






一、数组和集合的区别
相同点
- 都是容器,可以存储多个数据
不同点
- 数组的长度是不可变的,集合的长度是可变的
- 数组可以存基本数据类型和引用数据类型
- 集合只能存引用数据类型,如果要存基本数据类型,需要存对应的包装类
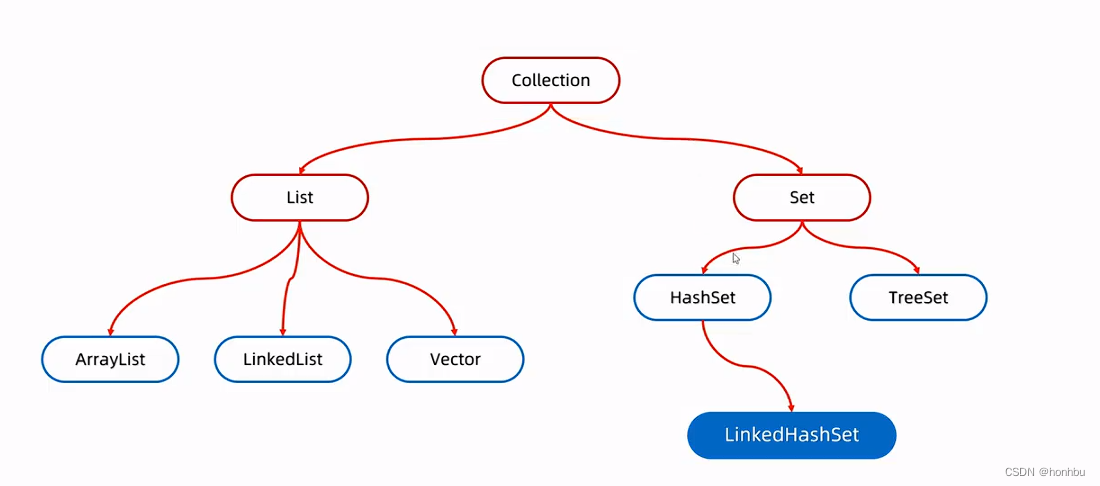
二、集合类体系结构
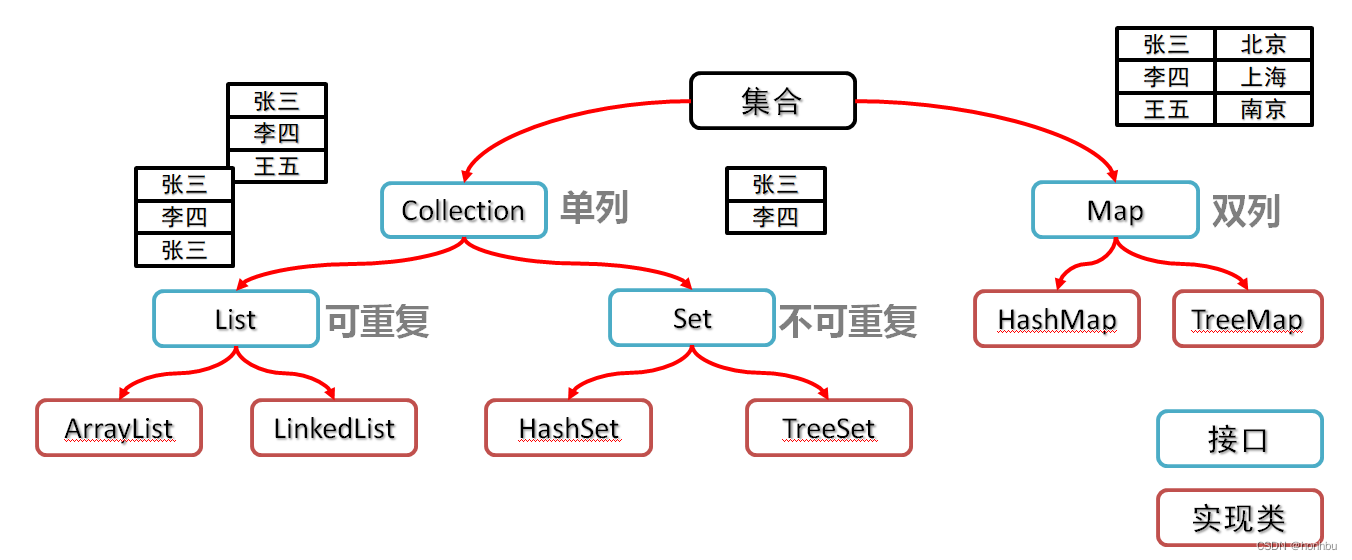
三、Collection 集合
1.Collection集合概述
-
是单例集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素
-
JDK 不提供此接口的任何直接实现.它提供更具体的子接口(如Set和List)实现
2.创建Collection集合的对象
-
多态的方式
-
具体的实现类ArrayLis
Collection<String> c = new ArrayList<>();
3.常用方法
| 方法名 | 说明 |
|---|---|
| boolean add(E e) | 添加元素 |
| boolean remove(Object o) | 从集合中移除指定的元素 |
| boolean removeIf(Object o) | 根据条件进行移除 |
| void clear() | 清空集合中的元素 |
| boolean contains(Object o) | 判断集合中是否存在指定的元素 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中元素的个数 |
4.Collection集合的遍历
1 迭代器遍历
-
迭代器介绍
-
迭代器,集合的专用遍历方式
-
Iterator<E> iterator(): 返回此集合中元素的迭代器,通过集合对象的iterator()方法得到
-
-
Iterator中的常用方法
boolean hasNext(): 判断当前位置是否有元素可以被取出 E next(): 获取当前位置的元素,将迭代器对象移向下一个索引位置
-
Collection集合的遍历
public class IteratorDemo1 {
public static void main(String[] args) {
//创建集合对象
Collection<String> c = new ArrayList<>();
//添加元素
c.add("hello");
c.add("world");
c.add("java");
c.add("javaee");
//Iterator<E> iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到
Iterator<String> it = c.iterator();
//用while循环改进元素的判断和获取
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
}
}- 迭代器中删除的方法
void remove(): 删除迭代器对象当前指向的元素
2 增强for
快捷键:list.for
-
介绍
-
它是JDK5之后出现的,其内部原理是一个Iterator迭代器
-
实现Iterable接口的类才可以使用迭代器和增强for
-
简化数组和Collection集合的遍历
-
-
格式
for(集合/数组中元素的数据类型 变量名 : 集合/数组名) {
// 已经将当前遍历到的元素封装到变量中了,直接使用变量即可
}
代码
public class MyCollectonDemo1 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
list.add("f");
//1,数据类型一定是集合或者数组中元素的类型
//2,str仅仅是一个变量名而已,在循环的过程中,依次表示集合或者数组中的每一个元素
//3,list就是要遍历的集合或者数组
for(String str : list){
System.out.println(str);
}
}
}细节点注意:
- 1.报错NoSuchElementException
