







 本文详细介绍了Python中字符串的常用操作,包括字符串格式化(占位符、f-string和format方法)、编码解码、数据验证、拼接去重、以及正则表达式的re模块应用,如match、search、sub和split等。
本文详细介绍了Python中字符串的常用操作,包括字符串格式化(占位符、f-string和format方法)、编码解码、数据验证、拼接去重、以及正则表达式的re模块应用,如match、search、sub和split等。
目录
一、字符串的常用操作
(1)
大小写只对英文字母有效,其他的不变
s1='Hello_BB8639757' print(s1.lower(),s1.upper()) #split() e_mail='yorelee@163.com' lst=e_mail.split('@') print('邮箱名:',lst[0],'邮件服务器域名:',lst[1]) #子串出现个数 print(s1.count("o")) #检索 print(s1.find('4'))#没找到返回-1 (正向索引哦) print('Hello_BB8639757'.find('l')) print(s1.index('l')) #print('Hello_BB8639757'.index('4'))#没找到会报错 #判断前缀后缀 print('I love yore'.endswith('yore')) print('I love yore'.endswith('qq')) print('I love yore'.startswith('I ')) print('I love yore'.startswith('qq')) ''' hello_bb8639757 HELLO_BB8639757 邮箱名: yorelee 邮件服务器域名: 163.com 1 -1 2 2 True False True False '''


(2)
replace有三个参数,最后一个参数是替换几次。默认为替换所有。
center返回的是一个字符串。
strip(chars) 去掉的是chars里面的字符,与顺序无关。
s='Hello world' print(s.replace('l','你好呀',2)) print(s.replace('l','你好呀',1)) print(s.replace('l','你好呀')) print(s.center(20)) print(s.center(20,'*')) s=' Hello world ' print(s.strip())#默认去掉空字符 print(s.strip(' ')) print(s.lstrip()) print(s.rstrip()) print(s.rstrip().rstrip('lrd')) print(s.rstrip().rstrip('wod')) ''' He你好呀你好呀o world He你好呀lo world He你好呀你好呀o wor你好呀d Hello world ****Hello world***** Hello world Hello world Hello world Hello world Hello wo Hello worl '''lst=['我给你的爱','写在西元前'] s='那已风化千年的诗篇' y=tuple(['深埋在美索不达米亚平原','噢噢~']) print(','.join(lst),','.join(s),','.join(y),sep='\n') ''' 我给你的爱,写在西元前 那,已,风,化,千,年,的,诗,篇 深埋在美索不达米亚平原,噢噢~ '''

