






一,简单介绍
数据的预处理过程,除了包括数据抽取、数据本身的清洗与检验以及数据转换操作,还包括数据加载操作,数据加载是数据预处理过程的最后一个步骤,主要是负责将清洗检验、转换后的高质量数据加载到目标数据库中。
数据的加载机制与数据的抽取机制相类似,数据的加载机制可以分为全量加载和增量加载。其中,全量加载是指将目标数据表中的数据全部删除后,进行数据加载的操作;而增量加载是指目标表只加载源数据表中变化的数据,其中变化的数据包含新增、修改和删除的数据。
二,全量加载
案例介绍:从技术角度来说,全量加载比增量加载的操作要简单很多,即只需要在数据加载之前,将目标数据表进行清空,再将源数据表中的数据全部加载到目标表中。 通过Kettle工具将数据表full_source中的数据全量加载到数据表full_target中。
1.数据预处理准备
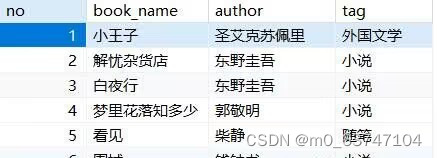
full_source表
create table `full_source` (
`no` int (10),
`book_name` varchar (60),
`author` varchar (30),
`tag` varchar (60)
);
insert into `full_source` (`no`, `book_name`, `author`, `tag`) values('1','小王子','圣艾克苏佩里','外国文学');
insert into `full_source` (`no`, `book_name`, `author`, `tag`) values('2','解忧杂货店','东野圭吾','小说');
insert into `full_source` (`no`, `book_name`, `author`, `tag`) values('3','白夜行','东野圭吾','小说');
insert into `full_source` (`no`, `book_name`, `author`, `tag`) values('4','梦里花落知多少','郭敬明','小说');
insert into `full_source` (`no`, `book_name`, `author`, `tag`) values('5','看见','柴静','随笔');
insert into `full_source` (`no`, `book_name`, `author`, `tag`) values('6','围城','钱钟书','小说');full_target表
create table `full_target` (
`no` int (10),
`book_name` varchar (60),
`author` varchar (30),
`tag` varchar (60)
);
insert into `full_target` (`no`, `book_name`, `author`, `tag`) values('1','小王子','圣艾克苏佩里','外国文学');
insert into `full_target` (`no`, `book_name`, `author`, `tag`) values('2','解忧杂货店','东野圭吾','小说');
insert into `full_target` (`no`, `book_name`, `author`, `tag`) values('5','看见','柴静','随笔');2.建立转换并添加控件
3.配置控件
执行AQL脚本控件
双击“执行SQL脚本”控件,进入“执行SQL语句”界面,具体如图所示。

表输入控件

保存运行

三,增量加载
增量加载是指目标表仅加载源数据表中新增和发生变化的数据。优秀的增量加载机制不但能够将业务系统中的变化数据按一定的频率准确地捕获到并加载到目标表中,同时还不会对业务系统造成太大的压力,也不会影响现有业务。
案例:通过Kettle工具将数据表incremental_source中的数据增量加载到数据表incremental_target中
数据准备
incremental_source表
create table `incremental_source` (
`id` int (20),
`name` varchar (60),
`age` int (20),
`create_time` datetime
);
insert into `incremental_source` (`id`, `name`, `age`, `create_time`) values('1','Isabella','18','2019-08-20 13:14:20');
insert into `incremental_source` (`id`, `name`, `age`, `create_time`) values('2','Jack','20','2019-08-21 13:14:21');
insert into `incremental_source` (`id`, `name`, `age`, `create_time`) values('3','Nicholas','22','2019-08-20 13:14:22');
insert into `incremental_source` (`id`, `name`, `age`, `create_time`) values('4','Jasmine','19','2019-08-20 13:14:23');
insert into `incremental_source` (`id`, `name`, `age`, `create_time`) values('5','Mia','20','2019-08-20 13:14:24');
insert into `incremental_source` (`id`, `name`, `age`, `create_time`) values('6','Jone','25','2018-08-20 13:14:24');
insert into `incremental_source` (`id`, `name`, `age`, `create_time`) values('7','张华','30','2019-08-20 13:14:24');incremental_target表
create table `incremental_target` (
`id` int (20),
`name` varchar (60),
`age` int (20),
`create_time` datetime
);
insert into `incremental_target` (`id`, `name`, `age`, `create_time`) values('1','Isabella','18','2019-08-20 13:14:20');
insert into `incremental_target` (`id`, `name`, `age`, `create_time`) values('2','Jack','20','2019-08-21 13:14:21');
insert into `incremental_target` (`id`, `name`, `age`, `create_time`) values('3','Nicholas','22','2019-08-20 13:14:22');
insert into `incremental_target` (`id`, `name`, `age`, `create_time`) values('4','Jasmine','19','2019-08-20 13:14:23');
insert into `incremental_target` (`id`, `name`, `age`, `create_time`) values('5','Mia','20','2019-08-20 13:14:24');2.建立转换并添加控件

