






Python数据分析_Pandas可视化
【模块一:空值处理及类型函数】
【理解】空值的定义及判断
-
目标:理解空值处理空值
-
实施
-
问题1:什么是空值?
-
定义:空值是指在数据中表示缺失或未知值的特殊标记,为空值的一种。
-
体现
平台 RDBMS Hive Python语言 Pandas 表示 null null[\N] None NaN、nan -
特殊:有时候我们会将特殊的异常值也解析成空值,比如空字符串
‘’ -
讨论:在数据分析和处理过程中,需要对空值进行适当的处理,常见的方式包括删除包含空值的行或列、填充/替换空值、或者通过插值等方法进行处理,以确保数据分析的准确性和可靠性。
-
-
问题2:读取数据的时候怎么会变成空值?
配置 含义 keep_default_na 默认是True 加载数据的时候 , 数据库中的Null 或者 Python 中None 空白的数据都会加载成NAN,False 会加载成空白 na_values 除了 Null None ‘’ 以外, 有一些特殊的值也做为空值来处理,该参数可以指定哪些值也会变成NaN -
问题3:空值怎么判定?
平台 语法 RDBMS col is null / col is not null Python var == None Pandas df.isnull() / df.notnull() -
示例
-
加载数据
# 导入pandas import pandas as pd # 正常加载数据6、NaN_Test.tsv文件 df = pd.read_csv('../data/6、NaN_Test.tsv', sep='\t', keep_default_na=False) df # 控制加载数据:空白转换为NaN df = pd.read_csv('../data/6、NaN_Test.tsv', sep='\t', keep_default_na=True) df # 控制加载数据:id为0或者空字符串转换为NaN df = pd.read_csv('../data/6、NaN_Test.tsv', sep='\t', keep_default_na=True, na_values=['\'\'', 0]) df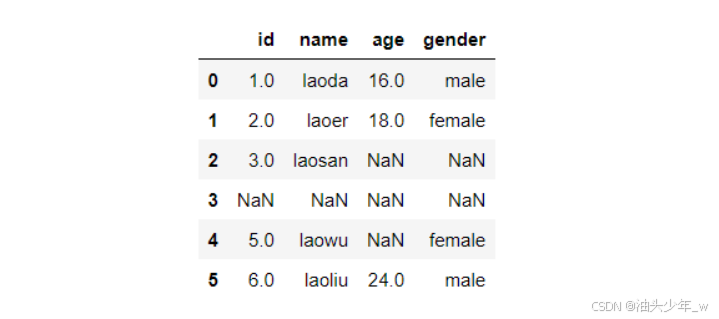
-
判断空值
# 判断当前值是否为null df.isnull() # 统计每一列null值的个数 df.isnull().sum() # 统计每一行null值的个数 df.isnull().sum(axis=1) # 查询 年龄 不为 NaN 的行 df[df['age'].notnull()]
-
-
-
小结:理解空值处理空值
#1.Pandas中的null值可以是:NaN、nan
#2.判断方式
isna()
isnull()
notna()
notnull()
【理解】空值的过滤及补全
-
目标:理解空值的过滤及补全
-
实施
-
空值过滤
-
语法
df.dropna( axis, how, inplace, subset, thresh ) -
参数
参数 功能 axis 制是删除包含缺失值的行还是列,默认为0(删除行),可以设置为1(删除列)。 how 可以取值为’any’或’all’。 'any’表示删除包含任何NaN的行或列,'all’表示只删除所有值为NaN的行或列。 inplace 默认为False,表示不修改原始DataFrame,返回一个新的DataFrame。 设为True时,表示在原始DataFrame上进行就地修改 subset 接受一个列名列表,用于指定在哪些列中查找缺失值并执行删除操作。 thresh 用于指定每行或每列至少需要非缺失值的数量,低于这个阈值的行或列将会被删除。 -
示例
# 原始数据 df # 删除包含缺失值的行 df1 = df.dropna() df1 # 删除包含缺失值的列 df2 = df.dropna(axis=1) df2 # 删除所有值为NaN的行 df3 = df.dropna(how='all') df3 # 删除所有值为NaN的列 df4 = df.dropna(axis=1, how='all') df4 # 删除 id 或者 gender 包含 None 的行 df5 = df.dropna(subset=['id', 'gender']) df5 # 保留非空字段至少有2个字段的行 df6 = df.dropna(thresh=2) df6
-
-
空值补全
-
规则:具体填充的值由业务需求来决定
- 如果是数值型数据, 可以用均值/中位数
- 如果是类别型/字符串 可以使用出现次数最多的 进行填充
-
语法
DataFrame.fillna(value, method, axis, inplace, limit) -
参数
| 参数 | 功能 |
| ------- | ------------------------------------------------------------ |
| value | 使用固定的值来填充缺失值,可以是标量、字典、Series等。 |
| method | 用于指定插值方法,如’ffill’(向前填充)、‘bfill’(向后填充)等。 |
| axis | 制是删除包含缺失值的行还是列,默认为0(删除行),可以设置为1(删除列)。 |
| inplace | 是否对原始DataFrame进行就地修改,默认为False。 |
| limit | 限制每列(或每行)可填充的缺失值数量。 | -
示例
# 原始数据 df # 将所有行的NaN值填充为0 df.fillna(value=0) # 使用前面的值填充 df.fillna(method='ffill') # 使用后面的值填充 df.fillna(method='bfill') # 按照列进行填充,填充每一列的前两个NaN值 df.fillna(value=-1, axis=1, limit=2)
-
-
-
小结:理解空值的过滤及补全
#1.空值填充
fillna()
#2.空值过滤
dropna()
#3.空值判断
isna()
notna()
【理解】数据类型及常用函数
-
目标:理解数据类型及时间函数
-
实施
-
Pandas中的数据类型
类型 说明 int 整数类型,可以是int16、int32或int64等 float 浮点数类型,可以是float16、float32或float64等 object Python对象类型,通常用于字符串或混合类型 bool 布尔值类型,True或False datetime64 日期和时间类型,表示时间戳 timedelta64 表示两个datetime64之间的差(时间间隔) -
Pandas中的字符串函数
函数 说明 str.lower() 将字符串转换为小写 str.upper() 将字符串转换为大写 str.len() 返回字符串的长度 str.split() 使用指定的分隔符拆分字符串 str.replace() 替换字符串中的子串 str.findall() 查找字符串中所有匹配给定模式的子串 str.startswith() 检查字符串是否以给定值开头 str.endswith() 检查字符串是否以给定值结尾 str.isnumeric() 检查字符串是否只包含数字,ID= ‘123456’ str.isalpha() 检查字符串是否只包含字母 -
Pandas中的时间函数
函数 功能 to_datetime() 将参数转换为Pandas的日期时间类型 dt.date 从日期时间类型中提取日期部分 dt.time 从日期时间类型中提取时间部分 dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second 从日期时间类型中提取年、月、日、小时、分钟和秒等信息 -
代码示例
-
字符串函数
# 读取csv文件 scientists = pd.read_csv('../data/2、scientists.csv') scientists # 字符串函数 print("转换成小写") print(df['Name'].str.lower()) print("转换成大写") print(df['Name'].str.upper()) print("计算值的长度") print(df['Name'].str.len()) print("分割字符串") print(df['Name'].str.split(' ')) print("替换字符串") print(df['Name'].str.replace('Franklin', 'itcast')) print("查找字符串") print(df['Name'].str.findall('l')) print("是否已以某个字符串开头") print(df['Name'].str.startswith('A')) print("是否已以某个字符串结尾") print(df['Name'].str.endswith('e')) print("是否是数值字符串") print(df['Name'].str.isnumeric()) print("是否是纯字母") print(df['Occupation'].str.isalpha()) -
时间函数
# 时间转换 df['Born'] = pd.to_datetime(df['Born']) df.dtype # 其他函数 print(df['Born'].dt.year) print(df['Born'].dt.month) print(df['Born'].dt.day) print(df['Born'].dt.hour) print(df['Born'].dt.minute) print(df['Born'].dt.second) print(df['Born'].dt.quarter) print(df['Born'].dt.dayofweek + 1) print(df['Born'].dt.weekday + 1)
-
-
-
小结:理解数据类型及时间函数
#1.时间函数
Series.dt.xxx,xxx就是函数名,具体的函数名可以查看官网
#2.字符串函数
Series.str.xxx,xxx就是具体的函数名,具体函数名可以查看官网
#3.对象类型转换为时间类型
pd.to_datetime(xxx),把xxx列转换为datetime类型
【理解】数据透视表的使用
-
目标:理解数据透视表的使用
-
实施
-
问题1:什么是数据透视表?
- Pandas中的数据透视表是一种数据汇总工具,用于将数据根据一个或多个键进行分组,并对这些分组进行聚合操作。
- 通过透视表,用户可以快速地了解数据集中不同特征之间的关系、统计信息和模式。
- 数据透视表在Pandas中使用
pivot_table函数创建,允许用户按照自己的需求,以某些列作为行索引、某些列作为列索引,从而把数据重新排列成用户希望查看的形式。 - 透视表提供了一种直观、灵活且易于理解的方式,方便用户进行数据分析和探索。
-
问题2:数据透视表怎么使用?
-
语法
pivot_table(values=None, index=None, columns=None, aggfunc='mean')- values:表示需要汇总的数值列名称,需要聚合的列。
- index:表示用作行索引的列名或者是多个列名组成的列表,需要分组的列。
- columns:表示用作列索引的列名或者是多个列名组成的列表,需要分组的列。
- aggfunc:表示聚合函数,可以是内置的聚合函数(如’mean’、'sum’等)或自定义的聚合函数。
-
示例
# 原始数据 df = pd.read_csv('../data/5、LJdata.csv') df # 统计每个区域每种户型的看房总人数 rs = df.pivot_table(index='区域', columns='户型', values='看房人数', aggfunc='sum') rs
-
-
-
小结:理解数据透视表的使用
【模块二:Python数据可视化】
【理解】Matplotlib的介绍
-
目标:理解Matplotlib的介绍
-
实施
-
问题1:什么是Matplotlib?
Matplotlib 是一个用于创建图表和其他视觉呈现的 2D 图形库。它包含大量的工具,使你能够轻松地展示数据并将结果 可视化。其功能包括创建折线图、散点图、条形图、直方图以及多种其他图表类型。Matplotlib 还支持各种不同的注释元素,如标签、标题以及图例。此外,通过导出图表,用户可以生成各种常见格式的图片文件。
-
问题2:它的特点和应用场景是什么?
- 优点
- 广泛的图表类型:Matplotlib 提供了许多不同类型的图表供用户选择,使其适用于各种分析和展示需求。
- 灵活性:用户可以根据自己的需求对图表进行高度定制,并应用各种样式和配置选项。
- 文档和社区:Matplotlib 拥有丰富的文档和强大的社区支持,因此易于学习和使用。
- 缺点
- 默认样式较为简单:需要进行美化才能得到具有吸引力的图表。
- 性能问题:在处理大型数据集时,Matplotlib 的性能可能会有所下降。
- 复杂度过高:Matplotlib所有组件部分都需要自己进行控制,导致学习和开发成本过高,无法快速构建
- 应用场景
- Matplotlib 可以用于复杂数据分析、科学计算、工程绘图、学术论文制作等领域。主要应用于数据可视化和结果展示。
- 优点
-
问题3:如何利用Matplotlib生成图表?
