






前言
本文是借鉴林子雨的教程不用安装zookeeper就可以安装kafka,此文章中的kafka版本包含了zookeeper。(内容有误,请你们直接指出哦~~)(新手教程)
一、kafka是什么?
kafka是一种分布式的,基于发布/订阅的消息系统。它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
二、使用步骤
1.官网下载kafka
访问Kafka官网下载页面(https://kafka.apache.org/downloads):
下载Kafka0.10.2.0的安装包kafka_2.11-0.10.2.0.tgz,此安装包内已经附带Zookeeper,不需要额外安装Zookeeper。

2.用FileZilla吧kafka文件导入虚拟机
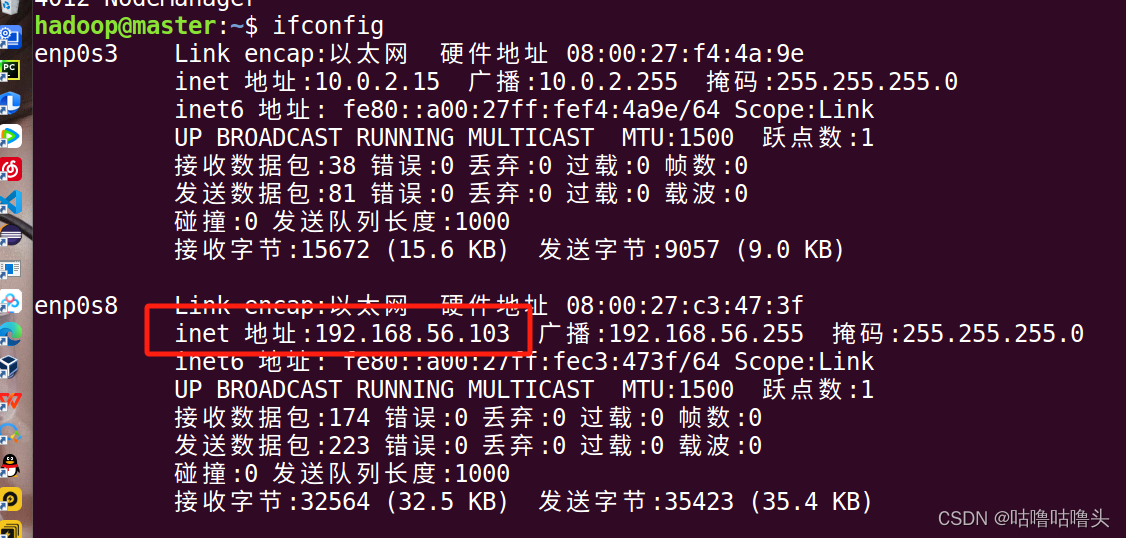
- 打开虚拟机一个终端:用ifconfig命令查看当前虚拟机ip地址:$ifconfig ip=192.168.56.103
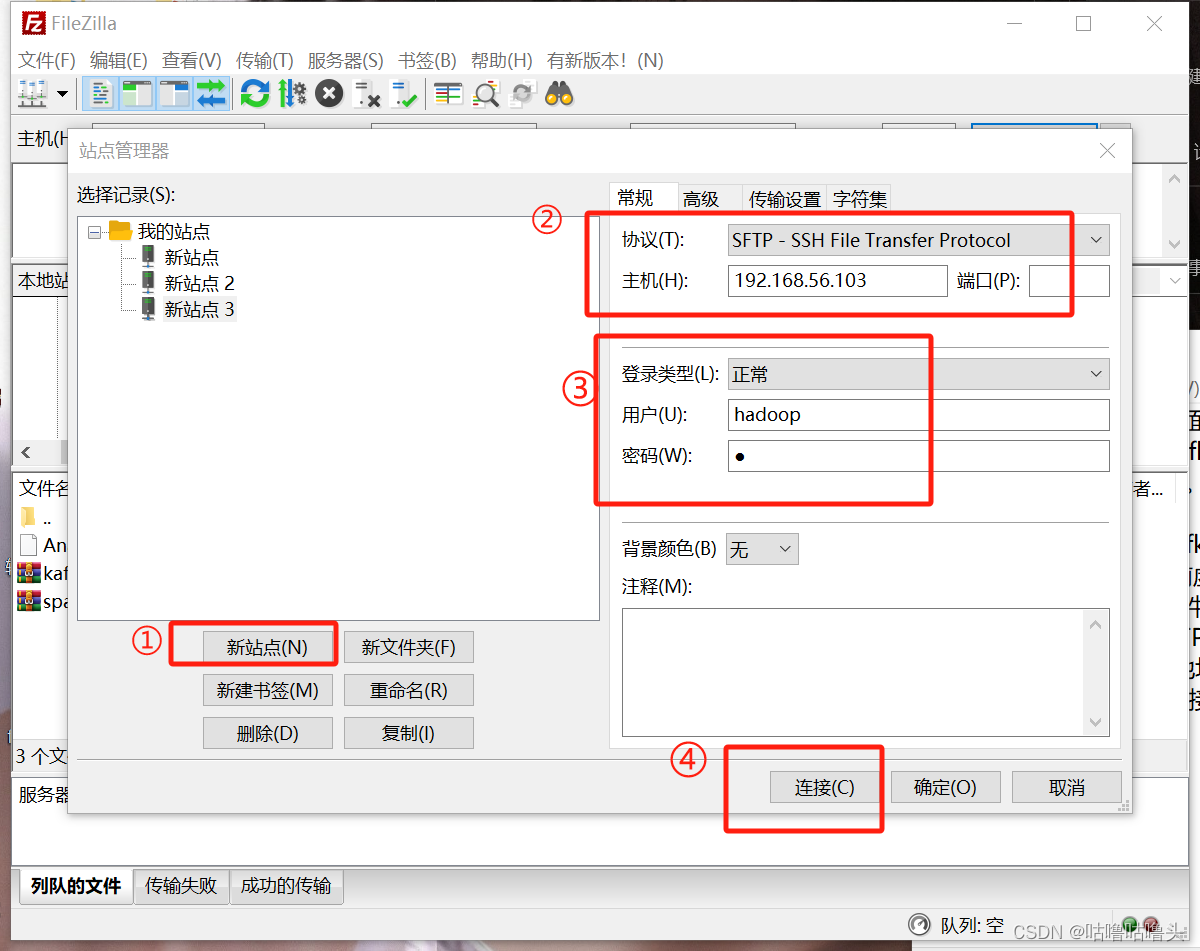
- 用 FileZilla 打开 =>“文件”=》“站点管理器”=》“新站点”=》 “协议”中选择“SFTP - SSH File T ransfer Protocol”=》“主机” 中填你的 ip地址 =》“用户”填你当前 虚拟机用户名称 =》 “密码”你的 登录密码 =》最后点“连接” .
