







线性/非线性卡尔曼滤波 EKF /kalman 微地震数据去躁 数据论文及Python代码`
摘要:研究的背景是针对微型地震数据处理中普遍存在的噪声问题。为了解决上述问题,本文基于线性状态空间卡尔曼滤波(Kalman Filter)和非线性状态空间扩展卡尔曼滤波(Extended Kalman Filter)的方法,开展了对微型地震数据的去噪研究。具体工作包括建立ARMA模型进一步转化为线性化状态空间,并利用卡尔曼滤波算法进行数据优化处理。同时,引入BP神经网络对非线性特性进行建模,利用扩展卡尔曼滤波算法进行数据去噪,探索更适应实际场景的数据去噪方案。
文章目录
微地震数据去噪
微型地震数据去噪作为地震学和地质学中的一个核心研究领域,其重要性不容忽视。随着油气资源勘探开发的不断深入,尤其是向复杂型、隐蔽型、深层和非常规油气藏的转变,对地震数据的质量提出了更高要求。微型地震,尽管震级较小且能量较弱,但因其频繁发生,成为了揭示地下地质构造、岩石物理性质及监测地震活动的关键信息源。
然而,微型地震数据的采集与分析过程充满了挑战。在自然界中,地震台站周围充斥着各种类型的噪声,包括但不限于人工活动(如交通、工业设备运作)产生的噪声、地震仪器自身的噪声以及自然环境中的背景噪声(如风、水流等)。这些噪声源的存在极大地降低了微型地震数据的信噪比,使得地震事件的信号特征被掩盖或扭曲,进而影响到后续的数据分析、震源定位及地下结构成像的准确性和可靠性。
一、模型介绍
1. ARMA时间序列模型
ARMA模型(AutoRegressive Moving Average model),即自回归滑动平均模型,是描述时间序列数据的经典统计模型之一,广泛应用于时序分析和预测中。该模型结合了自回归(AR)和滑动平均(MA)两种成分,用以捕捉时间序列数据中的动态特性和随机波动。
模型形式: ARMA模型可以用差分方程的形式表示为:
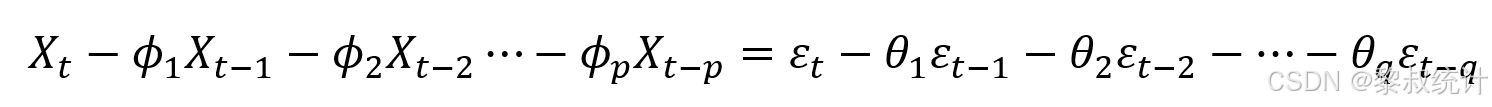
单位滞后算子表示: 将模型表示为单位滞后算子B的形式更加一般化:
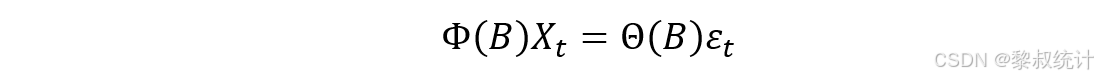
特殊情况: 当输入项的系数theta全部为0时,模型简化为p 阶自回归模型AR(p):
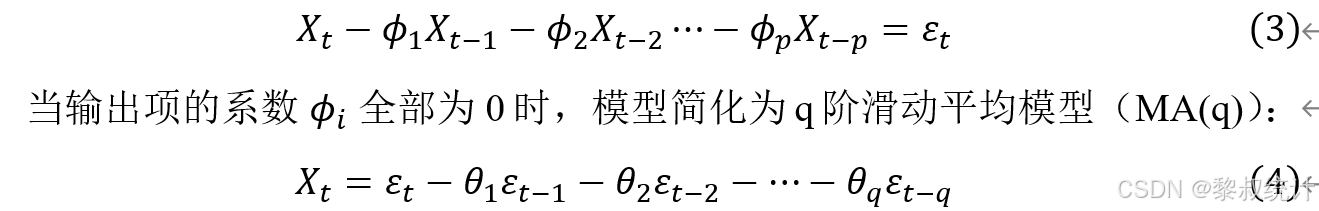
2. 卡尔曼滤波算法
卡尔曼滤波算法(Kalman Filter, KF)是一种用于估计线性离散系统状态的最优滤波算法,最早由R.E. Kalman于1960年提出。该算法假设系统的数学模型和噪声的统计特性已知,并且所有噪声信号服从高斯分布且相互独立。
系统模型: 线性离散系统的状态空间模型如下:
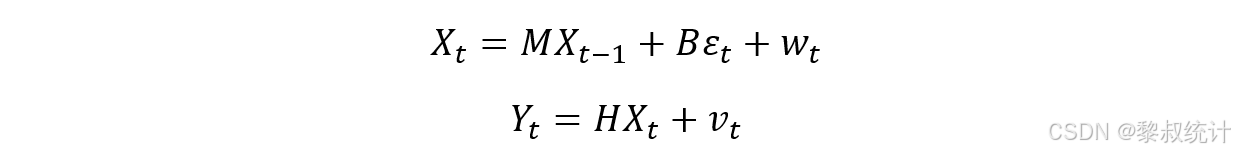

3. BP神经网络模型
Backpropagation (BP)神经网络是一种常见的人工神经网络模型,用于解决分类、回归等问题。它是一种前向传播和反向传播结合的算法,主要用于训练多层神经网络(MLP)。以下是BP神经网络的基本介绍:
BP神经网络由输入层、若干个隐藏层和输出层组成。每个层包含多个神经元(节点),层与层之间的神经元通过权重连接。
前向传播公式:输入数据通过网络从输入层传播到输出层。每一层的神经元接收上一层的输出,并应用激活函数产生输出。具体计算过程如下:
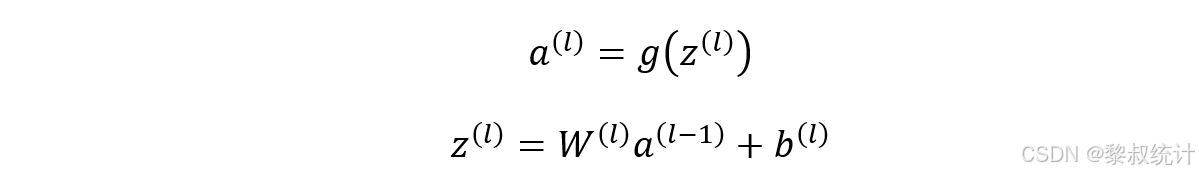
反向传播:反向传播是通过计算损失函数对网络中每个参数(权重和偏置)的梯度来更新参数,以最小化损失函数。具体步骤如下:
计算输出层误差:计算预测输出与真实输出之间的误差。
反向传播误差:从输出层向输入层传播误差,根据链式法则计算每层的误差梯度。
更新参数:根据误差梯度和学习率更新每层的权重和偏置,以减少损失函数。
训练过程:训练BP神经网络通常需要大量的标记数据和多次迭代。通过随机梯度下降(SGD)或其变种来优化网络参数。
4. 扩展卡尔曼滤波模型
扩展卡尔曼滤波(Extended Kalman Filter,EKF)是卡尔曼滤波的一种扩展,用于非线性系统的状态估计。与标准的卡尔曼滤波适用于线性系统不同,EKF通过线性化非线性系统的状态方程和观测方程来处理非线性问题。以下是扩展卡尔曼滤波模型的基本介绍:
基本思想:扩展卡尔曼滤波适用于非线性系统,其核心思想是通过对非线性函数进行泰勒级数展开(通常是一阶泰勒展开),以近似描述系统的非线性行为。通过这种方式,可以将非线性系统转化为线性形式,从而应用标准的卡尔曼滤波算法。
系统模型:状态空间模型通常表示为:
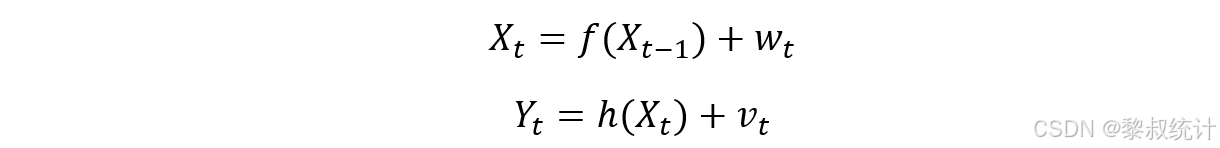
使用泰勒展开将非线性状态方程转化为线性状态方程:

定义

扩展卡尔曼滤波步骤如线性状态空间卡尔曼滤波类似,其基本步骤如下:
首先,根据系统的状态方程和初始状态估计,利用上一时刻的最优状态估计预测当前时刻的状态。这一预测基于系统的动态模型和上一时刻的最优值,构成了初始的状态预测值。
接下来,计算预测误差的协方差,即预测状态与实际测量之间的差异。这个步骤利用系统的动态模型和上一时刻的协方差矩阵,加上系统噪声的影响。
随后,计算Kalman增益,这是一个关键步骤,用于权衡预测值与实际测量之间的差异,以及两者之间的不确定性。Kalman增益根据测量误差的协方差和系统模型的协方差,调整最终的状态估计。
最后,根据Kalman增益调整预测的状态估计值,以及更新当前预测误差的协方差矩阵,以便于下一时刻的迭代更新。这一迭代过程持续进行,通过时间更新和测量更新,逐步优化对系统状态的估计,直至达到滤波算法的终止条件。
二、数据分析
1. 数据来源
本文所用数据来源于2008年四川汶川的微地震数据。地震数据的来源为中国地震台网(China Earthquake Networks Center,CENC)。数据记录的是加速度时间历史,单位为cm/s²,采样点数为25000个,采样时间间隔为0.02秒。数据在处理过程中应用了高通滤波器(截止频率为0.1 Hz)和低通滤波器(截止频率为40.0 Hz),以便于后续地震动分析和工程应用。

代码如下(示例):
