






一、最后效果
因为主要练习的是发送请求、处理数据和存储数据。所以前端页面并不是很美观。

---------------------------------------------------------------------------------------------------------------------------------
二、开发平台及开发语言
1、数据存储
在vmware上安装centOS系统并配置Hadoop环境,最后用其进行分布式存储
2、后端
使用Springboot框架构建项目,并使用Maven对依赖和代码进行管理
3、前端
HTML+JavaScript+echarts
4、开发工具
后端代码在idea上进行开发,前端在Hbuilderx上进行开发
---------------------------------------------------------------------------------------------------------------------------------
三、项目整体结构
该项目为前后端分离开发模式,Springboot整合SparkSQL作为web应用的后台服务,主要功能为爬取
国家统计局人口数据,根据爬取结果进行统计分析。
前端为web页面,调用后台接口获取数据,以echarts图表展示。
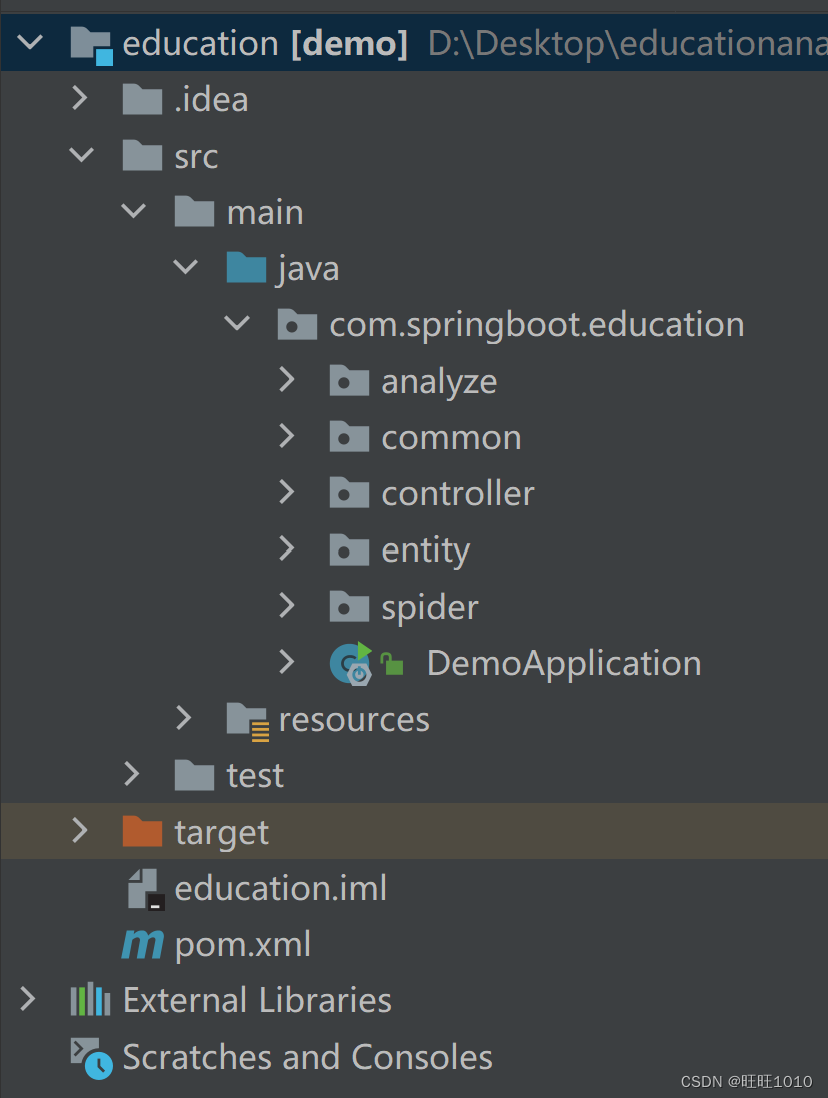
1、analyze包:对爬取下来的数据使用spark进行处理
2、common包:一些配置和组件,包含SSL证书,spark对象工厂,Unirest
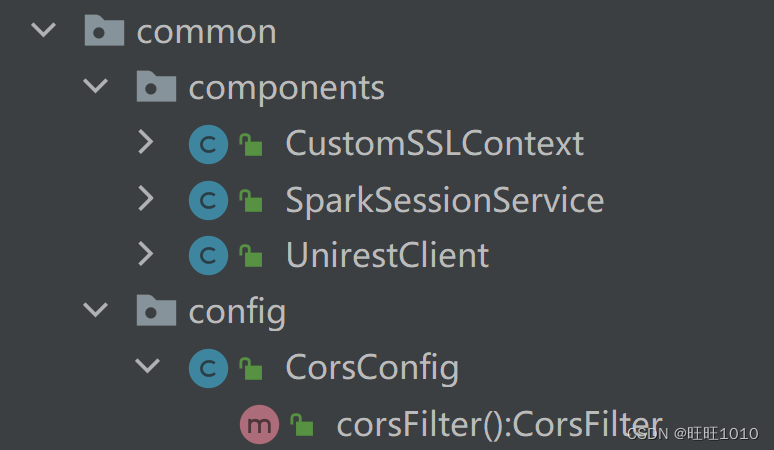
3、Controller包:将数据发送给前端
4、entyty包:实体类
5、spider包:封装请求参数,发送unirest请求,分析返回的数据找到目标数据,并将其存储。
---------------------------------------------------------------------------------------------------------------------------------
四、准备工作
1、SSL验证
使用 Unirest发出 GET 和 POST 请求时,在访问 SSL 加密站点时会遇到问题,所以要进行SSL验证。
进行SSL验证是为了确保与服务器建立的连接是安全可靠的。SSL验证帮助确认所连接的服务器是合法的,并且通过加密数据传输,防止数据在传输过程中被窃取或篡改。
public class CustomSSLContext {
public SSLContext disableCertificateValidation() {
try {
// 创建一个信任所有证书的 TrustManager
TrustManager[] trustAllCertificates = new TrustManager[]{
new X509TrustManager() {
@Override
public void checkClientTrusted(X509Certificate[]
x509Certificates, String s) throws CertificateException {
}
@Override
public void checkServerTrusted(X509Certificate[]
