







VMware虚拟机安装Linux教程1:创建和配置虚拟机及基本操作环境(超详细)-CSDN博客
VMware虚拟机安装Linux教程2:配置Linux虚拟机环境及必要操作(超详细)-CSDN博客
注意:安装Hadoop分布式集群时,所克隆使用的虚拟机必须为单数台。 过程中电脑插网线或者连接热点。
一、克隆出三台虚拟机
1、克隆出虚拟机bigdata112
关闭MobaXterm,关闭VMware里的虚拟机;
→在VMware中点击模板虚拟机bigdata111,右键管理→克隆;
→克隆源:克隆自“虚拟机中当前状态;
→克隆类型:创建完整克隆;
→在模板虚拟机bigdata111所在目录下建立一个新文件夹bigdata112;
→虚拟机命名bigdata112,位置选择刚才建立的文件夹;
如图所示,虚拟机bigdata112克隆完成:

2、重复以上操作,克隆出虚拟机bigdata113、114
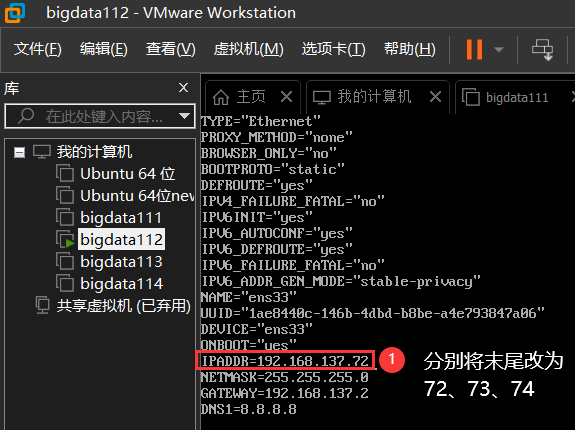
3、修改克隆机的ip地址,末位改为72、73、74
→打开虚拟机后进入如下目录: cd /etc/sysconfig/network-scripts
→编辑ifcfg-ens33文件内容 vi ifcfg-ens33
→分别将ip末位改为72、73、74,如图所示:
→改好后,按esc键,输入:wq!保存退出.
4、修改克隆机主机名称,分别命名为bigdata112、113、114
代码如下,命名如图所示:
vi /etc/hostname 
→点击i进入编辑,如上图修改后按esc键,输入 :wq! 退出。
5、使用MobaXterm连接这三台虚拟机
→重启这三台克隆的虚拟机,进行如下操作: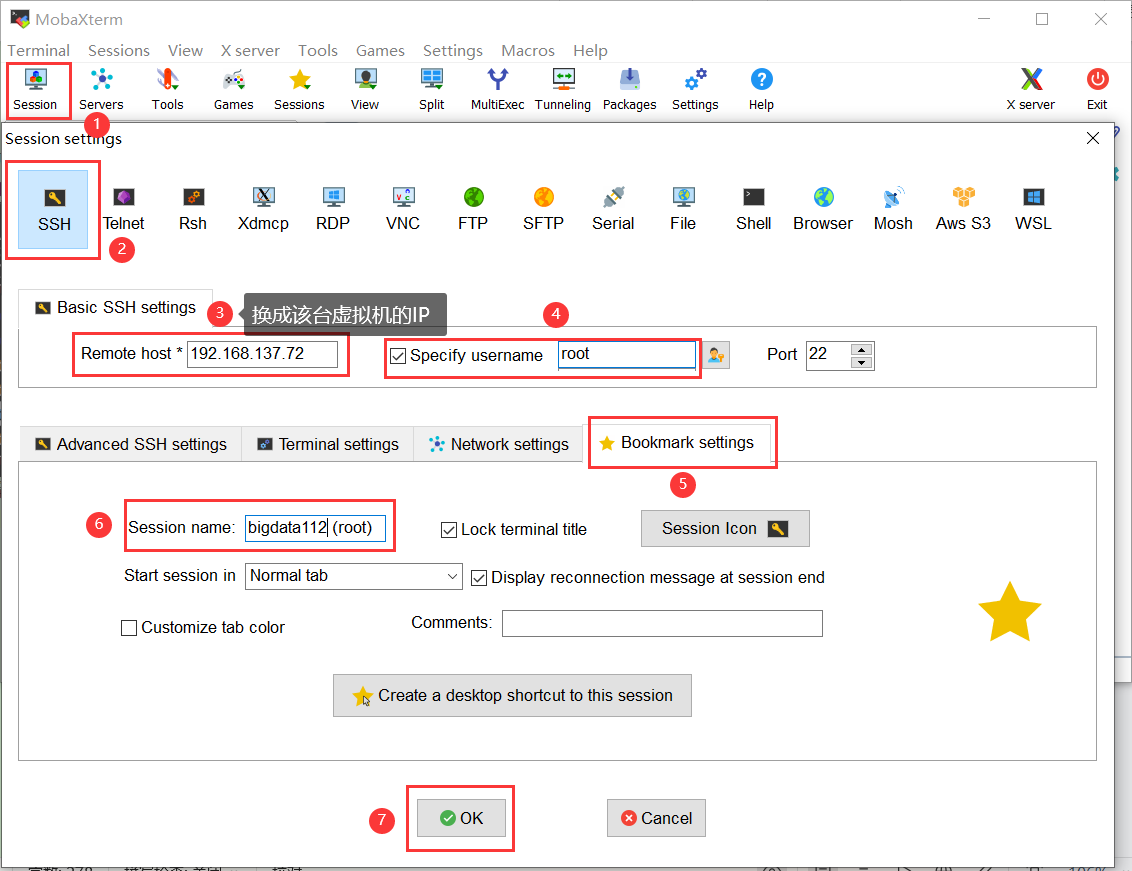
→重复上面操作,设置好bigdata113、114,创建成功后,如图所示:
二、安装、配置hadoop
1、在bigdata112安装hadoop
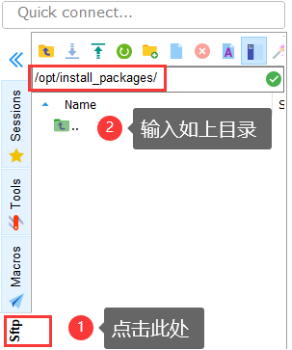
→连接虚拟机bigdata112,如图所示操作:
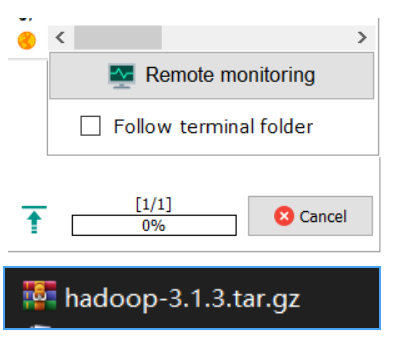
把hadoop压缩包(如右下黑图)拖拽到左图空白处,上传成功后如右上图所示。
→重命名文件:
①进入到softs目录下:
cd /opt/softs②修改文件夹名称:
mv hadoop-3.1.3/ hadoop3.1.3/2、配置hadoop的环境变量
①编辑配置文件:
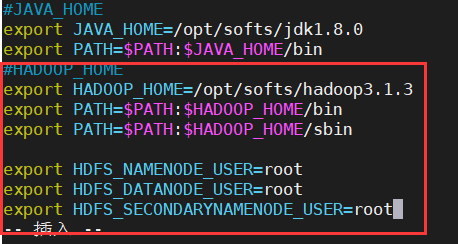
vim /etc/profile②点击 i 进入编辑,在文件末尾如下图修改后按esc键,输入 :wq!退出,代码如下:
#HADOOP_HOME
export HADOOP_HOME=/opt/softs/hadoop3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root如图所示:
③使用source命令使环境变量生效:
source /etc/profile④验证环境变量是否生效,代码如下,如图所示则生效:
echo $HADOOP_HOME 
三、配置三台虚拟机的映射
1、在bigdata112中编辑hosts文件
→进入目录/etc: cd /etc
→编辑hosts文件: vim /etc/hosts
→点击i编辑,在文件末增添如下代码,修改后按esc键,输入 :wq!退出,如图所示
192.168.137.72 bigdata112
192.168.137.73 bigdata113
192.168.137.74 bigdata114
2、将hosts文件远程传输给bigdata113、114
