






★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
【百度网盘AI大赛—表格检测】MASK R-CNN 方案
一、项目背景
1.1 比赛介绍
-
背景:生活中,扫描技术越来越常见,通过手机就能将图片转化为可编辑的文档等;但是现在的技术在处理带有表格类型的文字的时候往往没有那么灵敏,把完整表格拆分成难以使用的零散个体似乎很常见又令人苦恼。本次比赛旨在解决这个问题,通过万能的算法,准确地识别表格在图片中的位置并标注。
-
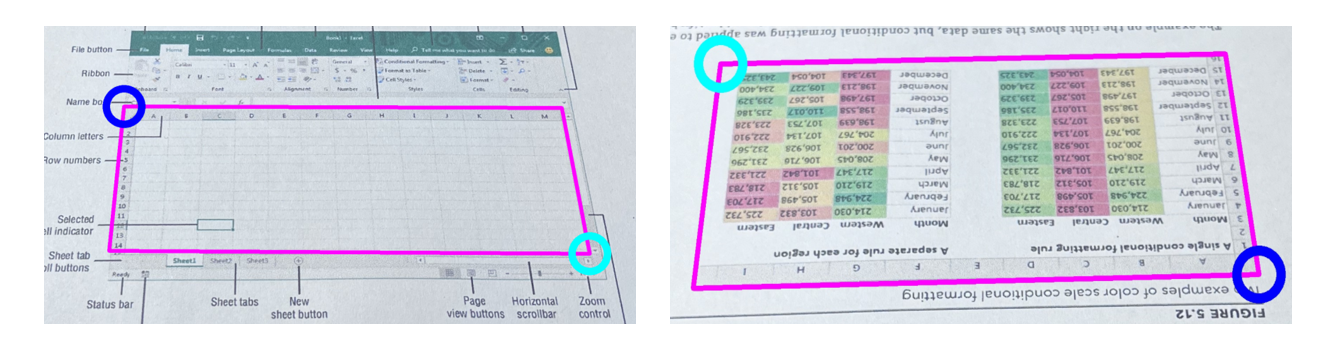
分析:赛题中的表格检测可以看成任意形状目标检测问题。目前,通用目标检测领域大多基于旋转框来处理这类问题。但是实际上,数据集中的表格存在严重的角度畸变,采用旋转矩形框可能无法对表格四个关键点进行有效回归。此外, 标注的左上角、左下角、右上角、右下角为语义关键点,而不是几何关键点,更为比赛增加了难度,这意味着网络不仅要识别出四个关键点的位置,还要判定表格的实际方向。下图为比赛标签可视化结果,深蓝色表示左上角关键点、浅蓝色表示右下角关键点,粉色边界框表示表格的具体形状。可以看出,真实标注中的左上角关键点会随着表格的旋转而旋转。同时,评估指标中,关键点的匹配较为严苛,在1K到2K测试图片上,20像素的容错率并不高,更何况测试集中还包括一些没有明确边界的图片。网络仅框出大致边界,但是不能与表格实际边界完美贴合或者表格方向分类错误都可能导致匹配失败。由于点匹配部分以关键点为单位,前者可能由于部分点与真实点距离小于20像素而获得一定分数,后者无法获得任何分数。
-
网络设计:基于上述分析,该方案采用 MASK R-CNN 进行实例分割,并通过 PP-LCNet 进行表格方向识别。MASK R-CNN 实例分割有效解决了表格形状不规则的问题,PP-LCNet 网络小、推理速度快,使得表格方向识别的计算成本较低。
-
模型选择原因:一方面,由于测试图像的尺寸大多在 1K 以上,只有采用较大的输入尺寸才能取得理想的实例分割效果。PaddleDetection 中的其他两种实例分割模型——Cascade Mask R-CNN 和 SOLOv2 在较大输入尺寸的情况下会导致测评环境显存崩溃,因此,该方案选择较为轻量的 Mask R-CNN 作为实例分割模型。另一方面,作为【百度网盘AI大赛——图像处理挑战赛:文档图像方向识别】的baseline模型, PP-LCNet 在文档方向识别任务上的速度和精度相较于其他网络具有较大优势。该模型大小仅为 7M, 即使采用 800 ∗ * ∗ 800 的图片作为输入,推理速度也可以保证在 20ms 以内,在文档识别A榜的准确率可达 85% 左右(榜一为 87%)。考虑到表格方向识别任务与文档方向识别任务类似,且该方案采用单个表格实例作为输入,而不是整张表格图像,我们选择 PP-LCNet 作为表格方向识别模型。
-
比赛链接:https://aistudio.baidu.com/aistudio/competition/detail/702/0/introduction
1.2 方案成绩