x509Certificates, String s) throws CertificateException {
}
public X509Certificate[] getAcceptedIssuers() {
return null;
}
}
};
// 创建 SSL 上下文并初始化
SSLContext sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, trustAllCertificates, new
java.security.SecureRandom());
return sslContext;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
2、跨源资源共享
跨源资源共享(CORS,或通俗地译为跨域资源共享)是一种基于 HTTP 头的机制,该机制通过允许服务器标示除了它自己以外的其他源(域、协议或端口),使得浏览器允许这些源访问加载自己的资源。跨源资源共享还通过一种机制来检查服务器是否会允许要发送的真实请求,该机制通过浏览器发起一个到服务器托管的跨源资源的“预检”请求。在预检中,浏览器发送的头中标示有 HTTP 方法和真实请求中会用到的头。
跨源 HTTP 请求的一个例子:运行在 https://domain-a.com 的 JavaScript 代码使用 XMLHttpRequest 来发起一个到 https://domain-b.com/data.json 的请求。
出于安全性,浏览器限制脚本内发起的跨源 HTTP 请求。例如,XMLHttpRequest 和 Fetch API 遵循同源策略。这意味着使用这些 API 的 Web 应用程序只能从加载应用程序的同一个域请求 HTTP 资源,除非响应报文包含了正确 CORS 响应头。
@Configuration
public class CorsConfig {
/**
* 跨域处理
* 给资源放行
*/
@Bean
public CorsFilter corsFilter(){
CorsConfiguration config = new CorsConfiguration();
config.addAllowedOriginPattern("*");
config.addAllowedMethod("*");
config.addAllowedHeader("*");
config.setAllowCredentials(true);
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**",config);
return new CorsFilter(source);
}
}
3、SparkSession运行Local模式
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试,在创建SparkSession时指定master为local,然后在idea中直接启动运行即可。
public class SparkSessionService {
/**
* SparkSession:spark会话管理,相当于spark入口和管理者
* builder:构建者模式
* appName:应用名称
* master:运行模式
* getOrCreate:获取或创建SparkSession
* @return
*/
/**
* Spark 2.0引入了SparkSession,其为用户提供了一个统一的切入点来使用Spark的各项功能,
