






目录
图的概念
图G由两个集合V和E组成,记为(V,E),其中,V是项点的有穷非空集合(顶点集),E是V中顶点偶对的有穷集合(边集),这些顶点偶对称为边。用|V|也可以表示图G中的顶点个数,也称为图G的阶。
注:图不可以为空,即V(G)一定为非空集,而E(G)可以为空集。
对于图G,若边集E(G)为有向边的集合,则称该图为有向图;若边集E(G)为无向边的集合,则称该图为无向图。
在有向图中,顶点对<x,y>是有序的,它称为从顶点x到顶点y的一条有向边。因此,<x.y>与<y,x>是不同的两条边。顶点对用尖括号括起来,对<x,y>而言,x是有向边的始点,y是有向边的终点。<x,y>也称作一条弧,则x为弧头,y为弧尾。
在无向图中,顶点对(x,y)是无序的,它称为与顶点x和顶点y相关联的一条边。这条边没有特定的方向,(xy)与(y,x)是同一条边。为了有别于有向图,无向图的顶点对用一对圆括号括起来。
图的基本术语
n表示图的顶点个数,e表示图边的个数
(1)子图: 假设有两个图G=(v,E)和G'=(v',E'),如果v'属于v且E'属于E,则称G‘为G的子图。
(2)无向完全图和有向完全图: 对于无向图,若具有n(n-1)/2条边,则称无向完全图。对于有向图,若具有n(n-1)条弧,则称为有向完全图。
(3)稀疏图和稠密图: 有很少条边或弧的图称为稀疏图,反之称为稠密图。
(4)权和网: 在实际应用中,每条边可以标上具有某种含义的数值,该数值称为该边上的权值。这些权值可以表示从一个顶点到另一个顶点的距离或耗费。 这种带权的图通常称为网。
(5)邻接点: 对于无向图G,如果图的边(v, v‘)属于E,则称顶点v和v’互为邻接点,即v和v相邻接。边(v, v‘)依附于顶点v和v',或者说边(v,v’)与顶点v和v’相关联。
(6)度、入度和出度: 顶点v的度是指和y相关联的边的数目,记为TD(v)。对干有向图顶点v的度分为入度和出度。入度(以v为终点)是以顶点v为头的弧的数目,记为ID(v); 出度(以v为始点)是以顶点为尾的弧的数目,记为OD(v)。 顶点v的度为TD()= ID(1)+ OD(v)。
顶点v的度=v的入度+v的出度。
(7)路径和路径长度:在无向图G中,从顶点v到顶点v的路径是个顶点序列。如果G是有向图,则路径也是有向的。路径长度是一条路径上经过的边或弧的数目。
(8)回路或环:第一个顶点和最后一个顶点相同的路径称为回路或环。
(9)简单路径、简单回路或简单环:序列中顶点不重复出现的路径称为简单路径。除了第一个顶点和最后 一个顶点之外, 其余顶点不重复出现的回路,称为简单回路或简单环。
(10)连通,连通图和连通分量: 在无向图G中,如果从顶点v到顶点v‘有路径,则称v和v’是连通的。如果对于图中任意两个顶点vi,vj∈V, vi和vj都是连通的,则称G是连通图。所谓连通分量,指的就是无向图中的极大连通子图(该子图是G连通子图,将G的任意不在该子图中的顶点加入。子图不再连通。
对于n个顶点的无向图G:
1>若G是连通图,则最少由n-1条边;
2>若G是非连通图,则最多有2/(n-1)(n-2)条边。
对于n个顶点的有向图G:
