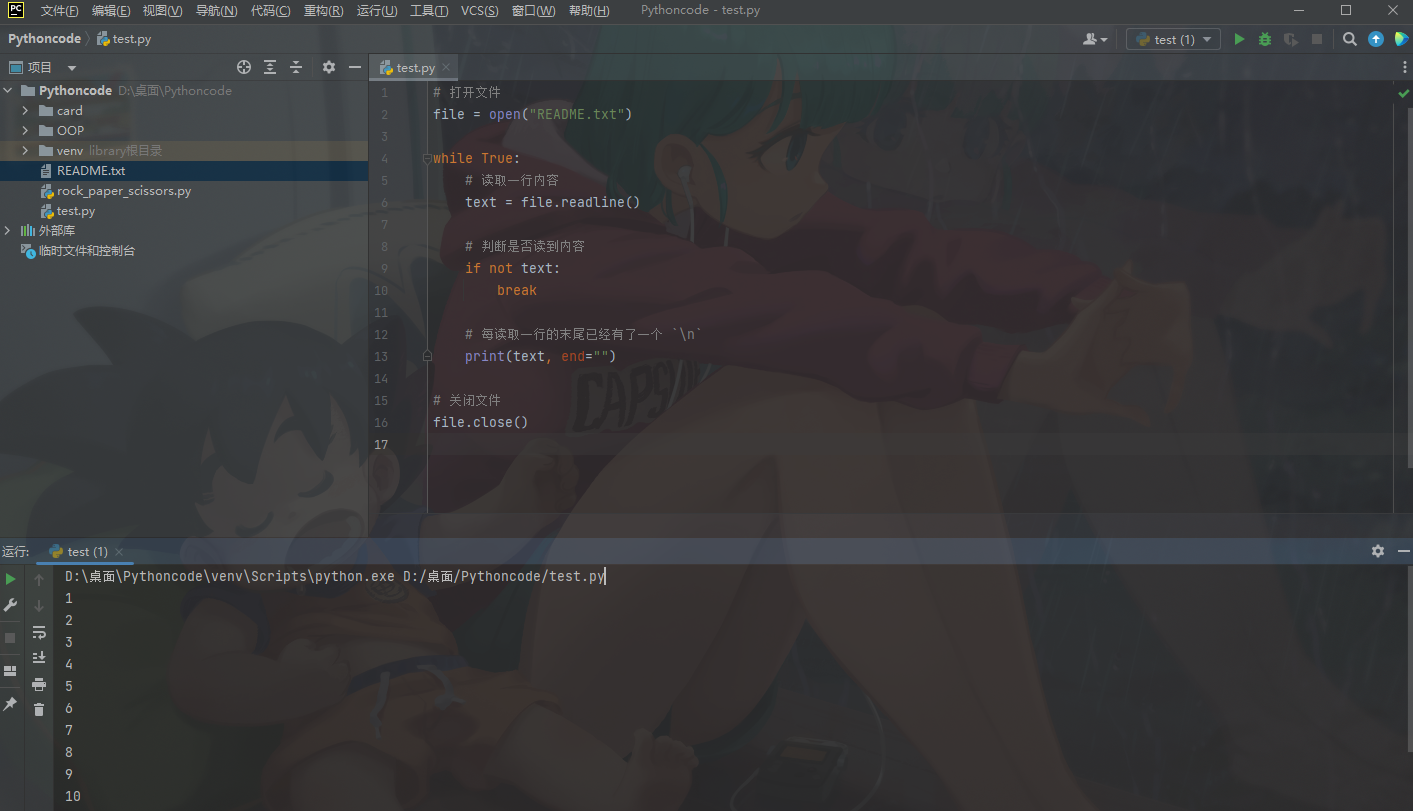
6.复制文件
文件读写案例 ——
小文件复制
用代码的方式,来实现文件复制过程
-
打开一个已有文件,读取完整内容,并写入到另外一个文件
# 1. 打开文件
file_read = open("README")
file_write = open("README[复件]", "w")
# 2. 读取并写入文件
text = file_read.read()
file_write.write(text)
# 3. 关闭文件
file_read.close()
file_write.close()
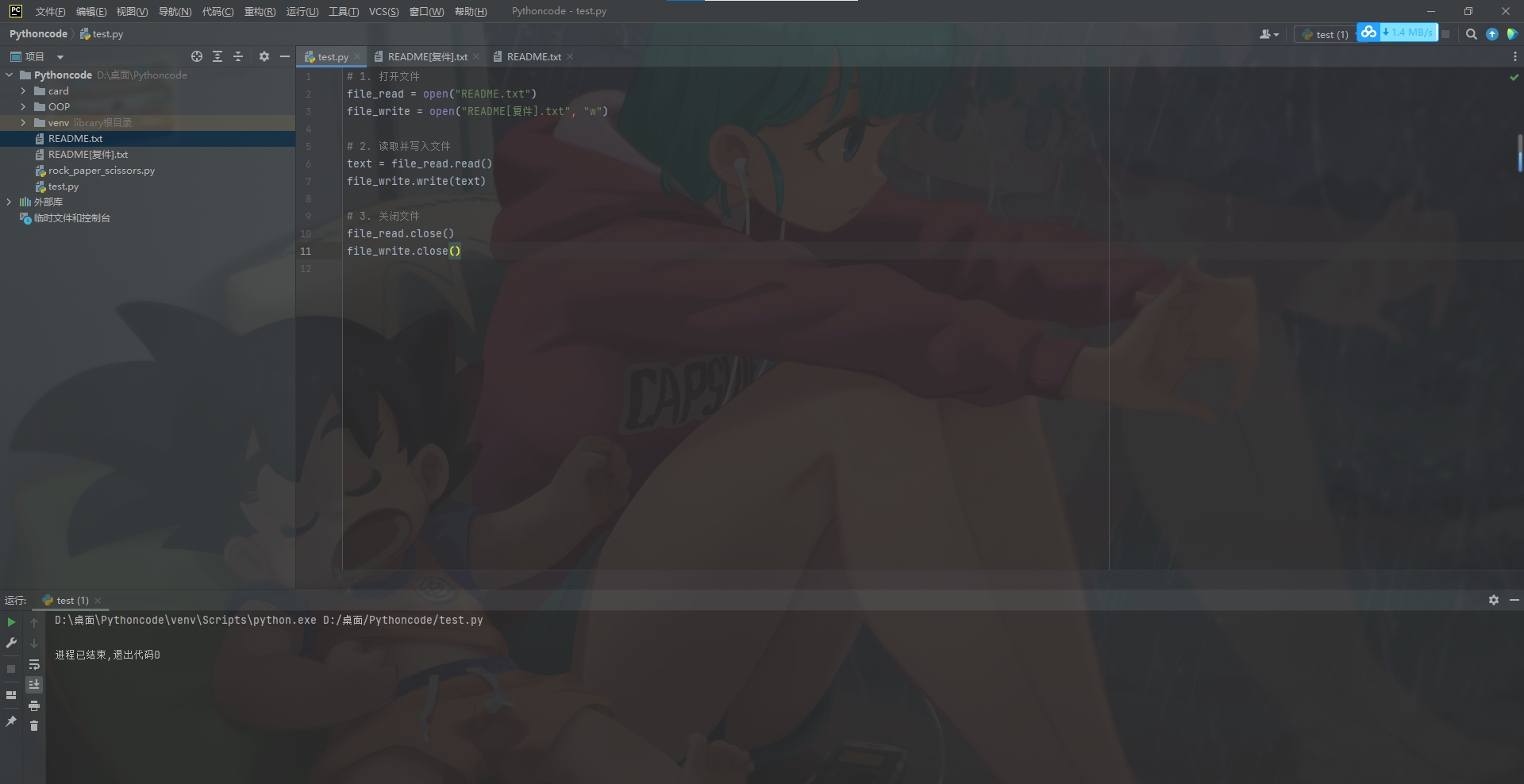
大文件复制
-
打开一个已有文件,逐行读取内容,并顺序写入到另外一个文件
# 1. 打开文件
file_read = open("README")
file_write = open("README[复件]", "w")
# 2. 读取并写入文件
while True:
# 每次读取一行
text = file_read.readline()
# 判断是否读取到内容
if not text:
break
file_write.write(text)
# 3. 关闭文件
file_read.close()
file_write.close()
(3)文件/目录的常用管理操作
-
在 终端 / 文件浏览器、 中可以执行常规的 文件 / 目录 管理操作,例如:
-
创建、重命名、删除、改变路径、查看目录内容、……
-
-
在
Python中,如果希望通过程序实现上述功能,需要导入os模块
文件操作
| 序号 | 方法名 | 说明 | 示例 |
|---|---|---|---|
| 01 | rename | 重命名文件 | os.rename(源文件名, 目标文件名) |
| 02 | remove | 删除文件 | os.remove(文件名) |