二、格式化字符串的三种方式
简化不同数据类型之间的连接操作。
这里只列举出常用的占位符。

一、占位符
name='马冬梅' age=18 score=98.5 print('姓名:%s,年龄:%d,成绩:%.1f'%(name,age,score))#只有一个时,可以不用括号 ''' 姓名:马冬梅,年龄:18,成绩:98.5 '''
二、f-string
name='马冬梅' age=18 score=98.5 print(f'姓名:{name},年龄:{age},成绩:{score}') ''' 姓名:马冬梅,年龄:18,成绩:98.5 '''
三、字符串的format方法
字符串中的{x},数字x对应了format()中位置参数。
name='马冬梅' age=18 score=98.5 print('姓名:{0},年龄:{1},成绩:{2}'.format(name,age,score)) print('姓名:{2},年龄:{0},成绩:{1}'.format(age,score,name)) ''' 姓名:马冬梅,年龄:18,成绩:98.5 姓名:马冬梅,年龄:18,成绩:98.5 '''
区分内置函数format的功能和调用。

详细格式
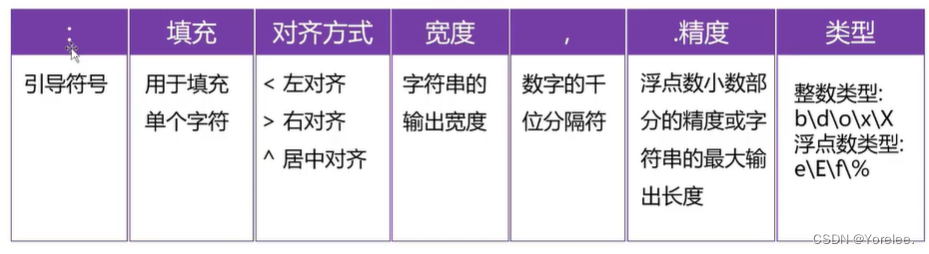
{参数位置:填充字符+对齐方式+宽度} (填充字符只能是单个字符,参数只能是字符串)
name='yorelee' print('{0:-^20}'.format(name)) #等价于print(format(name,'-^20')) #等价于print(name.center(20,'-')) ''' ------yorelee------- '''{参数位置:,} (参数只能是数字,可以是整型也可以是浮点型)
print('{0:,}'.format(8639757888)) print('{0:,}'.format(8639757888.8888)) ''' 8,639,757,888 8,639,757,888.8888 '''{参数位置: .nf} (参数只能是数字,表示小数部分精度)
{参数位置: .n}(参数是字符串,表示最大输出长度)
print('{0:.5f}'.format(8639757888)) print('{0:.5f}'.format(8639757888.8888)) print('{0:.2f}'.format(8639757888.8888)) print('{0:.2}'.format('8639757888.8888')) print('{0:.210}'.format('8639757888.8888')) ''' 8639757888.00000 8639757888.88880 8639757888.89 86 8639757888.8888 '''a=425 print('二进制:{0:b},八进制:{0:o},十六进制:{0:x}'.format(a)) b=3.1415926535 print('{0:.2f},{0:.2e},{0:.2E},{0:.2%}'.format(b))
三、字符串的编码和解码
strict是严格的,出错则抛出异常
ignore忽略出错
replace用?代替无法转换的字符。


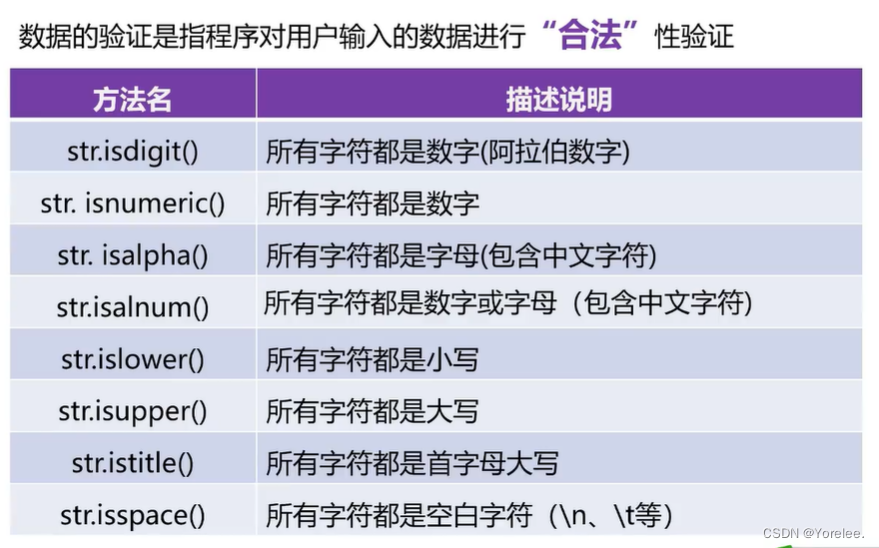
四、字符串的数据验证
isnumeric()可以识别中文的数字 一二三四这种,罗马数字,阿拉伯数字。它是按字符看的!
