







前言🍭
❤️❤️❤️网络爬虫专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️
上篇我们讲解了百度详细翻译这个案例,这篇同样也是进行案例讲解。
9.ajax的get请求🍉
Ⅰ、ajax的get请求请求豆瓣电影第一页🍓
我们打开豆瓣电影,随便打开一个排行榜(电影->剧情)
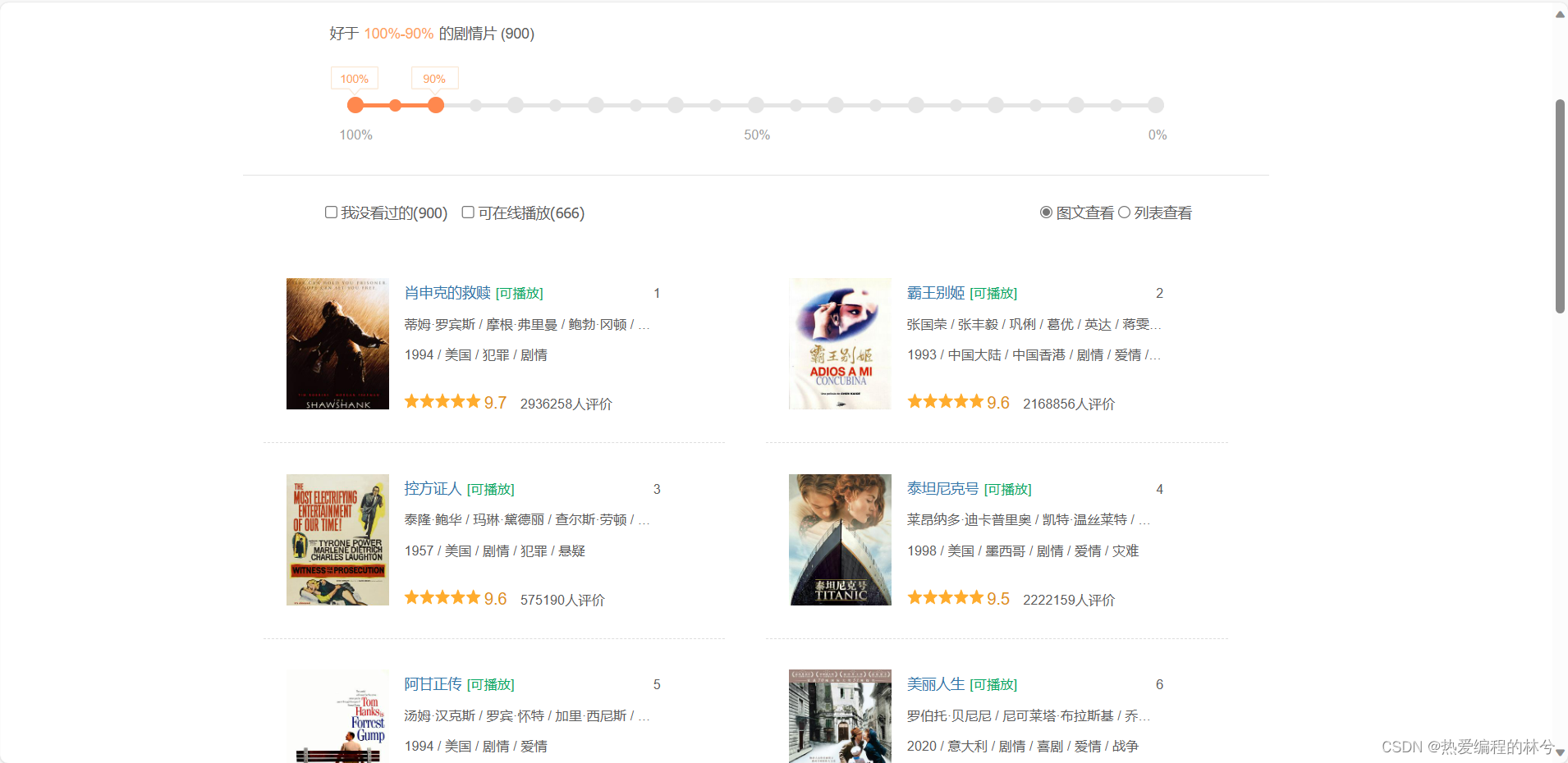
我们F12,打开开发者工具
打开第一个接口,可以看到只有网页,没有数据,我们继续找