目录操作
| 序号 | 方法名 | 说明 | 示例 |
|---|---|---|---|
| 01 | listdir | 目录列表 | os.listdir(目录名) |
| 02 | mkdir | 创建目录 | os.mkdir(目录名) |
| 03 | rmdir | 删除目录 | os.rmdir(目录名) |
| 04 | getcwd | 获取当前目录 | os.getcwd() |
| 05 | chdir | 修改工作目录 | os.chdir(目标目录) |
| 06 | path.isdir | 判断是否是文件 | os.path.isdir(文件路径) |
提示:文件或者目录操作都支持 相对路径 和 绝对路径
(4)文本文件的编码格式(科普)
-
文本文件存储的内容是基于 字符编码 的文件,常见的编码有
ASCII编码,UNICODE编码等
Python 2.x 默认使用
ASCII编码格式 Python 3.x 默认使用UTF-8编码格式
1.ASCII 编码和 UNICODE 编码
ASCII 编码
-
计算机中只有
256个ASCII字符 -
一个
ASCII在内存中占用 1 个字节 的空间-
8个0/1的排列组合方式一共有256种,也就是2 ** 8
-
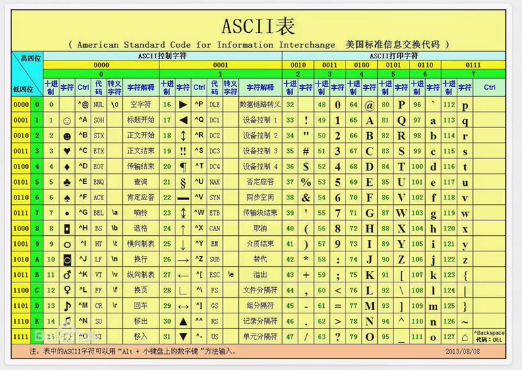
UTF-8 编码格式
-
计算机中使用 1~6 个字节 来表示一个
UTF-8字符,涵盖了 地球上几乎所有地区的文字 -
大多数汉字会使用 3 个字节 表示
-
UTF-8是UNICODE编码的一种编码格式
2.Ptyhon 2.x 中如何使用中文
Python 2.x 默认使用
ASCII编码格式 Python 3.x 默认使用UTF-8编码格式
-
在 Python 2.x 文件的 第一行 增加以下代码,解释器会以
utf-8编码来处理 python 文件
# *-* coding:utf8 *-*
这方式是官方推荐使用的!