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from statsmodels.tsa.arima_process import arma_generate_sample
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.arima_model import ARIMA
from pmdarima import auto_arima
import matplotlib.pylab as plt
import pandas as pd
from statsmodels.tsa.stattools import adfuller
# 读取数据
data = pd.read_csv('D:/汶川地震波.csv')
data.rename(columns={data.columns[0]: 't', data.columns[1]: 'a'}, inplace=True)
# 提取流量数据
series = data['a'][0:1000]
# 执行ADF检验
result = adfuller(series, autolag='AIC')
# 输出结果
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical Values:')
for key, value in result[4].items():
print('\t%s: %.4f' % (key, value))
# 判断平稳性
if result[1] < 0.05:
print("拒绝原假设:数据是平稳的")
else:
print("无法拒绝原假设:数据存在单位根,非平稳")
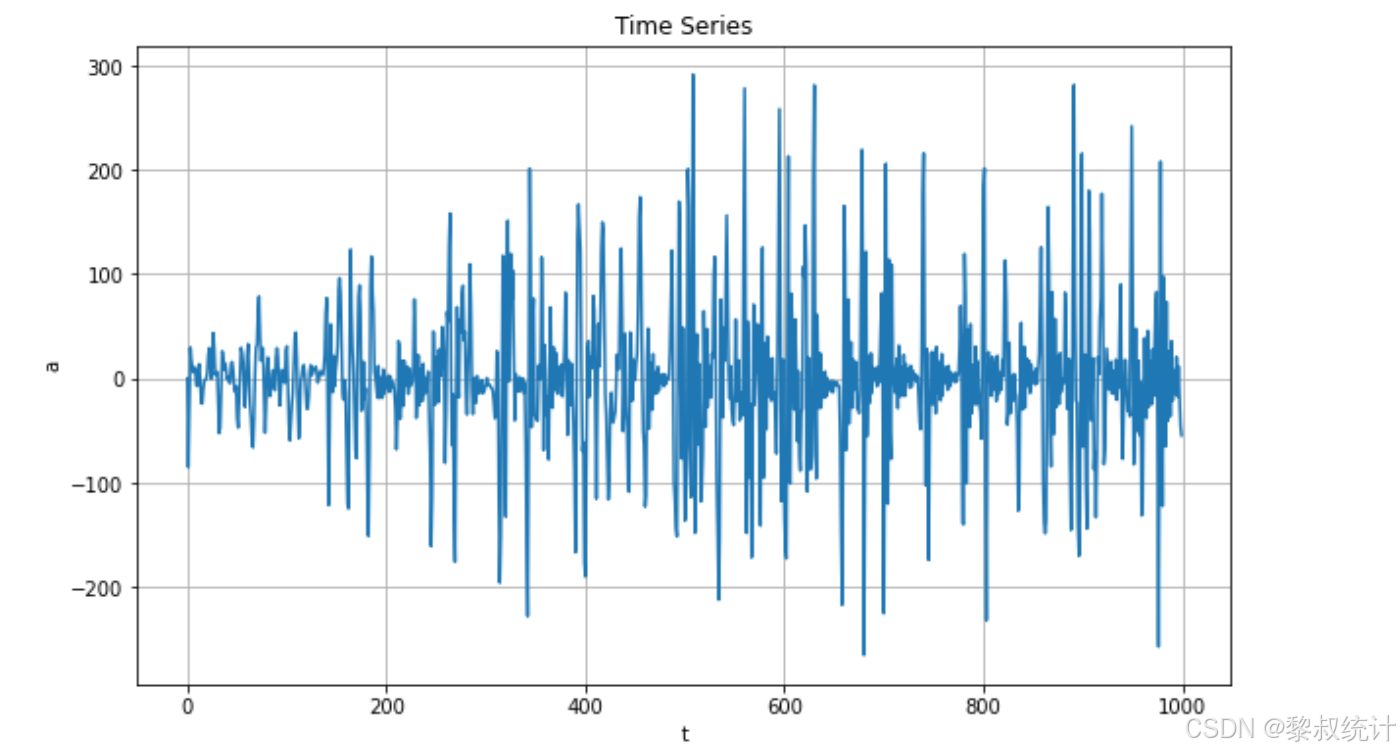
# 绘制时序图
plt.figure(figsize=(10, 6))
plt.plot(series)
plt.title("Time Series")
plt.xlabel("t")
plt.ylabel("a")
plt.grid(True)
plt.show()

2. ARMA-KF模型
