







(一)哈希(Hash)的定义:
Hash是散列的意思。
散列(hash)是一将预映射内容产生映射的过程,最终以一串数值呈现,称之散列值或者哈希值。
散列(哈希)过程 :
散列输入:任意长度的输入(或者称之为pre-image),可以是字符串,数据,任何文件。
散列过程:将输入的值通过散列算法处理
散列输出:散列值。
这个过程是一个压缩并映射的过程,压缩原来“输入的内容所占据的空间”,变为散列值之后,远小于输入内容所占据的空间。
哈希的过程就是调用了哈希算法或叫哈希函数进行这个过程的。
(二)哈希函数(散列算法)
1.理解哈希算法的过程:
散列(哈希)算法
它是哈希这个过程调用的算法,哈希算法根据输入的内容,可以是字符串,数据,文件等,输出一串数字作为散列值。(即根据内容的确定性,产生了结果的确定性)
输出的散列值重复的几率几乎为0,可以认为唯一的任何内容会产生唯一的哈希值,算法存在着不可逆的特点。
不可逆特性:指的是不能单单凭借散列值这串数字逆推出实际的输入内容类型等,因为它只是压缩、映射出的一个值,过程损失无数的信息。
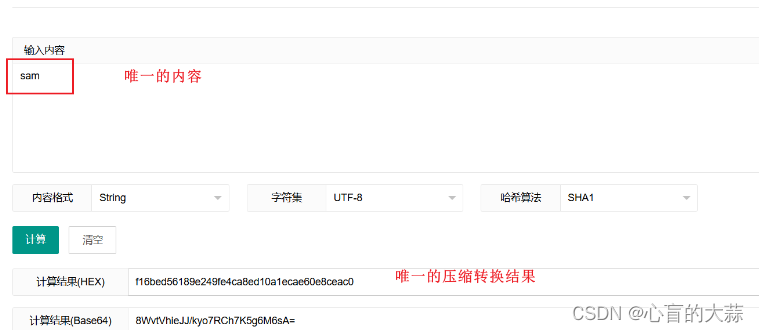
通过举例讲清楚哈希的过程

<1>以key作为输入: input
1.以key作为输入:输入’sam’,作为key的值
<2>对输入的键进行某个哈希算法,得到哈希值:hash value
2.将输入内容“sam”字符串,应用哈希算法的SHA1,压缩映射出一个哈希值。
找到哈希值算法的一种,比如SHA1,转化出来的结果例如:
哈希值:ef995514fa17e54a609c06e7a9df399c3694e398
<3>将哈希值进行处理后转换为哈希数组的索引:hash index
3.拿到16进制的哈希值,转换到10进制之后,通过取模等操作,获得索引:
示例:
int("ef995514fa17e54a609c06e7a9df399c3694e398",16)
转换为10进制结果:1367868219924655442010668301516224798581341873048。
假设数组的size是8,那么j接下来对这个哈希值进行取模操作
1367868219924655442010668301516224798581341873048%8=0
则对应数组的"0"索引位置。就称哈希索引hash index,对应数组的索引位置0
这个hash index作为返回值,后续用于其它各种操作中。
2.哈希表中任何的数据操作都执行一次哈希算法
哈希算法的特点在于"极其之快",它拿到key值就可以飞速算出对应的哈希值。
因此我们在哈希表中的任何操作(如查询、插入、删除某元素),它们的核心操作,都是进行一次哈希计算。
比如:
1.插入操作:
首次插入元素"sam"这个key,是对sam键,进行了算出对应索引位置,然后进行value的插入,插入操作的本质就是先利用键执行一次哈希算法,得到了它的索引位置。
2.搜索操作:
接下来某天我们想搜索表中sam这个键值对所在位置,想对这个键进行搜索查询的操作,查询的本质也将会是执行一次哈希的算法,找到它的位置。
插入、查询、删除等。更多哈希表中的数据操作,本质上都是进行对于key的一次哈希算法,哈希算法之迅速,使得这些操作的效率得到极大提升,根据唯一的输入内容,哈希算法会每次都产生唯一的哈希值,通过哈希值稳定、而快速地、每次都找到同样的位置
如下图是对一个输入内容进行哈希值的产生的一个压缩映射过程:
具体使用的是叫做SHA1的哈希算法

3.哈希算法的特性
哈希算法的特性:
1.速度"极快",无论输入内容大小,哪怕是几个G的电影,都会立刻在0.1秒内得到结果。
2.过程不可逆,无法根据散列值推测原本的文件或数据内容。
哈希算法的其它方面用途:
1.文件完整性校验
由于哈希值算法最初的文件内容作为得出散列值的根据,因此它的用途中可以用于“文件完整性”校验,
如果内容略有哪怕细微差别,也会得出完全不同的散列值
(这也称之为哈希值算法的雪崩效益,一点点的内容不同产生的是完全不同的结果)
但是内容完全一致时根据散列规则会得到一样的散列值,用散列值进行文件完整性校验。
2.密码加密
哈希算法加上其他的加密算法可以保证数据不被轻易泄露,比如支付宝中的密码就是经过哈希算法和其它算法
加密过后才存放在数据库中
4.python自带的hash()与hashlib中的哈希算法的区别
自带的hash算法以及缺陷
1.hash(" ")------用于教学和演示的非专用哈希算法
在视频教学使用哈希算法时候,通常不顾及实际是否能够真的作为代码底层,只是注重hash算法在其中的
大致作用,用于教学和演示的过程帮助学生理解。
课堂上往往使用hash()作为哈希表的实现原理的教学的内容,这种hahs()得到的结果还不需要在16进制和10进制中转换,
python内置的hash()突出一个简易好理解,直接得到10进制的非专用的哈希值。
但是hash()大概也只能用于教学中,因为它产生的哈希值在不同实例中是不同的,真正代码的底层不能使用自带的这个hash().
也就是说:你写的代码中,如果使用hash(),
仅能在!!本次执行中!!,相同的key才会得到一样的哈希值,
print(hash("sam"))
print(hash("sam"))
print(hash("sam"))
但是如果我们再次运行.py文件,根据python解释器的不同时间、或的任务进程、甚至不同机器的不同版本python解释器,对于这种简易的hash()都会导致不同hash值的产生。
(在市面上3.3以上的python解释器会被区分开,不同时间\任务进程\不同机器...产生不同的hash值。)
这样写出来的当然也只能用于演示"和代码运行在一个文件、执行的单次进程"。
真实场景于底层设计一个哈希表是不可以使用它的,对于不同的实例,比如不同python解释器,或者不同的时间,不同的时间运行它都会产生不一样的结果。
除非是再所有的插入、查询操作都同一页代码同一次任务执行这种演示教学场景。
hashlib中的hash算法
既然自带的hash(),不推荐用于实现真正的底层,我们可以从hashlib中选用一种哈希算法,使用专业的hash算法,达到所说的,“每次根据唯一的输入都有唯一的输出,不会任意变换”。
import hashlib
hash_object= hashlib.sha1(key.encode(“utf-8”))
hash_hexdig=hash_object.hexdigest()
1.具体使用只需要hashlib.加上具体的算法名,
至于具体写法,可以写 (b"String")的格式,
解释含义:先将其转换为字节型(bytes)数据类型.
另一种写法,可以对string使用(" ".encode("utf-8"))的格式,
解释含义:同样是转换为字节型的数据,而且是utf-8编码的字节类型,更为常用
2.如果要使用哈希值,就要调用它的.hexdigest().
