









Spark安装配置【全网最全保姆级教程】
前提
JDK 1.8
Hadoop 3.1.3(伪分布式)
Hadoop安装教程:
https://duanyx.blog.csdn.net/article/details/138035064?spm=1001.2014.3001.5502
在上述教程中已经配置
本教程安装内容
Spark 3.0.0
Scala 2.12.8
py4j
Pyspark
注:**【此教程版本】**Spark3.0.0对应的是Python3.8即Ubuntu自带的Python版本,所以如果你的Ubuntu版本为20,那么就下载Spark3.0.0的
注:**【其他版本问题】**如果在Ubuntu20.0版本下载2.4.0版本的Spark,系统自带的版本是3.8,2.4.0版本的Spark兼容python3.6,只能改系统版本,但是改了之后,再次开机会打不开终端
注:**【关于Spark是否只用安装Spark】**❌错的,Spark不能只安装Spark,还要安装对应的Scala,py4j,配置环境遍历,不然之后的代码跑不通的
1、安装Spark3.0.0
网址:Index of /dist/spark/spark-3.0.0 (apache.org)
在上述网址中安装Spark3.0.0
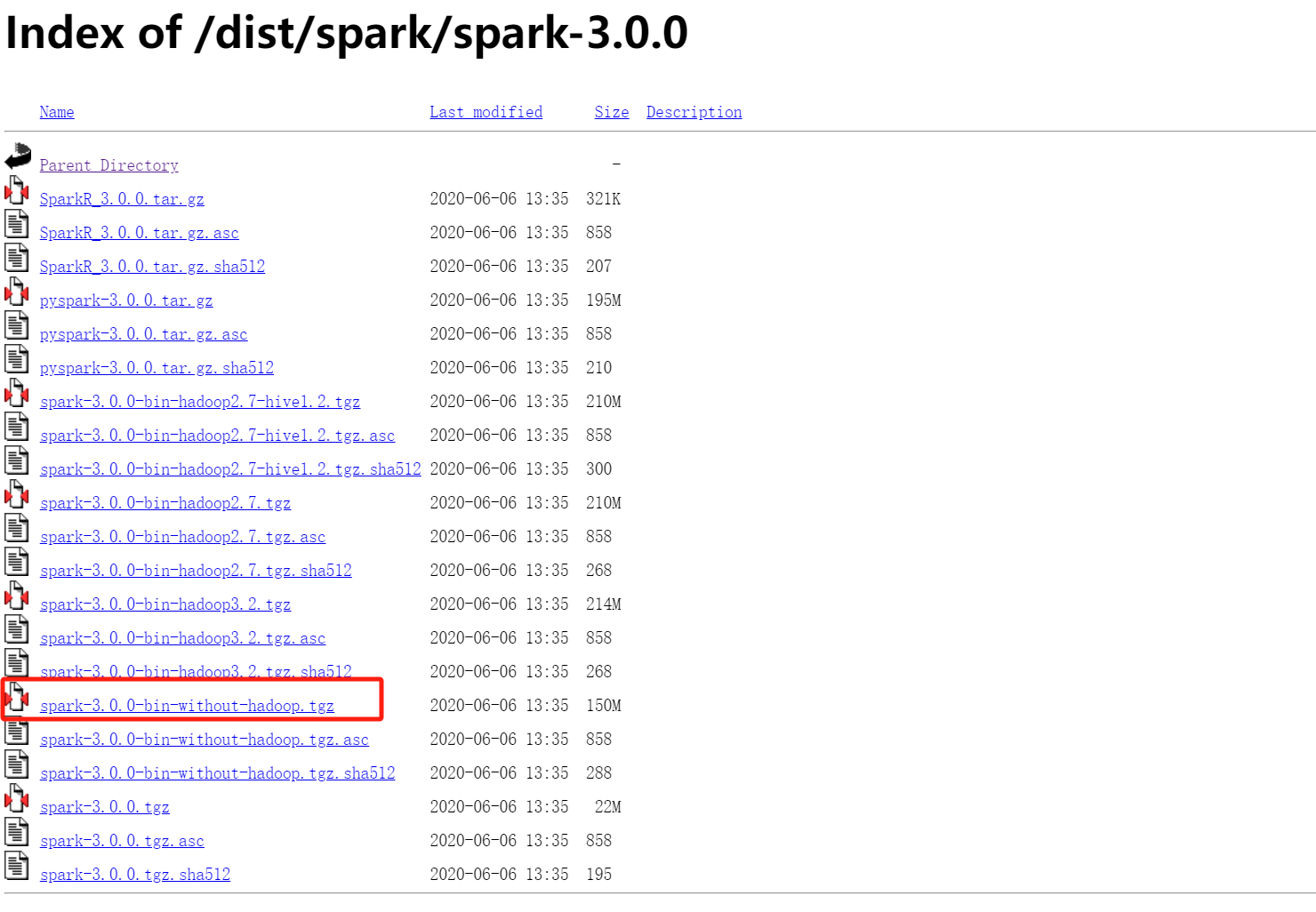
放置在Ubuntu的Downloads文件夹中
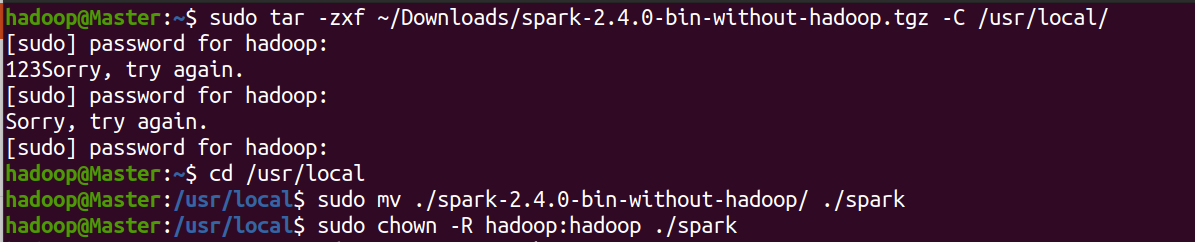
sudo tar -zxf ~/Downloads/spark-3.0.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-3.0.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
安装后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh

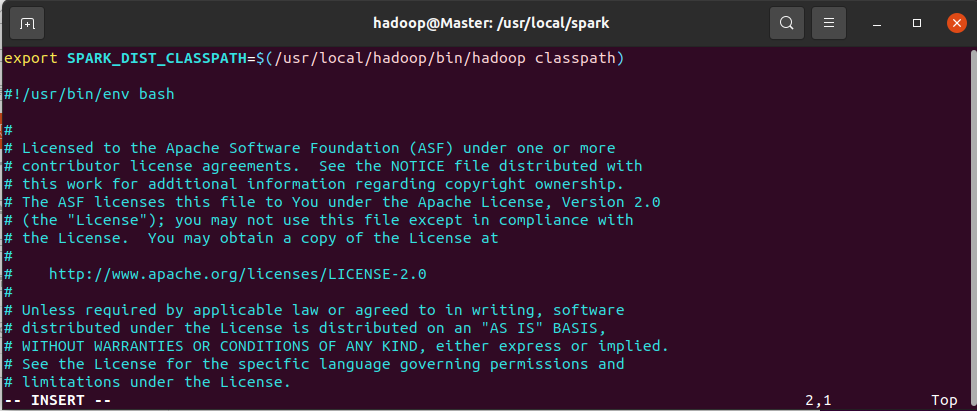
编辑spark-env.sh文件,在第一行添加以下配置信息:
vim ./conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功:(此步可以略过)
cd /usr/local/spark
bin/run-example SparkPi
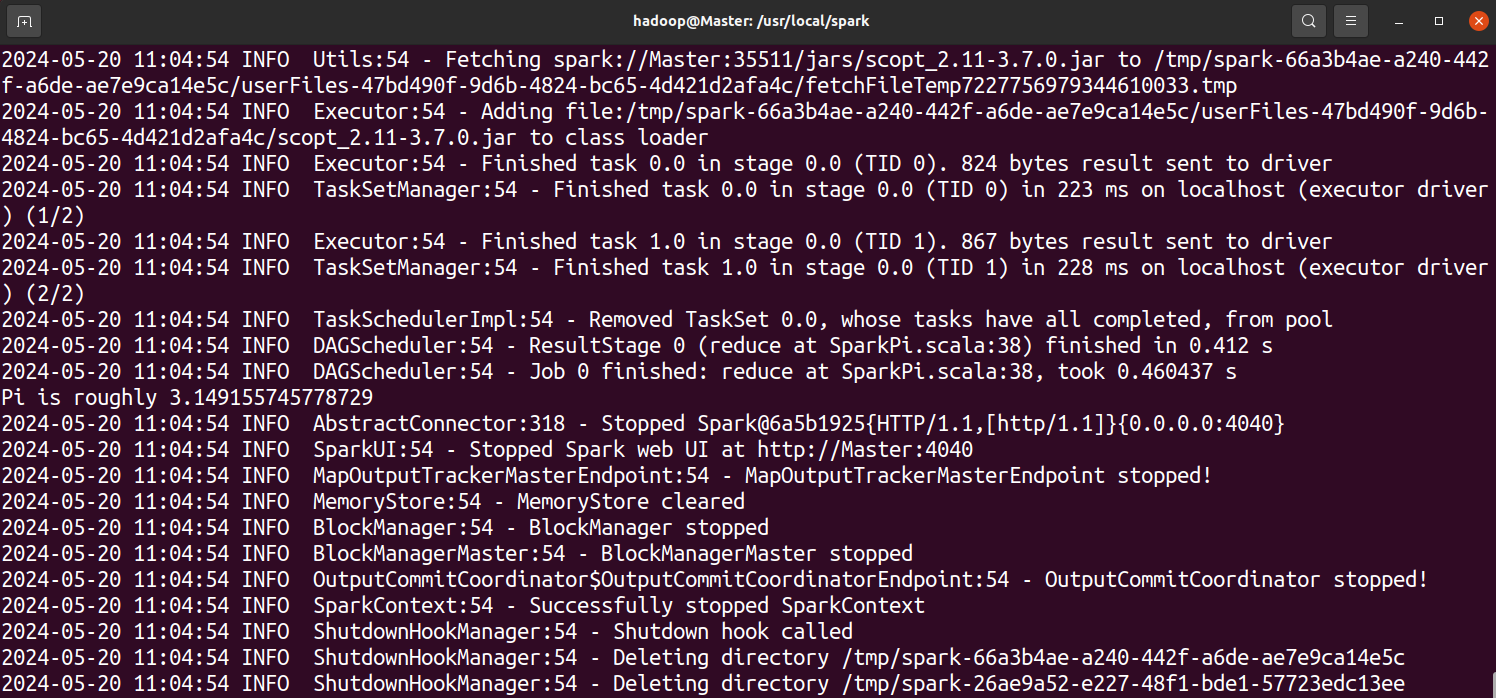