* 并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。
*/
public static SparkSession sparkSession(){
System.setProperty("HADOOP_USER_NAME", "root");
//master:运行模式:local(本地模式)
//getOrCreate:获取已经得到的 SparkSession,
// 或则如果不存在则创建一个新的基于builder选项的SparkSession
return SparkSession.builder().appName("sparkService")
.master("local[*]").getOrCreate();
}
}
4、unirest发送请求
Unirest是一个简单且轻量级的HTTP请求库,它可以让开发者更容易地发送HTTP请求,并处理响应数据
public class UnirestClient {
static {
//connectTimeout配置连接超时时间,socketTimeout配置socket的超时时间
Unirest.config()
.connectTimeout(5000)
.socketTimeout(20000)
.sslContext(new CustomSSLContext().disableCertificateValidation());
}
/**
* get方法发送请求的url
* queryString发送请求参数
* asJson一json格式返回数据
* @param url
* @param params
* @return
*/
public JSONObject get(String url,JSONObject params){
//Unirest是一个简单且轻量级的HTTP请求库,它可以让开发者更容易地发送HTTP请求,并处理响应数据。
//国家统计网站提供了数据查询的http接口,爬取数据可以使用Unirest向国家数据网站发送http请求获取数据结果。
HttpResponse<JsonNode> response = Unirest.get(url).queryString(params).asJson();
String s=response.getBody().toString();
JSONObject json= JSONObject.parseObject(s);
return json;
}
}
5、实体类
为了存储爬取下来的数据,以全体教职工为例
因为爬取的是近十年的数据,所以有数量和年份两个数据.
import lombok.Data;
@Data
public class Faculty {
private String year;
private Double data;
}
五、爬数据
1、确定请求参数
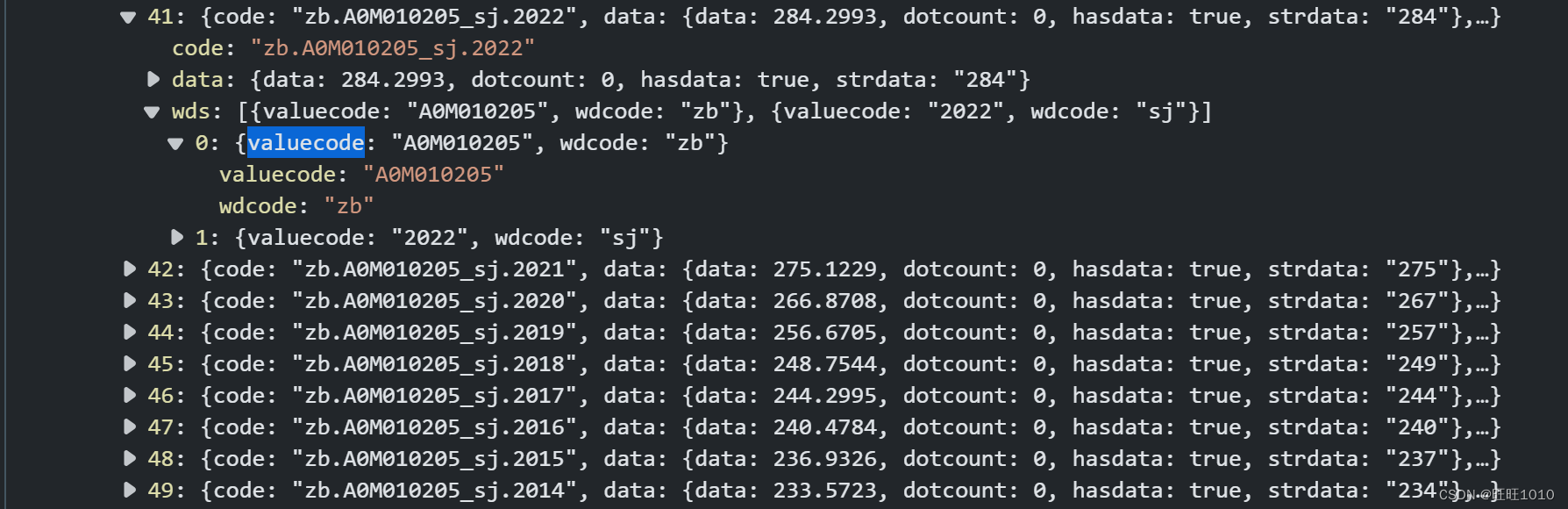
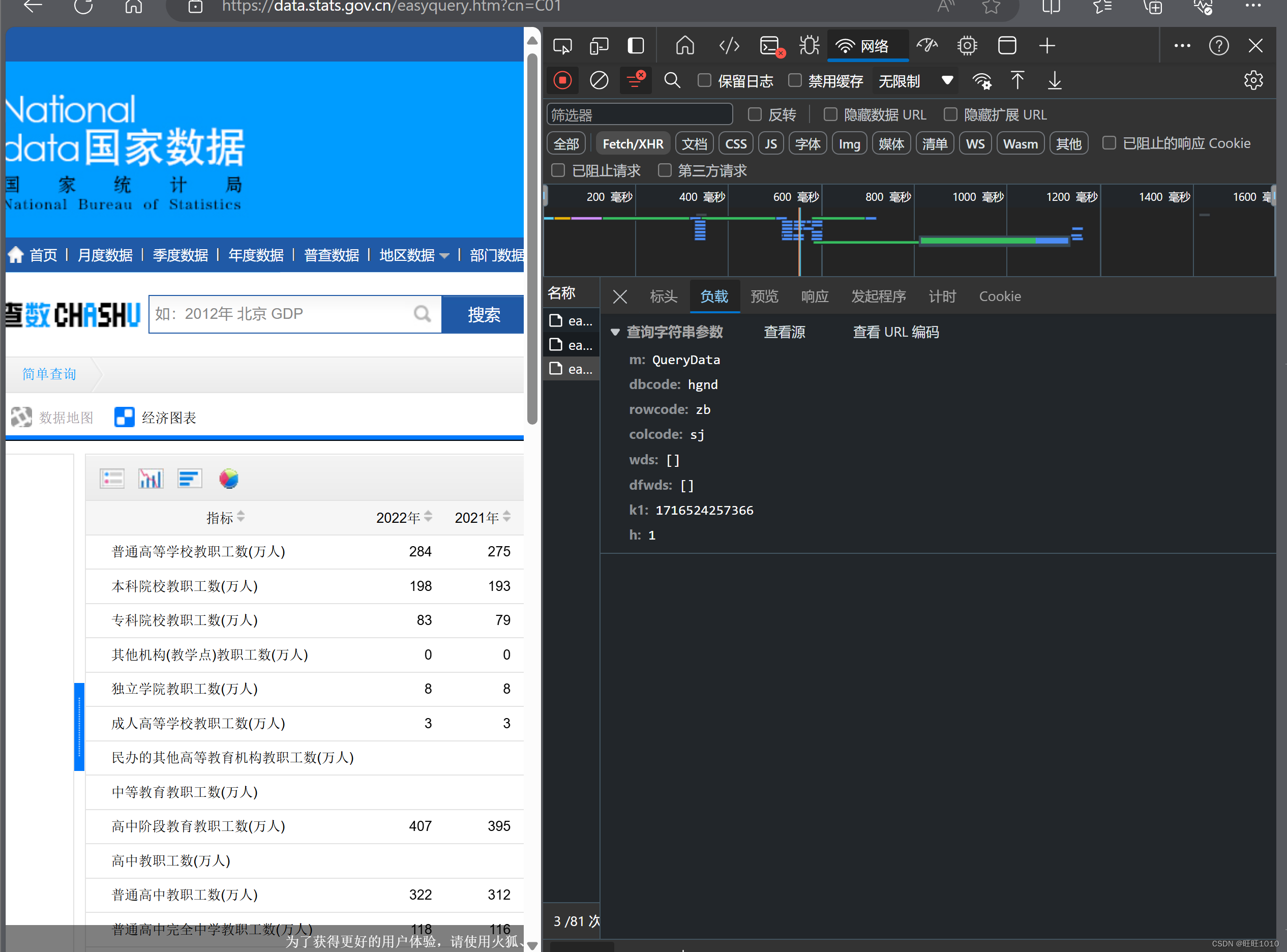
2、封装参数,发送请求,保存数据
/**
* 普通高等学校教职工人数
*/
@Slf4j
public class FacultySpider {
//请求路径
private final static String EASY_QUERY_URL = "https://data.stats.gov.cn/easyquery.htm";
