






一、C语言标准与编译器
C 编译器是软件开发中至关重要的工具,它的主要作用是将人类可读的 C 语言源代码转换为计算机能够理解和执行的可执行代码。
(一)C语言标准的制定
C语言标准的制定是一个逐步发展和完善的过程。在早期,C语言缺乏统一的标准,这导致了代码在不同平台和编译器上的可移植性问题。为了解决这一问题,ANSI(美国国家标准协会)和ISO(国际标准化组织)发挥了关键作用。
ANSI成立了专门的委员会,致力于制定C语言的标准规范。他们广泛征求了业界的意见和建议,对C语言的语法、语义、库函数等方面进行了明确和定义。ISO随后采纳了ANSI制定的标准,使其成为国际通用的C语言标准。
(二)POSIX C和ANSI C
POSIX C和ANSI C是两种不同的C语言标准。
ANSI C,也称为C89或C90,是由美国国家标准协会(ANSI)发布的C语言标准。它是第一个被广泛接受的C语言标准,包括一些基本的语法和语义规则,以及标准库函数的定义。ANSI C主要关注于程序的可移植性和可读性。
POSIX(Portable Operating System Interface)是为了保证计算机程序的可移植性而制定的一系列操作系统接口标准。POSIX C是ANSI C的一个子集,它添加了一些与操作系统交互相关的功能和库函数,以便程序可以在符合POSIX标准的操作系统上运行。
POSIX C在ANSI C的基础上扩展了一些功能,包括文件系统操作、进程管理、线程支持等。POSIX C可以在各种不同的操作系统上编译和运行,如Linux、Unix和macOS等。
(三)标准的内容与变化
C语言标准涵盖了众多关键内容。关键字方面,从早期的基本控制结构关键字(如if、for、while等),到后续增加的如const、volatile等。
数据类型上,不断丰富和完善,如C99引入了bool类型。
运算规则方面,包括算术运算、逻辑运算、位运算等的规则也在不断优化和明确。
不同标准版本有着显著的变化。C89奠定了基础,规范了基本的语法和特性。C99增加了可变长度数组、内联函数等新特性。C11则进一步引入了多线程支持、原子操作等功能。
(四)编译器对标准的支持
不同的编译器对C语言标准的支持情况存在差异。一些主流编译器如GCC对C语言的新标准支持较好,能够及时跟进并实现新特性。而某些商业编译器可能对最新标准的支持相对滞后。
对于标准扩展的实现,不同编译器也有各自的方式。例如,GNU C在标准C语言的基础上进行了部分扩展,如零长度数组、变量长度数组等。而其他编译器可能有不同的扩展重点和实现方式。
二、常用C编译器
(一)GCC
GCC(GNU Compiler Collection)是一款强大的编译器集合,具有众多显著的特点和优势。
特点方面,它支持多种编程语言,包括C、C++、Fortran、Java等,具有出色的语言兼容性。提供了丰富的编译选项,允许开发者根据具体需求进行精细的控制和优化。
优势上,其优化能力出色,能生成高效的目标代码。跨平台特性使得它可以在Linux、Windows、macOS等多种操作系统中运行。
在不同操作系统中的应用广泛。在Linux系统中,GCC是默认的编译器,为开源项目和系统开发提供了坚实的支持。在Windows系统中,通过MinGW等环境也能使用GCC进行编译工作。
(二)Clang
Clang 是 LLVM (The LLVM Compiler Infrastructure Project)项目中的一个重要子项目。它是一款强大的编译器前端,致力于为开发者提供高效、便捷的编译体验。
Clang 所属的 LLVM 项目是一个具有创新性的编译器架构系统,以其灵活、可扩展和优化性能而备受关注。LLVM 为编译器的设计和实现提供了全新的思路和方法。
