






目录
实验题通过df -h,把opt目录下磁盘使用率写一个冒泡排序
数组的作用
数组的最大作用,一次性定义多个变量就是对数组进行增删改查
创建数组
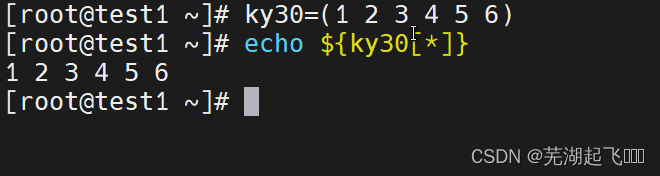
第一行创建数组
第二行获取数组当中的所有元素
也可以用@来代替*不加""时意思是一样的都是吧元素作为单个值来处理
加了""之后就会把123456作为一个整体输出了
$# :表示参数的数量,也就是数组的长度
创建数组三种格式
第一种格式:ky29=(1 2 3 4 5 )
第二种格式:arr=([0]=1 [1]=2 [2]=3)
第三种方式:abc=“1 2 3 4 ”
arr1=($abc)
echo
${arr1[*]}
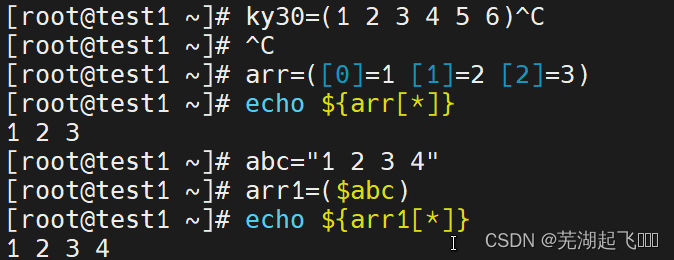
数组的下标索引是从0开始算第一个元素也就是说,数组当中第一个元素的索引是0
数组的数据类型
数值类型

字符类型

混合用法

获取数组的长度
就是显示数组当中有多少个变量
打印时加上#
这里长度就是7

读取下标索引的值
前面说了数组的下标索引是从0开始算第一个元素也就是说,数组当中第一个元素的索引是0不要混淆所以这里就是从0123开始计算对应的就是1234的4所以这里是4
![]()

数组遍历
ky29=(ztt hjp hrd qingge zjf)
for i in ${ky29[*]}
do
echo $i
done 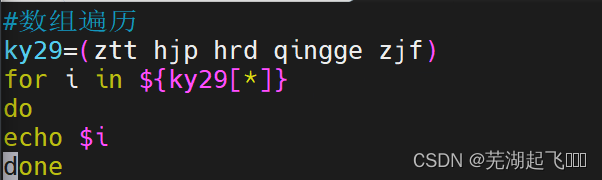
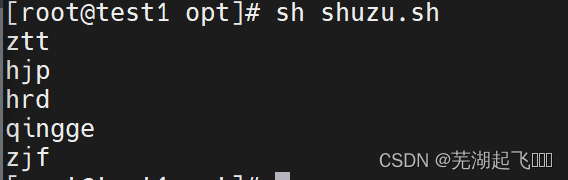
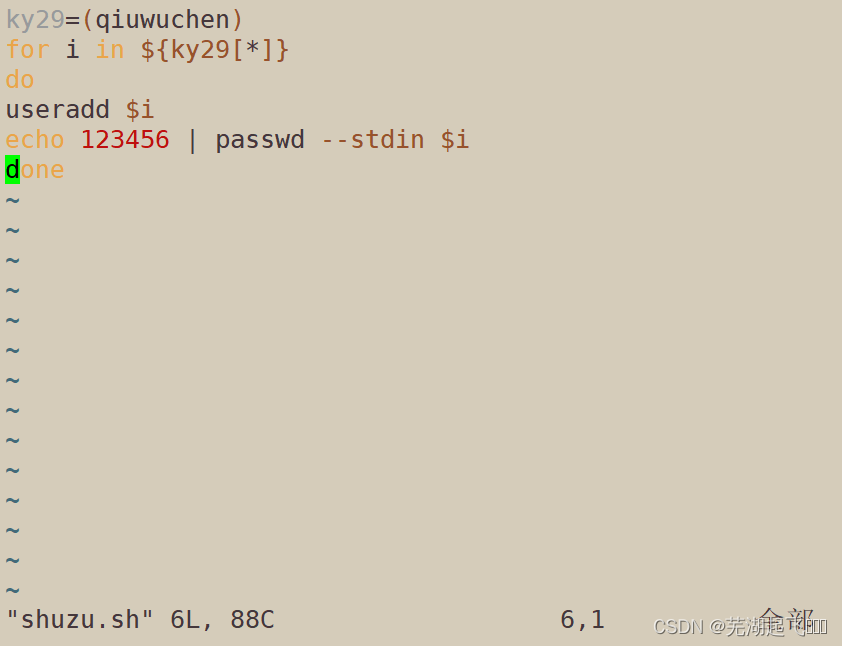
批量创建用户设置密码
ky29=(qiuwuchen)
for i in ${ky29[*]}
do
useradd $i
echo 123456 | passwd --stdin $i
done
以下是逐行解释:
ky29=(qiuwuchen)
定义了一个名为 ky29 的数组,数组中只有一个元素 qiuwuchen。
for i in ${ky29[*]}
do
对数组 ky29 进行循环,每次将其中的一个元素赋值给变量 $i。
useradd $i
使用 useradd 命令创建一个新用户,用户名为 $i,即 qiuwuchen。
echo 123456 | passwd --stdin $i
为新创建的用户设置密码为 123456,使用了 echo 命令的管道符号 | 将密码字符串 123456 传递给 passwd 命令。
done
循环结构的结束语句。
综上所述,这段代码的作用是创建一个用户名为 qiuwuchen 的新用户,并设置其密码为 123456。这段代码中使用了数组和循环结构,可以实现批量创建用户的功能。

