







【C++第十章】学习String
STL介绍🧐
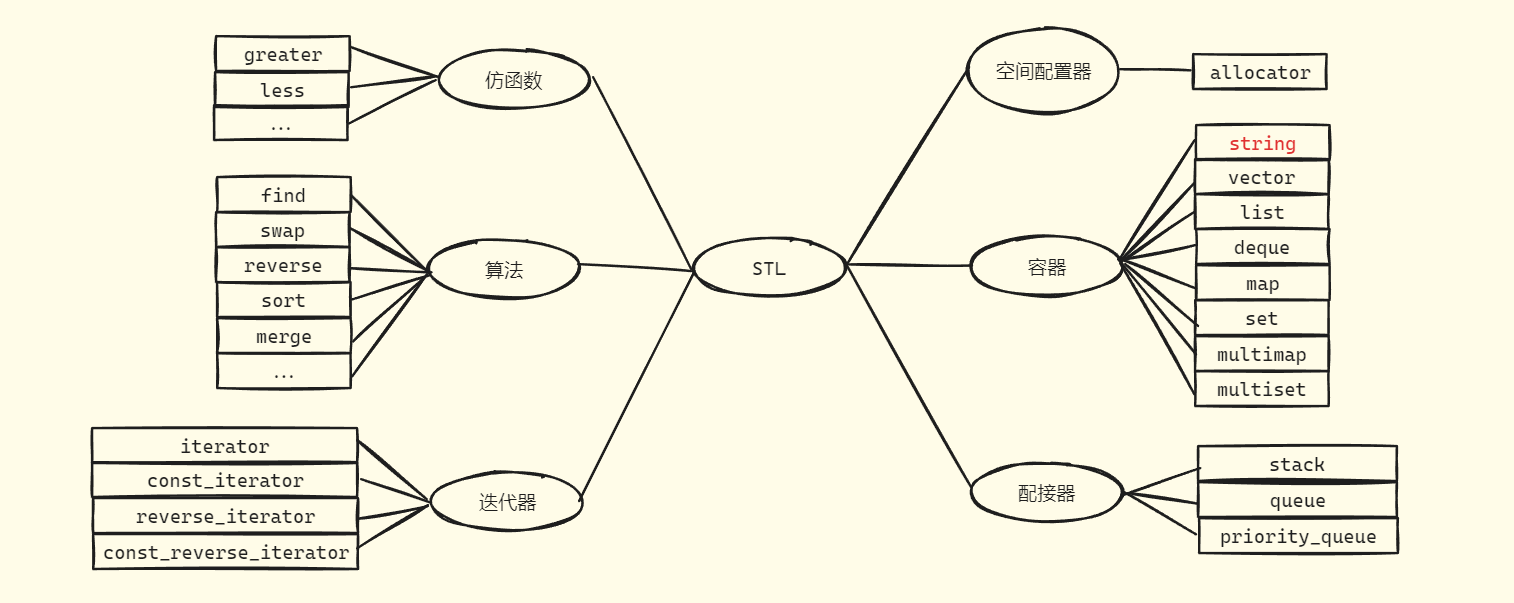
学习string之前,我们要先了解一下STL库,STL是C++标准库的重要组成部分,不仅是一个可复用的组件库,也是一个包罗数据结构与算法的软件框架。STL有四个版本——原始版本、P.J.版本、RW版本、SGI版本,本文所学习的是SGI版本的STL。
STL六大组件,分别为仿函数、算法、迭代器、空间配置器、容器、配接器,我们所学的string便是容器中的一种(不过严格来说string出现时间早于STL库,属于C++标准库)。
认识String🧐
string也是属于模板的一种,只不过被重命名了,那为什么要写成模板呢?这要从早期的编码说起。
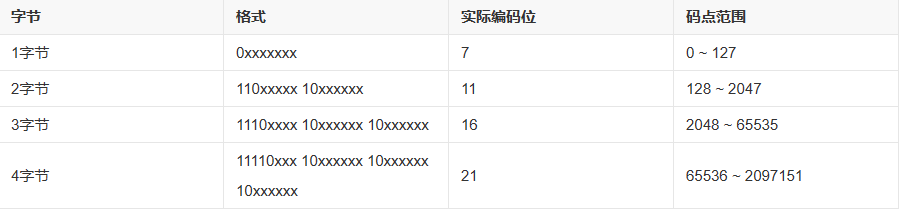
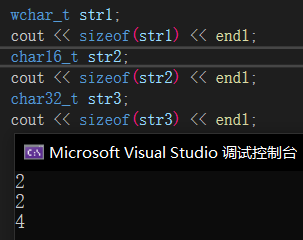
由于早期的ASCII码不能很好解决各国语言存在的差异化,随后出现了Unicode(万国码)用于解决传统字符编码的局限性,并且万国码兼容ASCII码,以0开头的就是ASCII码,而常见的汉字基本为两个字节。Unicode是字符集,而Unicode中的UTF-8、UTF-16、UTF-32才是字符编码规则,我们用UTF-8就足够了,而其他语言可能要用UTF-16、UTF-32才能存下该字符。
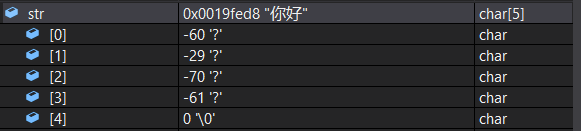
我们测试发现,前两个字节组成“你”,后两个字节组成“好”,在Windows下一般使用GBK编码,兼容更多的汉字,Linux下用UTF-8。
并且,在早期还出现过wchar_t宽字节去存储字符,后面为了规范还出了char16和char32去兼容UTF-16和UTF-32,它们所占用字节也不同。而我们发现输入一些生僻字时打印出来会变成乱码,这是因为计算机找不到对应的编码规则,比如编译器中仅存了ASCII的编码规则,我们输入中文进去自然无法识别。
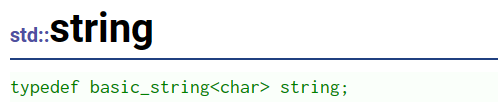
所以string写成模板是为了去兼容各种字符类型,不管是传char16和char32都可以接收。
基本使用🧐
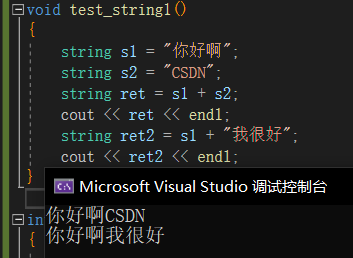
