







目录
3.URL(Uniform Resource Locator统一资源定位符)
一、HTTP协议原理
1.协议
什么是协议,网络协议的简称,网络协议是通信计算机双方必须遵从的一组约定,例如如何建立连接,怎么样互相识别文档。只有遵守了这个约定,计算机之间才能相互通信交流。
2.HTTP/HTTPS协议
| HTTP | HTTPS | |
| 端口 | 80 | 443 |
| 数据传输 | 明文传输 | 加密传输 |
| 真假网站识别 | 易被复制 | 有证书,难被复制 |
| 浏览器显示区别 | 浏览器显示问号,提示不安全 | 浏览器显示小锁,提示安全 |
| 门槛 | 无需证书 | 需要Gworg机构颁发证书,需要一定的成本 |
| 安全性 | 容易被劫持,跳转到其他网站 | 加密安全,很难被劫持,交易数据加密 |
如果大家对于两种协议感兴趣,可以查看这个这个文档
3.URL(Uniform Resource Locator统一资源定位符)
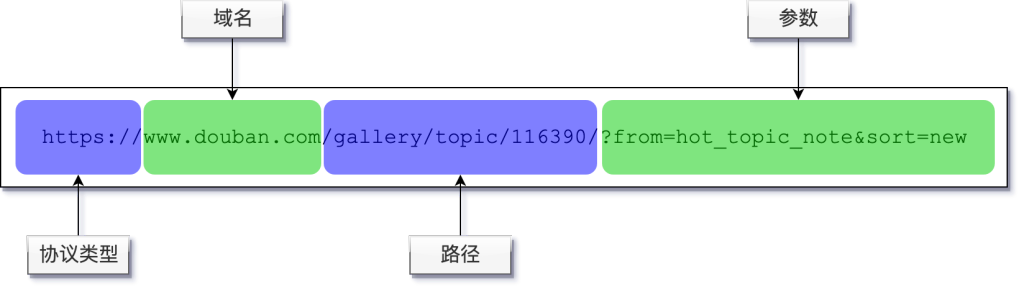
协议类型与域名之间以://分隔
路径以/开头,中间每层的分割也是/,路径相当于一层层的文件夹
路径和参数之间用?分隔,多个单数之间用&分割,参数用"参数名=参数值"的格式来表示
4.相对路径和默认路径
1.相对路径
gallery/topic/116390/?from=hot_topic_note&sort=new
注意,不是以斜杠/开头的路径,表示相对路径,如上面所示,这种相对路径非常容易出错
2.默认路径
我们在上网的时候,仅仅输入了https://www.douban.com或者https://www.douban.com都能打开豆瓣首页,并没有输入路径。实际上,没有输入路径,表示请求网站的默认页面,那么服务器就会返回一个默认的页面给浏览器,而默认页面是什么页面,是由服务器来决定,通常服务器默认的页面是首页。
二.简单的API调用
1.如何使用Java实现抓取网站内容
安装依赖库
首先安装一个Okhttp3,这是一个非常流行的HTTP库,可以简单快速的实现HTTP调用
安装Okhttp3的方式是在pom.xml文件中添加依赖:
<!-- https://mvnrepository.com/artifact/com.squareup.okhttp3/okhttp -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.1.0</version>
</dependency>示例爬取网站内容
package com.web.get;
import okhttp3.Call;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import java.io.IOException;
public class GetPage {
public String getContent(String url){
OkHttpClient okHttpClient = new OkHttpClient();
//定义一个请求配置url
Request request = new Request.Builder().url(url).build();
Call call = okHttpClient.newCall(request);
String result = null;
try {
result = call.execute().body().string();
} catch (Exception e) {
e.printStackTrace();
}
//返回结果
return result;
}
}2.什么是API
API (应用程序编程接口)

我们经常听到 API 这个专业名称。那么什么是 API 呢?
