







目录
2Mysql是如何保证原子性的?【要么同时成功,要么同时失败】
3.Mysql是如何保证持久性的?【事务一旦提交不能进行回滚】
MVCC(Multi-Version Concurrency Control)多版本并发控制
什么是事务?
事务就是操作数据库的最小执行单元,一个事务内的操作要么全部成功,要么全部失败,保证数据的一致性。
事务的四大特性?
事务的四大特性(ACID):原子性Atomicity 一致性Consistency 隔离性Isolation 持久性Durability
原子性:一个事务内的操作要么全部成功,要么全部失败。
持久性:事务一旦提交【不能回滚】,将数据持久化到磁盘中,保证数据不会丢失
隔离性:【事务之间互不影响】两个事务修改同一个数据,必须按顺序执行,并且前一个事务如果未完成,那么中间状态对另一个事务不可见
一致性:【事务执行前后都必须保证数据的总和是一致的】要求任何写到数据库的数据都必须满足预先定义的规则,它基于其他三个特性实现的【【转账的前后金额是一致的,少100,那边就会多100】 】
======================ACID拓展=============================
原子性:事务的原子性是如何保证的?就是如何保证事务回滚时,能够获取到以前的数据?
主要是利用Innodb的undolog日志(回滚日志),当事务进行回滚的时候能够根据undolog日志获取到原本的数据。
持久性:持久性的关键就是事务一旦提交,不能进行回滚。通过undolog实现事务的原子性,通过redolog实现事务的持久性。
undolog是记录旧数据的备份,redolog是记录新数据的备份。
在事务提交之前,只需要将redolog日志进行持久化到磁盘当中,不需要将数据持久化到数据库中。当系统崩溃时,虽然数据没有持久化到数据库当中,但是可以通过Redolog日志获取到新数据,将所有数据恢复到最新的状态。
MySql事务是如何保证ACID四大特性的?
1.Mysql是如何保证一致性的?【数据的一致性】
从数据库层面,数据库通过原子性,隔离性和持久性来保证 一致性。
所以说ACID中C(一致性【数据一致性】)是目的,原子性,隔离性,持久性三个是保证数据的一致性的手段。所以要想保证数据的一致性就需要保证事务中的原子性和隔离性和持久性。第二种,2采用排他锁,就是对当前数据进行操作时就进行加锁,其他事务不能进行操作该数据,只有等待当前线程执行完成释放锁过后才能获取锁。
2Mysql是如何保证原子性的?【要么同时成功,要么同时失败】
使用Innodb的undo log日志(进行回滚),用来记录旧的是数据,当事务执行失败,进行回滚就可以从undolog日志中获取原本的数据。
简明知意,就是回滚日志,是实现原子性的关键,当事务回滚时能够撤销已经执行成功的sql语句,并执行日志中的sql语句恢复旧数据。
3.Mysql是如何保证持久性的?【事务一旦提交不能进行回滚】
利用innodb的redo log日志。
redo log记录的是新数据的备份,在事务提交前,需要将Redo Log持久化到磁盘当中,不需要将数据持久化,当系统崩溃时,虽然数据没有持久化,系统可以根据redo Log的内容,将所有数据恢复到最新的状态
mysql事务的执行流程?
宏观上:开启事务,执行事务,提交事务,出现异常回滚事务。
实际上(举例说明):条件:事务需要将A=1修改成A=3。
执行流程:首先开启事务,将A=1存储到undolog日志用于回滚,修改A=3并将A=3存储到redolog日志(用于存储最新的数据),将redolog持久化到磁盘当中,修改成功,提交事务。
1.A.开启事务.
2.B.记录A=1到undo log.
3.C.修改A=3.
4.D.记录A=3到redo log.
5.E.记录B=2到undo log.
6.F.修改B=4.
7.G.记录B=4到redo log.
8.H.将redo log写入磁盘。
I.事务提交
Spring事务传播(机制)有哪些?