3.配置控件
表输入控件
在SQL框中编写查询数据表incremental_source的SQL语句,然后单击【预览】按钮,查看数据表incremental_source的数据是否成功从MySQL数据库中抽取到表输入流中,具体如图所示。


插入/更新控件
双击进入控件,单击目标表处的【浏览】按钮,弹出“数据库浏览器”窗口,选择目标表incremental_target,具体如图所示。

单击【获取字段】按钮,用来指定查询数据所需要的关键字,这里通过比较数据表incremental_target的字段id与输入流里的字段id是否一致为关键条件,更新数据表中的其它字段数据;单击【获取和更新字段】按钮,用来指定需要更新的字段,具体如图所示。

4.保存运行


四,数据的批量加载
通常情况下,对于几千条甚至几十万条记录的数据迁移而言,采取DML(即数据操纵语言)的INSERT语句能够很好地将数据迁移到目标数据库中。然而,当数据迁移量过于庞大时,就不能使用INSERT语句,因为执行INSERT、UPDATE以及DELETE语句的操作都会生成事物日志,事物日志的生成会减慢加载的速度,故需要针对数据采取批量加载操作。
1.数据准备
建立weibo_usr表
create table `weibo_user` (
`user_id` int (20),
`user_name` varchar (60),
`gender` varchar (30),
`message` varchar (3000),
`post_num` int (20),
`follower_num` int (20)
); 2.建立转换并添加控件

3.配置控件
csv文件输入控件
双击进入csv文件输入配置界面,在“文件名”处单击【浏览】按钮,选择要抽取的CSV文件weibo_user.csv;单击【获取字段】按钮,让Kettle自动检索CSV文件,并对文件中字段的类型、格式、长度、精度等属性进行解析,具体如图所示。


表输出控件
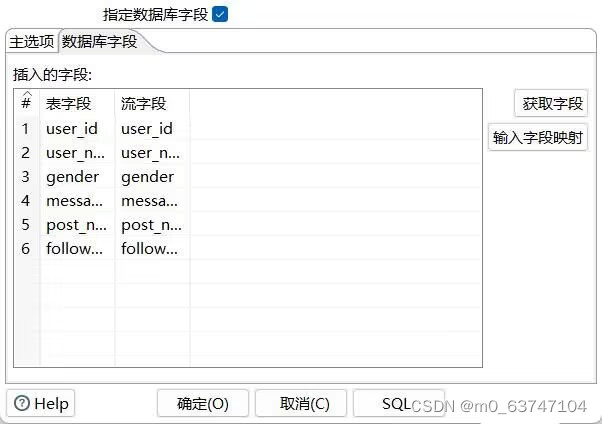
双击进入控件,单击目标表右侧的【浏览】按钮,选择输出的目标表,即数据表weibo_user(该表需提前创建,且表结构需根据文件weibo_user.csv中数据的字段和数据类型进行创建,这里不作演示);勾选“指定数据库字段”的复选框,用于将weibo_user数据表的字段与weibo_user.csv文件中的字段进行匹配;勾选“使用批量插入”的复选框,用于批量加载数据至目标表中,如图所示。
4.保存运行

















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









