






关于正则表达式的学习文档,还没写完…肝不动了,有空再更
文章目录
前言
正则表达式(regular expression,简称reges)可以在几乎所有语言和平台上执行各种复杂的文本处理和操作。
最近读了Bend Forta的《Learning regular expressions》,是一本适合初学者入门的书籍。同时进行了Python实战。特此记录。
一、reges是什么?
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开来的,后来在广泛运用于Scala 、PHP、C# 、Java、C++ 、Objective-c、Perl 、Swift、VBScript 、Javascript、Ruby 以及Python等等。
二、使用步骤
2.1 引入库
代码如下(示例):
import re
2.2 下载插件(选下)
以及可以下载pycharm的插件Regex Tester
三、匹配单个字符
3.1 匹配普通文本
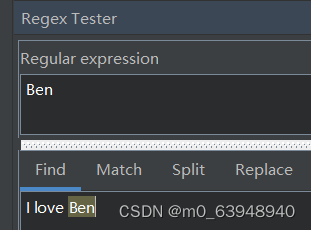
一个普通的文本也可以是正则表达式,即为plain text.
例如查找Ben
3.2 匹配任意字符
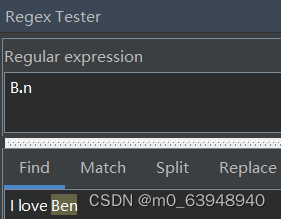
若查找任意字符,可以使用.来表示任意字符
四、匹配一组字符
4.1 匹配多个字符的某一个
使用元字符[和]来表示,用[和]来定义一个字符集合,必须匹配到其中的某个成员(但并非全部)。
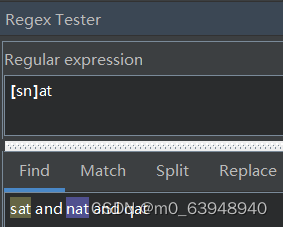
如,希望找到nat或sat。
[ns]at
匹配结果如下所示
4.2 利用字符区间
- A-Z 匹配A到Z的所有大写字母
- a-z 匹配a到z的所有小写字母
- 0-9 匹配0-9的所有数字
同一个字符集合里可以给出多个字符区间,如匹配所有字母或数字
[A-Za-z0-9]
4.3 排除
字符集合通常用来指定一组必须匹配其中之一的字符。但在某些场合,需要反过来做,就是排除字符集合里指定的那些字符。
可以使用元字符^来排除。例如匹配所有非字母且非数字的字符
[^A-Za-z0-9]
五、重复匹配
5.1 有多少个匹配
| 符号 | 意义 |
|---|---|
| + | 匹配一个或多个字符 |
| * | 匹配零个或多个字符 |
| ? | 匹配零个或一个字符 |
| {n,m} | 匹配n个到m个字符 |
例如,匹配s零次或一次
s?
s{0,1}
5.2 防止过度匹配
倘若我们想用正则表达式匹配html的< b >和< /b >标签中的文本。考虑下面这个例子
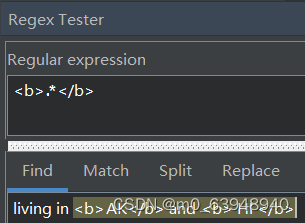
可以发现,这个模式只找到了 一个匹配而非预期的两个。在于*和+都是“贪婪型”的,它们会尽可能的从开头一直匹配到结尾。若想改成“懒惰型”,即在贪婪型两次后加上?
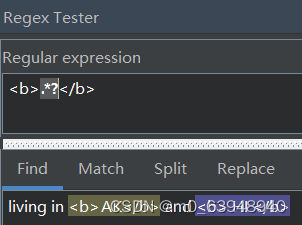
六、反向引用
6.1 反向引用匹配
假设你有一段文本,想把这段文本里所有连续出现两次的单词找到。显然,是先搜索一个单词,然后查找后面是不是之前匹配到的结果。这里就涉及到了反向引用。我们先来看正则表达式
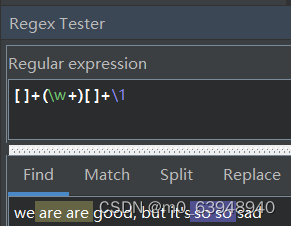
\1到底是什么意思?它其实匹配的是匹配模式中所使用的第一个子表达式。
下面回到html的例子,我们希望得到< hn > 到 </ hn >的内容(n = 1,2,3,4,5,6),即可使用
<h([1-6])>.*?<\/h\1>
6.2 替换
到目前为止,正则表达式都是用来搜索。而当学了反向引用,正则表达式的替换变得让人印象深刻。
替换操作要用到两个正则表达式。第一个用来指定搜索模式,第二个用于替换操作。其中$n表示指定搜索模式中第n个子表达式所匹配到的内容。

