







文章目录
Maven
Maven 核心9个概念
1.项目对象模型(POM):Maven对项目信息的管理核心,通过pom.xml文件体现。
这个模型包含了项目的基本信息、构建配置、依赖关系等关键信息,使得Maven能够自动化的处理项目的构建、报告和文档。
2.约定的目录结构:Maven按照约定的目录结构来组织项目,包括源代码、资源文件和测试代码的存放位置。
3.坐标:用于确定某个项目的唯一性,GAV相关信息共同定义了一个项目在中央仓库中的精准位置。
4.依赖管理:涉及直接/间接以来的处理、依赖范围的确定和依赖传递性的管理。
解决依赖冲突:
- 最短路径优先
- 最短依赖路径相同的时候,先声明优先
- 或者手动排除依赖
5.仓库管理: 本地 / 私服 /镜像 /中央 四个仓库
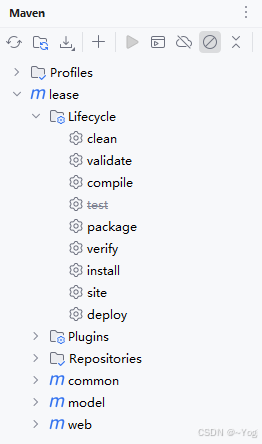
6.生命周期:clean、default 、 site 三个周期。生命周期为构建过程提供了清晰的划分,让开发者能够更好的控制构建的各个阶段。
7.插件和目标:插件负责实际执行Maven生命周期中的特定任务。通过配置插件 / 目标 ,开发者可以自定义构建过程中的行为,满足项目的特殊需求。
8.继承:允许一个项目中引用另一个项目的POM配置,实现了配置复用和统一管理,降低了维护成本增加了唯一性。
9.聚合:允许同时构建多个相关联的项目,对于大型多模块项目的管理很重要。
Maven 依赖范围传递规则
| 第一直接依赖的范围 | 第二直接依赖的范围 | 传递性依赖的范围 |
|---|---|---|
| compile | compile | compile |
| compile | test | 不传递 |
| compile | provided | 不传递 |
| compile | runtime | runtime |
| test | compile | test |
| test | runtime | test |
| provided | provided | provided |
| provided | runtime | provided |
| 场景描述 | 版本选择规则 |
|---|---|
多条路径引入不同版本(如 X(1.0) 和 X(2.0)) | 选择路径最短的版本;路径相同则选声明顺序靠前的版本 |
| 直接依赖显式声明版本 | 显式声明的版本优先覆盖传递性依赖版本 |
如果需要进一步调整格式,请告诉我!
SpringMVC
常用注解
常用的SpringMVC注解及其解释:
@RestController
是一个特殊的@Controller注解,结合了@Controller和@ResponseBody的功能
@Controller
定义:@Controller是一个特殊的@Component注解,用于标识一个类作为SpringMVC的控制器。
作用:将该类标记为SpringMVC的控制器,使其能够处理HTTP请求并返回视图或数据。
@RequestMapping
定义:@RequestMapping是一个用于映射Web请求到特定处理方法的注解。
作用:可以用于类级别和方法级别,指定URL路径、HTTP方法等信息,以确定哪些请求由哪个方法处理。
@GetMapping
定义:@GetMapping是一个组合注解,相当于@RequestMapping(method = RequestMethod.GET)。
作用:专门用于处理HTTP GET请求,简化了请求映射的配置。
@PostMapping
定义:@PostMapping是一个组合注解,相当于@RequestMapping(method = RequestMethod.POST)。
作用:专门用于处理HTTP POST请求,简化了请求映射的配置。
@PutMapping
定义:@PutMapping是一个组合注解,相当于@RequestMapping(method = RequestMethod.PUT)。
作用:专门用于处理HTTP PUT请求,简化了请求映射的配置。
@DeleteMapping
定义:@DeleteMapping是一个组合注解,相当于@RequestMapping(method = RequestMethod.DELETE)。
作用:专门用于处理HTTP DELETE请求,简化了请求映射的配置。
@PathVariable
定义:@PathVariable用于将URL中的模板变量绑定到方法参数上。
作用:从URL中提取值并将其赋给方法参数,常用于RESTful风格的URL设计。
@RequestParam
定义:@RequestParam用于将请求参数绑定到方法参数上。
作用:从HTTP请求中提取查询参数或表单参数,并将其赋给方法参数。
@RequestBody
定义:@RequestBody用于将HTTP请求体绑定到方法参数上。
作用:通常用于处理JSON或XML格式的请求体,将其转换为Java对象。
@ResponseBody
定义:@ResponseBody用于将方法的返回值直接写入HTTP响应体中。
作用:通常与@RequestBody结合使用,用于创建RESTful API,返回JSON或XML格式的数据。
@ModelAttribute
定义:@ModelAttribute用于将请求参数绑定到一个模型属性上,并将其添加到模型中。
作用:常用于预处理请求数据,如表单提交时的数据绑定。
@CookieValue
定义:@CookieValue是一个用于将HTTP请求中的特定Cookie值绑定到控制器方法参数上的注解。
作用:从请求中提取指定的Cookie值,并将其赋给方法参数,常用于需要读取客户端发送的Cookie信息的场景
@RequestHeader
定义:@RequestHeader是一个用于将HTTP请求中的特定头信息绑定到控制器方法参数上的注解。
作用:从请求中提取指定的头信息,并将其赋给方法参数,常用于需要读取客户端发送的头信息的场景
Rest风格
RESTful架构风格是一种基于HTTP协议的Web服务设计方法,它通过定义一组约束和原则来确保Web服务的可扩展性、可维护性和可操作性。
RESTful架构风格的四种主要请求方式是GET、POST、PUT和DELETE。以下是对这四种请求方式的详细解释:
GET请求
用途:用于从服务器检索资源。
幂等性:是,即多次执行相同的GET请求应该总是返回相同的结果。
安全性:是,因为GET请求不应该改变服务器上的资源状态。
POST请求
用途:用于在服务器上创建新的资源。
幂等性:否,因为每次POST请求都会创建新的资源。
安全性:否,因为POST请求会改变服务器上的资源状态。
PUT请求
用途:用于更新服务器上的现有资源。与POST请求不同,PUT请求通常用于替换整个资源的内容。
幂等性:是,即多次执行相同的PUT请求应该总是得到相同的结果(资源被更新到相同的状态)。
安全性:否,因为PUT请求会改变服务器上的资源状态。
DELETE请求
用途:用于从服务器删除资源。
幂等性:是,即多次执行相同的DELETE请求应该总是得到相同的结果(资源被删除)。
安全性:否,因为DELETE请求会改变服务器上的资源状态。
总的来说,RESTful架构风格通过使用这些标准化的HTTP方法来操作网络上的资源,使得API设计更清晰、简洁,并且易于理解和使用。
这种设计风格强调资源的表现形式(如JSON或XML)和无状态性,每个请求都是独立的,服务器不会在请求之间保存任何客户端状态
SpringMVC控制器如何接受请求数据
主要以下几种:
通过实体Bean接收:这种方式通常用于表单提交的数据,将表单中的字段与Java对象的属性进行绑定。
例如,如果有一个用户注册表单,可以创建一个User类,其中包含用户名、密码等属性,然后在控制器方法中直接使用User类型的参数来接收表单数据。
通过处理方法的形参接收:这种方式是最直接的方式,即在控制器方法中定义与请求参数名称相同的形参。当请求到来时,SpringMVC会自动将请求参数的值a注入到这些形参中。
通过HttpServletRequest接收:这种方式比较灵活,可以直接操作HttpServletRequest对象来获取请求中的所有信息,包括参数、头信息、Cookie等。
通过@PathVariable接收URL中的请求参数:这种方式用于处理RESTful风格的URL,可以通过@PathVariable注解将URL中的变量绑定到控制器方法的参数上。
通过@RequestParam接收请求参数:这种方式用于处理查询字符串中的参数,可以通过@RequestParam注解指定参数的名称和默认值。
通过@ModelAttribute接收请求参数:这种方式通常用于将请求参数绑定到一个模型对象上,可以在多个请求之间共享这个模型对象。
通过JSON参数及@RequestBody接收:这种方式适用于AJAX请求,可以通过@RequestBody注解将请求体中的JSON数据反序列化成一个Java对象。
通过文件上传及MultipartFile接收:这种方式用于处理文件上传,可以通过MultipartFile类型的参数接收上传的文件。
通过请求头及注解@RequestHeader接收:这种方式用于获取请求头中的信息,可以通过@RequestHeader注解指定要获取的请求头名称。
通过Cookie及注解@CookieValue接收:这种方式用于获取请求中的Cookie值,可以通过@CookieValue注解指定Cookie的名称。
总的来说,每种方式都有其特定的应用场景和优势,开发者可以根据实际需求选择最合适的方式来接收请求数据。
自定义token拦截器
yml
# 自定义属性
admin:
auth:
path-patterns:
include: /admin/**
exclude: /admin/login/**,/admin/xxx/**
拦截器
package com.atguigu.lease.web.admin.interceptor;
import com.atguigu.lease.common.context.LoginUser;
import com.atguigu.lease.common.context.LoginUserContext;
import com.atguigu.lease.common.exception.LeaseException;
import com.atguigu.lease.common.result.ResultCodeEnum;
import com.atguigu.lease.common.utils.JwtUtil;
import io.jsonwebtoken.Claims;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import org.springframework.web.servlet.HandlerInterceptor;
@Component
public class AuthenticationInterceptor implements HandlerInterceptor {
//在请求controller接口前进行拦截,校验token令牌
// Json web token -> jwt
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String token = request.getHeader("ACCESS_TOKEN");//获取请求头中令牌
if(StringUtils.isEmpty(token)){
throw new LeaseException(ResultCodeEnum.ADMIN_LOGIN_AUTH); // 未登录