Clang 支持多种编程语言,其中包括 C、C++、Objective-C 等。对于 C 语言,Clang 能够提供准确、高效的编译服务,遵循 C 语言的标准规范,确保代码的正确性和可移植性。在 C++方面,它不断改进对新特性的支持,以满足现代编程的需求。而对于 Objective-C,Clang 为苹果生态系统中的开发者提供了有力的编译支持,使得开发工作更加顺畅。
与其他编译器相比,Clang 具有诸多优势。例如,其编译速度快,能够显著缩短开发周期;错误提示信息清晰易懂,方便开发者快速定位和解决问题;采用模块化设计,易于与各种集成开发环境(IDE)进行集成和交互,提高开发效率。
编译速度快
在特定场景下,Clang 相较于其他编译器如 GCC 展现出了明显的速度优势。例如,在处理大型项目的增量编译时,Clang 能够更快地完成编译过程,节省开发者的时间。
Clang 实现快速编译的技术原理主要包括以下几点:首先,它采用了先进的词法分析和语法分析算法,能够快速准确地解析代码。其次,优化了代码生成策略,减少了不必要的中间步骤和重复计算。此外,Clang 还对编译过程中的并行化处理进行了优化,充分利用多核处理器的性能,提高编译效率。
内存占用小
Clang 占用内存小的优势使得在资源有限的环境中,如嵌入式系统或移动设备上,能够更高效地运行。实际表现为在编译相同规模的代码时,Clang 所需的内存资源明显少于其他编译器,从而减少了系统的负担。
实现高效内存管理的关键在于 Clang 对代码结构和数据结构的优化。它采用了更紧凑的内部数据表示方式,减少了内存的浪费。同时,在编译过程中,对临时数据和中间结果的存储和释放进行了精细的控制,避免了内存泄漏和不必要的内存占用。
模块化设计
模块化设计为 Clang 带来了诸多好处。其一,它使得各个模块可以独立开发、测试和优化,提高了开发效率和代码质量。其二,方便了与 IDE 的集成,例如,IDE 可以根据需要灵活调用 Clang 的特定模块,实现代码自动补全、语法检查等功能。
举例来说,在一些流行的 IDE 如 Xcode 中,Clang 的模块化设计使得其能够与 Xcode 紧密结合,为开发者提供实时的错误提示和代码建议。同时,在其他项目中,Clang 的模块也可以被重用,用于构建自定义的编译工具或代码分析工具。
诊断信息可读性强
以下是一个清晰可读的诊断信息示例:当代码中存在语法错误时,Clang 会明确指出错误所在的行号和具体位置,并给出详细的错误描述,如“语法错误:缺失分号”。
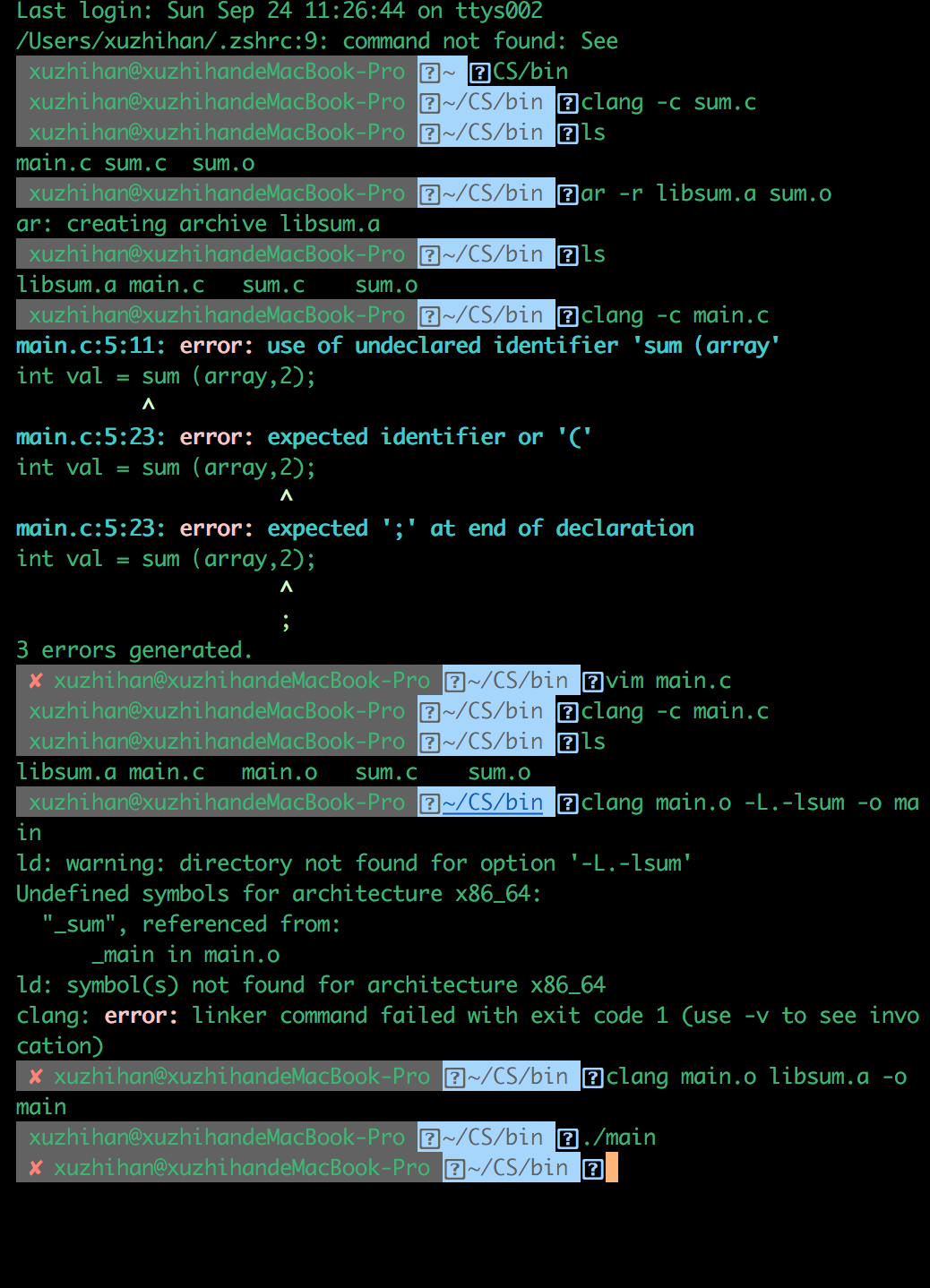
这种清晰可读的诊断信息对于调试和错误排查至关重要。它帮助开发者迅速定位问题,减少了查找错误的时间和精力。开发者能够根据准确的提示快速理解错误的本质,从而更高效地进行修复和优化代码。
(三)Microsoft Visual C++
Microsoft Visual C++编译器在Windows平台上具有独特的特点和广泛的适用场景。
特点包括与Windows操作系统紧密集成,能充分利用Windows的特性和API。提供了强大的调试工具和可视化界面,方便开发者进行代码调试和错误排查。
适用场景丰富,适用于开发Windows桌面应用程序、游戏、驱动程序等。在企业级应用开发中也表现出色,能满足高性能和复杂业务逻辑的需求。对于需要利用Windows特定功能和库的项目,Microsoft Visual C++是理想的选择。
(四)其他编译器
Dev-C++是一款轻量级的C/C++集成开发环境,安装简单,使用方便。适合初学者快速上手,具有完整的编译、运行和调试功能,编译出错信息能自动翻译为中文显示。
Turbo C是早期的C编译器,界面分割明确,调试方便,会指出语句运行错误并给出提示。操作简单,安装快捷,适用于一些特定的小型或老式项目开发。
三、常见的C构建系统
(一)Make
Make 构建系统创建于 1977 年,是最早的构建系统之一。其特点包括简单灵活,但也存在复杂、难以阅读和维护困难的问题。
(二)CMake