print(sha1_hash.hexdigest()),
解释含义:其中hex是hexadecimal(十六进制)的缩写,而digest是摘要的意思,即该哈希对象的十六进制哈希摘要。
5.哈希算法为什么出现:操作效率的极致需求
答:追求更高的增删查的效率,
值得一提的是哈希算法在追求效率的过程中独树一帜,其它的算法主要在搜索的策略层面进行优化,而是在另一种层面:将数组的内容与索引用哈希算法密切地联系到了一起,以提高数组的操作效率。
解释:我们之前学习数组的时候,提到过它有O(1)级别的利用索引访问操作的效率,
前面的学习中,我们没有学习,关于对数组的内容,进行搜索的几种算法
但在后面的章节中我们可能会学习到一些对于数组的搜索方法:
“二分查找”、"平衡二叉树"等方法,
发现它们这些搜索查询方法终究只能将效率突破到O(logn)的程度,对大型数据集来说:
我们需求不止步于此,仍想追求最大限度地提升效率,视图一个使数组的查询搜索删除达到O(1)级别的效率。
最终我们发现:哈希算法中,每次计算哈希值极快的特点达到了常数级别O(1),
如果利用哈希算法加强数组的索引与键的联系,(理想情况下)对数组的频繁搜索查找来说,哈希数组是搜索最快的O(1)级别的效率。
总结来说:
数组不甘于只在访问效率如:a[1]这种操作达到O(1)的常数级别,更是想将数组发挥到极致,让它在各个位置的查询、删除、插入都达到O(1)级别,而普通的线性数组的这三个操作都接近O(n)级别,要慢于哈希表。
哈希算法并不去跟其它搜索算法比较搜索办法的巧妙逻辑,而是直接利用key每次现场计算哈希值映射直接找到各个想查询的索引处。
(三)python中的dict和set与hash的关系
dict和set,二者都是使用了hash作为底层
使用hash作为底层的优势:
dict主要体现在,无论dict容纳多么庞大的数据集,仍旧具有超快的查询速度。
哈希表通过哈希算法映射作为根本,加上dict底层上的诸多其它方面的设计得以实现超高速查询。
set主要体现在,它具有天生的"去重"功能。
set是每个元素都是唯一的,存放的是元素,而dict认为整个键值对是唯一的,存放的是键值对。
所以我们说:set针对每个元素都“天生自带”去重机制。
(四)哈希表(HashTable)
哈希表 (HashTable)----------又可以意译为 散列数组。
也就是说hash是主要的算法,array数组(表)是主要的载体。
数组里面存放key(和value)
(主要利用数组里面存储的key进行一次哈希的过程)
数组的长度是不可扩展的
这表哈希表在数组余量越多时候可能效率越高,数组越接近于满的时候,越容易引发冲突(哈希冲突会在后面内容讲解,还有负载因子和解决方案),因此我们要尽可能早早预估哈希表中大致要存储的数据量级。
(五)“数组"与"槽位”
数组是哈希表的真实存储形式。
而’槽位’指的就是数组的各个位置,之所以把它叫做槽位,以更有条理的存储里面的数据(一般存放键值对),并且槽位后续会用于处理'哈希冲突'。
回想: 我们学习链表的时候,就把node作为每个位置,将实例出来的值存入node再写入链表。
比如:
node=Node(“value”)
root.next=node
那么:slot对于哈希表也是和node类似的一种"设计"的存在,我们每个新值都放入node,然后复制给数组的位置
slot=Slot(“key”,value)
self.item[index]=slot
类比node,可以设置size和value等属性。
slot作为哈希表的数组的底层,也可以自定义各种结构,比如设置成简单的键值对,或者设置成链表等数据结构。(呈现为size,value,“next地址”的设计形式)
(六)哈希表的实现(未解决collision版本)
<1> Slot(槽位)设计部分:设计成简单的键值对
class Slot():
def __init__(self,key=None,value=None):
'''构造方法,用于将Slot初始化'''
self.key=key
self.value=value
def __str__(self):
'''改写__str__方法,使得能print对应slot实例时候能以特定格式输出'''
return "key:{0} value:{1}".format(self.key,self.value)
<2>借用前面写的Array的数据结构,用于后续实现容器
class Array():
'''这里是对于ADT的具体实现'''
def __init__(self,size):
self.__size=size
self.__item=[None]*size
#用列表来创建一个更长的列表,隐式地把一个list列表充当Array数组。
#这里用list的乘法复制,有点消耗存储资源。
self.__length=0
def __setitem__(self,key,value):
self.__item[key]=value # __item属性派上用场了
self.__length+=1
def __getitem__(self,key):
return self.__item[key]
def __len__(self):
return self.__length