}
Claims claims = JwtUtil.parseToken(token); //令牌合法直接返回true,否则自动抛出异常。
Long userId = claims.get("userId", Long.class);
String username = claims.get("username", String.class);
//如何将数据往线程上绑定。这里使用TheadLocal工具类
LoginUser loginUser = new LoginUser(userId,username);
LoginUserContext.setLoginUser(loginUser);
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
LoginUserContext.clear();
}
}
配置类
package com.atguigu.lease.web.admin.custom.config;
import com.atguigu.lease.web.admin.custom.converter.StringToBaseEnumConverterFactory;
import com.atguigu.lease.web.admin.custom.converter.StringToItemTypeConverter;
import com.atguigu.lease.web.admin.interceptor.AuthenticationInterceptor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.format.FormatterRegistry;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class MvcWebConfiguration implements WebMvcConfigurer {
@Autowired
AuthenticationInterceptor authenticationInterceptor;
@Value("${admin.auth.path-patterns.include}")
private String[] includePathPatterns;
@Value("${admin.auth.path-patterns.exclude}")
private String[] excludePathPatterns;
/* @Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(authenticationInterceptor)
.addPathPatterns("/admin/**")
.excludePathPatterns("/admin/login"); //路径配置应具备可维护性,所以需要配置在yml
}*/
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(authenticationInterceptor)
.addPathPatterns(includePathPatterns)
.excludePathPatterns(excludePathPatterns); //路径配置应具备可维护性,所以需要配置在yml
}
}
swagger
@Tag(name = “”)
@Operation(summary = “”)
@Parameter(name = “”,description = “”,required = true)
@Schema(description = “”)
Ant路径匹配规则
SpringMVC中的Ant路径匹配规则是一种常用的URL模式匹配方式,它使用类似于Ant风格的通配符来匹配URL。以下是一些常见的Ant路径匹配规则:
?:匹配任意单个字符。
*:匹配任意数量的字符(包括零个字符)。
**:匹配任意数量的目录,可以跨越多个层级。
Jackson时区问题
全局解决格式问题:
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss
spring.jackson.time-zone=GMT+8
需要在每个bean Date类型属性上增加格式。
@JsonFormat(pattern = “yyyy-MM-dd HH:mm:ss”)
@JsonIgnore
统一结果
太多模板了
全局异常处理
package com.atguigu.lease.common.exception;
import com.atguigu.lease.common.result.Result;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
/**
* 全局统一异常处理
*/
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
@ResponseBody
public Result exception(Exception e) {
e.printStackTrace();
return yourResult;
}
}
枚举类型转换器
@Component
public class StringToBaseEnumConverterFactory implements ConverterFactory<String, BaseEnum> {
@Override
public <T extends BaseEnum> Converter<String, T> getConverter(Class<T> targetType) {
return string->{
T[] enumConstants = targetType.getEnumConstants();
for (T enumConstant : enumConstants) {
if(enumConstant.getCode().equals(Integer.valueOf(string))){
return enumConstant;
}
}
throw new IllegalArgumentException("参数非法");
};
}
}
@Configuration
public class WebMvcConfiguration implements WebMvcConfigurer {
@Autowired
private StringToBaseEnumConverterFactory stringToBaseEnumConverterFactory;
@Autowired
private LoginIntercepter loginIntercepter;
@Value("${web.admin.path-patterns.include}")
private String [] includePath;
@Value("${web.admin.path-patterns.exclude}")
private String [] excludePath;
@Override
public void addFormatters(FormatterRegistry registry) {
registry.addConverterFactory(stringToBaseEnumConverterFactory);
}
}
@JsonValue
Spring
AOP切面业务
AOP(面向切面编程)是一种编程范式,它允许开发者将横切关注点(如日志记录、事务管理、安全性等)与业务逻辑分离。
在项目中,常见的AOP切面业务有:
日志记录:记录方法的调用情况,包括方法名、参数、返回值以及执行时间等信息。
事务管理:确保数据库操作的一致性和完整性,通常用于处理分布式事务或跨多个服务的操作。
安全检查:验证用户权限、身份认证等,确保只有具备相应权限的用户才能访问特定资源。
缓存管理:对经常访问的数据进行缓存,以减少数据库查询次数,提高系统性能。
异常处理:统一处理项目中抛出的异常,避免在每个方法中重复编写相同的异常处理代码。
性能监控:收集系统运行时的性能数据,如响应时间、吞吐量等,以便分析和优化系统性能。
限流与熔断:防止系统过载,通过限制请求速率或在系统压力过大时自动断开部分功能,保护系统稳定运行。
审计:记录系统中的关键操作,便于后续审计和追踪。
消息队列:异步处理任务,提高系统的并发处理能力。
分布式锁:在分布式系统中实现资源的互斥访问,防止数据竞争和不一致问题。
AOP如何实现缓存管理 / 限流熔断 / 审计 /消息队列 / 分布式锁
以下是基于知识库信息和常见实践的 AOP 实现缓存管理、限流熔断、审计、消息队列、分布式锁 的详细说明:
1. AOP 实现缓存管理
核心思路
通过 自定义注解 + 切面 在方法执行前后插入缓存操作(读取、写入、清除),将缓存逻辑与业务代码解耦。
实现步骤
-
定义注解
定义@Cacheable、@CacheEvict等注解,标记需要缓存的方法:@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface Cacheable { String key(); // 缓存键 long expire() default 0; // 过期时间(秒) } -
编写切面(Aspect)
在切面中拦截带有注解的方法,并实现缓存逻辑:@Aspect @Component public class CacheAspect { @Autowired private RedisTemplate<String, Object> redisTemplate; @Around("@annotation(cacheable)") public Object aroundAdvice(ProceedingJoinPoint joinPoint, Cacheable cacheable) throws Throwable { String key = cacheable.key(); Object result = redisTemplate.opsForValue().get(key); if (result != null) { return result; // 从缓存直接返回 } try { result = joinPoint.proceed(); // 执行业务方法 redisTemplate.opsForValue().set(key, result, cacheable.expire(), TimeUnit.SECONDS); return result; } finally { // 异步刷新缓存(可选) } } } -
业务代码使用
@Service public class UserService { @Cacheable(key = "user:#{userId}", expire = 3600) public User getUserById(Long userId) { // 数据库查询逻辑 } }
注意事项
- 缓存穿透/击穿/雪崩:需结合布隆过滤器、本地锁、随机过期时间等策略(参考知识库[8]的“三防方案”)。
- 异步刷新:在返回缓存数据后,异步重新加载数据到缓存,避免缓存失效时的性能抖动。
2. AOP 实现限流熔断
核心思路
通过 切面拦截方法调用,结合限流算法(如令牌桶、漏桶)或熔断器(如 Hystrix、Sentinel)实现流量控制和熔断降级。
实现步骤
-
定义注解
