







BrainDreamer: Reasoning-Coherent and Controllable Image Generation from EEG Brain Signals via Language Guidance基于语言引导的EEG图像生成
只是为了学习
目录
3.1 Prelimiaries and Background
3.3 Mask-based Triple Contrastive Learning
3.5 Image Generation based on EEG and Texts
4.1 Implementation Details and Benchmark Datasets
4.4.1 Analysis about the Necessity of Textual Guidance Interaction
4.4.2 Explanation about Reasoning-coherent Interaction of EEG-Image Generation
总结
核心贡献:实现语义连贯且可控的EEG到图像生成
方法:
构建EEG-文本-图像三级跨模态映射框架
开发语言指导的跨模态注意力机制
创新点:通过文本提示实现生成图像属性的实时编辑(如"将狗变为猫")
摘要
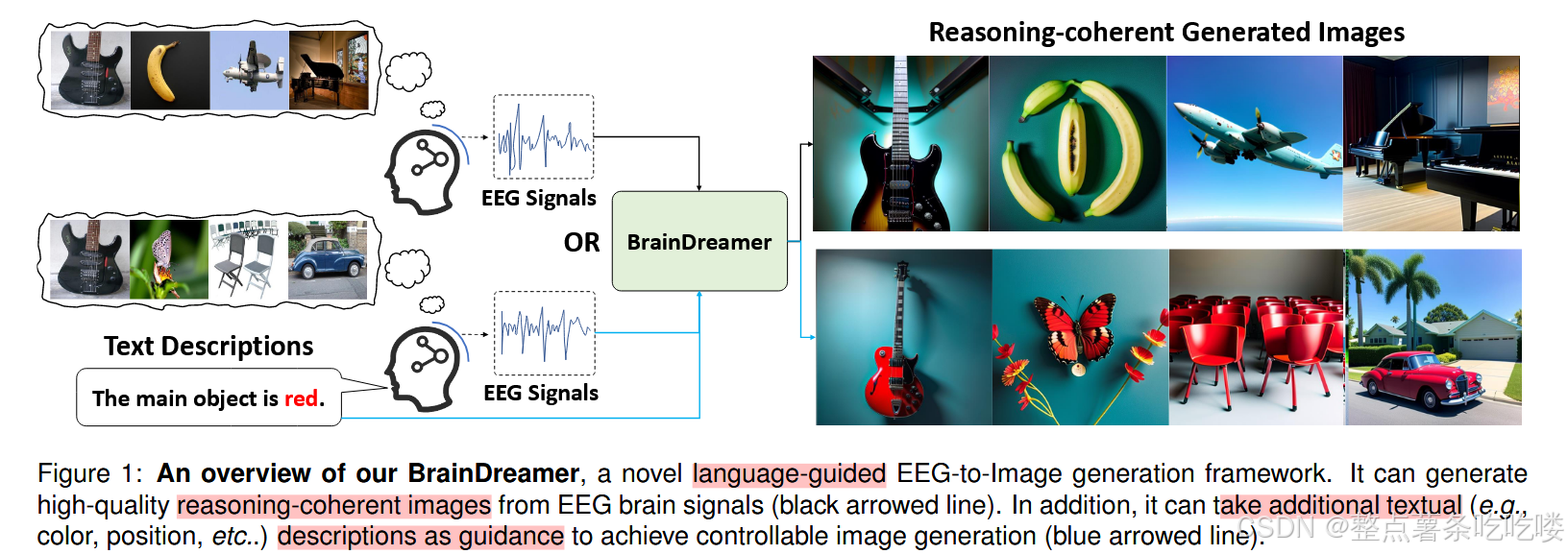
在本文中,我们提出了 BrainDreamer,这是一种新的端到端语言引导生成框架,可以通过模仿人类推理从脑电图 (EEG) 大脑信号生成高质量的图像。具体来说,BrainDreamer 由两个主要的学习阶段组成。 1) 模态对齐,2) 图像生成。 在对齐阶段,我们提出了一种新颖的基于掩码的三重对比学习策略,以有效地对齐脑电图、文本和图像嵌入,从而学习到统一的表征。 在生成阶段,我们通过设计可学习的脑电适配器,将脑电嵌入注入预训练的稳定扩散模型,从而生成高质量的推理相干图像。 此外,BrainDreamer 还能接受文本描述(如颜色、位置等),从而实现可控图像生成。 大量实验表明,我们的方法在生成质量和定量性能方面明显优于之前的技术。