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep "Pi is"

使用 Spark Shell 编写代码(此步可以略过)
cd /usr/local/spark
bin/spark-shell
到了这里会出现两个报错(此步可以略过,有强迫症即可解决)
报错1:
[ERROR] Failed to construct terminal; falling back to unsupported
java.lang.NumberFormatException: For input string: "0x100"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.valueOf(Integer.java:766)
at scala.tools.jline_embedded.internal.InfoCmp.parseInfoCmp(InfoCmp.java:59)
at scala.tools.jline_embedded.UnixTerminal.parseInfoCmp(UnixTerminal.java:242)
at scala.tools.jline_embedded.UnixTerminal.<init>(UnixTerminal.java:65)
at scala.tools.jline_embedded.UnixTerminal.<init>(UnixTerminal.java:50)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at java.lang.Class.newInstance(Class.java:442)
at scala.tools.jline_embedded.TerminalFactory.getFlavor(TerminalFactory.java:211)
at scala.tools.jline_embedded.TerminalFactory.create(TerminalFactory.java:102)
at scala.tools.jline_embedded.TerminalFactory.get(TerminalFactory.java:186)
at scala.tools.jline_embedded.TerminalFactory.get(TerminalFactory.java:192)
at scala.tools.jline_embedded.console.ConsoleReader.<init>(ConsoleReader.java:243)
at scala.tools.jline_embedded.console.ConsoleReader.<init>(ConsoleReader.java:235)
at scala.tools.jline_embedded.console.ConsoleReader.<init>(ConsoleReader.java:223)
at scala.tools.nsc.interpreter.jline_embedded.JLineConsoleReader.<init>(JLineReader.scala:64)
at scala.tools.nsc.interpreter.jline_embedded.InteractiveReader.<init>(JLineReader.scala:33)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at scala.tools.nsc.interpreter.ILoop$$anonfun$scala$tools$nsc$interpreter$ILoop$$instantiater$1$1.apply(ILoop.scala:858)
at scala.tools.nsc.interpreter.ILoop$$anonfun$scala$tools$nsc$interpreter$ILoop$$instantiater$1$1.apply(ILoop.scala:855)
at scala.tools.nsc.interpreter.ILoop.scala$tools$nsc$interpreter$ILoop$$mkReader$1(ILoop.scala:862)
at scala.tools.nsc.interpreter.ILoop$$anonfun$22$$anonfun$apply$10.apply(ILoop.scala:873)
at scala.tools.nsc.interpreter.ILoop$$anonfun$22$$anonfun$apply$10.apply(ILoop.scala:873)
at scala.util.Try$.apply(Try.scala:192)
at scala.tools.nsc.interpreter.ILoop$$anonfun$22.apply(ILoop.scala:873)
at scala.tools.nsc.interpreter.ILoop$$anonfun$22.apply(ILoop.scala:873)