- 2.迭代器遍历完毕,指针不会复位
- 3.循环中只能用一次next方法
- 4.迭代器遍历时,不能用集合的方法进行增加或者删除
3 lambda表达式
利用forEach方法,再结合lambda表达式的方式进行遍历
public class A07_CollectionDemo7 {
public static void main(String[] args) {
/*
lambda表达式遍历:
default void forEach(Consumer<? super T> action):
*/
//1.创建集合并添加元素
Collection<String> coll = new ArrayList<>();
coll.add("zhangsan");
coll.add("lisi");
coll.add("wangwu");
//2.利用匿名内部类的形式
//底层原理:
//其实也会自己遍历集合,依次得到每一个元素
//把得到的每一个元素,传递给下面的accept方法
//s依次表示集合中的每一个数据
/* coll.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});*/
//lambda表达式
coll.forEach(s -> System.out.println(s));
}
}四、List集合
1List集合的概述和特点
-
List集合的概述
-
有序集合,这里的有序指的是存取顺序
-
用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素
-
与Set集合不同,列表通常允许重复的元素
-
-
List集合的特点
-
存取有序
-
可以重复
-
有索引
-
2.List集合的特有方法
| 方法名 | 描述 |
|---|---|
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
3.List集合的五种遍历方式
-
迭代器
-
列表迭代器
-
增强for
-
Lambda表达式
-
普通for循环
//创建集合并添加元素
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
//1.迭代器
Iterator<String> it = list.iterator();
while(it.hasNext()){
String str = it.next();
System.out.println(str);
}
//2.增强for
//下面的变量s,其实就是一个第三方的变量而已。
//在循环的过程中,依次表示集合中的每一个元素
for (String s : list) {
System.out.println(s);
}
//3.Lambda表达式
//forEach方法的底层其实就是一个循环遍历,依次得到集合中的每一个元素
//并把每一个元素传递给下面的accept方法
//accept方法的形参s,依次表示集合中的每一个元素
list.forEach(s->System.out.println(s) );
//4.普通for循环
//size方法跟get方法还有循环结合的方式,利用索引获取到集合中的每一个元素
for (int i = 0; i < list.size(); i++) {
//i:依次表示集合中的每一个索引
String s = list.get(i);
System.out.println(s);
}
// 5.列表迭代器
//获取一个列表迭代器的对象,里面的指针默认也是指向0索引的
//额外添加了一个方法:在遍历的过程中,可以添加元素
ListIterator<String> it = list.listIterator();
while(it.hasNext()){
String str = it.next();
if("bbb".equals(str)){
//qqq
it.add("qqq");
}
}
System.out.println(list);4 细节点注意:
List系列集合中的两个删除的方法
1.直接删除元素
2.通过索引进行删除
删除元素
//请问:此时删除的是1这个元素,还是1索引上的元素?