def __iter__(self):
for value in self.__item:
yield value
<3>HashTable的ADT的构思部分:
class HashTableADT(ABC):
@abstractclassmethod
def __init__(self,size):
'''HashTable容器的底层应该用数组'''
pass
@abstractclassmethod
def myHash(self,key):
'''此函数用于实现哈希过程,得到哈希值并对数组取模获得索引位置'''
@abstractclassmethod
def put(self,key,value):
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写入'''
pass
@abstractclassmethod
def search(self,key,value):
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行返回对应位置值'''
pass
@abstractclassmethod
def remove(self,key,value):
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写删除操作'''
pass
<4>HashTable实现(暂时不考虑collision(冲突)问题)
class HashTable(HashTableADT):
def __init__(self,size):
self.size=size
self.item=Array(size)
# 容器底层应该用 的是数据结构的实例,是实例而不是类对象。
'''HashTable容器的底层应该用数组'''
def myHash(self,key):
'''此函数用于实现哈希过程,得到哈希值并对数组取模获得索引位置'''
hash_object=hashlib.sha1(key.encode("utf-8"))
hash_value=hash_object.hexdigest()
number_to_calculate=int(hash_value,16)
# 16不要误写成"16"
hash_index=number_to_calculate%self.size
return hash_index
def put(self,key,value):
slot=Slot(key,value)
self.item[self.myHash(key)]=slot
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写入'''
def search(self,key):
return f"查找到{key}的结果是------------{ self.item[self.myHash(key)] }"
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行返回对应位置值'''
def remove(self,key):
self.item[self.myHash(key)]=None
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写删除操作'''
def __iter__(self):
return iter(self.item)
# 我们想遍历时候发现没有设置遍历方法,Error:'HashTable' object is not iterable,
# 因此我们需要委托给它的实例对象Array里面早就写好过的遍历方法。
# iter() 函数是一个内置函数,用于获取对象的迭代器。
<5>全部代码汇总及进行测试:
from abc import ABC,abstractclassmethod
import hashlib
class Array():
'''这里是对于ADT的具体实现'''
def __init__(self,size):
self.__size=size
self.__item=[None]*size
#用列表来创建一个更长的列表,隐式地把一个list列表充当Array数组。
#这里用list的乘法复制,有点消耗存储资源。
self.__length=0
def __setitem__(self,key,value):
self.__item[key]=value # __item属性派上用场了
self.__length+=1
def __getitem__(self,key):
return self.__item[key]
def __len__(self):
return self.__length
def __iter__(self):
for value in self.__item:
yield value
class Slot():
def __init__(self,key=None,value=None):
'''构造方法,用于将Slot初始化'''
self.key=key
self.value=value
def __str__(self):