Spring事务传播(Propagation)是指在一个事务方法中调用了其他的事务方法时,当前事务和被调用方法的事务如何进行交互和传播。
在Spring中规定了7种类型的事务传播行为
增删改直接使用事务的注解@Transactional
其中默认就是 Propagation propagation() default Propagation.REQUIRED; boolean readOnly() default false;
查找使用事务注解(支持事务,有就用,没有就不用)
@Transactional(propagation = Propagation.SUPPORTS, readOnly = true)
Spring事务传播有7种类型,分别为:

其中,REQUIRED是默认传播行为,意味着如果当前有事务,则会加入到这个事务中,否则会新开一个事务。SUPPORTS表示如果当前有事务,就加入到这个事务中,如果没有就不处理事务。NEVER表示方法不能在事务上运行,如果当前存在事务,则抛出异常。另外,REQUIRES_NEW和NESTED都是新建一个事务来执行指定方法,不同的是,REQUIRES_NEW是在新的事务中执行,与外部事务相互独立,而NESTED则是在外部事务中启用一个保存点(Savepoint),如果嵌套事务失败,则只回滚这个保存点内的操作。
事务传播机制允许我们在一个方法调用链中控制事务边界,保证多个方法的操作都是原子性的,并且灵活控制事务的提交和回滚。
当我们在Spring中使用注解方式开启事务时,也可以指定事务传播行为。下面是一个简单的Java代码示例:
@Service
@Transactional
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
@Override
public void addUser(User user) {
userDao.addUser(user);
}
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void updateUser(User user) {
userDao.updateUser(user);
}
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void deleteUser(int userId) {
userDao.deleteUser(userId);
}
}在这个例子中,我们使用@Transactional注解来开启事务,然后在updateUser和deleteUser方法上使用@Transactional(propagation = Propagation.REQUIRED)注解,指定事务传播行为为REQUIRED。这意味着如果当前有事务,这两个方法就会加入到这个事务中,否则就会新开一个事务。
另外,addUser方法没有指定事务传播属性,因此默认使用REQUIRED事务传播行为,即如果当前有事务,就加入到这个事务中,如果没有就新建一个事务。
通过这种注解方式,我们可以很方便地指定事务传播行为,来控制事务的边界,并保证多个方法的操作都是原子性的。
Spring事务失效的场景
下面列举几种比较常见的:
-
事务修饰的方法不是公共方法:Spring只会拦截公共方法上的事务注解,如果你的事务方法没有声明为public,那么 Spring 就不会将其纳入事务管理范围,这会导致事务失效;
-
异常被try-catch捕获没有抛出异常: 如果事务方法在捕获了异常后没有将其重新抛出,那么事务就会被回滚,因为 Spring 完全不知道发生了异常;
-
声明的异常类型与抛出的异常不一致: 如果事务方法声明了一个异常类型,但是在方法内部抛出了另一种类型的异常,那么事务也会失效,因为 Spring 不会感知到这个异常;
-
数据库存储引擎不支持事务: 如果使用的是不支持事务的数据库存储引擎Myisam,那么事务注解就没有任何作用了,因为数据库本身就不支持事务机制;
-
手动提交了事务: 如果在事务方法中手动调用了
commit()方法,那么事务就不再受 Spring 管理,也就无法被回滚。
我分别使用代码举例说明这五种场景。
1.事务修饰的方法不是公共方法
// 错误示例
@Transactional
private void doSomething() {
// ...
}
// 正确示例
@Transactional
public void doSomething() {
// ...
}2.异常被try-catch块捕获,但是没有抛出。
// 错误示例
@Transactional
public void doSomething() {
try {
// ...
} catch (Exception e) {
// 异常被捕获,但是没有重新抛出,导致事务失效
}
}
// 正确示例
@Transactional
public void doSomething() {
try {
// ...
} catch (Exception e) {
// 重新抛出异常
throw new RuntimeException(e);
}
}3.声明的异常类型和抛出的异常类型不一致
// 错误示例
@Transactional(rollbackFor = SQLException.class)
public void doSomething() throws Exception {
// ...
// 这里抛出了RuntimeException,但是事务声明的是SQLException,导致事务失效
throw new RuntimeException();
}
// 正确示例
@Transactional(rollbackFor = RuntimeException.class)
public void doSomething() throws Exception {
// ...
throw new RuntimeException();
}4.数据库存储引擎不支持事务
数据库存储引擎使用的是Myisam,这种情况下,无论如何设置事务注解都无法让事务生效。
如何指定数据库的存储引擎:
1.可以通过在创建表的语句中指定存储引擎来决定该表使用哪种存储引擎。
CREATE TABLE my_table (
id INT PRIMARY KEY,
name VARCHAR(50)
) ENGINE=InnoDB;
在上面的示例中,使用了ENGINE=InnoDB来指定表的存储引擎为 InnoDB。你可以将 InnoDB 替换为其他支持的存储引擎,如 MyISAM、MEMORY 等。
如果你想设置默认的存储引擎,可以在 MySQL 配置文件(如 my.cnf 或 my.ini)中添加以下配置:

[mysqld]
default-storage-engine=InnoDB
5.手动提交了事务
如果在事务方法中手动调用了commit()方法,那么事务就不再受 Spring 管理,也就无法被回滚。事务是交给Spring进行管理的,来对事务进行开启、执行、提交、回滚。
// 错误示例
@Transactional
public void doSomething() {
Connection conn = getConnection(); // 假设这个方法获取一个连接对象
try {
conn.setAutoCommit(false); // 关闭自动提交
// ...
conn.commit(); // 手动提交,导致事务失效
} catch (Exception e) {
conn.rollback();
} finally {
conn.close();
}
}
// 正确示例
@Transactional
public void doSomething() {
// 不需要手动提交事务
// ...