在C语言中,我们创建字符串没办法按需申请和释放,但在C++中string支持各种运算符重载,如下代码,字符串能够自动扩容,自动追加,为我们节省了不少时间。
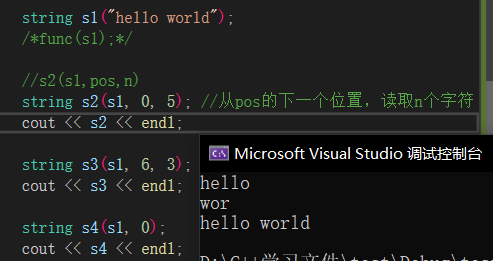
string初始化的方式有很多种,可以从pos位置,读取n个字符,如果不给n就在pos后全部读取,我们也可以用迭代器(后面有介绍迭代器)进行初始化。
并且,string可读可写,可以用下标的方式去访问字符串,非常便利。
注意:当我们使用字符串传参时,最好使用引用传参,传值传参会调用拷贝构造,会进行深拷贝,效率低于引用传参。当我们使用const接收string时,会调用const版本的string和迭代器。
迭代器🧐
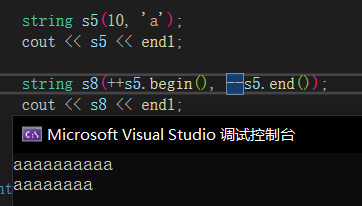
迭代器就像是指针一样的东西,能够对容器内的数据进行遍历,我们创建一个迭代器的方法如下,begin是字符串开始的位置,end是字符串结束的位置,end会在\0结束,但是不会算上\0。
迭代器遍历时最好用“!=”来做结束条件,因为it和end都是地址,在连续的地址中还可以使用大于小于来判断,但在非连续的地址中就会失效,所以用“!=”是最好的。
链表也可以用迭代器遍历,这也体现了C++封装的好处,底层代码不一样,但我们使用方式一样,省去了造轮子的时间。
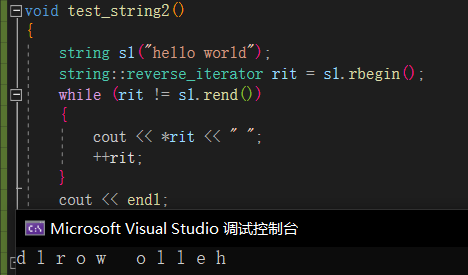
迭代器又分正向和反向,反向迭代器的++就是倒着走的。
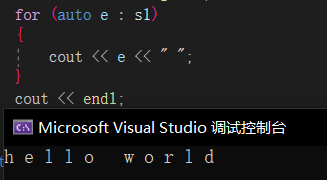
auto可以简化代码,自动推出类型,创建迭代器时就不用写那么多了。并且,范围for原理就是编译器替换成了迭代器,但范围for不支持反向迭代。

string常用函数🧐
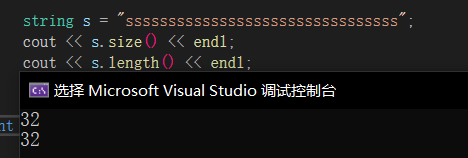
size和length🔎
size和length都是计算字符串大小且不包含\0的函数,由于string早于STL,在STL出来后length的函数名对于其它容器不太规范(函数名意思表达不准确),所以STL中又搞了个size来表示容器大小,具有通用性,而length仅string有。