@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface RateLimiter { String key(); // 限流键(如方法名+参数) int permitsPerSecond(); // 每秒允许的请求数 } -
编写切面(Aspect)
使用 Guava 的RateLimiter实现限流:@Aspect @Component public class RateLimiterAspect { @Around("@annotation(rateLimiter)") public Object aroundAdvice(ProceedingJoinPoint joinPoint, RateLimiter rateLimiter) throws Throwable { String key = rateLimiter.key(); RateLimiter limiter = RateLimiter.create(rateLimiter.permitsPerSecond()); if (!limiter.tryAcquire()) { throw new RuntimeException("请求被限流"); } return joinPoint.proceed(); } } -
熔断逻辑(结合 Hystrix)
使用 Hystrix 的@HystrixCommand注解,结合 AOP 统一管理降级逻辑:@HystrixCommand(fallbackMethod = "fallbackMethod", commandKey = "getUserById") public User getUserById(Long userId) { // 可能失败的业务逻辑 }
注意事项
- 熔断策略:需配置熔断阈值(如失败率超过 50% 时触发熔断)。
- 降级逻辑:在
fallbackMethod中返回默认值或备用数据。
3. AOP 实现审计(日志记录)
核心思路
通过切面拦截方法调用,记录 请求参数、执行时间、结果 等信息,用于审计或监控。
实现步骤
-
定义注解
@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface Audit { String value() default ""; // 审计描述 } -
编写切面(Aspect)
@Aspect @Component public class AuditAspect { @Around("@annotation(audit)") public Object aroundAdvice(ProceedingJoinPoint joinPoint, Audit audit) throws Throwable { long startTime = System.currentTimeMillis(); // 记录请求参数 Object[] args = joinPoint.getArgs(); try { Object result = joinPoint.proceed(); // 记录成功日志(如使用 SLF4J) log.info("Audit: {} - 成功, 耗时: {}ms", audit.value(), System.currentTimeMillis() - startTime); return result; } catch (Exception e) { // 记录失败日志 log.error("Audit: {} - 失败, 耗时: {}ms, 错误: {}", audit.value(), System.currentTimeMillis() - startTime, e.getMessage()); throw e; } } } -
业务代码使用
@Service public class OrderService { @Audit("创建订单") public Order createOrder(OrderRequest request) { // 业务逻辑 } }
注意事项
- 敏感信息过滤:避免日志中记录密码、Token 等敏感数据。
- 异步日志:高并发场景下建议异步记录日志(如通过消息队列)。
4. AOP 实现消息队列
核心思路
在 方法执行后 触发消息发送,解耦业务逻辑与消息队列操作。
实现步骤
-
定义注解
@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface SendMessage { String exchange(); // 消息队列交换机 String routingKey(); // 路由键 } -
编写切面(Aspect)
@Aspect @Component public class MessageAspect { @Autowired private RabbitTemplate rabbitTemplate; @AfterReturning("@annotation(sendMessage)") public void afterReturning(JoinPoint joinPoint, SendMessage sendMessage) { Object result = joinPoint.getArgs()[0]; // 假设返回值为消息体 rabbitTemplate.convertAndSend( sendMessage.exchange(), sendMessage.routingKey(), result ); } } -
业务代码使用
@Service public class OrderService { @SendMessage(exchange = "order-exchange", routingKey = "order.created") public Order createOrder(OrderRequest request) { Order order = saveOrder(request); return order; // 返回值作为消息体 } }
注意事项
- 消息可靠性:需结合消息队列的事务机制或死信队列确保消息不丢失。
- 序列化:确保消息体对象可被序列化(如使用 JSON 或 Protobuf)。
5. AOP 实现分布式锁
核心思路
通过切面在 方法执行前后获取和释放锁,确保方法在分布式环境下的线程安全。
实现步骤
-
定义注解
@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface DistributedLock { String key(); // 锁的键(如方法名+参数) long timeout() default 3000; // 锁等待超时时间(毫秒) } -
编写切面(Aspect)
使用 Redis 实现分布式锁(参考知识库[8]的“双重检查锁”):@Aspect @Component public class LockAspect { @Autowired private RedisTemplate<String, String> redisTemplate; @Around("@annotation(distributedLock)") public Object aroundAdvice(ProceedingJoinPoint joinPoint, DistributedLock lock) throws Throwable { String lockKey = lock.key(); String identifier = UUID.randomUUID().toString(); // 尝试获取锁 if (!redisTemplate.opsForValue().setIfAbsent(lockKey, identifier, lock.timeout(), TimeUnit.MILLISECONDS)) { throw new RuntimeException("获取分布式锁失败"); } try { return joinPoint.proceed(); } finally { // 释放锁(可使用 Lua 脚本保证原子性) String currentValue = redisTemplate.opsForValue().get(lockKey); if (currentValue != null && currentValue.equals(identifier)) { redisTemplate.delete(lockKey); } } } } -
业务代码使用
@Service public class StockService { @DistributedLock(key = "stock:#{productId}", timeout = 5000) public void deductStock(Long productId, int quantity) { // 扣减库存逻辑 } }
注意事项
- 锁的粒度:合理设计锁的键(如
productId),避免过度锁竞争。 - 超时控制:设置合理的锁等待时间和自动释放时间,防止死锁。
总结
通过 AOP + 自定义注解,可以将 横切逻辑(如缓存、限流、审计、消息、锁)从业务代码中解耦,实现以下优势:
- 代码简洁:业务代码无需关注非核心逻辑。
- 统一管理:集中配置和修改公共逻辑(如缓存策略、限流阈值)。
- 扩展性高:新增功能只需添加注解,无需修改业务代码。
组件注解
Spring框架提供了丰富的注解来简化开发过程,以下是一些常用的Spring注解:
@Component
定义:@Component是一个通用的Spring注解,用于将一个类标记为Spring容器中的组件。
作用:通常用于标记服务层、数据访问层或任何其他需要被Spring管理的类。
@Service
定义:@Service是@Component的一个特化版本,用于标记服务层的组件。
作用:通常用于标记业务逻辑类,表示这些类包含业务操作。
@Repository
定义:@Repository是@Component的另一个特化版本,用于标记数据访问层的组件。
作用:通常用于标记DAO(Data Access Object)类,表示这些类负责与数据库进行交互。
@Controller
定义:@Controller是@Component的一个特化版本,用于标记控制器层的组件。
作用:通常用于标记处理HTTP请求的类,表示这些类负责接收和响应Web请求。
@RestController
定义:@RestController是@Controller和@ResponseBody的组合注解,用于创建RESTful Web服务。
作用:通常用于标记返回JSON或XML数据的控制器类。
@Autowired
定义:@Autowired用于自动装配Spring容器中的bean。
作用:可以用于构造函数、方法或字段上,以实现依赖注入。
@Qualifier
定义:@Qualifier用于在自动装配时消除歧义,指定要注入的具体bean。
作用:通常与@Autowired一起使用,以选择特定的bean进行注入。
@ExceptionHandler
定义:@ExceptionHandler用于定义异常处理方法,当控制器抛出特定异常时调用该方法。
作用:提供集中的异常处理机制,使代码更简洁。
@Transactional
定义:@Transactional用于声明事务性的方法或类。
作用:确保方法内的数据库操作在一个事务中执行,提供原子性和一致性。
@Value
定义:@Value用于注入外部化配置的值,如属性文件或环境变量中的值。
作用:常用于注入配置参数。
@Configuration