at scala.collection.immutable.Stream$$anonfun$map$1.apply(Stream.scala:418)
at scala.collection.immutable.Stream$$anonfun$map$1.apply(Stream.scala:418)
at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1233)
at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1223)
at scala.collection.immutable.Stream.collect(Stream.scala:435)
at scala.tools.nsc.interpreter.ILoop.chooseReader(ILoop.scala:875)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1$$anonfun$newReader$1$1.apply(SparkILoop.scala:184)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1$$anonfun$newReader$1$1.apply(SparkILoop.scala:184)
at scala.Option.fold(Option.scala:158)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.newReader$1(SparkILoop.scala:184)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.org$apache$spark$repl$SparkILoop$$anonfun$$preLoop$1(SparkILoop.scala:188)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1$$anonfun$startup$1$1.apply(SparkILoop.scala:249)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1$$anonfun$startup$1$1.apply(SparkILoop.scala:247)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.withSuppressedSettings$1(SparkILoop.scala:235)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.startup$1(SparkILoop.scala:247)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.apply$mcZ$sp(SparkILoop.scala:282)
at org.apache.spark.repl.SparkILoop.runClosure(SparkILoop.scala:159)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:182)
at org.apache.spark.repl.Main$.doMain(Main.scala:78)
at org.apache.spark.repl.Main$.main(Main.scala:58)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:845)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:920)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:929)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
解决1:
gedit ~/.bashrc
export TERM=xterm-color # 添加
source ~/.bashrc # 使其生效
报错2:
WARN NativeCodeLoader:60 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决2:
vim ~/.bashrc
export JAVA_LIBRAY_PATH=/usr/local/hadoop/lib/native
source ~/.bashrc
然后切换到spark目录下
cd /usr/local/spark
vim conf/spark-env.sh
export LD_LIBRARY_PATH=$JAVA_LIBRARY_PATH # 添加命令
再次启动Spark Shell
cd /usr/local/spark
bin/spark-shell
