







1.一维数组索引和切片
x = np.arange(10)
print('x=',x)
print('x[2]=',x[2]) # 获取索引为2的元素
print('x[2:7:2]=',x[2:7:2]) # 获取索引2-7的元素,按照step=2的规律获取
print('x[2:]=',x[2:]) # 从索引为2的位置截取到数组结尾,进行切片得到新数组
print(x[-2]) # 获取倒数第二个元素
print(x[-2:]) # 获取倒数第二个元素之后

2.二维数组的索引和切片与赋值时内存的指向问题
x = np.arange(1,13)# 创建一个一维数组
a = x.reshape(4,3) # reshape将一个一维数组的形状重塑,生成一个新的二维数组
print('a=',a)
# 方法 a[行的起始行默认为0:行的终止:步长(默认为1),列的起始列默认为0:列的终止:步长(默认为1)]
# 获取二维数组的索引为1的那一行(第二行)
print('a[1]=',a[1])
# 获取索引为2的行 中索引为1的列的元素
print('a[2][1]=',a[2][1])
# 获取所有行的索引为1的列
print("a[:,1]=",a[:,1])
# 第三行第二列的数
print("a[2,1]=",a[2,1])
# 奇数行的第一列
print("a[::2,0]=",a[::2,0])
# 提取二维数组中的某两个位置(3,2)(4,1)
print("a[(2,3),(1,0)]=",a[(2,3),(1,0)])
# 行倒叙
print("a[::-1]=",a[::-1])
# 行列倒叙
print("a[::-1,::-1]=",a[::-1,::-1])

# 测试使用copy复制与直接赋值的区别
a = np.arange(1,13).reshape(3,4)
print('初始的a数组:',a)
sub_array = a[:2,:2] # 获取前两行两列, 此时的sub_array的内存也是在a中的内存,所以修改sub_array会同时修改a,反之成立
print("初始的sub_array:",sub_array)
# 修改sub_array的值
sub_array[0][0] = 1000
print("修改完sub_array后的a:",a)
print('-------------------使用copy赋值:会开辟新的内存,修改一处位置,原先的不发生改变-------------------------------')
sub_array2 = np.copy(a[:2,:2])
sub_array2[0][0] = 1000
print("修改完sub_array2后的a:",a)

3.改变数组的维度
通过reshape方法可以将一维数组变成二维、三维或者多维数组,也可以通过reshape方法将多维数组变成一维。
# 创建一维数组
a = np.arange(24)
print("a=",a)
# 使用reshape将一维数组生成出三维数组
b = a.reshape(2,3,4)
print("b=",b)
# 使用reshape将一维数组生成出二维数组
c = a.reshape(2,3,4)
print("c=",c)
# 使用reshape将多维数组生成出一维数组
print(b.reshape(-1))

通过ravel方法或flatten方法可以将多维数组变成一维数组。
- ravel() 返回的是视图,会影响原始数组(内存指向的空间不发生改变,对一个数组修改,另一个也发生变化);
- flatten() 返回的是拷贝,对拷贝所做的修改不会影响原始数组。
改变数组的维度还可以直接设置numpy数组的shape属性(元组类型),通过resize方法也可以改变数组的维度。
# ravel
a = np.arange(24)
b = a.ravel()
b[0]=1000
print(a)
# array([1000, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,22, 23])
4.数组的拼接

concatenate 函数用于沿指定轴连接相同形状的两个或多个数组
# concatenate数组拼接
import numpy as np
# 一维数组拼接
x = np.arange(1,4)
y = np.arange(4,7)
print("拼接后的一维数组:",np.concatenate([x,y])) # 默认是水平拼接
a = np.array([[1,2,3],[4,5,6]])
b = np.array([['a','b','c'],['e','f','g']])
print('拼接后的一维数组axis=1沿着横轴拼接\n ',np.concatenate([a,b],axis=1))
print('拼接后的一维数组axis=0沿着纵轴拼接\n ',np.concatenate([a,b],axis=0))

a = np.array([[1,2,3],[4,5,6]])
b = np.array([['a','b','c'],['e','f','g']])
print('拼接后的一维数组axis=1沿着纵轴拼接\n ',np.vstack([a,b]))
print('拼接后的一维数组axis=0沿着横轴拼接\n ',np.hstack([a,b]))

