







博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!

| 课题名称(必填) | 基于Spring Boot的食物热量分析平台设计与实现 |
| 技术栈:vue 3,spring boot, 详细功能需求描述(必填) ①用户端 | |

第二章 所用开发工具介绍
在本项目的后端开发中,我们选择了Java语言和Spring Boot框架,以简化业务逻辑和数据操作。数据存储则依赖于MySQL数据库。前端部分,我们利用HTML、CSS、JavaScript和Vue.js创建了用户友好的界面。开发工具方面,我们选用了Eclipse,其强大的功能和效率助力了代码编写和项目管理。Navicat用于数据库管理,提高了操作的效率和准确性。这样的技术组合不仅加速了项目开发,还确保了系统的稳定性。
2.1 Spring Boot框架
Spring Boot是Spring项目的一个子项目,旨在简化Spring应用程序的初始搭建以及开发过程。它通过提供默认配置来减少开发中的配置工作,支持独立运行的Spring应用程序。Spring Boot内置了Tomcat等容器,使得应用无需部署WAR文件即可运行。还提供了多种Starter,方便开发者快速集成各种功能,如数据库访问、消息传递等。Spring Boot的自动配置特性让应用部署变得简单快捷,非常适合微服务架构的开发。
2.2 Vue.js前端框架