//为什么?
//因为在调用方法的时候,如果方法出现了重载现象
//优先调用,实参跟形参类型一致的那个方法。
list.remove(1);
//手动装箱,手动把基本数据类型的1,变成Integer类型
Integer i = Integer.valueOf(1);
list.remove(i);
System.out.println(list);五、LinkedList集合
特有方法:
| 方法名 | 说明 |
|---|---|
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |
public class MyLinkedListDemo4 {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
// public void addFirst(E e) 在该列表开头插入指定的元素
//method1(list);
// public void addLast(E e) 将指定的元素追加到此列表的末尾
//method2(list);
// public E getFirst() 返回此列表中的第一个元素
// public E getLast() 返回此列表中的最后一个元素
//method3(list);
// public E removeFirst() 从此列表中删除并返回第一个元素
// public E removeLast() 从此列表中删除并返回最后一个元素
//method4(list);
}
private static void method4(LinkedList<String> list) {
String first = list.removeFirst();
System.out.println(first);
String last = list.removeLast();
System.out.println(last);
System.out.println(list);
}
private static void method3(LinkedList<String> list) {
String first = list.getFirst();
String last = list.getLast();
System.out.println(first);
System.out.println(last);
}
private static void method2(LinkedList<String> list) {
list.addLast("www");
System.out.println(list);
}
private static void method1(LinkedList<String> list) {
list.addFirst("qqq");
System.out.println(list);
}
}六、ArrayList源码分析:
核心步骤:
-
创建ArrayList对象的时候,他在底层先创建了一个长度为0的数组。
数组名字:elementDate,定义变量size。
size这个变量有两层含义: ①:元素的个数,也就是集合的长度 ②:下一个元素的存入位置
-
添加元素,添加完毕后,size++
扩容时机一:
-
当存满时候,会创建一个新的数组,新数组的长度,是原来的1.5倍,也就是长度为15.再把所有的元素,全拷贝到新数组中。如果继续添加数据,这个长度为15的数组也满了,那么下次还会继续扩容,还是1.5倍。
扩容时机二:
-