当前公开版本在 A 榜分数为 0.26324, 精度为 0.26324, 召回率为 0.2718, 单张图片测试耗时为 0.52231 s,截止 2月2号,排名为11名。

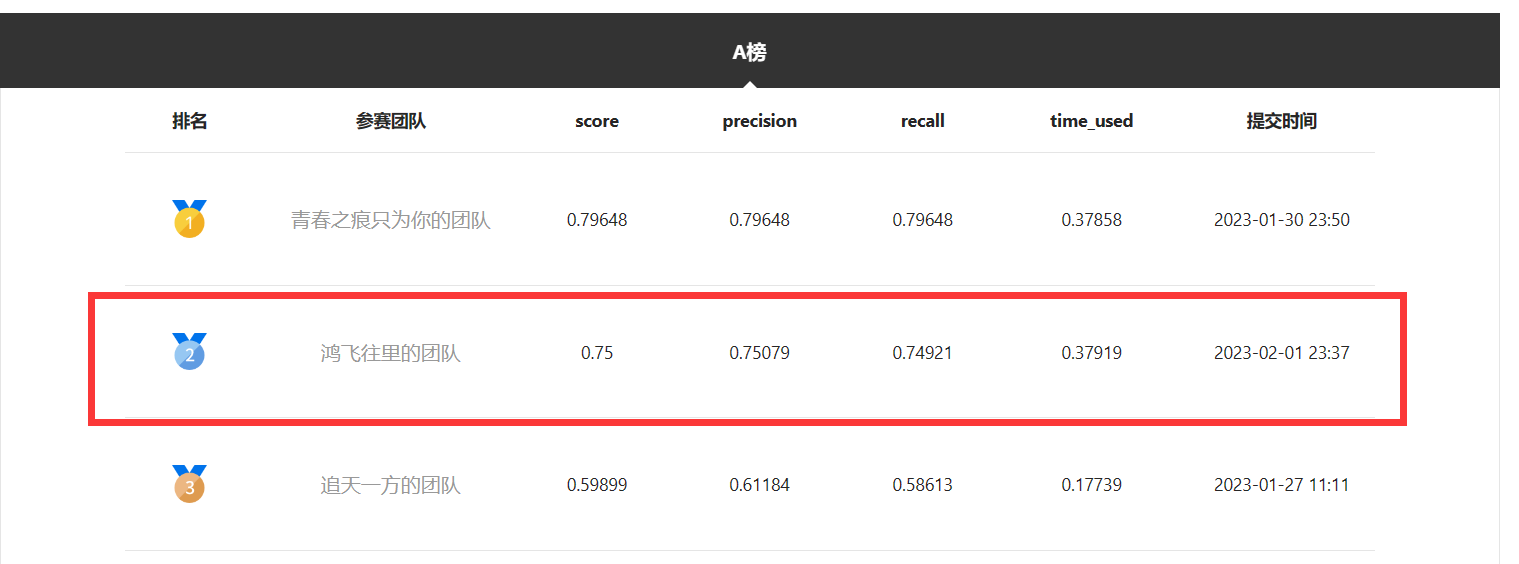
当前项目的后续优化版本在 A 榜分数为 0.75,精度为 0.75079, 召回率为 0.74921, 单张图片测试耗时为 0.37919 s,截止 2月2号, 排名为第2名。因此,基于实例分割+表格方向识别的方案具有极大的优化空间。
二、项目方案
该项目采样实例分割网络 MASK R-CNN 和表格方向识别网络 PP-LCNet 相结合的方案进行表格检测,具体架构如下图所示:
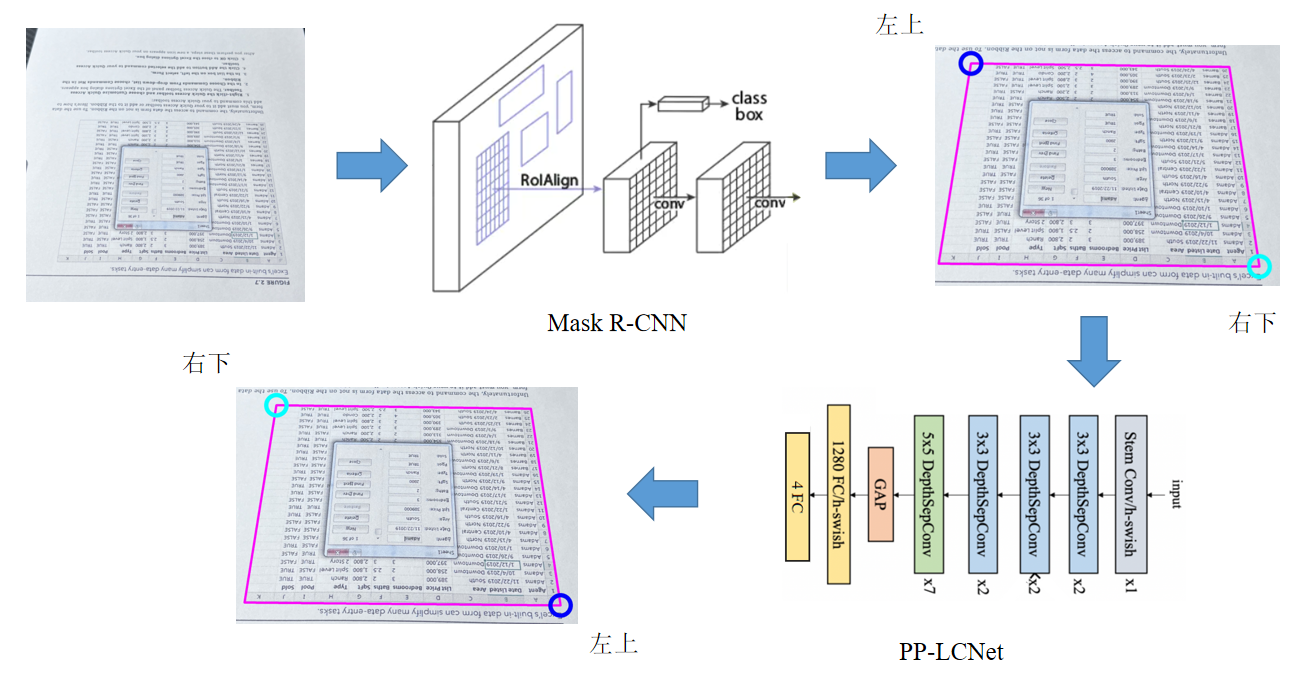
表格图片首先通过 MASK R-CNN 获得一系列表格实例对象,并通过opencv相关函数提取表格轮廓点,之后,我们根据边界框左上角坐标 (xmin, ymin) 和右下角坐标 (xmax, ymax) 对表格图片进行裁剪。最后,裁剪后的表格图片送入到 PP-LCNet进行方向识别,并根据分类结果将几何轮廓点调整到语义轮廓点。分类标签根据几何轮廓点与语义轮廓点位置的相对关系进行定义,详见第三部分——数据说明。这里,MASK R-CNN 通过 PaddleDetection 实现。PP-LCNet 的训练代码改写自 PaddleClas 源码,模型大小仅 6.5MB 左右。
三、数据说明
该项目的数据包含两个部分——用于实例分割的百度网盘表格检测官方数据集和表格方向识别数据集,其中,表格方向识别数据集对官方数据集图片中的表格实例进行裁剪,并根据几何轮廓点和语义轮廓点位置的相对关系定义四分类标签。
3.1 表格检测数据集介绍
数据集构成
训练数据集构成
train_data
├── annos.txt
├── imgs
- 本次比赛最新发布的数据集共包含训练集、A榜测试集、B榜测试集三个部分,其中训练集共10000张图片,A榜测试集共500张图片,B榜测试集500张图片;
- imgs目录下为所有训练图片;
- annos.txt 为标注文件,json格式,格式示例如下:
{
"a.jpg": [ # 图片文件名称,不含路径
{
'box': [xmin, ymin, xmax,ymax], # 表格box位置,(xmin, ymin)为box左上点,(xmax, ymax)为box右下点
'lb': [x, y], # 表格left bottom点,即左下顶点
'lt': [x, y], # 表格left top点,即左上顶点
'rt': [x, y], # 表格right top点,即右上顶点
'rb': [x, y] # 表格right bottom点,即右下顶点
},
{
'box': [xmin, ymin, xmax, ymax],
'lb': [x, y],
'lt': [x, y],
'rt': [x, y],
'rb': [x, y]
}
],
"b.jpg": [{
'box': [xmin, ymin, xmax, ymax],
'lb': [x, y],
'lt': [x, y],
