







目录
一、Sqoop 简介
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
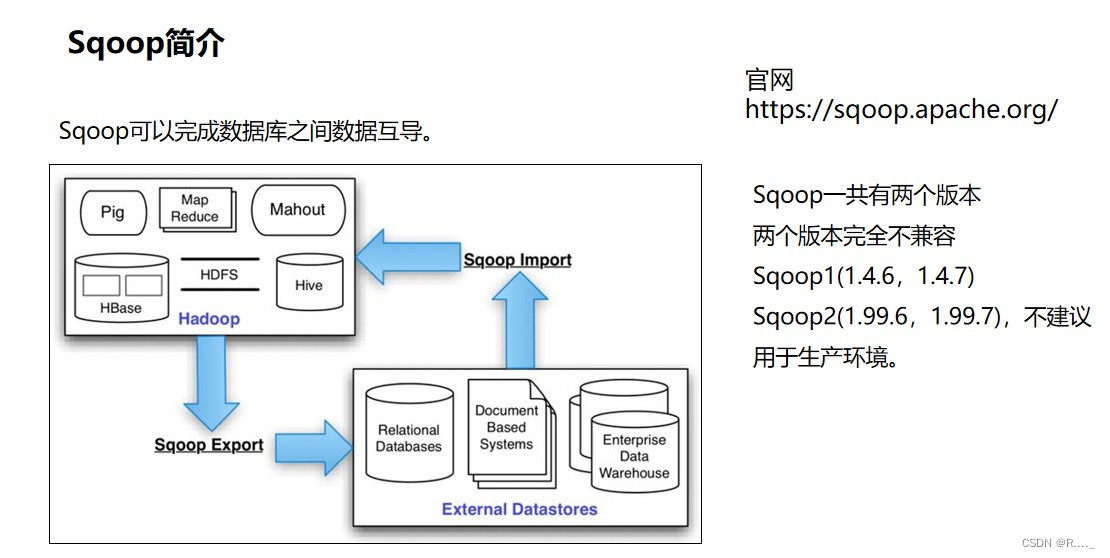
基本思想
插拔式Connector架构, Connector是与特定数据源相关的组件, 主要负责(从特定数据源中)抽取和加载数据。
用户可选择Sqoop自带的Connector, 或者数据库提供的native Connector。
Sqoop: MapReduce方式并行导入导出,性能高; 类型自动转换(用户也可自定义类型转换); 自动传播元信息。
二、Sqoop 架构
2.1 Sqoop1 架构 (1.4.6,1.4.7)
客户端工具, 不需要启动任何服务,调起MapReuce作业(实际只有Map操作), 使用方便, 只有命令行交互方式。
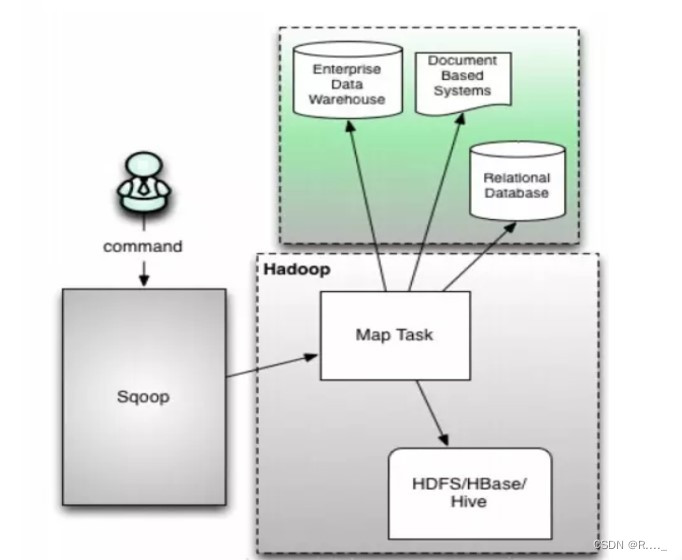