-
安装
# 注意先进入自己的虚拟环境,然后再安装 matplotlib 扩展包 pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/ -
测试
# 屏蔽警告 import warnings warnings.filterwarnings('ignore') # 导包 import matplotlib.pyplot as plt # 准备数据 x = [1, 2, 3, 4, 5] y = [2, 3, 5, 7, 11] # 绘制折线图 plt.plot(x, y) # 添加标签和标题 plt.xlabel('this is x') plt.ylabel('this is y') plt.title('this is a line') # 显示图表 plt.show()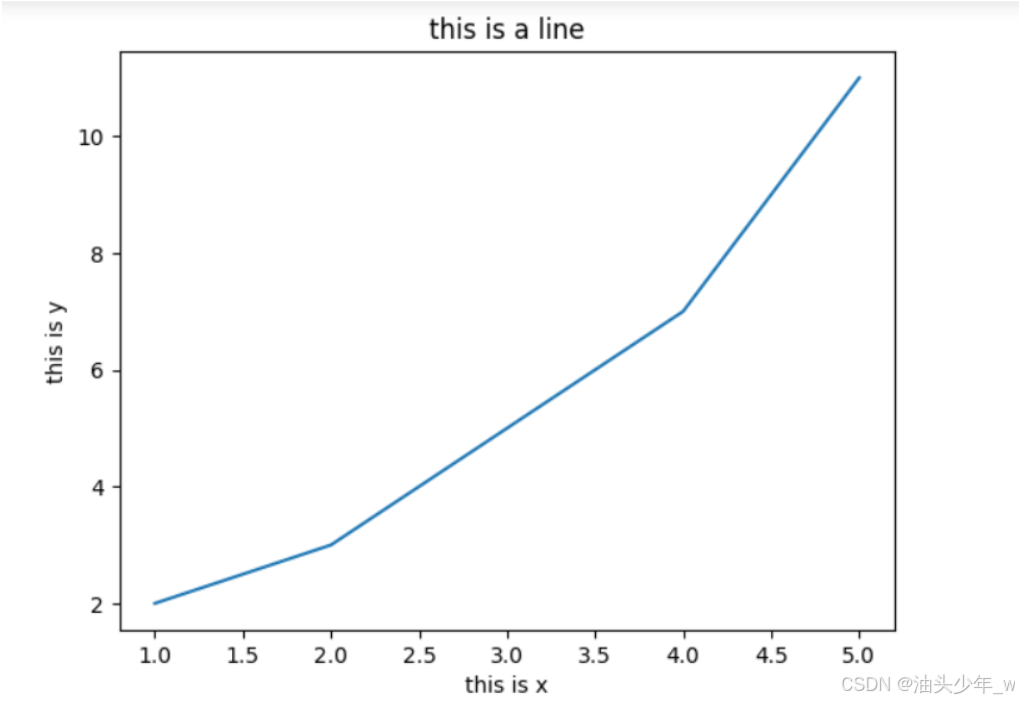
-
-
-
小结:理解Matplotlib的介绍
Matplotlib就是一个画图工具,plot就是画折线图,颜色、线条等参数非常多,详情查看官网。
【理解】Matplotlib的使用
-
目标:理解Matplotlib的使用
-
实施
-
Matplotlib常用基础图表:线图、柱状直方图、散点图、饼图
-
Matplotlib图表构建流程:1、导入图表,2、构建图表,3、展示图表
-
Matplotlib图表常用配置
参数 描述 可选值 figsize 设置图表的尺寸大小 任意元组,如 (8, 6) 表示宽度为 8 像素、高度为 6 像素 title 标题,用于设置图表的标题 字符串,标题内容 xlabel 设置 x 轴的标签 字符串,x 轴标签内容 ylabel 设置 y 轴的标签 字符串,y 轴标签内容 xlim 设置 x 轴的显示范围 任意数值,如 (0, 10) 表示从 0 到 10 的范围 ylim 设置 y 轴的显示范围 任意数值,如 (0, 20) 表示从 0 到 20 的范围 legend 配置图例,显示数据对应的 label 字符串,图例内容 color 设置图表或数据系列的颜色 颜色名称或十六进制颜色代码,如 ‘r’ 表示红色 linestyle (ls) 设置线条的样式 字符串,如 ‘- ’ 表示实线,’:’ 或者 ’–‘表示虚线 marker 设置数据点的样式 字符串或字符,如 ‘o’ 表示圆圈,‘s’ 表示方块 fontsize 设置字体大小 整数,如 12 表示字体大小为 12 grid 是否显示网格线 布尔值,True 或 False xticks 设置 x 轴的刻度位置和标签 序列,包括刻度位置和标签 yticks 设置 y 轴的刻度位置和标签 序列,包括刻度位置和标签 alpha 设置图表元素的透明度 0 到 1 之间的浮点数,表示透明度的程度 linewidth (lw) 设置线条宽度 任意整数,表示线条的宽度 -
折线图
# 导包 import matplotlib.pyplot as plt # 准备数据 x = [1, 2, 3, 4, 5] y = [2, 3, 5, 7, 11] # 创建折线图 plt.plot(x, y, linestyle='--', color='green', marker='o') plt.xlabel('X') plt.ylabel('Y') plt.title('Sine Wave') plt.grid(True) # 显示图表 plt.show()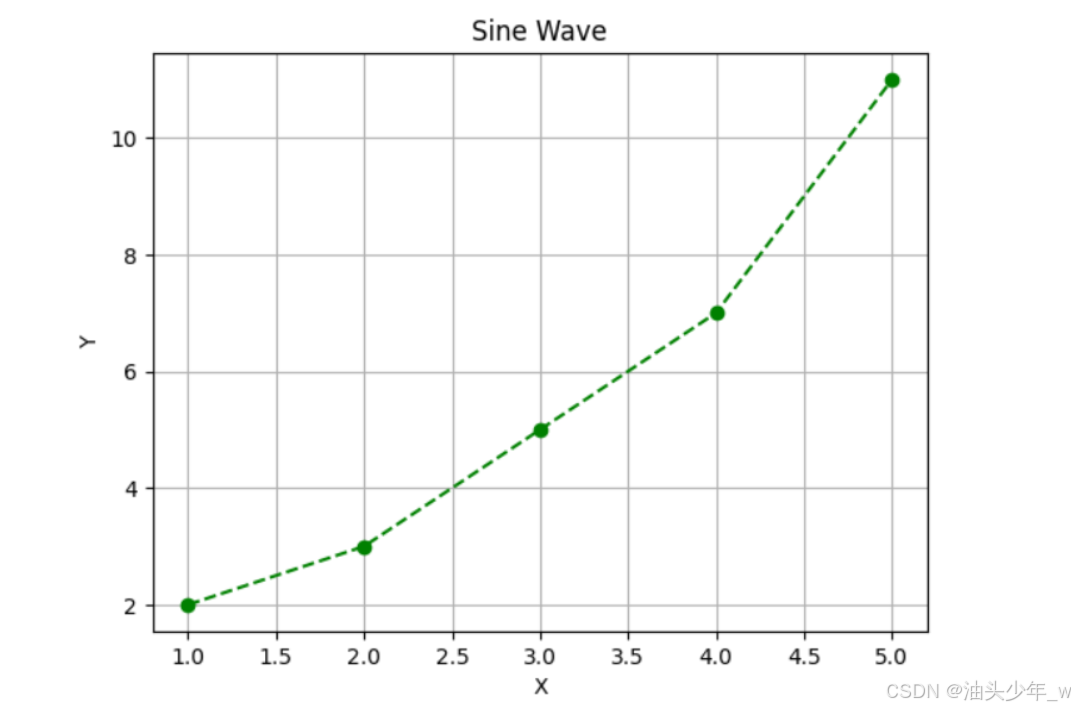
-
柱状图
# 设置图的大小 plt.figure(figsize=(5, 4)) # 示例数据 categories = ['A', 'B', 'C'] values = [3, 7, 2] colors = ['r', 'g', 'b'] # 每个柱子对应的颜色 # 创建柱状图 plt.bar(categories, values, color=colors) plt.xlabel('Category') plt.ylabel('Value') plt.title('Bar Chart') # 显示图表 plt.show()
-
散点图
# 生成随机数据 import numpy as np x = np.random.rand(50) y = np.random.rand(50) # 创建散点图 plt.scatter(x, y, c='orange') # 添加标签和标题 plt.xlabel('X') plt.ylabel('Y') plt.title('Scatter Plot') # 显示图表 plt.show()
-
饼图
# 示例数据 labels = ['A', 'B', 'C'] sizes = [30, 40, 30] # 创建饼图 plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=['lightcoral', 'lightskyblue', 'lightgreen']) plt.title('Pie Chart') plt.legend() # 显示图表 plt.show()
-
-
小结:理解Matplotlib的使用
#1.Matplotlib画图的API:
(1)plot:折线图
(2)bar:柱状图
(3)scatter:散点图
(4)pie:饼图
#2.用法:
plt.xxx(plot\bar\scatter\pie\....)
【理解】Pandas绘图介绍
-
目标:理解Pandas绘图的介绍
-
实施
-
问题1:什么是Pandas的绘图?
- Pandas 提供了使用内置的
plot()函数进行数据可视化的功能,支持多种类型的图表,包括折线图、柱状图、散点图、饼图等。 - 底层基于Matplotlib,只是简化了API,做了一些优化
- Pandas 提供了使用内置的
-
问题2:为什么要用Pandas的绘图?
- 优点
- 简单易用,直接在 DataFrame 或 Series 上调用
plot方法 - 集成于 Pandas 和NumPy 数据结构,适合处理大型数据集
- 可以轻松地根据数据进行可视化,快速发现数据特征和趋势
- 简单易用,直接在 DataFrame 或 Series 上调用
- 缺点
- 在复杂的定制化需求下灵活性相对较弱
- 在处理大规模数据时可能略显缓慢
- 应用场景:数据探索和分析、快速生成简单的可视化结果
- 优点
-
问题3:如何利用Pandas生成图表?