'rt': [x, y],
'rb': [x, y]
}, {
'box': [xmin, ymin, xmax, ymax],
'lb': [x, y],
'lt': [x, y],
'rt': [x, y],
'rb': [x, y]
}]
}
数据集下载
| 数据集类型 | 是否开放 | 百度网盘链接 | AI Studio链接 |
|---|---|---|---|
| 训练集 | 已开放 | 百度网盘下载 | AI studio引用 |
| A榜测试集 | 已开放 | 链接失效 | AI studio引用 |
| B榜测试集 | 未开放 |
数据增广
- 为了提高网络鲁棒性,在数据集读取过程中,对表格图像进行了色彩增强、随机缩放、随机翻转和归一化操作。
数据划分
- 该项目采用全部训练集,不进行数据集划分。
3.2 表格方向识别数据集介绍
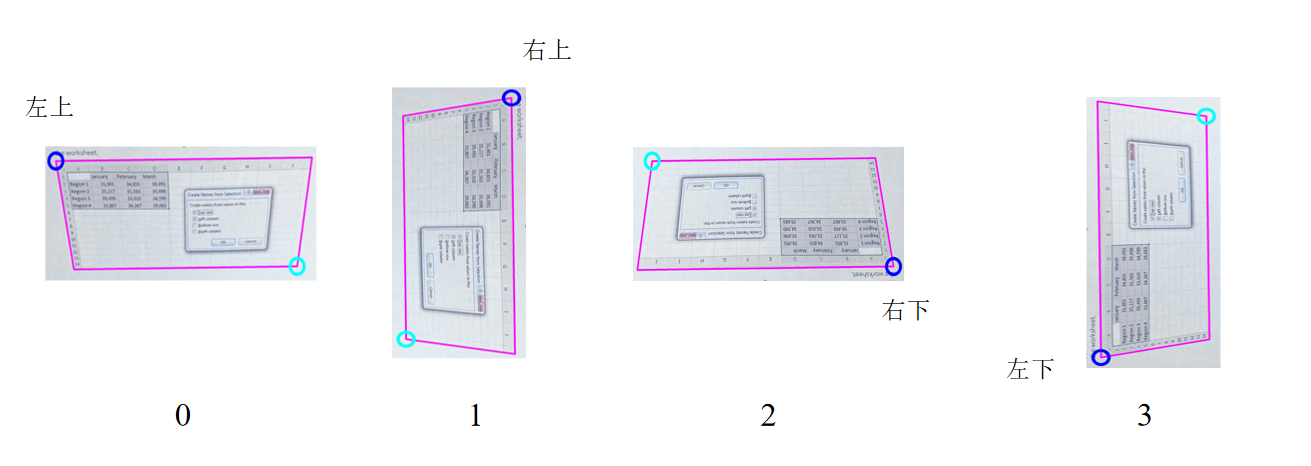
- 该数据集通过几何轮廓点和语义轮廓点位置的相对关系对表格方向的类别进行定义。第一步,根据语义轮廓点计算几何轮廓点,具体计算过程如下:首先,根据 x 轴坐标大小排序,选择x轴坐标较小的两个关键点作为左侧坐标,剩余两个点作为右侧坐标。之后,分别比较左侧坐标和右侧坐标的y轴坐标大小,左侧坐标中y轴坐标较小的为左上角,较大的为左下角;右侧坐标中y轴坐标较小的为右上角,y轴坐标较大的为右下角。第二步,根据几何左上角与语义左上角的相对位置定义方向类别标签,如下图所示,语义左上角位于几何左上角,定义为0;语义左上角位于几何右上角定义为1;语义左上角位于几何右下角定义了2;语义左上角位于几何左下角定义为3。
数据集构成
- 表格方向识别数据集包含10240张图片。其中,训练集共9216张图片,测试集共1024张图片。
数据增广
- 由于原始裁剪图片方向大部分是语义左上角位于几何左上角,数据集的其他方向类别较少,我们对表格进行了随机旋转操作。这里随机旋转仅包含0度,90度、180度、270度四个角度。此外,为了提高模型鲁棒性,我们还进行了色彩增强、填充缩放和归一化等数据增强操作,
数据划分
- 训练集和测试集按 9:1 进行划分。
四、代码实现
-
训练细节: 我们在表格检测数据集和表格方向分类数据集上分别训练了 MASK R-CNN 网络和 PP-LCNet 网络。其中, MASK R-CNN 网络采用 ResNet+FPN 结构训练了 30 个 epoch, batch-size 为 10;PP-LCNet 训练了70 个 epoch, batch-size 为96。训练环境为 V100 32G, 如需在 V100 16G 环境下训练,请降低 batch 数量。
-
与baseline差异: 与已有baseline不同,我们采用实例分割与表格方向识别相分离的方式进行表格检测,而不是直接回归表格语义点或使用旋转框。一方面,采用实例分割方法对表格形状具有较强的适应性,可以有效进行表格四个关键点的计算。另一方面,与街道文字场景不同,表格中的文本多、字符小,单独训练分类网络可以更好地对表格方向进行识别。
-