3.1 Prelimiaries and Background
在前向过程中,输入 x0 会在 t 时刻加入方差为 βt∈ (0, 1) 的高斯噪声,从而产生噪声输入。
在取样阶段,"稳定扩散 "还会随机剔除 c,以减少对条件的依赖。 换句话说,预测噪声是根据条件模型 εθ (zt , c,t) 和非条件模型 εθ (zt ,t) 的预测计算得出的:
Diffusion models的原理和公式,记住这个公式2和3,后面这个论文更新了这两个公式。

3.2 Overview
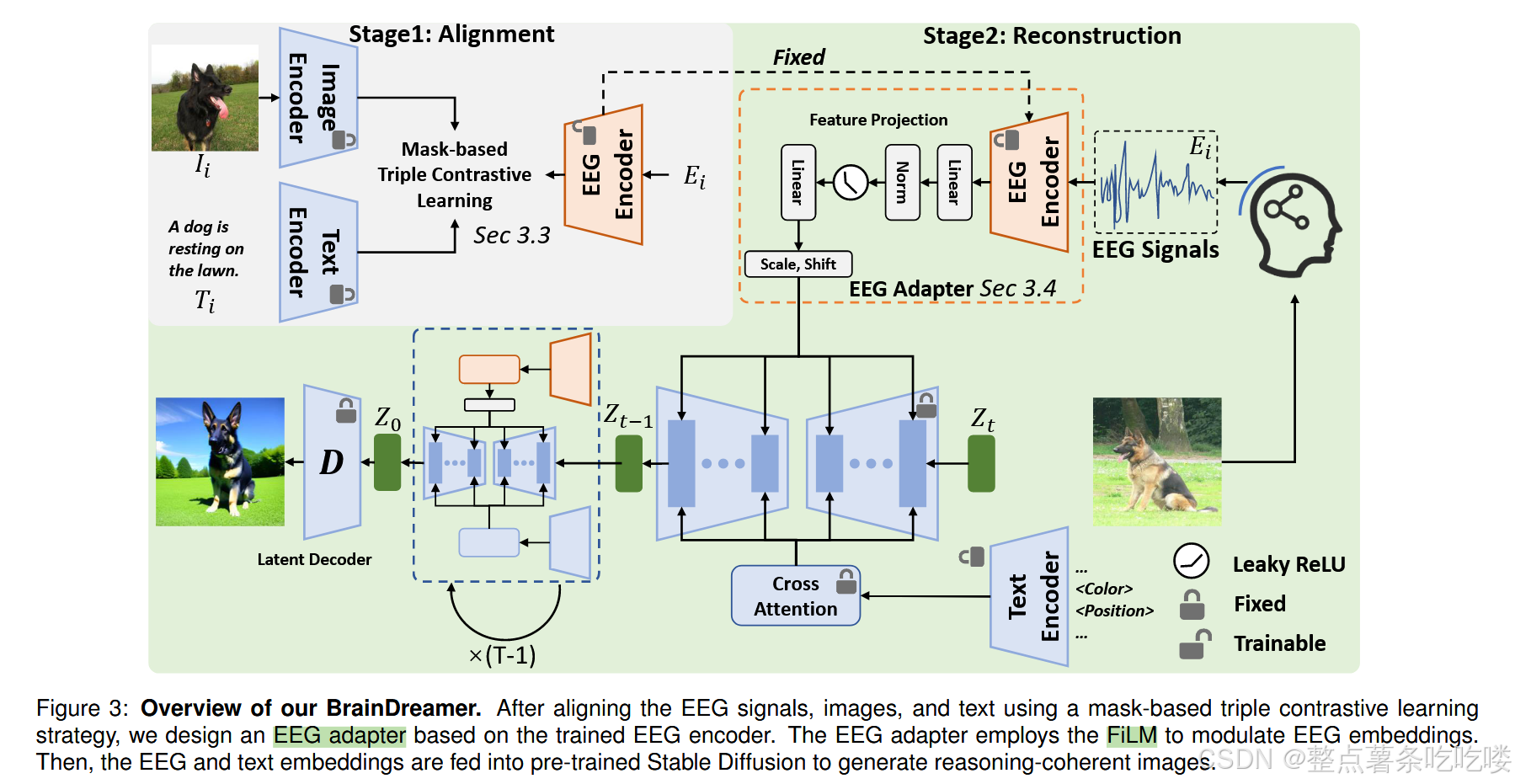
使用基于掩码的三重对比学习策略对脑电图信号、图像和文本进行对齐后,我们设计了基于训练的脑电图编码器的脑电图适配器。 脑电图适配器采用 FiLM 来调制脑电图嵌入。 然后,将脑电图和文本嵌入输入预训练的稳定扩散,生成推理相干图像。
 如图 3 所示,我们的 BrainDreamer 采用两阶段管道,既有效又稳健。 首先,我们利用预训练的 CLIP 图像编码器和文本编码器来帮助我们训练脑电编码器。 我们设计了一种基于掩码的三重对比学习策略(见第 3.3 节),将脑电图嵌入映射到 CLIP 嵌入空间。 随后,我们构建了由脑电图编码器和特征投影模块组成的脑电图适配器(见第 3.4 节),其中脑电图编码器的参数权重保持不变。 脑电图适配器以 FiLM 的方式将脑电图嵌入注入预训练的稳定扩散模型,与常用的交叉注意方法相比,这种方法的计算开销更低。
如图 3 所示,我们的 BrainDreamer 采用两阶段管道,既有效又稳健。 首先,我们利用预训练的 CLIP 图像编码器和文本编码器来帮助我们训练脑电编码器。 我们设计了一种基于掩码的三重对比学习策略(见第 3.3 节),将脑电图嵌入映射到 CLIP 嵌入空间。 随后,我们构建了由脑电图编码器和特征投影模块组成的脑电图适配器(见第 3.4 节),其中脑电图编码器的参数权重保持不变。 脑电图适配器以 FiLM 的方式将脑电图嵌入注入预训练的稳定扩散模型,与常用的交叉注意方法相比,这种方法的计算开销更低。