print('123'.isdigit())#True print('十'.isdigit())#False print('0b1010'.isdigit())#False print('Ⅰ'.isdigit())#False print('-'*50) print('123'.isnumeric())#True print('十壹'.isnumeric())#True print('ⅠⅠⅠ'.isnumeric())#True print('0b1010'.isnumeric())#False print('-'*50) print('hello你好'.isalpha())#True print('hello你好123'.isalpha()) #False print('hello你好123?'.isalpha())#False print('hello你好123Ⅰ'.isalpha())#False print('hello你好123'.isalnum())#True print('hello你好123?'.isalnum())#False print('hello你好123Ⅰ壹'.isalnum())#True print('-'*50) print('Helloworld'.islower())#False print('helloworld'.islower())#True print('helloworld你好123?'.islower())#True print('Ⅰ'.islower())#False 罗马字符是大写 print('Ⅰ'.isupper())#True print('helloworld你好123'.upper()) print('-'*50) print('HelloWorld'.istitle())#False print('Helloworld'.istitle())#True print('Hello World'.istitle())#True 用空格分隔单词 print('HEl'.istitle())#False 是否只有首字母大写
五、字符串的处理
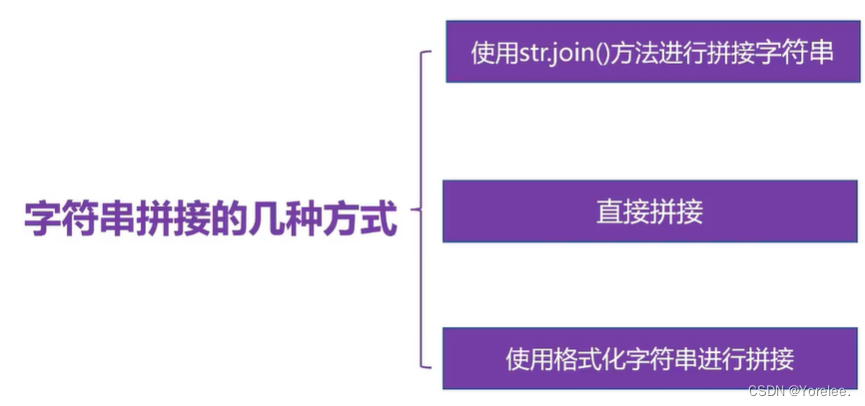
一、字符串的拼接
s1='hello' s2='world' #+号连接 print(s1+s2) #join连接 print(''.join([s1,s2])) print(',你好呀,'.join([s1,s2,s1])) #直接拼接 只有俩常字符串可以 s3='hello''world' print('hello''world') #格式化字符串 