缺陷:
(1) 仅支持JDBC的Connector
(2) 要求依赖软件必须安装在客户端上(包括Mysql/Hadoop/Oracle客户端, JDBC驱动,数据库厂商提供的Connector等)。
(3)安全性差: 需要用户提供明文密码
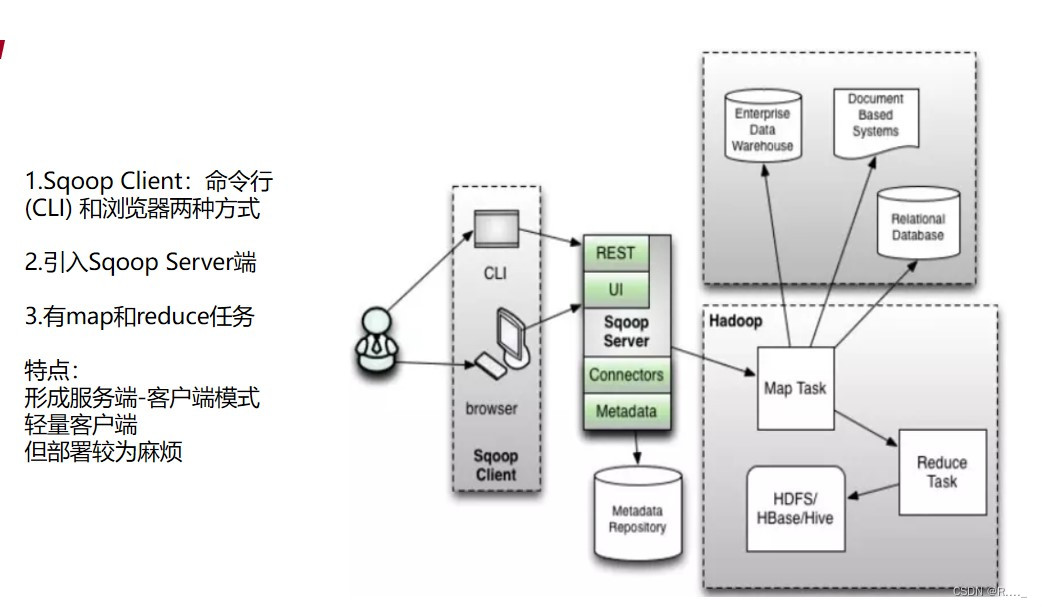
2.2 Sqoop2 架构 (1.99.6,1.99.7)
引入了Sqoop Server端, 形成服务端-客户端,Connector集成到Server端,轻量客户端,部署较麻烦.
(1) Sqoop Client:
用户交互的方式:命令行(CLI) 和浏览器两种方式
(2) Sqoop Server:
-
Connector:
1> Partitioner 数据切片
2> Extractor 数据抽取 Map操作
3> Loader 读取Extractor输出的数据,Reduce操作 -