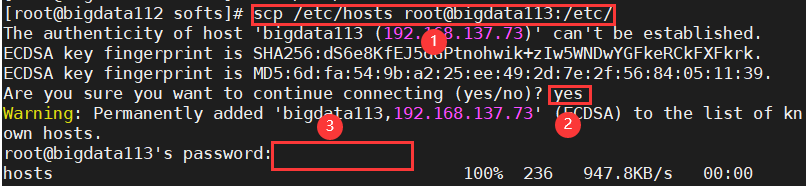
①将编辑好的hosts文件远程传输给bigdata113
scp /etc/hosts root@bigdata113:/etc/ 
命令解释如上,如下图显示即为成功:
②将编辑好的hosts文件远程传输给bigdata114
scp /etc/hosts root@bigdata114:/etc/ ③检查是否传输成功:在bigdata113、114中输入: cat /etc/hosts,如图所示即为成功:

四、设置免密登录
(bigdata112、bigdata113、bigdata114上都要执行一次)
1、设置三台虚拟机上bigdata112的免密登录
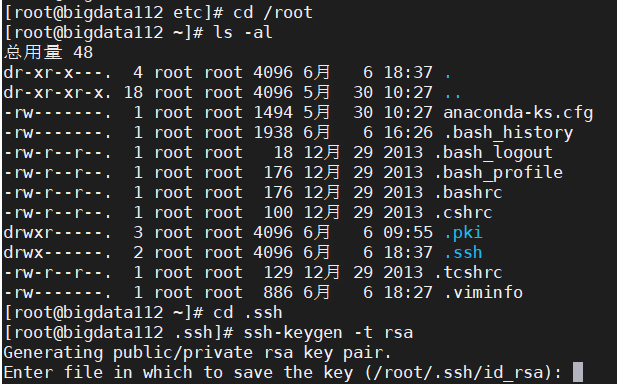
→切换到根目录: cd /root
→查看隐藏内容: ls -al
→进入.ssh目录: cd .ssh
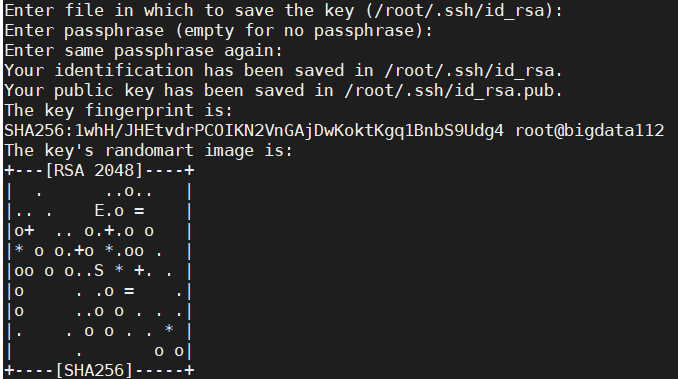
→生成免密登录的公钥和私钥: ssh-keygen -t rsa 如图所示:
→点击三次enter键,才能生成,如下图所示:
→将公钥和私钥发送到要免密的虚拟机bigdata112上,代码如下,操作如图:
ssh-copy-id bigdata112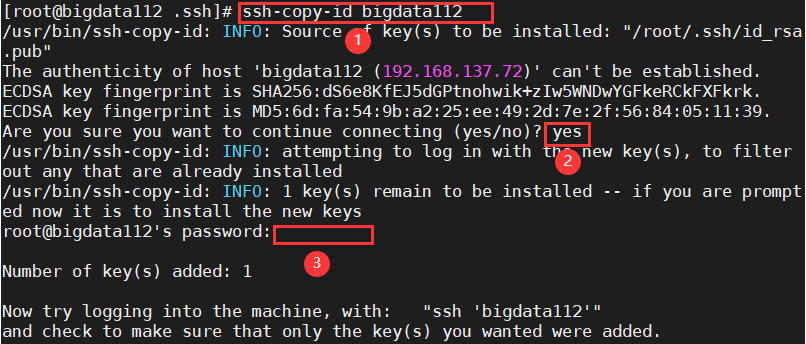 输入以下代码,将公钥和私钥发送到bigdata113、114:
输入以下代码,将公钥和私钥发送到bigdata113、114:
ssh-copy-id bigdata113
ssh-copy-id bigdata1142、重复步骤1,为bigdata113、114分别设置免密登录
补①:在为bigdata113、bigdata114操作时,这俩虚拟机没有 .ssh 目录;