数组切片
![]()

从0索引开始玩后走两位0 1 2 也就是1 2
下面也是同理但是不能:2:2:2
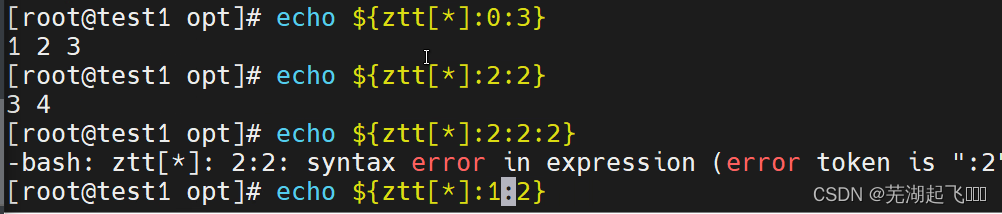
如果超出了最后一位则只显示最后一位

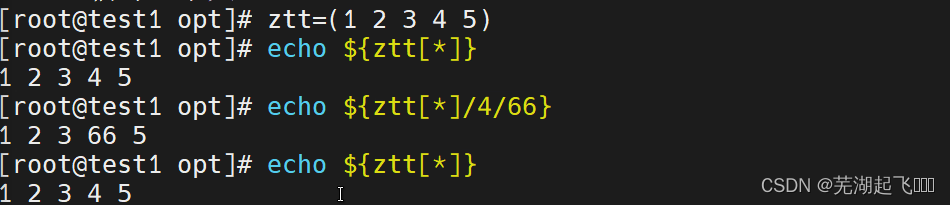
数组替换
临时替换
这里是把前一个数组当中要替换的数据4换成了66但是临时的再echo一次就回去了
永久替换
要通过重新赋值的方式才能实现要在{}里面这样才能永久替换