'''改写__str__方法,使得能print对应slot实例时候能以特定格式输出'''
return "key:{0} value:{1}".format(self.key,self.value)
class HashTableADT(ABC):
@abstractclassmethod
def __init__(self,size):
'''HashTable容器的底层应该用数组'''
pass
@abstractclassmethod
def myHash(self,key):
'''此函数用于实现哈希过程,得到哈希值并对数组取模获得索引位置'''
@abstractclassmethod
def put(self,key,value):
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写入'''
pass
@abstractclassmethod
def search(self,key,value):
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行返回对应位置值'''
pass
@abstractclassmethod
def remove(self,key,value):
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写删除操作'''
pass
class HashTable(HashTableADT):
def __init__(self,size):
self.size=size
self.item=Array(size)
# 容器底层应该用 的是数据结构的实例,是实例而不是类对象。
'''HashTable容器的底层应该用数组'''
def myHash(self,key):
'''此函数用于实现哈希过程,得到哈希值并对数组取模获得索引位置'''
hash_object=hashlib.sha1(key.encode("utf-8"))
hash_value=hash_object.hexdigest()
number_to_calculate=int(hash_value,16)
# 16不要误写成"16"
hash_index=number_to_calculate%self.size
return hash_index
def put(self,key,value):
slot=Slot(key,value)
self.item[self.myHash(key)]=slot
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写入'''
def search(self,key):
return f"查找到{key}的结果是------------{ self.item[self.myHash(key)] }"
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行返回对应位置值'''
def remove(self,key):
self.item[self.myHash(key)]=None
'''用key,value初始化一个slot,用hash算法计算出这对key value对应的哈希值,再转换成取模后对应的位置,进行写删除操作'''
def __iter__(self):
return iter(self.item)
# 我们想遍历时候发现没有设置遍历方法,Error:'HashTable' object is not iterable,
# 因此我们需要委托给它的实例对象Array里面早就写好过的遍历方法。
# iter() 函数是一个内置函数,用于获取对象的迭代器。
hashtable1=HashTable(5)
hashtable1.put("1","一号")
print(hashtable1.search("1"))
print("----------开始展示hashtable的内容--------")
for v in hashtable1:
print(v)
测试结果展示:
测试结果:
查找到1的结果是------------key:1 value:一号
----------开始展示hashtable的内容--------
None
None
None
key:1 value:一号
None
哈希过程正确性的分析:
对String utf-8的"1"进行哈希算法的Sha1
最终会得到"356a192b7913b04c54574d18c28d46e6395428ab"
进行十进制转换后会得到
3559191979129038086404088824044842668262
进行size5的"取模得到3"
刚好满足出现在"数组的第三个位置"。
可以见得我的简陋的哈希表实现成功,接下来将关注哈希冲突的解决,并继续做出修改。
(七)哈希冲突、冲突解决方案、负载因子
1.哈希冲突是什么
哈希冲突:
哈希值是几乎不可能雷同的,但是最终被限制在数组大小内的时候,取模的结果,也就是哈希索引,对应的索引值这里很有可能雷同,这时候如果不做处理,后面加入的内容就会替换掉前面的内容。
2.哈希冲突的解决方案
