






转载AI Studio项目链接https://aistudio.baidu.com/aistudio/projectdetail/3480829
用错误打败错误:通过错误的识别将签到记录图片转化为电子表格
项目背景
懒人打卡统计:用OCR+花名册一键统计打卡结果
出席各种会议或活动时均需要进行签到,有的时候是纸质的签到表,有时候则是APP打卡,之后再人工将签到信息填入EXCEL表格中。为了避免人工操作,可以通过PaddleHub调用OCR模型,一键识别照片或者截图中的签到人姓名,并且通过字符匹配的方式,找到excel表格中的签到人进行标注。
OCR识别模型中的弊端
但OCR模型+字符匹配的方式会导致“误判”的情况发生,从而无法正确统计信息,例如:
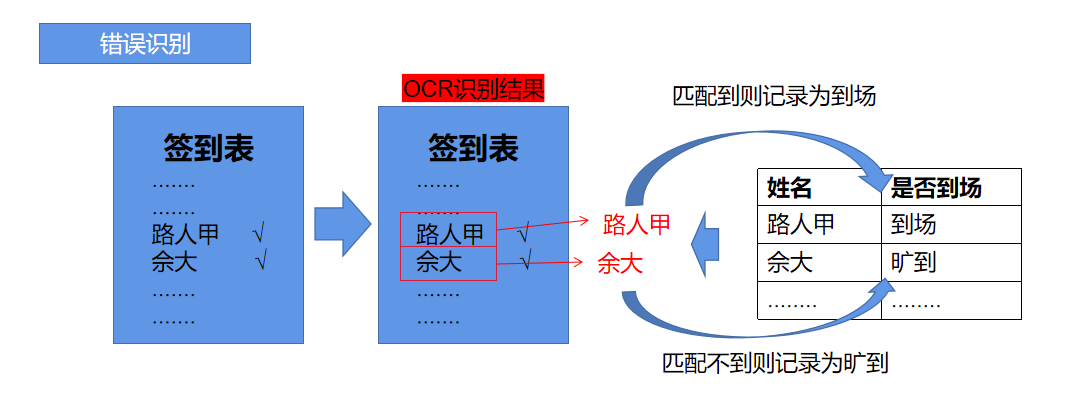
“佘(she)大”同学按时出席并签到后,机器识别很有可能会识别为“余(yu)大”,从而无法在花名册excel文件中找到“佘(she)大”同学,最终“佘(she)大”同学每次都有旷到记录。
为了解决这个问题,可以利用**“错误”打败错误**。首先,生成包含“佘(she)大”同学姓名的图片A,进行识别。而后,将图片A的识别结果和签到表截图的识别结果进行匹配。如果匹配成功,则意味着“佘(she)大”同学签到成功。
具体介绍
懒人打卡统计:用OCR+花名册一键统计打卡结果
如下所示,对于这样的app打卡内容,如果人工找到打卡人姓名(带✔的方框),再在excel中将对应日期的对应姓名的同学标注为打卡成功会花费大量时间,影响我们打游戏。