CMake 的优势在于强大的跨平台特性和易于理解的配置方式。它能够为不同平台生成相应的构建文件,如为 Unix 系统生成 Makefile,为 Windows 生成 Visual Studio 解决方案等。
(三)Ninja
Ninja 构建系统以速度为主要优势。它通过充分利用硬件资源和优化内部算法,实现了快速构建。
Ninja 常与 CMake 等元构建系统结合使用。在 CMake 生成 Ninja 所需的输入文件后,Ninja 能够迅速执行构建操作。
(四)其他构建系统
GNU Autotool:是类 Unix 系统常用的生成系统之一,通过 configure、make 和 make install 来构建和安装软件。但存在复杂、阅读困难和对 Windows 不友好的问题。
Bazel:类似于 Make、Maven 和 Gradle,使用高级构建语言,支持多种语言和多平台构建,适用于大型代码库和跨多个存储库的项目。
四、Make
MAKE 工具是软件开发和项目管理中的重要工具。它能够根据指定的规则和依赖关系,自动完成编译和构建工作。
在项目管理中,MAKE 工具的重要性不可忽视。当项目规模较大,涉及众多源文件和复杂的依赖关系时,MAKE 工具可以有效地组织和管理编译过程。它可以确保只有那些被修改或依赖关系发生变化的文件被重新编译,大大提高了编译效率,节省了时间和计算资源。
MAKE 工具自动维护编译工作的方式基于其对依赖关系的精确判断。它会检查源文件和目标文件的修改时间,当源文件的修改时间晚于目标文件时,就会重新执行编译命令。这种智能的判断机制避免了不必要的重复编译,减少了错误的发生。
通过 Makefile 文件,开发者可以清晰地定义项目的目标、依赖以及相应的编译命令。例如,一个可执行文件可能依赖于多个源文件和库文件,MAKE 工具会根据这些定义准确地执行编译和链接操作,生成最终的可执行文件。
此外,MAKE 工具还支持各种参数和选项,以便更灵活地控制编译过程。例如,可以指定特定的编译器、优化选项等。
快速入门
如果有读过我之前文章的读者,应该知道我之前在VsCode中为多文件的编译,写了一个批处理文件,我们只需执行这个文件,便可以快速运行我们的程序。从某程度上而言,Make是这种方式的专业版。
Make工具,一般,或者说经常在类Linux系统中运行,你可以很方便的通过,诸如
sudo apt install make命令获得,如果你想在Windows系统中,也可以通过 【Releases · maweil/MakeForWindows (github.com)】等渠道下载。
话不多说,我们来看看如何运用
执行Make命令后,Make会默认找寻当前文件夹下的Makefile文件,在Windows系统中,就是一个Makefile.txt文件。
当然,你也可以选择,通过
make -f 文件
// 或
make --file=文件文件里面一系列,所谓的规则(rules)构成,它的通式如下:
<target> : <prerequisites>
[tab] <commands>这条规则的意思是,在前置条件(prerequisites)存在的情况下,通过命令(commands)制作目标(target)。
一个目标(target)通常是程序生成的文件的名字;例如可执行文件或对象文件就是目标。目标也可以是指定要执行的动作的名字,比如“clean”。
先决条件(prerequisite)是用于创建目标的输入文件。一个目标通常依赖于多个文件。
命令(command)是`make`执行的动作。一条规则可能包含多条命令,每条命令都在单独的一行上。请注意:你需要在每条命令行的开头放置一个制表符!这是一个容易让人忽视的要求,常常会使人措手不及。
通常,一条命令位于带有先决条件的规则中,并且在任何先决条件发生变化时用于创建目标文件。然而,指定目标命令的规则不一定需要有先决条件。例如,与目标“clean”关联的删除命令所在的规则就没有先决条件。