一次性添加多个数据,扩容1.5倍不够,怎么办呀?
如果一次添加多个元素,1.5倍放不下,那么新创建数组的长度以实际为准。
举个例子: 在一开始,如果默认的长度为10的数组已经装满了,在装满的情况下,我一次性要添加100个数据很显然,10扩容1.5倍,变成15,还是不够,
怎么办?
此时新数组的长度,就以实际情况为准,就是110
添加一个元素时的扩容:

添加多个元素时的扩容:

七、LinkedList源码分析:
底层是双向链表结构
核心步骤如下:
-
刚开始创建的时候,底层创建了两个变量:一个记录头结点first,一个记录尾结点last,默认为null
-
添加第一个元素时,底层创建一个结点对象,first和last都记录这个结点的地址值
-
添加第二个元素时,底层创建一个结点对象,第一个结点会记录第二个结点的地址值,last会记录新结点的地址值
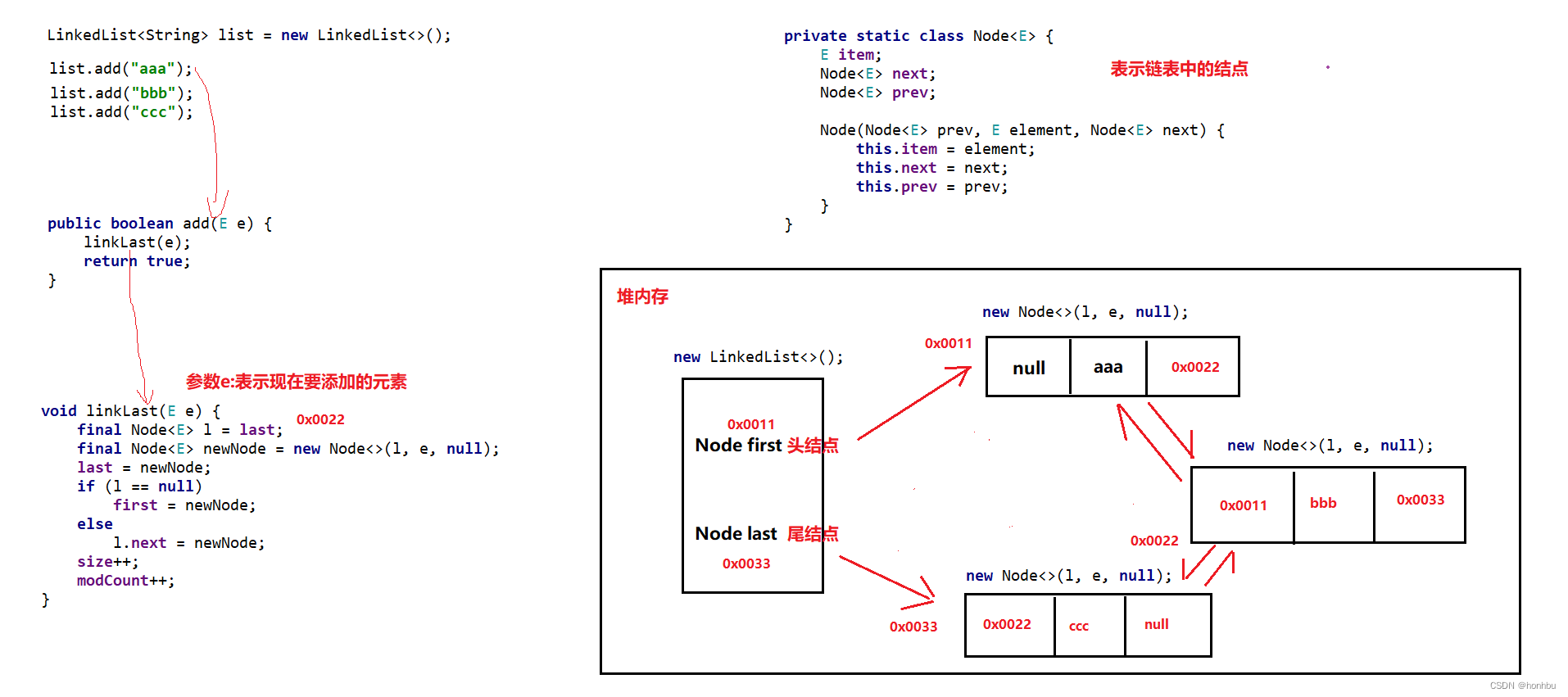
八、迭代器源码分析:
迭代器遍历相关的三个方法:
-
Iterator<E> iterator() :获取一个迭代器对象
-
boolean hasNext() :判断当前指向的位置是否有元素
-
E next() :获取当前指向的元素并移动指针

九、泛型
泛型概述
-
泛型的介绍
泛型是JDK5中引入的特性,它提供了编译时类型安全检测机制
-
泛型的好处
-
把运行时期的问题提前到了编译期间
-
避免了强制类型转换
-
-
泛型的细节
- 泛型中不能写基本数据类型
- 指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型如果不写泛型,类型默认是Object
-
泛型的定义格式
-
<类型>: 指定一种类型的格式.尖括号里面可以任意书写,一般只写一个字母.例如: <E> <T>
-
<类型1,类型2…>: 指定多种类型的格式,多种类型之间用逗号隔开.例如: <E,T> <K,V>
-
泛型可以在很多地方定义
- 类后面 泛型类
使用场景:当一个类中,某个变量的教据类型不确定时,就可以定义带有泛型的类
例:
public class MyArrayList<E> {
Object[] obj = new Object[10];
int size;
/*
E : 表示是不确定的类型。该类型在类名后面已经定义过了。
e:形参的名字,变量名
* */
public boolean add(E e){
obj[size] = e;
size++;
return true;
}
public E get(int index){
return (E)obj[index];
}
@Override
public String toString() {
return Arrays.toString(obj);
}
}
- 方法上面 泛型方法
方法中形参类型不确定时
方案①:使用类名后面定义的泛型
方案②:在方法申明上定义自己的泛型
例:Public<T> void show(T t)
public class ListUtil {
private ListUtil(){}
//类中定义一个静态方法addAll,用来添加多个集合的元素。
/*
* 参数一:集合
* 参数二~最后:要添加的元素
*
* */
public static<E> void addAll(ArrayList<E> list, E e1,E e2,E e3,E e4){
list.add(e1);
list.add(e2);
list.add(e3);
list.add(e4);
}