定义:@Configuration用于标记一个类为Spring的配置类,相当于传统的XML配置文件。
作用:定义bean和其他Spring基础设施组件。
@Bean
定义:@Bean用于在配置类中定义一个bean,并将其注册到Spring容器中。
作用:替代XML配置中的元素。
@EnableAspectJAutoProxy
定义:@EnableAspectJAutoProxy用于启用Spring AOP代理支持。
作用:允许使用AOP切面编程。
总的来说,Spring框架通过这些注解大大简化了开发过程,使得开发者能够专注于业务逻辑而不是繁琐的配置工作。
Spring事务处理通用规则
| 规则 | 描述 | 示例 |
|---|---|---|
| 自动回滚运行时异常 | 默认回滚 RuntimeException 及其子类(如 NullPointerException)。 | java<br>@Transactional // 默认回滚运行时异常<br>public void method() { ... } |
| 显式配置回滚规则 | 通过 @Transactional(rollbackFor = {Exception.class}) 指定需回滚的异常。 | java<br>@Transactional(rollbackFor = {SQLException.class, IOException.class})<br>public void method() { ... } |
| 避免吞异常 | 如果捕获异常但未抛出,事务会被认为成功,不会回滚。 | java<br>try { ... } catch (Exception e) { // 不抛出异常,事务提交 } |
| 资源管理 | 使用 try-with-resources 或 finally 释放资源(如数据库连接、文件流)。 | java<br>try (FileWriter writer = new FileWriter("file.txt")) { ... } |
场景1:数据库和文件操作
@Service
public class MyService {
@Transactional(rollbackFor = {SQLException.class, IOException.class})
public void saveDataToFileAndDB(String data) {
try {
// 数据库操作
jdbcTemplate.update("INSERT INTO logs (content) VALUES (?)", data);
// 文件操作
Files.write(Paths.get("data.txt"), data.getBytes());
} catch (SQLException | IOException e) {
// 记录日志并抛出异常触发回滚
throw new RuntimeException("Transaction failed", e);
}
}
}
场景2:批量数据库操作
@Transactional(rollbackFor = BatchUpdateException.class)
public void batchUpdate() {
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement()) {
conn.setAutoCommit(false);
stmt.addBatch("UPDATE ...");
stmt.addBatch("UPDATE ..."); // 假设此语句失败
int[] results = stmt.executeBatch();
for (int res : results) {
if (res == Statement.EXECUTE_FAILED) {
throw new BatchUpdateException("Batch failed");
}
}
conn.commit();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
注意事项
-
回滚配置:
- 使用
rollbackFor显式指定需回滚的异常类型。 - 若需回滚所有异常,可配置
@Transactional(rollbackFor = Exception.class)。
- 使用
-
资源释放:
- 即使事务回滚,未关闭的资源(如文件流、数据库连接)仍需手动释放。
-
异常传播:
- 如果在事务方法中捕获异常但未重新抛出,Spring认为事务成功,不会回滚。
总结
| 异常类型 | Spring事务处理策略 |
|---|---|
| 检查型异常(编译时异常) | 必须通过 @Transactional(rollbackFor = ...) 显式配置回滚规则,或在方法中抛出异常。 |
| 运行时异常 | 默认自动回滚,无需额外配置。 |
Mybatis/Plus
mybatis动态sql
if:条件判断,根据条件是否满足来决定是否包含某部分SQL片段。
choose、when、otherwise:类似于Java中的switch语句,根据不同条件选择不同的SQL片段。
trim、where、set:用于自动处理SQL语句中的多余逗号和AND、OR等连接符。
foreach:用于遍历集合,通常用于IN或批量插入、更新操作。
软删除
yml
spring:
datasource:
type: com.zaxxer.hikari.HikariDataSource
url: jdbc:mysql://192.168.6.101:3306/lease?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=GMT%2b8
username: root
password: 123456
hikari:
connection-test-query: SELECT 1 # 自动检测连接
connection-timeout: 60000 #数据库连接超时时间,默认30秒
idle-timeout: 500000 #空闲连接存活最大时间,默认600000(10分钟)
max-lifetime: 540000 #此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
maximum-pool-size: 12 #连接池最大连接数,默认是10
minimum-idle: 10 #最小空闲连接数量
pool-name: SPHHikariPool # 连接池名称
#用于打印框架生成的sql语句,便于调试
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
auto-mapping-behavior: full
global-config:
db-config:
logic-delete-field: is_deleted # 全局逻辑删除的实体字段名(配置后可以忽略不配置步骤二)
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
update-strategy: not_null #非null的字段参与update语句。
mapper-locations: classpath*:/mapper/**/*.xml
注解:@TableLogic
自动填充
package com.atguigu.lease.common.mybatisplus;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.util.Date;
@Component
public class MybatisMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject,"createTime", Date.class,new Date());
}
@Override
public void updateFill(MetaObject metaObject) {
this.strictUpdateFill(metaObject,"updateTime",Date.class,new Date());
}
}
分页
pom依赖
<!--无需声明版本和依赖范围-->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
package com.atguigu.lease.common.mybatisplus;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@MapperScan("com.atguigu.lease.web.*.mapper")
public class MybatisPlusConfiguration {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return mybatisPlusInterceptor;
}
}
O-R Mapping
对一映射
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.lease.web.admin.mapper.RoomInfoMapper">
<resultMap id="RoomItemVoMap" type="com.atguigu.lease.web.admin.vo.room.RoomItemVo" >
<id property="id" column="id"/>
<association property="apartmentInfo" javaType="com.atguigu.lease.model.entity.ApartmentInfo" >
<id property="id" column="apart_id"/>
<result property="isRelease" column="apart_is_release"/>
</association>
</resultMap>
<!-- 2,5是代表正在出租的房子-->
<select id="pageRoomItemByQuery" resultMap="RoomItemVoMap">
select ri.*,
la.room_id is not null is_check_in,
la.lease_end_date,
ai.id apart_id,
ai.name,
ai.introduction,
ai.district_id,
ai.district_name,
ai.city_id,
ai.city_name,
ai.province_id,
ai.province_name,
ai.address_detail,
ai.latitude,
ai.longitude,
ai.phone,
ai.is_release apart_is_release
from room_info ri
left join lease_agreement la
on ri.id = la.room_id
and la.is_deleted = 0
and la.status in (2,5)
left join apartment_info ai
on ri.apartment_id = ai.id
and ai.is_deleted = 0
<where>
and ri.is_deleted = 0
<if test="queryVo.provinceId != null">
and ai.province_id = #{queryVo.provinceId}