print('%s%s'%(s1,s2)) print(f'{s1}{s2}') print('{0}{1}'.format(s1,s2)) ''' helloworld helloworld hello,你好呀,world,你好呀,hello helloworld helloworld helloworld helloworld '''
二、字符串的去重
(1)字符串拼接+not in
new_s='' for item in s: if item not in new_s: new_s+=item print(new_s)(2)使用索引+not in (本质是一样的,就是for循环遍历的时候不一样而已)
new_s='' for i in range(len(s)) if s[i] not in new_s: new_s+=s[i] print(new_s)(3)通过集合去重+列表排序
new_s=set(s) lst=list(new_s) lst.sort(key=s.index) #key给定参数 s.index 是指lst中的元素传入函数s.index() 返回值作为排序值 new_s=''.join(lst)
六、正则表达式
这里只列出了一部分。这里的匹配指的是
和编译原理里面的正则表达式有点像。
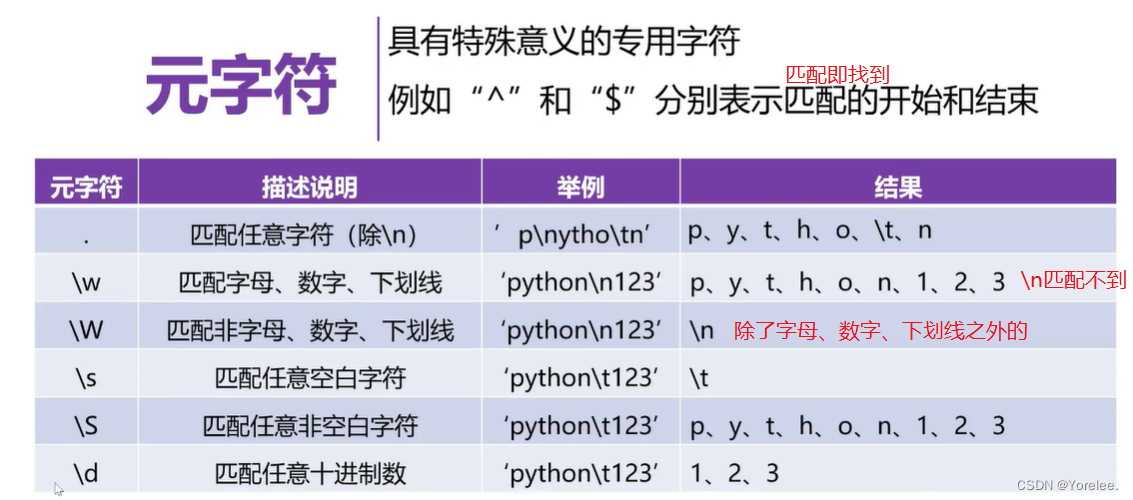