删除数组
unset 加数组名称即可这里删除了前面建立的ztt再echo即为空

删除指定值时需要通过下标索引来删这里要删除poor所有对应的索引是0 1 2 3 4也就是 4 poor

追加数组
索引下标是几他添加的就是几这里添加的是5虽然也会显示但是echo4查不到任何东西只有5才看得到
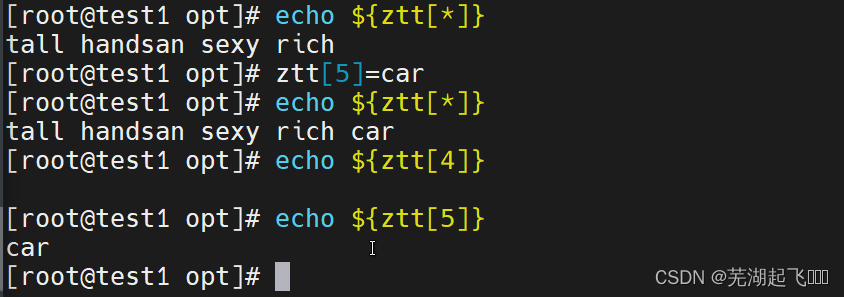
这里把4再添加上去就可以查到了
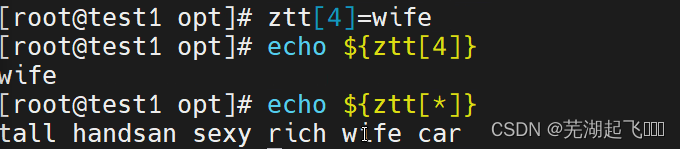
如果不想指定索引位就在后一位添加可以这样输入这样就是按顺序在最后一位添加也就是索引6添加一个boat
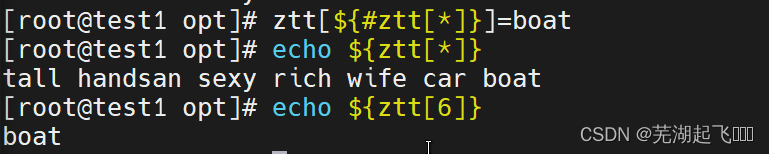 同样的道理也可以这样此方法同样默认最后一位添加无需指定索引号
同样的道理也可以这样此方法同样默认最后一位添加无需指定索引号


数组给函数传参
hanshu () {
abc1=($(echo $@)) #或者abc1=(`echo $@`)两种方式都可
以
echo "数组的值: ${abc1[*]}"
}
abc=(`seq 1 10`)
hanshu ${abc[*]}
以下是逐行解释:
hanshu () {
定义一个名为 hanshu 的函数。
abc1=($(echo $@))
将函数的所有参数作为一个字符串,通过管道传递给 echo 命令,然后使用 $() 进行命令替换,将字符串转换成一个数组。这里使用 ${@} 调用函数的参数列表,${@} 相当于 "$1" "$2" "$3" ...。
echo "数组的值: ${abc1[*]}"
输出数组的每个元素的值,使用 ${abc1[*]} 将数组元素展开为一个字符串,元素之间用空格分割。输出的字符串前面加上了 "数组的值:" 的描述性文字。
abc=(`seq 1 10`)
定义一个名为 abc 的数组,数组中包含一个序列(1~10)。
hanshu ${abc[*]}
调用函数 hanshu,并将数组 abc 中的所有元素展开为一个字符串,作为函数的参数列表传递给函数 hanshu。${abc[*]} 表示连接数组 abc 中的所有元素为一行,并以空格分隔。函数内部将这个字符串转换为一个数组,并输出每个元素的值。
综上所述,这段代码的作用是使用函数 hanshu 输出数组 abc 中所有的元素。在函数中,使用 $@ 将函数的参数列表转换为一个数组,并输出每个参数的值。在调用函数时,使用 ${abc[*]} 将数组 abc 中的所有元素连接为一个字符串,然后作为函数的参数列表传递给函数 hanshu,从而实现输出数组元素的功能。
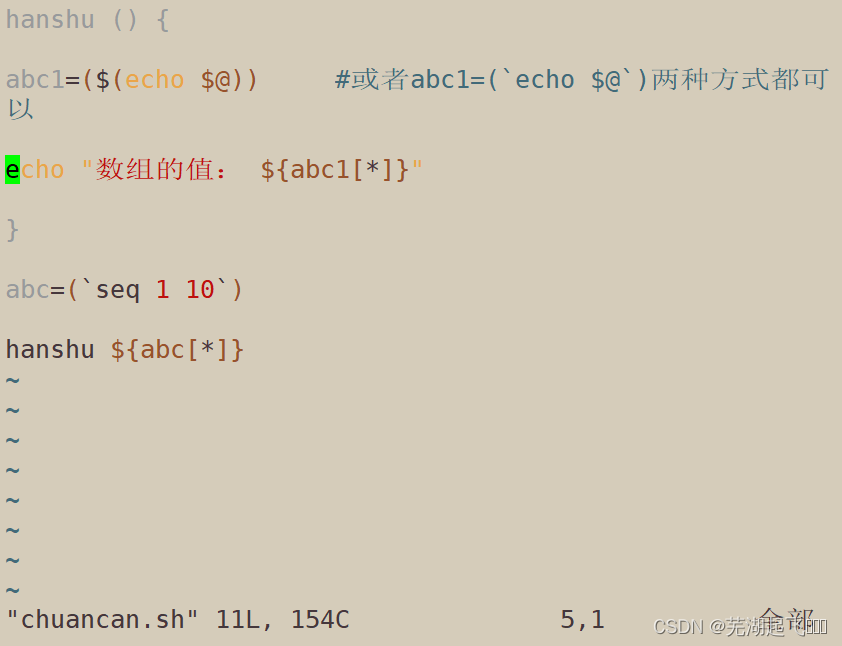