因此,一条规则解释了如何以及何时重新构建特定文件,这些文件是该特定规则的目标。`make`会在先决条件上执行命令来创建或更新目标。一条规则还可以解释如何以及何时执行一个动作。
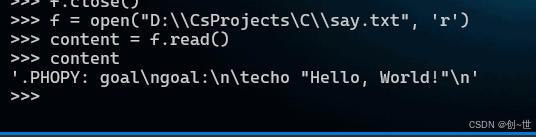
下面以一个小栗子说明一下,准备一个say.txt作为执行文件,内容如下,为了便于说明,这里使用了一个伪目标,具体后面有说明,我们的任务很简单,就是打印一条语句
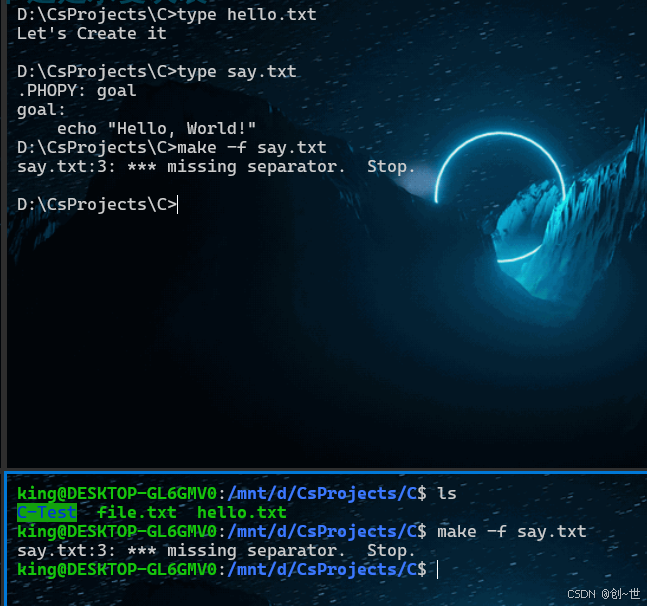
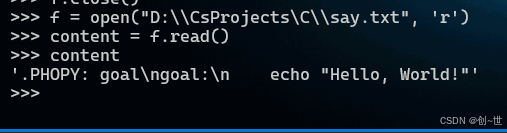
文件内容,我在Windows vscode中编写,tab键确有无疑,不过执行如下,错误提示,在最后一行没有分隔符,也即是tab,即使再三确认,它还是会报错,为什么呢?主要原因,这里用python说明,我们将文件内容输出,可以看到在tab键的地方,是四个空格,好像也没问题。
那我们在Linux(Windows的WSL)中再编辑一下,效果上是不会有区别的,我们同样使用tab键。编辑好后,在Windows和Linux系统中再次执行,可以看到都成功了
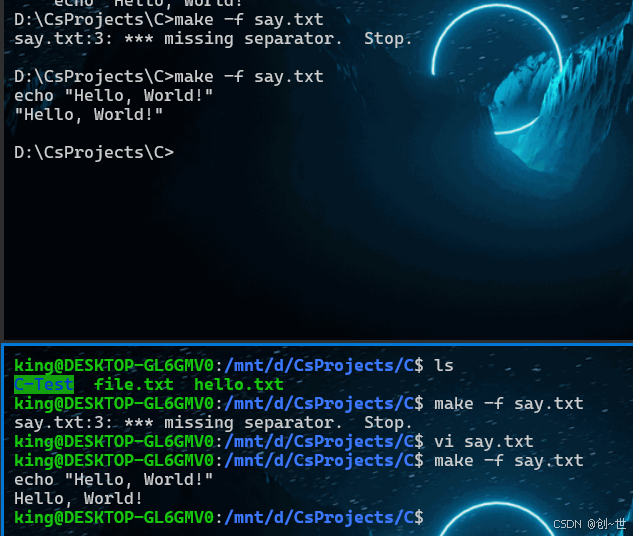
OK,我们再看看文件内容,可以发现,在Linux中,tab键的地方是一个\t,制表符,这就是原因所在,因为tab键本身就应该是一个制表符,而之所以在vscode中是四个空格,是因为编辑器使用了所谓的软制表符(soft tab),这将使用四个或者另有规定的(你会在一些IDE中发现可以指定Tab的空格数)空格替代制表符,当然这是有原因的,读者可以自行查找。如果在Windows的记事本中编辑,使用tab键,这将是原始的制表符,读者可以尝试一下。
就因为一个tab键,搞得入门这么难,是不是有点。没关系,Make提供有解决办法,那就是使用内置变量
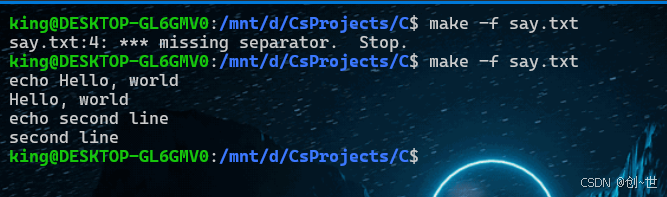
.RECIPEPREFIX = >
goal:
> echo Hello, world
echo second line在第一行,我们将命令的分隔符换成了>,这样我们就不用使用tab键了。 如果第四行仍然使用tab,这就会报错了,如果make版本过低,这个内置变量是没有的,也就不会有效果。
可以通过以下命令查看,如果是4以上应该没有问题
make --version现在回到输出,你可以发现,对于一条规则,make会先打印命令,再执行命令。OK,那现在看看如何编译C文件,修改文件如下:
.RECIPEPREFIX = >
main.o: main.c
> gcc -c main.c
all: main.o
> gcc main.o -o mainmake一下,嗯,只执行了一个

不急,原因,官方是这么说的
默认情况下,目标(goal)是 Makefile 中的第一个目标(不包括以点号开始的目标)。因此,Makefiles 通常编写成使得第一个目标是为了编译整个程序或所描述的程序集。
如果 Makefile 中的第一条规则有多个目标,则只有这条规则中的第一个目标成为默认目标,而不是整个列表。你可以使用 `.DEFAULT_GOAL` 变量从 Makefile 内部管理默认目标的选择。
你也可以通过给 `make` 命令行参数来指定不同的目标。使用目标的名字作为参数。如果你指定了多个目标,`make` 将按照你命名的顺序依次处理每个目标。
所以,有两种方式,第一,指定可以完成我们需求的规则,或者执行这条规则可以间接完成我们的需求(如下),其二,把可以完成我们需要的规则放在开头(经常如此)。
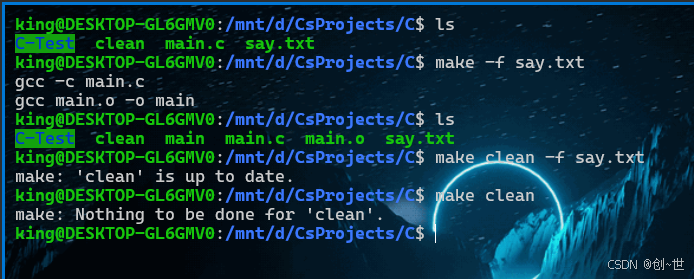
make all -f say.txt 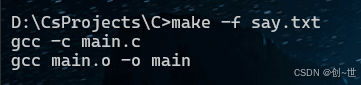
整个过程,你可以看成是这样的:
要制作目标all, 输入文件main.o存在?