</if>
<if test="queryVo.cityId != null">
and ai.city_id = #{queryVo.cityId}
</if>
<if test="queryVo.districtId != null">
and ai.district_id = #{queryVo.districtId}
</if>
<if test="queryVo.apartmentId != null">
and ri.apartment_id = #{queryVo.apartmentId}
</if>
</where>
</select>
</mapper>
对多映射
无分页情况
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.lease.web.admin.mapper.AttrKeyMapper">
<resultMap id="AttrKeyVoResultMap" type="com.atguigu.lease.web.admin.vo.attr.AttrKeyVo">
<id column="id" property="id"></id>
<result column="key_name" property="name"></result>
<collection property="attrValueList" ofType="com.atguigu.lease.model.entity.AttrValue">
<id column="value_id" property="id"></id>
<result column="value_name" property="name"></result>
<result column="attr_key_id" property="attrKeyId"></result>
</collection>
</resultMap>
<select id="attrInfoList" resultMap="AttrKeyVoResultMap">
select
k.id,
k.name as key_name,
v.id as value_id,
v.name as value_name,
v.attr_key_id
from attr_key k
left join attr_value v on k.id = v.attr_key_id and v.is_deleted=0
where k.is_deleted=0
</select>
</mapper>
有分页
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.lease.web.app.mapper.RoomInfoMapper">
<!-- result map -->
<resultMap id="RoomItemVoMap" type="com.atguigu.lease.web.app.vo.room.RoomItemVo" autoMapping="true">
<id property="id" column="id"/>
<association property="apartmentInfo" javaType="com.atguigu.lease.model.entity.ApartmentInfo" autoMapping="true">
<id property="id" column="apart_id"/>
<result property="isRelease" column="apart_is_release"/>
</association>
<collection property="graphVoList" ofType="com.atguigu.lease.web.app.vo.graph.GraphVo" autoMapping="true" select="listGraphVoByRoomId" column="id"/>
<collection property="labelInfoList" ofType="com.atguigu.lease.model.entity.LabelInfo" autoMapping="true" select="listLabelByRoomId" column="id"/>
</resultMap>
<!-- 根据条件查询房间列表 -->
<select id="pageRoomItemByQuery" resultMap="RoomItemVoMap">
select
ri.id,
ri.room_number,
ri.rent,
ri.apartment_id,
ri.is_release,
ai.id apart_id,
ai.name,
ai.introduction,
ai.district_id,
ai.district_name,
ai.city_id,
ai.city_name,
ai.province_id,
ai.province_name,
ai.address_detail,
ai.latitude,
ai.longitude,
ai.phone,
ai.is_release apart_is_release
from room_info ri
left join apartment_info ai on ai.is_deleted=0 and ri.apartment_id=ai.id
<where>
ri.is_deleted=0
and ai.is_deleted=0
and ri.id not in(
select room_id
from lease_agreement
where is_deleted = 0
and status in(${@com.atguigu.lease.model.enums.LeaseStatus@SIGNED.getCode()},
${@com.atguigu.lease.model.enums.LeaseStatus@WITHDRAWING.getCode()}))
and ri.is_release = ${@com.atguigu.lease.model.enums.ReleaseStatus@RELEASED.getCode()}
<if test="queryVo.provinceId != null">
and ai.province_id = #{queryVo.provinceId}
</if>
<if test="queryVo.cityId != null">
and ai.city_id = #{queryVo.cityId}
</if>
<if test="queryVo.districtId != null">
and ai.district_id = #{queryVo.districtId}
</if>
<if test="queryVo.minRent != null and queryVo.maxRent != null">
and (ri.rent >= #{queryVo.minRent} and ri.rent <= #{queryVo.maxRent})
</if>
<if test="queryVo.paymentTypeId != null">
and ri.id in (
select
room_id
from room_payment_type
where is_deleted = 0
and payment_type_id = #{queryVo.paymentTypeId}
)
</if>
</where>
<if test="queryVo.orderType == 'desc' or queryVo.orderType == 'asc'">
order by ri.rent ${queryVo.orderType}
</if>
</select>
<!-- 根据房间ID查询图片列表 -->
<select id="listGraphVoByRoomId" resultType="com.atguigu.lease.web.app.vo.graph.GraphVo">
select
name,
url
from graph_info
where is_deleted = 0
and item_id=#{id}
</select>
<!-- 根据公寓ID查询标签列表 -->
<select id="listLabelByRoomId" resultType="com.atguigu.lease.model.entity.LabelInfo">
select id,
name
from label_info
where is_deleted = 0
and id in (select label_id
from room_label
where is_deleted = 0
and room_id = #{id})
</select>
</mapper>
自动映射配置
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
auto-mapping-behavior: full
枚举类型转换
TypeHandler
@EnumValue
MySQL
SQL常用连接方式
INNER JOIN(内连接):返回两个表中存在匹配的行。
LEFT JOIN(左连接):返回左表中的所有行,即使在右表中没有匹配的行。
RIGHT JOIN(右连接):返回右表中的所有行,即使在左表中没有匹配的行。
FULL JOIN(全连接):返回两个表中的所有行,即使其中一个表中没有匹配的行。
左连接注意事项:
子表条件加on后,主表条件加where后
内连接注意事项:
主、子表连接加on后还是where后效果相同。推荐加where后。优化器自动优化。
| JOIN 类型 | 描述 |
|-------------------|----------------------------------------------------------------------|
| INNER JOIN | 返回两个表中匹配的行。 |
| LEFT JOIN | 返回左表所有行,右表匹配的行;若无匹配,右表字段为 NULL。 |
| RIGHT JOIN | 返回右表所有行,左表匹配的行;若无匹配,左表字段为 NULL。 |
| FULL [OUTER] JOIN | 返回两个表所有行,不匹配的字段为 NULL(MySQL不直接支持,需用UNION模拟)。|
| CROSS JOIN | 无条件连接,生成笛卡尔积(相当于不带ON的JOIN)。 |
| SELF JOIN | 表自连接,将表视为两个独立表进行连接。 |
| NATURAL JOIN | 基于两个表中名称和类型相同的列进行自动连接(等同于ON所有共同列)。 |
FullText 全文索引使用
CREATE TABLE test (
id INT AUTO_INCREMENT PRIMARY KEY,
title TEXT,
FULLTEXT(title)
);
-- 创建一个使用ngram解析器的全文索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title, body) WITH PARSER ngram
) ENGINE=InnoDB;
-- 设置ngram的最小和最大长度(可选)
SET GLOBAL innodb_ft_aux_table = 'database_name/articles';