七、环视
7.1 环视简介
还是来看一个html的例子,我需要提取出title标签之间的文字
<head>
<title>Ben Forta's Homepage</title>
</head>
我们用正则表达式提取满足在title标签里的文字
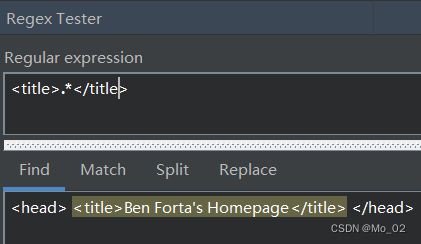
然而可以发现,它不仅返回了标签里的内容,同时把tilte标签也给返回了。方法之一可以使用子表达式,将匹配的文本划分为3个部分。可是,明知不是自己需要的东西还要检索出来是无意义的行为。
找到正确匹配位置而不是让匹配位置自身属于匹配结果,换句话说,需要进行“环视”。
7.2 向前查看
向前查看的语法是一个以?=开头的子表达式。例如查找冒号前的http
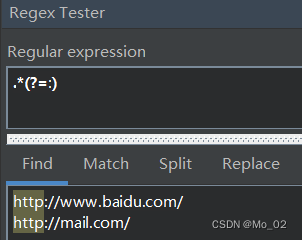
注意,向前查看和向后查看其实是有返回结果的,不过结果永远都是零长度字符串,所以环视操作有时也被称为零宽度匹配操作。
7.3 向后查看
向后查看的操作符是?<=。比如需要提取出价格

7.4 否定式环视
截至目前,向前查看和向后查看通常都是用来匹配文本,这种用法被称为肯定式向前查看和肯定式向后查看。环视还有一种不太常见的形式为否定式环视,会查看不匹配指定模式的文本。
| 种类 | 说明 |
|---|---|
| (?=) | 肯定式向前查看 |
| (?!) | 否定式向前查看 |
| (?<=) | 肯定式向后查看 |
| (?<!) | 否定式向后查看 |
八、嵌入式条件
8.1 反向引用条件
?(n)表示第n个子表达式是否找到,若找到则执行下面操作。
8.2 环视条件
九、python实战
9.1 re库函数
| 函数 | 说明 |
|---|---|
| re.search() | 从一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
9.2 例子:提取标签内内容
<p>My second to last laptop was a Core2Duo 2.4 GHz processor. I have recently purchased a new laptop, which has 2.5 GHz i7 processors (the new model Macbook Pro).</p>

<p>It it fairly obvious that a 5-year newer processor is faster. </p>

<p>My assumption is the processor speed has something to do with actual calculations per second, but obviously the “GHz” comparison is meaningless as a comparison when not comparing the same model of processor.</p>

<li>How can I reliably or meaningfully determine the differences in performance from two processors of different models? </li>
只有<xxx>和</xxx>之间的内容是有用的。所以想到用向前查看和向后查看结合引用来进行提取
body_content = re.compile(r'(?<=<.*?>).*?(?=<\/\1>)')
body_content.findall(Body)
然而python报了错error: look-behind requires fixed-width pattern。原因在于python的re模块不支持断言变长。
解决这个问题可以使用子表达式,用findall提取中间内容
body =re.findall(r'<(.+)>(.+?)<\/\1>',Body)
body返回值为:
[(‘p’,
‘My second to last laptop was a Core2Duo 2.4 GHz processor. I have recently purchased a new laptop, which has 2.5 GHz i7 processors (the new model Macbook Pro).’),
(‘p’, 'It it fairly obvious that a 5-year newer processor is faster. '),
(‘p’,
‘My assumption is the processor speed has something to do with actual calculations per second, but obviously the “GHz” comparison is meaningless as a comparison when not comparing the same model of processor.’),
(‘li’,
'How can I reliably or meaningfully determine the differences in performance from two processors of different models? ')]
再提取第二个子表达式内容
result = ''.join([w[1] for w in body])
result
即可得到结果
My second to last laptop was a Core2Duo 2.4 GHz processor. I have recently purchased a new laptop, which has 2.5 GHz i7 processors (the new model Macbook Pro).It it fairly obvious that a 5-year newer processor is faster. My assumption is the processor speed has something to do with actual calculations per second, but obviously the “GHz” comparison is meaningless as a comparison when not comparing the same model of processor.How can I reliably or meaningfully determine the differences in performance from two processors of different models?
总结
持续更新ing…(主要是太晚了,肝不动了)















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