定义
API(Application Programming Interface,应用程序接口)是一些预先定义的函数,或指软件系统不同组成部分衔接的约定。目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问原码,或理解内部工作机制的细节。
在互联网时代,API 常常以 URL 的形式提供给开发者。URL 的 路径(英文称作path)部分就是函数,而函数的参数就等同于 URL 的参数(英文称作paramter或简称param)。
下图是 URL 格式参考图:

小结
我们常说的 API 有两种:
-
调用别的代码接口;
-
调用一个
URL(需要发HTTP请求)。
这两种都是 API ,在网络编程的场景下,API 经常指的是第二种。无论哪一种,简言之,都是触发一个功能,取得相应的结果。
案例
对于第二种,调用一个 URL 形式的 API ,最常见的场景是需要取得数据,API 把数据以某种格式进行包装后返回给调用者。
例如,我们常常在网站上看到天气信息
网站上调用天气的数据 API (会在 URL 参数中指定城市),取得天气数据后,显示在网站上。网站不需要知道天气数据是如何获取的(涉及到复杂的气象观测、气象数据运算),拿到数据后,可以灵活把天气信息显示在任意的位置,这是由网站自己决定的。
由此可见,API 只是提供纯粹的数据(7゜c),并不包含与展示相关的字体颜色、字体大小、位置等信息。而网站作为调用者,只需要关心如何展示更漂亮,而不需要关心具体的数据。
3.POST表单数据
Okhttp3库也支持POST操作,我们之前学的调用API属于GET操作,不同的是,POST操作数据不是放在URL中的,而是放在表单中提交的
所以程序的实现,需要构建一个FormBody表单对象,用于放置表单数据,核心代码如下
Builder builder = new FormBody.Builder();
// 设置数据,第一个参数是数据名,第二个参数是数据值
builder.add("", "");
FormBody formBody = builder.build();
Request request = new Request.Builder().url(url).post(formBody).build();示例:发送表单数据到gitee网站,完成登录
package com.web.post;
import okhttp3.Call;
import okhttp3.FormBody;
import okhttp3.FormBody.Builder;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import java.io.IOException;
import java.util.Map;
public class FormPost {
public String postContent(String url, Map<String,String> formData){
OkHttpClient okHttpClient = new OkHttpClient();
//post方式提交数据
Builder builder = new FormBody.Builder();
//放入表单数据
for (String key : formData.keySet()) {
builder.add(key,formData.get(key));
}
//构建FormBody对象
FormBody formBody = builder.build();
//指定Post方式提交formBody
Request request = new Request.Builder().url(url).post(formBody).build();
//使用client 去请求
Call call = okHttpClient.newCall(request);
//返回结果字符串
String result = null;
try {
result = call.execute().body().string();
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
}
package com.web.post;
import java.util.HashMap;
import java.util.Map;
public class Demo {
public static void main(String[] args) {
String url = "https://gitee.com/login";
FormPost formPost = new FormPost();
Map<String,String> formDate = new HashMap<>();
formDate.put("user[login]","1781125992");
String content = formPost.postContent(url,formDate);
System.out.println("API调用结果");
System.out.println(content);
}
}
运行结果提示失败,原因是gitee对密码做了特殊加密,所以失败,但是gitee已经收到了请求,只是判断登录没有成功而已
三.Request Response对象
1.Response-网页
上文我们学习了java中使用Okhttp3库请求网页或者调用API的知识,使用一条语句执行调用请求,并且返回字符串:
call.execute().body().string()
实际上,除了具体返回结果,我们还关心:http状态码
状态码是用一个数字直观反应了本次请求的状况,例如常见的200表示请求成功,404表示出错
为了获取状态码。可以使用语句
call.execute().code()
但是通常还要读取响应内容,但是又不能执行两次请求,所以代码应该优化为:
import okhttp3.Response;
//执行请求
Response rep = call.execute();
//获取响应状态码
int code = rep.code();
//获取响应内容
String content = rep.body().string();2.Response-非文本文件
实际上,okhttp3库不仅可以请求网页、API、也可以请求图片、excel等各种文件
3.Response-JSON
前面的学习中,我们会用okhttp3库获取请求返回的内容。无论是文本文件,还是二进制文件