2.1 ARMA定阶
将该模型拟合ARMA(1,1)模型
参数估计:常数项 const 的估计值为 920.7023,表示 Nile 数据序列存在一个常值趋势。
AR(1) 参数 ar.L1.Flow 的估计值为 0.8610,表示 Nile 数据序列具有较强的自相关性。
MA(1) 参数 ma.L1.Flow 估计值为 -0.5177,Nile 数据序列存在移动平均成分。
模型诊断:
所有参数p值都小于 0.05 (显著性水平为 5%),AIC 值为 1282.078,BIC 值为 1292.498,表明该 ARMA(1,1) 模型较好地拟合了 Nile 数据序列。
模型的 AR 根和 MA 根都在单位圆内,表示模型是稳定的。
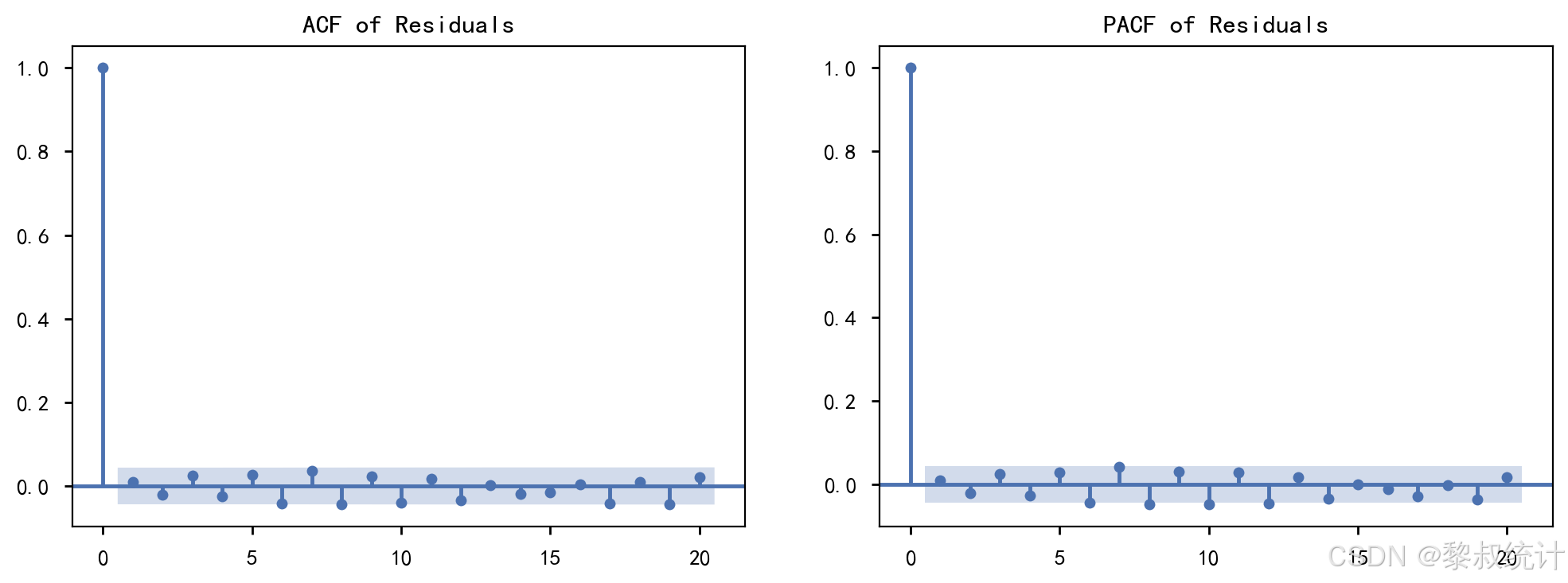
2.2 ARMA-KF

关键代码如下(示例):
import numpy as np
import matplotlib.pyplot as plt
# ARMA(10, 1)模型参数
AR_params = np.array([0.1395,-0.4787,0.2178 ,-0.4998 ,0.2213 ,-0.4897 ,0.1704 ,-0.3027,0.1565,-0.2000])
MA_param = 0.9933
# 状态向量的维度
m = len(AR_params)
# 转移矩阵 M
M = np.zeros((m, m))
M[:, 0] = AR_params
M[1:, 1:] = np.eye(m-1)
# 转移向量部分 beta_t
beta_t = np.zeros((m, 1))
beta_t[0] = 1
beta_t[1] = MA_param
beta_t[2:] = 0 # 确保余下部分为零
# 过程噪声协方差矩阵 Q
Q = 0.01 * np.eye(m)
# 观测矩阵 H
H = np.array([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]]) # 观测矩阵H,根据ARMA参数设置