若G为强连通图,则最少有n条边(形成回路)。
图的存储结构
注:图没有顺序存储结构
由于图的结构复杂,任意两点都有可能存在联系,可以借助二维数组来表示元素之间的关系,因此采用链式存储结构。
邻接矩阵
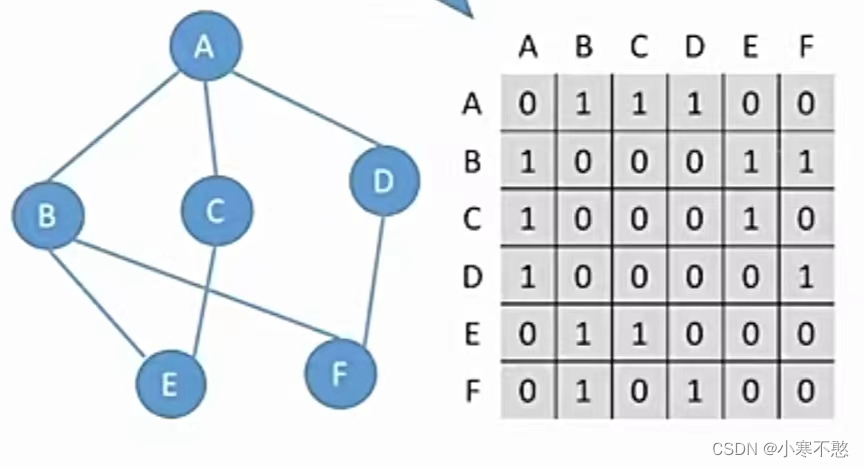
邻接矩阵:是表示顶点之间相邻关系的矩阵。
对于无向图
对于有向图
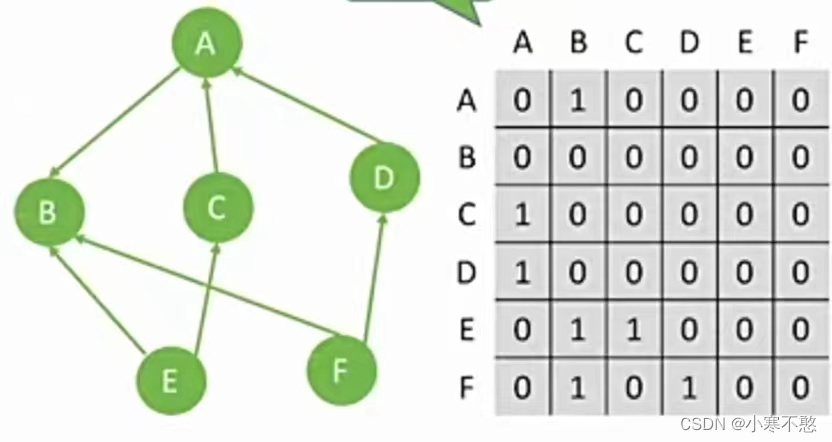
注:无向图的邻接矩阵是对称的,有向图的邻接矩阵不一定对称。
对于有向图:出度看行,入度看列。
图的邻接矩阵表示
#define MaxInt 32767 //表示极大值,即∞
#define MVNum 100 //最大顶点数
typedef char VerTexType; //假设顶点的数据类型为字符型
typedef int ArcType; //假设边的权值类型为整型
typedef struct
{
VerTexType vexs [MVNum] ; //顶点表
ArcType arcs [MVNum] [MVNum] ; //邻接矩阵
int vexnum, arcnum; //图的当前点数和边数} AMGraph;
} AMGraph;采用邻接矩阵表示法创建无向网
算法思路
①输人总顶点数和总边数。
②依次输人点的信息并将其存入顶点表中。
③初始化邻接矩阵,使每个权值初始化为极大值。
④构造邻接矩阵。依次输入每条边依附的顶点和其权值,确定两个顶点在图中的位置之后,使相应边赋予相应的权值,同时使其对称边赋予相同的权值。
Status CreateUDN (AMGraph &G)
{ //采用邻接矩阵表示法,创建无向网G
cin>>G. vexnum>>G. arcnum; //输人总顶点数,总边数
for (i=0; i<G. vexnum; ++i) //依次输人点的信息
cin>>G.vexs[i] ;
for (i=0; i<G. vexnum; ++i) //初始化邻接矩阵,边的权值均置为极大值MaxInt
for (j=0; j<G. vexnum; ++j)
G.arcs[i] [j] =MaxInt;
for (k=0; k<G.arcnum; ++k) //构造邻接矩阵
{
cin>>v1>>v2>>W; //输人一条边依附的顶点及权值
i=LocateVex (G, v1);j=LocateVex(G,v2); // 确定v1和v2在G中的位置,即顶点数组的下标
G.arcs[i][j]=w; //边<v1, v2>的权值置为w
G.arcs[j][i]=G. arcs[i][j]; //置<v1, v2> 的对称边<v2,v1> 的权值为w
} //for
return OK;
}邻接矩阵表示法的优缺点
(1)优点
①便于判断两个顶点之间是否有边,即根据A[i][j]= 0或1来判断。
②便于计算各个顶点的度。对于无向图,邻接矩阵第i行元素之和就是顶点v;的度;对于有向图,第i行元素之和就是顶点vi的出度,第i列元素之和就是顶点的人度。
(2)缺点
①不便于增加和删除顶点。
②不便于统计边的数目,需要查找邻接矩阵所有元素才能统计完毕,时间复杂度为O(n^2)。