PS:之所以C++还包含\0,是因为很多接口是C语言实现的,C++调用C接口要传字符串参数时还要用上c_str(),将其转为C语言标准的字符串,并且C语言中字符串以\0为结束标识,如果C++没有那传过去就找不到结束位置了,所以需要C++去兼容C。
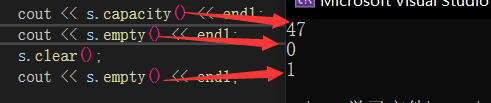
capacity、empty和clear🔎
capacity是当前字符串的容量,empty为判空,空为1,非空为0,clear清除当前数据,但不清除所开的空间,方便之后再次使用。vs下每次扩容大约扩capacity的1.5倍,g++下扩2倍。
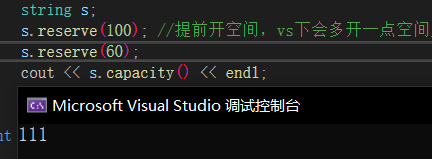
reserve🔎
reserve可以提前开空间,在知道要开多少空间的情况下,减少扩容次数,提高效率,但不能进行初始化,一般情况下reserve不能将空间缩小。
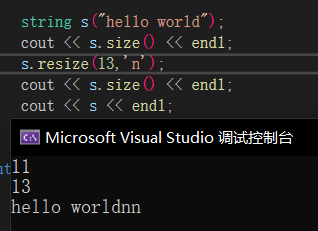
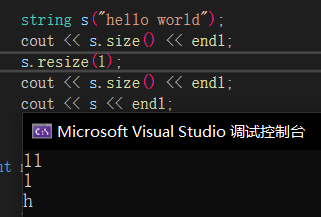
resize🔎
resize用于改变字符串长度,当resize大于原字符长度时,给值就插入数据,不给值就添加\0,如果resize大于capacity则会自动扩容,小于size就会删除多余字符,我们一般用于开空间+初始化。
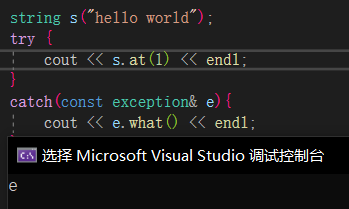
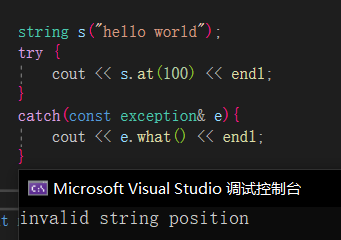
at🔎
at功能与方括号一样,但方括号是断言报错,at是抛异常
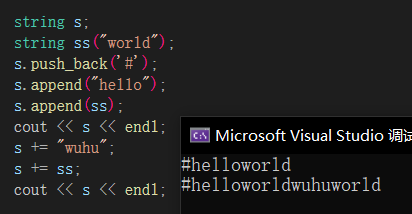
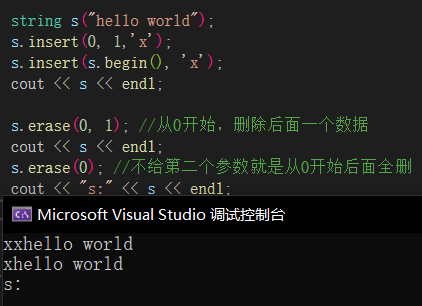
push_back、append、insert和erase🔎
由于string给了很多函数重载,我们在这就写几个比较常用的,append和push_back都属于尾插,也可以使用“+=”的方式进行尾插,insert和erase是在pos位置插入和删除,但会挪动数据,效率不高。
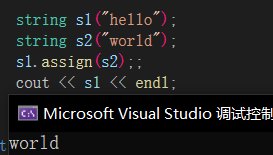
assign🔎
将一个已有的字符串赋值给另一个,如果另一个已经有数据了,就会进行覆盖