模型保存: MASK R-CNN 网络每5个epoch保存一次模型,使用全部训练数据,不进行测试。PP-LCNet每1个epoch保存一次模型,并进行测试。项目提供了一个提交代码样例,该样例位于/home/aistudio/predict_dir/submit_1_20.zip,直接提交可获得的 0.23 左右的分数。该项目旨在对赛题进行分析,并提供解决思路,故所给模型并非最优模型。
4.1 MASK R-CNN 实例分割部分训练
# 解压数据集
%cd /home/aistudio/
!unzip /home/aistudio/data/data180786/train.zip
!unzip /home/aistudio/data/data180786/testA.zip
# 解压PaddleDetection
%cd /home/aistudio/
!unzip /home/aistudio/data/data180786/PaddleDetection-release-2.5.zip
# 安装PaddleDetection依赖包
%cd /home/aistudio/PaddleDetection-release-2.5
!pip install --user -r requirements.txt -i https://mirror.baidu.com/pypi/simple
# 将annos.txt转化为coco instance格式, 生成的json文件位于/home/aistudio/work/train_all.json, 转换文件在命令完成后才会出现
%cd /home/aistudio/work/
!python txt2coco.py
# 对PaddleDetection中配置文件进行修改
!rm /home/aistudio/PaddleDetection-release-2.5/configs/datasets/coco_instance.yml
!rm /home/aistudio/PaddleDetection-release-2.5/configs/mask_rcnn/mask_rcnn_r50_vd_fpn_ssld_1x_coco.yml
!rm /home/aistudio/PaddleDetection-release-2.5/configs/mask_rcnn/_base_/mask_fpn_reader.yml
%cd /home/aistudio/work/modify_code
!cp coco_instance.yml /home/aistudio/PaddleDetection-release-2.5/configs/datasets/coco_instance.yml
!cp mask_rcnn_r50_vd_fpn_ssld_1x_coco.yml /home/aistudio/PaddleDetection-release-2.5/configs/mask_rcnn/mask_rcnn_r50_vd_fpn_ssld_1x_coco.yml
!cp mask_fpn_reader.yml /home/aistudio/PaddleDetection-release-2.5/configs/mask_rcnn/_base_/mask_fpn_reader.yml
