






在写一个爬虫脚本爬取网站的时候第一次遇到了403请求,通过网上的搜集都是告诉我 把请求头给换一下,使之能够更加相像地模拟人类行为。我经过了以下尝试,将页面的请求头都拉下来了发现还是不可以,具体如下:
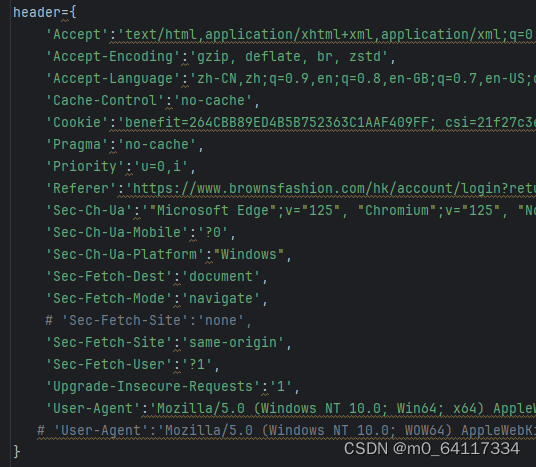
之后我甚至去思考是否此页面具有那种每次请求都会更新请求的cookie从而限制了我的请求,但是尝试了之后发现cookie的生成实在太过复杂,最后我准备使用selenium去模拟拿数据,这一下可让我发现了问题所在,具体如下图所示:
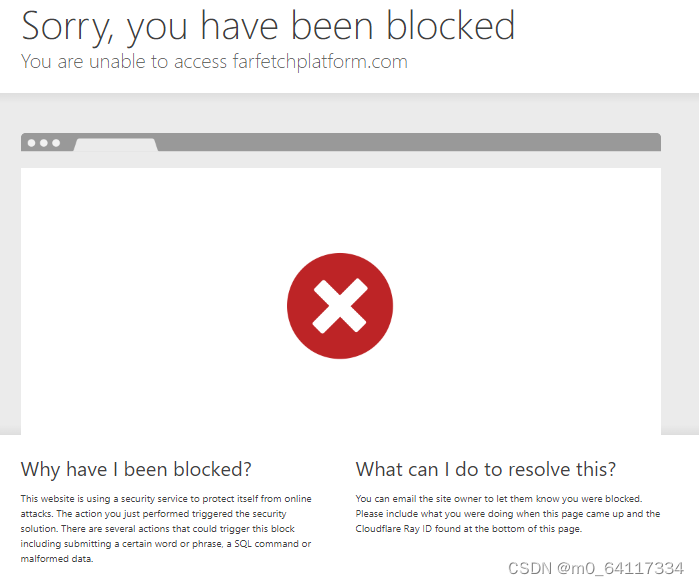
这样就说明并不是cookie或其他参数在作怪,是该网站具有安全服务保护。通过请求的信息我们了解到是cloudflare保护机制。
至于解决这个问题的方法就是导入处理cloudflare的库文件之后向目标网站发起请求,当然由于该方法是在访问网站前等待一些时间,所以用该方法请求的时间会比直接request慢一点,但总归能够拿到我们所需要的数据。
import cloudscraper
url='https://www.brownsfashion.com/hk/shopping/woman-clothing?pageindex=1'
#目标网站含有cloudflare反爬机制
scraper=cloudscraper.create_scraper()
res=scraper.get(url).text














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