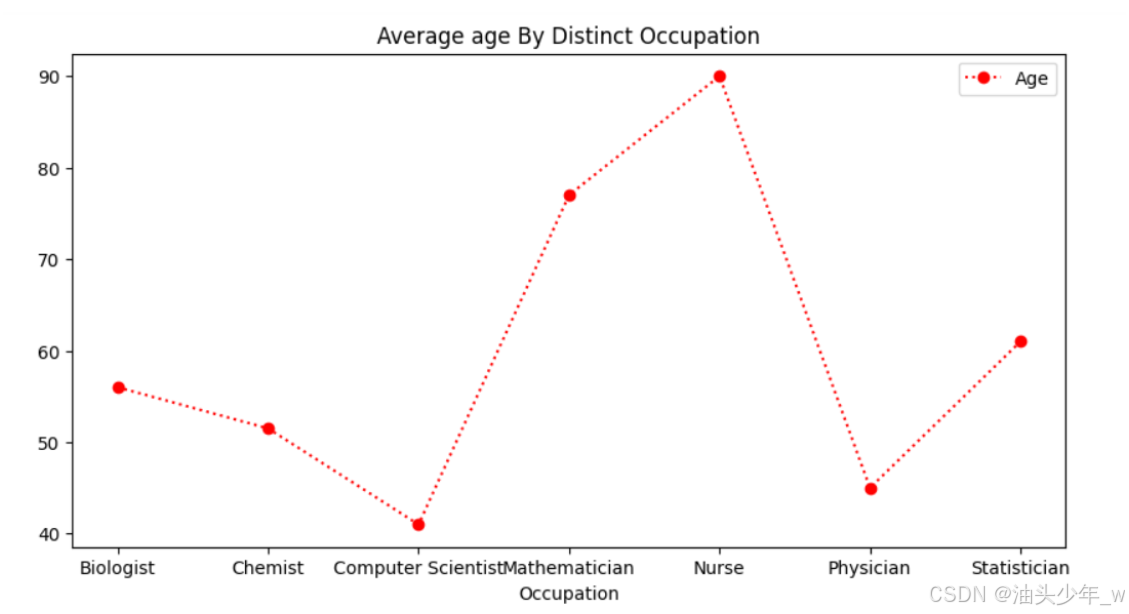
# 准备数据 # 不同职业科学家平均寿命 scientists = pd.read_csv('../data/2、scientists.csv').groupby('Occupation').mean() scientists_avg_age_by_occupation = scientists.reset_index() scientists_avg_age_by_occupation # 屏蔽警告 import warnings warnings.filterwarnings('ignore') # 导包 import matplotlib.pyplot as plt # 生成图表 scientists_avg_age_by_occupation.plot(x='Occupation', y='Age', color='r', linestyle=':', marker='o', figsize=(10, 5)) plt.title('Average age By Distinct Occupation') # 展示图表 plt.show()
-
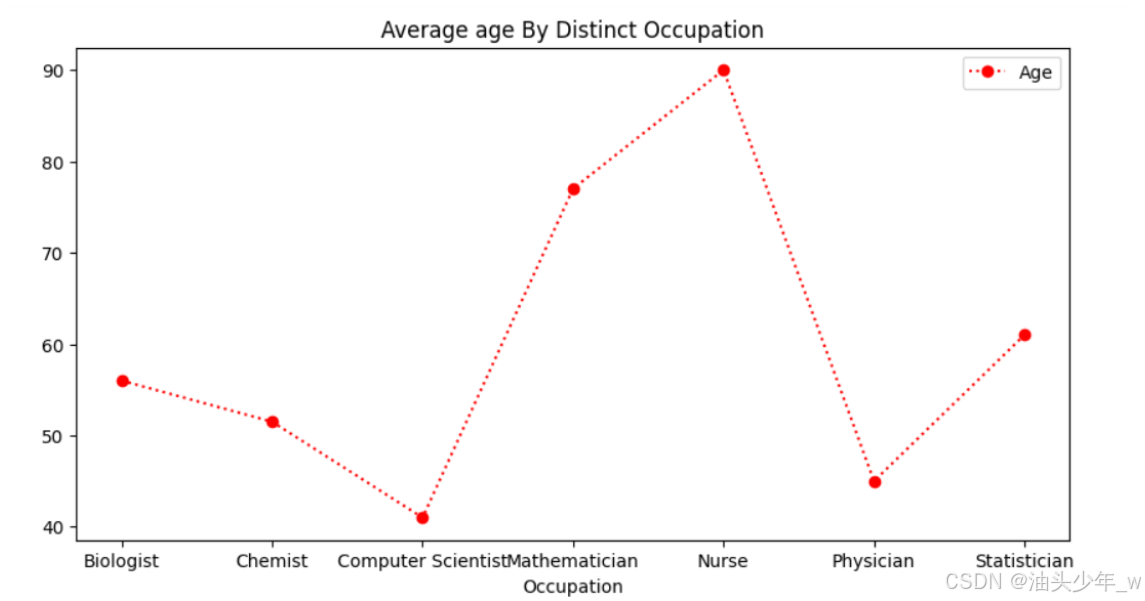
- 小结:理解Pandas绘图的介绍
【理解】Pandas绘图使用
-
目标:理解Pandas绘图使用
-
实施
-
Pandas线图
# 导包 import matplotlib.pyplot as plt # 生成图表 scientists_avg_age_by_occupation.plot(x='Occupation', y='Age', color='c', linestyle='-', marker='s', figsize=(10, 5)) plt.xlabel('Occupation') plt.ylabel('Age') plt.title('Average age By Distinct Occupation') plt.grid() # 展示图表 plt.show()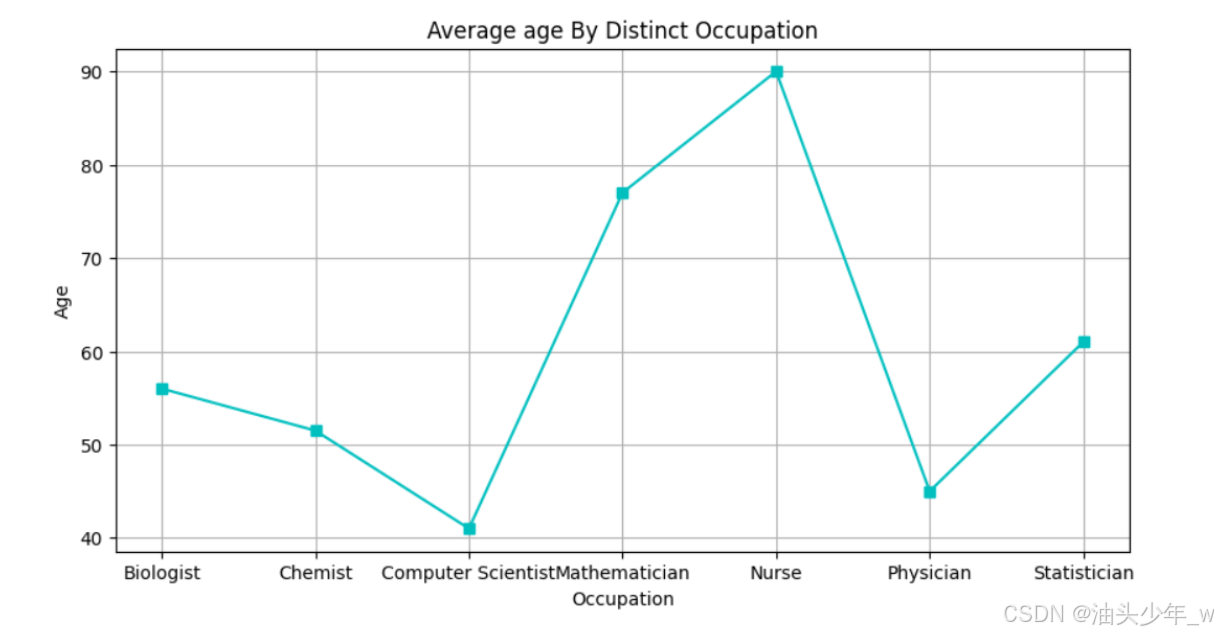
-
Pandas柱状图
# 导包 import matplotlib.pyplot as plt # 生成图表 ax = scientists_avg_age_by_occupation.plot(x='Occupation', y='Age',kind='bar', color='pink', figsize=(10, 6), ) plt.xlabel('Occupation') plt.ylabel('Age') plt.title('Average age By Distinct Occupation') for i, v in enumerate(scientists_avg_age_by_occupation['Age']): ax.text(i, v, str(v), ha='center') # 展示图表 plt.show()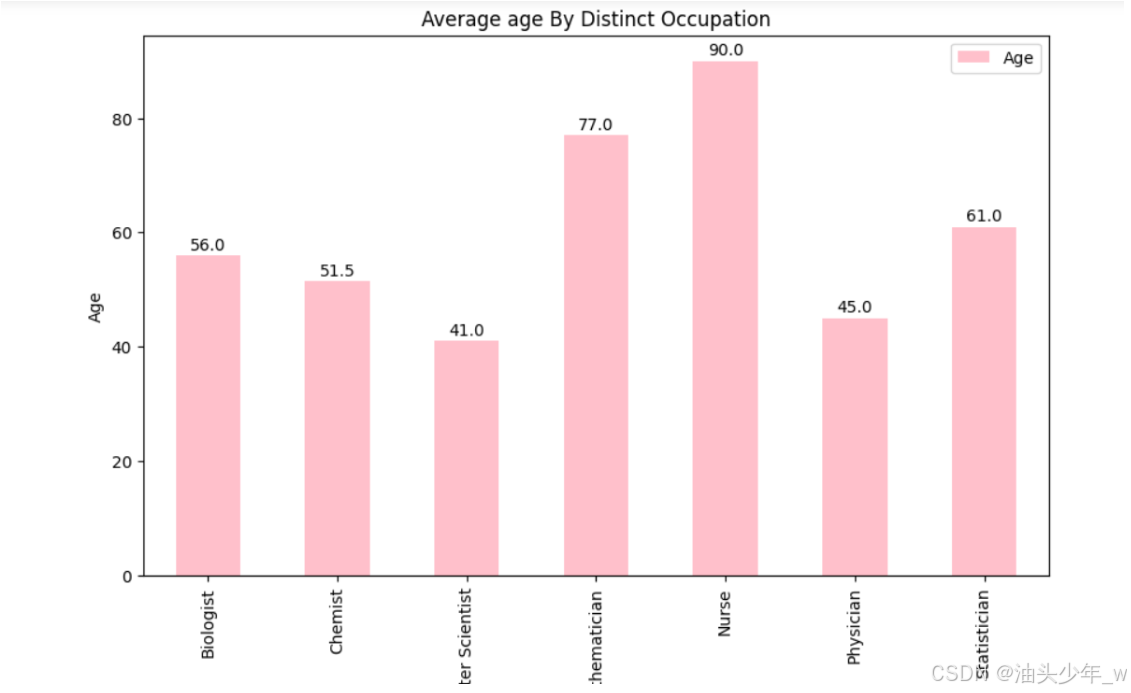
-
Pandas散点图
# 导包 import matplotlib.pyplot as plt # 生成图表 ax = scientists_avg_age_by_occupation.plot(x='Occupation', y='Age',kind='scatter', color='Purple', figsize=(10, 6)) plt.xlabel('Occupation') plt.ylabel('Age') plt.title('Average age By Distinct Occupation') plt.grid() for i, v in enumerate(scientists_avg_age_by_occupation['Age']): ax.text(i, v, str(v), ha='center') # 展示图表 plt.show()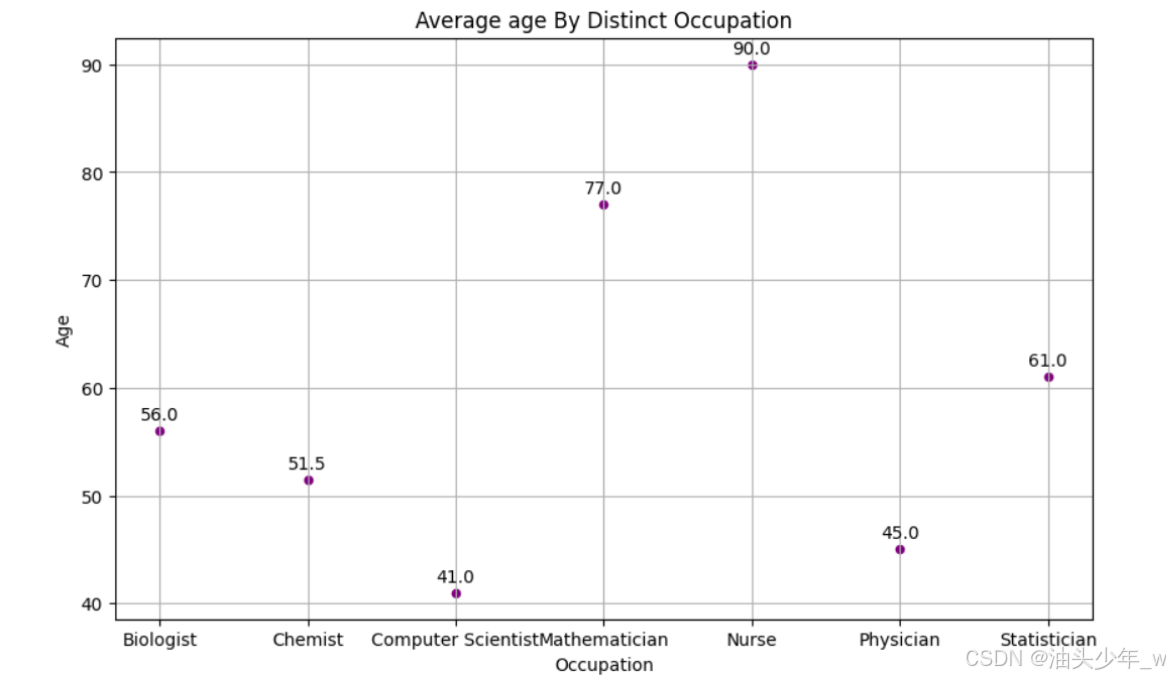
-
Pandas饼图
import matplotlib.pyplot as plt # 创建示例DataFrame data = {'sale_amt': [300, 500, 700]} categories = ['productA', 'productB', 'productC'] df = pd.DataFrame(data, index=categories) # 基于DataFrame创建饼图 df.plot(y='sale_amt', kind='pie', autopct='%1.1f%%', figsize=(10, 6)) # 添加标题 plt.title('amount_rate by distinct product') # 显示图表 plt.show()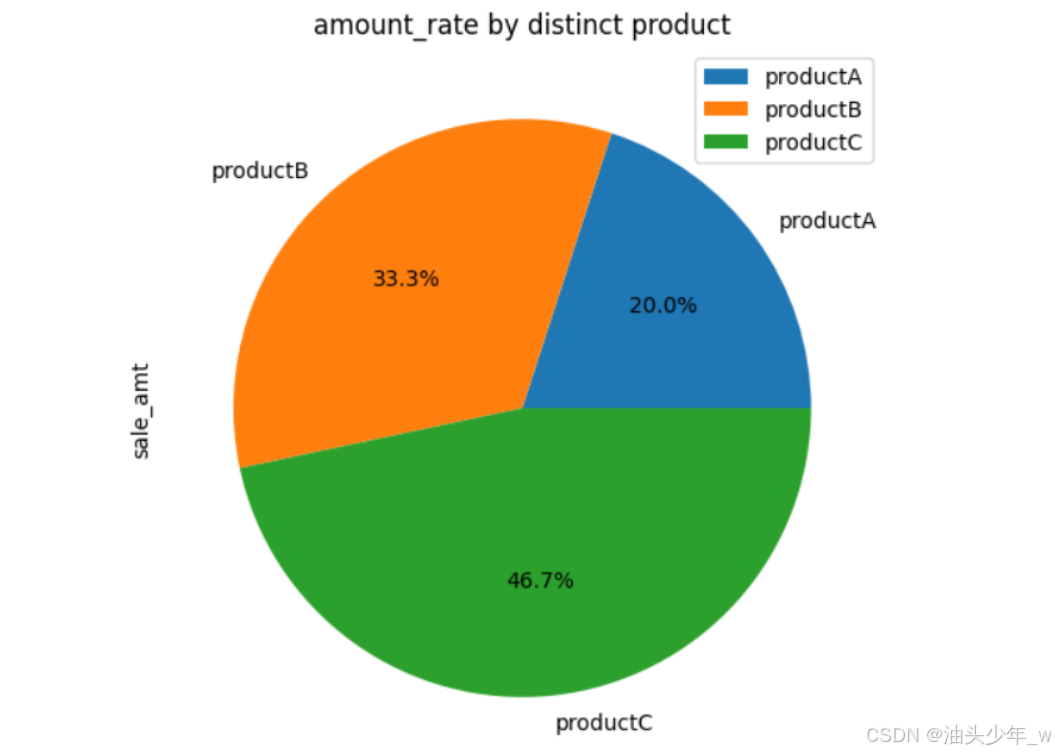
-
-
小结:理解Pandas绘图使用
#pandas的画图核心就是一个API:plot,不同的图表通过kind参数来制定。
#2.kind的值:
line(折线图)
bar(柱状图)
scatter(散点图)
pie(饼图)
【理解】Seaborn绘图介绍
-
目标:理解Seaborn绘图介绍
-
实施
-
问题1:什么是Seaborn?
Seaborn 是基于 Matplotlib 的 Python 可视化库,提供了更高级的统计数据可视化功能,包括常用的统计图表类型,如分布图、分类图以及热图。同时也支持比较各个子组内的数据情况。

-
问题2:为什么要使用Seaborn?
- 优点
- 提供美观且具有统计意义的默认风格
- 支持作为参数传入 DataFrame 的列名称进行绘制
- 整合性较好,可以与 Pandas 直接结合使用
- 能够方便地创建复杂的多变量图
- 缺点
- 在某些方面的灵活性相对较弱,不如直接使用 Matplotlib 灵活
- 对于定制化需求超出其内置功能的图表,可能需要借助 Matplotlib 进行修改