以后我们还会遇到一种文本内容是JSON格式
参数对象 ==>JSON格式字符串 需要用到fastjson库
JSON格式数据==>Java对象 JSON.parseObject()
实战:请求JSON数据
package com.web.requestjson; import okhttp3.Call; import okhttp3.OkHttpClient; import okhttp3.Request; import okhttp3.Response; import java.io.IOException; public class ApiAsker { public String getContent(String url){ OkHttpClient okHttpClient = new OkHttpClient(); Request request = new Request.Builder().url(url).build(); Call call = okHttpClient.newCall(request); String result = null; Response response = null; try { response = call.execute(); result = response.body().string(); } catch (IOException e) { e.printStackTrace(); } return result; } }package com.web.requestjson; import com.alibaba.fastjson.JSON; import java.util.Map; public class Demo { public static void main(String[] args) { ApiAsker apiAsker = new ApiAsker(); String url = "http://ip-api.com/json/"; String content = apiAsker.getContent(url); Map contentObj = JSON.parseObject(content, Map.class); System.out.println(contentObj); } }打印结果:
{zip=, country=China, city=Pingdingshan, org=China Mobile, timezone=Asia/Shanghai, regionName=Henan, isp=China Mobile communications corporation, query=120.219.16.129, lon=113.3016, as=AS24445 Henan Mobile Communications Co.,Ltd, countryCode=CN, region=HA, lat=33.7347, status=success}
4.解析JSON对象
在开发过程中,我们经常会遇到多层嵌套结构的JSON数据
例如:
{
"code": 0,
"data": {
"ip": "117.89.35.58",
"country": "中国",
"area": "",
"region": "江苏",
"city": "南京",
"county": "XX",
"isp": "电信",
"country_id": "CN",
"area_id": "",
"region_id": "320000",
"city_id": "320100",
"county_id": "xx",
"isp_id": "100017"
}
}我们只需要多次的取出嵌套的Map对象即可:
Map contentObj = JSON.parseObject(content, Map.class);
Map dataObj = (Map)contentObj.get("data");
String city = (String)dataObj.get("city");由于Map可以存储任何对象,所以从Map中get()到对象必须指定其实际的类型:(Map)、(String)
四.Headers
1.User-Agent
我们学了Okhttp3库请求网页,API,也会解析JSON格式的文本
但是不一定任何请求都能够成功,这是因为像某宝这样的大型网站,处于安全等各种因素的考虑,会对请求进行比较严格的校验,其中一个重要的校验,是判断请求是否真的来自一个真实的浏览器而不是Java程序、API服务器
判断请求是否真的来自一个真实的浏览器,需要从HTTP消息头(Headers)中取得User-Agent信息后,才能判断
HTTP header
HTTP消息头Headers是HTTP协议的一项重要内容,作用是在发起请求的时候,除了请求参数外,可以附加更多的信息,只要记住,Headers信息并不是写在URL中的,属于隐藏的数据,不能直观看到
User-Agent
User-Agent是存放在Headers中的一种数据信息,作用是在指定URL发送请求的时候,告诉服务端当前用户的浏览器类型,版本,甚至操作系统、CPU等非隐私的技术信息
服务器从Headers中的User-Agent信息获取到浏览器类型、版本等数据后,就认为是一个浏览器请求的环境了,就会给出响应
所以,我们只要在程序代码中,附加上User-Agent信息,就能允许成功了。当然,这里的User-Agent是模拟的。
模拟win7+chrome环境,User-Agent的写法如下:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1
Okhttp3库支持Headers只需要在构建Request对象的时候,调用addHeader()方法即可:
Request request = new Request.Builder().url(ur;).addHeader("User-Agent","").build();
2.Referer
以上学了设置User-Agent解决程序请求HTTP不成功的情况,是类似于模拟一个浏览器环境去请求
有时候我们看到图片无法正常显示,这个是因为图片做了防盗链
防盗链
因为浏览器在请求网页中的图片(或者其他任何文件)时,会自动在HTTP消息头Headers中,加一个Referer信息,表示请求的来源(或者可以理解为图片的上级是网页)。
浏览器自动添加Referer是业界规范
即浏览器自动告诉图片服务器,从当前网址请求此图片,这是图片服务器拒绝了访问,因为服务器的规则是不允许其他网站访问图片。
为什么直接贴网址可以访问?