解决:输入 ssh root@bigdata113执行,如下所示进行操作:
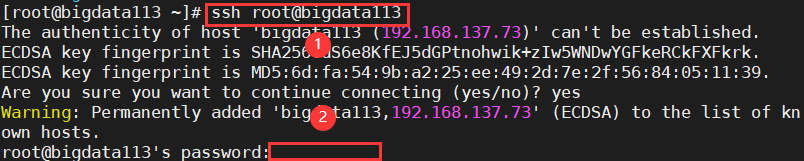
补②:输入ssh root@bigdata113后,报错如下:

解决:系统未识别到复制的命令,需要手敲一遍该命令。
五、集群规划
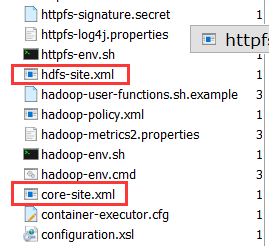
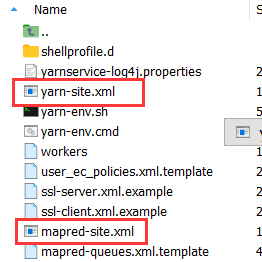
1、在bigdata112中添加4个xml配置文件
→在bigdata112中跳转到配置文件目录:
cd /opt/softs/hadoop3.1.3/etc/hadoop
→修改hadoop-env.sh:
vim hadoop-env.sh→点击i进入编辑,在红框位置如下图修改后按esc键,输入:wq!退出:
→在左侧打开该目录: /opt/softs/hadoop3.1.3/etc/hadoop ,将4个xml文件拖到此处,如图所示:
2、修改配置文件xml,结构如图:
| bigdata112 | bigdata113 | bigdata114 | |
| HDFS | NameNode, DataNode | 2nn,DataNode | DataNode |
| YARN | NodeManager | NodeManager | ResourceManager,NodeManager |
集群规划时有两个注意点:
1. hdfs中的NameNode和2nn不要安装在同一个节点上
2. yarn中的ResourceManager不要和NameNode和2nn在同一个节点上
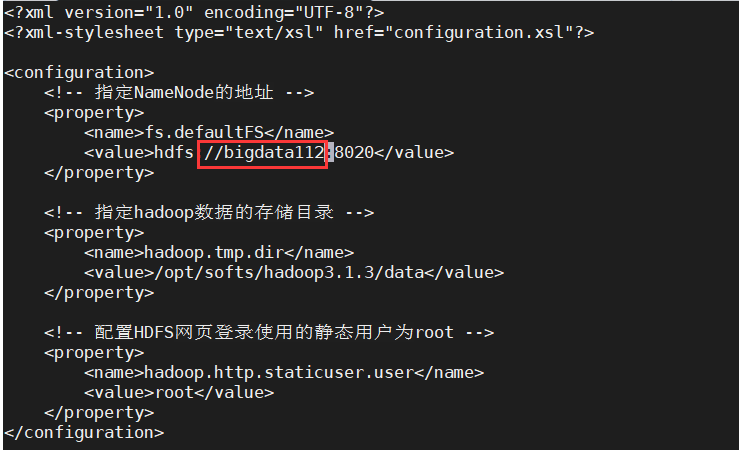
①core-site.xml修改如下:
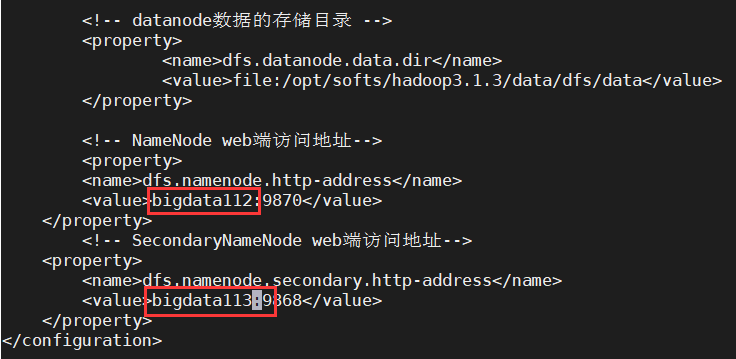