解决方案
为了能一键完成工作安排,继续快乐打游戏,不妨试试PaddleOCR吧:
- 使用OCR模型识别姓名的位置
- 按照姓名的位置锚定右上角的绿色对勾
- 将csv中带有绿色对勾的姓名的标注改为1
为了保护同学们的姓名隐私不在项目中提供截图对应的 打卡截图,花名册文件,仅提供一个随意生成的案例图片,花名册和代码
截图界面为微信小程序:接龙管家的打卡记录界面
由于手机型号/分辨率各有差别,使用本代码请务必对以下参数进行设定
img_dir='1.jpg' # 打卡截图
name_csv='name_csv.csv' # 花名册文件,表头为(name,1,2,3,4,5,6,7...),对应的内容分别为姓名,第一天的打卡结果,第二天的打卡结果...,其中姓名填入即可,其他方格可以留空
save_dir='output.csv' # 打卡后的结果保存路径
block_size=25 # 右上角的绿色对勾的区域大小
w_bias=35 # 绿色对勾相对于姓名位置的横向偏移量
h_bias=-50 # 绿色对勾相对于姓名位置的纵向偏移量
threshold=175 # 阈值,低于此阈值则为绿色,否则则偏向于灰色,可以根据像素点均值进行分类
clock_in_col=1 # 打卡条目,此处设为1对应第一天的打卡结果,结果会写入到第二行中
打卡前后截图示例
用错误打败错误
为了解决OCR识别模型将形近字误判从而导致无法正确生成签到电子记录的情况发生,可以通过以下步骤生成签到人的“伪姓名”从而使用“伪姓名”获得正确的匹配结果。
下表以“佘大”同学的签到检测作为示例:
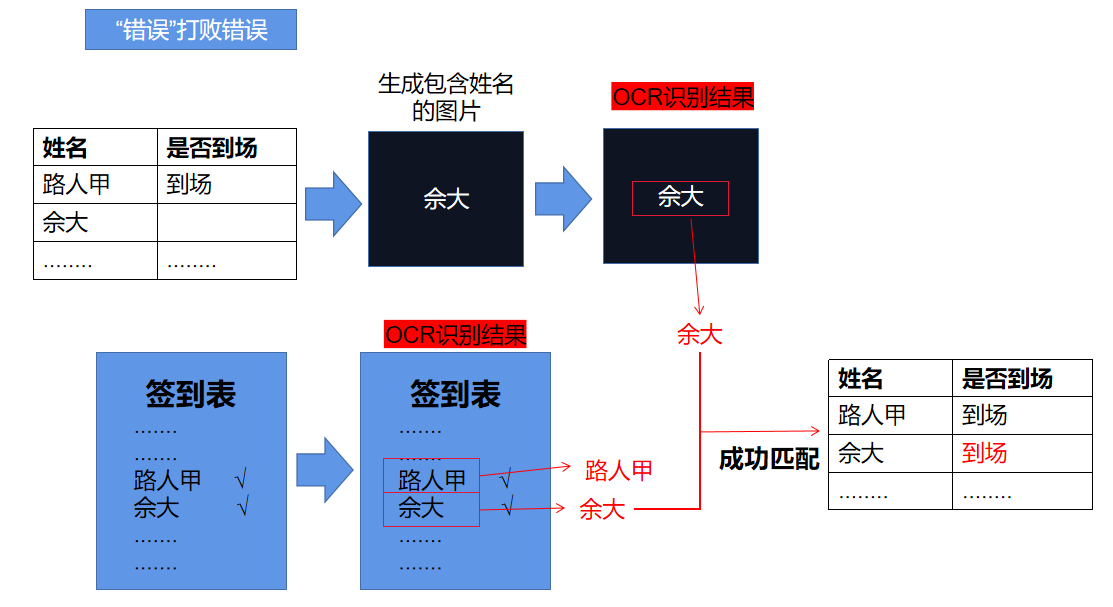
可以看到通过这种生成“伪姓名”方式,就可以顺利地将“佘大”同学和签到表截图中地姓名匹配上啦~
代码逻辑
- 获取签到结果截图的OCR识别结果
- 获取花名册excel中第i个同学的姓名
- 通过上述方法生成“伪姓名”
- 将“伪姓名”和OCR识别结果匹配,若有匹配项,且签到标记存在,则对应同学签到成功,若否则签到失败
- i=i+1, 跳到第2步执行
代码
!pip install --upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
!pip install --upgrade paddlehub -i https://mirror.baidu.com/pypi/simple
!pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
import cv2
import paddlehub as hub
import pandas as pd
import numpy as np
from PIL import ImageFont,ImageDraw,Image
# 定义参数
# define some parameters
img_dir='案例.jpg' # 打卡截图
name_csv='案例.csv' # 花名册文件,表头为(name,1,2,3,4,5,6,7...),对应的内容分别为姓名,第一天的打卡结果,第二天的打卡结果...,其中姓名填入即可,其他方格可以留空
save_dir='输出案例.csv' # 打卡后的结果保存路径
block_size=25 # 右上角的绿色对勾的区域大小
w_bias=35 # 绿色对勾相对于姓名位置的横向偏移量
h_bias=-50 # 绿色对勾相对于姓名位置的纵向偏移量
threshold=175 # 阈值,低于此阈值则为绿色,否则则偏向于灰色,可以根据像素点均值进行分类
clock_in_col=1 # 打卡条目,此处设为1对应第一天的打卡结果
# 导入文字识别模型
# ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
ocr = hub.Module(name="chinese_ocr_db_crnn_server")
# 读取测试文件夹test.txt中的照片路径
img=cv2.imread(img_dir)
np_images =[img]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=True, # 是否将识别结果保存为图片文件;
box_thresh=0.8, # 检测文本框置信度的阈值;
text_thresh=0.8) # 识别中文文本置信度的阈值;
# 匹配文字与识别结果
# the function make codes shorter
def is_name_in_ocr(name,ocr_result):
for item in ocr_result[0]['data']:
if item['text']==name:
return True, item['text_box_position']
return False,None
# 根据指定文字生成图片并用ocr模型识别
def generate_name_and_ocr(name,ocr):
w=200
h=100
img = np.full((h,w,3),fill_value=255,dtype=np.uint8)
fontpath = "simhei.ttf" #导入字体文件
b,g,r,a = 0,0,0,0 #设置字体的颜色
font = ImageFont.truetype(fontpath,30)#设置字体大小
img_pil = Image.fromarray(img)#将numpy array的图片格式转为PIL的图片格式
draw = ImageDraw.Draw(img_pil)#创建画板
draw.text((w/2-10,h/2-20),name,font=font,fill=(b,g,r,a))#在图片上绘制中文
img = np.array(img_pil)#将图片转为numpy array的数据格式
results = ocr.recognize_text(
images=[img], # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=True, # 是否将识别结果保存为图片文件;
box_thresh=0.8, # 检测文本框置信度的阈值;
text_thresh=0.8) # 识别中文文本置信度的阈值;
return results[0]['data'][0]['text']
# 检索识别框右上角的绿色方块,如果存在则打卡成功
df=pd.read_csv(name_csv,encoding='gbk')
for i in range(len(df)):
name=df.iloc[i,0]
name=generate_name_and_ocr(name,ocr) # 注释此行代码可以看到 案例 中的佘大同学签到失败了
flag, text_box=is_name_in_ocr(name,results)
if flag:
center_point=[(text_box[2][0]-text_box[0][0])/2+text_box[0][0],(text_box[2][1]-text_box[0][1])/2+text_box[0][1]]
center_point=[int(x) for x in center_point]
check_img=img[center_point[1]+h_bias:center_point[1]+h_bias+block_size,center_point[0]+w_bias:center_point[0]+w_bias+block_size,:]
# print(name,check_img.mean())
if check_img.mean()<threshold:
df.iloc[i,clock_in_col]=1
df.to_csv(save_dir,index=None)
参考链接
- 带文字图片生成:https://blog.csdn.net/sinat_29957455/article/details/105069917 CC 4.0 BY-SA
- simhei.ttf 从下述网址获得 http://www.font5.com.cn/font_download.php?id=151&part=1237887120
- 如何使用paddlehub导入OCR识别模型 https://aistudio.baidu.com/aistudio/projectdetail/507159


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









