







*不求点赞,只求耐心看完,指出您的疑惑和写的不好的地方,谢谢您。本人会及时更正感谢。希望看完后能帮助您理解算法的本质*
一、题目:本文用一道题深度剖析记忆化和暴搜的区别
一个整数总可以拆分为2的幂的和,例如: 7=1+2+4 7=1+2+2+2 7=1+1+1+4; 7=1+1+1+2+2; 7=1+1+1+1+1+2; 7=1+1+1+1+1+1+1 总共有六种不同的拆分方式。 再比如:4可以拆分成:4 = 4,4 = 1 + 1 + 1 + 1,4 = 2 + 2,4=1+1+2。
用f(n)表示n的不同拆分的种数,例如f(7)=6. 要求编写程序,读入n(不超过1000000),输出f(n)%1000000000。
输入描述:
每组输入包括一个整数:N(1<=N<=1000000)。
输出描述:
对于每组数据,输出f(n)%1000000000。
示例1
输入
7
输出
6
二、暴搜:详解细节问题,看一遍终生难忘!

思路:
在这个问题中,sum是当前已经选取的物品总重量,last是上一次选取的物品的编号。
在搜索时,如果当前搜索到第i个物品,那么sum就表示前i-1个物品已经选了多少,last就表示上一次选取的物品的编号。
sum和last的主要作用是为了避免枚举重复方案。由于这道题目需要枚举所有选取物品的方案,因此在搜索的过程中,需要记录下已经选取的物品的编号和总重量,避免重复搜索相同的方案。
具体地,在每一层搜索中,都需要从上一次选取的物品编号开始枚举下一个物品,同时统计已经选取的物品总重量。如果当前物品已经选取过,那么就跳过这个物品,继续枚举下一个物品。如果当前已经选取的物品总重量超过了背包容量,那么就返回。
最终,当搜索到第n个物品时,如果已经选取的物品总重量正好等于背包容量,那么就说明找到了一种可行方案,将结果加1。
last的作用:
last表示上一次选取的物品的编号。主要作用是为了避免枚举重复方案。由于这道题目需要枚举所有选取物品的方案,因此在搜索的过程中,需要记录下已经选取的物品的编号和总重量,避免重复搜索相同的方案。
具体地,在每一层搜索中,都需要从上一次选取的物品编号开始枚举下一个物品,同时统计已经选取的物品总重量。如果当前物品已经选取过,那么就跳过这个物品,继续枚举下一个物品。如果当前已经选取的物品总重量超过了背包容量,那么就返回。
重复的情况:因为在题目中:[1 2 1] = [1 1 2] = [2 1 1]三种顺序不同的序列,但是却是同一种方案!所以说last就是为了避免出现这种情况;而这种情况的递归体通常是这样的:
