







哈夫曼树的基本介绍
-
相关概念:
-
哈夫曼树:n个带权值的叶子结点构成的二叉树,若该树的路径长度(WPL)达到最小
-
路径长度:L-1(第L层)
-
带权路径长度:路径长度*该结点权值
-
树的带权路径长度(WPL):所有叶子结点的带权路径长度之和(权值越大应离根结点越近)
-
WPL最小的就是哈夫曼树
-
-
构建哈夫曼树的步骤:
-
从小到大进行排序,将每一个数据看作一棵最简单的二叉树
-
取出根节点权值最小的两棵二叉树
-
组成一棵新的二叉树,该新的二叉树根节点的权值是前面两棵二叉树根节点权值之和
-
原列表中加入这棵新树,删去两棵旧树,再重复上述过程,知道只剩下一棵树
-
-
哈夫曼树的代码实现
import java.util.ArrayList;
import java.util.Collections;
public class HuffmanTree {
public static void main(String[] args) {
int arr[] = {1, 4, 2, 3, 66, 44};
Node root = createHuffmanTree(arr);
preOrder(root);
}
public static Node createHuffmanTree(int[] arr) {
//第一步为了操作方便
//1.遍历arr数组
//2.将arr中的每个元素构成一个Node
//3.将node放入ArrayList中
ArrayList<Node> nodes = new ArrayList<>();
for (int value : arr) {
nodes.add(new Node(value));
}
while (nodes.size() > 1) {
Collections.sort(nodes);
//第二步将权值最小两棵树取出组成新树,重复过程
Node leftNode = nodes.get(0);
Node rightNode = nodes.get(1);
Node node = new Node(leftNode.value + rightNode.value);
node.setLeft(leftNode);
node.setRight(rightNode);
nodes.remove(leftNode);
nodes.remove(rightNode);
nodes.add(node);
}
return nodes.get(0);
}
public static void preOrder(Node root){
if (root==null){
System.out.println("树空");
return;
}else root.preOrder();
}
}
//让Node实现Comparable接口,实现排序
class Node implements Comparable<Node> {
int value;//结点权值
Node left;//指向左子结点
Node right;//指向右子节点
public void preOrder() {
System.out.println(value);
if (left != null) {
left.preOrder();
}
if (right != null) {
right.preOrder();
}
}
public Node(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
@Override
