






目录
1)请用value_count函数统计人数,并绘制条图,按颜色区分是否。
1.试用mean、median、var、sd函数求数据的均值、中位数、方差、标准差。
2.绘制该数据的散点图和直方图,应用hist函数构建自己的计量频数表函数。
2.试通过编写计算基本统计量的函数来分析数据的集中趋势和离散程度
3.试分析为何该数据的均值和中位数差别如此之大,方差、标准差在此有何作用?如何正确分析该数据的集中趋势和离散程度?
matplotlib数据库相关参数
bar(x, height, width=0.8, bottom=None, color=None, edgecolor=None,
linewidth=None, tick_label=None, xerr=None, yerr=None,
label = None, ecolor=None, align, log=False, **kwargs)x:传递数值序列,表示起始位置,指定条形图中x轴上的刻度值。
height:传递数值序列,指定条形图y轴上的高度。
width:指定条形图的宽度,默认为0.8。 bottom:用于绘制堆叠条形图。
color:指定条形图的填充色。
edgecolor:指定条形图的边框色。
linewidth:指定条形图边框的宽度,如果指定为0,表示不绘制边框。
tick_label:指定条形图的刻度标签。
xerr:如果参数不为None,表示在条形图的基础上添加误差棒。
yerr:参数含义同xerr。
label:指定条形图的标签,一般用以添加图例。
ecolor:指定条形图误差棒的颜色。
align:指定x轴刻度标签的对齐方式,默认为center,表示刻度标签居中对齐,如果设置为edge,则表示在每个条形的左下角呈现刻度标签。
log:bool类型参数,是否对坐标轴进行log变换,默认为False。
**kwargs:关键字参数,用于对条形图进行其他设置,如透明度等。
plt.style.use函数用来定义绘图风格
如:plt.style.use('ggplot')
plt.style.use('dark_background')
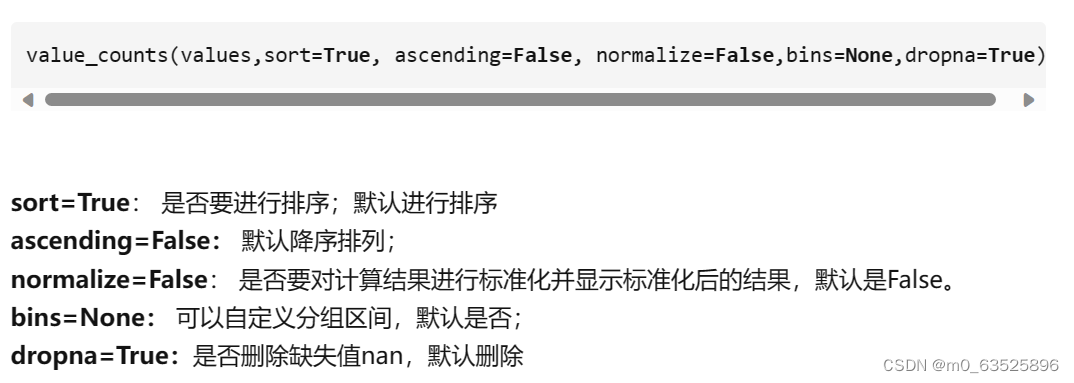
利用pandas模块下的value_counts方法
注释可以通过ctrl+/进行全部注释,取消全部注释也是这样的操作

例题1:调查数据
调查数据。某公司对财务部门人员是否抽烟进行调查,结果为:否,否,否,是,是,否,否,是,否,是,否,否,是,是,否,是,否,否,是,是。