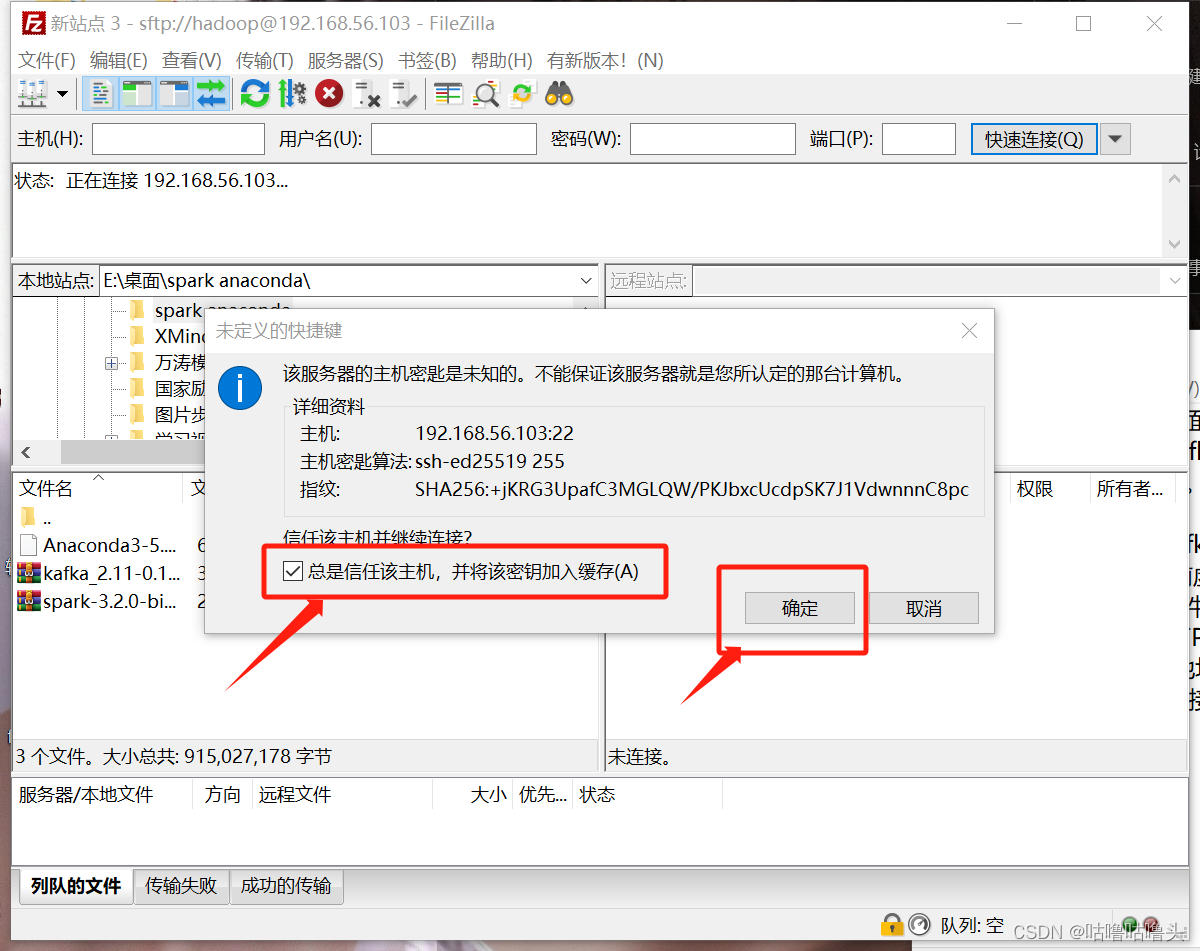
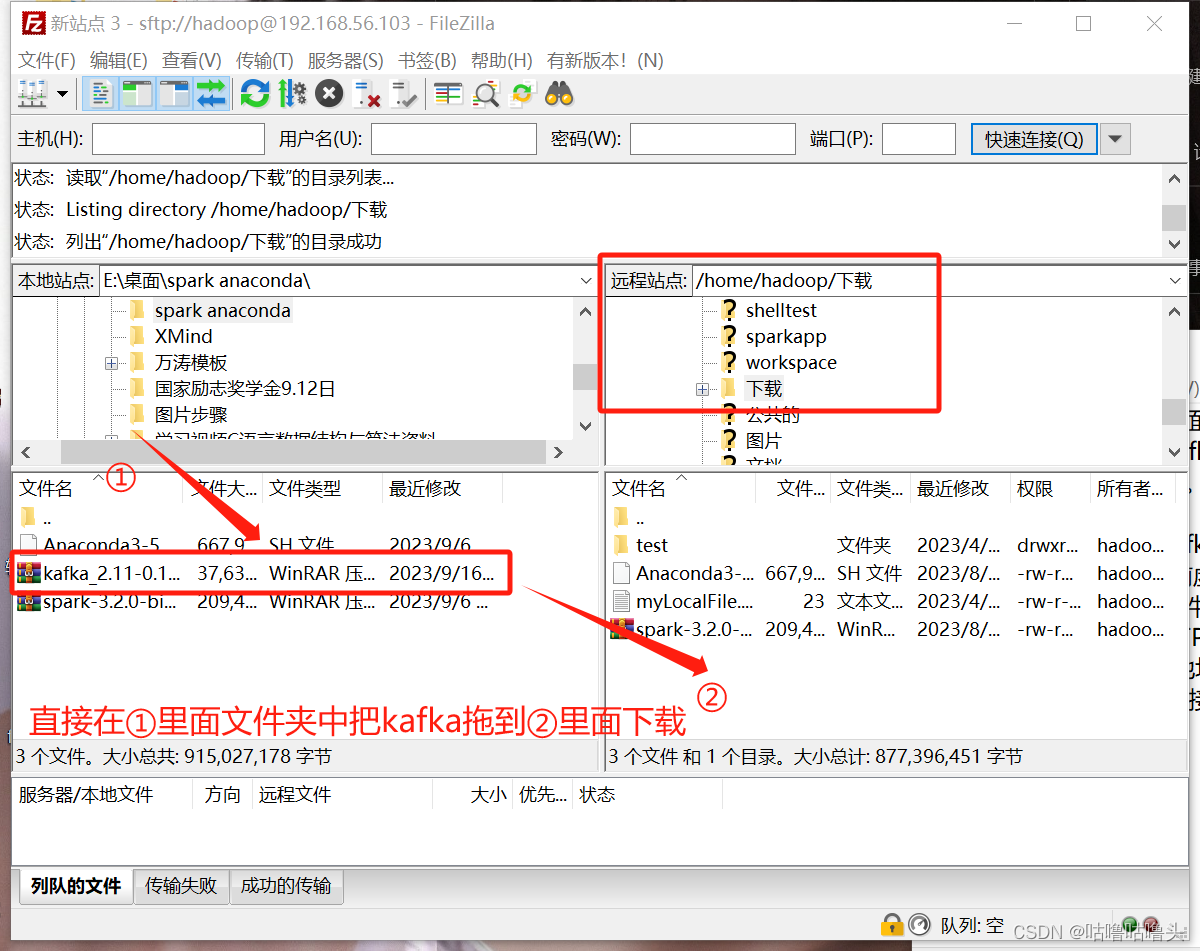
3. 在放kafka文件里面拖到:/home/hadoop/下载;目录中等下载完成。
3.打开虚拟机终端,并输入一下命令
①启动集群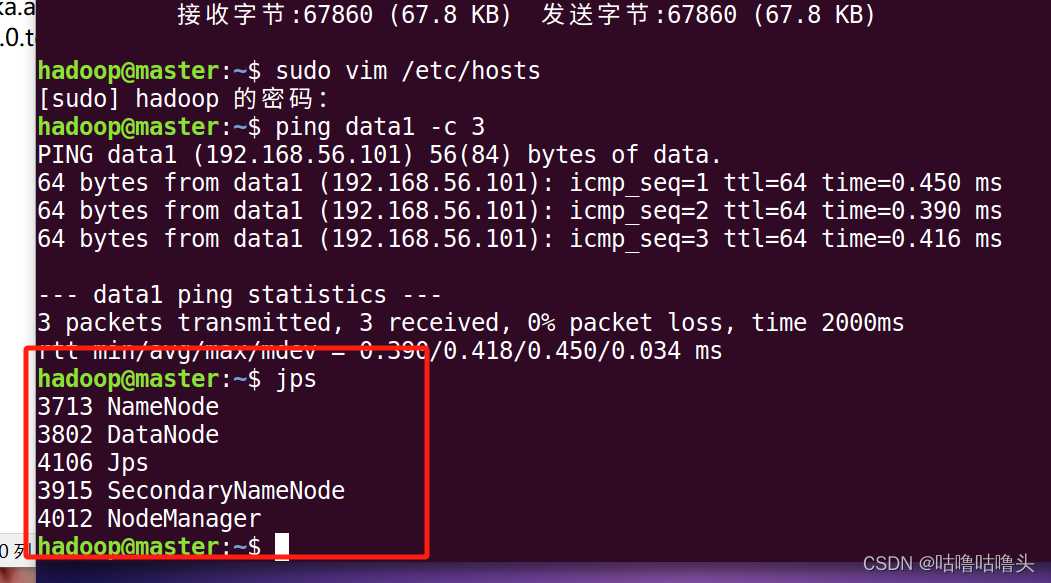
② 回到虚拟机中,打开一个终端,执行如下命令:
$ cd ~/下载
$ sudo tar -zxvf kafka_2.11-0.10.2.0.tgz -C /usr/local
$ cd /usr/local
$ sudo mv kafka_2.11-0.10.2.0/ ./kafka
$ sudo chown -R hadoop ./kafka