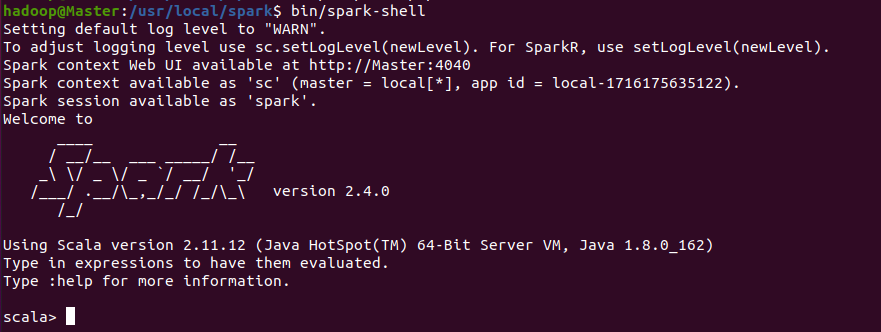
退出Spark Shell
:quit
2、安装Scala
wget https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.deb
sudo dpkg -i scala-2.12.8.deb
scala -version
3、安装 py4j
Py4J在驱动程序上用于Python和Java SparkContext对象之间的本地通信;大型数据传输是通过不同的机制执行的。
sudo pip install py4j
如果使用pip报错:
使用下面的命令进行解决
先使用命令(99%报错问题不大)
sudo apt install python3-pip
再解决
sudo apt-get remove python-pip-whl
sudo apt -f install
sudo apt update && sudo apt dist-upgrade
sudo apt install python3-pip
4、配置环境变量
vim ~/.bashrc
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#上述是我的,根据自己的配置自行斟酌,但是必须有Java的环境遍历
#下面的是必要的,不要改动
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
source ~/.bashrc
5、启动pyspark
控制台直接输入pyspark即可
pyspark
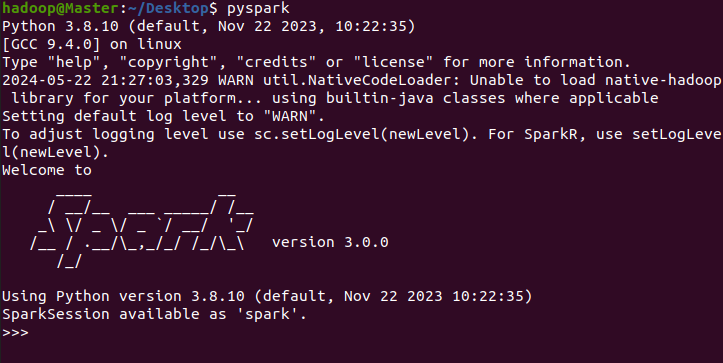
上述安装Spark即完成
不建议使用Pyspark进行关于Spark的Python编程
安装VScode教程如下
Ubuntu安装VScode
链接下载
https://code.visualstudio.com/
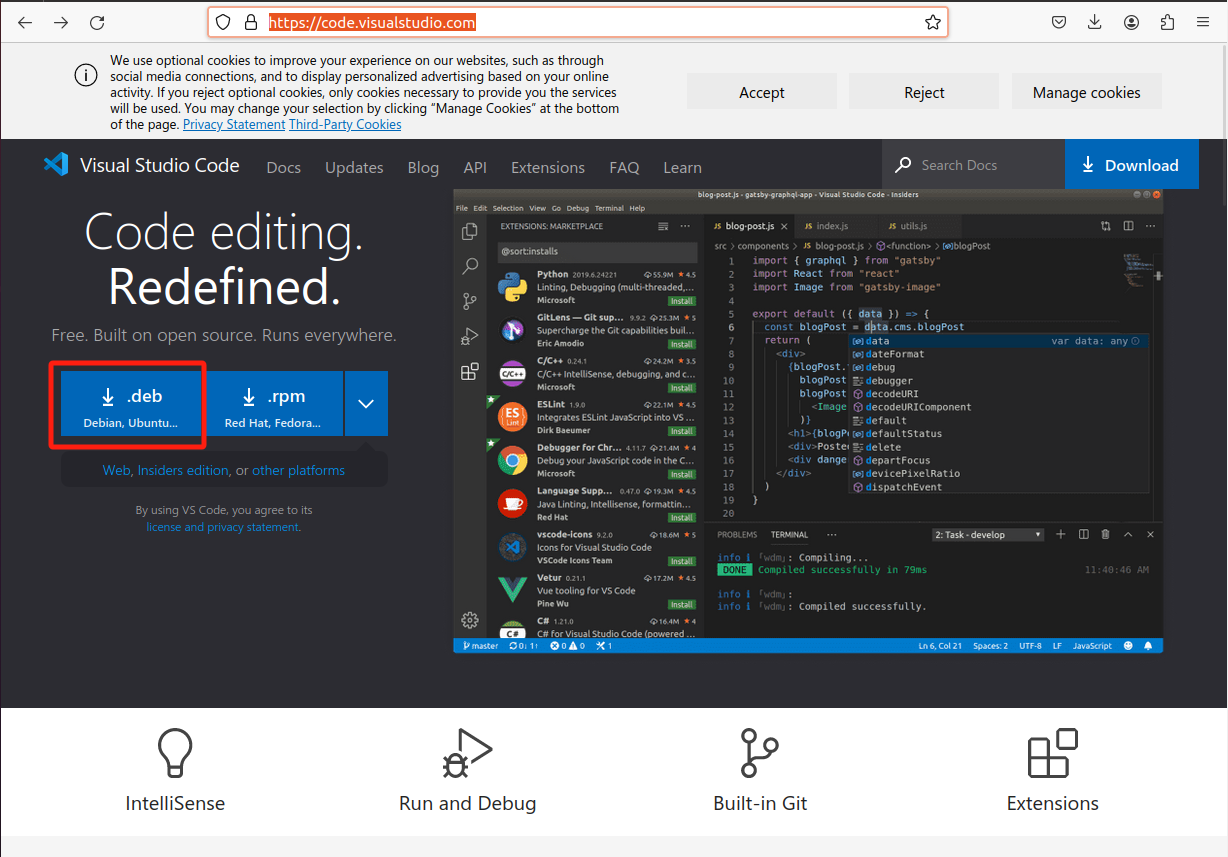
cd Downloads
sudo dpkg -i code_*.deb
打开
code
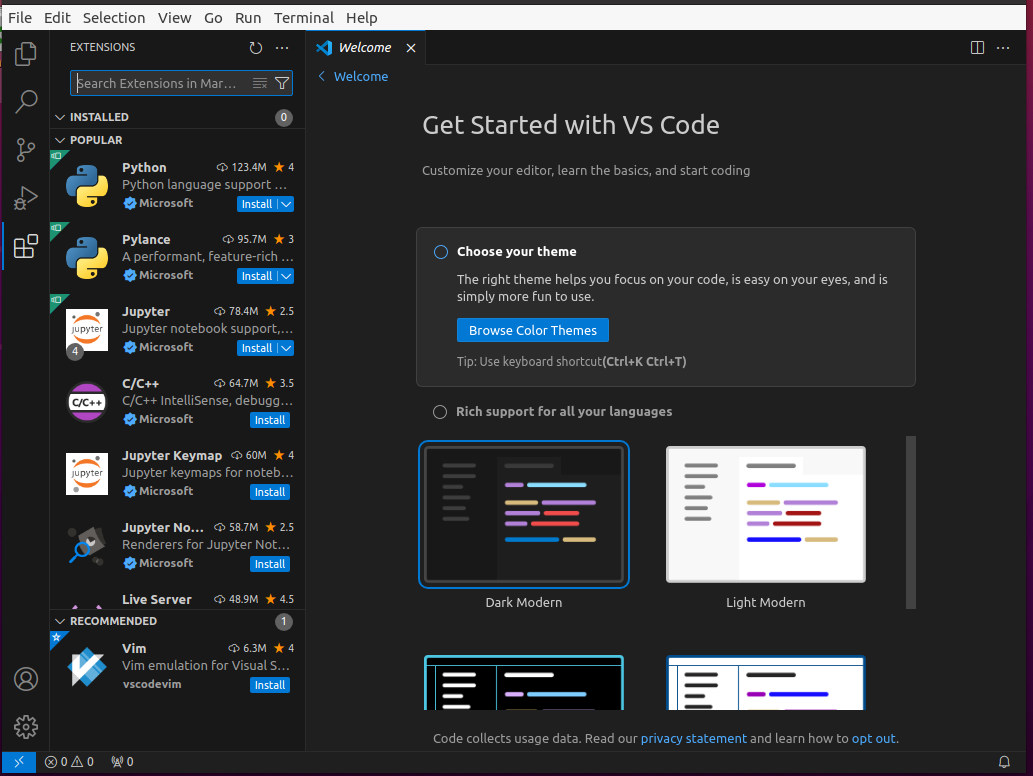
若想使用Python编程,则开始下面的配置
配置python
选择第一个,点击install















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