从函数返回数组
求和
test () {
abc1=(`echo $@`)
sum=0
for i in ${abc1[*]}
do
sum=$(($sum+$i))
done
echo "$sum"
}
abc=(1 2 3 4 5)
test ${abc[*]}
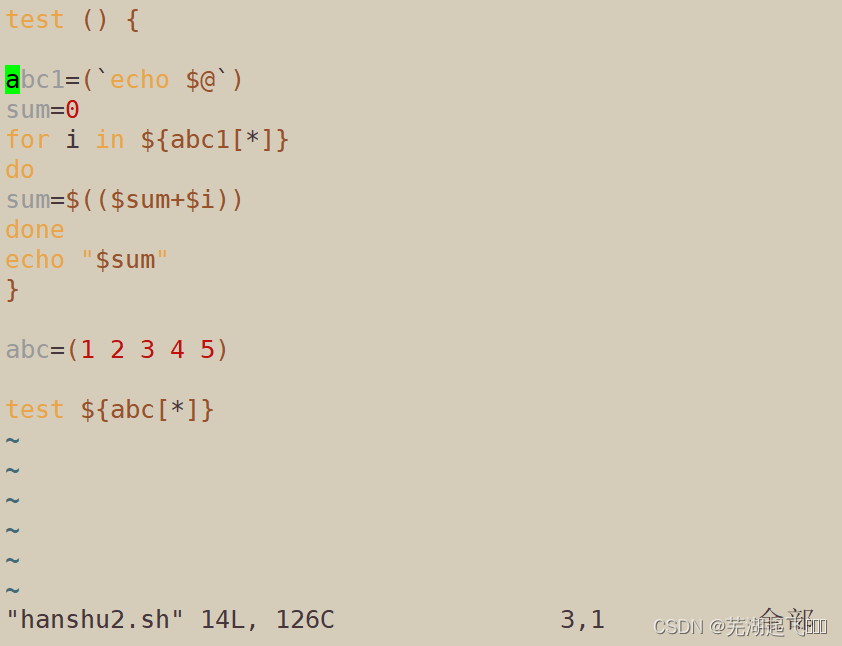
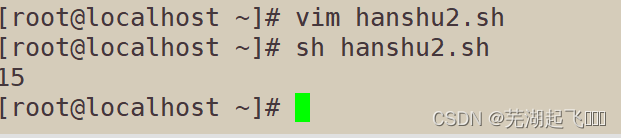
乘法
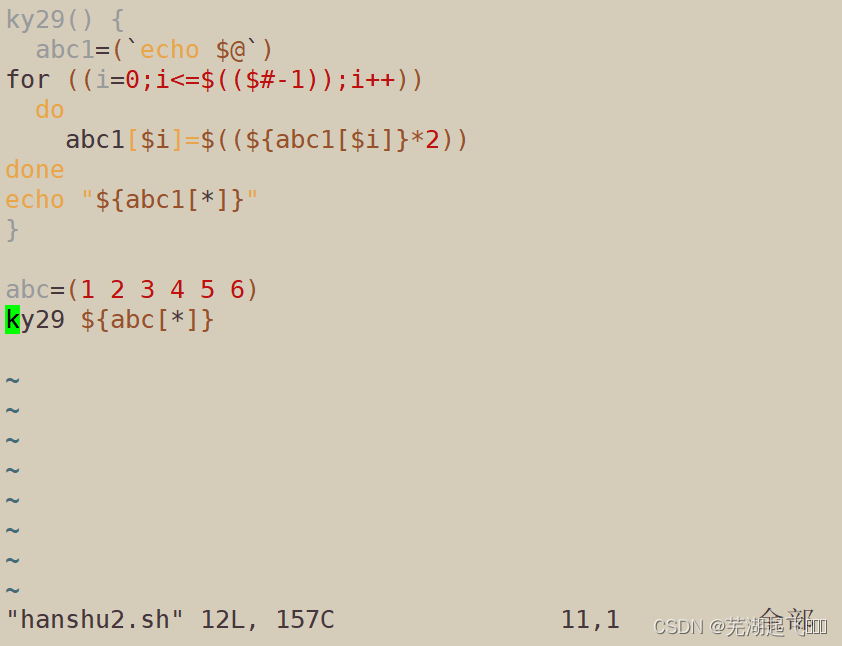
ky29() {
abc1=(`echo $@`)
for ((i=0;i<=$(($#-1));i++))
do
abc1[$i]=$((${abc1[$i]}*2))
done
echo "${abc1[*]}"
}
abc=(1 2 3 4 5 6)
ky29 ${abc[*]}