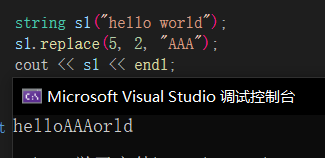
replace🔎
replace可以替换字符串中的内容,这里是将pos为5的后两个字符替换成AAA,也会挪动数据
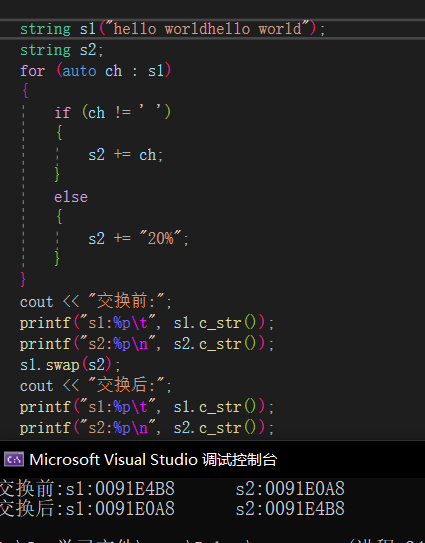
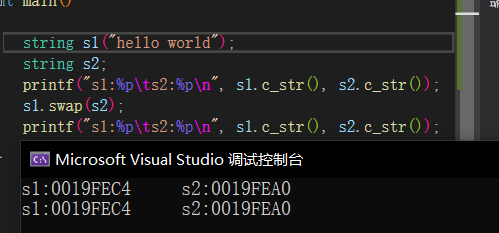
swap🔎
string的swap与标准库的swap不同,它会交换指针指向,减少了拷贝代价,但是我们直接使用swap交换两个字符串时,编译器可以识别到参数类型,调用全局的std::swap(string)函数,所以当我们传入string类型时,不会调用到普通的swap函数。
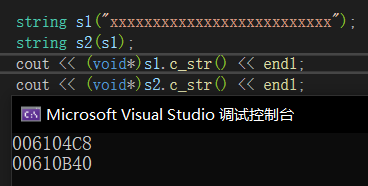
注:在vs下string的存储方式不一样,内部结构为,先有一个联合体,联合体用来定义string中字符串的存储空间,当字符串小于16时,使用内部固定的字符数组来存放,当字符串大于16时,才会从堆上开辟空间,这样设计是认为大多数情况16个字符长度够用了,所以直接为我们创建一个固定的数组空间,不用再去堆上开辟,提高效率。所以当字符串长度小于16时,不会交换地址,而是直接进行值的交换。
find、substr🔎
参考以下代码,find默认从0开始找,找到后返回下标,没找到返回npos,rfind从末尾开始找,substr从pos位置开始取子串,没限定取多少个就是全部取。
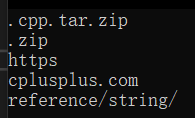
void test_string11() { string s1("test.cpp.tar.zip"); int i = s1.find("."); //找到第一次出现.的下标 string s2 = s1.substr(i); //取到该下标的后面的所有字符 cout << s2 << endl; string s3("test.cpp.tar.zip"); int j = s3.rfind("."); //倒着找 string s4 = s3.substr(j); cout << s4 << endl; //查找域名 资源名 string s5("https://cplusplus.com/reference/string/"); string sub1, sub2, sub3; int