②hdfs-site.xml修改如下:
③mapred-site.xml不做修改;
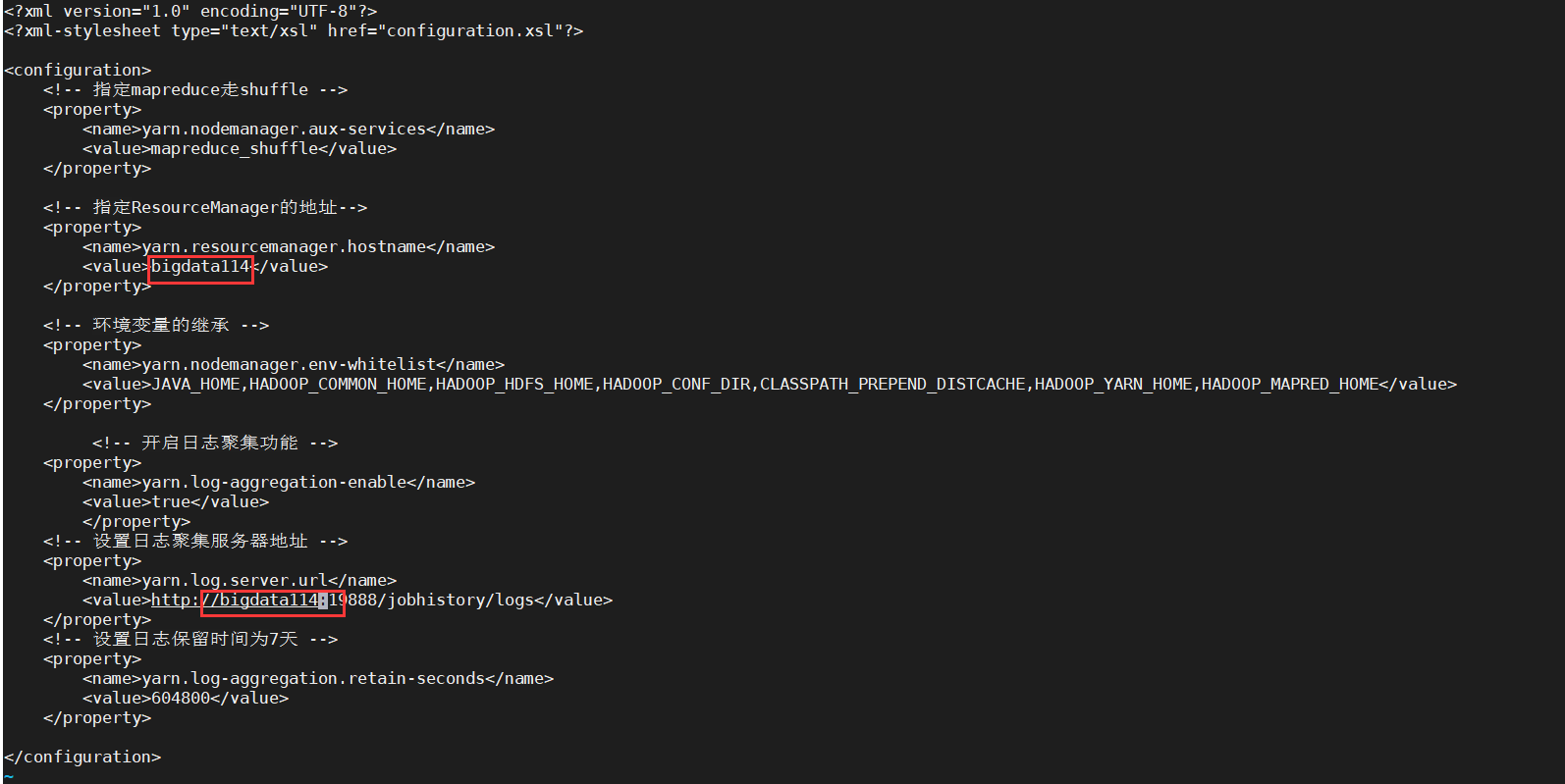
④yarn-site.xml修改如下:
⑤编辑workers:vim workers输入如下内容:(一行一个命令,不能并行) 如图所示:
bigdata112
bigdata113
bigdata114 3、把Hadoop、profile文件传给bigdata113和114。
①将hadoop3.1.3文件远程传输给bigdata113和114;
scp -r /opt/softs/hadoop3.1.3/ root@bigdata113:/opt/softs/
scp -r /opt/softs/hadoop3.1.3/ root@bigdata114:/opt/softs/ ![]()
→再通过以下命令在113、114中检查一下:cd /opt/softs ; ll ; 如图所示:

②将profile文件传输给bigdata113和114;
scp /etc/profile root@bigdata113:/etc/ scp /etc/profile root@bigdata114:/etc/ 
③分别在bigdata113和bigdata114中输入: source /etc/profile
注意:每次修改了profile文件都需要运行该命令,否则修改不生效。
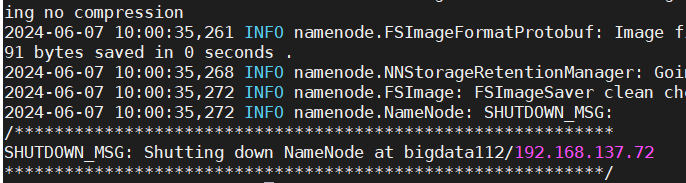
4、初始化NameNode
①在bigdata112中输入: hdfs namenode -format 如图所示:
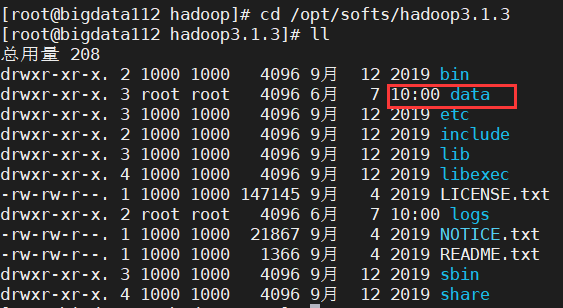
②检查:进入目录 cd /opt/softs/hadoop3.1.3,再输入 ll ,出现 data ,如图所示:
5、启动hdfs和yarn
①在bigdata112上启动hdfs和yarn
→先进入指定目录:cd /opt/softs/hadoop3.1.3/sbin
报错: 没有该文件或目录,如图所示: 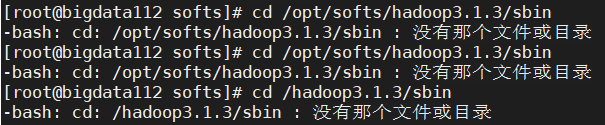
解决:复制命令时,命令开头或末尾有空格,导致系统找不到该目录。之前复制粘贴的命令报错“未找到命令”也是这个原因造成的。建议手打命令,多使用tab键补全命令,或者复制粘贴之后记得删掉空格。
→启动hdfs:start-dfs.sh如图所示: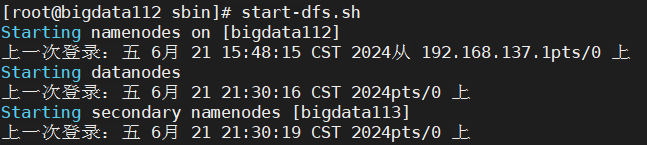
→启动命令: start-yarn.sh 如图所示:
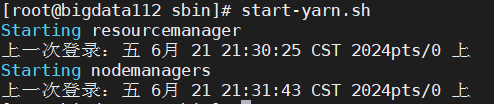
②在bigdata113和114中重复第①步;
③三台都输入 jps 进行检验,是否与集群规划一致:
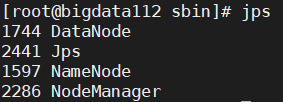
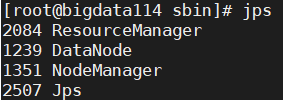
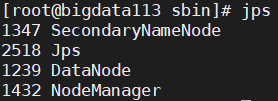
④关闭hdfs和yarn (在关闭虚拟机前要关掉这两个服务!!!)
stop-yarn.shstop-dfs.sh⑤使用jps命令检查,三台都如下图所示只剩下jps则说明关闭成功,可以关闭虚拟机了:

至此,Hadoop分布式集群的搭建已完成,之后我会发布hadoop的Windows环境准备、如何创建并在hdfs上运行maven项目等教程。















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