即每次从1开始枚举!!
for (int i = 1; i <= n; i *= 2) {
// 从上一次选择的数开始,每次选择下一个2的幂次方数
res += dfs(sum + i);
}
从而造成重复而last变量的引入就可以避免这种情况,请仔细品味下面的递归树:
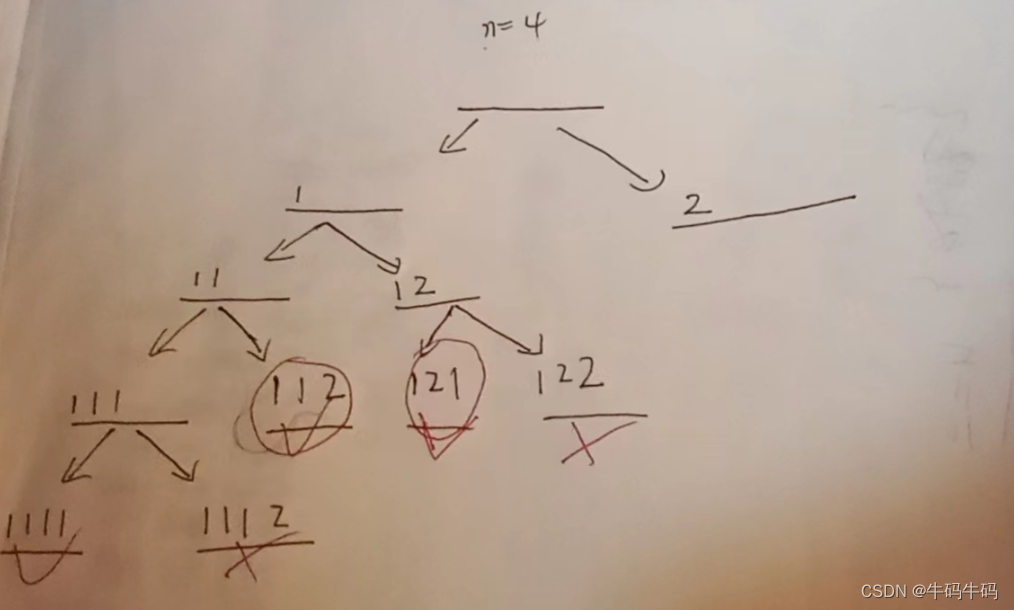
for (int i = last; i <= n; i *= 2) {
// 从上一次选择的数开始,每次选择下一个2的幂次方数
res += dfs(sum + i, i);
// 对每个选择进行递归搜索,并将结果加起来
res %= mod;
}
由图可知红色圈的部分是合法的,但是两者是重复的!而重复的原因是当我们回溯到 1____这里的时候,11___的情况已经枚举完毕了,那么接下来我们应该枚举的是:12___的情况,而当你从 dfs (sum, last = 2)去递归的时候,那么 递归里的for循环就是从 i=last=2开始,而不是从1开始,从1开始的话,就会出现重复!本质是个完全背包问题!所以才会涉及重复性!
假设没有last呢?代码如下:
for (int i = 1; i <= n; i *= 2) {
// 从上一次选择的数开始,每次选择下一个2的幂次方数
res += dfs(sum + i);
}
那么结合图和代码进行模拟,那么回溯到 1__时,开始递归 12___的下一个位置:dfs (sum) ,然后由 for(int i=1; ) dfs(sum + i) —> 12 1___,即每次都从1开始!
res为什么是局部变量?
记住,在递归里面用 局部变量去记录答案的时候,记录的是:当前状态到终点状态的答案。而不是起点到终点的答案
答案要求是最大值:则res记录的是从当前状态到终点状态的最大值。
答案要求是方案数:则res记录的是从当前状态到终点状态的方案数目。
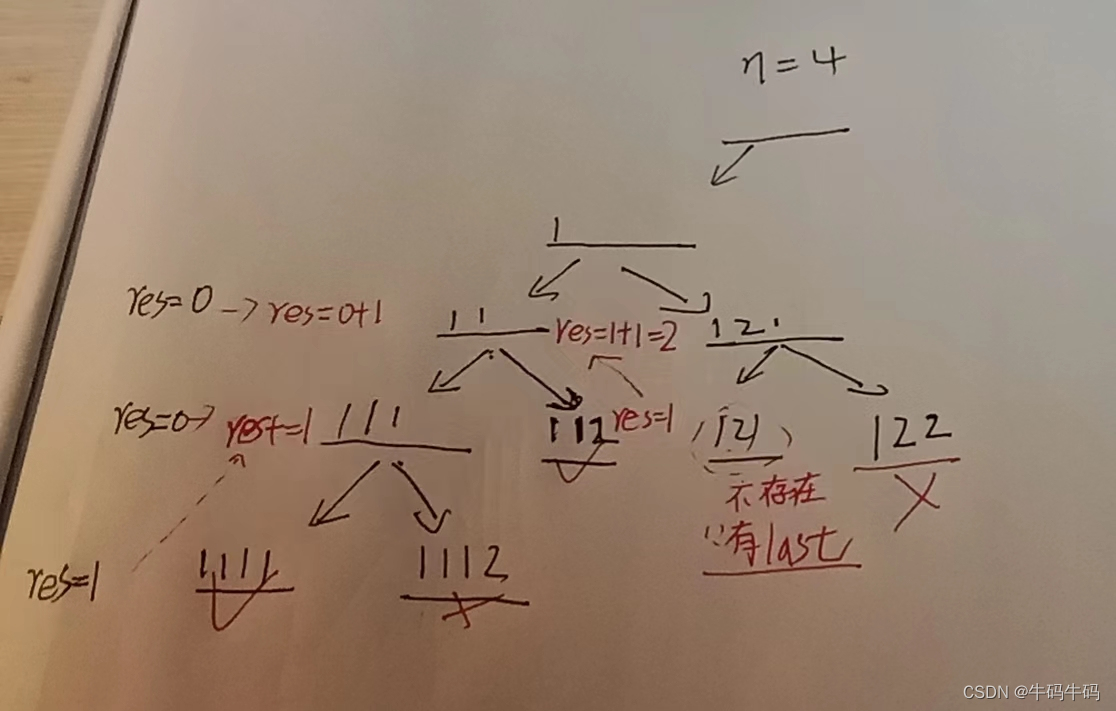
那么很明显:第二层的
r
e
s
res
res 记录的是从 11___到 目标和等于4的状态 11XXXX…的状态的方案数,为2(1111,112);
第三层的res=1,记录的是从:111__到目标状态的方案数:(111);
依次类推,由于第三层的所有状态(111___)属于第二层状态(11___)的子集,所以说,第三层的方案也是包括在第二层里面的,回溯的时候会累加答案:
r
e
s
+
=
d
f
s
(
.
.
.
)
;