-> 不存在, 如何制作
->制作main.o需要main.c
->main.c存在
->执行 gcc -c main.c
-> main.o存在
-> 执行gcc main.o -o main到这里,你可以发现Make好像有点意思,如果你再运行一下,你就可以发现Make的好处:我们无需在制作那些已经制作好的“原料”,而只需将那些经过更改的文件重新更新即可,对于大量的文件,这点就尤其不错,笔者之前的批处理文件,你会发现,每次批处理都必须删除所有的O文件,exe文件,尽管有时候只修改了一点。
另外,你会发现,在上面的文件中,我没有声明all为伪目标,显然在这里也不是某个文件,但是它依然成功了,你也可以试试声明一下,因为就算make认为all是文件,除非它作为某条规则的先决条件,否则我们总是会成功的。但是如果存在就不一样了,试看下面的场景:
所以,能声明,还是声明得好。
(一)Makefile 的基本规则
1、规则的构成
在 Makefile 中,target(目标文件)、prerequisites(依赖文件)和 command(命令)之间存在着紧密的关系。target 代表着最终期望生成的文件或者操作的结果,可以是可执行文件、库文件、中间文件等。prerequisites 则明确了生成目标所需的文件或其他目标。command 则规定了具体的操作步骤,用于将依赖文件转化为目标文件。
例如,一个简单的 Makefile 规则可能如下:
my_program: main.o helper.o
gcc -o my_program main.o helper.o
main.o: main.c
gcc -c main.c
helper.o: helper.c
gcc -c helper.c在这个例子中,my_program 是目标文件,main.o 和 helper.o 是其依赖文件,gcc -o my_program main.o helper.o 是生成目标的命令。
2、规则的执行条件
当 prerequisites 中的文件更新时,会对 target 的生成产生重要影响。如果 prerequisites 中任何一个文件的修改时间比 target 新,那么 Makefile 就会认为 target 已经过时,需要重新执行相应的 command 来生成更新后的 target 。
例如,如果 main.c 或 helper.c 被修改并保存,其修改时间将晚于对应的 .o 文件和最终的可执行文件 my_program。此时,Makefile 会识别到这种变化,并重新执行相应的编译命令来更新 main.o、helper.o 和 my_program。
以下是一个更具体的代码示例来说明规则的触发机制:
app: main.c utils.c
gcc -o app main.c utils.c
main.c:
echo "Modified main.c" > main.c
utils.c:
echo "Modified utils.c" > utils.c当我们修改了 main.c 或 utils.c 中的内容并保存后,再次执行 make 命令,Makefile 会检测到这些文件的更新,从而触发重新编译和链接的操作,生成新的 app 可执行文件。
(二)Makefile 中的变量
1、变量的定义与使用
在Makefile中,变量是非常重要的特性之一,它们允许你定义可以在构建过程中重复使用的值。Makefile中的变量可以用来存储路径、文件名、编译选项等信息,从而使得构建脚本更加灵活和易于维护。
Makefile 中变量的命名规则较为灵活,变量名可以包含字符、数字和下划线,但不能包含 #、= 或空字符,同时变量是大小写敏感的。
变量的定义方式有多种,常见的有“=”和“:=”。使用“=”定义的变量是递归展开式变量,其值在引用时会根据其他相关变量的最新值进行动态计算。例如:
VAR1 = $(VAR2)
VAR2 = value
all:
@echo $(VAR1)而使用“:=”定义的变量是直接展开式变量,其值在定义时就确定,不会受后续其他变量变化的影响。比如:
以下通过一个简单的代码示例展示如何引用和操作变量:
FILES = file1.txt file2.txt
RESULT = $(FILES)
all:
@echo $(RESULT)2、目标变量与模式变量
目标变量的作用范围仅限于特定的目标及其相关的规则。这意味着在该目标范围内定义的变量,不会影响到其他目标。比如:
prog : CFLAGS = -g
prog : prog.o
gcc $(CFLAGS) prog.o -o prog在上述示例中,CFLAGS 仅在 prog 目标的规则中有效。
目标变量常用于为特定目标设置独特的编译选项或其他参数,以实现更精细的控制。
模式变量在多目标规则中发挥着重要作用。例如,使用 %.o : %.c 这样的模式规则,可以方便地处理具有相同编译规则的多个目标。
以下是一个模式变量在多目标规则中的应用示例:
OBJS = main.o helper.o
%.o : %.c
gcc -c $< -o $@
all: $(OBJS)
gcc -o all $(OBJS)在这个例子中,%.o : %.c 规则适用于所有符合 *.o 与 *.c 对应关系的文件,使得编译过程更加简洁和高效。
- Make还提供了其它一些特殊变量,它们的值与当前构建的规则相关联。
- 例如:
$@:表示目标文件。$<:表示第一个前置条件。$?:表示所有比目标更新的前置条件。$^:表示所有前置条件。$*:表示匹配符%匹配的部分。$(@D)和$(@F):分别表示目标文件的目录名和文件名。$(<D)和$(<F):分别表示第一个前置条件的目录名和文件名。
(三)Makefile 中的伪目标
1、伪目标的概念
伪目标是 Makefile 中的一种特殊目标,它并不对应实际的文件,而是用于执行特定的操作或管理构建流程。伪目标不生成实际的文件,其目的是执行相关的命令。
与普通目标不同,普通目标通常代表实际存在或需要生成的文件,而伪目标的存在纯粹是为了执行特定命令,不涉及文件的创建或更新。
2、伪目标与普通目标的区别
- 普通目标与实际文件对应,其生成依赖于相关的依赖文件。而伪目标没有这种实际的文件对应关系。
- 普通目标的执行取决于其依赖文件的更新情况,若依赖未更新,可能不会执行相关命令。但伪目标无论其相关文件的状态如何,只要通过 make 命令明确指定,就会无条件执行其定义的命令。
- 普通目标的名称通常与实际文件名相关,而伪目标的名称可以更灵活,不受实际文件名的限制。
3、常见的伪目标应用
“clean”伪目标
“clean”是常见的伪目标,用于清理编译过程中生成的临时文件或中间文件,例如:
clean:
rm -rf *.o temp其用途是在需要重新编译或清理项目时,删除之前生成的二进制文件等,为新的编译提供干净的环境。
“all”伪目标
“all”常作为默认的伪目标,执行主要的编译工作。例如:
all: prog1 prog2 prog3它将多个相关的编译目标组合在一起,一次性执行主要的编译操作,提高了编译的便利性。
在实现方式上,伪目标通常需要明确声明为伪目标,通过在目标名称后面加上 .PHONY 标记,例如:
.PHONY: clean all这样可以确保无论相关文件的存在与否,伪目标的命令都会被执行。
(四)Makefile 中的条件语句
1、条件语句的语法
在 Makefile 中,常用的条件判断指令包括 ifeq、ifneq、ifdef 和 ifndef 。
- ifeq 用于判断两个参数是否相等,如果相等则执行其后的命令,否则跳过。其语法形式如 ifeq ($(var1), $(var2)) 。
- ifneq 则相反,用于判断两个参数是否不相等,不相等时执行其后的命令。例如 ifneq ($(opt), debug) 。
- ifdef 用于判断一个变量是否有值,有值时执行相应命令。比如 ifdef $(FLAG) 。
- ifndef 用于判断一个变量是否没有值,没有值时执行相应命令,像 ifndef $(VAR) 。
在使用这些指令时,要注意参数的格式和空格的使用。例如,在 ifeq 和 ifneq 中,参数之间要用逗号分隔,并且逗号后面要有空格。
2、条件语句的应用实例
以下是一个 Makefile 中条件语句的应用示例:
CC = gcc
CFLAGS = -Wall
ifeq ($(CC), clang)
CFLAGS = -O3
else
CFLAGS = -g
endif
prog: main.c
$(CC) $(CFLAGS) -o prog main.c在上述示例中,根据 CC 变量的值来决定 CFLAGS 的取值。如果 CC 是 clang ,则使用优化选项 -O3 ,否则使用调试选项 -g 。
再比如:
DEBUG = 1
ifeq ($(DEBUG), 1)
CFLAGS += -DDEBUG
endif这里根据 DEBUG 变量的值来决定是否添加 -DDEBUG 编译选项。
又如:
VAR =
ifdef VAR
@echo "VAR is defined"
else
@echo "VAR is not defined"
endif通过 ifdef 判断 VAR 是否有定义来输出不同的信息。
(五)MAKE 的调试方法
1、调试选项
-d 选项是 Make 命令中用于打印调试信息的重要选项。它能够为开发者提供丰富且详细的关于 Makefile 执行过程的信息,有助于深入理解和排查编译过程中的问题。
使用方式如下:
在命令行中直接输入 make -d 即可启用该选项。例如:
$ make -d通过使用 -d 选项,Make 命令会输出诸如 Makefile 中的变量值、规则匹配过程、命令执行顺序等详细信息。这对于理解 Makefile 的内部工作机制以及找出可能存在的错误或异常非常有帮助。
然而,需要注意的是,由于 -d 选项输出的信息通常非常冗长和复杂,可能需要结合 more 或其他分页工具来逐页查看,例如:
$ make -d | more2、常见调试问题及解决
在调试 Makefile 的过程中,可能会遇到一些常见的问题。
问题一:依赖关系错误
可能出现依赖文件未正确声明或依赖关系不正确的情况,导致部分文件未被及时编译或重复编译。解决思路是仔细检查 Makefile 中的规则,确保依赖文件的准确性和完整性。
问题二:变量引用错误
变量的定义或引用不正确,导致编译命令无法正常执行。此时需要确认变量的命名、赋值和引用是否符合预期,尤其注意变量的作用域和展开方式。
问题三:语法错误
例如缩进错误、命令行格式错误等。对于这类问题,需要严格遵循 Makefile 的语法规范,仔细检查每一行的格式和语法。
问题四:目标未更新
即使源文件有修改,但目标文件未被重新编译。可以通过检查文件的修改时间、依赖关系和相关规则来确定问题所在。
(六)MAKE 结合代码的实例
1、逐个编译源代码
以下是一个简单的示例,展示如何手动编写 Makefile 来逐个编译源代码文件:
CC = gcc
CFLAGS = -Wall
# 定义目标文件
target1: target1.c
$(CC) $(CFLAGS) -o target1 target1.c
target2: target2.c
$(CC) $(CFLAGS) -o target2 target2.c在上述示例中,我们定义了两个目标文件 target1 和 target2,每个目标都有对应的源文件和编译命令。这样,当我们执行 make target1 或 make target2 时,就会分别对相应的源文件进行编译。
2、自动推导编译
GNU make 具有强大的自动推导功能,可以大大简化 Makefile 的编写。例如,对于以下代码:
CC = gcc
CFLAGS = -Wall
# 无需明确指定依赖关系,make 会自动推导
target: target.c
$(CC) $(CFLAGS) -o target target.c在这个示例中,当 target.c 文件被修改时,make 会自动识别并重新编译生成 target 可执行文件,无需我们手动指定依赖关系,提高了编写 Makefile 的效率和便捷性。
五、CMake
CMake 是一个强大的跨平台构建工具。它的定义是通过简单的配置语句来生成适应不同平台和编译器的构建文件。其作用在于简化软件构建过程,提高开发效率。
在软件开发中,CMake 的重要性不可忽视。它能够有效地管理项目的源文件、库和依赖项,使得开发者无需为每个平台和编译器手动编写复杂的构建脚本。
无论是大型复杂项目,还是小型简单项目,CMake 都能提供清晰且可维护的构建规则。它支持多种编程语言和开发环境,为跨平台开发提供了极大的便利,是现代软件开发中不可或缺的一部分。
(一)获得 CMake
可以在Download CMake官网下载自己需要的版本,对于有些IDE如Clion,直接有CMAKE配套更加方便一点。
(二)CMakeLists.txt 文件基础
1、最低版本要求
cmake_minimum_required命令用于指定项目所需的最低CMake版本。其格式通常为
cmake_minimum_required(VERSION <min>[...<policy_max>] [FATAL_ERROR])<min>参数指定了CMake的最低版本要求,例如cmake_minimum_required(VERSION 3.10),如果当前CMake版本低于此要求,将停止处理项目并报告错误。
可选的<policy_max>参数在3.12版本引入,用于指定版本区间。
FATAL_ERROR参数在CMake 2.6及更高版本中被接受但被忽略,在2.4及更低版本中使用时,如果版本不满足要求,将触发错误而非仅警告。
使用该命令的主要意义在于确保项目在特定版本的CMake环境下能够正常运行,避免因版本差异导致的语法不兼容或功能缺失等问题。
2、项目信息设置
project命令用于定义项目的各种信息,包括名称、版本等。
例如,project(MyProject VERSION 1.2.3),其中MyProject是项目名称,1.2.3是项目版本。
通过project命令设置项目名称后,在后续的CMake配置中,可以使用预定义的变量PROJECT_NAME来引用该名称,从而提高了代码的可维护性和灵活性。