通过 CLIP 文本编码器提取的文本嵌入和脑电图嵌入都被输入到预训练的稳定扩散中,以实现可控的高质量图像生成。
3.3 Mask-based Triple Contrastive Learning
除图像信息外,我们还结合文本信息,将脑电图嵌入映射到 CLIP 嵌入空间。 我们设计了一种基于掩码的三重对比学习策略,用于嵌入对齐。 给定 EEG 编码器 FE、冻结的 CLIP 图像编码器 FI 和冻结的 CLIP 文本编码器 FT,以及 EEG 信号、其对应的观察图像和相关文本的一批采样三元组(Ei, Ii, Ti),对齐的对比损失表述如下:
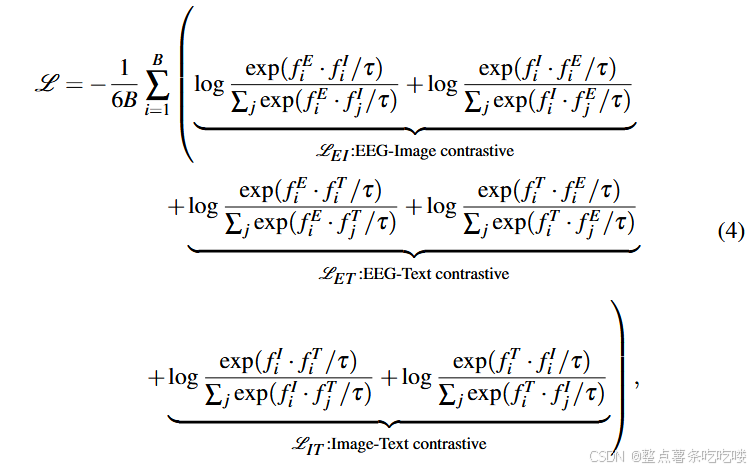
其中,B 是批次中形状的数量;τ 是可学习的温度;fiE = Norm(FE (Ei));fiI = Norm(FI(Ii));fiT = Norm(FT (Ti));Norm 是归一化。 此外,我们还对图像和脑电图数据进行了掩蔽建模。 这不仅增强了特征的鲁棒性,还降低了训练成本。 训练脑电图编码器的目标是最小化 L 。
公式理解,感觉是为了数值稳定性,不是交叉熵:

3.4 EEG Adapter

DreamDiffusion只是简单地将脑电图 嵌入 StableDiffusion的固定交叉注意层,从而生成相应的图像,忽略了脑电图嵌入数据与文本嵌入数据之间的领域差距。
解决:引入特征投影模块


GFLOPs(Giga Floating-point Operations)
-
定义:每秒十亿次浮点运算次数,用于衡量模型的计算复杂度。
-
意义:GFLOPs越高,模型运行所需的计算资源越多(如GPU/TPU时间、功耗)。
为什么Cross-Attention会引入额外计算开销?

