






 本文详细介绍了正则表达式的逻辑运算符、预定义字符、数量词以及在数据爬取中的使用技巧,包括贪婪匹配与非贪婪匹配,split方法和replaceAll方法的应用,以及分组括号和非捕获分组的用法。
本文详细介绍了正则表达式的逻辑运算符、预定义字符、数量词以及在数据爬取中的使用技巧,包括贪婪匹配与非贪婪匹配,split方法和replaceAll方法的应用,以及分组括号和非捕获分组的用法。
正则表达式就是用来验证各种字符串的规则。它内部描述了一些规则,我们可以验证用户输入的字符串是否匹配这个规则。

一、逻辑运算符
&&:并且(交集)
| :或者
\ :转义字符 : 改变后面那个字符原本的含义
例:打印双引号"
System.out.println("\"");二、预定义字符
1. "." : 匹配任何字符。
2. "\d":任何数字[0-9]的简写;
3. "\D":任何非数字\[^0-9\]的简写;
4. "\s": 空白字符:[ \t\n\x0B\f\r] 的简写
5. "\S": 非空白字符:\[^\s\] 的简写
6. "\w":单词字符:[a-zA-Z_0-9]的简写
7. "\W":非单词字符:\[^\w\]
简单来记:两个\表示一个\
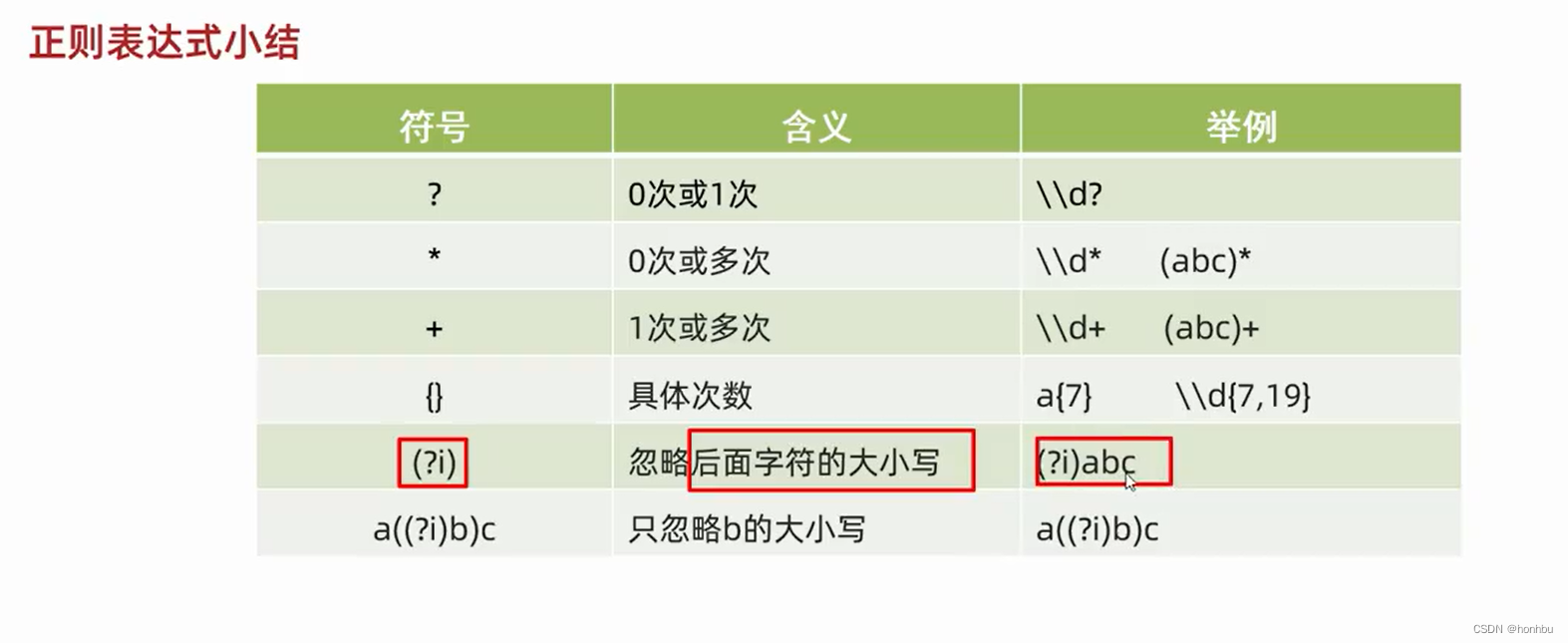
三、数量词
1. X? : 0次或1次
2. X* : 0次到多次
3. X+ : 1次或多次
4. X{n} : 恰好n次
5. X{n,} : 至少n次
6. X{n,m}: n到m次(n和m都是包含的)
对于"((?i)Java)(?=8|11|17)","((?i)Java)(?:8|11|17)","((?i)Java)(?!8|11|17)"来说, ?理解为前面的数据;?!表示大小写都可;=表示在Java后面要跟随的数据,但是在获取的时候,只获取前半部分;?:表示需要这些数据;?!表示不需要这些数据
编写正则的小心得:
第一步:按照正确的数据进行拆分
第二步:找每一部分的规律,并编写正则表达式
第三步:把每一部分的正则拼接在一起,就是最终的结果
书写的时候:从左到右去书写。
本地数据爬取
Pattern:表示正则表达式
Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。
在大串中去找符合匹配规则的子串。
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//1.获取正则表达式的对象
String regex ="Java\\d{0,2}"
Pattern p = Pattern.compile(regex);
//2.获取文本匹配器的对象
//拿着m去读取str,找符合p规则的子串
Matcher m = p.matcher(str);
//3.利用循环获取
while (m.find()) {
String s = m.group();
System.out.println(s);
}网络数据爬取:
//创建一个URL对象
URL url = new URL("https://m.sengzan.com/jiaoyu/29104.html?ivk sa=1025883i");