1)请用value_count函数统计人数,并绘制条图,按颜色区分是否。
import matplotlib.pyplot as plt
import pandas as pd
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 统计数据人数
df = pd.DataFrame({'人数': ['否', '否', '否', '是', '是', '否', '否', '是', '否', '是', '否', '否', '是', '是', '否', '是', '否', '否', '是','是']})
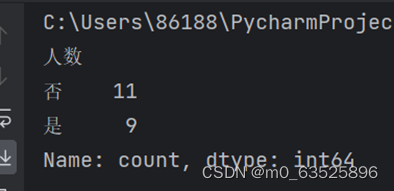
print(df['人数'].value_counts())#输出频数
a2=df['人数'].value_counts()
colors = ['blue','yellow']#设置条形图的颜色
a2.plot(kind='bar',color=colors)#设置条形图的样式
plt.title('财务部吸烟情况')#定义条形图的标题
plt.show()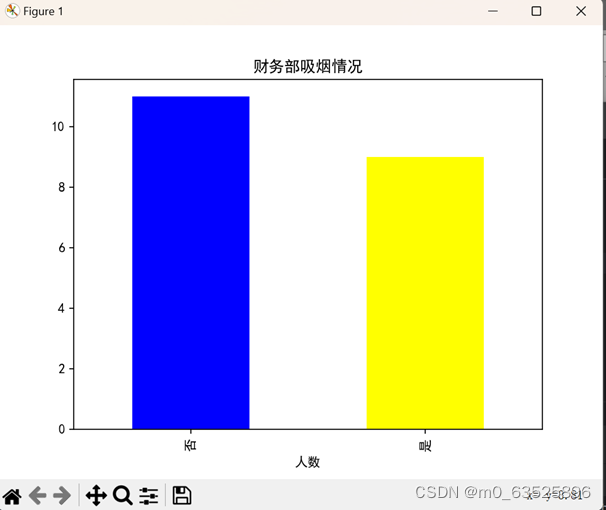
2)请用自定义函数tab生成频数表和频数图。
import pandas as pd
import matplotlib.pyplot as plt
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df = pd.DataFrame({'人数': ['否', '否', '否', '是', '是', '否', '否', '是', '否', '是', '否', '否', '是', '是', '否', '是', '否', '否', '是','是']})
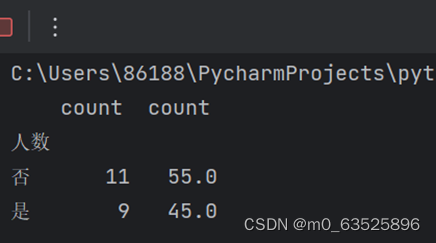
f=df['人数'].value_counts()
def tab(x):
f=x.value_counts()#统计关键词次数
s=sum(f)#计算总数
p=f/s*100#计算频率
T1=pd.concat([f,p],axis=1)#定义每一行的输出
print(T1)
tab(df)
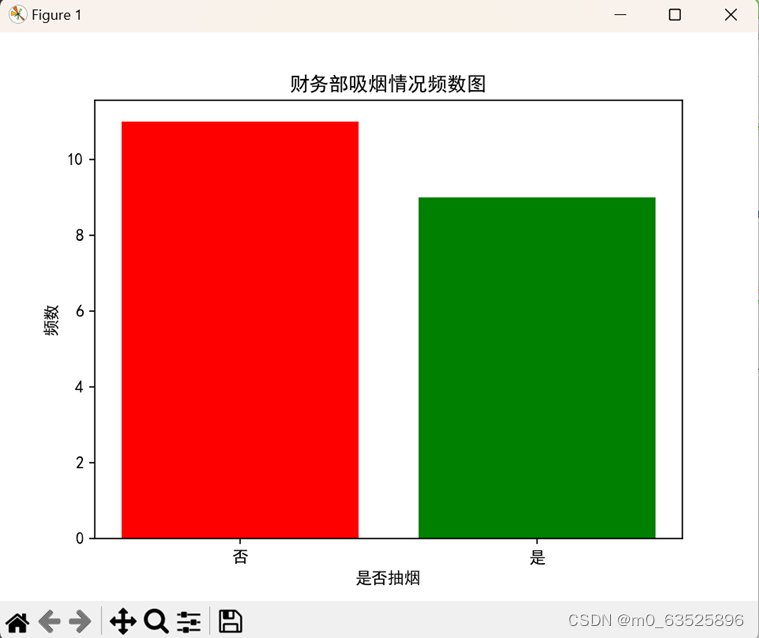
plt.bar(f.index,f.values,color=['red','green'])# 设置条形图的样式,index表示x轴的数据,value表示y轴的数据