res += dfs (...);
res+=dfs(...);
批注:没想到 $2^x$可以用一个for循环来表示$2^0,2^1,,2^2...$:而我之前还单蠢地写了一个快速幂来求解:
for (int i=1; i <= n; i *= 2)
就可以表示2的0次幂到2的i次幂了,i=1,表示的是2的0次幂
而我之前写的如下;
int qmi(int a, int b)
{
int res=1;
while (b)
{
if (b&1) res = res*1ll*a;
a = a*1ll*a;
b >>= 1;
}
return res;
}
for (int i=0; qmi(2, i) <= n; i ++) 我好笨!!!!
或者:
for (int i=0; (1<<i) <= n; i ++) 我真的笨!!!!
....
代码:
#include <iostream>
#include <vector>
using namespace std;
const int mod = 1e9;
int n;
int dfs(int sum, int last)
{
if (sum == n) {
// 如果当前和等于n,则返回1,表示找到一种方案
return 1;
} else if (sum > n) {
// 如果当前和大于n,则返回0,表示不是有效方案
return 0;
}
int res = 0;
for (int i = last; i <= n; i *= 2) {
// 从上一次选择的数开始,每次选择下一个2的幂次方数
res += dfs(sum + i, i);
// 对每个选择进行递归搜索,并将结果加起来
res %= mod;
}
return res;
}
int main()
{
cin >> n;
cout << dfs(0, 1) << endl;
return 0;
}

三、记忆化搜索:千万不要错过,很精彩!
思路:
对于记忆化而言,上面的 r e s res res,实际上就是记忆化里面的一种体现,只不过它并没有记录的是当前状态是什么!!!,
- 而记忆化的本质就是记录当前状态,到目标状态的答案,即记录了答案,也记录了当前的状态!!
而一个局部变量 $res$,仅仅记录的是当局的答案!- 而记忆化的高效就在于这里:可以利用记录的
状态及该状态的答案去提前判断后面的路径是否已经 (递归) 走过了,走过了的话,说明一定记录了当前的答案,所以直接返回 (剪枝) 即可!而不是花费时间走一遍,从而造成2倍的时间,得到了同样的效果!