库 区别 应用场景 总结 Matplotlib 原始绘图库,提供了各种各样的绘图功能,但在一些情况下需要编写较多代码以实现特定的可视化效果。适合于创建定制化程度高、复杂的图表。 用于绘制基本图表和具有高度定制化需求的图表。 上手难,图表丑,定制化程度高 Pandas 基于 Matplotlib 构建的数据分析工具,提供快速、简单的方式来创建基本图表,可直接在 DataFrame 或 Series 上使用 plot()方法实现各种常见的图表。适用于探索性数据分析(EDA)和基本的数据可视化,对结构化数据展示非常方便。 简单易用,中规中矩,设计感差 Seaborn 基于 Matplotlib,提供高级数据可视化功能,更注重统计数据可视化和美学设计,能够轻松创建具备统计意义的图表,支持作为参数传入 dataframe 的列名称进行绘制。 用于创建统计图表,如分布图、分类图以及热图,并通过美学设计改进默认的 Matplotlib 风格。 简单易用,美观好看 - 优点
-
问题3:Seaborn如何实现画图?
-
安装
# 注意先进入自己的虚拟环境,然后再安装 seaborn 扩展包 pip install seaborn==0.11 -i https://pypi.tuna.tsinghua.edu.cn/simple/ -
测试
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd # 示例数据 data = { 'category': ['A', 'B', 'C', 'D', 'E', 'F'], 'value': [3, 5, 8, 6, 4, 7] } df = pd.DataFrame(data) # 创建示例分类图 sns.barplot(x='category', y='value', data=df, palette='pastel') plt.xlabel('Category') plt.ylabel('Value') plt.title('Bar Plot') # 显示图表 plt.show()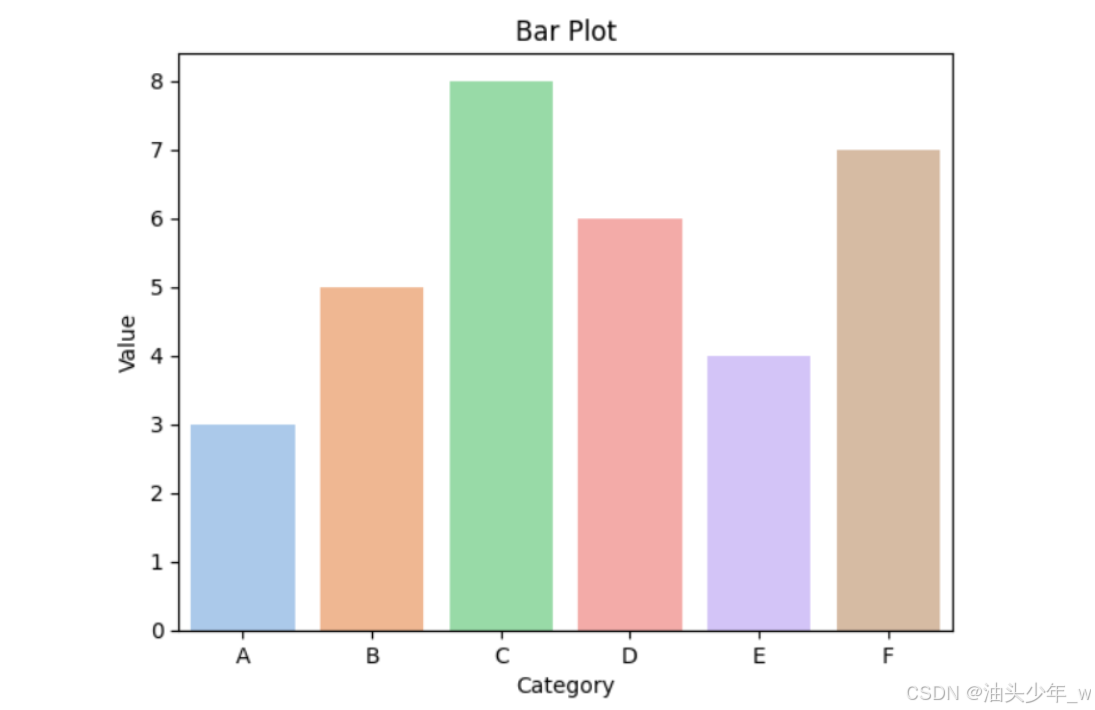
-
-
-
小结:理解Seaborn绘图介绍
#1.seaborn的画图API:sns.xxxplot(),xxx可以是任意的图形。官网支持的都可以。
【理解】Seaborn绘图使用
-
目标:理解Seaborn绘图使用
-
实施
-
线图
# 示例数据 index = np.arange(10) data = np.random.rand(4, 10) df = pd.DataFrame(data.T, index=index, columns=list('ABCD')) # 创建线图 sns.lineplot(data=df, palette="pastel", linewidth=2.5) # 添加标签和标题 plt.xlabel('Index') plt.ylabel('Value') plt.title('Line Plot') # 显示图表 plt.show()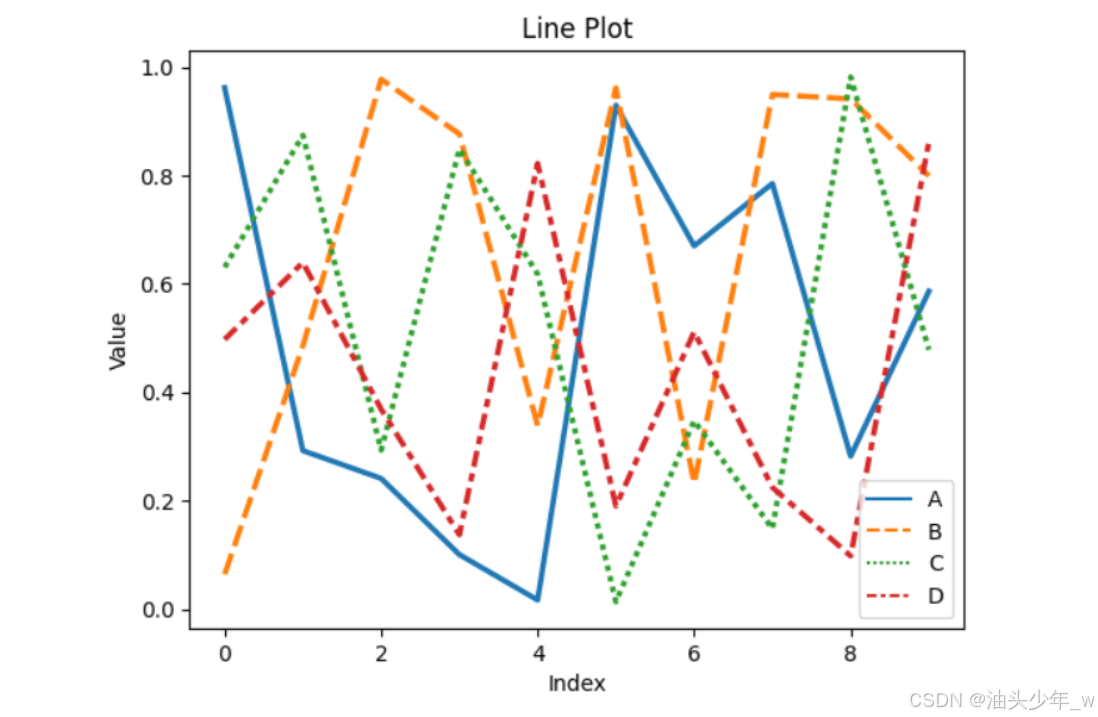
-
柱状图
# 示例数据 data = { 'product': ['A', 'B', 'C', 'D'], 'sales': [350, 420, 300, 500] } df = pd.DataFrame(data) # 创建条形图 ax = sns.barplot(x='product', y='sales', data=df, palette='Blues') # 在每个柱形上显示数值 for i in ax.patches: ax.text(i.get_x() + i.get_width() / 2, i.get_height(), f'{int(i.get_height())}', ha='center', va='bottom') # 添加标签和标题 plt.xlabel('Product') plt.ylabel('Sales (units)') plt.title('Sales of Different Products') # 显示图表 plt.show()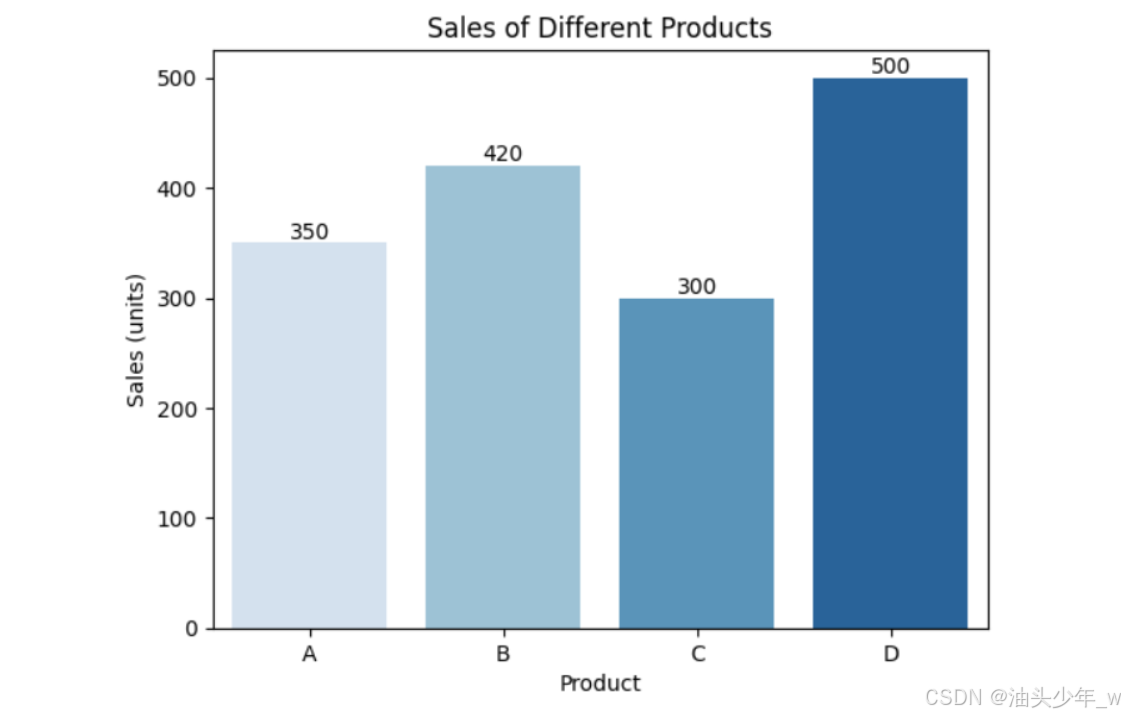
-
散点图
# 示例数据 np.random.seed(0) x = np.random.randn(100) y = np.random.randn(100) data = pd.DataFrame({'X': x, 'Y': y}) # 创建散点图 sns.scatterplot(x='X', y='Y', data=data, hue=data['X'], size=data['Y'], palette='viridis') # 添加标签和标题 plt.xlabel('X') plt.ylabel('Y') plt.title('Scatter Plot') # 负号正常显示 plt.rcParams['axes.unicode_minus'] = False # 显示图表 plt.show()
-
饼图
# 示例数据 labels = ['0-20', '21-40', '41-60', '61+'] sizes = [25, 35, 20, 20] # 表示各年龄段的人口比例 # 创建饼图 # seaborn没有创建饼图的pieplot API plt.figure(figsize=(8, 8)) plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=140, colors=sns.color_palette('pastel')) # 添加标题 plt.title('Population Distribution by Age Group') # 显示图表 plt.show()
-
箱线图
# 示例数据 data = pd.DataFrame({ "day": np.random.choice(['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'], 100), "values": np.random.randint(1, 100, size=100) }) # 创建箱线图 sns.boxplot(x="day", y="values", data=data, palette="Set3") # 添加标签和标题 plt.xlabel("Day of the week") plt.ylabel("Values") plt.title("Box Plot") # 显示图表 plt.show()
-