plt.title('财务部吸烟情况频数图') # 定义条形图的标题
plt.xlabel('是否抽烟')#设置x轴,y轴显示
plt.ylabel('频数')
plt.show()频数表:
频数图:
例题2
工资数据。上述企业财务部员工的月工资数据如下:
2050,2100,2200,2300,2350,2450,2500,2700,2900, 2850,3500,3800,2600,3000,3300,3200,4000,3100,4200,3500。
1.试用mean、median、var、sd函数求数据的均值、中位数、方差、标准差。
import numpy as np
salary=[2050, 2100, 2200, 2300, 2350, 2450, 2500, 2700, 2900, 2850, 3500, 3800, 2600, 3000, 3300, 3200, 4000, 3100, 4200, 3500]
a = np.mean(salary)
b = np.median(salary)
c = np.var(salary)
d = np.std(salary)
print(a, b, c, d)
2.绘制该数据的散点图和直方图,应用hist函数构建自己的计量频数表函数。
3.请用自定义函数freq生成频数表和频数图。
注:2,3题的代码放在了一起
from matplotlib import pyplot, pyplot as plt
import random
import pandas as pd
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
list = {'工资':[2050,2100,2200,2300,2350,2450,2500,2700,2900,2850,
3500,3800,2600,3000,3300,3200,4000,3100,4200,3500]}
df = pd.DataFrame(list)
workers = random.sample(range(1,21),20)#生成一个包含1到20之间的随机数样本,样本数量为20个,并将结果赋值给变量workers。
workers.sort()
#散点图
pyplot.scatter(workers,df)#创建一个散点图,其中workers表示横坐标数据,df表示纵坐标数据。
pyplot.xlabel('员工')#设置x轴的标签为'员工'
pyplot.ylabel('工资')#设置y轴的标签为'工资'
pyplot.title('财务部员工工资数据散点图')