项目版本的设置可以通过VERSION子参数来实现,格式为<MAJOR>[.<MINOR>[.<PATCH>[.<TWEAK>]]],其中MAJOR表示主版本号,MINOR表示次版本号,PATCH表示补丁版本号,TWEAK表示微调版本号(可选)。
此外,project命令还可以指定项目使用的编程语言等其他信息,为项目的整体配置提供了基础。
(三)生成可执行文件
add_executable 是 CMake 中用于添加可执行文件的重要命令。以下将结合代码示例详细讲解其使用方法以及源文件的指定方式。
1、普通可执行文件
命令形式为:
add_executable(<name> [WIN32] [MACOSX_BUNDLE][EXCLUDE_FROM_ALL][source1] [source2...])例如:
cmake_minimum_required(VERSION 3.5)
project(MyProject)
add_executable(myExecutable main.cpp helper.cpp)在上述示例中,myExecutable 为生成的可执行文件的名称,main.cpp 和 helper.cpp 为构建该可执行文件的源文件。
2、导入的可执行文件
命令形式:
add_executable(<name> IMPORTED [GLOBAL])例如:
cmake_minimum_required(VERSION 3.10.2)
project(test)
set(GIT_EXECUTABLE "/usr/local/bin/git")
add_executable(Git::Git IMPORTED)
set_property(TARGET Git::Git PROPERTY IMPORTED_LOCATION "${GIT_EXECUTABLE}")3、别名可执行文件
命令形式:
add_executable(<name> ALIAS <target>)例如:
cmake_minimum_required(VERSION 3.10.2)
project(test)
SET(CMAKE_RUNTIME_OUTPUT_DIRECTORY output)
add_executable(runtest main.cpp)
add_executable(test_name ALIAS runtest)4、源文件的指定方式
源文件可以通过以下几种方式进行指定:
- 直接在命令中列出源文件,如 add_executable(myExecutable main.cpp helper.cpp) 。
- 使用变量来存储源文件列表,如 set(sources main.cpp helper.cpp) ,然后 add_executable(myExecutable ${sources}) 。
还可以通过一些函数来自动查找源文件,如 file(GLOB_RECURSE sources *.cpp *.h) ,然后 add_executable(myExecutable ${sources}) 。但需要注意其可能存在的问题,如可能会将一些不必要的文件也包含进来。
对于将源码放在子文件夹中的情况,可以使用 aux_source_directory 函数来自动搜集需要的文件后缀名,如 aux_source_directory(mylib sources) ,然后 add_executable(myExecutable ${sources}) 。
(四)管理库文件
1、生成库文件
add_library 命令用于创建库,其形式如下:
add_library(<name> [STATIC | SHARED | MODULE][EXCLUDE_FROM_ALL][source1] [source2...])- STATIC:表示生成静态库。例如:add_library(myStaticLib STATIC mySource1.cpp mySource2.cpp) 。
- SHARED:表示生成动态库。例如:add_library(mySharedLib SHARED mySource3.cpp mySource4.cpp) 。
同时,add_library 还有一些其他参数和用法:
- EXCLUDE_FROM_ALL:如果指定,将在创建的目标上设置相应属性,在默认编译时该目标不会被编译。
- 若不指明库的类型,默认生成静态库。
不同库类型的特点和适用场景
- 静态库(Static Library):
-
- 特点:代码在编译过程中被完整地载入可执行程序,体积较大;生成的可执行文件独立执行,软件发布方便。
-
- 适用场景:适用于对软件体积要求不高,且需要独立发布可执行文件的情况,如一些小型工具软件。
- 动态库(Shared Library / Dynamic Library):
-
- 特点:代码在可执行程序运行时才载入内存,编译过程中仅简单引用,代码体积较小;但生成的可执行文件发布时必须同时发布其依赖的动态库。
-
- 适用场景:适用于大型软件项目,节省空间,方便升级,如大型游戏、复杂的应用程序。
2、链接库文件
target_link_libraries 命令用于指定链接给定目标和/或其依赖项时要使用的库或标志。其格式多样,例如:
target_link_libraries(<target>... <item>......) ,其中 <target> 必须由诸如 add_executable 或 add_library 之类的命令创建。
每个 <item> 可能是:
- 库目标名称,生成的链接行将具有与目标关联的可链接库文件的完整路径。
- 完整路径的库文件。
- 普通的库名称,生成的链接行将要求链接器搜索库。
- 链接标志。
target_link_libraries 还支持不同的关键字,如 PRIVATE、PUBLIC 和 INTERFACE,用于更精细地控制链接关系。
例如:
add_library(myLib SHARED mySource.cpp)
add_executable(myExecutable main.cpp)
target_link_libraries(myExecutable myLib)通过上述命令,将 myLib 库链接到可执行文件 myExecutable 。
(五)头文件与搜索路径
include_directories 命令用于添加头文件搜索路径。其语法为
include_directories([AFTER|BEFORE] [SYSTEM] dir1 [dir2...])可以添加一个或多个目录,这些目录将被添加到编译器的头文件搜索路径中。
相对路径将被解释为相对于当前 CMakeLists.txt 文件的路径。例如,如果当前文件位于 /project/src ,那么 include_directories(../../include) 将添加 /project/include 作为搜索路径。
AFTER 和 BEFORE 选项可控制添加的路径在现有路径列表中的位置。SYSTEM 选项表示将添加的目录视为系统头文件目录。
使用示例:
cmake_minimum_required(VERSION 3.5)
project(MyProject)