//数据存储路径
private final static String LOCAL_FILE_PATH = "D:\\Desktop\\educationanalyze\\spiderdata\\faculty.csv";
//private final static String HDFS_FILE_PATH = "hdfs://spark-master:9000/peopleAnalyze/province.csv";
private final static String HDFS_FILE_PATH = "hdfs://spark-master:9000/educationAnalyze/Faculty.csv";
//得到数据
private List<Faculty> getData(){
UnirestClient unirestClient = new UnirestClient();
ArrayList<Faculty> list = new ArrayList<>();
for(int i = 2013; i < 2023; i++) {
try{
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
//查询参数封装
JSONObject params = new JSONObject();
params.put("m", "QueryData");
params.put("dbcode", "hgnd");
params.put("rowcode", "zb");
params.put("colcode", "sj");
params.put("wds", new JSONArray());
params.put("k1", System.currentTimeMillis());
JSONArray arrs = new JSONArray();
JSONObject o1 = new JSONObject();
o1.put("wdcode", "sj");
o1.put("valuecode", i);
JSONObject o2 = new JSONObject();
o2.put("wdcode", "zb");
o2.put("valuecode", "A0M010205");
arrs.add(o1);
arrs.add(o2);
params.put("dfwds", arrs);
//发送请求
JSONObject result = unirestClient.get(EASY_QUERY_URL, params);
log.info("result:{}", result);
//获取教职工的数量:result.returndata.datanodes[0].data.data
JSONObject datanode = (JSONObject) result.getJSONObject("returndata")
.getJSONArray("datanodes").get(0);
Double data = datanode.getJSONObject("data").getDouble("data");
Faculty faculty = new Faculty();
faculty.setYear(i + "");
faculty.setData(data);
list.add(faculty);
}