# Mask R-CNN 训练
%cd /home/aistudio/PaddleDetection-release-2.5
! python tools/train.py -c configs/mask_rcnn/mask_rcnn_r50_vd_fpn_ssld_1x_coco.yml
# Mask R-CNN 模型导出 可通过修改weight参数设置导出模型的路径
%cd /home/aistudio/PaddleDetection-release-2.5
!python tools/export_model.py -c configs/mask_rcnn/mask_rcnn_r50_vd_fpn_ssld_1x_coco.yml -o weights=/home/aistudio/data/data187483/17.pdparams
# 将表格实例分割模型拷贝到预测目录,以便之后可视化和打包提交
%cd /home/aistudio/
!cp -r /home/aistudio/PaddleDetection-release-2.5/output_inference/mask_rcnn_r50_vd_fpn_ssld_1x_coco predict_dir
%cd /home/aistudio/predict_dir
!mkdir output
4.2 PP-LCNet 表格方向识别部分训练
# 通过脚本生成表格方向识别数据集,由于需要用到官方数据集中的annos.txt文件,请确保官方数据集已经解压
%cd /home/aistudio/CLS/
!mkdir image
# 生成的裁剪图片位于/home/aistudio/CLS/image,标签位于/home/aistudio/CLS/,label.txt为生成的标签文件
!python json2label.py
# 将标签划分为训练集和测试集,两者比例为9:1
%cd /home/aistudio/CLS/
!python labelsplit.py
# 进行 PP-LCNet 表格方向识别模型训练,取测试集分数最高的模型进行保存,保存模型位于/home/aistudio/CLS/code/angleClass_base
# 可更改/home/aistudio/CLS/code/configs/config_base.py配置文件,对训练参数进行设置
%cd /home/aistudio/CLS/code
!python train_base.py
# 将表格方向识别模型拷贝到预测目录,以便之后可视化和打包提交
%cd /home/aistudio/CLS/code/
!cp angleClass_base /home/aistudio/predict_dir/angleClass_base
五、效果展示与提交
# 预测结果可视化,可视化结果位于/home/aistudio/predict_dir/output
%cd /home/aistudio/predict_dir/
