






首先安装Ubuntu20.04.6
安装教程:【精选】Ubuntu20.04安装详细图文教程(双系统)_ubuntu20.04安装教程_Hacah的博客-CSDN博客
将磁盘分出一部分出来安装Ubuntu,在磁盘管理中点击压缩卷即可分出一部分磁盘,之后制作Ubuntu系统安装盘,进行安装。
开机时狂按F12(红米Gpro)进入启动选择,选择u盘启动即可
在磁盘划分的时候,要分成/,/boot,swap交换空间,/home四个部分,我总共为Ubuntu准备了260g空间,/空间给了70g,/boot给了4g(网上说2g就行),swap给了16g(网上说跟内存一样就行),剩下的就一股脑分给了/home。之后等待安装就行。
如果有独立显卡的建议关闭独显,使用集显进入Ubuntu,之后在Ubuntu中安装显卡驱动就行,否则有可能出现黑屏情况
对Ubuntu初步的配置
首先是显卡驱动问题,命令行输入nvidia-smi会显示显卡型号等一系列信息,如果没有就需要去安装显卡驱动,只有安装了显卡驱动,我们才能在Ubuntu种调用显卡。
终端输入ubuntu-drivers devices,查看显卡版本,推荐的版本旁会写着recommend,记下来,终端输入sudo apt install nvidia-driver-XXX(xxx改成显卡推荐的版本)即可。
其次是亮度问题,进入Ubuntu时很有可能无法调节亮度,我之前也试过很多方法,比如修改英伟达驱动文件、命令行查询显示器控制亮度,都不太稳定,最后我采用的是程序控制,参考这篇文章ubuntu20.04屏幕亮度无法调节(亮度条调节无效)的简单靠谱解决方案及踩坑历程_ubuntu亮度调节无效-CSDN博客第三种方法,通过命令行输入
sudo add-apt-repository ppa:apandada1/brightness-controller
sudo apt-get update
sudo apt-get install brightness-controller-simple
安装程序即可调节亮度。
还有,Ubuntu记得要更换下载源,我比较推荐清华源,具体方法可以上网查询。
Anaconda的安装
由于Ubuntu系统不太稳定,我们在使用中又要配置各种环境,所以我们使用虚拟环境,当环境出现错误时删除虚拟环境即可,不用每次都重装系统。
首先是下载anaconda安装包,我这里是在清华镜像源下载到本地的,地址如下
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
之后打开下载目录,在其中打开终端,输入
bash Anaconda3-5.3.1-Linux-x86_64.sh进行安装(注意修改后缀,使其与自己安装包版本一致)
一路enter,注意最后有yes需要输入,一不小心容易错过。之后按照文章进行操作即可
输入conda –version可以看到版本号即完成安装
之后创建自己的虚拟环境,记住名字。记得虚拟环境python版本一定要大于或等于3.8,否则后面yolov5无法安装
Pytorch安装
Ubuntu20.04配置深度学习环境yolov5最简流程_ubuntu yolov5_耳语ai的博客-CSDN博客
Ubuntu20.04|22.04下,从零开始配置yolov5环境,适合小白,每一步带图 - 知乎 (zhihu.com)
激活虚拟环境,之后进入官网找到自己需要下载的版本,复制进入命令行下载即可
CUDA安装