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_CONFIG WHERE KEY='ngram_token_size';
-- 如果需要更改ngram_token_size, 可以通过修改系统变量innodb_ft_aux_table来调整
在MySQL中,ngram解析器主要用于中文、日文等非空格分隔语言的全文搜索优化。通过合理配置和调整相关参数,可以显著提升其性能和搜索效果。以下是具体的优化方法和步骤:
PARSER ngram优化
一、核心优化参数
1. 调整 ngram_token_size
- 作用:控制分词的字符长度(n值),默认为2(即bigram)。
- 优化策略:
- 根据搜索需求选择n值:
- 若需搜索单字词(如“我”、“你”),设置
ngram_token_size=1。 - 若需搜索双字词(如“数据库”、“优化”),设置
ngram_token_size=2。 - 若需搜索三字及以上词组,设置
ngram_token_size=3或更高(最大值为10)。
- 若需搜索单字词(如“我”、“你”),设置
- 平衡索引大小与搜索精度:
- 较小的n值(如1):索引更细,但会生成更多token,索引体积增大。
- 较大的n值(如3):索引更精简,但可能遗漏短词,影响搜索召回率。
- 根据搜索需求选择n值:
- 配置方法:
# 启动MySQL时设置(需重启) mysqld --ngram_token_size=2# 在配置文件(my.cnf或my.ini)中设置 [mysqld] ngram_token_size=2
2. 控制分词最小/最大长度
- 参数说明:
innodb_ft_min_token_size:最小分词长度,默认3(但ngram解析器不支持此参数,需忽略)。innodb_ft_max_token_size:最大分词长度,默认84(同样不支持)。
- 注意:在ngram模式下,这两个参数无效,仅需依赖
ngram_token_size。
二、优化步骤
1. 合理选择分词长度
- 场景示例:
- 搜索“数据库优化”:
- 若
ngram_token_size=2,分词结果为“数库”、“据库”、“据优”、“优化”,可能无法准确匹配“数据库优化”。 - 若
ngram_token_size=3,分词结果为“数据库”、“据优化”,能更精准匹配。
- 若
- 建议:根据常用关键词长度选择n值,例如:
- 以双字词为主的场景(如中文):
ngram_token_size=2。 - 需要三字词支持(如“人工智能”):
ngram_token_size=3。
- 以双字词为主的场景(如中文):
- 搜索“数据库优化”:
2. 建立高效全文索引
- 创建索引示例:
CREATE TABLE articles ( id INT PRIMARY KEY, content TEXT, FULLTEXT (content) WITH PARSER ngram -- 显式指定ngram解析器 ) ENGINE=InnoDB; - 避免冗余索引:仅对需要全文搜索的字段(如
title、content)建立ngram索引,减少存储开销。
3. 优化查询性能
- 使用布尔模式搜索:
SELECT * FROM articles WHERE MATCH(content) AGAINST('+数据库 +优化' IN BOOLEAN MODE);+:强制包含关键词。*:通配符(如“数据*”匹配“数据库”、“数据科学”)。
- 结合覆盖索引:
确保查询字段包含在索引中,避免回表查询:-- 创建覆盖索引 CREATE INDEX idx_content ON articles (id, content);
4. 定期维护索引
- 重建索引:
-- 优化表并重建索引 OPTIMIZE TABLE articles; - 清理碎片:
定期执行OPTIMIZE TABLE减少索引碎片,提升查询速度。
5. 监控与调优
- 查看分词效果:
-- 查看分词后的token SET GLOBAL innodb_ft_aux_table = 'dbname/articles'; SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE; - 分析查询计划:
EXPLAIN SELECT * FROM articles WHERE MATCH(content) AGAINST('数据库优化');- 确保查询使用了
fulltext类型索引。
- 确保查询使用了
三、典型优化案例
案例1:提升中文搜索准确率
- 问题:搜索“数据库优化”时,结果中包含无关文档。
- 优化步骤:
- 调整
ngram_token_size=3,确保能匹配“数据库”和“优化”。 - 使用布尔模式强制匹配:
SELECT * FROM articles WHERE MATCH(content) AGAINST('+数据库 +优化' IN BOOLEAN MODE);
- 调整
案例2:减少索引体积
- 问题:索引过大导致存储压力。
- 优化步骤:
- 降低
ngram_token_size至2,减少token数量。 - 删除冗余索引:
ALTER TABLE articles DROP INDEX idx_old;
- 降低
四、注意事项
- 参数生效条件:
ngram_token_size需重启MySQL后生效,并需重新创建全文索引。
- 平衡性能与精度:
- 过大的n值可能漏掉短词,过小的n值可能增加索引冗余。
- 测试环境验证:
- 在测试环境中调整参数,通过
EXPLAIN和实际查询验证效果。
- 在测试环境中调整参数,通过
总结
通过合理设置ngram_token_size、优化查询语句、定期维护索引,可以显著提升ngram解析器的性能和搜索效果。同时,结合MySQL的全文索引优化策略(如覆盖索引、布尔模式),可进一步满足复杂场景的中文全文检索需求。
Redis缓存过期淘汰策略
- noeviction
不进行数据淘汰,也是Redis的默认配置。这时,当缓存被写满时,再有写请求进来,Redis不再提供服务,直接返回错误。
2.volatile-random
缓存满了之后,在设置了过期时间的键值对中进行随机删除。
3.volatile-ttl
缓存满了之后,会针对设置了过期时间的键值对中,根据过期时间的先后顺序进行删除,越早过期的越先被删除。
4.volatile-lru
缓存满了之后,针对设置了过期时间的键值对,采用LRU算法进行淘汰,不熟悉LRU的可以看这篇文章。
5.volatile-lfu
缓存满了之后,针对设置了过期时间的键值对,采用LFU的算法进行淘汰。
6.allkeys-random
缓存满了之后,从所有键值对中随机选择并删除数据。
7.allkeys-lru
缓存写满之后,使用LRU算法在所有的数据中进行筛选删除。
8.allkeys-lfu
缓存满了之后,使用LRU算法在所有的数据中进行筛选删除。
在日常使用过程中,主要根据你的数据要求来配置相应的策略,这里我给你三点建议。
我们优先使用allkeys-lru 策略。这样,我们就可以借助LRU算法去淘汰那些不常用的数据,把最近最常用的放在缓存中,从而提高应用的性能。如果你的数据有明显的冷热区分,建议你使用allkeys-lru策略。
如果你的数据的访问频率相差不大,也没有冷热之分,直接使用allkeys-random 策略,随机选择淘汰的数据就行。
如果你的数据有置顶要求,比如置顶新闻等。那么我们就选择volatile-lru策略,同时不给置顶数据设置过期时间,这样一来,置顶的数据永远不会被删除,而其他设置了过期时间的数据,会更加LRU算法进行淘汰
Https
传输层安全性(TLS) / 安全套接字 层(SSL)
TLS(Transport Layer Security) 是 SSL(Secure Socket Layer) 的后续版本,它们是用于在互联网两台计算机之间用于身份验证和加密的一种协议。
TLS(Transport Layer Security) 是 SSL(Secure Socket Layer) 的后续版本,它们是用于在互联网两台计算机之间用于身份验证和加密的一种协议。
一些在线业务(比如在线支付)最重要的一个步骤是创建一个值得信赖的交易环境,能够让客户安心的进行交易,SSL/TLS 就保证了这一点,SSL/TLS 通过将称为 X.509 证书的数字文档将网站和公司的实体信息绑定到加密密钥来进行工作。每一个密钥对(key pairs) 都有一个 私有密钥(private key) 和 公有密钥(public key),私有密钥是独有的,一般位于服务器上,用于解密由公共密钥加密过的信息;公有密钥是公有的,与服务器进行交互的每个人都可以持有公有密钥,用公钥加密的信息只能由私有密钥来解密。
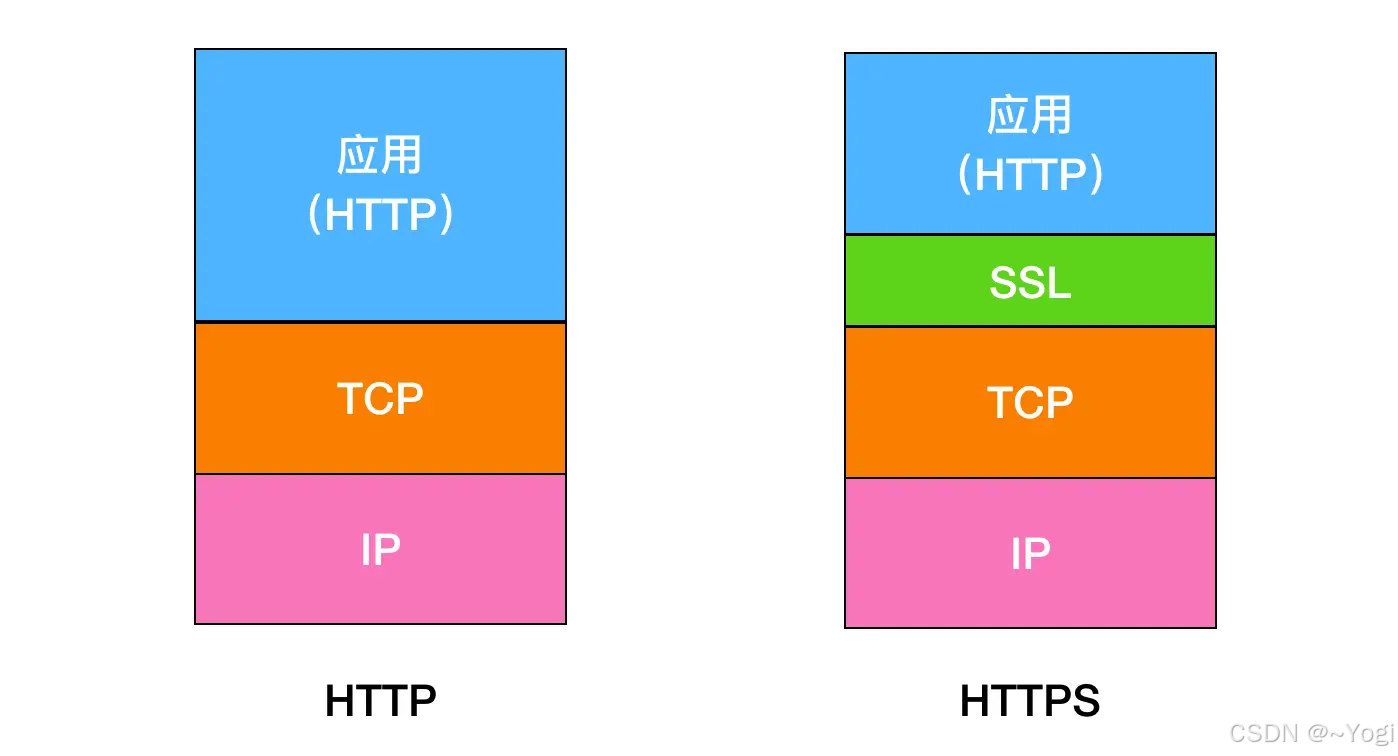
HTTPS会被解密吗
一、HTTPS 的加密原理
-
混合加密机制:
- 非对称加密(如 RSA/ECDH):用于协商对称加密密钥。
- 对称加密(如 AES):用于实际传输数据的加密,效率高。
- 数字证书(SSL/TLS 证书):由权威 CA(证书颁发机构)签名,验证服务器身份。
-
握手阶段:
- 客户端与服务器协商加密算法和密钥。
- 服务器通过证书证明身份,客户端验证证书的合法性(是否由可信 CA 签名)。
- 生成对称密钥并通过非对称加密传输,后续通信使用对称密钥加密。
二、HTTPS 被解密的场景
1. 中间人攻击(MITM)
- 条件:攻击者能够伪造证书并欺骗客户端信任其证书。
- 实现方式:
- Fiddler/Charles 等工具:通过安装自签名证书到客户端,使客户端信任中间人的证书(如知识库[2]所述)。
- 恶意 CA 证书:某些国家或组织可能控制 CA,签发伪造证书(知识库[5]提到的信用链问题)。
- 解密过程:
- 攻击者拦截通信,伪装成服务器与客户端建立连接。
- 客户端和攻击者、攻击者和服务器分别协商密钥,攻击者可解密双向流量。
2. 密钥泄露
- 服务器私钥泄露:
- 如果服务器的私钥被窃取(如证书文件被盗),攻击者可直接解密 TLS 握手阶段的对称密钥(知识库[3]提到通过私钥解密流量)。
- 对称密钥泄露:
- 通过配置工具(如 Chrome 的
SSLKEYLOGFILE环境变量)记录密钥文件,Wireshark 可利用该文件解密流量(知识库[3])。
- 通过配置工具(如 Chrome 的
3. 算法漏洞或弱加密
- 过时的加密算法:如使用已被破解的 RC4 或弱加密套件。
- 协议漏洞:如 Heartbleed(CVE-2014-0160)漏洞可泄露内存数据,包括密钥。
4. 证书管理不当
- 无效证书:证书过期、域名不匹配或未正确配置,可能导致客户端忽略警告,间接暴露风险。
- 私钥未妥善保护:如服务器配置错误导致私钥可被下载。
三、HTTPS 的安全性保障
尽管存在上述风险,HTTPS 仍是当前最安全的通信协议之一,其安全性依赖以下措施:
-
证书信任链:
- 浏览器内置可信 CA 列表,只有由 CA 签名的证书才被信任(知识库[4][5])。
- 防止伪造证书(除非攻击者控制 CA 或客户端信任自签名证书)。
-
前向保密(Perfect Forward Secrecy, PFS):
- 通过 ECDHE 等算法,确保每次会话的对称密钥独立生成,即使私钥泄露,历史通信仍安全。
-
协议更新:
- TLS 1.3 取消了弱加密算法,强制使用 AEAD(如 AES-GCM),并简化握手流程(知识库[10])。
-
密钥安全:
- 私钥应存储在安全硬件(如 HSM)中,避免泄露。
- 定期更换证书和密钥(知识库[1]提到的建议)。
四、用户如何防范 HTTPS 被解密?