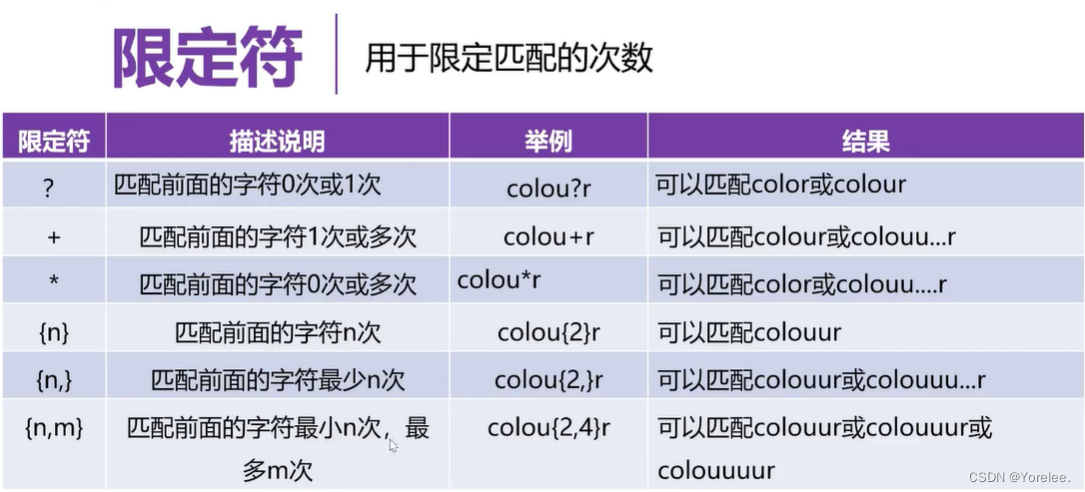

re模块
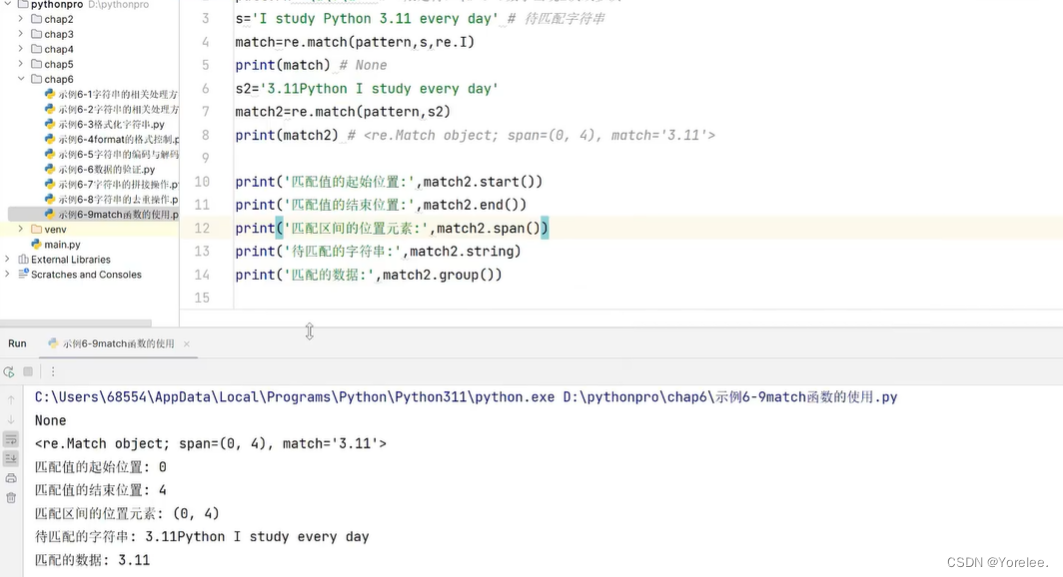
match
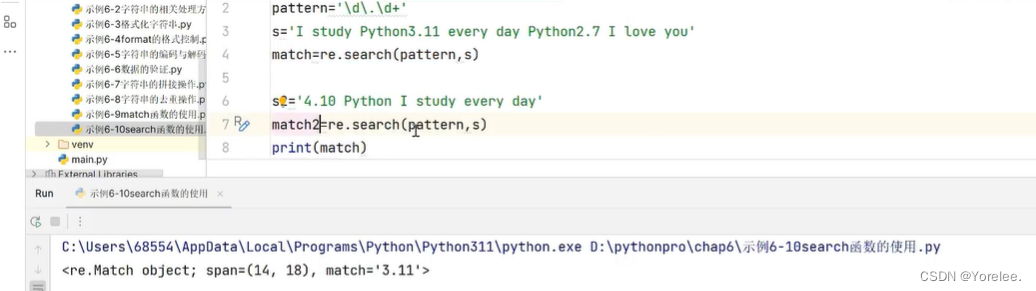
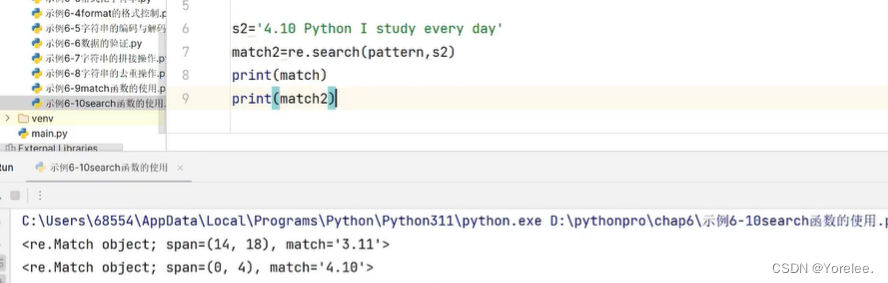
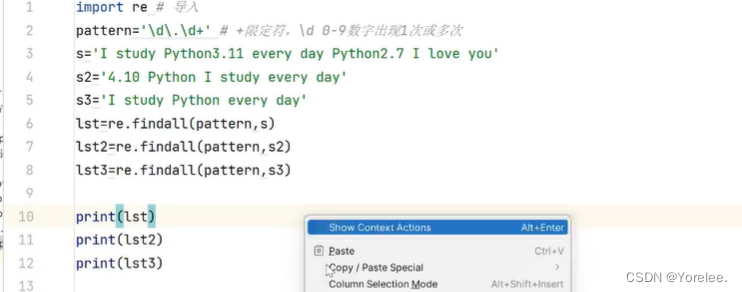
search和findall
search和match的区别在于,search是从整个字符串中找第一个,而match只在开始起始位置找。findall是在整个字符串中找出所有。
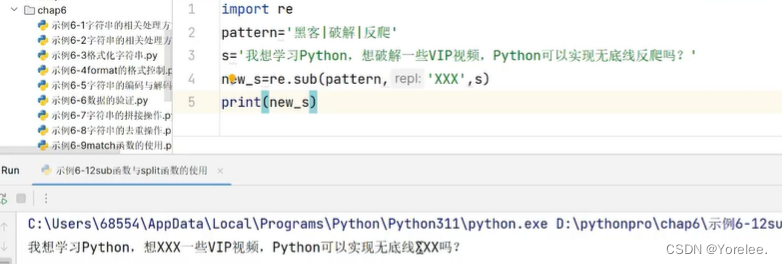
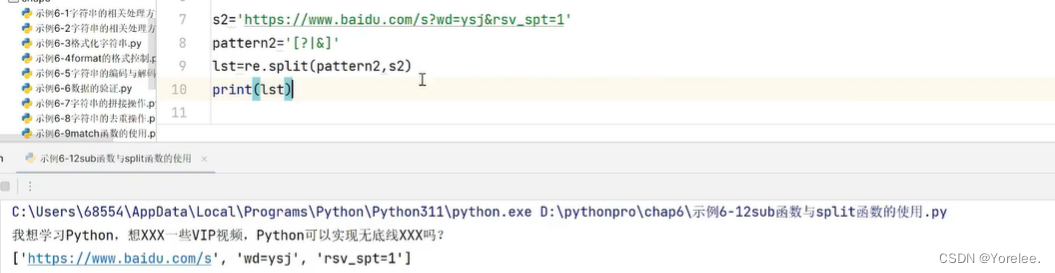
sub和split

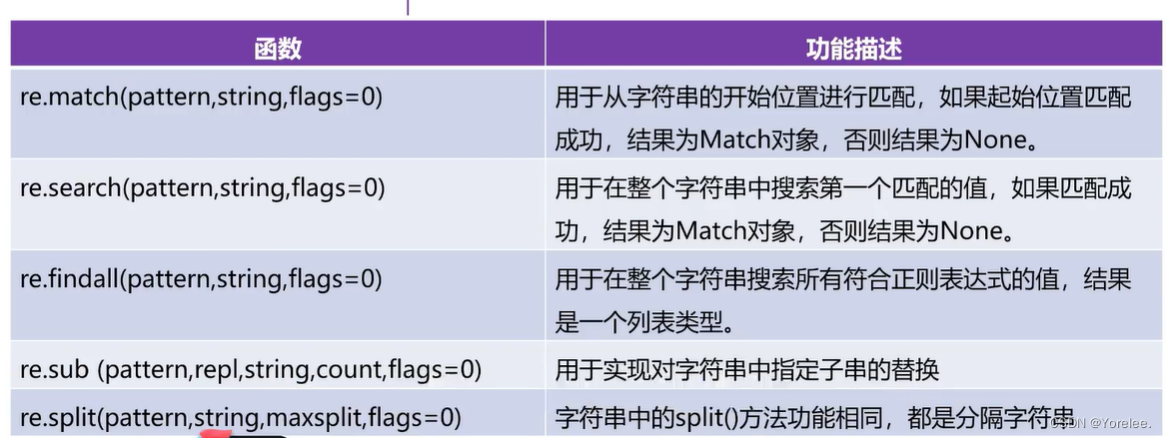
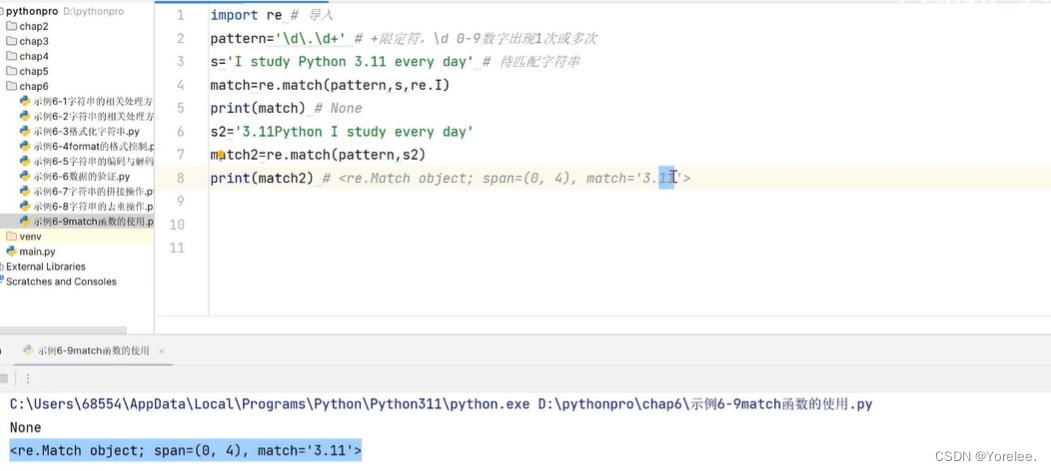



















 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