3.5 Image Generation based on EEG and Texts
query features指的是输入序列中每个位置的特征向量,用于生成查询向量

公式(8)原来是εθ (xt , c,t),Xt是加了高斯噪声的X0, 现在变成了t时刻的经过autoencoder that converts an image x into a latent z的Zt。
公式(9):EEG embeddings Ce,the text embeddings Ct,原来是C,text prompt。
4 EXPERIMENTS
4.1 Implementation Details and Benchmark Datasets
参照DreamDiffusion中的最佳设置,对参数进行了调整: 脑电图时间序列长度为 512,嵌入维度为 1280,通道为 128。
第一阶段:对EEG encoder进行微调
只更新脑电图编码器的参数,文本编码器和图像编码器在这一步被冻结。
对脑电图编码器的联合微调使其与 普通的 CLIP 模型兼容。
图像和脑电图数据的掩码比率设置为 0.5。
对于 CLIP,我们使用 ViT-L/14 模型提取特征嵌入。 脑电图编码器的架构与 ViT-Large [5] 相同。
生成模型架构: 1.5 版SD。 该模型共有 16 个交叉注意层,每个层添加了一个新的 EEG 适配器。
第二阶段:训练EEG Adapter
使用固定学习率为 0.0001、权重衰减为 0.01 的 AdamW 优化器。
为了实现无分类器引导,使用 0.05 的概率单独丢弃脑电图嵌入和文本嵌入,并使用 0.05 的概率同时丢弃脑电图嵌入和文本嵌入。
无分类器引导
在扩散模型中,无分类器引导通过在训练时随机丢弃条件信息(如文本、EEG信号),使模型同时学习有条件生成和无条件生成的能力。推理时通过调节条件与非条件预测的差异,控制生成结果的方向,无需额外分类器。条件丢弃策略
单独丢弃EEG嵌入的概率为0.05:训练时每个样本有5%的概率仅移除EEG条件,迫使模型学习仅依赖文本生成。
单独丢弃文本嵌入的概率为0.05:同样5%的概率仅移除文本条件,让模型学习仅依赖EEG生成。
同时丢弃两者的概率为0.05:另有5%的概率同时移除EEG和文本条件,迫使模型学习无条件生成(类似生成随机样本)。
保留所有条件的概率为0.85:其余85%的情况下,模型正常使用所有条件信息。
技术实现逻辑
概率分配
上述四种情况(单独丢弃EEG、单独丢弃文本、同时丢弃、全部保留)的概率总和为1(0.05+0.05+0.05+0.85=1),保证每次训练仅应用一种丢弃模式。这种非独立设计旨在显式控制多模态条件的组合影响。训练目标
模型需适应不同条件组合的输入,例如:
当EEG被丢弃时,需依赖文本生成与文本语义一致的输出。
当文本被丢弃时,需从EEG信号中提取特征生成合理结果。
当两者均丢弃时,需进行无条件生成(类似通用样本生成)。
推理阶段的引导
在生成时,通过调节条件与非条件预测的权重(如公式:output = 条件预测 + guidance_scale * (条件预测 - 无条件预测)),增强条件对生成结果的控制力,而无需额外分类器。
应用场景与优势
多模态条件生成:适用于同时依赖EEG(脑电图)和文本输入的任务,例如:基于脑电信号的文本生成、多模态医疗数据分析等。
鲁棒性提升:强制模型在部分条件缺失时仍能生成合理结果,避免过拟合单一条件组合。
灵活性增强:在推理阶段,可通过调整引导因子(guidance scale),动态控制EEG或文本条件对生成结果的影响强度。
示例说明
假设训练一个基于EEG和文本描述的图像生成模型:
正常训练(85%):模型接收EEG信号和文本描述,生成与两者一致的图像。
仅丢弃EEG(5%):模型仅接收文本,生成与文本一致但可能与EEG无关的图像。
仅丢弃文本(5%):模型仅接收EEG,生成反映脑电活动特征但无文本约束的图像。