-
也可以使用
# coding=utf8
unicode 字符串
-
在
Python 2.x中,即使指定了文件使用UTF-8的编码格式,但是在遍历字符串时,仍然会 以字节为单位遍历 字符串 -
要能够 正确的遍历字符串,在定义字符串时,需要 在字符串的引号前,增加一个小写字母
u,告诉解释器这是一个unicode字符串(使用UTF-8编码格式的字符串)
# *-* coding:utf8 *-* # 在字符串前,增加一个 `u` 表示这个字符串是一个 utf8 字符串 hello_str = u"你好世界" print(hello_str) for c in hello_str: print(c)
十.eval 函数
eval() 函数十分强大 —— 将字符串 当成 有效的表达式 来求值 并 返回计算结果
# 基本的数学计算
In [1]: eval("1 + 1")
Out[1]: 2
# 字符串重复
In [2]: eval("'*' * 10")
Out[2]: '**********'
# 将字符串转换成列表
In [3]: type(eval("[1, 2, 3, 4, 5]"))
Out[3]: list
# 将字符串转换成字典
In [4]: type(eval("{'name': 'xiaoming', 'age': 18}"))
Out[4]: dict
案例 - 计算器
需求
-
提示用户输入一个 加减乘除混合运算
-
返回计算结果
input_str = input("请输入一个算术题:")
print(eval(input_str))
请输入一个算术题:5*5 25
不要滥用 eval
在开发时千万不要使用
eval直接转换input的结果
__import__('os').system('ls')
-
等价代码
import os
os.system("终端命令")
-
执行成功,返回 0
-
执行失败,返回错误信息
飞机大战
1.确认模块

在Windows系统中在cmd中输入:pip install pygame 即可安装
win 输入 python -m pygame.examples.aliens 如果进入:
表示安装成功
2.使用pygame创建图形窗口
(1)游戏的初始化和退出

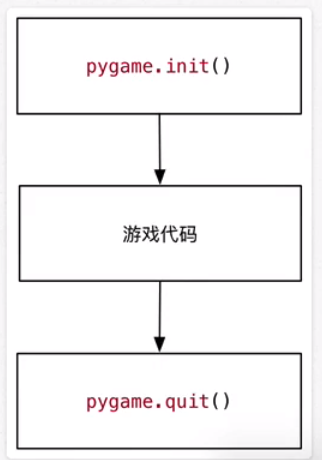
(2)理解游戏中的坐标系

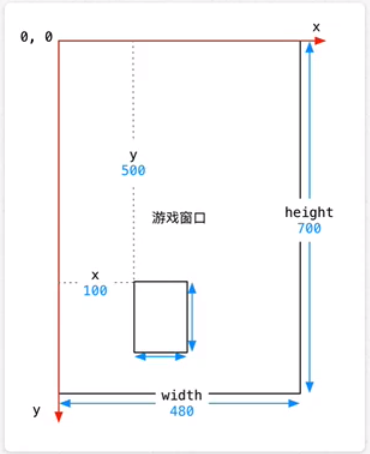
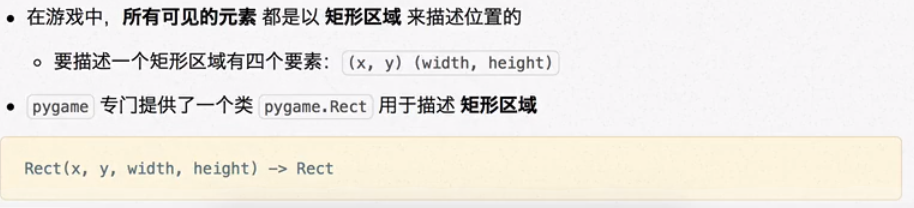
提示:
-
pygame.Rect是一个比较特殊的类,内部只是封装了一些数字技术
-
不执行pygame.init()方法同样是能够直接使用

eg:
import pygame
hero_rect = pygame.Rect(100, 500, 120, 125)
print("英雄的原点 %d %d " % (hero_rect.x, hero_rect.y))
print("英雄的尺寸 %d %d " % (hero_rect.width, hero_rect.height))
print("%d %d " % hero_rect.size)
英雄的原点 100 500 英雄的尺寸 120 125 120 125
(3)创建游戏主窗口
pygame专门提供了一个模块pygame.display用于创建管理主窗口
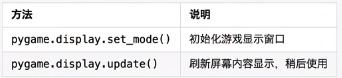

eg:
import pygame
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 游戏循环