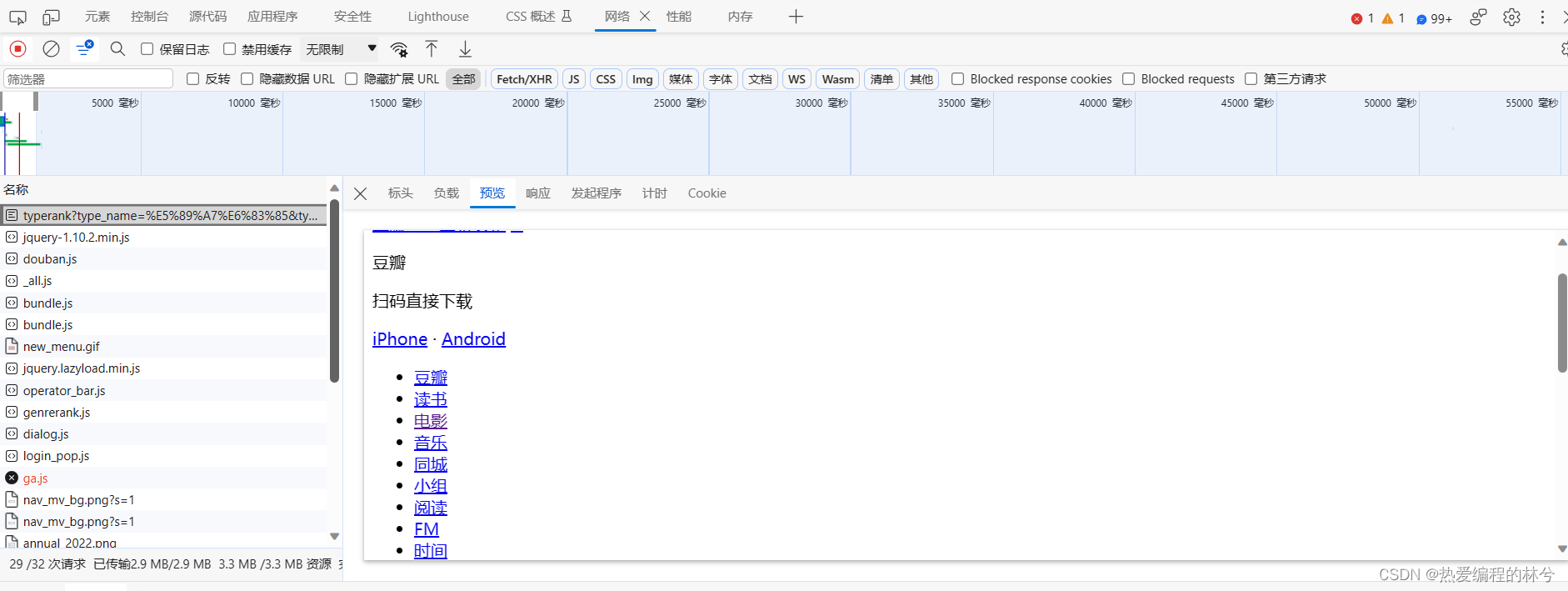
找到下面这个,发现了“肖申克的救赎” ,但是这个只有一个数据啊,继续找
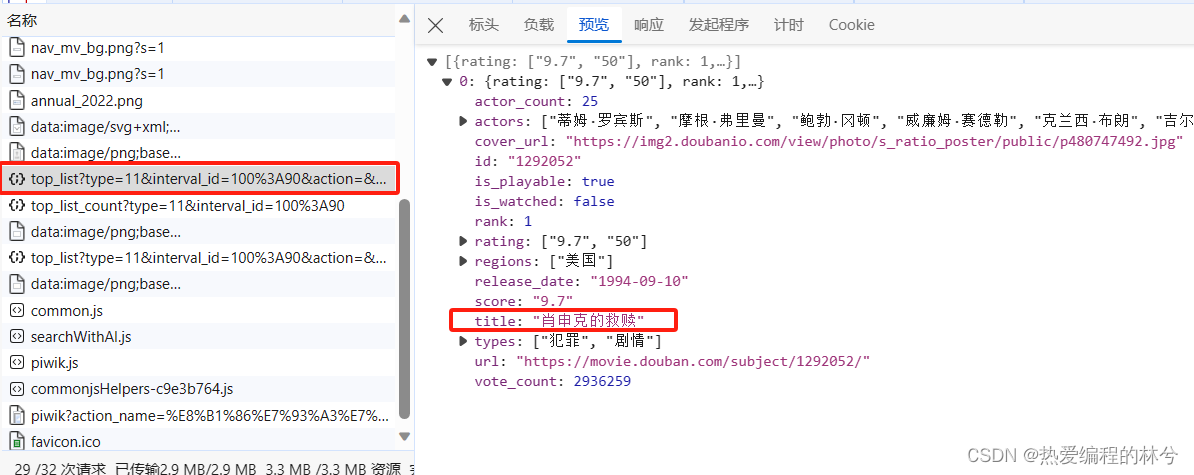
我们又找到一个,有20个数据(都是json格式的,因为它给我们返回的就是json数据,前后端分离),我们打开来看看
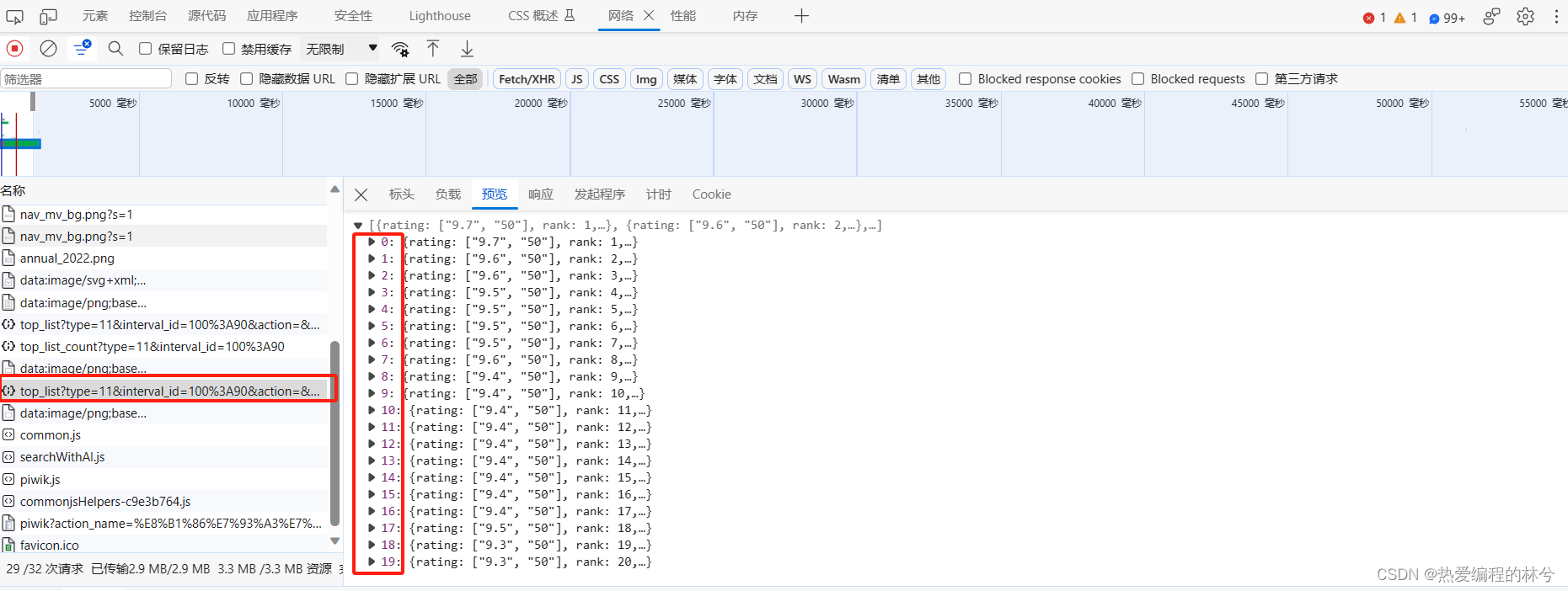
前面两个是 肖申克的救赎 和 霸王别姬

最后一个(第二十个)是 海上钢琴师

果然 第二十部电影是 海上钢琴师

这个接口就是我们想要的数据,好下面我们来写代码:

这是get请求,我们就按get请求来做。
# get请求
# 获取豆瓣电影的第一页的数据 并且保存起来
import urllib.request
# header中的url
url = 'https://movie.douban.com/j/chart/top_lis 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3472
3472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