pyplot.xticks(workers)#设置x轴刻度为workers列表中的值
pyplot.show()
#直方图
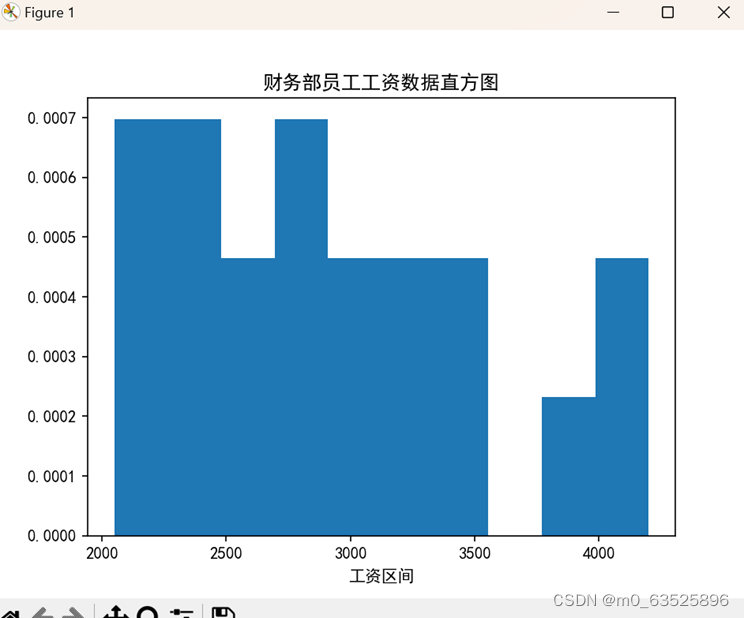
plt.hist(df['工资'],density=True)#density=True表示将频数转换为频率
plt.xlabel('工资区间')
plt.title('财务部员工工资数据直方图' )
plt.show()
#hist函数
def freq(x):
H=plt.hist(x)#使用x的数据创建一个直方图,并将返回的结果赋值给变量H
x = H[1][:-1]#提取直方图的边界值,即频数的上限
y = H[1][1:]#提取直方图的边界值,即频数的下限
k = H[0]#提取直方图的频数
z = k/sum(k)*100#频率
a = pd.DataFrame([x,y,k,z],index=['上限','下限','频数','频率'])
return(a)
print(freq(df))散点图:

直方图:
我的频数表在Pycharm里面运行出来不知道为什么会不全,所有是去到终端下运行的
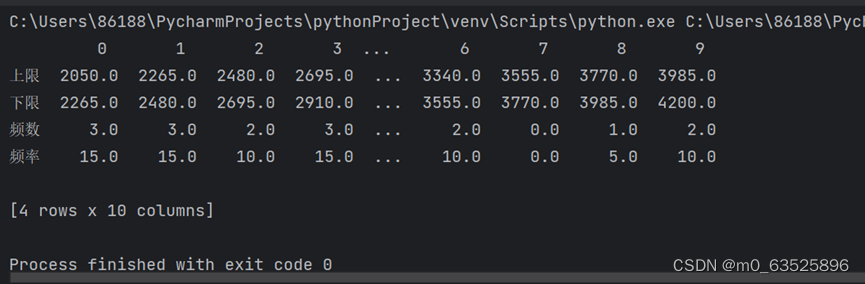
终端下的执行结果:
代码:我的py文件名为workersalary
from workersalary import * freq(df['工资'])

例题3 计算题
经理年薪。收集某沿海发达城市2015年66个年薪超过10万元的公司经理的收入(单位:万元)为
11,19,14,22,14,28,13,81,12,43,11,16,31,16,23,42,22,26,17,22, 13,27,108,16,43,82,14,11,51,76,28,66,29, 14,14,65,37,16,37,35,39,27,14,17,13,38,28,40,85,32,25,26,16,120,54,40,18,27,16,14,33,29,77,50,19,34
注:这题完整代码在下面
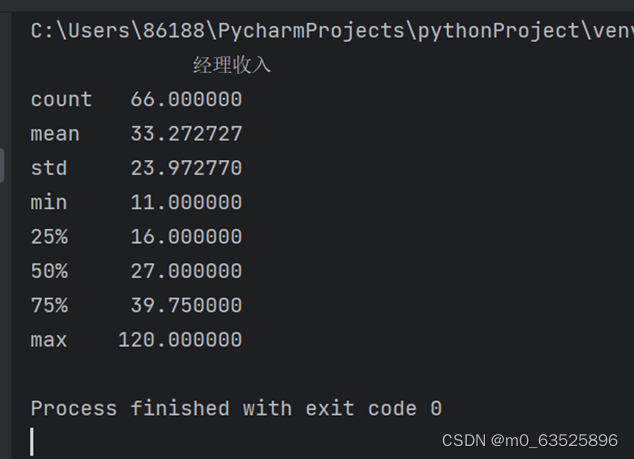
1.可以对这些薪酬的分布状况作何分析?
用describe()函数进行数据分析
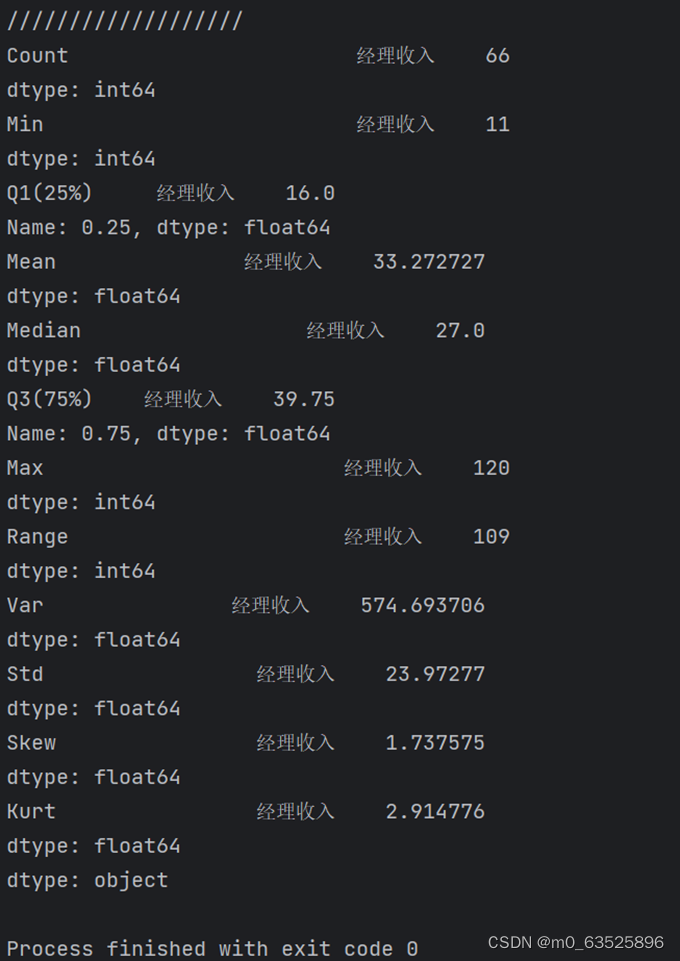
2.试通过编写计算基本统计量的函数来分析数据的集中趋势和离散程度

3.试分析为何该数据的均值和中位数差别如此之大,方差、标准差在此有何作用?如何正确分析该数据的集中趋势和离散程度?