while True:
pass
pygame.quit()
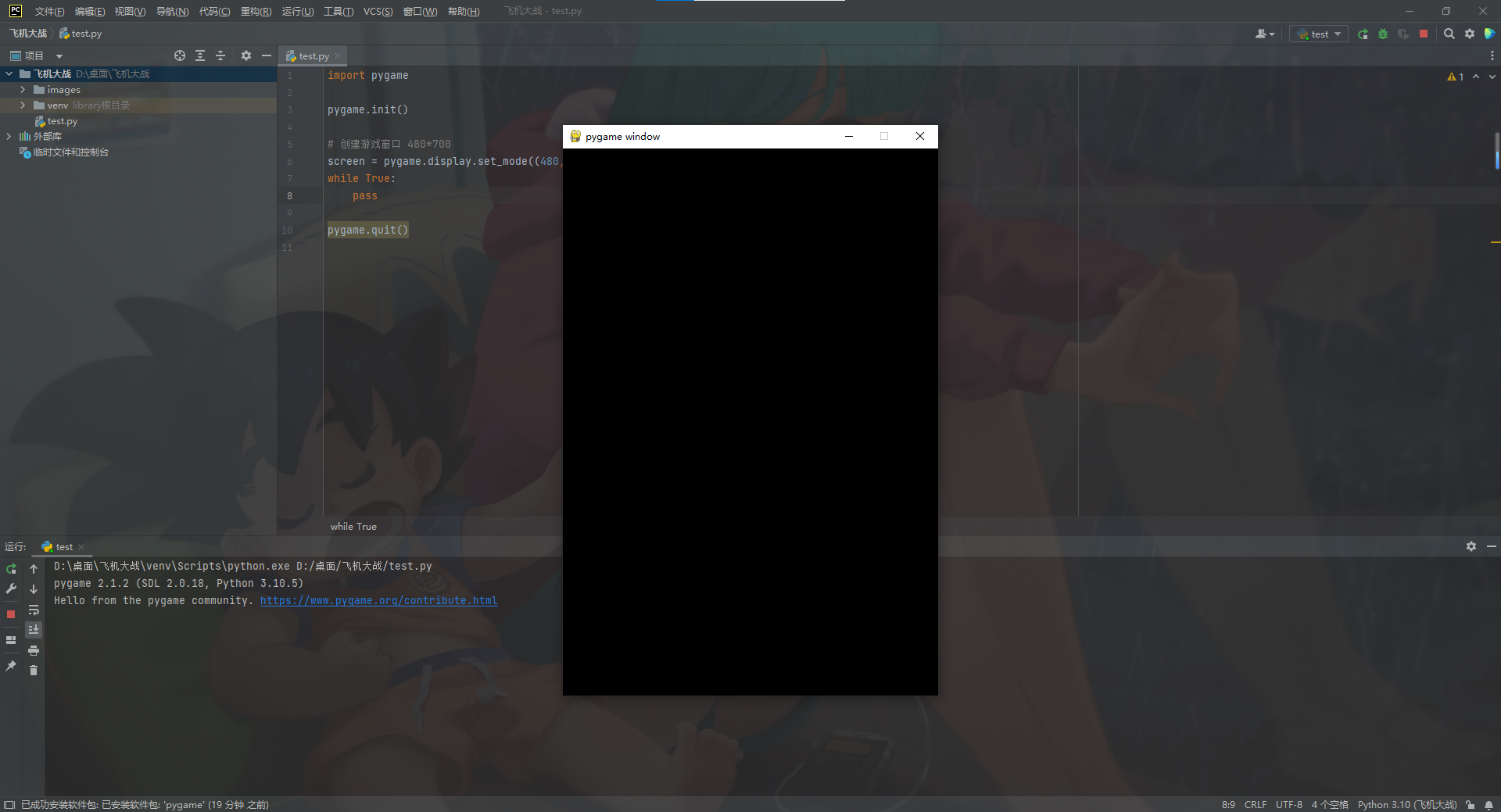
(4)理解图像并实行图像绘制

import pygame
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 绘制背景图像
# 1> 加载图像数据
bg = pygame.image.load("./images/background.png")
# 2> blit 绘制图像(这里的(0,0)的意思是在屏幕的左上角绘制图像)
screen.blit(bg, (0, 0))
# 3> 更新屏幕的显示
pygame.display.update()
# 游戏循环
while True:
pass
pygame.quit()

import pygame
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 绘制背景图像
# 1> 加载图像数据
bg = pygame.image.load("./images/background.png")
# 2> blit 绘制图像(这里的(0,0)的意思是在屏幕的左上角绘制图像)
screen.blit(bg, (0, 0))
# 3> 更新屏幕的显示
pygame.display.update()
# 绘制英雄的飞机
hero = pygame.image.load("./images/me1.png")
screen.blit(hero, (200, 600))
pygame.display.update()
# 游戏循环
while True:
pass
pygame.quit()

(5)update()方法的作用

3.理解游戏循环和游戏时钟
现在的飞机已经被绘制到屏幕上了,怎么能让飞机移动呢?
(1)游戏中的动画原理
-
跟电影的原理类似,游戏中的动画效果,本质上是快速的在屏幕上绘制图像。电影是将多张静止的电影胶片连续、快速的播放,产生连贯的视觉效果!
-
一般在电脑上每秒绘制60次,就能够达到非常连续高品质的动画效果。每次绘制的结果被称为帧Frame
(2)游戏循环
游戏循环的作用
-
保证游戏不会直接退出
-
变化图像位置--动画效果
-
每隔1/60秒 移动一下所有图像的位置
-
调用pygame.display.update()更新屏幕显示
-
-
检测用户交互--按键、鼠标等...
(3)游戏时钟
-
pygame专门提供了一个类pygane.tine.Clock可以非常方便的设置屏幕绘制速度--刷新帧率 -
要使用时钟对象 需要两步:
-
在游戏初始化创建一个时钟对象
-
在游戏循环中让时钟对象调用 tick(帧率)方法
-
-
tick方法会根据上次被调用的时间,自动设置游戏循环中的延时
eg:
import pygame
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 绘制背景图像
# 1> 加载图像数据
bg = pygame.image.load("./images/background.png")
# 2> blit 绘制图像(这里的(0,0)的意思是在屏幕的左上角绘制图像)
screen.blit(bg, (0, 0))
# 3> 更新屏幕的显示
pygame.display.update()
# 绘制英雄的飞机
hero = pygame.image.load("./images/me1.png")
screen.blit(hero, (200, 600))
pygame.display.update()