include_directories(include) # 添加当前目录下的 include 目录1、库文件搜索路径
link_directories 命令用于设置库文件的搜索路径。其格式为
link_directories(directory1 [directory2...]) 该命令主要用于向链接器提供额外的库文件搜索目录,以便在链接过程中能够找到所需的库。
例如:
cmake_minimum_required(VERSION 3.10)
project(MyProject)
link_directories(/path/to/libs) # 添加指定的库文件搜索路径使用场景包括:
- 当项目中的库文件位于非标准位置时,通过该命令告知链接器在哪里查找。
- 对于一些特殊的项目架构,可能需要为不同的目标设置特定的库搜索路径。
需要注意的是,此命令在现代 CMake 中使用相对较少,更推荐使用 target_link_directories 命令来为特定的目标设置库搜索路径,以实现更精细的控制和更好的可维护性。
(六)复杂项目结构示例
1、多源文件项目
在多源文件项目中,源文件数量众多时,需要合理组织和配置 CMake 来确保项目的正确构建。例如,当源文件分布在同一目录或不同目录时,我们可以采用不同的策略。
如果源文件都在同一目录下,可以使用 aux_source_directory 函数来自动收集所有源文件,然后将其用于生成可执行文件或库。
当源文件分布在不同目录时,我们可以为每个子目录创建单独的 CMakeLists.txt 文件,在父目录的 CMakeLists.txt 中使用 add_subdirectory 命令来引入子目录,并在子目录的 CMakeLists.txt 中进行相应的配置。
2、包含子目录的项目
add_subdirectory 命令在处理包含子目录的项目时发挥着关键作用。
其命令格式通常为
add_subdirectory(sourceDir [binaryDir [EXCLUDE_FROM_ALL]]) sourceDir 是必选参数,指定子目录的路径,该子目录必须包含 CMakeLists.txt 文件。子目录的路径可以是相对路径或绝对路径。
binaryDir 是可选参数,如果指定,用于指定子目录生成的输出文件的存放位置。
EXCLUDE_FROM_ALL 也是可选参数,如果指定,子目录中的目标默认不会被父目录的目标包含,除非父目录的目标依赖于子目录的目标。
例如,在父目录的 CMakeLists.txt 中:
cmake_minimum_required(VERSION 3.10.2)
project(test)
add_subdirectory(sub) # 仅指定子目录或者:
cmake_minimum_required(VERSION 3.10.2)
project(test)
add_subdirectory(sub output) # 指定子目录和输出目录又或者:
cmake_minimum_required(VERSION 3.10.2)
project(test)
add_subdirectory(sub output EXCLUDE_FROM_ALL) # 加上排除选项在子目录的 CMakeLists.txt 中,同样可以进行各种配置,如创建库、添加源文件等。
通过合理使用 add_subdirectory 命令,可以有效地组织和构建包含子目录的复杂项目结构,提高项目的可维护性和可扩展性。
(七)可选库与条件编译
1、引入可选库
在 CMake 中,引入可选库是一种常见的需求,尤其是在大型项目中。以下是一个结合代码示例展示如何根据条件添加可选库的步骤:
首先,我们创建一个名为MathFunctions的库,在其所在的子目录MathFunctions中的CMakeLists.txt文件中,添加以下代码:
add_library(MathFunctions mysqrt.cxx)在项目的根目录CMakeLists.txt中,添加以下代码来设置一个可选库的选项:
option(USE_MYMATH "Use tutorial provided math implementation" ON)然后,根据选项的值来决定是否添加和链接MathFunctions库:
if (USE_MYMATH)
include_directories("${PROJECT_SOURCE_DIR}/MathFunctions")
add_subdirectory(MathFunctions)
list(APPEND EXTRA_LIBS MathFunctions)
endif()最后,在链接可执行文件时使用EXTRA_LIBS变量:
target_link_libraries(Tutorial ${EXTRA_LIBS})这样,通过设置USE_MYMATH选项的值,就可以控制是否引入MathFunctions库。
2、条件判断语句
if/else/endif在 CMake 中有着广泛的应用。其基本语法如下:
if(condition)
# 条件为真时执行的指令块
else()
# 条件为假时执行的指令块
endif()条件可以是各种形式,例如:
- 变量的判断:if(DEFINED MY_VARIABLE)
- 版本的比较:if(${CMAKE_BUILD_TYPE} STREQUAL "Release")
- 逻辑运算:if(flag1 AND flag2)
以下是一个简单的示例,根据不同的条件设置不同的编译选项:
if(USE_FEATURE_A)
add_compile_options(-DENABLE_FEATURE_A)
else()
add_compile_options(-DDISABLE_FEATURE_A)
endif()通过灵活运用if/else/endif条件判断语句,可以使 CMake 配置更加灵活和适应不同的项目需求。
(八)指定 C 标准
1、设置最低版本
要确保使用特定版本的 CMake 进行构建,可以在 CMakeLists.txt 文件的开头使用 cmake_minimum_required 命令。例如,如果您希望项目要求 CMake 版本至少为 3.10,可以这样编写:
cmake_minimum_required(VERSION 3.10)如果当前系统中的 CMake 版本低于此要求,CMake 将停止处理项目并报告错误。这样可以避免因版本差异导致的语法不兼容或功能缺失问题。
2、选择 C 标准
在 CMake 中,可以通过 set 命令来指定 C 标准。常见的 C 标准包括 C89、C99、C11 等。以下是示例代码:
# 选择 C89 标准
set(C_STANDARD 89)
# 选择 C99 标准
set(C_STANDARD 99)
# 选择 C11 标准
set(C_STANDARD 11)将上述代码添加到 CMakeLists.txt 文件中的适当位置,即可指定所需的 C 标准。需要注意的是,指定 C 标准后,还需要将其应用于特定的目标,以确保在编译和构建过程中生效。

















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