答:在数据中均值为33.2727.27,中位数为27,差别大的原因是离群值比较大,即数据中某些值与其他值有着明显不一样的特征,离群值可以拉大数据的平均值大小,但是对于中位数的影响较小。
方差和标准差可以反应测试数据的离散程度,对于方差和标准差来说当他们的数值越大时,反应了数据的数值差距比较大或者说分散,当方差或标准差比较小是反应了数据的差值差不多,也可说明都比较接近平均值。
可以通过平均值和中位数以及方差、标准差来判断数据的集中趋势和离散程度,均值适用于数据的差距不大时,中位数适用与数据的差距较大时,方差和标准差则用来判断数据的离散程度。以及通过绘图的方式用直方图,散点图,箱线图等等。
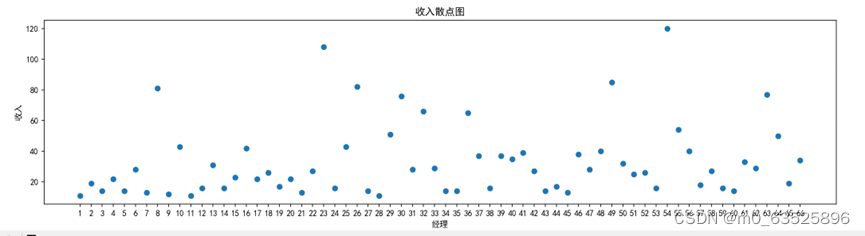
4.绘制该数据的散点图和直方图。
散点图:
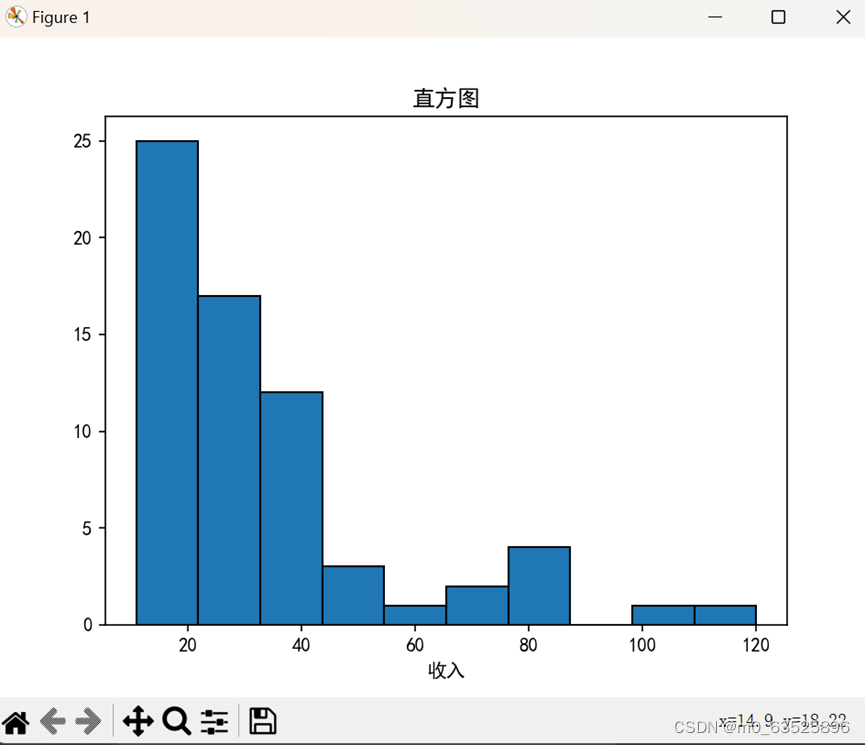
直方图
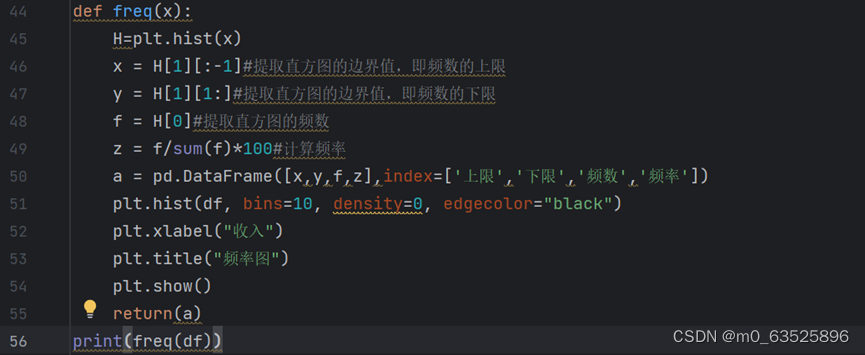
5.请用自定义函数freq生成频数表和频数图。
注:此题的频数表也是在终端中获取的
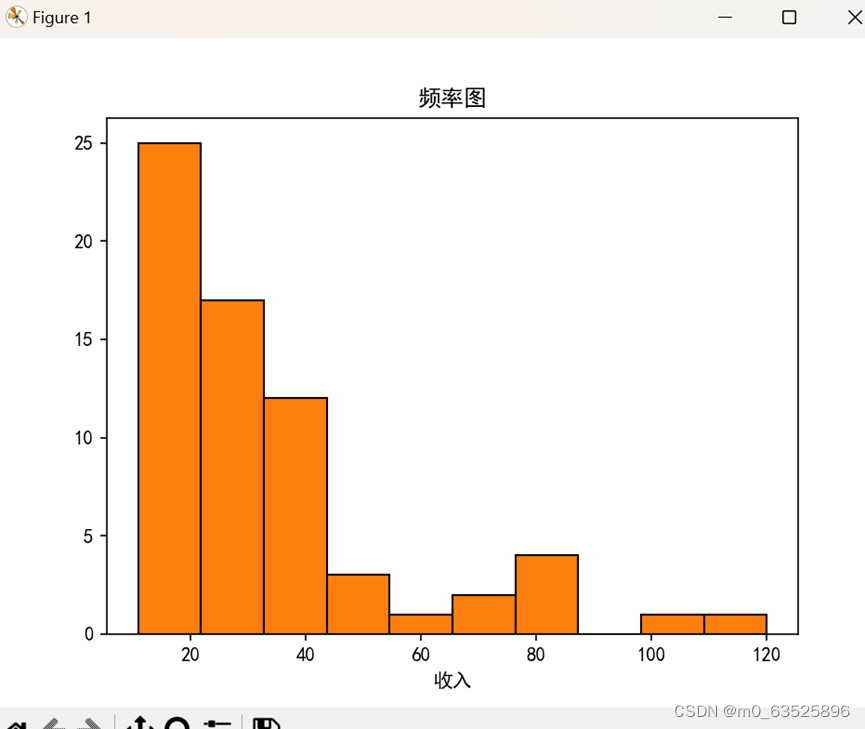
频数表

频数图
完整代码:
from matplotlib import pyplot, pyplot as plt
import pandas as pd
import random
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df=pd.DataFrame({'经理收入':[11,19,14,22,14,28,13,81,12,43,11,16,31,16,23,42,22,26,17,22,13,27,108,16,43,82,14,11,51,76,28,66,29,14,14,65,37,16,37,35,39,27,14,17,13,38,28,40,85,32,25,26,16,120,54,40,18,27,16,14,33,29,77,50,19,34]})
print(df.describe())#进行数据的描述,即显示数据的平均值,中位数,标准差等等
print('///')
print('\n')
def base(x): # 基本统计量
#定义一个stats统计量计算相关的基本统计量
base = [x.count(), x.min(), x.quantile(.25), x.mean(), x.median(),