!python vis_maskrcnn.py /home/aistudio/pubtest/imgs /home/aistudio/predict_dir/output
/home/aistudio/predict_dir
W0202 17:55:34.023200 23827 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0202 17:55:34.026822 23827 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
# 提交代码测试, 若执行成功,则生成/home/aistudio/predict_dir/output/result.txt文件
%cd /home/aistudio/predict_dir/
!python predict.py /home/aistudio/pubtest/imgs /home/aistudio/predict_dir/output
/home/aistudio/predict_dir
W0202 17:56:05.032280 24009 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0202 17:56:05.035823 24009 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
8.2.
# 打包提交,将压缩包直接下载到本地提交即可
%cd /home/aistudio/predict_dir/
!zip -r submit_2_2_1.zip ./mask_rcnn_r50_vd_fpn_ssld_1x_coco predict.py cls_model.py angleClass_45
六、后续优化点
-
目前不规则目标检测在 OCR 领域主要有两种方案——轮廓点检测和实例分割,MASK R-CNN 本质上是一种实例分割方法,但由于并不是为文本类目标检测任务专门设计的网络,因此并不是最优方案,感兴趣的选手可以尝试 PaddleOCR 中其他算法。
-
由于A榜测试集只有十几张图片,实际提交分数较低可能是网络过拟合造成的,可以考虑采用其他公共的表格检测数据集进行数据增广。
-
MASK R-CNN 中的交叉熵损失不利于表格这种形状规则、类别单一对象的分割,可采用 Dice Loss 提升分割性能。
-
对于 IMG 和 paper 类图片,由于表格实例的背景较为复杂,分割出来的表格可能是任意多边形,可以考虑采用损失函数对表格形状进行约束或通过后处理手段,找到多边形顶点中的左上、左下、右上、右下四个角点。
七、参考项目
[1] 百度网盘AI大赛——表格检测进阶:表格的结构化 Baseline
https://aistudio.baidu.com/aistudio/projectdetail/5234267?channelType=0&channel=0
[2] 百度网盘AI大赛——图像处理挑战赛:文档图像方向识别Baseline















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