# 观测噪声方差 R
R = 0.25
# 实际数据
# 读取数据
data = pd.read_csv('C:/Users/卡尔曼滤波/汶川地震波.csv')
# 数据点数量
n = len(data['t'])
# 初始化状态估计和协方差矩阵
x_est = np.zeros((n, m))
P = np.eye(m)
# 执行卡尔曼滤波过程
for t in range(1, n):
# 预测步骤
w_t = np.random.normal(size=m) # 生成大小为 m 的正态分布随机向量
x_pred = M @ x_est[t-1]+beta_t.T @ w_t # 注意:将 w_t 转换为列向量
P_pred = M @ P @ M.T + Q
# 更新步骤
innovation = data['a'][t] - H @ x_pred.flatten() # 计算创新(innovation),确保维度匹配
K = P_pred @ H.T / (H @ P_pred @ H.T + R)
x_est[t] = x_pred + K @ innovation
P = (np.eye(m) - K @ H) @ P_pred
# 绘制处理前后数据对比图表
plt.figure(figsize=(12, 6))
plt.plot(data['a'], label='原始数据')
plt.plot(x_est[:, 0], label='滤波后数据')
plt.legend()
plt.show()
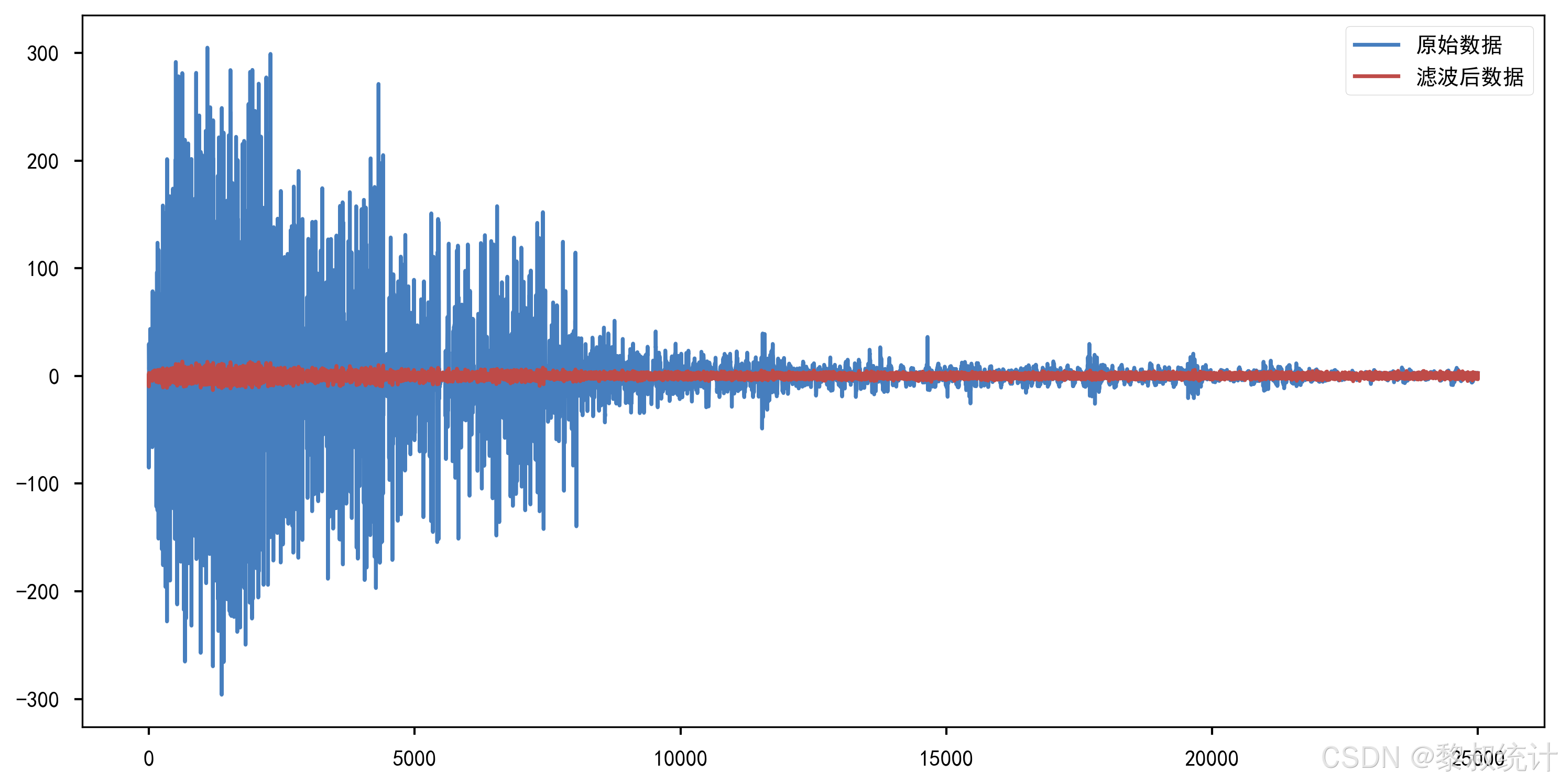
3. BP-KF模型
3.1 BP神经网络训练
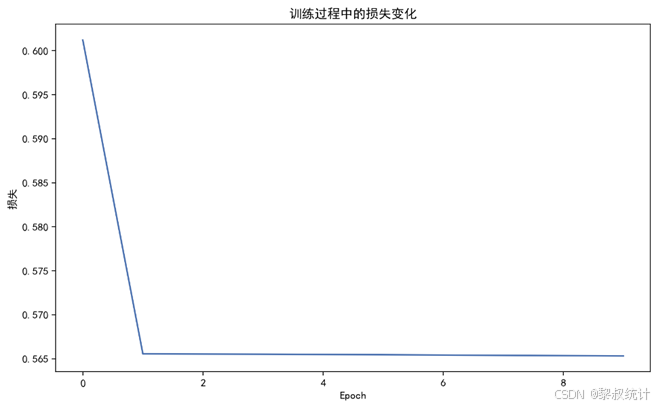
3.2 BP-EKF
# 获取神经网络在每个时间步的预测结果
predictions = []
for t in range(len(y_true)):
if t == 0:
predictions.append(y_true[0])