# 创建时钟对象
clock = pygame.time.Clock()
# 游戏循环
i = 0
while True:
clock.tick(60)
print(i)
i = i + 1
pass
pygame.quit()
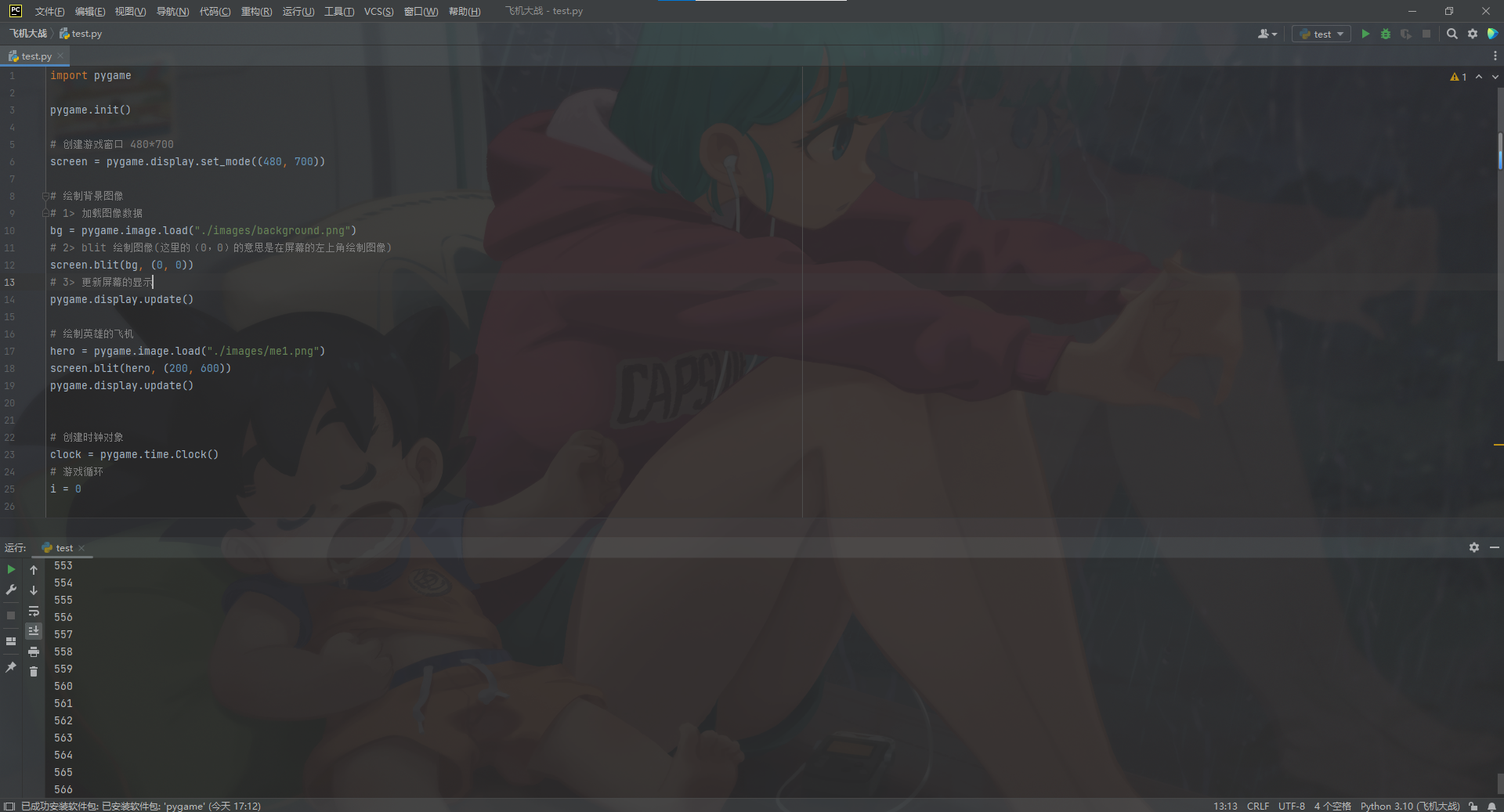
若把时钟对象中的60改成1
则:
import pygame
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 绘制背景图像
# 1> 加载图像数据
bg = pygame.image.load("./images/background.png")
# 2> blit 绘制图像(这里的(0,0)的意思是在屏幕的左上角绘制图像)
screen.blit(bg, (0, 0))
# 3> 更新屏幕的显示
pygame.display.update()
# 绘制英雄的飞机
hero = pygame.image.load("./images/me1.png")
screen.blit(hero, (200, 600))
pygame.display.update()
# 创建时钟对象
clock = pygame.time.Clock()
# 游戏循环
i = 0
while True:
clock.tick(1)
print(i)
i = i + 1
pass
pygame.quit()
(4)英雄的简单动画实现
需求:
-
在游戏初始化定义一个
pygame.Rect的变量记录英雄的初始位置 -
在游戏循环中每次让英雄的
y-1-- 向上移动 -
y <= 0将英雄移动到屏幕的底部
提示:
每一次调用 update()方法之前,需要把所有的游戏图像都重新绘制一遍
而且应该 最先 重新绘制 背景图像
import pygame
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 绘制背景图像
# 1> 加载图像数据
bg = pygame.image.load("./images/background.png")
# 2> blit 绘制图像(这里的(0,0)的意思是在屏幕的左上角绘制图像)
screen.blit(bg, (0, 0))
# 3> 更新屏幕的显示
pygame.display.update()
# 绘制英雄的飞机
hero = pygame.image.load("./images/me1.png")
screen.blit(hero, (150, 300))
pygame.display.update()
# 创建时钟对象
clock = pygame.time.Clock()
# 1. 定义rect记录飞机的初始位置
hero_rect = pygame.Rect(150, 300, 102, 126)
# 游戏循环
while True:
# 可以指定循环体内部的代码执行的频率
clock.tick(60)
# 2. 修改飞机的位置
hero_rect.y -= 1
# 判断飞机的位置如果到了边界再次回到底部
if hero_rect.y <= 0:
hero_rect.y = 700
# 3. 调用blit方法绘制图像
# 再次绘制背景图像,以防止留下残影
screen.blit(bg, (0, 0))
screen.blit(hero, hero_rect)
# 4. 调用update方法更新显示
pygame.display.update()
pass
pygame.quit()
(4)监听事件
事件 event
-
就是游戏启动后,用户针对游戏所做的操作
-
例如:点击关闭按钮,点击鼠标,按下键盘...