(一)"开放寻址"Open Addressing方案解决冲突
<1>线性探查
线性探查的思想:
就比如哈希索引的值所在位置已经被占用,那就+1依次查看后面的位置是否仍被占用
如果被占用,继续+1…直到找到某个位置放置。
<2>'二次’探查
二次探查: 其中的“二次”是指"二次方",做二次方的偏移量。
第一次尝试:hash index+0的平方然后取余
第二次尝试:hash index+1的平方然后取余
…
直到找到某个位置放置
二次探查的结果最终显示要比线性探查更能降低冲突。
或者使用类似二次探查的其它探查
了解:
类似二次探查,可以自己也定义一个规律,然后这种偏移量的规律跳着去找空闲位置。
道理也是类似,只是不是线性的探查了,可能有时候会用。但是一般使用二次探查就很不错了。
<3>描述开放寻址方案存在的扩容问题:
负载因子(load factor)
用数组已经使用了的槽数,与数组的最大长度进行比值。
一般达到0.75(或者0.8)时候,就要开始进行扩容操作了,而不是等满了才扩容。
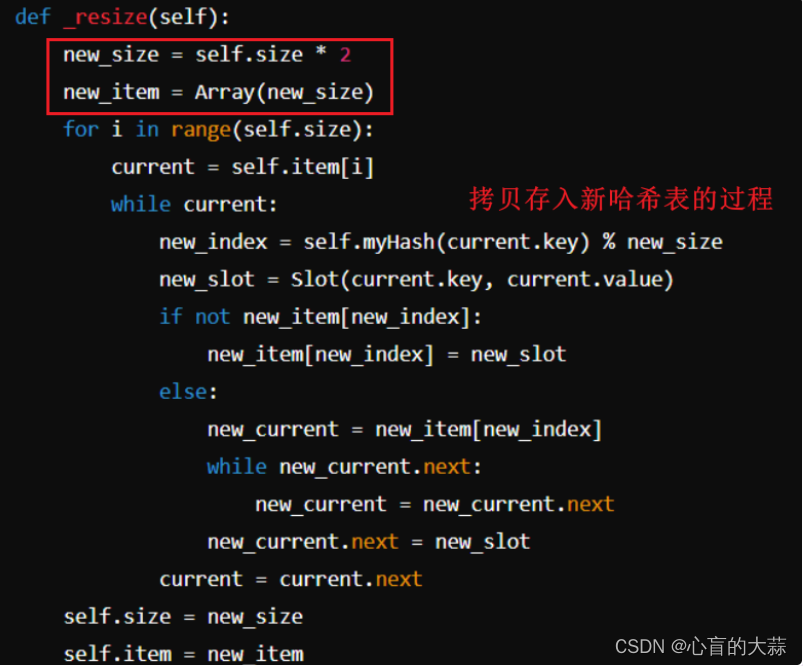
重哈希(rehashing):数组的扩容
感兴趣可以去查看cpython,也就是我们平常调用的python解释器,它就叫做Cpython,它不仅是解释器,而且是一种运行环境,还提供了各种库。
其中cpython中python3.3以上的策略是将槽数扩大2倍的量,并将原有的不为空的数据放到新的扩展后的数组里面。
<4>开放寻址方案解决冲突和重哈希的代码实现:

(二)用"链地址法Separate Chaining"方案解决冲突
<1>哈希冲突采用链表组合数组的设计
链地址法设计思想:
在上面的代码中,使用slot(槽位)的时候,我们把“slot之于数组"类比成"node之于链表"
但是它们终究只是一个名称,内部结构是自己定的,我们结合一下,
对于数组,我们将slot改造升级一下,将它能存放除了key,value,再加上下一个slot的指针
key,vlaue,next.的形式,既可以存储键值对,又可以存放下一个节点。
具体的作用:
这样设计之后,遇到哈希冲突的时候,就将不进行探查,而是直接在该索引位置下的slot上再挂载一个slot,第二个slot里面存放这次的key和value,依次类推,一直把遇到冲突的键值挂在slot后面(前面也可以,这里尾插和头插都可以),形成链表。
(和之前学习的链表并无两样,只是把node换成了slot的称呼。)
最终这个数组每个索引位置很可能都会链接的各个slot在数组的侧面形成一串串链表。
如下图:
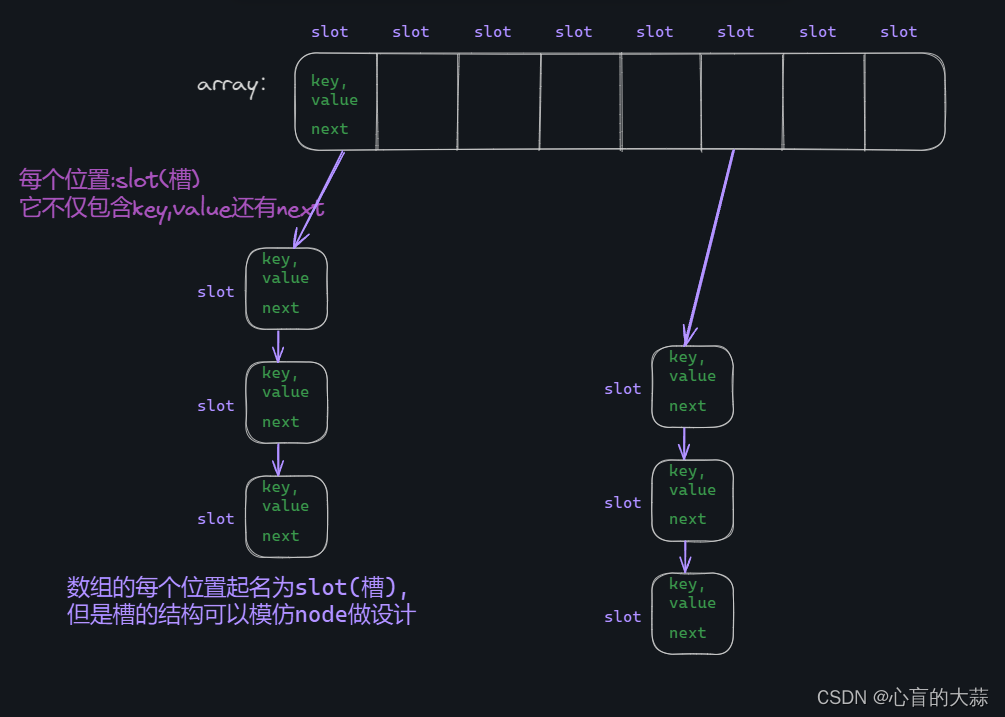
对于具体操作:(查询、插入、删除等)
只需要在具体的查询、插入、删除等操作时候,虽然一整个链表中都对应了同一个取模后的值的索引位置,但是因为它们每个slot内的key是不同的,根据不同的key最终仍能找到对应的值
<2>链地址法解决冲突的代码实现:
Slot的新设计
class Slot():
def __init__(self,key=None,value=None,next=None):
'''构造方法,用于将Slot初始化'''
self.key=key
self.value=value
self.next=None
def __str__(self):
'''改写__str__方法,使得能print对应slot实例时候能以特定格式输出'''
return "key:{0} value:{1}".format(self.key,self.value)
"链表+数组"HashTable的设计
class HashTable(HashTableADT):
def __init__(self,size):
self.size=size
self.item=Array(size)
# 容器底层应该用 的是数据结构的实例,是实例而不是类对象。
'''HashTable容器的底层应该用数组'''
def myHash(self,key):
'''此函数用于实现哈希过程,得到哈希值并对数组取模获得索引位置'''
hash_object=hashlib.sha1(key.encode("utf-8"))
hash_value=hash_object.hexdigest()
number_to_calculate=int(hash_value,16)
# 16不要误写成"16"
hash_index=number_to_calculate%self.size
return hash_index
def put(self,key,value):
slot=Slot(key,value)
index=self.myHash(key)
head=self.item[index] # 专门把第一个slot也叫做head,方便书写逻辑
if not head:
self.item[index]=slot
else:
current=head # 设置一个临时的current用于遍历
while(current.next): #current.next不为空是为了找到最后的那个节点
current=current.next
current.next=slot
def search(self,key):