//连接上这个网址
//细节:保证网络是畅通
URLConnection conn = url.openConnection();//创建一个对象去读取网络中的数据
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
//获取正则表达式的对象pattern
String regex = "[1-9]\\d{17}";
Pattern pattern = Pattern.compile(regex);//在读取的时候每次读一整行
while ((line = br.readLine()) != null) {
//拿着文本匹配器的对象matcher按照pattern的规则去读取当前的这一行信息
Matcher matcher = pattern.matcher(line);
while (matcher.find()) {
System.out.println(matcher.group());
}
}
br.close();
}贪婪爬取和非贪婪爬取:
只写+和表示贪婪匹配,如果在+和后面加问号表示非贪婪爬取
+? 非贪婪匹配
*? 非贪婪匹配
贪婪爬取:在爬取数据的时候尽可能的多获取数据
非贪婪爬取:在爬取数据的时候尽可能的少获取数据
split方法
public String[] split(String regex)
//参数regex表示正则表达式。可以将当前字符串中匹配regex正则表达式的符号作为"分隔符"来切割字符串。
String[] arr = s.split("[\\w&&[^_]]+");
replaceAll方法
public String replaceAll(String regex,String newStr)
//参数regex表示一个正则表达式。可以将当前字符串中匹配regex正则表达式的字符串替换为newStr。
String result1 = s.replaceAll("[\\w&&[^_]]+", "vs");
分组括号( ):
细节:如何识别组号?
只看左括号,不看有括号,按照左括号的顺序,从左往右,依次为第一组,第二组,第三组等等

\\组号:表示把第X组的内容再出来用一次
例:String regex1 = “(.).+\\1"; a123a
* 表示0次或多次
例:"((.)\\2*).+\\1" aaa132131aaa
捕获分组
后续还要继续使用本组的数据。
正则内部使用: \\组号
正则外部使用: $组号
String result = str.replaceAll("(.)\\1+", "$1");
非捕获分组:
分组之后不需要再用本组数据,仅仅是把数据括起来。
不占用组号
更多使用?:
| 符号 | 含义 | 举例 |
| (?:正则) | 获取所以 | Java(?:8|11|17) |
| (?=正则) | 获取前面部分 | Java(?=8|11|17) |
| (?!正则) | 获取不是指定内容的签名部分 | Java(?!8|11|17) |
小节:



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