监听
-
在游戏循环中,判断用户 具体的操作
只有捕获到用户具体的操作,才能有针对性的做出响应
代码实现
-
pygame中通过pygame.event.get()可以获得用户当前所做动作的事件列表。用户可以同一时间做很多事情 -
提示:这段代码非常的固定,几乎所有的
pygame游戏都大同小异!
import pygame
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 绘制背景图像
# 1> 加载图像数据
bg = pygame.image.load("./images/background.png")
# 2> blit 绘制图像(这里的(0,0)的意思是在屏幕的左上角绘制图像)
screen.blit(bg, (0, 0))
# 3> 更新屏幕的显示
pygame.display.update()
# 绘制英雄的飞机
hero = pygame.image.load("./images/me1.png")
screen.blit(hero, (150, 300))
pygame.display.update()
# 创建时钟对象
clock = pygame.time.Clock()
# 1. 定义rect记录飞机的初始位置
hero_rect = pygame.Rect(150, 300, 102, 126)
# 游戏循环
while True:
# 可以指定循环体内部的代码执行的频率
clock.tick(120)
# 事件监听(检测是否通过鼠标关闭)
for event in pygame.event.get():
if event.type == pygame.QUIT:
print("游戏退出...")
# 先卸载quit所有模块,再退出
pygame.quit()
exit()
# 捕获事件
event_list = pygame.event.get()
if len(event_list) > 0:
print(event_list)
# 2. 修改飞机的位置
hero_rect.y -= 1
# 判断飞机的位置如果到了边界再次回到底部
if hero_rect.y <= -126:
hero_rect.y = 700
# 3. 调用blit方法绘制图像
# 再次绘制背景图像,以防止留下残影
screen.blit(bg, (0, 0))
screen.blit(hero, hero_rect)
# 4. 调用update方法更新显示
pygame.display.update()
pass
pygame.quit()
随着鼠标在框体的移动,控制台也会输出对应的信息,点击右上角的关闭按钮游戏也会随之关闭
4.理解精灵和精灵组
(1)精灵和精灵族

(2)派生精灵子类
import pygame
class GameSprite(pygame.sprite.Sprite):
"""飞机大战精灵"""
# 在开发子类时,如果子类的父类不是object的基类,在初始化方法中需要主动调用父类的初始化方法
# 若不主动调用父类的初始化方法,就没有办法享受到父类中已经封装好的初始化方法
def __init__(self, image_name, speed=1):
# 调用父类的初始化方法
super.__init__()
# 定义对象
self.image = pygame.image.load(image_name)
self.rect = self.image.get_rect()
self.speed = speed
def update(self):
# 在屏幕的垂直方向移动
self.rect.y += self.speed
(3)创造敌机

import pygame
from plane_sprites import *
# 游戏的初始化
pygame.init()
# 创建游戏窗口 480*700
screen = pygame.display.set_mode((480, 700))
# 绘制背景图像
# 1> 加载图像数据
bg = pygame.image.load("./images/background.png")
# 2> blit 绘制图像(这里的(0,0)的意思是在屏幕的左上角绘制图像)
screen.blit(bg, (0, 0))
# 3> 更新屏幕的显示
pygame.display.update()
# 绘制英雄的飞机
hero = pygame.image.load("./images/me1.png")
screen.blit(hero, (150, 300))
pygame.display.update()
# 创建时钟对象
clock = pygame.time.Clock()
# 1. 定义rect记录飞机的初始位置
hero_rect = pygame.Rect(150, 300, 102, 126)
# 创建敌机的精灵
enemy = GameSprite("./images/enemy1.png")
enemy1 = GameSprite("./images/enemy1.png",2)
# 创建敌机的精灵族
enemy_group = pygame.sprite.Group(enemy, enemy1)
# 游戏循环
while True:
# 可以指定循环体内部的代码执行的频率
clock.tick(120)
# 事件监听(检测是否通过鼠标关闭)
for event in pygame.event.get():
if event.type == pygame.QUIT:
print("游戏退出...")
# 先卸载quit所有模块,再退出
pygame.quit()
exit()
# 捕获事件
event_list = pygame.event.get()
if len(event_list) > 0:
print(event_list)
# 2. 修改飞机的位置
hero_rect.y -= 1
# 判断飞机的位置如果到了边界再次回到底部
if hero_rect.y <= -126:
hero_rect.y = 700
# 3. 调用blit方法绘制图像
# 再次绘制背景图像,以防止留下残影
screen.blit(bg, (0, 0))
screen.blit(hero, hero_rect)
# 让精灵组调用两个方法
# update - 让组中的所有精灵更新位置
enemy_group.update()
# draw - 在screen上绘制所有的精灵
enemy_group.draw(screen)
# 4. 调用update方法更新显示
pygame.display.update()
pass
pygame.quit()
5.游戏框架搭建
目标 —— 使用 面相对象 设计 飞机大战游戏类
(1)明确主程序职责
-
回顾 快速入门案例,一个游戏主程序的 职责 可以分为两个部分:
-
游戏初始化
-
游戏循环
-
-
根据明确的职责,设计
PlaneGame类如下:
提示 根据 职责 封装私有方法,可以避免某一个方法的代码写得太过冗长
如果某一个方法编写的太长,既不好阅读,也不好维护!