热力图
# 示例数据 data = np.random.rand(10,10) # 创建热力图 sns.heatmap(data, cmap="YlGnBu") # 添加标题 plt.title('Heatmap') # 显示图表 plt.show()
-
-
小结:理解Seaborn绘图使用
#1.seaborn的画图主要是xxxplot.除此之外,可能有些复杂的图形不是这个API,比如heatmap。
【模块三:业务分析指标及方法】
【理解】业务分析:数据指标
-
目标:理解数据指标
-
实施
-
数据指标:用于评估事实的度量值
-
活跃用户指标:一个产品是否成功,如果只看一个指标,那么这个指标一定是活跃用户数
- 日活(DAU):一天内日均活跃设备数(去重,有的公司启动过APP就算活跃,有的必须登录账户才算活跃)
- 月活(MAU):一个月内的活跃设备数(去重,一般用月活来衡量APP用户规模)
- 周活跃数(WAU):一周内活跃设备数(去重)
- 活跃度(DAU/MAU):体现用户的总体粘度,衡量期间内每日活跃用户的交叉重合情况
-
新增用户指标:主要是衡量营销推广渠道效果的最基础指标
- 日新增注册用户量:统计一天内,即指安装应用后,注册APP的用户数。
- today:今天新增用户:新用户 + 老用户
- history:所有出现过的用户ID信息:老用户
- 周新增注册用户量:统计一周内,即指安装应用后,注册APP的用户数。
- 月新增注册用户量:统计一月内,即指安装应用后,注册APP的用户数。
- 注册转化率:从点击广告/下载应用到注册用户的转化。
- DNU占比:新增用户占活跃用户的比例,可以用来衡量产品健康度
- 新用户占活跃用户的比例过高,那说明该APP的活跃是靠推广得来
- 日新增注册用户量:统计一天内,即指安装应用后,注册APP的用户数。
-
留存指标:是验证APP对用户吸引力的重要指标。通常可以利用用户留存率与竞品进行对比,衡量APP对用户的吸引力
- 次日留存率:某一统计时段新增用户在第二天再次启动应用的比例
- 7日留存率:某一统计时段新增用户数在第7天再次启动该应用的比例,14日和30日留存率以此类推
-
行为指标:
- PV(访问次数,Page View):一定时间内某个页面的浏览次数,用户每打开一个网页可以看作一个PV。
- 某一个网页1天中被打开10次,那么PV为10。
- UV(访问人数,Unique Visitor):一定时间内访问某个页面的人数。
- 某一个网页1天中被1个人打开过10次,那么UV是1。
- 通过比较PV或者UV的大小,可以看到用户喜欢产品的哪个功能,不喜欢哪个功能,从而根据用户行为来优化产品
- 转化率:计算方法与具体业务场景有关
- 淘宝店铺,转化率=购买产品的人数/所有到达店铺的人数
- “双11”当天,有100个用户看到了你店铺的推广信息,被吸引进入店铺,最后有10个人购买了店铺里的东西,那么转化率=10(购买产品的人数)/100(到店铺的人数)=10%。
- 在广告业务中,广告转化率=点击广告进入推广网站的人数/看到广告的人数。
- 例如经常使用百度,搜索结果里会有广告,如果有100个人看到了广告,其中有10个人点击广告进入推广网站,那么转化率=10(点击广告进入推广网站的人数)/100(看到广告的人数)=10%
- 淘宝店铺,转化率=购买产品的人数/所有到达店铺的人数
- 转发率:转发率=转发某功能的用户数/看到该功能的用户数
- 现在很多产品为了实现“病毒式”推广都有转发功能
- 公众号推送一篇文章给10万用户,转发这篇文章的用户数是1万,那么转发率=1万(转发这篇文章的用户数)/10万(看到这篇文章的用户数)=10%
- PV(访问次数,Page View):一定时间内某个页面的浏览次数,用户每打开一个网页可以看作一个PV。
-
产品数据指标
- GMV (Gross Merchandise Volume):指成交总额,也就是零售业说的“流水”
- 需要注意的是,成交总额包括销售额、取消订单金额、拒收订单金额和退货订单金额。
- 成交数量对于电商产品就是下单的产品数量,下单就算
- 人均付费=总收入/总用户数
- 人均付费在游戏行业叫ARPU(Average Revenue Per User)
- 付费用户人均付费(ARPPU,Average Revenue Per Paying User)=总收入/付费人数,这个指标用于统计付费用户的平均收入
- 电商行业叫客单价
- 付费率=付费人数/总用户数。付费率能反映产品的变现能力和用户质量
- 例如,某App产品有100万注册用户,其中10万用户有过消费,那么该产品的付费率=付费人数(10万)/总用户数(100万)=10%。
- 复购率是指重复购买频率,用于反映用户的付费频率。
- 复购率指一定时间内,消费两次以上的用户数/付费人数
- GMV (Gross Merchandise Volume):指成交总额,也就是零售业说的“流水”
-
推广付费指标:
-
CPM(Cost Per Mille) :展现成本,或者叫千人展现成本
- 广告每展现给一千个人所需花费的成本。按CPM计费模式的广告,只看展现量,按展现量收费,不管点击、下载、注册。一般情况下,APP启动开屏,视频贴片、门户banner等非常优质的广告位通常采用CPM收费模式。
-
CPC(Cost Per Click) 点击成本,即每产生一次点击所花费的成本
- 典型的按点击收费的模式就是搜索引擎的竞价排名,如谷歌、百度、360、搜狗的竞价排名。在CPC的收费模式下,不管广告展现了多少次,只要不产生点击,广告主是不用付费的。只有产生了点击,广告主才按点击数量进行付费
-
按投放的实际效果付费(CPA,Cost Per Action)包括:
- CPD(Cost Per Download):按App的下载数付费;
- CPI(Cost Per Install):按安装App的数量付费,也就是下载后有多少人安装了App;
- CPS(Cost Per Sales):按完成购买的用户数或者销售额来付费。
-
-
不同的业务可能关心的指标不尽相同
-
-
**小结:**理解数据指标
上述只是极个别行业,如果需要参考其他行业,可以访问神策数据官网:
https://www.sensorsdata.cn/target_disassembly.html
【理解】业务分析:分析方法
-
目标:理解业务分析的分析方法
-
实施
-
问题1:如何选择指标?