以下是逐行解释:
ky29() {
abc1=(`echo $@`)
定义一个名字为 ky29 的函数。将函数的所有参数作为一个字符串,通过管道传递给 echo 命令,然后通过 $() 进行命令替换,将字符串转换成一个数组 abc1。这里使用 ${@} 调用函数的参数列表,${@} 相当于 "$1" "$2" "$3" ...。
for ((i=0;i<=$(($#-1));i++))
do
abc1[$i]=$((${abc1[$i]}*2))
done
使用 for 循环,遍历数组 abc1 中的每一个元素,将每个元素的值乘以 2,然后重新将其赋值给对应的数组元素。
echo "${abc1[*]}"
将修改后的数组 abc1 中的所有元素使用空格连接起来,并输出到终端。
综上所述,这段代码的作用是将函数 ky29 的每个参数乘以2,然后将乘以2后的结果输出到终端。在函数内部,使用 $@ 将函数的所有参数转化为一个数组 abc1,然后使用 for 循环对数组中的每个元素进行乘以 2 的操作。最后,通过 ${abc1[*]} 将数组中所有元素连接成一个字符串,输出到终端。在调用函数时,使用 ${abc[*]} 将数组 abc 中的所有元素展开为一个字符串,作为函数的参数列表传递给函数 ky29,从而实现对数组中的每个元素乘以 2 的操作。
冒泡排序
类似旗袍上浮的动作把数据在数组中从小到大或者从大到小不停的向前或者向后移动
最小的在第一个位置最大的在最后
每一个数组都相比较小的往左边走,大的往后移
abc=(20 40 60 30 50 70)排完就是(20 30 40 50 60 70)
for双层循环来做
for外层循环控制排序轮次
for内循环比较相邻两个元素的大小,来交换位置,要比外循环小一位
abc=(20 40 60 30 50 70)
len=${#abc[*]}
for ((i = 1; i < len; i++))
do
for ((k = 0; k < len - 1; k++))
do
first=${abc[k]} # 取第一个值也就是20
j=$((k + 1)) # 当前索引号加1
second=${abc[$j]} # 取第二个值也就是40,这里就是要拿20和40比大小以此来排序
if [ $first -gt $second ]
then
temp=$first # 把第一个元素的值保存在临时变量当中
abc[$k]=$second
abc[$j]=$temp
fi
done
done
echo "${abc[*]}"
以下是逐行解释:
abc=(20 40 60 30 50 70)
len=${#abc[*]}
定义一个数组 abc,数组中包含了 6 个整数。然后,使用 ${#abc[*]} 获取数组 abc 的长度,存储到变量 len 中。
for ((i = 1; i < len; i++))
do
for ((k = 0; k < len - 1; k++))
do
first=${abc[k]} # 取第一个值也就是20
j=$((k + 1)) # 当前索引号加1
second=${abc[$j]} # 取第二个值也就是40,这里就是要拿20和40比大小以此来排序
if [ $first -gt $second ]
then
temp=$first # 把第一个元素的值保存在临时变量当中
abc[$k]=$second # 交换两个元素的位置
abc[$j]=$temp
fi
done
done
使用双重循环对数组 abc 进行冒泡排序。外层循环控制比较的轮数,从 1 到 len - 1。内层循环用于比较相邻元素的大小并进行交换。在每一轮循环中,将数组中第一个元素的值保存到变量 first 中,将数组中第二个元素的值保存到变量 second 中。然后,通过比较 first 和 second 的大小,如果 first 大于 second,则交换这两个元素的位置。在交换元素位置时,使用临时变量 temp 保存第一个元素的值,从而实现交换操作。
echo "${abc[*]}"
输出已经排序后的数组 abc,使用 ${abc[*]} 将数组的所有元素连接成一个字符串,并使用双引号括起来输出,这样可以保证字符串中的空格不会被忽略。
解题思路
题目中给出的代码是一个冒泡排序算法实现。它的思路是从数组的第一个元素开始,向后比较相邻两个元素的大小,如果顺序相反就交换它们的位置,直到遍历到数组的最后一个元素。然后重复这个过程,直到排序完成。
我们通过对代码的逐行分析,可以将它的执行流程分成以下几个步骤:
-
定义要排序的数组,比如
abc=(20 40 60 30 50 70)。 -
获取数组的长度,保存在变量
len中。 -
使用双重循环对数组进行冒泡排序,最外层循环控制排序的轮数,内层循环用于比较相邻元素的大小并交换它们的位置。
-
对于每对相邻的元素,在内层循环中按照冒泡排序的方法进行比较,并在必要的情况下交换它们的位置。
-
每一轮排序完成后,外层循环的计数器
i自增。 -
当外层循环的计数器
i等于数组长度时,冒泡排序完成。 -
最后,输出已经排序好的数组,即输出
${abc[*]}。
可以直接运行这个算法,将要排序的数组赋值给 abc,然后按照上述流程对代码进行逐行分析和注释。