/* public static<E> void addAll2(ArrayList<E> list, E...e){
for (E element : e) {
list.add(element);
}
}*/
public void show(){
System.out.println("尼古拉斯·纯情·天真·暖男·阿玮");
}
}- 接口后面 泛型接口
重点:如何使用一个带泛型的接口
方式1:实现类给出具体类型
例:public class MyArrayList2 implements List<String>
方式2:实现类延续泛型,创建对象时再确定
例:ublic class MyArrayList3<E> implements List<E>
泛型不具备继承性,数据具备继承性
泛型里面写的是什么类型,那么只能传递什么类型的数据。弊端:
利用泛型方法有一个小弊端,此时他可以接受任意的数据类型Ye Fu zi student
希望:本方法虽然不确定类型,但是以后我希望只能传递Ye Fu Zi
此时我们就可以使用泛型的
通配符:
? 也表示不确定的类型
他可以进行类型的限定
? extends E:表示可以传递E或者E所有的子类类型
? super E:表示可以传递E或者E所有的父类类型
应用场景:
1.如果我们在定义类、方法、接口的时候,如果类型不确定,就可以定义泛型类、泛型方法、泛型接口。2.如果类型不确定,但是能知道以后只能传递某个继承体系中的.就可以泛型的通配符
泛型的通配符:
关键点:可以限定类型的范围。
十、Set集合
1Set集合概述和特点【应用】
-
不可以存储重复元素
-
没有索引,不能使用普通for循环遍历
2.2Set集合的使用【应用】
存储字符串并遍历
十一、HashSet
HashSet底层原理
HashSet集合底层采取哈希表存储数据
哈希表是一种对于增删改查数据性能都较好的结构
哈希表组成
JDK8之前:数组+链表
JDK8开始:数组+链表+红黑树
哈希值
对象的整数表现形式
根据hashCode方法算出来的int类型的整数
该方法定义在object类中,所有对象都可以调用,默认使用地址值进行计算
一般情况下,会重写hashcode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点
如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。|(哈希碰撞)
Hashset在JDK8以前底层原理
创建一个默认为16,默认加载因子为0.75的数组,数组名table(当数组中元素达到16*0.75时,会扩容2倍)
根据元素的哈希值跟数组的长度计算出应存入的位置![]()
判断是否为null,如果是null直接存入
如果不是null,表示有元素,则调用equal方法比较属性值
一样:不存 不一样:存入数组,形成链表
jdk8以前:新元素存入数组,老元素挂在新元素下面
jdk8以后:新元素直接挂在老元素下面
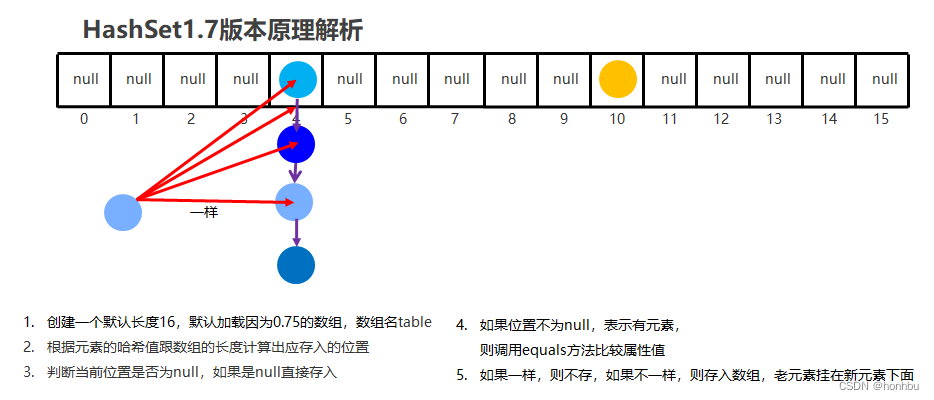
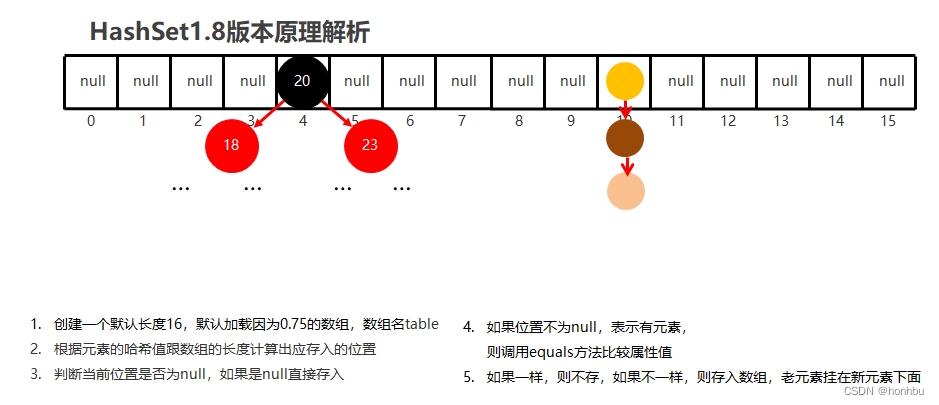
JDK8以后,当链表长度超过8,而且数组长度大于等于64时,自动转换为红黑树
如果集合中存储的是自定义对象,必须要重写hashCode和equals方法
问题1: Hashset为什么存和取的顺序不一样?
存的时候是按哈希值放到数组中,存放顺序不一定连续,取的时候是顺序从数组中取
问题2:HashSet为什么没有索引?