5.数组的转置
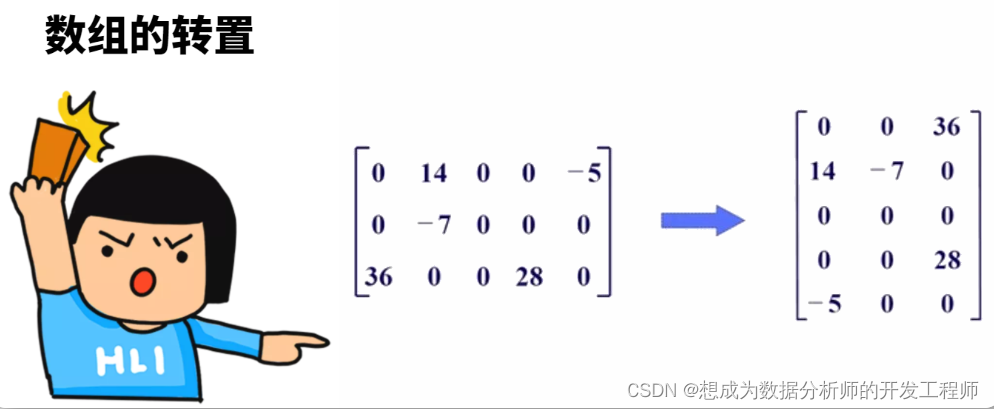
将行与列对调,即第一行变成第一列…或第一列变成第一行…的操作即使转置操作。生成一个新的数组
a = np.arange(1,13).reshape(2,6)
print(a)
t_a = a.transpose()
print(t_a)

6.数组的分隔
numpy.split 函数沿特定的轴将数组分割为子数组
# numpy.split 函数沿特定的轴将数组分割为子数组
# 一维数组的切分
x = np.arange(1,9)
print(x)
a = np.split(x,4) # 原来的数组平均分成4份
print('a=',a)
print('a[0]=',a[0])
b = np.split(x,[3,5]) # 对于x数组的3和5的后面进行分隔,创建一个新的数组
print('b=',b)

# 二维数组的切分
grid = np.arange(16).reshape(4,4) # 创建一个4x4的二维数组
print("grid=",grid)
# 利用hsplit进行水平切分
print("利用hsplit进行竖直切分2份水平状的数组:\n",np.hsplit(grid,2))
# 等效于上面的
print("利用split进行竖直切分2份水平状的数组:\n",np.split(grid,2,axis=1))
# 利用vsplit进行竖直切分
print("利用hsplit进行水平切分2份竖直状的数组:\n",np.vsplit(grid,2))
# 等效于上面的
print("利用split进行水平切分2份竖直状的数组::\n",np.split(grid,2,axis=0))

7.数学函数
a = np.arange(1,10,dtype=np.float).reshape(3,3)
print("原数组:\n", a)
# reciprocal计算各元素的倒数
print("打印数组中的倒数:\n", np.reciprocal(a))
# square计算各元素的平方
print("打印数组中的平方:\n", np.square(a))
print('------------------------------------------------------')
# 三角函数的使用
x = np.linspace(1,10,100)
print('原数组:\n',np.sin(x))
# sin函数的使用
print("打印数组中的sin:\n", np.sin(x))
# 四舍五入 around、floor(向下)、ceil(向上)函数
a = np.array([1.0, 4,55,123,0.5621,25.231])
print('around常规四舍五入:\n',np.round(a))
print('floor向下四舍五入:\n',np.floor(a))
print('ceil常规四舍五入:\n',np.ceil(a))


8.算术函数
numpy 算术函数包含简单的加减乘除: add(),subtract(),multiply() 和 divide()。
a = np.arange(9).reshape(3,3)
b = np.array([10,10,10])
# 加法运算
print('加法运算 add\n',np.add(a,b))
print('加法运算 +\n',a+b) # 效果一致,与二维数组的每一行相加
# 减法运算
print('减法运算 subtract\n',np.subtract(a,b))
print('减法运算 -\n',a-b) # 效果一致,与二维数组的每一行相减
# 乘法运算
print('乘法运算 add\n',np.multiply(a,b))
print('乘法运算 *\n',a*b) # 效果一致,与二维数组的每一行相乘
# 除法运算
print('除法运算 add\n',np.divide(a,b))
print('乘法运算 ÷\n',a/b) # 效果一致,与二维数组的每一行相乘
# 取余数
a = np.array([10,10,30])
b = np.array([3,5,7])
print('取余运算 mod\n',np.mod(a,b))
print('取余运算 %\n',a%b)