a = s5.find(':'); if (a != string::npos) //没找到就会返回npos sub1 = s5.substr(0, a); //取0-a之间的子串 else cout << "没有找到a" << endl; int b = s5.find("/", a + 3); if (b != string::npos) sub2 = s5.substr(a + 3, b - (a + 3)); else cout << "没有找到b" << endl; sub3 = s5.substr(b+1); cout << sub1 << endl; cout << sub2 << endl; cout << sub3 << endl; }
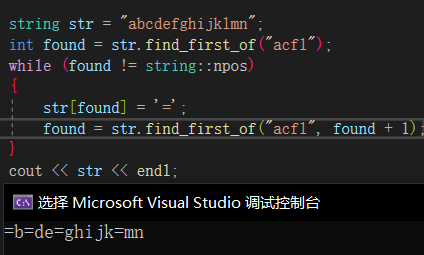
find_first_of、find_first_not_of🔎
find_first_of找出所有参数中字符的下标,find_last_of就是倒着找,第二个参数为在pos位置后开始寻找,下图中找到字符串中’a’、‘c’、‘f’、'l’字符的下标,并全部修改为“=”。
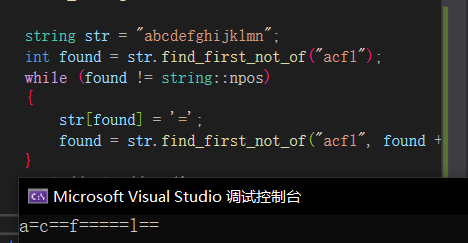
find_first_not_of找出非参数字符的下标。

写实拷贝、引用计数(了解)🧐
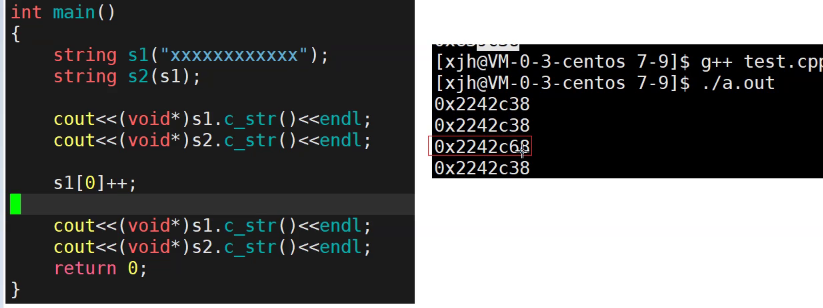
由于存在深浅拷贝,在涉及开辟空间问题上都会自己写一个拷贝构造进行深拷贝,但这时所有的拷贝都会调用拷贝构造,而深拷贝影响效率,所以我们可以用写时拷贝和引用计数的方式来进行优化。
浅拷贝的问题在于修改和析构,所以用引用计数记录有几个对象指向这个空间,在拷贝时++引用计数,析构时–引用计数,当我们要修改一个引用计数不为1的数据时,才进行深拷贝,当引用计数减到0时才能进行析构,用这种方式可以减少不必要的深拷贝。
g++下用的写时拷贝,谁修改谁去做深拷贝,而vs下直接深拷贝。
结尾👍
以上便是string的全部介绍,如果有疑问或者建议都可以私信笔者交流,大家互相学习,互相进步!🌹
















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