③空间复杂度高。如果是有向图,n个顶点需要n2个单元存储边。如果是无向图,因其邻接矩阵是对称的,所以对规模较大的邻接矩阵可以采用压缩存储的方法,仅存储下三角或者上三角。
邻接表
1.邻接表表示法
邻接表是图的一种链式存储结构。在邻接表中,对图中每个顶点v建立一个单链表,把与vi相邻接的顶点放在这个链表中。邻接表中每个单链表的第一个节 点存放有关顶点的信息,把这一节点看成链表的表头,其余节点存放有关边的信息,这样邻接表便由两部分组成:表头节点表和边表。
(1)表头节点表:由所有表头节点以顺序结构的形式存储,以便可以随机访问任一 顶点的边链表。表头节点包括数据域和链域两部分。其中,数据域用于存储顶点vi的名称或其他有关信息;链域用于指向链表中第一个节点(与顶点vi邻接的第一个邻接点)。
(2)边表:由表示图中顶点间关系的2n个边链表组成。边链表中边节点包括邻接点域、数据域和链域3个部分。其中,邻接点域指示与顶点v邻接的点在图中的位置;数据域存储和边相关的信息,如权值等;链域指示与顶点v;邻接的下一条边的节点。
注:邻接表不唯一,因各边节点的链入顺序是任意的。
图的邻接表的存储表示
typedef struct ArcNode //边节点
{
int adjvex; //该边所指向的顶点的位置
struct ArcNode* nextarc; //指向下一条边的指针
OtherInfo info; //和边相关的信息
} AraNode;
typedef struct VNode // 顶点信息
{
VerTexType data;
ArcNode *firstarc; //指向第-条依附该顶点的边的指针
}VNode, AdjList [MVNum]; //AdjList表示邻接表类型
typedef struct //邻接表
{
AdjList vertices; //图的当前顶点数和边数
int vexnum, arcnum;
}ALGraph;
邻接表表示法的优缺点
1、优点
①便于增加和删除顶点。
②便于统计边的数目,按顶点表顺序查找所有边表可得到边的数目,时间复杂度为O(n+e)。
③空间效率高。对于一个具有n个顶点、 e条边的图G,若G是无向图,则在其邻接表表示中有n个顶点表节点和2e个边表节点;若G是有向图,则在它的邻接表表示或逆邻接表表示中均有n个顶点表节点和e个边表节点。因此,邻接表或逆邻接表表示的空间复杂度为O(n+ e),适合表示稀疏图。对于稠密图,考虑到邻接表中要附加链域,因此常采取邻接矩阵表示法。
2、缺点
①不便于判断顶点之间是否有边,要判定vi和yj之间是否有边,就需查找第i个边表,最坏情况下时间复杂度为O(n)。
②不便于计算有向图各个顶点的度。对于无向图,在邻接表表示中顶点v的度是第i个边表中的节点个数。在有向图的邻接表中,第i个边表上的节点个数是顶点v的出度,但求v的人度较困难,需遍历各顶点的边表。若有向图采用逆邻接表表示,则与邻接表表示相反,求顶点的入度较容易,而求顶点的出度较困难。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