public int compareTo(Node o) {
return this.value - o.value;//从小到大排
}
}
哈夫曼编码
-
基本介绍
-
哈夫曼编码是一种编码方式,可用于数据压缩,压缩率在20%~90%
-
哈夫曼编码是可变编码的一种,哈夫曼1952年提出,被称为最佳编码
-
-
信息处理原理剖析
-
定长编码(占用空间较大)
-
变长编码(空间压缩,但编码出现二义性)
-
哈夫曼编码(空间压缩且无二义性)
-
-
构建哈夫曼编码的过程(例如:处理字符串i like you)
-
统计每个字符出现的次数,按照字符出现次数构建哈夫曼树
-
Node类中新增char类型表示字符,value表示出现次数
-
-
构建哈夫曼树
-
从小到大进行排序,将每一个数据看作一棵最简单的二叉树
-
取出根节点权值最小的两棵二叉树
-
组成一棵新的二叉树,该新的二叉树根节点的权值是前面两棵二叉树根节点权值之和
-
原列表中加入这棵新树,删去两棵旧树,再重复上述过程,直到只剩下一棵树
-
-
根据哈夫曼树,给每个字符规定编码(前缀编码),向左路径为0,右为1
-
-
说明与注意
-
哈夫曼编码是无损处理方案,满足前缀编码,不会造成多义性
-
根据哈夫曼树排序方法不同,对应的哈弗曼编码也不完全相同,但是WPL是一样的,都是最小的
-
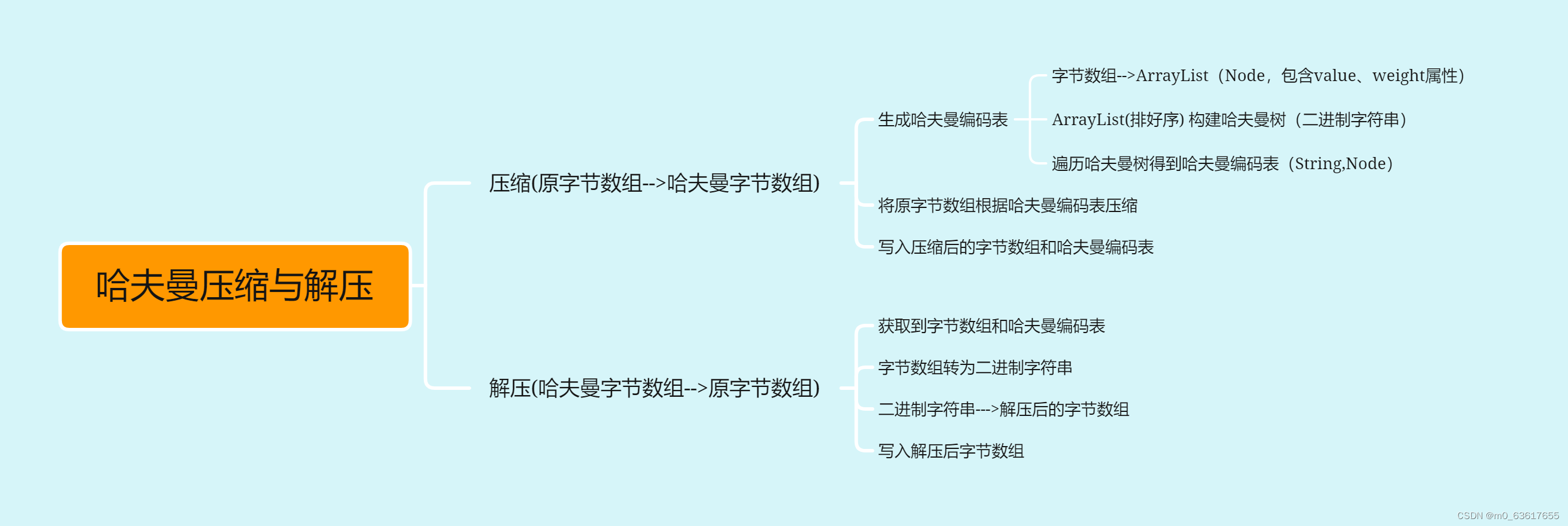
哈夫曼压缩与解压
-
数据压缩过程
-
读取压缩文件对应的字节数组文件
-
将字节数组元素转成一个个Node结点,将其存放在一个ArrayList集合中,过程用HashMap辅助操作
-
将得到的ArrayList排序(Node需要提前实现Comparable接口)
-
根据排好序的结点集合构建哈夫曼树(运用普通的构建哈夫曼树方法)
-
递归方式得到哈夫曼编码表
-
将原字节数组依据哈夫曼编码表转换成一个哈夫曼字节数组
-
先得到二进制的哈夫曼字符串,然后将其转换成字节数组(每八位二进制转成一个字节)
-
-
将字节数组和哈夫曼编码表写入新的文件即可
-
此处无法避免使用对象流(Map编码表难以与字节数组相互转化,还得考虑map和压缩数据的字节数组边界问题),但对象流相比字节流会多出头文件信息,多占用了一点点空间,实测1kb左右,当压缩文件特别小的时候,反向压缩率特别大;但只要文件大小适中,使用字节流和对象流的差距不大,对象流还方便些
-
但我这里使用的是对象流加字节流此处,对象流直接写入编码表,而数据字节数组使用二进制方式写入(为了界面展示中的进度条动态展示)
-
-
-
数据解压过程
-
读取哈夫曼编码和对应的编码表
-
调用相应方法,根据编码表将哈夫曼编码解码得到原来的编码
-
先将字节数组转化成二进制的字符串
-
得到的字符串一位位加大区间去匹配编码表,然后得到解压后的字节数组
-
-
哈夫曼编码压缩文件注意事项
-
如果文件本身就是经过压缩处理的,那么使用哈夫曼编码再次压缩效率不会有明显变化,比如视频,ppt等
-
哈夫曼编码是按字节来处理的,因此可以处理所有的文件
-
如果一个文件重复内容不多,压缩效果会不明显
-
注意二进制字符串和字节数组互转的过程,要考虑到一些细节
当前程序存在的缺陷(有时间再去迭代)
-
无法处理过大的文件,由于java虚拟机缓存的限制,大文件需要分段处理,而本程序设计之初并未考虑这么多
-
代码还是比较冗杂,可读性较差
-
......
完整源代码:















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









