






导包,这里我导了很多,因为我其他东西要用,光连接查询只需要两个包
import math
from pyspark import SparkConf
from pyspark.sql import SparkSession
import traceback
import os
from math import sqrt
from pyspark.sql import Row
import pandas as pd
# spark_home 的环境变量
from pyspark.sql.functions import isnull, isnan
from pyspark.sql.functions import expr
一些设置
appname = "test" # 任务名称
master = "local" # 单机模式设置
创建sparkSession
这里的连接数据库的jar包每个人的位置不同
conf = SparkConf().setAppName(appname).setMaster(master) # spark资源配置
spark = SparkSession.builder.config(conf=conf)\
.config('spark.driver.extraClassPath', '/usr/local/apache-hive-2.3.9-bin/lib/mysql-connector-java-5.1.49.jar') \
.getOrCreate()
连接mysql 数据库
这里的employee和salaries是我自己数据库里面的表,每个人的mysql配置不一样,每个人的用户和密码要修改
employee = spark.read.jdbc('jdbc:mysql://localhost:3306/employee?user=root&password=123&serverTimezone=UTC&useSSL=false', table='employees')
salaries = spark.read.jdbc('jdbc:mysql://localhost:3306/employee?user=root&password=123&serverTimezone=UTC&useSSL=false', table='salaries')
查询方法
在Spark中,registerTempTable方法是DataFrame或Dataset API的一个方法,用于将一个DataFrame注册为一个临时表,以便可以使用SQL查询语句对其进行查询。
这里就相当于查employee中的前10条数据
employee.registerTempTable("emp_tbl")
result = spark.sql('SELECT * FROM emp_tbl limit 10')
result.show()
#等价于employee.select("*").limit(10)
查询结果: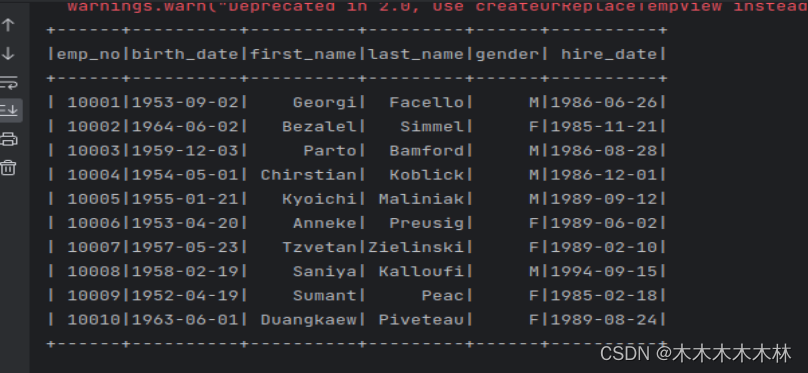















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