index=self.myHash(key)
head=self.item[index]
current=head
while(current): # 检查每个current的值
if current.key==key:
return f"查找到{key}的value对应结果是------------{current.value}"
else:
current=current.next
return "Error:key not found"
def remove(self,key):
index=self.myHash(key)
head=self.item[index]
current=head
while(current): # 检查每个current的值
if current.key==key:
current=None
else:
current=current.next
return "Error:key not found"
def __iter__(self):
return iter(self.item)
# 我们想遍历时候发现没有设置遍历方法,Error:'HashTable' object is not iterable,
# 因此我们需要委托给它的实例对象Array里面早就写好过的遍历方法。
# iter() 函数是一个内置函数,用于获取对象的迭代器。
测试结果展示:
hashtable1=HashTable(5)
hashtable1.put("1","一号")
hashtable1.put("2","二号")
hashtable1.put("3","三号")
hashtable1.put("4","四号")
hashtable1.put("5","五号")
hashtable1.put("6","六号")
hashtable1.put("7","七号")
hashtable1.put("8","八号")
hashtable1.put("9","九号")
hashtable1.put("10","十号")
print("----------开始展示hashtable的搜索结果--------")
print(hashtable1.search("1"))
print(hashtable1.search("2"))
print(hashtable1.search("3"))
print(hashtable1.search("4"))
print(hashtable1.search("5"))
print(hashtable1.search("6"))
print(hashtable1.search("7"))
print(hashtable1.search("8"))
print(hashtable1.search("9"))
print(hashtable1.search("10"))
print("----------开始展示hashtable的内容--------")
for v in hashtable1:
print(v)
----------开始展示hashtable的搜索结果--------
查找到1的value对应结果是------------一号
查找到2的value对应结果是------------二号
查找到3的value对应结果是------------三号
查找到4的value对应结果是------------四号
查找到5的value对应结果是------------五号
查找到6的value对应结果是------------六号
查找到7的value对应结果是------------七号
查找到8的value对应结果是------------八号
查找到9的value对应结果是------------九号
查找到10的value对应结果是------------十号
----------开始展示hashtable的内容--------
key:4 value:四号
key:2 value:二号
key:9 value:九号
key:1 value:一号
key:3 value:三号
<3>描述链地址法存在的效率降低的问题:
链地址法经常不能"第一次就"找到数组里面的值,而是继续在该索引位置下遍历直到找到,这是一种效率的降低。
假如数组的大小为n,而我们超额以链表的形式一共放入了2n的元素。
假如多出的那n个元素,
假想以最糟糕的情况:它们全都挂载在了同一索引位置之下,
那么对于这里面的元素,查询、删除、插入的效率将会由哈希表的O(1)降低至O(n)。
但是如果这n个元素都几乎平均分布在哈希表的每个索引下,那么对于每个索引位置下的查询、插入、删除的效率,将会只受到一点点忽略不计的影响,O(1)到O(2~3)左右,仍是常数级。
但是这种`平均`终究只能靠运气,不能人为干预,因此我们还是需要保证负载因子在一定范围能以保证哈希表的效率。
因此我们不是理论上对于链地址法可以超过限度一直塞入元素就要这样去做,
而是"仍应该一开始就规划好数组部分的最大长度,而不是期盼着产生哈希冲突后加在链表里面"。
也就是说:对于链地址法,保持负载因子 λ在如0.75到1.5内,往往可以确保较高的效率。
一旦高于这个限度,推荐不要继续依赖链表,而是进行重哈希(rehashing)扩容整个哈希表.