9.统计函数
numpy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。 具体如下
# power()函数的使用
x = np.arange(1,5)
y = np.empty_like(x)
np.power(x,2,out=y) # 将x的值进行2次方运算后值存到y中
print('y=',y)
# median()求中位数函数的使用
a = np.array([4,1,2,5])
print('计算偶数的中位数:', np.median(a))
a = np.array([4,1,2,5,6])
print('计算奇数的中位数:', np.median(a))
# mean()求平均值函数的使用
a = np.arange(1,11).reshape(2,5)
print(np.mean(a))
print("调用mean函数 axis=0列 竖直求平均:", np.mean(a,axis=0))
print("调用mean函数 axis=1列 水平求平均:", np.mean(a,axis=1))
# 其他函数使用
print(a)
print('最大值的索引argmax:',np.argmax(a))
print('最大值max:',np.max(a))
print('求和sum:', np.sum(a))
print('最小值min:',np.min(a))
print('删除重复数据,并排序unique:',np.unique(a))
print('返回非0元素的索引 nonzero:',np.nonzero(a))

10.矩阵相乘
import numpy as np
# 一维数组的点乘运算:对应元素相乘后再相加的结果
a = np.array([1,2,3])
b = np.array([4,5,6])
print('方式1:',a.dot(b))
print('方式2:',np.dot(a,b))
# 矩阵(二维)与向量(一维)的点乘
# 把矩阵的每一行分别于向量做点成运算,作为结果向量的个数
# 前提条件,矩阵的列数与向量包含的元素个数相同
X = np.array([[7,8,9],[10,11,12]])
print("多维矩阵点乘一维向量:",X.dot(a))
# 矩阵与矩阵点乘
# 前提条件 左矩阵的列等于右矩阵的行数
A = np.array([[1,2],[3,4],[5,6]])
print('矩阵与矩阵点乘:', X.dot(A))

11.数组排序
排序中主要用到的方法是np.sort和np.argsort。其中np.sort()是对数组直接排序。而np.argsort()是返回排序后的原始索引。
# 一维数组排序方法:
# 创建一个一维数组
a = np.array([5,2,4,6,1,9])
print('排序前:',a)
print('sort排序:',np.sort(a)) # sort产生新的排序后的数组
print('argsort排序:',np.sort(a)) # argsort排序产生新的数组,数组是原数组排序后的索引值
# 二维数组排序
b = np.random.randint(100,size=(4,6))
# 直接使用sort排序指定axis的值
print("根据列排序axis=0",np.sort(b, axis=0)) # 列排序
print("根据行排序axis=1",np.sort(b, axis=1)) # 行排序
# 二维数组按照某一列进行排序
# 思路:输出时,可以根据索引进行输出,所以只需要提取出某一列的值进行排序后得到索引,进行输出即可
c = b[:,0]# 选择第一列
# 根据第一列进行排序,返回排序后对应的元素所在原始位置的索引
index = np.argsort(c)
print('二维数组根据第一列排序后得到结果:', b[index])
12.numpy广播机制
什么时numpy广播机制?
- numpy中的广播机制在于解决不同形状数组之间的算术运算问题。
- 如果数组与某个数运算,则将数组中的每个元素与该数组运算。
- 广播机制可以通过对某个数组或者两个数组在水平或垂直方向的拉伸,使其变成形状相同的数组,从而进行运算
# 一维数组与数字之间的广播机制
a = np.array([1,2,3])
print('一维数组与数字之间的广播机制:',a+5)
# 不同维度的数组间的广播机制运算
a = np.array([[0,0,0],
[10,10,10],
[20,20,20],
[30,30,30]])
b = np.array([1,2,3])
print("垂直方向扩展b后的运算:",a+b)
c = np.arange(3)
d = np.arange(3).reshape(3,1) # 3x1 与 1x3形状的二维数组运算
print('同时延申c和d后进行运算:',c+d)

13.比较掩码
- 比较操作,会返回与参与运算数组形状相同的数组,其中,满足条件的为True,不满足的为False
- 传入的数组,需要和数组形状一致,且类型为Bool类型,这个叫做掩码式索引
# 通过掩码式索引取值,过滤掉不符合条件的值
# 通过比较掩码返回的bool值,得到目标值
# 获取数组中的符合条件的数据
a = np.array([[1,2,30],[45,67,98]])
print("比较后返回的布尔值:\n",a<60)
print('通过返回的布尔值数组过滤出数据:\n',a[a<60])

