







1、字符集与编码格式
字符集:定义每个字符对应的数字,便于以字节方式存储在计算机中。
编码格式:如何将对应字符在字符集里的数字,转换为二进制格式,让计算机识别不同字符。
需要注意的是,有时候字符集与编码格式对应(比如GBK),这时字符集又叫字符集编码,即指字符集,又指对应编码方式。有时候,字符集与编码格式不一一对应,比如Unicode字符集对应了utf-8、utf-16、utf-32等三种编码方式。
码点:一个字符在字符集中对应的值,'A’对应码点为65
代码单元(码元):对编码格式而言,将码点转换为二进制所需的最小存储单元。比如utf-8的码元为1B,utf-16为2B
所以一个码点可能对应多个代码单元
更具体的文章
2、UTF-8与UTF-16编码方式
UTF-8

红色部分用来识别码点范围,黑色部分表示码点值
UTF-16
utf-16采用2个字节作为码元。
- 当字符的码点为0~65532时,则直接使用两字节表示。
- 当字符码点为0xD800 ~ 0xDFFF时,采用四个字节来表示。高位两个字节的范围为0xD800 ~ 0xDBFF,低位两个字节的范围为0xDC00 ~ 0xDFFF
码点为(0xD800 ~ 0xDFFF)的计算方法:
- 将码点值减去0X10000,得到一个20位长的二进制数
- 将这个二进制数分为高10位与低10位
- 20位长的高10位比特加上0xD800得到高位两个字节
- 20位长的低10位比特加上0xDC00得到低位两个字节
- 将高位字节与低位字节组合
因为0xD800 ~ 0xDBFF需要用来表示范围超过65535的字符,所以在0xD800 ~ 0xDBFF范围内,Unicode表没有对应字符。
UTF-16一次编码多个字节,所以在写入、读取时涉及到大小端问题。utf-8一次只编码一个字节,每一个字节都存在标识,所以不存在大小端问题。
那么UTF-16是怎么解决大小端问题呢?答案是使用BOM来实现
BOM(byte-order mark)----字节顺序标记
字节顺序标记(英语:byte-order mark,BOM)是一个有特殊含义的统一码字符,码点为U+FEFF。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。经常被用于区分是否为UTF编码。
字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前。如果它出现在字节流的中间,则表达零宽度非换行空格的意义,用户看起来就是一个空格。从Unicode3.2开始,U+FEFF只能出现在字节流的开头,只能用于标识字节序,就如它的名称——字节序标记——所表示的一样;除此以外的用法已被舍弃。取而代之的是,使用U+2060来表达零宽度无断空白。
UTF-8以字节为编码单元,没有字节序的问题。但是某些操作系统也会使用带BOM的UTF-8,叫做UTF-8 with BOM。Python中叫utf-8-sig。Unicode规范中说明UTF-8不必也不推荐使用BOM。多数时候UTF-8都是不带BOM的,但是微软公司的某些软件(如Excel)打开某些不带BOM的utf8文件(如cvs文件)会乱码,需要转换成带BOM的utf8编码才能正常显示。
所以Java中获取以UTF-16编码的字符串字节个数时,总是会比实际含有字符的字节个数多2。不过目前已经有很多主流的文本编辑器支持不带BOM的UTF编码了,通过后缀(LE和BE)区分是小端还是大端。
3、Java中的编码
用一张图来讲,就如下图
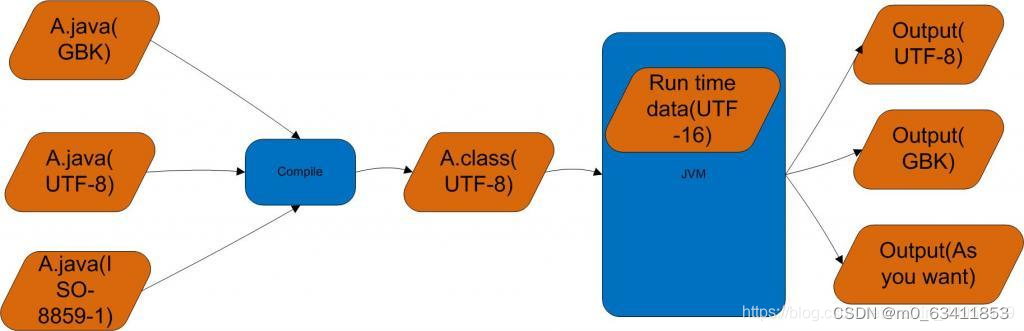
下面对这张图进行讲解:
1、源码的编码可以是任意的,但是编译时会采用系统默认的编码,如果源码与系统编码不一致,就可能报错,比如用GBK来编译UTF-16源码,如果源码中有中文就可能报错。
2、可以用-Dfile.encoding=UTF-8来指定系统默认编码,告诉编译器用什么编码来读取源码
3、编译后形成的.class文件为modified utf-8编码,这个编码不同于utf-8,具体不同可查看上文的链接。所以编译器将源码编码转换成了modified utf-8编码
4、所以在Java内部数据(指.class文件到JVM运行之间)是统一使用modified UTF-8进行编码的,这个编码解码出来的码元是UTF-16编码出来的2字节。JVM把UTF-16编码出来的16位长的数据(2字节,操作系统用8位长的数据,即1字节)作为最小单位进行信息交换。
内码与外码
内码是程序内部使用的字符编码,特别是某种语言实现其char或String类型在内存里用的内部编码;外码是程序与外部交互时外部使用的字符编码。
补充
Java中将字符转换为Byte数组,是得到字符编码后的01序列。比如在utf-8下,a编码后为0x41,在utf-16下,a编码后为0x0041















 8340
8340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









