






redis中的dict和java中的hashmap有部分相同:
1、哈希映射,key的索引计算公式是hash&(n-1),其中hash为key对应的hash值(通过murmurhash算法计算得出)
2、redis通过链地址法解决哈希冲突。
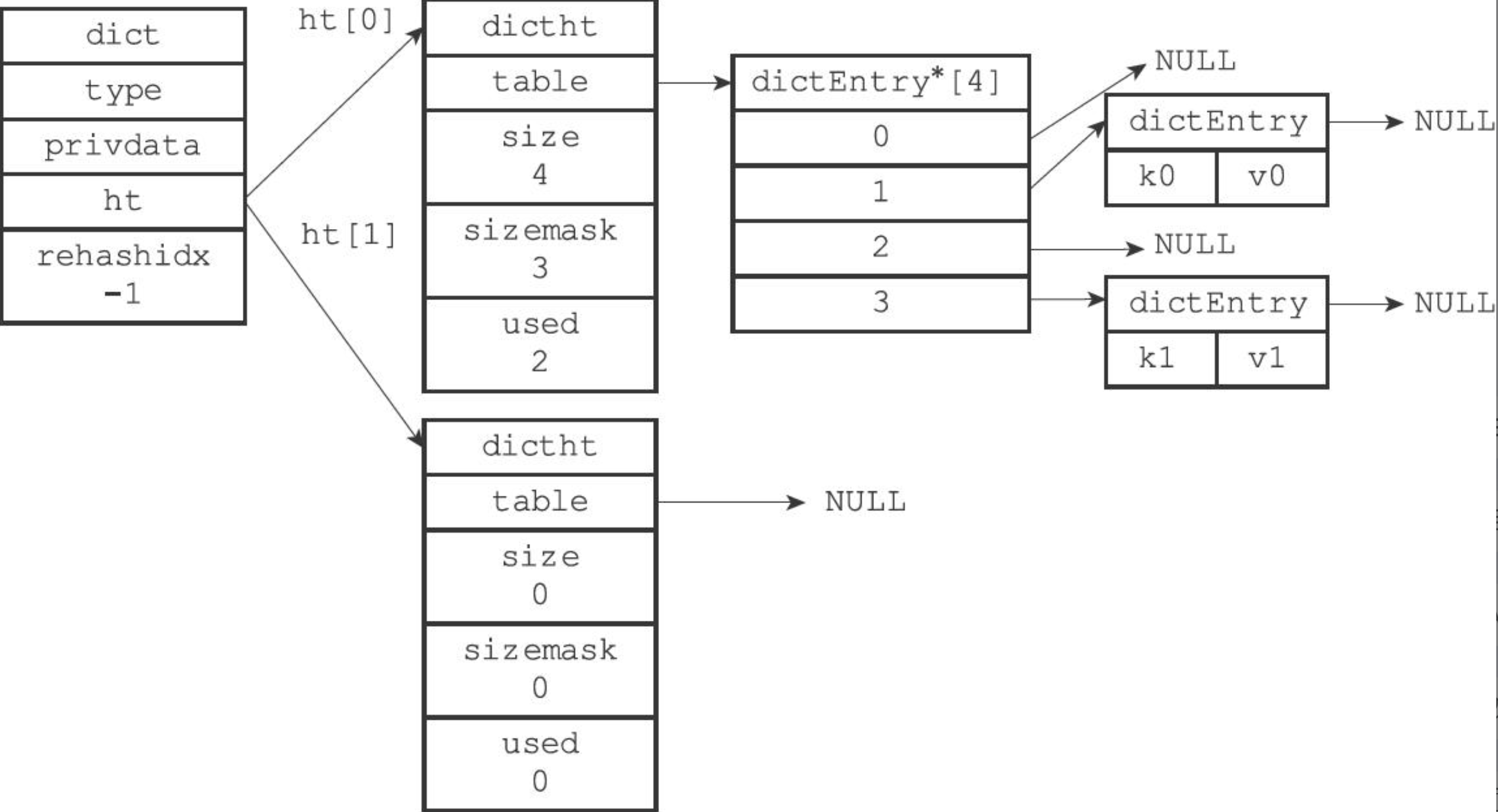
dict的数据结构
typedef struct dict {
dictType *type; //类型特定函数
void *privdata; //私有数据
dictht ht[2]; //2个哈希表,哈希表负载过高进行rehash的时候才会用到第2个哈希表
int rehashidx; //rehash目前进度,当哈希表进行rehash的时候用到,其他情况下为-1
}dict;type属性是一个指向dictType结构的指针,里面存放了一些用于操作特定类型键值对的函数
privdata属性则保存了需要传给那些类型特定函数的可选参数
ht[2] 数组中存放了两张哈希表,只有在 rehash 的过程中,ht[0] ht[1] 才都有效;正常情况下只有 ht[0] 有效,ht[1] 中没有任何数据
rehashidx 用来表示 rehash 过程到了哪一个索引位置,正常情况下 rehashidx = -1,表示当前没有进行 rehash
dictht的结构
typedef struct dictht {
dictEntry **table; //哈希表数组
unsigned long size; //哈希表大小,即哈希表数组大小
unsigned long sizemask; //哈希表大小掩码,总是等于size-1,主要用于计算索引
unsigned long used; //已使用节点数,即已使用键值对数C
}dictht;dictEntry 数组,用来存放键值对
size 表示当前 dictEntry 数组的大小
sizemask,值为 size - 1,在计算 key 的索引位置时用到, index = hash & sizemask
used 记录现有 dict 的数据个数
dictType的定义
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //计算哈希值
void *(*keyDup)(void *privdata, const void *key); //复制键
void *(*valDup)(void *privdata, const void *obj); //复制值
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //对比键
void (*keyDestructor)(void *privdata, void *key); //销毁键
void (*valDestructor)(void *privdata, void *obj); //销毁值
}dictType;其中包括了一些用于操作特定类型键值对的函数。
dictEntery定义
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64; //uint64_t整数
int64_t s64; //int64_t整数
}v;
struct dictEntry *next; //指向下个哈希表节点
}dictEntry;其中next就是为了解决hash冲突,也就是链地址法。
dict的数据结构
随着我们操作的进行,哈希表中的值对会怎加或者减少,为了让负载因子(已保存节点数量/哈希表大小)保持在合理的状态下,redis会进行扩容或者缩容,这个操作就叫做rehash。
rehash
通过ht[1]来进行rehash操作,首先会给ht[1]分配地址(比h[0]的used的两倍大的最近的2的倍数),然后将rehashidx设置为0,这时就会把ht[0]上rehashidx所对应的的值对rehash到h[1]上面
,然后rehashidx的值就加1,直到结束,并将h[1]给到h[0],将rehashidx置为-1,此时rehash结束.
dict的插入过程
1、先通过Murmurhash算法算出hash值
hash = dict->type->hashFunction(key)
2、借助sizemask和hash值算出索引
index = hash & dict->ht[x].sizemask
3、通过索引去找到dictEntery的数组下标,如果没有数据就直接加进去,如果有就通过头插法添加进去(因为没有尾指针),此时的时间复杂度为O(1)















 5389
5389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