Hashet并不纯粹,是由数组链表红黑树组合而成,无法规定索引
问题3: HashSet是利用件么机制保证数据去重的?
HashCode方法得到哈希值,确定数组添加到哪个位置
equals方法去判断对象内部属性是否相同
如果Hashset存储的是自定义对象,一定要重写HashCode和equal方法
十二、LinkedHashSet
底层原理
有序、不重复、无索引。
这里的有序指的是保证存储和取出的元素顺序一致
原理:底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序。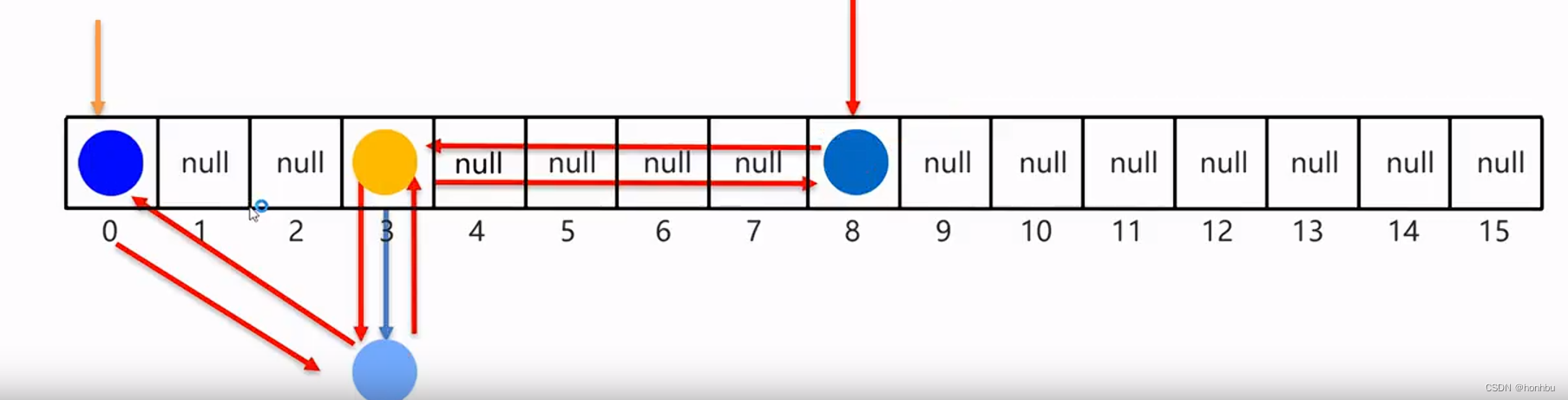
十三、TreeSet
特点:
- 不重复、无索引、可排序
- 可排序:按照元素的默认规则(有小到大)排序。
- TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好。
TreeSet集合默认的规则
- 对于数值类型:Integer , Double,默认按照从小到大的顺序进行排序。
- 对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序。
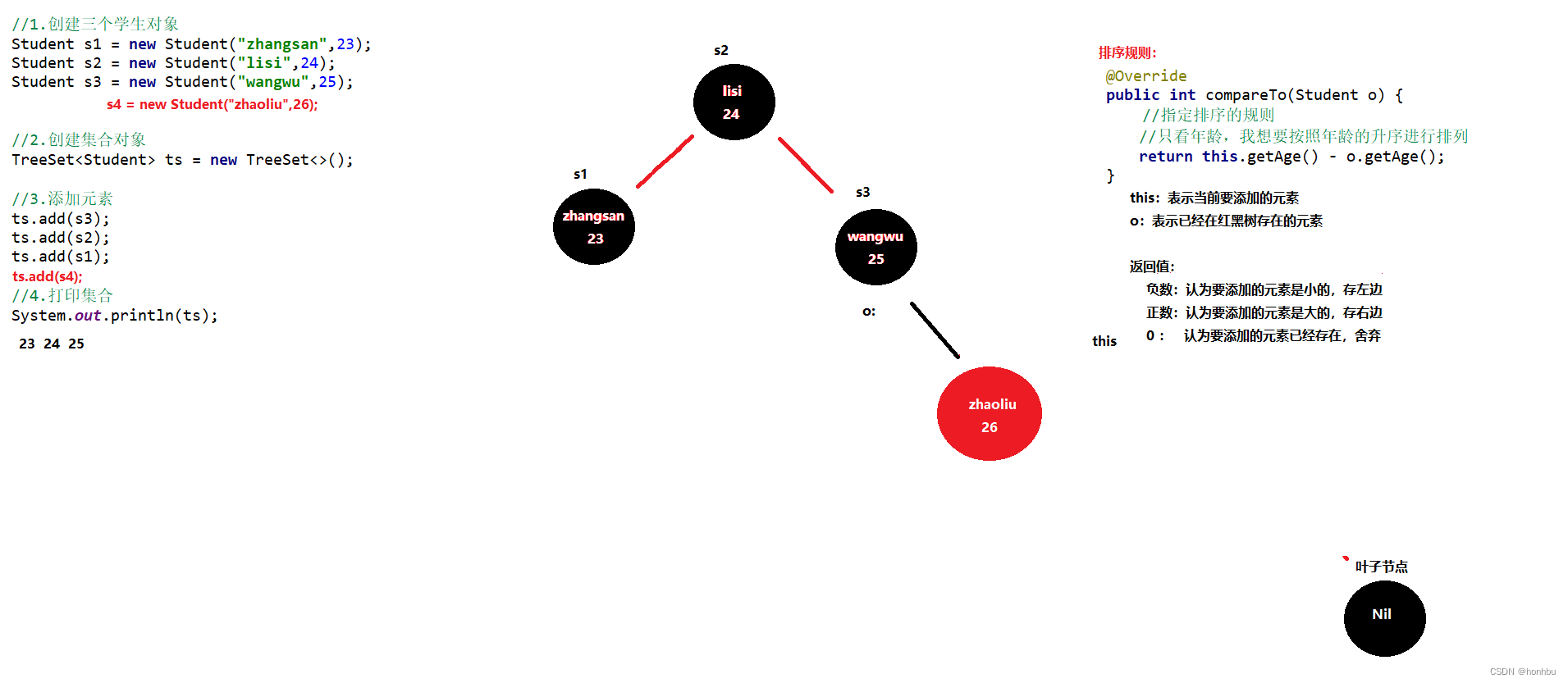
-
TreeSet():根据其元素的自然排序进行排序
-
TreeSet(Comparator comparator) :根据指定的比较器进行排序
自定义排序有两种
使用原则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种
方式一:默认排序,自然排序,就是让元素所属的类实现Comparable接口指定比较规则,重写compareTo(To)方法重写接口中的compareTo方法
重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写

public int compareTo(student o) {
system.out. println("System.out.println("this:" + this);
System.out.print1n(""o:" + o);
//指定排序的规则
//只看年龄,我想要按照年龄的升序进行排列
return this.getAge() - o.getAge();
}
方式二:比较器排序:创建TreeSet对象时候,传递比较器Comparator指定规则
实现步骤
- 用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
- 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(T o1,T o2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
@Override
public int compare(Teacher o1, Teacher o2) {
//o1表示现在要存入的那个元素
//o2表示已经存入到集合中的元素
//主要条件
int result = o1.getAge() - o2.getAge();
//次要条件
result = result == 0 ? o1.getName().compareTo(o2.getName()) : result;
return result;
}
});两种比较方式总结【理解】
-
两种比较方式小结
-
自然排序: 自定义类实现Comparable接口,重写compareTo方法,根据返回值进行排序
-
比较器排序: 创建TreeSet对象的时候传递Comparator的实现类对象,重写compare方法,根据返回值进行排序
-
在使用的时候,默认使用自然排序,当自然排序不满足现在的需求时,必须使用比较器排序