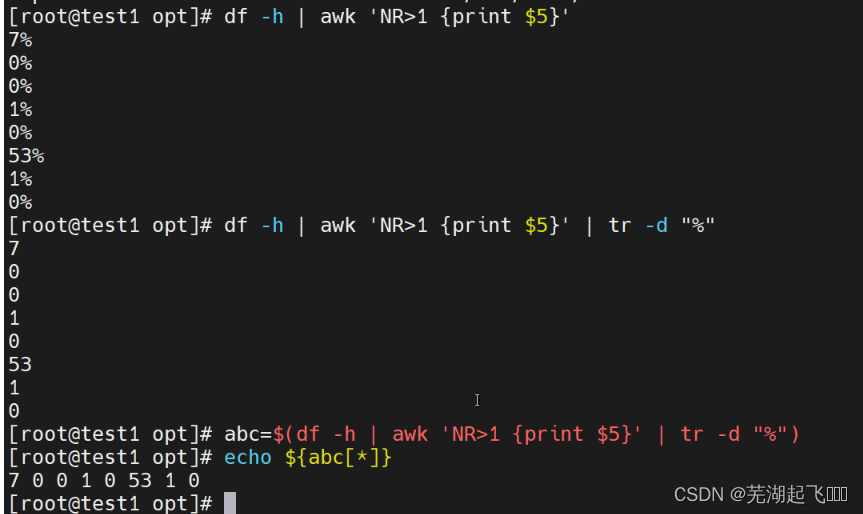
实验题通过df -h,把opt目录下磁盘使用率写一个冒泡排序
我们先来查询一下看看都有什么
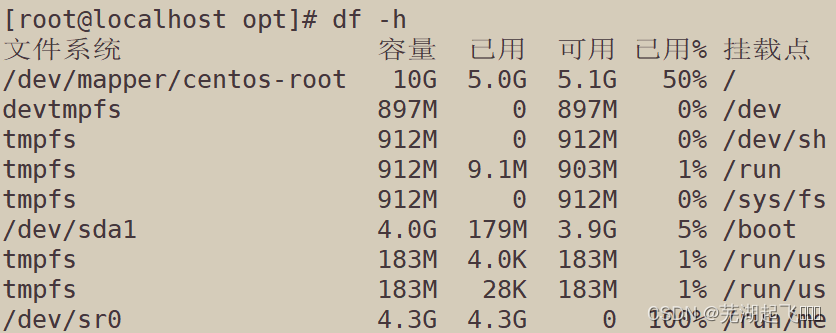
这里可以看到要排序的是已用的磁盘占用
想要把他冒泡排序就要先取值但这里有百分号所以要给他先切片
这段命令的含义是获取当前计算机上所有磁盘分区的使用率,将其保存到一个数组中,并输出到屏幕上。
以下是这个命令的各个部分对应的含义:
-
df -h: 显示当前计算机上所有磁盘分区的使用情况。其中-h选项表示使用易读的格式显示磁盘空间的大小和使用情况,比如 "2.5G" 或 "67%" 等等。 -
|: 重定向符号,将df -h命令的输出重定向到下一个命令中。 -
awk 'NR>1 {print $5}': 使用awk命令来处理df -h的输出,提取其中的第五列数据。具体来说,awk命令会将df -h的输出分解成多个字段,在这里我们使用$5来获取第五个字段的值,也就是磁盘分区的使用率。-
NR>1表示只匹配行号从第二行开始的数据,因为df -h的第一行是表头。 -
{print $5}表示输出第五个字段的值。
-
-
|: 再次使用重定向符号,将awk命令的输出重定向到下一个命令中。 -
tr -d "%": 将awk命令的输出中所有的百分号字符删除。因为awk命令的输出结果中会包含一些百分号字符,我们需要先将它们删除掉,以便后续能够对磁盘使用率进行排序。-
-d "%"表示删除所有的百分号。
-
综合起来,这段命令的含义就是:获取当前计算机上所有磁盘分区的使用率,并将使用率保存到一个数组中。这个命令的输出结果是一个数字数组,输出的内容是所有磁盘分区的使用率,单位为百分比。
以下是每一行代码的注释,用通俗易懂的语言来解释代码的含义:
# 获取磁盘使用率,并将其保存到数组 ky29 中
ky29=($(df -h | awk 'NR>1 {print $5}' | tr -d "%"))
# 获取数组 ky29 的长度,这里的 # 是 Bash 中的一个运算符,用于获取数组长度或字符串长度。具体来说,${#ky29[*]} 表示获取 ky29 数组的长度,即数组中元素的个数,${#ky29} 其中的 [*] 表示对数组中的所有元素进行操作,即可返回 ky29 数组的长度。
len=${#ky29[*]}