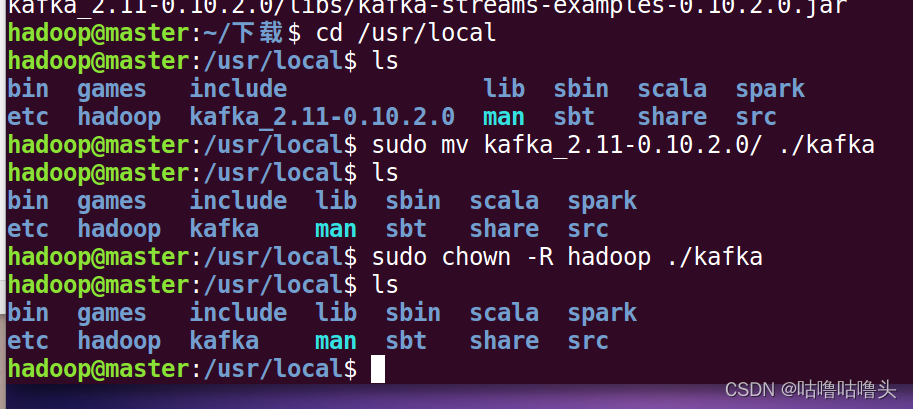
③在虚拟机中下载好kafka
新建一个Linux终端,执行如下命令启动Zookeeper:
$ cd /usr/local/kafka
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties新建第二个终端,输入如下命令启动Kafka:
$ cd /usr/local/kafka
$ ./bin/kafka-server-start.sh config/server.properties新建第三个个终端,输入如下命令:
$ cd /usr/local/kafka
$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab

④可以用list命令列出所有创建的topics,来查看刚才创建的topic是否存在,命令如下:
$ cd /usr/local/kafka
$ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
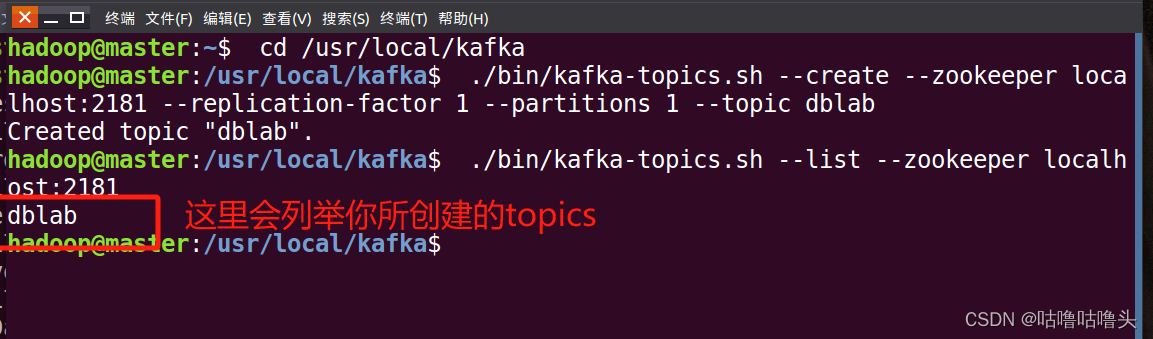
可以在结果中查看到,dblab这个topic已经存在。接下来用producer生产一些数据,命令如下:
$ cd /usr/local/kafka
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab
该命令执行后,可以在该终端中输入以下信息作为测试:
hello hi heihei
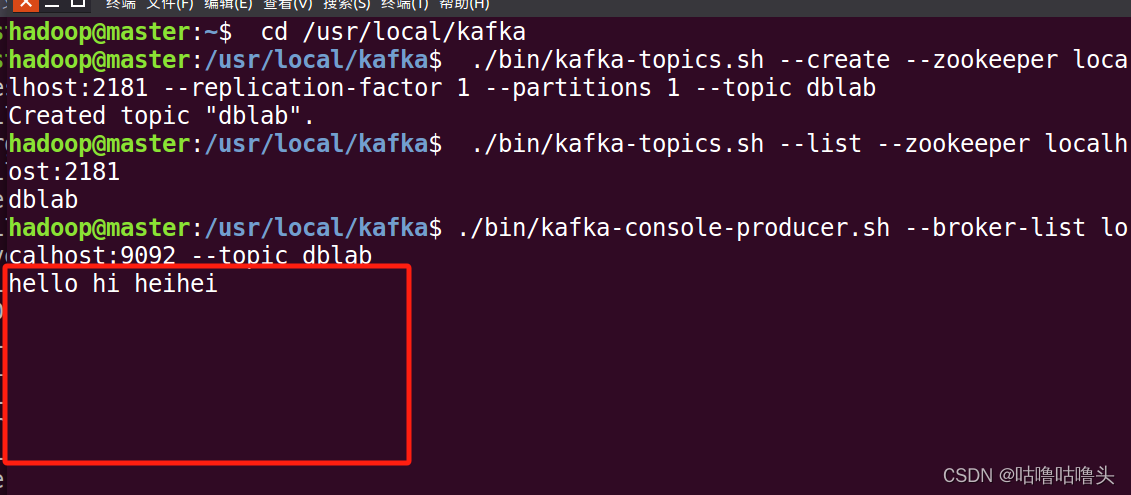