-
客户端防护:
- 不随意信任未知证书:浏览器提示证书错误时(如“证书不受信任”),应立即终止连接。
- 禁用弱加密套件:确保操作系统和浏览器更新到最新版本,禁用过时算法。
-
服务端防护:
- 使用强证书和密钥:选择 RSA 2048+ 或 ECC 密钥,配置 TLS 1.3。
- 启用 HSTS(HTTP Strict Transport Security):强制浏览器仅通过 HTTPS 访问,防止降级攻击。
- 定期更新证书:避免证书过期或被吊销。
-
开发与运维:
- 监控密钥安全:使用 HSM 存储私钥,限制访问权限。
- 配置密钥记录(谨慎使用):仅在调试时启用
SSLKEYLOGFILE,完成后立即关闭。
五、总结
| 场景 | 是否可解密 | 条件 |
|---|---|---|
| 正常 HTTPS 通信 | 否 | 双方密钥安全,无中间人干预。 |
| 中间人攻击(MITM) | 是 | 攻击者伪造证书并欺骗客户端信任。 |
| 私钥泄露 | 是 | 服务器私钥被窃取,可解密对称密钥或直接解密流量。 |
| 对称密钥泄露(如密钥日志) | 是 | 攻击者获取密钥日志文件(如 Wireshark 配置)。 |
| 算法漏洞 | 是 | 使用已被破解的加密算法(如 RC4)。 |
关键结论
- HTTPS 是安全的,但并非绝对不可破解:其安全性依赖于加密算法、证书管理、密钥保护和协议实现。
- 用户与开发者需共同维护安全:客户端避免信任不明证书,服务端确保密钥安全并及时更新协议与证书。
如果需要进一步探讨具体场景(如 Wireshark 解密步骤或中间人攻击防御),可以继续提问!
SE
编译时异常
| 异常类型 | 是否为编译时异常 | 异常描述 | Spring事务默认行为 | Spring处理方式 | 处理示例 |
|---|---|---|---|---|---|
IOException | 是 | 输入/输出操作失败(如文件读写、网络通信) | 不自动回滚 | 需显式配置 @Transactional(rollbackFor = IOException.class) 或 throws 声明 | java<br>@Transactional(rollbackFor = IOException.class)<br>public void method() { ... } |
SQLException | 是 | 数据库操作失败(如连接错误、SQL语法错误) | 不自动回滚 | 需显式配置 @Transactional(rollbackFor = SQLException.class) 或 throws 声明 | java<br>@Transactional(rollbackFor = SQLException.class)<br>public void method() { ... } |
ClassNotFoundException | 是 | 动态加载类失败 | 不自动回滚 | 需显式配置 @Transactional(rollbackFor = ClassNotFoundException.class) | java<br>@Transactional(rollbackFor = ClassNotFoundException.class)<br>public void method() { ... } |
FileNotFoundException | 是 | 文件不存在 | 不自动回滚 | 需显式配置 @Transactional(rollbackFor = FileNotFoundException.class) | java<br>@Transactional(rollbackFor = FileNotFoundException.class)<br>public void method() { ... } |
InterruptedException | 是 | 线程被中断 | 不自动回滚 | 需显式配置 @Transactional(rollbackFor = InterruptedException.class) | java<br>@Transactional(rollbackFor = InterruptedException.class)<br>public void method() { ... } |
JUC
常用类及其场景
JUC 常用类及场景对比表
| 类名 | 定义 | 核心方法 | 典型场景 | 示例代码片段 |
|---|---|---|---|---|
| CountDownLatch | 允许一个或多个线程等待其他线程完成一组操作的计数器。 | CountDownLatch(int count)await()countDown() | 1. 主线程等待所有子线程完成任务后汇总结果。 2. 多线程准备就绪后统一启动。 | java<br>CountDownLatch latch = new CountDownLatch(3);<br>new Thread(() -> { ...; latch.countDown(); }).start();<br>latch.await();<br> |
| CyclicBarrier | 线程间相互等待的同步屏障,可重复使用。 | CyclicBarrier(int parties)await() | 1. 多线程需同时到达某个点后继续执行。 2. 分阶段任务处理(如分批次处理)。 | java<br>CyclicBarrier barrier = new CyclicBarrier(2);<br>barrier.await();<br> |
| Semaphore | 控制同时访问某资源的线程数量,实现资源池或限流。 | Semaphore(int permits)acquire()release()availablePermits() | 1. 限制数据库连接数。 2. 限流(如每秒最多处理 100 个请求)。 | java<br>Semaphore sem = new Semaphore(5);<br>sem.acquire();<br>try { ... } finally { sem.release(); }<br> |
| ReentrantLock | 可重入锁,提供比 synchronized 更灵活的锁机制。 | lock()unlock()tryLock() | 1. 需要显式控制锁的获取和释放。 2. 支持公平锁与非公平锁。 | java<br>ReentrantLock lock = new ReentrantLock();<br>lock.lock();<br>try { ... } finally { lock.unlock(); }<br> |
| ThreadPoolExecutor | 线程池管理工具,复用线程并控制资源。 | execute(Runnable task)submit(Callable task)shutdown() | 1. 高并发任务处理(如 Web 服务器请求)。 2. 异步任务执行与资源优化。 | java<br>ExecutorService pool = Executors.newFixedThreadPool(10);<br>pool.submit(() -> { ... });<br> |
| ConcurrentHashMap | 线程安全的哈希表,支持高效并发读写。 | put(K key, V value)get(Object key)computeIfAbsent() | 1. 高并发场景下的数据缓存。 2. 需要频繁读写共享数据的场景。 | java<br>ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();<br>map.put("key", 1);<br> |
| Future & Callable | 异步任务执行与结果获取。 | Callable<V>Future<V> submit(Callable<V> task)get() | 1. 需要获取线程执行结果。 2. 阻塞或超时等待任务完成。 | java<br>Future<Integer> future = executor.submit(() -> compute());<br>int result = future.get();<br> |
| Phaser | 扩展版的 CyclicBarrier,支持动态注册和注销线程。 | register()arriveAndAwaitAdvance()bulkRegister(int arrivals) | 1. 复杂流程控制(如分阶段任务,线程数动态变化)。 | java<br>Phaser phaser = new Phaser(2);<br>phaser.arriveAndAwaitAdvance();<br> |
关键类对比与选择
1. CountDownLatch vs CyclicBarrier
- CountDownLatch:
- 适用场景:主线程等待多个子线程完成(如汇总结果)。
- 特点:一次性,计数器归零后无法重用。
- CyclicBarrier:
- 适用场景:多个线程需相互等待后同时执行(如分批次处理任务)。
- 特点:可复用,可通过
reset()重新设置计数器。
2. ReentrantLock vs synchronized
- ReentrantLock:
- 优势:支持公平锁、尝试加锁(
tryLock())、条件变量(Condition)。 - 适用场景:需要精细控制锁行为的场景(如超时等待)。
- 优势:支持公平锁、尝试加锁(
- synchronized:
- 优势:语法简单,自动释放锁(避免死锁风险)。