# 这是外部循环,i 从 1 开始,循环次数是 len - 1次,因为冒泡排序算法需要将最大值逐步往后推。例如,第一轮排序时,需要比较 ky29[0] 和 ky29[1],第二轮排序时,需要比较 ky29[0] 和 ky29[2],等等,循环次数是总元素数减一个(len - 1)。
for ((i=1;i<len;i++))
do
for ((k=0;k<len-1;k++)) # 内层循环也是使用 for 命令实现,循环次数是剩余需要排列的元素数量减去 1。
#内层循环中,在第 k 次排序中,首先比较数组中第 k 个元素和它后面的第 k+1 个元素的大小,如果前一个元素比后一个元素大,就交换这两个元素的位置,否则就保持不变。内层循环结束后,第 k 个元素就是已排序的最小值,它将被放到数组的前面,以作为下一轮比较的基准。外层循环结束后,数组将按从小到大的顺序排列。
do
# 获取当前要比较的两个元素的值
first=${ky29[k]}#获取第一个值也就是50
j=$((k+1)) # 当前索引号加1当前第一次索引号为0
second=${ky29[$j]}# 取第二个值也就是0来和第一个值50对比
if [ $first -gt $second ] #这行代码是一个条件判断语句,用来比较数组中第 k 个元素和第 k+1 个元素的大小。如果第 k 个元素(即 $first)比第 k+1 个元素(即 $second)大(即 $first > $second),则条件为真,执行以下代码块。否则,条件为假,跳过以下代码块。
then
temp=$first #这句代码将第 k 个元素(即 $first)的值保存到了一个临时变量 $temp 中,以便后面进行交换时使用。
ky29[$k]=$second
ky29[$j]=$temp # 这两句代码用来对数组元素进行交换位置。具体来说:将第 k+1 个元素(即 $second)的值赋给第 k 个元素(即 ky29[$k]),即将第 k+1 个元素的值赋给第 k 个元素,即 ky29[k] = $second。将临时变量 $temp 中保存的第 k 个元素的值(即 $first)赋给第 k+1 个元素(即 ky29[$j]),即将第 k 个元素的值赋给第 k+1 个元素,即 ky29[j] = $temp。这样,就完成了第 k 个元素和第 k+1 个元素的位置交换操作。
fi
done
done
# 输出排序后的数组 ky29
echo "${ky29[*]}"