log.info("list:{}:",list);
return list;
}
//存文件
public void saveData(List<Faculty> list, String filePath){
SparkSession sparkSession = SparkSessionService.sparkSession();
//把list转换为DataFrame:在数据库里能做的操作在dataframe里也能做
Dataset<Row> dataFrame = sparkSession.createDataFrame(list, Faculty.class);
dataFrame.show();
//把文件存到本地的目录
dataFrame.write().mode(SaveMode.Overwrite)
.option("header","true").csv(filePath);
}
public static void main(String[] args){
FacultySpider facultySpider = new FacultySpider();
List<Faculty> list = facultySpider.getData();
// facultySpider.saveData(list,LOCAL_FILE_PATH);
facultySpider.saveData(list,HDFS_FILE_PATH);
}
}
3、spark数据分析
Spark 2.0引入了SparkSession,其为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许
用户通过它调用DataFrame和Dataset相关API来编写Spark程序。将原始数据进行拆分,year存在一个list里,data存在一个list里。并将她们都保存到result里并返回。
@Slf4j
@Component
public class FacultyAnalyze {
private final static String LOCAL_FILE_PATH = "D:\\Desktop\\educationanalyze\\spiderdata\\faculty.csv";
private final static String HDFS_FACULTY_FILE_PATH = "hdfs://spark-master:9000/educationAnalyze/Faculty.csv";
public JSONObject analyze(){
//1、读取文件
SparkSession sparkSession = SparkSessionService.sparkSession();
Dataset<Row> dataFrame = sparkSession.read().option("header","true").csv(HDFS_FACULTY_FILE_PATH);
dataFrame= dataFrame.sort("year");
dataFrame.show();
//2、将dataFrame拆分成两个list
List<String> yearList=new ArrayList<>();
List<Double> datalist = new ArrayList<>();
List<Row> rowList = dataFrame.collectAsList();
for(Row row : rowList){