else:
pred = nn.forward(np.array([[y_true[t-1]]]))
predictions.append(pred.flatten()[0])
# 输出预测的非线性函数值
for t in range(len(y_true)):
print(f'时间步 {t}: 预测值 {predictions[t]}')
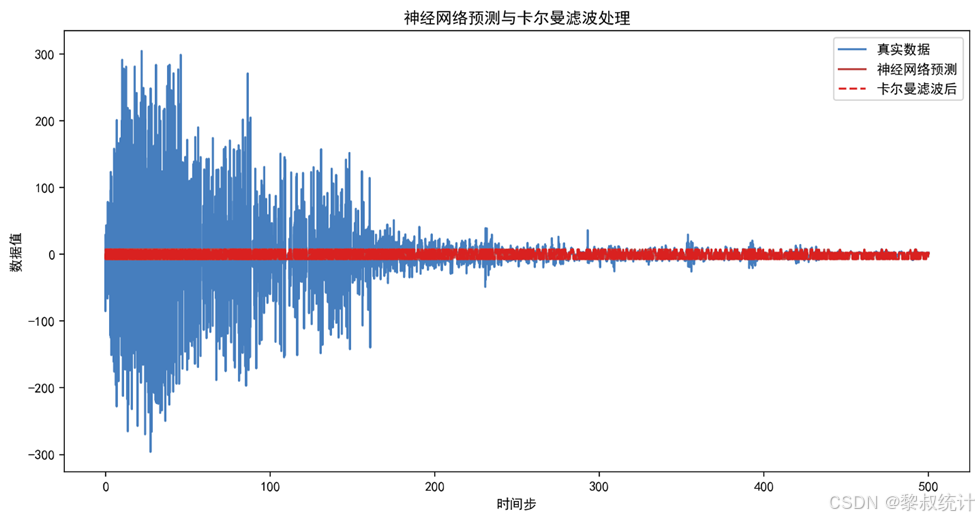
# 绘制结果
plt.figure(figsize=(12, 6), dpi=200)
plt.plot(data['t'], y_true, label='真实数据', color='#467EBE')
plt.plot(data['t'], predictions, label='神经网络拟合', color='#BE4B48')
plt.title('神经网络拟合的非线性状态空间')
plt.xlabel('时间步')
plt.ylabel('数据值')
总结
结果对比

ARMA-KF通过在ARMA模型基础上结合卡尔曼滤波技术,显著降低了模型的均方误差至880.4889,但信噪比仅为0.0803。BP-EKF结合了BP神经网络和扩展卡尔曼滤波技术,展现出对比ARMA-KF更优异的性能。其均方误差仅为876.7700,信噪比为0.0414,显示出在高噪声环境中显著改善的能力。BP神经网络能够更好地处理非线性数据特征,而扩展卡尔曼滤波则在动态系统的状态估计和噪声抑制方面提供了有效支持。
在学习卡尔曼滤波时,先区分数据可表示为的状态空间为线性,或非线性,并用状态方程表达出来(这一过程涉及线性或非线性的不同拟合方法,大家可以多多尝试)。之后再用卡尔曼滤波算法预测。
完整数据代码及论文见https://m.tb.cn/h.gLUZPCl?tk=mBgC3TEgaRD CZ8908
欢迎大家多多交流


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