-
两个原则:
-
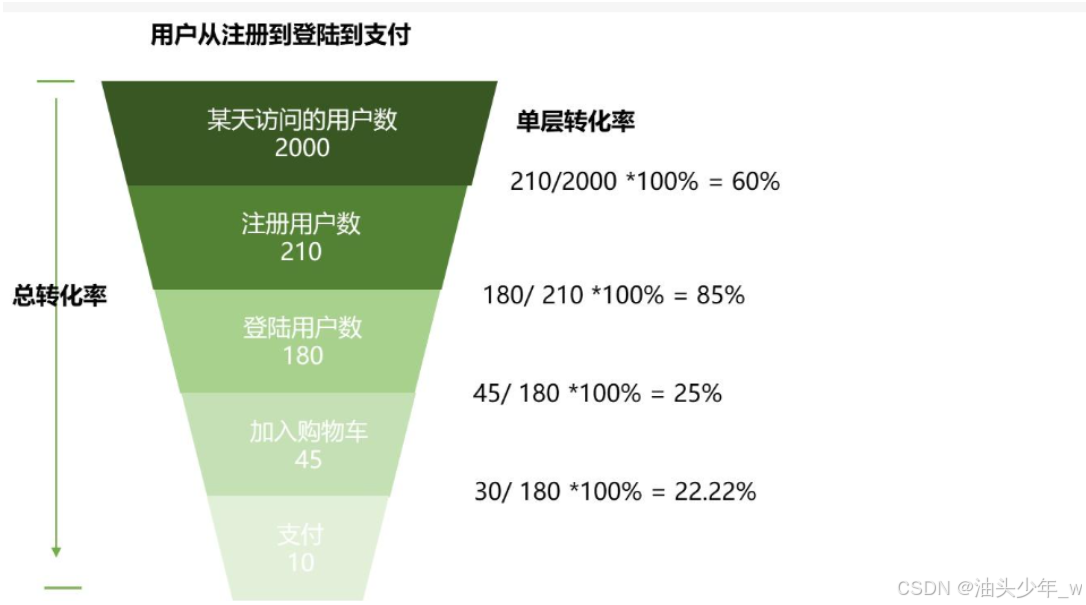
1、好的数据指标应该是比率型指标
- 公众号打开次日文章用户数(活跃用户数)是1万,让你分析公众号是否有问题。这其实是看不出什么的
- 总粉丝量是10万,那么可以计算出次日活跃率=1万(活跃用户数)/10万(总用户数)=10%
- 和行业平均活跃率(公众号的平均活跃率是5%)比较,会发现这个公众号活跃率很高。
-
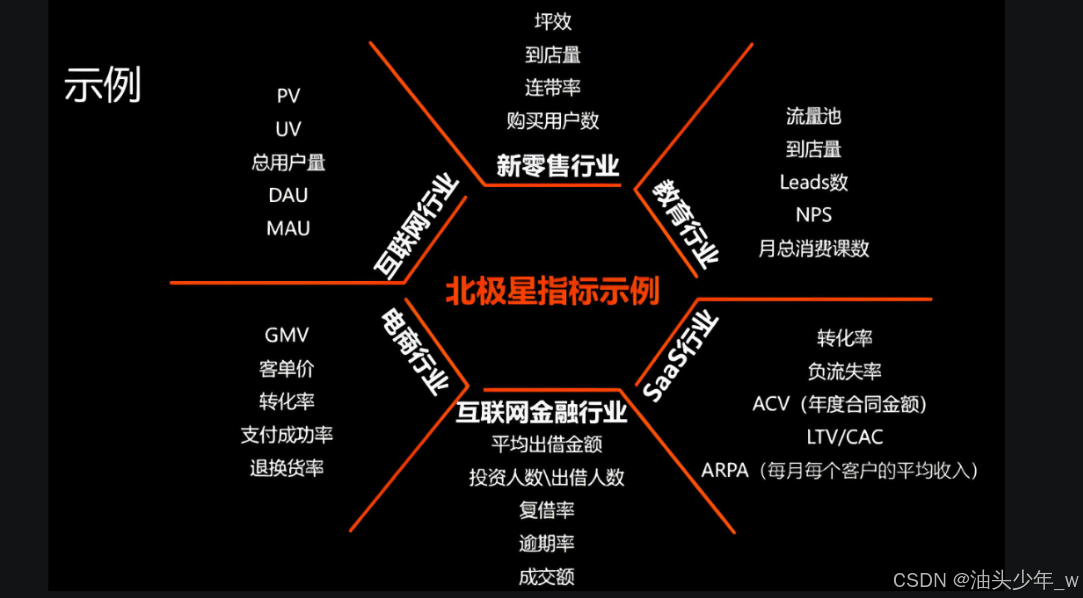
2、根据目前的业务重点,找到北极星指标
- 在实际业务中,北极星指标一旦确定,可以像天空中的北极星一样,指引着全公司向着同一个方向努力
- 根据目前的业务重点寻找北极星指标:
- 北极星指标没有唯一标准。不同的公司关注的业务重点不一样
- 同一家公司在不同的发展阶段,业务重点也不一样
-
-
问题2:电商业务中常见的指标有哪些?
从用户和商品这两个电商分析绕不开的模块入手,结合商家视角,了解电商分析的基础指标。7.3.1 用户相关指标对于用户指标,从用户购前、购中和购后三个阶段来看,会更加清晰。
1.购前(下单前)
-
访客数:同UV(Unique Visitor),统计周期内访问店铺的去重人数。每个用户都有一个唯一识别ID,统计周期内用户多次访问最终会去重,只统计一次。
-
浏览量:即PV(Page View),在电商平台一般代表统计周期内用户访问店铺的次数,如近一周有10000个用户访问店铺50000次。
-
平均停留时长:所有访客总停留时长/访客数。常用来看商品维度,即某商品平均每一个访客的停留时长。
-
加购、收藏人数:统计周期内产生加入购物车或收藏行为的去重人数。
-
访问加购转化率:统计周期内加购人数/访问人数。例如,1月份有10000个访客,其中有2000人在1月份有加购商品的行为,对应的访问加购转化率=2000/10000=20%。
2.购中(下单时)
-
支付人数:也叫作购买人数,是统计周期内有付款行为的去重人数。
-
支付件数:和销量同义,统计周期内用户完成支付的商品数量。
-
支付金额:也叫作销售额,是用户实际支付的金额,需要注意的是支付金额包含退款。如1月份用户支付了100万元,其中有10万元相关用户最终退款,但支付金额的统计仍是100万元。
-
支付转化率:统计周期内支付人数/访客数,意思是访客转化为买家的比例。这是一个重要的衡量流量效率的指标。在电商语境下,常说的转化率就是支付转化率。
-
客单价:支付金额/支付人数,平均每个购买的用户会花多少钱。
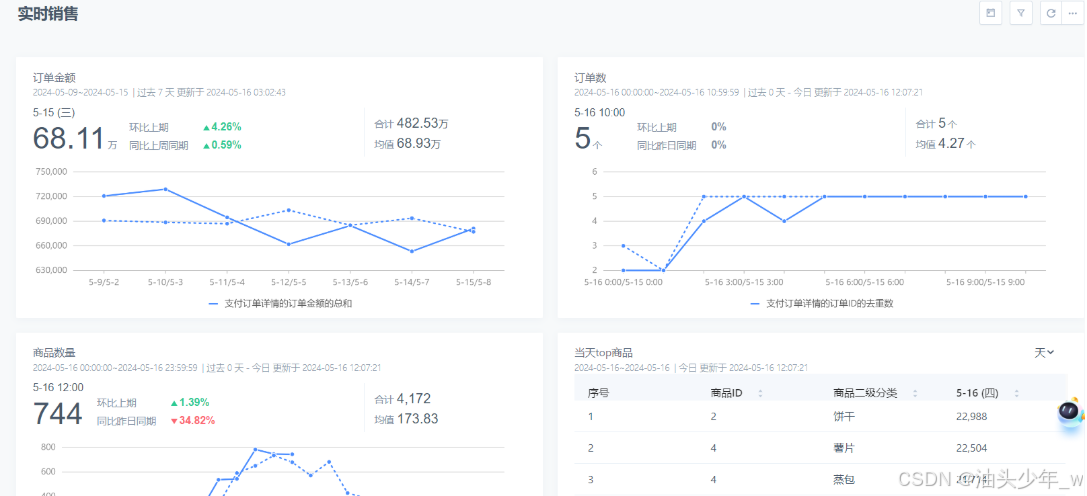
3.购后(下单后)
-
退款率:一般是子订单的维度,用户一次购买A和B两种商品,从子订单的角度A和B分别会生成一行数据记录(子订单)。退款率则是统计周期内成功退款的订单数/总订单数。
-
客诉率:产生投诉行为的购买人数/购买人数。
-
评价率:给出评价的购买人数/购买人数。
-
差评率:给产品差评的购买人数/给产品评价的购买人数。
-
复购率:统计周期内购买2次及以上的购买人数/统计周期内的购买人数
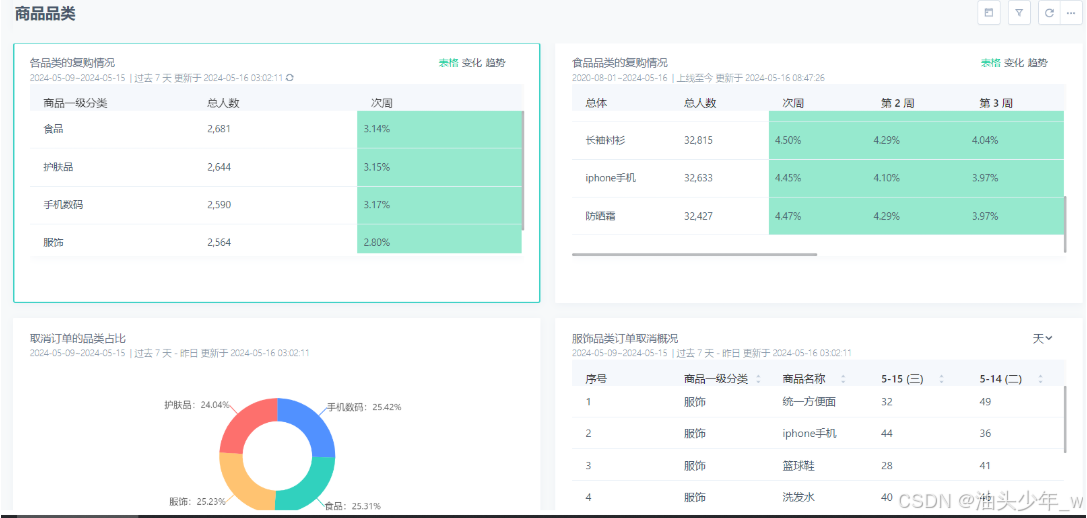
商品相关指标
商品和用户分析密不可分,上面讲的几乎所有用户指标在大多数情况下都需要结合商品维度,聚焦到某个品类或者某个商品做交叉分析。这里主要补充容易引起混淆的与商品相关的概念和拓展指标。
-
SPU:Standard Product Unit,商品聚合信息的最小单位。例如,一部iPhone 18就是一个SPU。
-
SKU:Stock Keeping Unit,商品不可再分的最小单位,往往对应到商品具体的规格。iPhone 18是一个SPU,但如果要到SKU的维度,还需要更加明确。例如iPhone 18黑色128GB版本,它无法进一步细分,是一个SKU。
-
动销率:统计周期内有销量的SKU数/总SKU数。假设1月份店铺总共有100款产品(SKU),其中88款有销量(至少卖出1件),则动销率=88/100=88%。
-
售罄率:统计周期内产品的销量/产品总的进货量。例如,A产品进货10000个,实际卖出6000个,售罄率=6000/10000=60%。
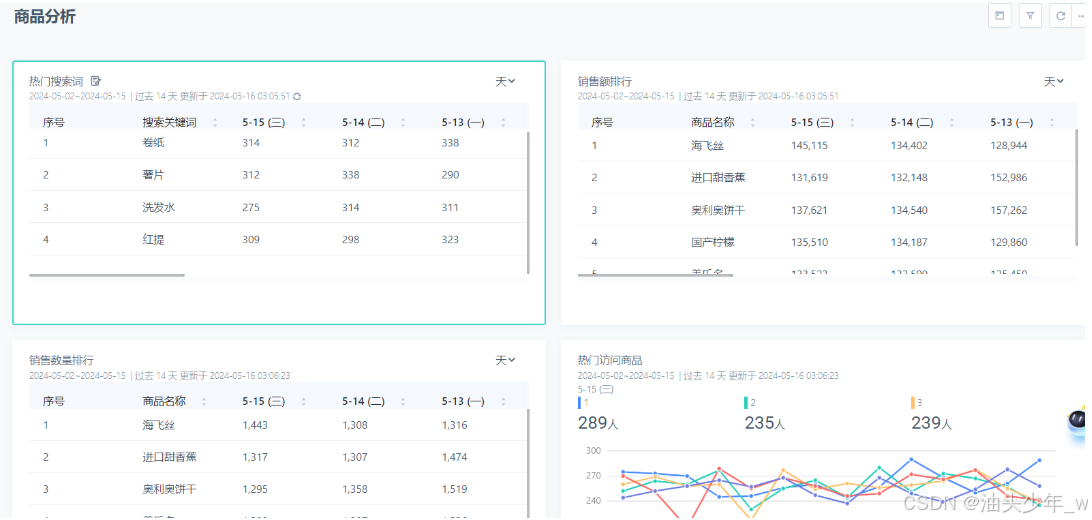
-
-
问题3:在企业中具体会对哪些业务板块做分析?
行业趋势分析
很多时候选择大于努力,找到一个有潜力的朝阳行业,就相当于找对了风口,稍加努力便能乘风而起。行业趋势分析,从行业规模、行业增速、增长驱动因素、利润情况和宏观趋势等几个方面,帮助我们识别潜力行业。
1.行业销售规模
- 从销售规模可以看出行业是否值得进入。
- 行业规模不能太小,如果某行业一年只有100万元销售额,那么就算做到行业第一,盈利空间也十分有限。
- 行业规模过大,往往意味着竞争激烈,需要结合增速综合考量。
2.行业销售增速
- 行业规模尚可,则要重点关注行业每年的销售增速。