x.quantile(.75), x.max(), x.max() - x.min(), x.var(), x.std(), x.skew(), x.kurt()]
base = pd.Series(base, index=['Count', 'Min', 'Q1(25%)', 'Mean', 'Median',
'Q3(75%)', 'Max', 'Range', 'Var', 'Std', 'Skew', 'Kurt'])
print(base)
base(df)
#散点图
plt.figure(figsize=(20, 4))#设置画布大小
number = random.sample(range(1,67),66)# 从1到66中随机抽取66个数,并保存在列表number中
number.sort()#对number进行排序
pyplot.scatter(number, df)#创建一个散点图,其中number表示横坐标数据,df表示纵坐标数据
pyplot.xlabel('经理')
pyplot.ylabel('收入')
pyplot.title('散点图')
pyplot.xticks(number)
pyplot.show()
#直方图
plt.hist(df, bins=10, density=0, edgecolor="black")# 绘制直方图,设置bin数、是否归一化、边界颜色和透明度
plt.xlabel("收入")
plt.title("直方图")
plt.show()
print('///')
print('\n')
def freq(x):
H=plt.hist(x)
x = H[1][:-1]#提取直方图的边界值,即频数的上限
y = H[1][1:]#提取直方图的边界值,即频数的下限
f = H[0]#提取直方图的频数
z = f/sum(f)*100#计算频率
a = pd.DataFrame([x,y,f,z],index=['上限','下限','频数','频率'])
plt.hist(df, bins=10, density=0, edgecolor="black")
plt.xlabel("收入")
plt.title("频率图")
plt.show()
return(a)
print(freq(df))















 3848
3848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