(八)负载因子
“负载因子”与“开放寻址的哈希表”
1.哈希表采用线性探查或者二次探查的方式提到了扩容问题,又叫做rehashing"重哈希"。
2哈希表采用链地址法进行链表+数组的设计方案又提到了效率降低问题。
以上这两点,归根到底都跟哈希表的"负载因子"有关
负载因子的定义是:
实际元素的个数除以哈希表的最大限度。
举个例子,假设有一个初始容量为16的哈希表,如果插入了12个元素,那么负载因子为:
负载因子= 12/16= 0.75
负载因子=0.75时刻,如果我们使用的不是链地址法,那么此刻就该进行重哈希的操作了,如果使用链地址方案,也应该在1.5左右进行扩容。
负载因子都说明了什么?
1.哈希表的利用率:
越高利用率越高,但是接近满的时候会导致哈希冲突,降低查询、插、删的操作的效率。
2.什么时候该进行哈希扩容:
当负载因子达到0.75是传统上我们进行扩容的判断依据。
"负载因子”与“链地址法的哈希表”
负载因子在"链地址法"中的计算也一样,仍是实际元素的个数除以数组的长度。
容量最大为10的数组假如我们使用链地址法塞了30个元素。
λ=30/10=3
假如万分幸运,几乎平均分布在数组的各个索引位置,那么各个索引位置的查询、搜索、删除的效率是O(1+λ)
但这毕竟全靠运气,不是人为能控制它平均分布的,哈希值最终取模对应哪个索引谁都说不准,那么最好建议将λ控制在0.75~1.5
超过1.5时候,不要依赖运气,而应该进行重哈希,扩容我们的数组大小。
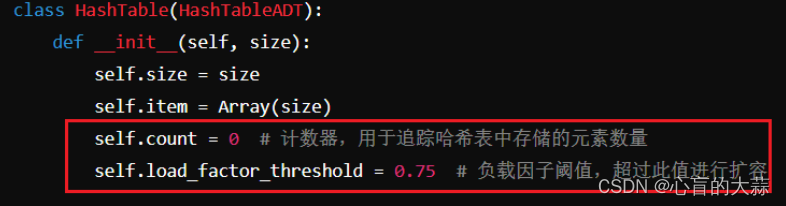
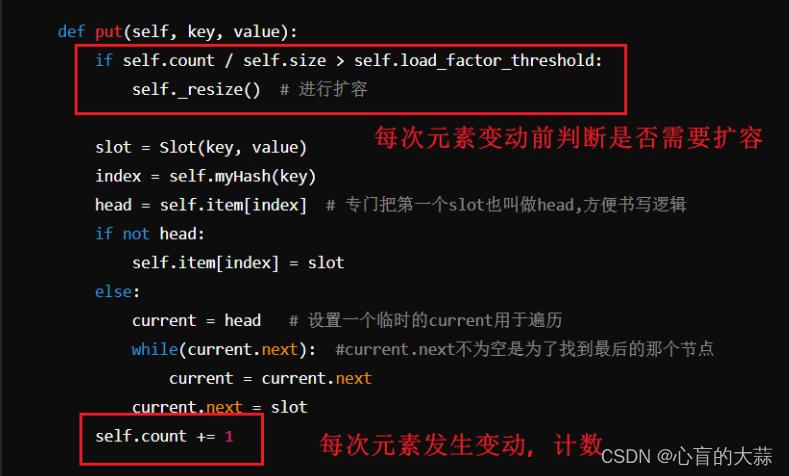
在代码里面监测负载因子的变化的思路:
在整个哈希表的属性中,增加count用于每次增加删除操作的计数。
load_factor=count/size
再在底层添加一个rehashing的方法:
def rehashing(self)
另外,对于每个put的操作里面,操作前先进行if判断,是否此次添加操作是否应该进行扩容















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