一个简单的例图阐述记忆化的作用:
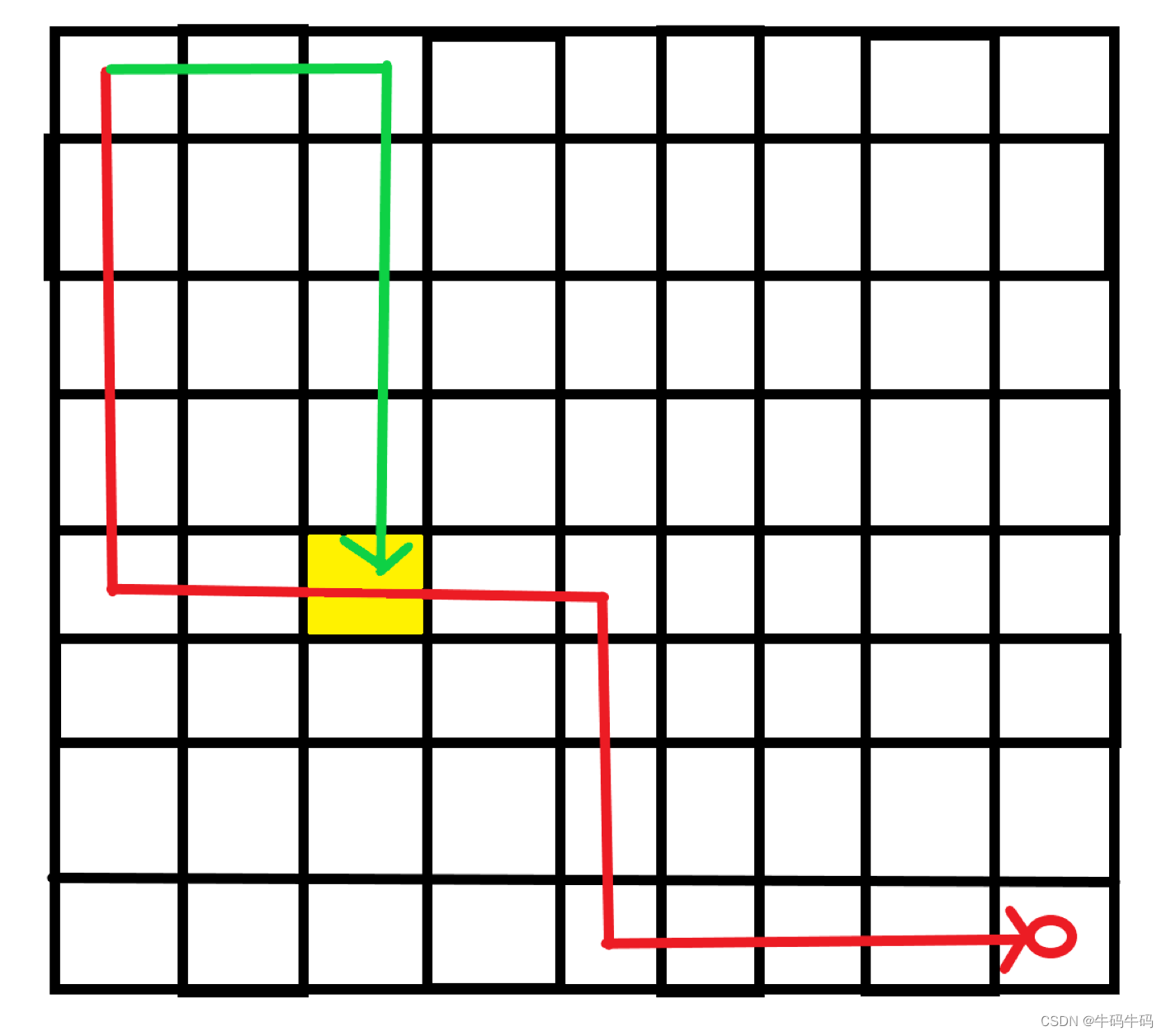
如图所示:红色的路径,是之前已经走过了的,绿色的路径是当前正在走的,如果这里采用的是暴搜,那么在相遇点黄色格子,绿色路线再暴搜一遍,枚举完其所有的分支后,其最优解仍然是和红色的后半段路径一样的,从而造成了大量的枚举,因为每个点都会存在有大量的分支!
但如果采用的是记忆化搜索就不一样了!在第一次红色路径的时候,回溯的时候,我们就会记录各个点(状态)到目标点的最优解,那么在绿色路径走的时候,在黄色格子点,会即刻返回,而不是去搜索,直接就利用了记忆化里的答案,返回累加,然后将该答案和之前的最优解进行比较!取一个更优的!















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