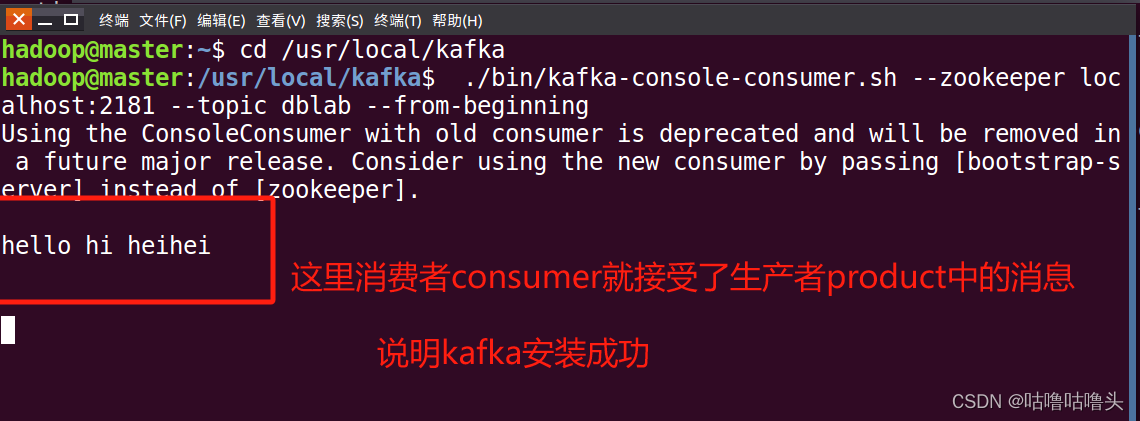
⑤然后,再次开启新的第四个终端,输入如下命令使用consumer来接收数据:
$ cd /usr/local/kafka
$ ./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning执行该命令以后,就可以看到刚才在另外一个终端的producer产生的一条信息
“hello hi heihei”。
说明Kafka安装成功。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了如何下载kafka。以上代码用手敲的时候请小心,敲错了容易报错,最后可以直接复制过去。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