Ubuntu 20.04安装CUDA & CUDNN 手把手带你撸_ubuntu cuda_哈希Map的博客-CSDN博客
进入虚拟环境,终端输入nvidia-smi查询CUDA版本,一般在右上角,记下来,接着去英伟达官网https://developer.nvidia.com/cuda-toolkit-archive找比自己版本号低一个的版本下载我的cuda是12.3,我下载的就是12.2.2,一定要找比自己低的版本。点进去参考文章选择版本,之后会给你一串命令,复制粘贴命令行运行即可。如果最后查询版本号的时候找不到,千万不要按照系统提示的代码去安装,这时候是已经安装完成了的,只需要修改环境配置即可查询到。
Labelimg标注工具安装
Ubuntu 18.04 Linux安装labelImg的教程_ubuntu18.04 labelimg-CSDN博客
进行训练需要先对数据进行标记,我目前用的是这个标注软件
首先进入虚拟环境(不进入虚拟环境也行,我主要是怕系统崩掉),按照文章进行安装,中间qt5那个包会下载很长时间,我尝试换源还有代理都没能解决,之能慢慢等,中间还有一系列的问题,比如有的东西没有安装,有的东西报错,可以去CSDN查找解决方案
Labelimg的使用
【教程】标注工具Labelimg的安装与使用 - 知乎 (zhihu.com)

首先要新建一个总的存放文件夹Model1,里面新建两个文件夹,一个images存放照片,一个labels存放标注数据,之后在images下建立两个文件夹,train和val。同样的,在labels下建立两个相同的文件夹。结构如下图
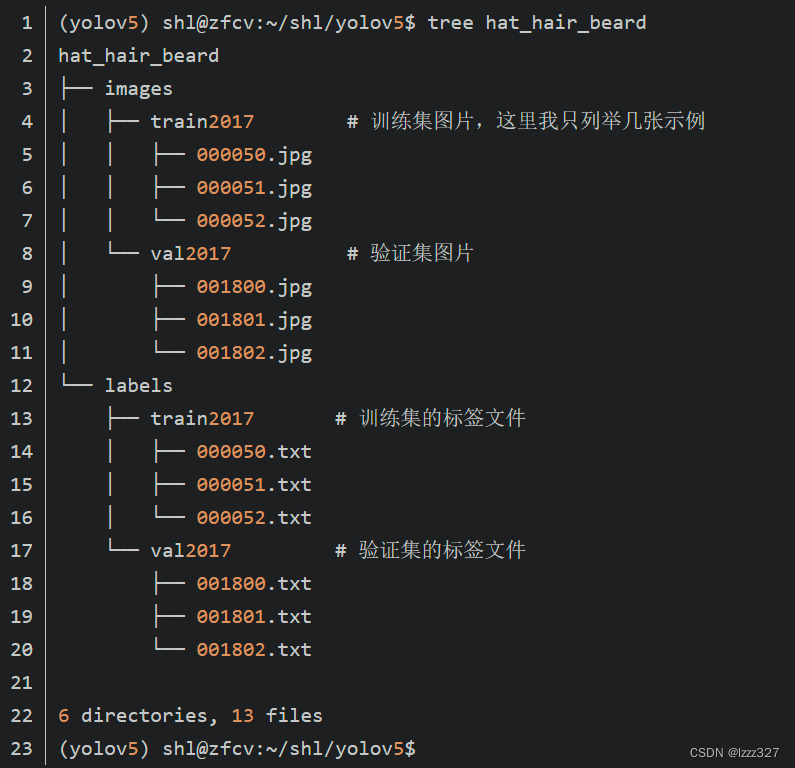
我来说明一下这里的对应关系,images是存放图片的,其下的文件夹中train是存放训练用的图片,val是存放验证用的图片的。Labels是存放标注数据的,其下的两个文件夹作用也和image中的一样,对应关系是train中的图标注后数据存入labels中的train标注时注意文件夹的选择。
首先将想要标注的照片放入Photo中,之后打开Labelimg软件,参照上图,打开存放照片的文件夹images,之后再选择存放标注文件的路径,改为labels,标注文件类型改为YOLO
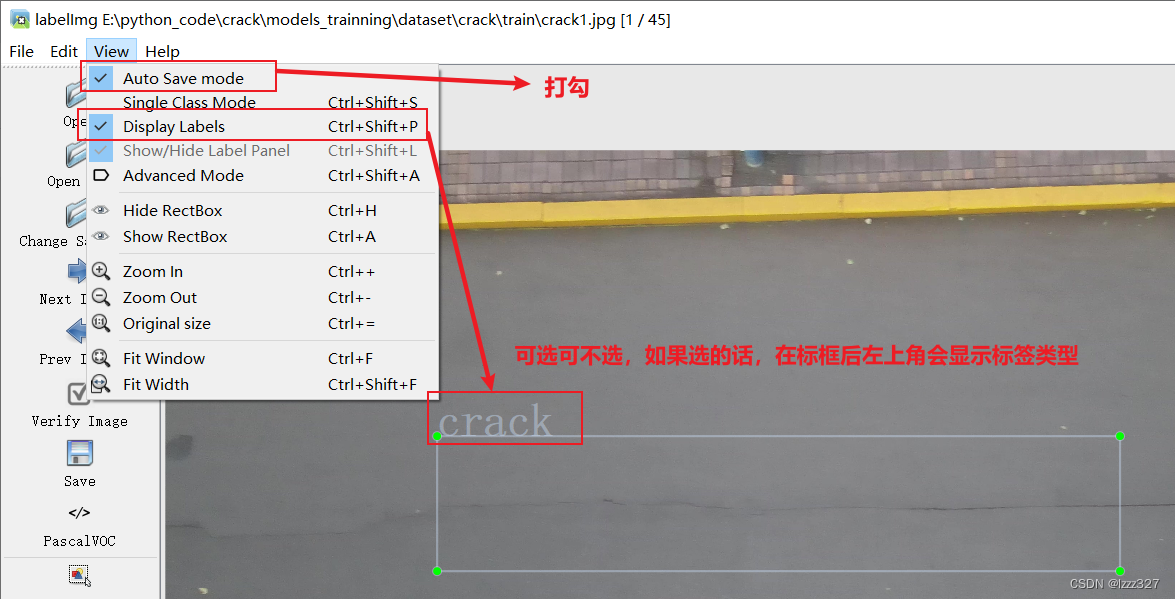
之后打开view标签,将上图勾选。
之后可以进行标注,注意,如果在一个标注集中想要识别两个以上的图像,即有多个类别存在时,要注意标签设置以及标注顺序。因为在我们标注后,在Data文件中会生成一个总的文件Classes,会记录我们对于图像的称呼,比如我想要两类图片(左转和右转),在classes中,会吧左转标为1,右转标为2,之后的标注数据中就只会用1和2来代表,所以在标注时的标签建立要格外注意,要不然会导致标注错误。
YOLOV5的安装
首先找到一个镜像源下载YOLOV5,之后将其解压到主目录存放
终端输入cd yolov5-master,进入文件夹
之后输入pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
如果pip3没下载的可以先下载在安装
安装完后输入python3 detect.py --source 0 摄像头正常识别即安装成功
建议下载一个VScode进行代码的调试,会更加的方便
YOLOV5的基本使用
YOLOv5的详细使用教程,以及使用yolov5训练自己的数据集_yolo5训练集_普通网友的博客-CSDN博客