-
-
两种方式中关于返回值的规则
-
正数:表示当前存入的元素是较大值,存右边
-
负数:表示当前存入的元素是较小值,存左边
-
0:表示当前存入的元素跟集合中元素重复了,不存
-
总结:
1.如果想要集合中的元素可重复
用ArrayList集合,基于数组的。(用的最多)
2.如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
用LinkedList集合,基于链表的。
3.如果想对集合中的元素去重
用HashSet集合,基于哈希表的。(用的最多)
4.如果想对集合中的元素去重,而且保证存取顺序
用LinkedHashset集合,基于哈希表和双链表,效率低于HashSet
5.如果想对集合中的元素进行排序
用Treeset集合,基于红黑树。后续也可以用List集合实现排序。
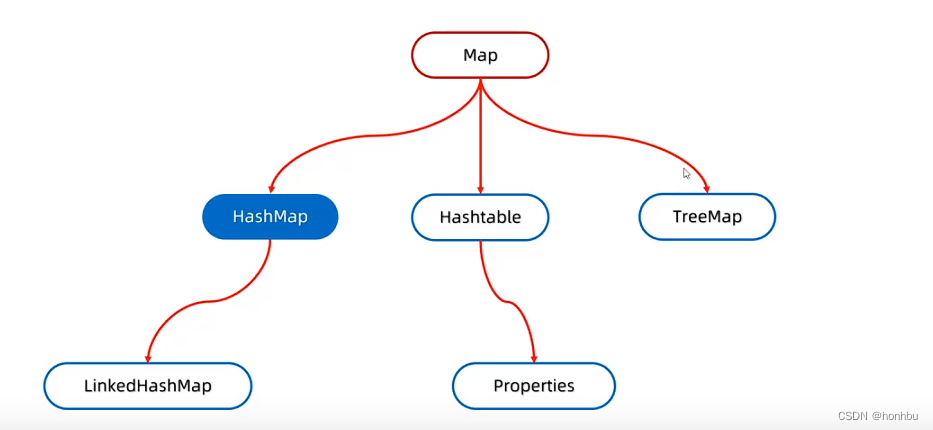
十四、Map集合
概述
interface Map<K,V> K:键的类型;V:值的类型
特点
- 双列集合一次需要存一对数据,分别为键和值
- 键不能重复,值可以重复
- 键和值是一一对应的,每一个键只能找到自己对应的值
- 键+值这个整体我们称之为“键值对”或者“键值对对象”,在Java中叫做“Entry对象”
MAP常用API
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
| entrySet() | 获取键值对 |
put方法的细节:
添加/覆盖
在添加数据的时候,如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回null
在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,会把被覆盖的值进行返回。
Map集合的遍历
方式1:键找值
步骤分析
-
获取所有键的集合。用keySet()方法实现
-
遍历键的集合,获取到每一个键。用增强for实现
-
根据键去找值。用get(Object key)方法实现
public class MapDemo01 {
public static void main(String[] args) {
//创建集合对象
Map<String, String> map = new HashMap<String, String>();
//添加元素
map.put("张无忌", "赵敏");
map.put("郭靖", "黄蓉");
map.put("杨过", "小龙女");
//获取所有键的集合。用keySet()方法实现
Set<String> keySet = map.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
for (String key : keySet) {
//根据键去找值。用get(Object key)方法实现
String value = map.get(key);
System.out.println(key + "," + value);
}
}
}方式二:键值对
步骤分析
-
获取所有键值对对象的集合
-
Set<Map.Entry<K,V>> entrySet():获取所有键值对对象的集合
-
-
遍历键值对对象的集合,得到每一个键值对对象
-
用增强for实现,得到每一个Map.Entry
-
-
根据键值对对象获取键和值
-
用getKey()得到键
-
用getValue()得到值
-
public class MapDemo02 {
public static void main(String[] args) {
//创建集合对象
Map<String, String> map = new HashMap<String, String>();