Vue.js 是一款用于构建用户界面的渐进式 JavaScript 框架。它通过采用自底向上的增量开发设计,使得开发者可以逐步将 Vue 引入到项目中,而无需一次性重构整个应用。Vue.js 的核心在于其响应式的数据绑定和组合式的视图组件,能够轻松实现数据与视图的同步更新,极大地提高了前端开发的灵活性和效率。Vue 还提供了强大的指令系统、模板语法以及虚拟 DOM 机制,帮助开发者更高效地构建动态、交互性强的单页应用(SPA)。无论是简单的页面还是复杂的应用程序,Vue.js 都能提供简洁且高效的解决方案。
2.3 MySQL数据库
MySQL是一个广泛使用的开源关系型数据库管理系统(RDBMS),它基于SQL(Structured Query Language)语言。MySQL由瑞典MySQL AB公司开发,后来被Sun Microsystems收购,现在是Oracle公司的产品。MySQL以其高性能、可靠性和易用性而闻名。它支持多种操作系统,包括Linux、Windows和macOS。MySQL数据库使用客户端-服务器架构,客户端可以通过网络与服务器进行通信,执行SQL查询和管理数据库。MySQL的特点是它提供了丰富的数据类型,支持事务处理、子查询和复杂的连接操作。MySQL还提供了存储过程、触发器和视图等高级功能,使得开发者可以编写高效的数据库操作代码。
2.4 B/S结构