- 一个规模很大但连续几年负增长的行业,很可能是一个处于衰退期的夕阳行业。行业销售增速一定程度上和行业所处阶段(初创、成长、成熟、衰退)挂钩。
3.行业销售增长驱动因素
- 在行业销售增速基础上,可以把销售增长进一步拆解为用户数、用户人均频次、次单价三个维度
- 行业增长到底是因为有更多的人来买,用户买得更频繁,还是用户消费升级、买得更贵?
- 通过对增长的分解,能够形成对行业增长趋势的更细致的感知,甚至可以预判未来增长趋势和潜力。
4.行业利润情况
- 行业的利润情况和利润结构决定了,100万元的销售额带来的利润是30万元还是3000元,也影响了能够花多少钱来做推广和促销。
5.行业宏观趋势
上面几个问题是从可量化的角度展开的,行业分析有时也需要更宏观的视角来辅助。例如经典的PEST分析,综合考察行业的政治、经济、社会、技术趋势变革等因素。宏观框架分析的优点是高屋建瓴,考虑大方向和行业变革,缺点则是非常考验分析者的功底,稍不注意就会变成生搬硬套的八股文。
竞争格局分析
对于行业规模和整体走势有了初步的认知后, 要对行业内部的竞争情况进行分析。
1.行业集中度
行业集中度是关于行业垄断程度的分析,行业集中率CRn是衡量行业集中度的一个很好的指标
- CRn表示行业前n个品牌的市场占有率之和。例如某行业最近一年CR3=90%,表示该行业前3个品牌的销售额之和占据了整个行业的90%。行业集中率越高,往往意味着新势力进入难度越大。
2.行业集中趋势探究
- 某行业2022年CR5=50%
- 该行业2021年前5个品牌总共只占据了10%的市场份额,一年时间CR5从10%→50%,说明行业资源在快速向头部品牌集中。
3.垄断真伪判别
-
CR5=90% 是否有机会?
-
头部企业是否出名?行业规模大不大?
品牌策略探究
在竞争格局分析中,已经占据领先地位的头部品牌的发展历程和关键策略对于后进入者有极高的借鉴意义。
1.品牌背景研究
通过对公开资料的收集和研究,对头部品牌的发展历程、关键节点、团队背景等信息做一个初步了解。
2.渠道布局策略
- 有不少品牌在天猫渠道做品牌,维持产品高价作为价格标杆,通过其他渠道的相对低价来完成销售目标。
- 品牌是否在京东、拼多多、抖音或线下销售
- 各渠道的销售规模占比怎样,到底哪个或者哪些才是品牌重点发力的渠道
3.流量来源分析
- 站外(电商平台内)投放了多少偏品牌、产品宣传种草类的广告,这些会影响消费者认知;
- 站内(电商平台内)的流量分析,即品牌流量以免费还是付费流量为主,付费流量又是如何分配的,具体效率如何,等等。
4.货品策略
- 以单品类为主还是多品类全面开花?
- 核心产品定位是高端、中端还是低端?
- 不同产品的独特竞争力是什么?
- 产品在不同渠道销售是怎样做差异化和价格管控的?
5.供应探究
任何品牌的产品都要经历研发、生产与销售三个主要阶段
- 头部品牌的产品研发、生产环节是自主还是交给工厂来做
- 主要供应商有哪些
- 在供应链上有什么优势可以借鉴?
用户分析
用户分析可以分为两个阶段,第一阶段是创立品牌、的探索期,第二阶段则以用户为主线,从拉新和复购两个方面串起运营整体策略。
1.用户心智占领情况
- 假设有1000个人是通过搜索关键词来浏览和购买产品的,其中有800个人的搜索词带有具体的品牌名
- 用搜索词带有具体品牌的人/总体搜索人数,即800/1000=80%,得到一个简单便捷来衡量品牌用户心智占领情况的指标
- 这个指标可以用来辅助衡量行业进入门槛是否够高。
2.用户画像分析
- 在探索期,分析头部品牌的人群定位和用户画像,
3.用户反馈挖掘
用户评论中蕴藏着的信息常被低估。用科学合理的方式对评论进行分句和情感判断后
- 正面可以量化且提炼消费者对产品、店铺、品牌提及最多和最满意的地方
- 负面能够对用户差评点做精准排序,产品、物流、客服、营销哪方面被用户吐槽最多,
1.拉新策略
拉新的使命是以更低的成本获取更多高质量的新客,听起来有点“既要、又要、还要”的感觉,但在实际商业环境中就是这样,目标总是不能打折扣的,资源总是紧缺的。
(1)用什么方式
选择合适的方式与渠道对新用户的获取非常重要。目前常见的拉新方法
- 诸如付邮费领取试用,9.9元或19.9元试用装
- 入会即享20元无门槛限时优惠券等
- 主要通过拉低购买门槛,降低用户决策成本,起到消费临门一脚的作用。作为决策者,在各种方式尝试之后,结合拉新成本(平均拉来一个新客花多少钱),评估不同方式、渠道获取新用户的规模和ROI(投入产出比),找到成本可控且新客质量稳定的方式。
(2)用什么产品
- 低单价的产品选择成本低,拉新效率更高,在同样的时间里可以拉取更多的新客,但会存在相当一部分“薅羊毛”的用户
- 高单价产品不容易拉取大规模新客,但新客质量稳定。对于特殊行业(如母婴用品),由于用户购买周期有限,品牌一般通过较早期的产品(比如孕妇用的待产包)来筛选出高质量用户
(3)拉来什么样的用户
我们希望拉来高价值的用户,但什么样的用户才是高价值的用户?