-
游戏初始化 ——
__init__()会调用以下方法:
| 方法 | 职责 |
|---|---|
__create_sprites(self) | 创建所有精灵和精灵组 |
-
游戏循环 ——
start_game()会调用以下方法:
| 方法 | 职责 |
|---|---|
__event_handler(self) | 事件监听 |
__check_collide(self) | 碰撞检测 —— 子弹销毁敌机、敌机撞毁英雄 |
__update_sprites(self) | 精灵组更新和绘制 |
__game_over() | 游戏结束 |
(2)实现飞机大战主游戏类
1.明确文件职责
-
plane_main-
封装 主游戏类
-
创建 游戏对象
-
启动游戏
-
-
plane_sprites-
封装游戏中 所有 需要使用的 精灵子类
-
提供游戏的 相关工具
-
代码实现
-
新建
plane_main.py文件,并且设置为可执行 -
编写 基础代码
import pygame
from plane_sprites import *
class PlaneGame(object):
"""飞机大战主游戏"""
def __init__(self):
print("游戏初始化")
def start_game(self):
print("开始游戏...")
if __name__ == '__main__':
# 创建游戏对象
game = PlaneGame()
# 开始游戏
game.start_game()
2.游戏初始化部分
-
完成
__init__()代码如下:
def __init__(self):
print("游戏初始化")
# 1. 创建游戏的窗口
self.screen = pygame.display.set_mode((480, 700))
# 2. 创建游戏的时钟
self.clock = pygame.time.Clock()
# 3. 调用私有方法,精灵和精灵组的创建
self.__create_sprites()
def __create_sprites(self):
pass
使用 常量 代替固定的数值
常量 —— 不变化的量
变量 —— 可以变化的量
应用场景
-
在开发时,可能会需要使用 固定的数值,例如 屏幕的高度 是
700 -
这个时候,建议 不要 直接使用固定数值,而应该使用 常量
-
在开发时,为了保证代码的可维护性,尽量不要使用 魔法数字
常量的定义
-
定义 常量 和 定义 变量 的语法完全一样,都是使用 赋值语句
-
常量 的 命名 应该 所有字母都使用大写,单词与单词之间使用下划线连接
常量的好处
-
阅读代码时,通过 常量名 见名之意,不需要猜测数字的含义
-
如果需要 调整值,只需要 修改常量定义 就可以实现 统一修改
提示:Python 中并没有真正意义的常量,只是通过命名的约定 —— 所有字母都是大写的就是常量,开发时不要轻易的修改!
代码调整
-
在
plane_sprites.py中增加常量定义
import pygame # 游戏屏幕大小 SCREEN_RECT = pygame.Rect(0, 0, 480, 700)
-
修改
plane_main.py中的窗口大小
self.screen = pygame.display.set_mode(SCREEN_RECT.size)
3.游戏循环部分
-
完成
start_game()基础代码如下:
def start_game(self):
"""开始游戏"""
print("开始游戏...")
while True:
# 1. 设置刷新帧率
self.clock.tick(60)
# 2. 事件监听
self.__event_handler()
# 3. 碰撞检测
self.__check_collide()
# 4. 更新精灵组
self.__update_sprites()
# 5. 更新屏幕显示
pygame.display.update()
def __event_handler(self):
"""事件监听"""
for event in pygame.event.get():
if event.type == pygame.QUIT:
PlaneGame.__game_over()
def __check_collide(self):
"""碰撞检测"""
pass
def __update_sprites(self):
"""更新精灵组"""
pass
@staticmethod
def __game_over():
"""游戏结束"""
print("游戏结束")
pygame.quit()
exit()
03. 准备游戏精灵组
3.1 确定精灵组
3.2 代码实现
-
创建精灵组方法
def __create_sprites(self):
"""创建精灵组"""
# 背景组
self.back_group = pygame.sprite.Group()
# 敌机组
self.enemy_group = pygame.sprite.Group()
# 英雄组
self.hero_group = pygame.sprite.Group()
-
更新精灵组方法
def __update_sprites(self):
"""更新精灵组"""
for group in [self.back_group, self.enemy_group, self.hero_group]:
group.update()
group.draw(self.screen)
游戏背景
目标
-
背景交替滚动的思路确定
-
显示游戏背景
01. 背景交替滚动的思路确定
运行 备课代码,观察 背景图像的显示效果:
-
游戏启动后,背景图像 会 连续不断地 向下方 移动
-
在 视觉上 产生英雄的飞机不断向上方飞行的 错觉 —— 在很多跑酷类游戏中常用的套路
-
游戏的背景 不断变化
-
游戏的主角 位置保持不变
-
1.1 实现思路分析
解决办法
-
创建两张背景图像精灵
-
第
1张 完全和屏幕重合 -
第
2张在 屏幕的正上方
-
-
两张图像 一起向下方运动
-
self.rect.y += self.speed
-
-
当 任意背景精灵 的
rect.y >= 屏幕的高度说明已经 移动到屏幕下方 -
将 移动到屏幕下方的这张图像 设置到 屏幕的正上方
-
rect.y = -rect.height
-
1.2 设计背景类
-
初始化方法
-
直接指定 背景图片
-
is_alt判断是否是另一张图像-
False表示 第一张图像,需要与屏幕重合 -
True表示 另一张图像,在屏幕的正上方
-
-
-
update() 方法
-
判断 是否移动出屏幕,如果是,将图像设置到 屏幕的正上方,从而实现 交替滚动
-
继承 如果父类提供的方法,不能满足子类的需求:
派生一个子类
在子类中针对特有的需求,重写父类方法,并且进行扩展
02. 显示游戏背景
2.1 背景精灵的基本实现
-
在
plane_sprites新建Background继承自GameSprite
class Background(GameSprite):
"""游戏背景精灵"""
def update(self):
# 1. 调用父类的方法实现
super().update()
# 2. 判断是否移出屏幕,如果移出屏幕,将图像设置到屏幕的上方
if self.rect.y >= SCREEN_RECT.height:
self.rect.y = -self.rect.height
2.2 在 plane_main.py 中显示背景精灵
-
在
__create_sprites方法中创建 精灵 和 精灵组 -
在
__update_sprites方法中,让 精灵组 调用update()和draw()方法
__create_sprites方法
def __create_sprites(self):
# 创建背景精灵和精灵组
bg1 = Background("./images/background.png")
bg2 = Background("./images/background.png")
bg2.rect.y = -bg2.rect.height
self.back_group = pygame.sprite.Group(bg1, bg2)
__update_sprites方法
def __update_sprites(self):
self.back_group.update()
self.back_group.draw(self.screen)
2.3 利用初始化方法,简化背景精灵创建
思考 —— 上一小结完成的代码存在什么样的问题?能否简化?