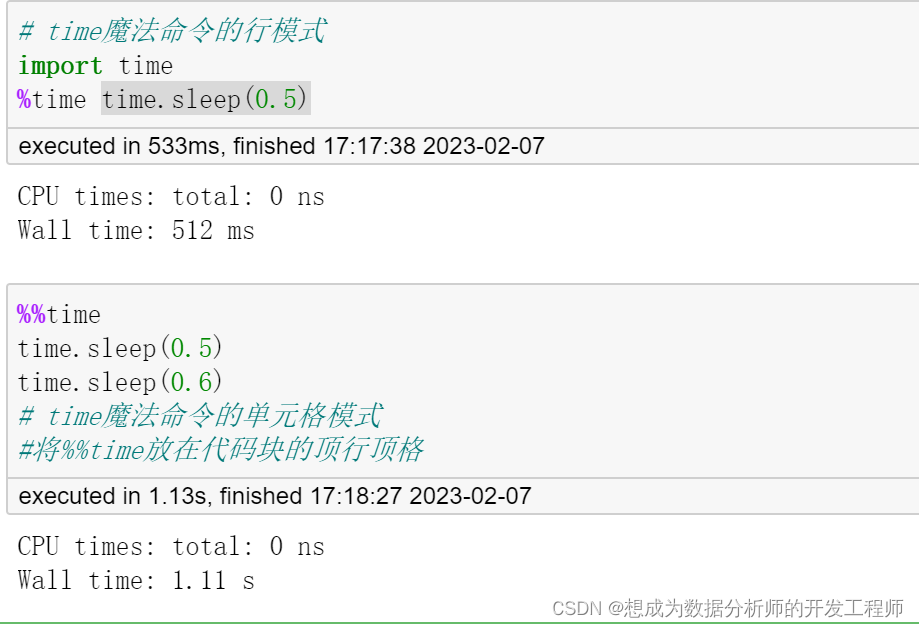
14.time魔法命令
魔法命令是ipython提供特殊命令,能实现一些特殊功能,统计行或者单元格占用内存与时间
魔法命令的两种形式
- %:行模式
- %%:单元格模式
15.timeit魔法命令
timeit魔法命令介绍
- timeit计时更为精确
- timeit可以循环多次执行被统计语句,得到平均执行时间,支持行模式和单元格模式。
- timeit命令参数,-n指定每轮测试次数,-r指定测试轮数
%timeit a=1
# 23.4 ns ± 3.15 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
# 这句话的意思是:执行这一条语句的时间是23.4 ns ± 3.15ns(标准差) 执行7轮 每一轮执行10,000,000 计算出的平均值

%timeit -n 1000 -r 2 a=1 # 指定统计2轮 每一轮统计1000次

单元格模式
- 第一行语句(与timeit同一行语句)为初始化语句,作用为后续代码中变量提供初始化功能。
- 初始化语句执行次数由轮数来决定。
- 初始化语句每轮测试只执行一次,且不参与计时。第二行至整个单元格末尾语句会执行相应次数,并参与计时。
%%timeit -n 2 -r 3 print('初始化语句 只执行一次 补不参与计时')
print('hello')
print('python')