}数据库并发问题有哪些问题?
首先要知道是数据库并发问题,就是当多个事务同时对同一个数据(例如数据库的一行数据)进行操作时,导致数据不一致问题。
数据库并发可能出现那些问题呢?
1脏读:读取到的数据可能是其他事务未提交到数据库的数据。
例如,事务A先读取了一条数据,并对这条数据进行修改,还未提交,这时候事务B对这条数据进行查询,读到的是已经被事务A修改但未提交的数据。这就会导致数据的不一致性。

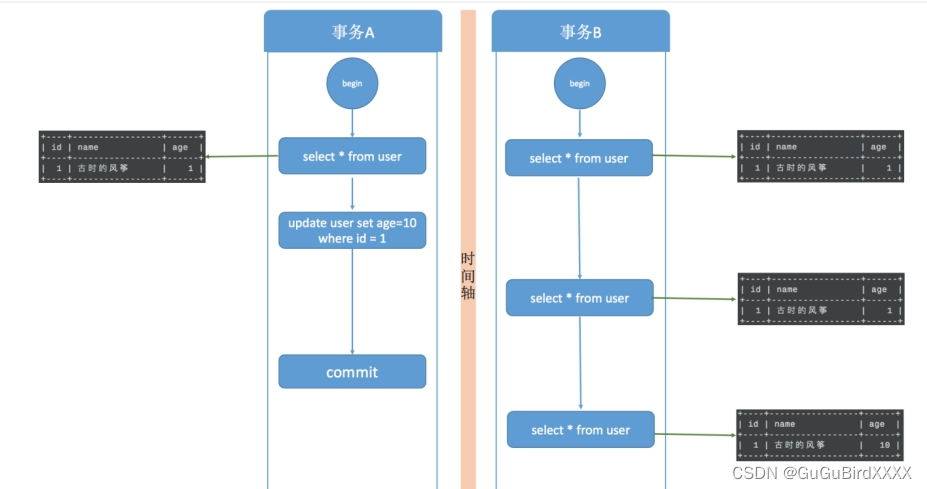
2不可重复读:同一个事务中多次使用相同条件读取到的数据不一致。
例如,事务B读取了一条数据,此时事务A修改了这条数据并提交,事务B再次读取同一条数据时,读到的数据与之前读取的不一致,这种情况就称为不可重复读。
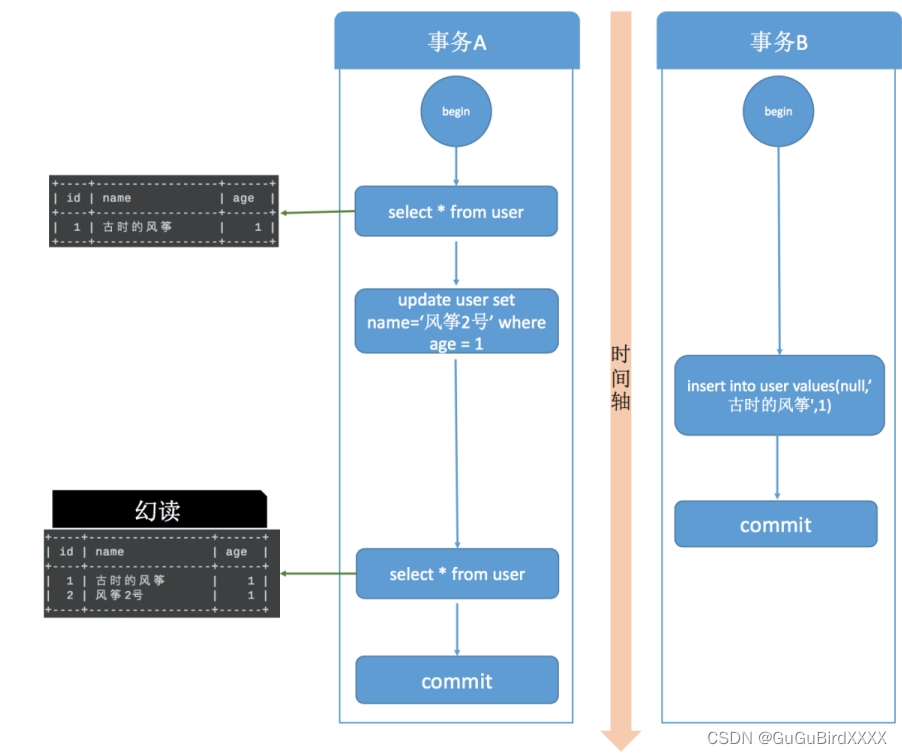
3幻读:同一个事务使用相同的条件读取到的数据条数不一致。
事务A根据某个条件查询了一条数据,此时事务B插入了一个符合条件的新数据并提交,事务A再次按照同样的查询条件再次查询时,会发现多查询出了一条数据,这就称为幻读。
但是当你在 MySQL 中测试幻读的时候,并不会出现上图的结果,幻读并没有发生,因为MySQL数据库在InnoDB存储引擎中采用了MVCC(多版本并发控制)来解决幻读问题。MVCC的实现方式是在每行数据后面添加两个隐藏字段:一个是创建时间,一个是过期时间。在读取某一行数据时,只能读取创建时间早于当前事务开始时间或过期时间为空的行,这样可以有效避免幻读问题的发生。
同时,MySQL数据库还提供了一些锁机制来避免幻读的发生,如共享锁和排他锁。在使用MySQL的InnoDB存储引擎时,可以通过使用SELECT … FOR UPDATE语句和SELECT … LOCK IN SHARE MODE语句来分别获取排他锁和共享锁,从而控制并发执行事务的锁竞争。
在MySQL 8.0版本中,还提供了一种新的隔离级别:REPEATABLE READ WITH CONSISTENT SNAPSHOT。这种隔离级别集成了MVCC和锁机制,能够有效地解决幻读问题。在这种隔离级别下,每个事务在开始时会创建一个一致性的快照,读取时只能读取该快照中的数据,就像数据是静态的一样,因此能够大大降低幻读问题的发生。