-
在主程序中,创建的两个背景精灵,传入了相同的图像文件路径
-
创建 第二个 背景精灵 时,在主程序中,设置背景精灵的图像位置
思考 —— 精灵 初始位置 的设置,应该 由主程序负责?还是 由精灵自己负责?
答案 —— 由精灵自己负责
-
根据面向对象设计原则,应该将对象的职责,封装到类的代码内部
-
尽量简化程序调用一方的代码调用
-
初始化方法
-
直接指定 背景图片
-
is_alt判断是否是另一张图像-
False表示 第一张图像,需要与屏幕重合 -
True表示 另一张图像,在屏幕的正上方
-
-
在 plane_sprites.py 中实现 Background 的 初始化方法
def __init__(self, is_alt=False):
image_name = "./images/background.png"
super().__init__(image_name)
# 判断是否交替图片,如果是,将图片设置到屏幕顶部
if is_alt:
self.rect.y = -self.rect.height
-
修改
plane_main的__create_sprites方法
# 创建背景精灵和精灵组 bg1 = Background() bg2 = Background(True) self.back_group = pygame.sprite.Group(bg1, bg2)
"""输入1000以内的素数及其这些素数的和"""
n = 1000
s = 0
print("1000以内的素数为:", end='')
while n >= 3:
for i in range(2, int(n ** 0.5 + 1)):
if n % i == 0:
break
else:
print(n, end=' ')
s = n + s
n = n - 1
print("\n1000以内的素数的和为:%d" % (s + 2))
def factors(n):
iffactor = False
print("该数除了1和自身以外的因子为:")
for i in range(2, int(n // 2) + 1):
if n % i == 0:
print(i, end=' ')
iffactor = True
if not iffactor:
print("无")
num = input("请从键盘输入一个数:")
factors(int(num))
class Vehicle(object):
def __init__(self, wheels, weight):
self.setWheels(wheels)
self.setWeight(weight)
def setWheels(self, wheels):
self.whells = wheels
def setWeight(self, weight):
self.weight = weight
def getWhells(self):
return self.whells
def getWeight(self):
return self.weight
def display(self):
print("汽车车轮个数为:%s,汽车的重量为%s 吨" % (self.whells, self.weight))
class Car(Vehicle):
def __init__(self, wheels, weight, passenger_load='4'):
super(Car, self).__init__(wheels, weight)
self.passenger_load = passenger_load
def display(self):
super(Car, self).display()
print("该汽车为小汽车,载客为:%s" % self.passenger_load)
class Truk(Vehicle):
def __init__(self, wheels, weight, passenger_load, load):
super(Truk, self).__init__(wheels, weight)
self.passenger_load = passenger_load
self.load = load
def display(self):
super(Truk, self).display()
print("该汽车为货车,载客为:%s,载重为:%s 吨" % (self.passenger_load, self.load))
if __name__ == '__main__':
car_passenger_load = input("请输入小汽车的载客数量:")
truk_passenger_load = input("请输入货车的载客数量:")
truk_load = input("请输入货车的载重量:")
car = Car(4, 2, car_passenger_load)
car.display()
truk = Truk(4, 10, truk_load, truk_passenger_load)
truk.display()
class Person(object): # Person类
def __init__(self, number, name):
self.set_number(number)
self.set_name(name)
def set_number(self, number):
self.number = number
def set_name(self, name):
self.name = name
def get_number(self):
return self.number
def get_name(self):
return self.name
def print_number_name(self):
print("编号为:%s,姓名为:%s" % (self.get_number(), self.get_name()), end=",")
class Student(Person):
def __init__(self, number, name, classnumber, grade):
super(Student, self).__init__(number, name)
Person.__init__(self, number, name)
self.set_classnumber(classnumber)
self.set_grade(grade)
# 设置Student类中的set和get方法
def set_classnumber(self, classnumber):
self.classnumber = classnumber
def set_grade(self, grade):
self.grade = grade
def get_classnumber(self):
return self.classnumber
def get_grade(self):
return self.grade
def print_classnumber_grade(self):
print("学生", end="--->")
# 调用Person类中的输出编号和姓名的方法
super(Student, self).print_number_name()
print("班号:%s,成绩:%s" % (self.get_classnumber(), self.get_grade()))
class Teacher(Person):
def __init__(self, number, name, title, department):
super(Teacher, self).__init__(number, name)
Person.__init__(self, number, name)
self.set_title(title)
self.set_department(department)
# 设置Teacher类中的set和get方法
def set_title(self, title):
self.title = title
def set_department(self, department):
self.department = department
def get_title(self):
return self.title
def get_department(self):
return self.department
# 调用Person类中的输出编号和姓名的方法
def print_title_department(self):
print("老师", end="--->")
super(Teacher, self).print_number_name()
print("称号:%s,部门:%s" % (self.get_title(), self.get_department()))
if __name__ == '__main__':
# 使用户输入学生和老师的信息
list1 = input("请输入学生的编号,姓名,班号,成绩(用空格分隔):")
list2 = input("请输入老师的编号,姓名,班号,成绩(用空格分隔):")
# 把用户输入的字符串类型的信息通过map()方法和split()方法转化为列表
list_student = list(map(str, list1.split(' ')))
list_teacher = list(map(str, list2.split(' ')))
student = Student(list_student[0], list_student[1], list_student[2], list_student[3])
teacher = Teacher(list_teacher[0], list_teacher[1], list_teacher[2], list_teacher[3])
# 分别调用两个类中的输出信息方法
student.print_classnumber_grade()
teacher.print_title_department()














 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