yearList.add(row.getAs("year"));
datalist.add(row.getAs("data"));
}
//3、将两个list封装到JSONObject里边
JSONObject result = new JSONObject();
result.put("year",yearList);
result.put("data",datalist);
return result;
}
}
六、将数据传给前端
调用FacultyAnalyze类的analyze()进行数据处理,并接受返回值,最后将返回值传给前端。
@RestController
@RequestMapping("/faculty")
public class FacultyController {
//依赖注入
@Resource
private FacultyAnalyze facultyAnalyze;
@GetMapping("/bar")
public JSONObject facultyBar(){
JSONObject object = facultyAnalyze.analyze();
if (ObjectUtils.isEmpty(object)){
object.put("code",500);
}else {
object.put("code",200);
}
return object;
}
}
七、前端
1、接收数据并绘图
function facultyBar() {
var chart = echarts.init(document.getElementById('echart1'));
$.getJSON('http://localhost:8080/faculty/bar').success(function(result) {
if (result.code == 200) {
var option = {
tooltip: {
trigger: 'axis',
axisPointer: {
type: 'shadow'
}
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: [{
type: 'category',
data: result.year,
axisTick: {
alignWithLabel: true
},
axisLabel: {
show: true,
textStyle: {
color: '#fff'
}
}
}],
yAxis: [{
type: 'value',
axisLabel: {
show: true,
textStyle: {
color: '#fff'
}
}
}],
series: [{
name: '教职工人数',
type: 'bar',
itemStyle: {
color: '#EDA7A7'
},
barWidth: '60%',
data: result.data
}]
};
chart.setOption(option);
}
})
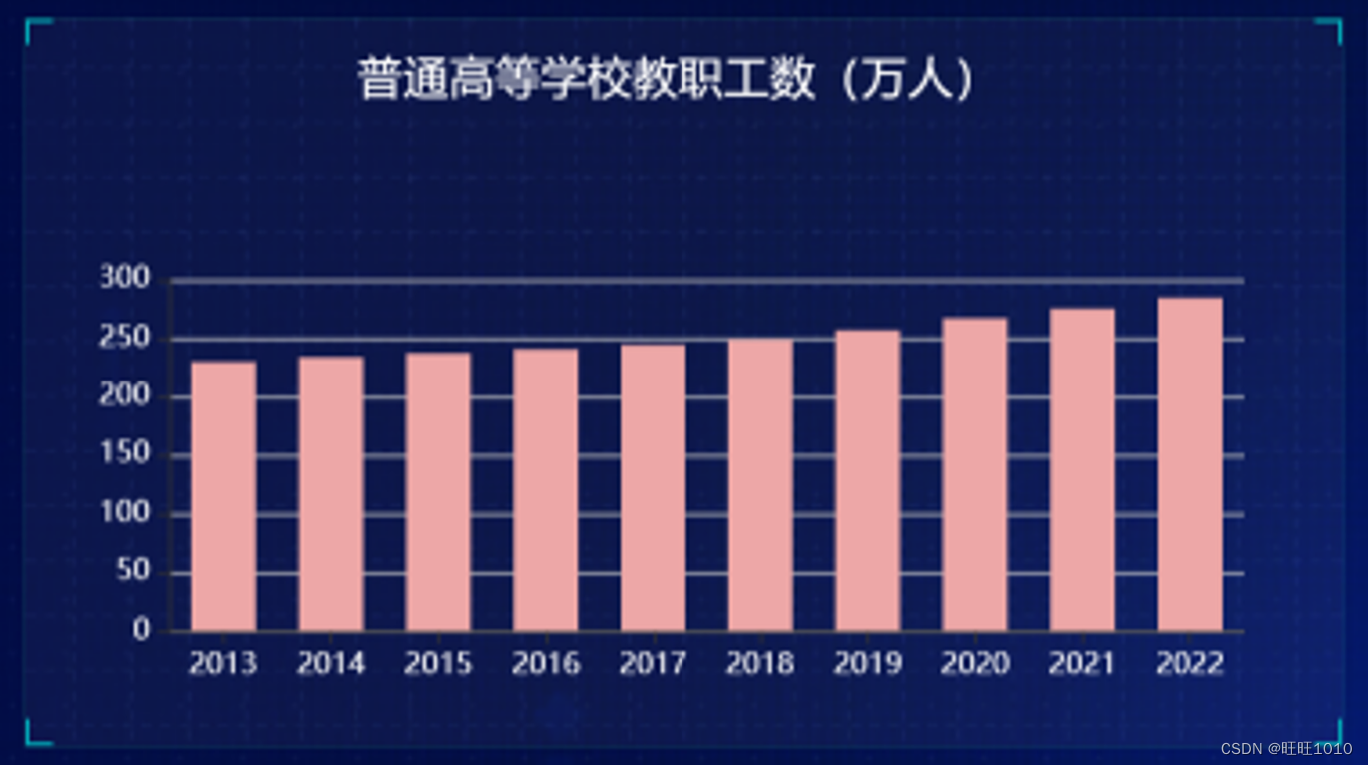
}2、效果
注意单位
八、尾声
以上就是爬取近十年普通高等学校教职工数的步骤,之后我们可以根据以上的方法爬取我们想要的数据并将其绘制成图表,思路都是一样的,只是需要改一下请求参数即可。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