- 新用户的用户画像与品牌核心用户是否匹配,例如核心用户定位是18~24岁、一线城市、高消费力(月均在天猫上消费10000元以上),理想情况下招募来的新用户也应该符合这个分布。
- 追踪新用户交易数据,如通过同期群分析统计新用户首单消费客单价,后30天、60天、90天回购率,回购客单价等关键指标,拉长时间段来看新用户整体贡献金额是否符合高价值的标准。
2.复购策略
(1)会员体系
一个优秀的会员体系可以显著提升用户对品牌的忠诚度,促进用户生命周期价值的提升。
- 会员应该划分为几个等级?
- 每个等级门槛值怎样制定才合理?
- 同一等级的会员是否应该差异化对待?
- 会员体系的资金投入和预期产出是怎么样的关系?
- 只有这些关键问题基于数据找到了答案或者方向,才算是好的会员体系。
(2)购买行为分析
根据已经积累一段时间的用户交易数据,挖掘用户购买行为的魔法数字。例如某公司发现:
- 对购买A商品的用户,在其签收后7天通过短信和站内提醒推送B商品的定向优惠券,可以有效提升用户复购率
- 在90天内促进用户购买4次,用户生命周期能够显著延长
- 这些魔法数字结合具体的用户购买行为,能够挖掘出非常丰富的信息,给CRM策略制定指明方向,提升用户复购率。
(3)关联渗透购买
- 常规的关联购买算法用来发现用户在购买A商品的同时购买什么商品概率更高。
- 发现这些规律之后,可以通过目标商品组合优惠、页面关联展示、客服推荐等形式有效提升用户购买数量和购买金额。
- 在此基础上,还有延伸的关联购买分析,可以分析买了A商品的用户,后续复购什么商品的概率更高,这种上下游关联分析结果对于用户精准触达有很大帮助。
- 通过分析购买规律,引导用户向高留存的购买模式靠近,最终提升用户的购买次单价和黏性。
-
问题4:常见的数据分析的手段有哪些?
-
黄金公式:销售额= 访客数×转化率×客单价
(1)结合对比思维当拿到这样一组数据:2023年A品牌销售额为2000万元,访客数为400万,转化率为5%,客单价为100元。我们大概率对这几个指标背后的意义是没有感知的,但是可以从几个方面进行对比
维度 访客数 转化率 客单价 销售额 实际 23年实际 400万 5% 100 2000万 与目标对比 22年目标 250万 8% 90 1800万 与某周期对比 22年实际 200万 9% 80 1440万 与竞品对比 23年竞品实际 500万 5% 150 3750万 -
和目标对比:转化率未能达到预期,但因为流量有较大提升,2023年还是超额完成了销售额目标。
-
和某周期对比:2023年实际较2022年也有很大提升,2023年的流量是2022年的两倍,客单价也提升了25%。
-
和竞品对比:虽然和过去同期、和目标对比都超额完成,但是2022年规模和我们差不多的竞品,2023年销售额高达3750万元,且访客数和客单价均显著领先,需要密切关注并研究竞品的策略。
结合拆分思维
总体指标往往看起来比较模糊,带有迷惑性。拆分思维则是把指标按照更细的维度进行拆分,往往会结合对比思维一起应用。对于上面的案例,我们可以把销售额拆分成免费部分和付费部分
- 销售额= 免费流量访客数×转化率×客单价 + 付费流量访客数×转化率×客单价
拆分后分别分析免费、付费流量的结构和核心指标的变化,找到影响总体的关键因素。
还有其它拆分方法是从品类或产品的角度拆分,因为定位到具体的产品,相关的运营策略和动作会更加具体,也更明确后续应该如何调整以提升销售额。
-
-
GROW
GROW也是关于销售拆分的方法论。黄金公式基于流量和货品,关注的重点是用什么方法与资源完成阶段性销售目标;而GROW以用户为核心,通过对用户更细致的洞察找到并把握品牌生意的机会点。
1.什么是GROW
品牌销售的增长或下降到底是由什么导致或驱动的?这是品牌在复盘时要思考的核心问题之一。如果一个问题很大,且无法很好地量化,就必然会引起争论。复盘经常会变成各部门邀功或甩锅的大会,有了成绩是自己未雨绸缪、运筹帷幄,出了问题则是兄弟部门急功近利、考虑不周。至于后续如何改进,倒成了次要问题。
GROW由阿里巴巴提出,把品牌销售增长的驱动力分解为四大要素,分别是渗透力(G)、复购力®、价格力(O)和延展力(W)。以“人”的视角,对销售进行更细致的拆解,帮助品牌识别和量化增长来源,对各方面查漏补缺,明确接下来要改进的方向。它的具体定义如下。
- 渗透力(Gain):更多的购买人数对总增长的贡献。
- 复购力(Retain):用户更高频次的购买对总增长的贡献。
- 价格力(bOost):用户购买更高价格的产品对总增长的贡献。
- 延展力(Widen):品牌提供与现有品类关联的其他类型产品对总增长的贡献。
2.GROW的计算逻辑
GROW的本质是对销售额波动的解构,而销售额可以拆解成购买人数、人均购买次数、每次买多少钱三个部分
- 销售额=购买人数×人均频次×次单价,进一步细分得到GRO的具体数值。
举一个具体的案例,我们要看2023年相对于2022年销售变化的GRO拆解,计算逻辑如下
-
G:购买人数促进(2023年购买人数-2022年购买人数)×2022年人均频次×2022年次单价。
-
R:人均频次促进(2023年人均频次-2022年人均频次)×2023年购买人数×2022年次单价。
-
O:次单价促进(2023年次单价-2022年次单价)×2023年购买人数×2023年人均频次。
不难发现,GRO最终可以把两年销售额的波动拆分成每个指标对销售额波动的贡献上。
案例数据中,购买人数(G)增长的贡献是58%,人均频次®提升的贡献是16%,次单价(O)上涨的贡献是26%,三者之和正好等于100%。
3.GROW的应用
1)找到并强化增长的驱动因素。品牌通过GROW公式,计算出GRO三个指标分别对自身销售增长的贡献,明确品牌增长驱动的来源及其重要程度,强化主要驱动因素。同时,结合积累的行业大盘数据或者官方公布的行业榜单,按照同样的逻辑计算行业关键驱动指标,并参考行业GROW值做调整。例如,对于本品牌而言,G指标对销售额增长的贡献是58%,是品牌增长最重要的来源,如果接下来要继续保持增长,这驾马车一定要保持。但我们也发现行业的增长驱动和品牌差异很大,行业GRO的具体数值是G为10%,R为30%,O为60%,这意味着行业增长受人数上涨影响较小,主要由次单价的提升驱动。行业趋势如此,给本品牌两点启示:一是靠购买人数驱动增长的方式可能会不再有效;二是要密切关注次单价趋势,结合自身情况探讨次单价提升的可行性及方案。
2)用GROW指导运营动作。针对不同的维度,可以采取不同的策略,以下是几个参考方向。
-
提升G:做好内容“种草”和宣传,为品牌认知兴趣人群蓄水;用派样等拉新方式获取更多的新客。
-
提升R:制定会员和老客召回体系,定期唤回老客;引导用户跨品类购买,让买了A品类的用户再购买B品类。
-
提升O:产品功能升级及价格提升,产品组合套装开发。
-
提升W:分析现有品类及新兴品类机会,拓展新的品类。
-
AIPL:为了让品牌能够更好地把控用户的每个阶段,更精细化地运营自己的用户资产,阿里巴巴提出AIPL分析框架并不断普及,把用户和品牌的交互细分到认知(A)、兴趣(I)、购买§、忠诚(L)四个阶段,帮助品牌全链路追踪用户。
1.什么是AIPL:AIPL来源于4个单词的首字母,对应着4个阶段的人群。
-
A(Awareness):认知人群,即用户对品牌产生了认知。可能是品牌投放了大量广告,让从来没听过、见过的人看到。
-
I(Interest):兴趣人群,用户对品牌有了进一步的兴趣并有一些主动行为,包括但不限于用户主动搜索、点击浏览、收藏加购品牌相关的商品。
-
P(Purchase):购买人群,这一阶段很明确,表示用户购买了品牌相关的商品。
-
L(Loyalty):忠诚人群,对品牌已经建立起好感和信任,具体表现可以是购买之后主动好评,也可以是多次购买或者向朋友分享。
与AIPL概念相匹配的是阿里巴巴的数据银行工具。在数据银行中,品牌可以很容易地看到不同时间段AIPL人群资产总量,每个细分状态下的人群数量、用户关系加深率等数据。
2.AIPL的应用
1)人群资产规模分析。
- 品牌既可以拉长时间范围,分析AIPL人群资产的变化趋势
- 发现人群资产总量及AIPL每个阶段人群数量的波动异常并查明原因,
- 和行业优秀标杆相比,明确自己的人群资产量级和结构处于什么位置
2)人群流转问题诊断。
- AIPL之间存在着丰富的流转关系
- 认知可以转为兴趣,兴趣可以转为购买,购买则可以转为忠诚
- 品牌需要定期分析每个阶段或跨阶段人群的流转率是否存在问题
- 若存在问题则要找到背后的原因,并尝试通过不同的策略来提升对应阶段的流转率。
3)目标拆解和追踪
- 根据目标反推AIPL人群资产的缺口
- 公司CEO定下了未来某个时期的销售目标,比如双11销售额达到100亿元
- 基于现阶段和历史几个关键时间段的AIPL人群资产,对应时间段的人群流转率,并结合新老客单等数据,可以反推出要实现这个销售目标,认知、兴趣、购买、忠诚每个阶段的人群存不存在缺口,存在多大的缺口,以及利用哪些经验证相对高效的方式可以补上这些缺口。
- 从现状看目标达成可能性。通过现阶段AIPL人群资产,推断以目前的人群资产规模和趋势,在未来某个时间范围能够实现多少销售额。
-
-
抖音5A与京东4A
京东4A与阿里巴巴的AIPL可谓殊途同归,都根据用户行为把用户细分成不同的阶段。前面已经对AIPL进行了详细介绍,这里我们只需对抖音5A和京东4A的概念做个基本了解。
1.抖音5A:抖音5A对应5个阶段的人群。
- A1(Aware):感知人群,被广告、自然内容、直播等低频曝光、浅阅读的行为。
- A2(Appeal):短期记忆人群,被广告、自然内容、直播等中频曝光、中频阅读和互动行为。
- A3(Ask):深交互人群,被广告、自然内容、直播或搜索等相关内容高频曝光、深度阅读、深度互动行为和主动获取信息的主动行为。
- A4(Act):购买人群,有过购买或被定义为转化的行为。
- A5(Advocate):品牌拥护人群,关注品牌官方账号的粉丝人群。
2.京东4A:京东4A框架对应以下人群。
-
A1(Aware):认知人群,和AIPL中的A(认知人群)很像,都是被动曝光、浅度浏览相关的人群。
-
A2(Appeal):吸引人群,有主动搜索、多次浏览或收藏加购品牌产品等行为的人群。
-
A3(Act):行动人群,即发生购买行为的人群。
-
A4(Advocate):拥护人群,品牌会员或有过复购、好评、分享等忠诚行为的人群。
-
-
-
小结:理解业务分析的分析方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