安装好YOLOV5后,由于使用命令行训练及调用很麻烦,建议安装VScode,方便我们使用YOLOV5,接下来我将基于VScode下讲解YOLOV5的使用。
首先将标注好的总文件夹Model1放入yolov5-master文件夹下,要和detect.py以及train.py文件平级,这里的话
之后是选择我们需要的训练模型,从./models目录下选择一个模型的配置文件,这里我们选择yolov5s.ymal,这是一个最小最快的模型,不同配置文件的参数不同,训练出来的模型识别精度以及算力需求也不同,可以根据自己的的需求选择。
接下来是修改数据配置文件,作用是让模型知道本次训练的图片位置以及训练类别,此处我们选择是直接复制默认的yaml文件,重命名并且修改其中的内容放在同一个文件夹下,这样省时省力,打开./yolov5/data/coco128.yaml,首先是train以及val,建议这里使用绝对路径,不容易出错还省脑子,下面是修改前与修改后的,修改前的是相对路径,修改后的是绝对路径,其中hat_hair_beard是标注总文件的名称,我们这里应该是Model1


之后修改类别,就是names那一串,这里要参照labels中的classes文件里的类别顺序进行输入修改,一定一定要按照顺序来
接下来修改模型配置文件,同样复制yolov5/models/yolov5s.yaml模型的配置文件,重命名为(模型总名称_yolov5s.yaml)修改即可,这里只需要修改一处,就是文件第三行的nc:80,将后面80改成我们模型中的类别数即可。
接下来介绍一点参数,不是太重要,想要个性化训练模型的话可以参考


这些数值都是有默认值的,不修改的话也是可以按照默认值训练的。
首先我们进行预训练,可以得到一个最初的训练模型,命令的格式是
python train.py --img 640 --batch 16 --epochs 300 --data ./data/hat_hair_beard.yaml --cfg ./models/hat_hair_beard_yolov5s.yaml --weights ./weights/yolov5s.pt --device 1
其中,我们首先要调用train.py训练文件,如果我们使用VScode,只需要在train.py文件中修改保存并运行即可,训练轮数就是epoch建议100~200轮即可,cfg和data是必须要修改的,改为上面我们保存的两个yaml文件,weight为预训练模型的保存地址
接下来就是修改detect文件中的weight文件目录,改成我们模型的存放目录,再将source更改为0(设备列表中第一个设备,大部分情况下是电脑摄像头),即可使用电脑摄像头进行实时识别。可以根据识别效果对数据标注集中的图片进行删除或者补充。个人建议是首先调用自己的模型对标注集进行一边识别,就是训练集中的图片进行识别,按道理来说识别成功率应该是百分之百,如果出现百分之99及以下的,应该删除改图片并及时进行补拍,记得对应的标注数据也要删除。
另外,在数据集拍摄过程中,将需要拍摄的对象在镜头中进行拉伸缩放,以便模型在不同位置都能识别到
一类数据集的图片数量应该在1000张以上,才能有更好的训练结果。
图片的背景色建议无色,或者是尽量少点颜色,至少不可以干扰到识别的图像,否则会干扰模型的图像识别。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









