







Step4:Inference 推理
从模型中产生新的数据,推理过程就是逐步预测概率分布的过程,整个过程伴随持续的概率选择。我们现在使用GPT所输出的结果实际上是很多个月前对模型训练的结果,而不是实时更新的模型。
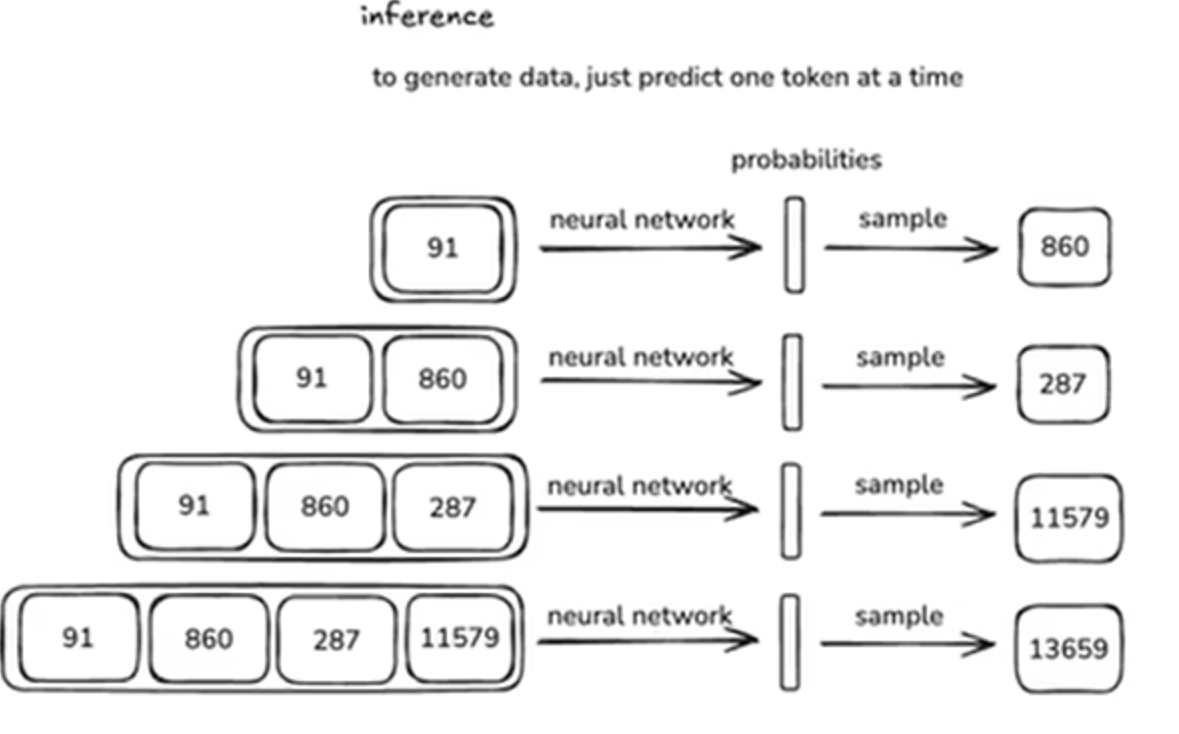
在GPT-2时代,最大的mordern transformer 是1.6百万(现在通常到达千亿或者万亿量级),context length token还比较少,只有1024左右,远低于现在的规模(数十万、上百万)。
 2019年训练GPT-2的成本大约4000美元,但现在训练成本只需要672美元,如果深度优化的情况下,训练成本还能更低,比如100美元。但是随着大家对AI的关注,数据质量提高,硬件/软件上得到了很多进展,所以目前训练数据能更大,context length也更大。
2019年训练GPT-2的成本大约4000美元,但现在训练成本只需要672美元,如果深度优化的情况下,训练成本还能更低,比如100美元。但是随着大家对AI的关注,数据质量提高,硬件/软件上得到了很多进展,所以目前训练数据能更大,context length也更大。
 每次更新处理100万token
每次更新处理100万token
每次更新耗时7秒
整个优化过程计划执行32,000步骤
32,000步乘以每步100万token,需要处理330亿个token
可以设置每多少步就做一次inference
这个损失,是由softmax的函数计算出来的,这中间的运算过程很大,所以需要在云服务器上运行

常看到的instruct model代表这个模型是可以问答交互的模型
hyperbolic 等网站可以找到最新发布的模型,
我们也可以用类似于LMstudio来本地部署模型。
我们不能完全信任模型中输出的所有东西,因为实际上他只是对之前收集文档所做的统计重演recollection。但我们在做测试的时候,如果发现回复的语句完全和训练用的文本素材一致,这就叫做regurgitation。我们并不希望模型完全重现某篇文档里一样的内容,这属于不良行为。发生这种情况的原因是,素材质量较高则会被优先采样,重复学习很多次,甚至能达到背诵的程度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