15.writefile和run魔法命令
15.1 writefile魔法命令
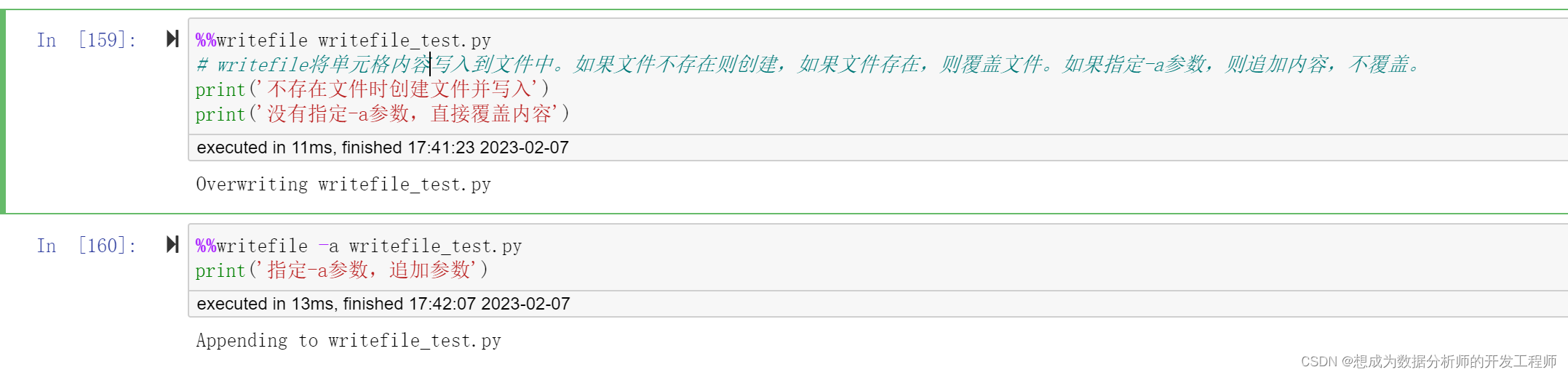
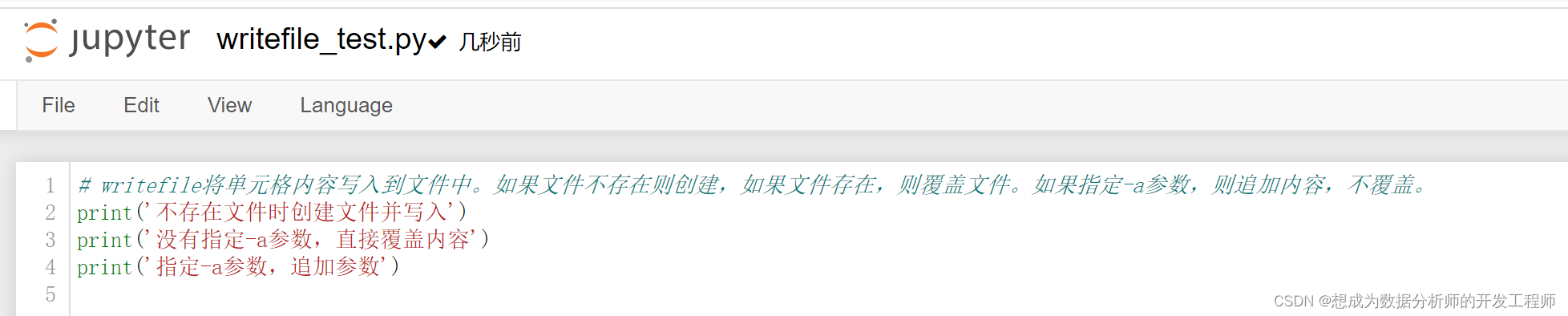
writefile将单元格内容写入到文件中。如果文件不存在则创建,如果文件存在,则覆盖文件。如果指定-a参数,则追加内容,不覆盖。
%%writefile writefile_test.py
# writefile将单元格内容写入到文件中。如果文件不存在则创建,如果文件存在,则覆盖文件。如果指定-a参数,则追加内容,不覆盖。
print('不存在文件时创建文件并写入')
print('没有指定-a参数,直接覆盖内容')
15.2 run魔法命令


16.memit魔法命令
分析语句内存使用情况。memit支持行模式与单元格模式。单元格模式下,初始化语句不会参与计算内存。第二行至整个单元格末尾会参与计算内存。
- memit不是Ipython内置,需要安装memory_profiler模块(pip install memory_profiler==0.60.0)
- 安装后,需要通过%load_ext memory_profiler载入,才能使用
%load_ext memory_profiler
# 分析函数
def m1():
print('test')
%memit m1()
# peak memory: 87.00 MiB, increment: 0.07 MiB peak memory(峰值内存)是运行此代码的进程消耗的内存。increment增量只是由于添
#加这行代码而需要/消耗的内存。同样的逻辑也适用于以下其他的显示。

17.mprun魔法命令
逐行分析语句内存使用情况。
- mprun不是Ipython内置,需要安装memory_profiler模块
- 安装后,需要通过%load_ext memory_profiler载入,才能使用
- mprun测试的内容必须定义在独立模块中,不能定义在交互式Ipython环境中
- 如果需要重新加载模块,可以调用importlib模块提供reload函数实现
















 1367
1367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