B/S结构是一种应用程序架构模式,它将应用程序的用户界面和业务逻辑分离。在B/S结构中,用户通过浏览器访问服务器上的应用程序,服务器处理请求并返回结果。它的优势在于它的跨平台性和可访问性。用户不需要安装特定的客户端软件,只需要一个支持Web技术的浏览器即可访问应用程序。这使得B/S应用程序更容易部署和维护。B/S结构通常与MVC模式结合使用,以实现高效的用户界面和业务逻辑分离。在这种模式下,服务器端的应用程序负责处理业务逻辑,并将结果发送到客户端的浏览器进行展示。

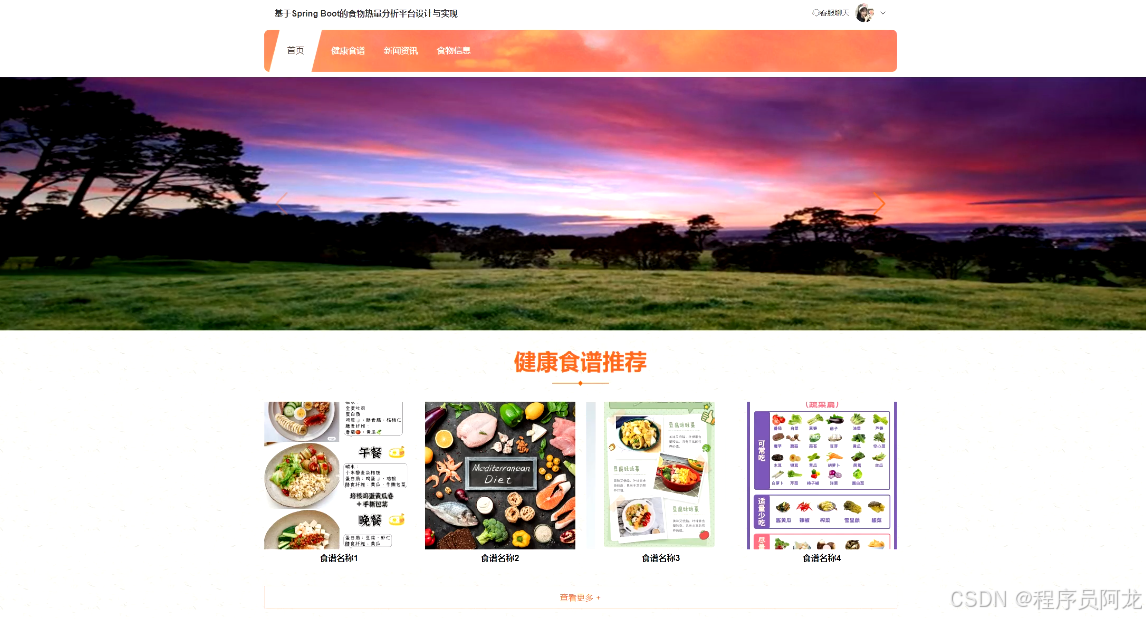
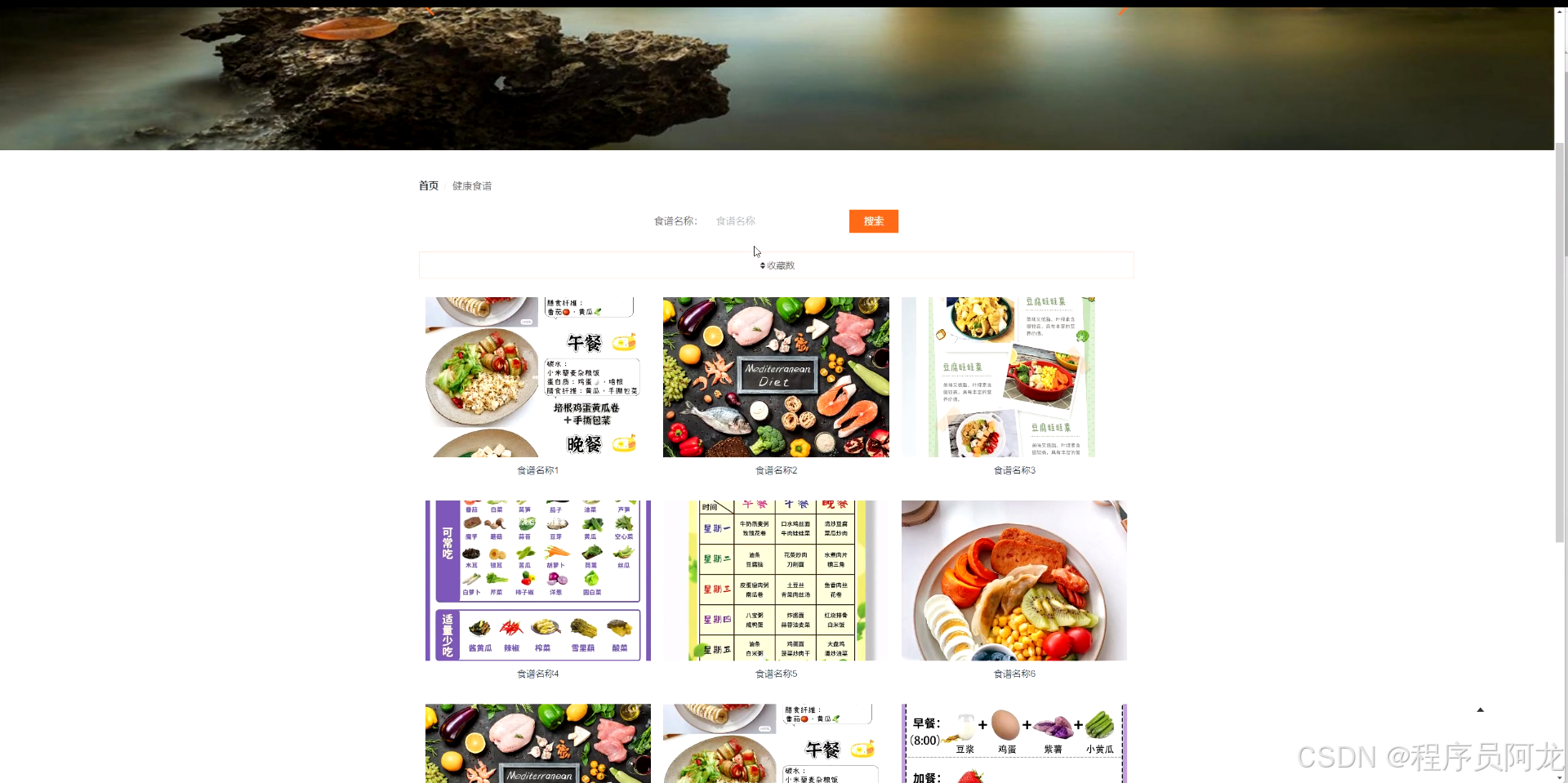
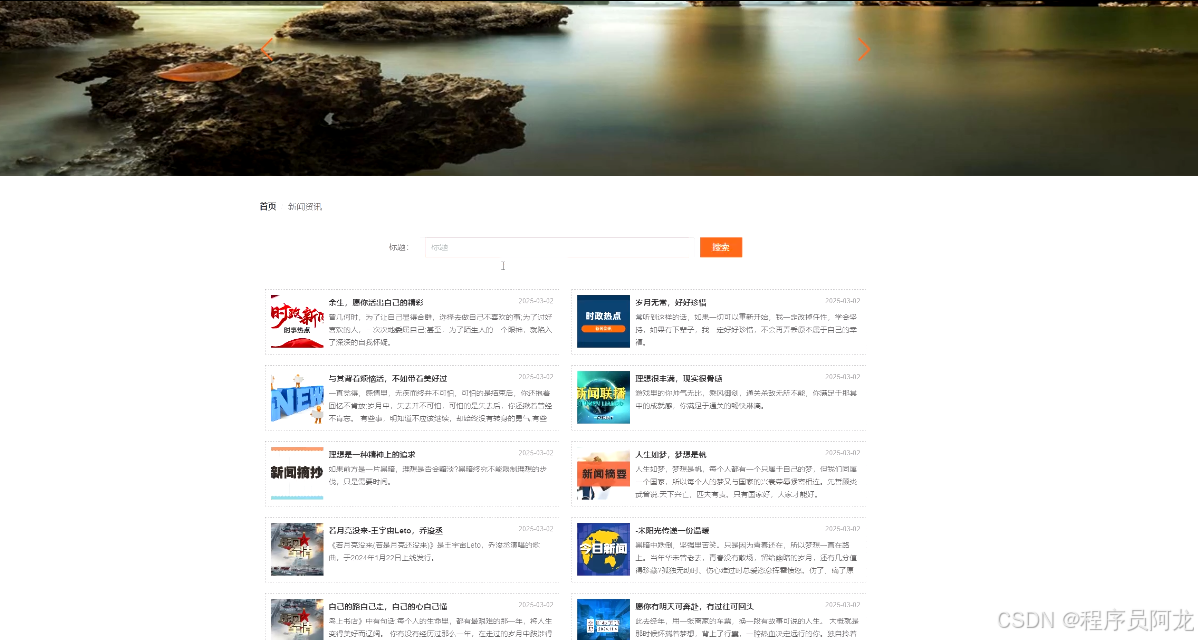
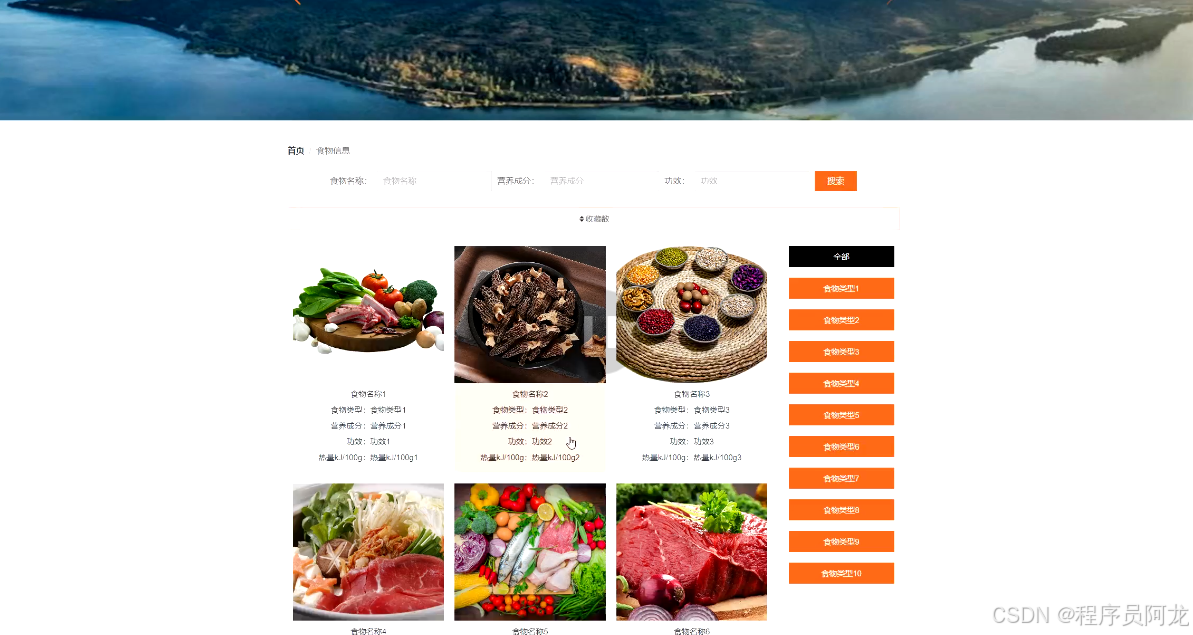
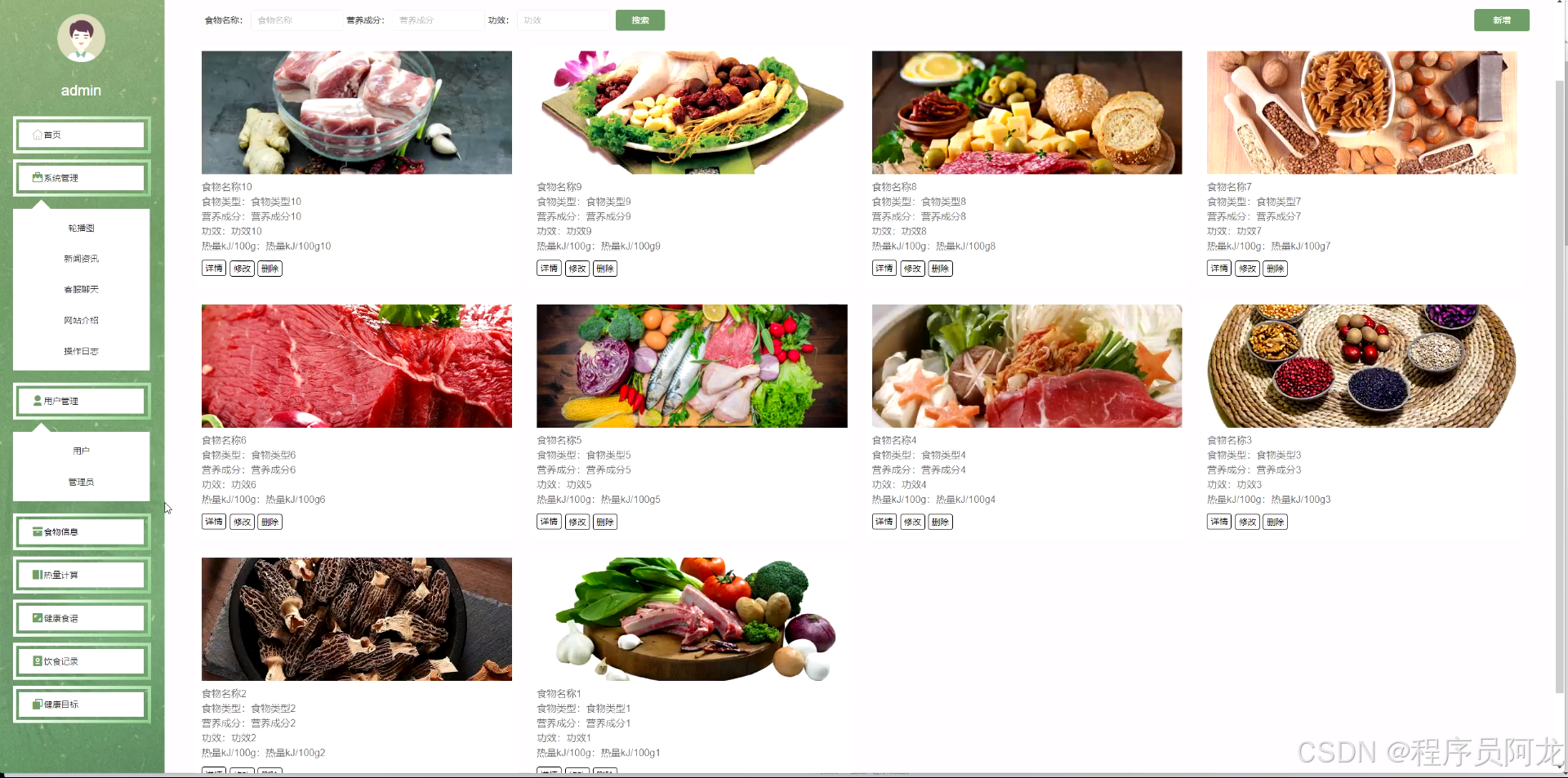
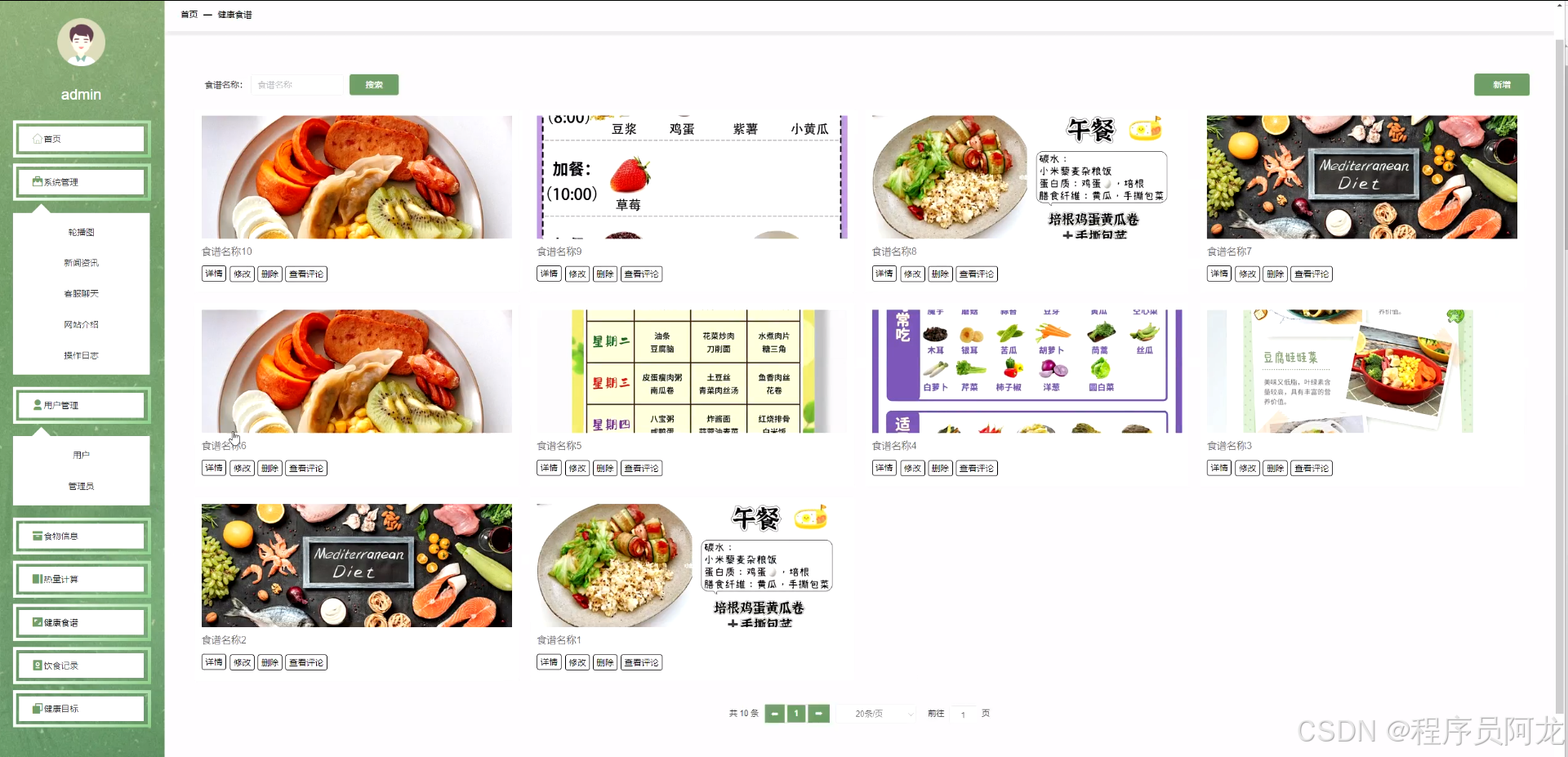
系统界面实现:


import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
class CollaborativeFiltering:
"""
A simple user-based collaborative filtering implementation.
"""
def __init__(self, ratings_matrix):
"""