同时丢弃(5%):模型无任何条件,生成完全随机的图像。
在推理时,通过调整不同条件的权重,可生成既符合EEG特征又贴合文本描述的图像,或偏向某一条件的输出。
在推理阶段,采用 50 步的 DDIiffusiM (Denoising don implicit models)采样器,并将引导尺度 w 设为 7.5。
只使用脑电图提示时,将文本提示设为空,λ = 1.0。
4.4 Disccusion
4.4.1 Analysis about the Necessity of Textual Guidance Interaction
1. EEG与文本的互补性
-
EEG信号的特性:
-
粗粒度信息:反映用户想象的核心主体(如“船”“狗”“猫”),但缺乏细节(颜色、背景)和精确性。
-
直接性:通过脑电设备直接捕捉用户想象的核心内容,无需语言描述。
-
-
文本的特性:
-
细粒度补充:提供背景信息及物体细节(如颜色、纹理),但无法单独确定主体。
-
局限性:用户需主动描述细节,无法直接从大脑中提取核心意图。
-
2. 结合生成图像的逻辑
-
协作流程:
-
EEG捕捉主体:用户想象核心物体 → 脑电设备采集信号 → 生成主体框架。
-
文本补充细节:用户描述颜色、背景等 → 文本输入 → 完善细节。
-
融合输出:生成兼具主体正确性与细节丰富性的图像。
-
-
类比嫌疑犯画像:
-
EEG ≈ 目击者的初步印象(性别、体型等粗粒度信息)。
-
文本 ≈ 逐步细化的细节(五官、发型、服饰等)。
-
两者结合可生成更精准、完整的图像。
-
3. 方法的合理性
-
符合人类认知逻辑:人类想象通常是“先整体后细节”,EEG-文本融合过程模拟了这一认知模式。
-
功能互补:EEG确保主体正确性,文本填补细节缺失,避免单一模态的局限性。
-
应用价值:在脑机接口、辅助设计、心理可视化等领域,可生成更贴合用户心理预期的图像。
4. 实例验证
-
图9示例:
-
仅用EEG生成的图像(前两列)主体正确(船、狗、猫),但颜色和背景错误。
-
结合文本后,图像在主体与细节上均符合用户想象。
-

-
4.4.2 Explanation about Reasoning-coherent Interaction of EEG-Image Generation
EEG-文本融合图像生成方法的推理一致性及其创新性
EEG-文本融合图像生成方法通过模拟人类“从整体到细节”的想象过程,结合EEG的潜意识捕捉能力和文本的有意识描述能力,生成推理一致、细节丰富的图像。这一创新性方法不仅提升了用户体验,还为虚拟现实、个性化创作和认知神经科学研究等领域开辟了新的可能性。
局限性
在图 12 中,我们展示了 BrainDreamer 一些不尽如人意的结果。 虽然这些结果与地面实况的粗粒度匹配程度很高,而且确实与我们的文字描述进行了交互,但它们仍然不完美。 在案例(a)和(b)中,我们的 BrainDreamer 无法识别图像中的主要主体,导致实例不匹配。 特别是在(b)中,墙壁被错误地染成了红色,而不是椅子。 在(c)和(d)中,BrainDreamer 的着色不足,特别是在(d)中,只有一半的蝴蝶是红色的。 这样的图像非常不真实。 将脑电信号与文本描述或其他补充信息相结合,实现实例级图像生成将是我们未来工作的重点。
知识点学习
FiLM
通过外部条件信息(如任务标签、上下文信息等)对EEG embeddings进行动态调整,从而增强模型的表达能力
“保留了特征的局部结构”
是指在使用FiLM(或其他特征调制方法)时,特征的局部空间、时序或通道间的相关性没有被破坏,仅通过线性变换(缩放和偏移)调整特征的强度或分布,而不改变其底层结构。这一特性在信号处理(如EEG、语音)或图像处理中尤为重要。
具体理解
1. 什么是“局部结构”?
-
定义:特征中相邻位置(空间、时间或通道)之间的内在关系或模式。
-
示例:
-
图像特征:卷积特征图中相邻像素的纹理、边缘关系。
-
时序信号(如EEG):相邻时间点的信号连续性、周期性或突发模式。
-
通道间关系:不同脑电通道(EEG通道)之间的协同活动模式。
-
2. FiLM如何保留局部结构?
FiLM的调制方式是逐通道(feature-wise)的线性变换,即对每个通道(或特征维度)独立进行缩放(γγ)和偏移(ββ),而不跨位置或通道混合信息。例如:
-
输入特征:假设EEG信号的特征维度为
[Batch, Time, Channels]。 -
FiLM操作:对每个通道(Channels维度)单独应用 γcγc 和 βcβc,公式为:
Output[t,c]=γc⋅Input[t,c]+βc -
效果:
-
时间维度(Time):同一通道的所有时间点被相同的 γcγc 和 βcβc 调制,时间连续性不变。
-
通道维度(Channels):不同通道的调制参数不同,但通道间的独立性被保留(例如通道1和通道2的关系未被混合)。
-
3. 对比破坏局部结构的操作
-
全连接层(FC Layer):将特征的所有位置或通道混合计算,可能破坏局部相关性。
-
例如,若对EEG信号的所有时间点和通道进行全连接操作,会模糊时序依赖和通道间的固有关系。
-
-
FiLM的优势:仅调整特征的强度和偏移,不引入跨位置或跨通道的交互,因此局部模式(如EEG中的事件相关电位、脑区协同)得以保留。
实例说明
场景:EEG信号处理
-
任务:根据EEG信号识别运动意图(如想象左手/右手运动)。
-
原始特征:EEG信号的特征维度为
[Batch, Time=1000, Channels=64](1000个时间点,64个电极通道)。 -
FiLM调制:
-
条件信息(如任务标签)生成64个γcγc和βcβc(每个通道一对参数)。
-
每个通道的1000个时间点被同一组γcγc和βcβc调制。
-
-
保留的结构:
-
时间局部性:信号在时间轴上的波形(如事件相关电位的上升沿、下降沿)未被破坏。
-
通道局部性:不同电极(如C3、C4对应左右运动皮层)的信号独立性保留,但通过γcγc和βcβc增强了任务相关通道的激活。
-
对比:若使用全连接层调制
-
全连接层可能将64个通道的1000个时间点全部混合,导致:
-
时间维度模糊(例如早期和晚期信号被混合)。
-
通道间关系被强制重构(如C3和C4的信号被加权相加,失去空间特异性)。
-
核心意义
-
保持模型对局部模式的敏感性:例如,EEG中特定脑区的瞬态活动(如α波抑制)或图像中的局部纹理,需要依赖原始结构进行检测。
-
高效的条件注入:通过轻量级的线性变换引入条件信息,避免复杂计算破坏原有特征。
-
可解释性:由于局部结构保留,可以通过分析γcγc和βcβc理解条件信息如何影响特定通道或特征(例如,某些EEG通道可能对特定任务更敏感)。
总结
“保留特征的局部结构”意味着FiLM在调整特征时,仅改变特征的数值分布(如放大重要信号、抑制噪声),而不破坏特征在时间、空间或通道维度上的固有模式。这种特性使FiLM特别适合需要保留原始信号结构的任务(如EEG、语音、视频),同时实现高效的条件信息融合。
learnable temperature
在机器学习中,(可学习温度参数) 是一个通过训练动态调整的超参数,通常用于调节概率分布或相似度计算的“平滑程度”。
温度参数(Temperature)的作用
温度参数最初来源于 softmax函数 的变体,公式如下:
τ > 1:增大温度会平滑概率分布,使各选项的概率更接近(不确定性增加)。
τ < 1:降低温度会锐化分布,概率集中在最大值附近(置信度更高)。
Learnable temperature 是一个通过梯度下降动态优化的参数,用于自适应调节概率分布或相似度计算的平滑程度。它的核心价值在于:
替代人工调参,提升模型对不同任务的适应性。
在对比学习、知识蒸馏等场景中,通过平衡“探索与利用”提升性能。
需注意初始化、数值稳定性和学习率设置,以保证训练效果。
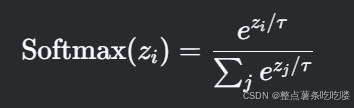
Query(查询)、Key(键)、Value(值)
在深度学习的注意力机制(尤其是Transformer模型中),Query(查询)、Key(键)、Value(值) 是三个核心概念,用于计算输入序列中不同位置之间的关联权重。以下是它们的详细解释和中文对应翻译:
| 英文术语 | 中文翻译 | 核心作用 |
|---|---|---|
| Query (Q) | 查询 | 表示当前需要关注的目标位置(例如,解码器当前要生成的词)。 |
| Key (K) | 键 | 表示输入序列中每个位置的“标识符”,用于与Query匹配相似度。 |
| Value (V) | 值 | 表示输入序列中每个位置的实际信息,最终通过权重加权得到输出。 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