因为直接拷贝网址,黏贴到浏览器地址栏,就没有了来源了,此时不是网页中加载图片,而是浏览器直接加载图片,图片没有上级。浏览器只是收集了一些信息提交到服务器,并不能决定是否能看到图片
程序中的Referer
为了模拟浏览器自动加Referer信息的行为,可以调用语句
Request request = new Request.Builder()
.url(url)
.addHeader("Referer", "")
.build();但是仍然是报错
解决方案是:需要把Referer信息设置为图片原始使用的网站
3.Host
Host也是Headers中非常重要的信息之一。
Host表示当前请求的域名,虽然这个域名已经存在于URL中,但是遇到复杂的场景,例如使用代理服务器,或者URL中不写域名而是写IP地址进行请求等,设置Host就非常有用了
五.下载文件、图片
1.下载文件
写入文本文件
package com.web.filewrite;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
//创建文件对象
File file = new File("7.26.txt");
String content = "7月完成任务,八月继续加油";
{
try {
FileWriter fileWriter = new FileWriter(file.getName());
//写入内容
fileWriter.write(content);
//关闭写入操作
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}写入二进制文件
package com.web.filewrite;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
public class Demo1 {
public static void main(String[] args) {
// 文件对象
File file = new File("china-city-list.xlsx");
// 写文件
FileOutputStream fos = null;
try {
fos = new FileOutputStream(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
//data是字节数组
fos.write(data);
// 必须刷新并关闭
fos.flush();
fos.close();
}
}
2.下载图片
下载图片与下载其他文件别无二致。图片都是二进制文件,直接用一个字节数组接受即可
package com.web.get;
public class Demo {
public static void main(String[] args) {
GetPage getPage = new GetPage();
byte[]content= getPage.getContent("https://img1.baidu.com/it/u=2020082651,1869885258&fm=253&fmt=auto&app=138&f=JPEG?w=519&h=500");
System.out.println(content.length);
}
}package com.web.get;
import okhttp3.Call;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import java.io.IOException;
public class GetPage {
public byte[] getContent(String url){
//实例出okhttp3库对象,可以快速实现http调用
OkHttpClient okHttpClient = new OkHttpClient();
//定义一个请求配置url
Request request = new Request.Builder().url(url).build();
//使用client去请求
Call call = okHttpClient.newCall(request);
//返回结果字符串
byte[] result = null;
try {
result = call.execute().body().bytes();
} catch (Exception e) {
e.printStackTrace();
}
//返回结果
return result;
}
}
3.解析Excel
Java很强大,已经有库可以操作excel文件了
easyexcel是阿里巴巴出品的快速,简单操作excel文件的库。使用前必须在pom.xml文件中加入
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.1</version>
</dependency>调用库
excel文件是多sheet模式的,每个sheet实际上是一个表格,表格又分为行和列
所以解析Excel的路径是:sheet -->row-->column
计算机中,第一个单元格的位置是0,第一个sheet、row、column的位置都是0
import com.alibaba.excel.EasyExcel;
import java.util.Map;
import java.util.List;
// 读取第一个sheet
List<Map<Integer, String>> sheetDatas = EasyExcel.read("xzq_201907.xlsx").sheet(0).doReadSync();
// List 中每个元素表示一行
for (Map<Integer, String> rowData : sheetDatas) {
// Map 中用序号指代每一列
for (Integer index : rowData.keySet()) {
// 列值
String columnValue = rowData.get(index); //根据列号遍历列值
}
}六.cookie & session
1.cookie
所谓cookie就是存在客户端浏览器的一段文本内容。以key=value的格式存储一条数据;多条数据之间用分号分开,cookie的核心功能是存储登录数据额外可以存储一些小数据。
2.session
未更新,敬请期待~~~















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