ratings_matrix: 2D numpy array of shape (num_users, num_items)
with zeros for missing ratings.
"""
self.R = ratings_matrix
self.num_users, self.num_items = self.R.shape
self.user_means = np.true_divide(self.R.sum(axis=1), (self.R != 0).sum(axis=1))
self.similarity = self._compute_user_similarity()
def _compute_user_similarity(self):
"""
Compute user-user cosine similarity matrix based on ratings.
"""
# Normalize by subtracting mean user rating
R_norm = np.zeros_like(self.R, dtype=float)
for u in range(self.num_users):
for i in range(self.num_items):
if self.R[u, i] != 0:
R_norm[u, i] = self.R[u, i] - self.user_means[u]
# Compute cosine similarity
sim = cosine_similarity(R_norm)
np.fill_diagonal(sim, 0) # ignore self-similarity
return sim
def predict(self, user_index, item_index, k=5):
"""
Predict rating of user u for item i using k most similar users.
"""
# Get similarities and ratings for users who rated item
sim_scores = self.similarity[user_index]
# Users who have rated the item
rated_by = np.where(self.R[:, item_index] != 0)[0]
if len(rated_by) == 0:
return self.user_means[user_index]
# Select top-k similar users
neighbors = rated_by[np.argsort(sim_scores[rated_by])][-k:]
sim_neighbors = sim_scores[neighbors]
ratings_neighbors = self.R[neighbors, item_index] - self.user_means[neighbors]
if sim_neighbors.sum() == 0:
return self.user_means[user_index]
pred = self.user_means[user_index] + np.dot(sim_neighbors, ratings_neighbors) / np.sum(np.abs(sim_neighbors))
return pred
# Example usage
if __name__ == "__main__":
# Sample ratings: rows=users, cols=items, 0 means missing
ratings = np.array([
[5, 3, 0, 1],
[4, 0, 0, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4],
])
cf = CollaborativeFiltering(ratings)
u, i = 0, 2
print(f"Predicted rating for user {u} on item {i}: {cf.predict(u, i):.2f}")

为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。
源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