Metadata: Sqoop中的元信息,次啊用轻量级数据库Apache Derby, 也可以替换为Mysql
-
RESTful和HTTP Server: 客户端对接请求
几个概念
Connector: 访问某种数据源的组件,负责抽取或写入数据;Sqoop2内置多个数据源组件:
- generic-jdbc-connector: 访问支持JDBC协议的数据库的Connector
- hdfs-connector: 访问Hadoop HDFS的Connector
- kafka-connector: 访问kafka的Connector
- kit-connector: 使用Kite SDK实现,可访问HDFS/Hive/Hbase
三、Sqoop 安装
3.1 部署方式
修改conf/sqoop-env-template.sh名称为 sqoop-env.sh

-
添加数据库厂商Jdbc驱动包到lib:
Oracle - ojdbc6.jar
Mysql - mysql-connector-java-5.1.40-bin.jar -
修改环境变量

四、Sqoop 使用方式
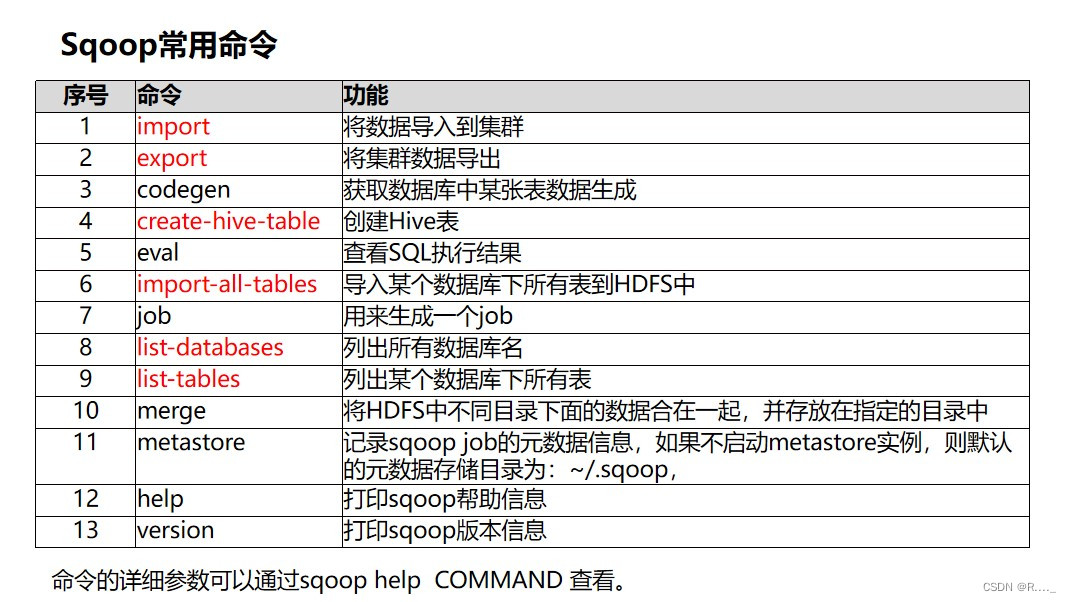



五、Sqoop的公用参数
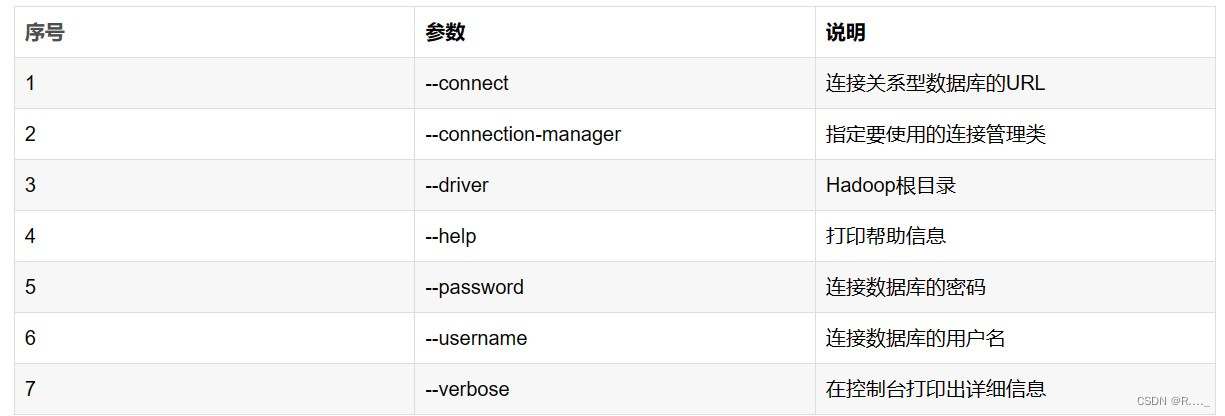
5.1 数据库连接参数
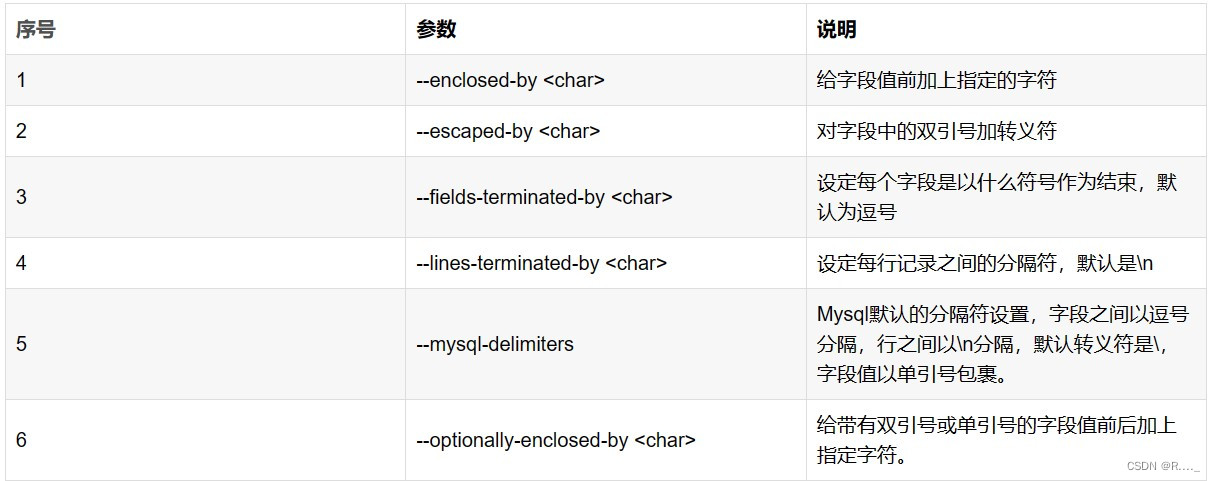
5.2 import参数
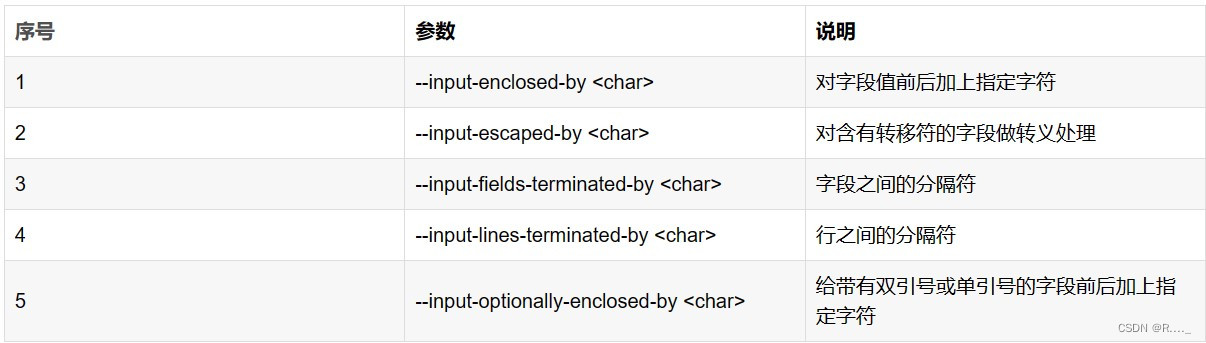
5.3 export参数
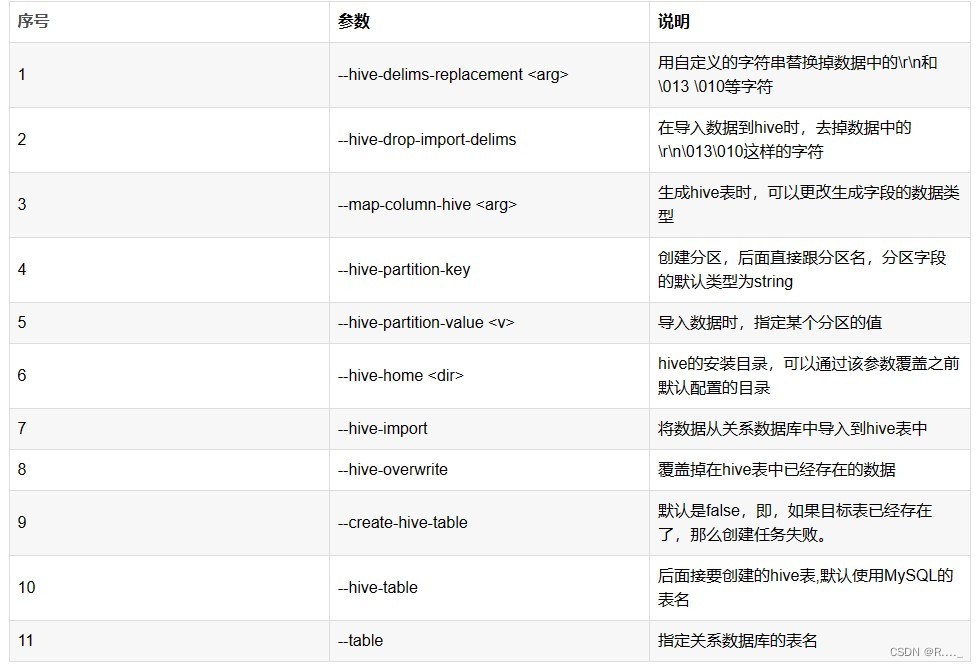
5.4 hive参数















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