这段代码的目标是要将当前计算机上所有磁盘分区的使用率从小到大排列起来。它使用的是一个基于冒泡排序算法的排序方法。
具体来说,这段代码的运行原理和机制如下:
-
首先,使用
$ df -h命令获取当前计算机上所有磁盘分区的使用情况,其中-h选项表示使用易读的格式显示磁盘空间的大小和使用情况,比如 "2.5G" 或 "67%" 等等。 -
使用
$ awk 'NR>1 {print $5}'命令,可以将df -h命令输出的结果中的第五列,也就是磁盘分区的使用率提取出来。-
表达式
'NR>1 {print $5}'中的NR>1表示只匹配行号从第二行开始的数据,因为df -h命令的第一行是表头。 -
而
{print $5}表示只输出第五列的数据,也就是磁盘分区的使用率。
-
-
为了方便后续排序,使用
$ tr -d "%"命令从提取的磁盘分区使用率中将百分号字符去掉。 -
将经过处理后的磁盘使用率数组保存到名为
ky29的数组中。这个数组被创建成一个 Bash 数组,可以存储$ awk处理结果中的多个值。 -
使用
$ len=${#ky29[*]}命令计算数组ky29的长度$len,也就是当前计算机上磁盘分区的数量。 -
开始进行冒泡排序,将
ky29数组中的元素按从小到大的顺序重新排列。在冒泡排序的过程中,两个相邻元素之间进行比较,如果前一个元素的值大于后一个元素的值,则交换它们的位置。排序过程由外层循环和内层循环实现。-
外层循环负责遍历整个数组,循环次数是要排列的元素总数减去 1。
-
内层循环则用来比较和交换数组元素的位置。在每一次排序中,从第一个元素开始遍历到倒数第二个元素。比较当前元素和下一个元素的大小,如果前一个元素比后一个元素大,则交换它们的位置。
-
-
当所有的元素都被排列好之后,输出已排列好的
ky29数组中的元素,也就是当前计算机上所有磁盘分区的使用率排列结果。
综上所述,这段代码主要使用 df、awk 和 tr 命令获取磁盘使用率数组,然后使用冒泡排序算法对其进行排序,并输出排序结果。
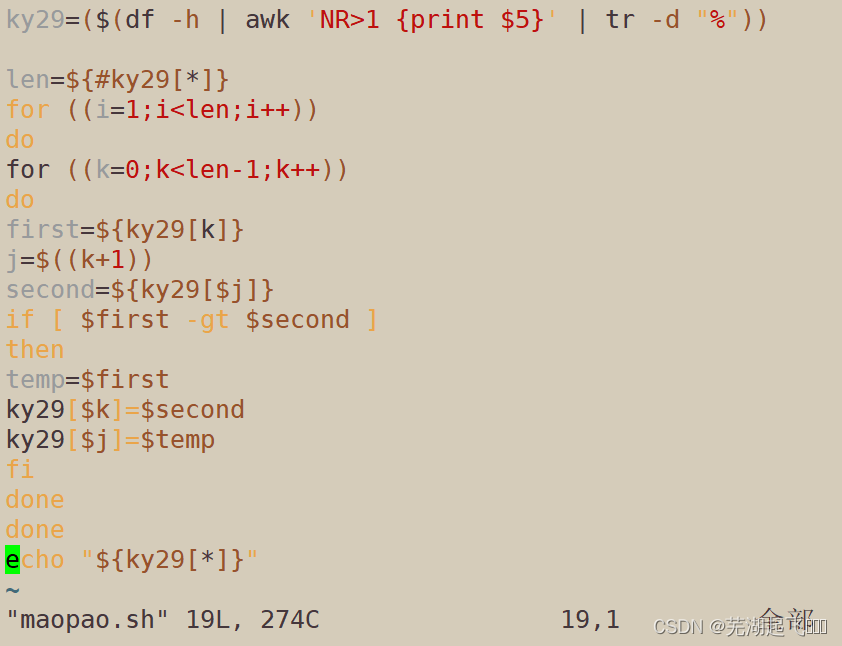

这里可以看见磁盘占用已经按照从小到大的顺序排好了至此排序结束















 6463
6463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