//添加元素
map.put("张无忌", "赵敏");
map.put("郭靖", "黄蓉");
map.put("杨过", "小龙女");
//获取所有键值对对象的集合
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : entrySet) {
//根据键值对对象获取键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "," + value);
}
}
}方式三:Lambda表达式
底层:
forEach其实就是利用第二种方式进行遍历,依次得到每一个键和值
再调用accept方法
public class A04_MapDemo4 {
public static void main(String[] args) {
//Map集合的第三种遍历方式
//1.创建Map集合的对象
Map<String,String> map = new HashMap<>();
//2.添加元素
//键:人物的名字
//值:名人名言
map.put("鲁迅","这句话是我说的");
map.put("曹操","不可能绝对不可能");
map.put("刘备","接着奏乐接着舞");
map.put("柯镇恶","看我眼色行事");
//3.利用lambda表达式进行遍历
//底层:
//forEach其实就是利用第二种方式进行遍历,依次得到每一个键和值
//再调用accept方法
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + "=" + value);
}
});
System.out.println("-----------------------------------");
map.forEach((String key, String value)->{
System.out.println(key + "=" + value);
}
);
System.out.println("-----------------------------------");
map.forEach((key, value)-> System.out.println(key + "=" + value));
}
}十五、HashMap集合
概述
-
HashMap底层是哈希表结构的
-
依赖hashCode方法和equals方法保证键的唯一
-
如果键要存储的是自定义对象,需要重写hashCode和equals方法
-
如果值存储自定义对象,不需要重写hashCode和equals方法
特点
- HashMap是Map里面的一个实现类。
- 没有额外需要学习的特有方法,直接使用Map里面的方法就可以了。
- 都是由键决定的:无序、不重复、无索引
- HashMap跟HashSet底层原理是一模一样的,都是哈希表结构。键一样,直接覆盖;键不一样,直接使用链表,在长度超过8&数组长度>=64,自动转成红黑树
十六、LinkedHashMap
由键决定:
有序、不重复、无索引。
有序:
这里的有序指的是保证存储和取出的元素顺序一致
原理︰
底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序。
十七、TreeMap
- TreeMap跟TreeSet底层原理一样,都是红黑树结构的。
- 由键决定特性:不重复、无索引、可排序
- 可排序: 对键进行排序。
- 注意: 默认按照键的从小到大进行排序,也可以自己规定键的排序规则
代码书写两种排序规则
- 实现Comparable接口,指定比较规则。
- 创建集合时传递Comparator比较器对象,指定比较规则。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