- 适用场景:简单同步需求,无需复杂控制。
3. Semaphore vs RateLimiter
- Semaphore:
- 适用场景:控制资源访问的并发数(如数据库连接池)。
- 特点:基于许可(permits)的计数器。
- RateLimiter(Guava 提供,非 JUC):
- 适用场景:限流(如每秒允许固定请求数)。
- 特点:基于时间窗口的速率控制。
4. ConcurrentHashMap vs Hashtable
- ConcurrentHashMap:
- 优势:分段锁(Segment)或 CAS 算法实现,读写性能更高。
- 适用场景:高并发读写场景。
- Hashtable:
- 劣势:方法全锁(
synchronized),性能较低。 - 适用场景:简单线程安全需求(已逐渐被
ConcurrentHashMap替代)。
- 劣势:方法全锁(
场景示例
场景 1:主线程等待子线程完成(CountDownLatch)
CountDownLatch latch = new CountDownLatch(3); // 3 个子线程
for (int i = 0; i < 3; i++) {
new Thread(() -> {
// 执行任务
latch.countDown(); // 每个线程完成时减少计数
}).start();
}
latch.await(); // 主线程等待计数归零
System.out.println("所有子线程已完成");
场景 2:多线程同时启动(CyclicBarrier)
CyclicBarrier barrier = new CyclicBarrier(2); // 需要 2 个线程到达
new Thread(() -> {
System.out.println("线程1准备就绪");
barrier.await(); // 等待所有线程到达
System.out.println("线程1开始执行");
}).start();
new Thread(() -> {
System.out.println("线程2准备就绪");
barrier.await();
System.out.println("线程2开始执行");
}).start();
场景 3:限流(Semaphore)
Semaphore sem = new Semaphore(2); // 允许同时 2 个线程访问
for (int i = 0; i < 5; i++) {
new Thread(() -> {
sem.acquire(); // 获取许可
try {
// 临界区代码(如数据库操作)
System.out.println(Thread.currentThread().getName() + " 正在执行");
} finally {
sem.release(); // 释放许可
}
}).start();
}
总结
- 核心思想:JUC 类通过无锁化(如 CAS)、分段锁、线程池复用等技术,提升并发性能并简化开发复杂度。
- 选择原则:
- 等待协调:用
CountDownLatch(单次等待)或CyclicBarrier(多次等待)。 - 资源控制:用
Semaphore限制并发数,用ThreadPoolExecutor管理线程资源。 - 数据安全:用
ConcurrentHashMap替代Hashtable,用ReentrantLock替代细粒度锁。 - 异步任务:用
Callable+Future获取执行结果。
- 等待协调:用
SpringCloud / SpringCloud Alibaba
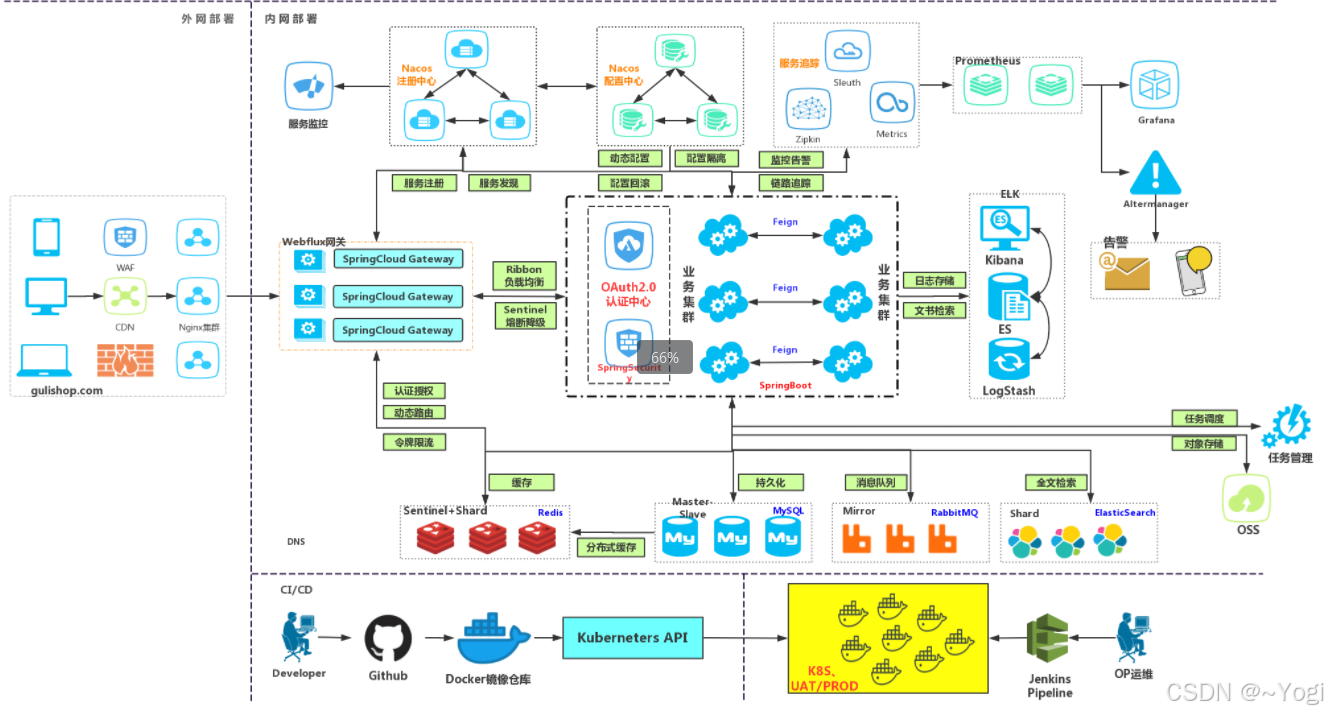
常见微服务项目架构图
HTTP调用和RPC调用的区别
| 对比项 | RPC调用 | HTTP调用 |
|---|---|---|
| 协议基础 | 可基于TCP/UDP/自定义协议(如gRPC) | 固定使用HTTP协议(HTTP/1.1/HTTP/2) |
| 传输效率 | 二进制序列化(如Protobuf),体积小、解析快 | 文本格式(JSON/XML),体积大、解析慢 |
| 性能 | 低延迟、高吞吐,适合高频内部调用 | 较高延迟,但HTTP/2优化后有所提升 |
| 调用方式 | 面向方法,像本地函数调用(如userService.getUser()) | 面向资源,通过URL+HTTP动词(如GET /user/123) |
| 数据格式 | 二进制(Protobuf/Thrift) | JSON/XML(文本格式) |
| 连接管理 | 连接池复用,长连接 | HTTP/1.x需频繁建立连接,HTTP/2支持复用 |
| 适用场景 | 内部微服务通信、高吞吐场景 | 对外API、跨平台(浏览器/移动端)、RESTful接口 |
| 典型框架 | gRPC、Dubbo、Thrift | SpringMVC、Flask、Express、REST API |
| 状态管理 | 无状态(需自行处理) | 无状态(天然支持) |
| 跨语言支持 | 需框架支持(如gRPC的IDL定义) | 通用性强,几乎所有语言支持 |
什么是面向服务编程
- 定义:将系统拆分为独立、自治、可重用的服务单元,通过标准化接口协作。
- 核心特点:
- 松耦合:服务间通过接口通信,不依赖内部实现。
- 自治性:每个服务独立部署、维护,拥有自己的数据存储。
- 可重用性:服务可被多个业务场景复用(如支付、鉴权)。
- 典型场景:微服务架构、企业级系统集成。
服务辅助(监控,追踪,注册,发现,熔断,降级)
| 功能 | 描述 |
|---|---|
| 监控 | 实时跟踪服务状态(如CPU、内存、请求量),工具:Prometheus、Grafana。 |
| 追踪 | 跨服务请求链路跟踪(如分布式事务),工具:Zipkin、SkyWalking。 |
| 注册 | 服务启动时向注册中心(如Nacos、Eureka)上报元数据。 |
| 发现 | 消费者通过注册中心动态获取服务实例地址,实现负载均衡。 |
| 熔断 | 当服务调用失败率过高时,暂时禁用该服务(如Hystrix、Sentinel的熔断机制)。 |
| 降级 | 在熔断或异常时返回预定义值或备用逻辑,保证系统可用性。 |
网关(负载均衡)
- 作用:统一入口,处理路由、鉴权、限流、协议转换等。
- 负载均衡实现:
- 轮询:请求按顺序分发到后端服务实例。
- 随机:随机选择一个可用实例(如Spring Cloud Gateway的
RandomRouteLocator)。 - 权重:根据实例权重分配流量(如高配置实例承担更多请求)。
- 工具:Spring Cloud Gateway、Nginx、APIGee。
RestTemplate使用细节
- 基本用法:
RestTemplate template = new RestTemplate(); String result = template.getForObject("http://example.com/api", String.class); - 常见注解:
@PathVariable:获取URL路径参数。@RequestBody:接收请求体数据。@RequestParam:获取查询参数。
- 配置优化:
- 设置连接池(
HttpComponentsClientHttpRequestFactory)。 - 添加拦截器(
Interceptor)处理通用逻辑(如日志、认证)。
- 设置连接池(
Nacos内置Tomcat
- 作用:Nacos默认使用内嵌Tomcat提供HTTP服务,用于配置管理、服务注册与发现。
- 配置:
- 修改端口:在
application.properties中设置server.port。 - 自定义线程池:通过
nacos.core.pool配置调整Tomcat线程数。
- 修改端口:在
- 注意:生产环境建议通过反向代理(如Nginx)暴露服务,避免直接暴露Tomcat端口。
Nacos单机和集群的区别,启动条件
| 对比项 | 单机模式 | 集群模式 |
|---|---|---|
| 数据存储 | 基于本地文件(conf/config.txt) | 依赖MySQL/其他数据库,支持高可用 |
| 高可用性 | 单点故障,无冗余 | 多节点部署,故障自动切换 |
| 注册/配置中心 | 支持,但数据易丢失 | 支持,数据持久化 |
| 启动条件 | 直接启动,无需额外配置 | 需配置数据库连接、集群节点地址(cluster.conf) |
LoadBalancer使用
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
@LoadBalanced
- 作用:标记RestTemplate或WebClient,使其具备负载均衡能力。
- 示例:
@Bean @LoadBalanced public RestTemplate restTemplate() { return new RestTemplate(); } - 使用:
// 调用服务时直接使用服务名 String result = restTemplate.getForObject("http://service-user/api", String.class);
### 说明
1. **服务辅助**:重点列出微服务中常见的辅助功能及其工具。
2. **网关负载均衡**:简要说明实现方式和工具选择。
3. **Nacos配置**:对比单机与集群的核心差异及启动条件。
4. **LoadBalancer**:提供依赖和注解的直接代码示例。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