4.丢失更新:丢失更新是指多个事务同时修改同一行数据,其中一个事务的修改可能会被另一个事务的修改覆盖,导致数据的丢失。
4.1.第一类丢失更新:也叫回滚丢失,事务A和事务B(多个事务)同时对同一条数据进行写操作,事务B先完成了修改,此时事务A异常终止,回滚后造成事务B的更新也丢失了
4.2.第二类丢失更新:也叫覆盖丢失,事务A和事务B同时对同一条数据进行写操作,事务B先完成了修改,事务A再次修改并提交,把事务B提交的数据给覆盖了。
丢失更新问题
脏读,幻读,不可重复读:都是发生在一个事务在写,一个事务在读的时候出现的问题。
丢失更新:都是发生在多个事务同时都在做写操作的时候出现的。
丢失更新分为:回滚丢失更新(一类)和覆盖丢失更新(二类)
事务隔离级别有那些?分别解决了什么问题?
事务隔离级别:指在数据库并发访问时,控制多个事务之间的隔离程度。
主要的目的就是解决数据库并发问题:脏读、幻读、不可重复读、丢失更新等问题。
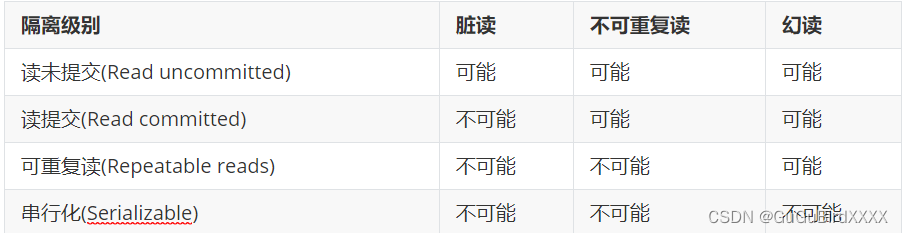
事务隔离级别包含4种:
1、读未提交(READ UNCOMMITTED)
最低的隔离级别,一个事务可能读取到另一个事务未提交的修改,这可能导致脏读(读到未提交的数据)和不可重复读(同样的查询条件读取到的数据结果不一致)和幻读问题。
2、读提交(READ COMMITTED)
一个事务只能读取到已经提交的修改,可以解决脏读问题,但是可能会导致不可重复读和幻读问题。
3、可重复读(REPEATABLE READ)
一个事务在同一个事务中执行多次相同的查询,查询的数据结果都是一致的。但是,其他事务可以插入新数据,导致幻读(条数不一样)问题。
4、串行化(SERIALIZABLE)【乐观锁和悲观锁】:
最高的隔离级别,事务是串行执行的,防止脏读、不可重复读和幻读,但是并发性能会大大降低。
MVCC(Multi-Version Concurrency Control)多版本并发控制
MVCC(Multi-Version Concurrency Control)是一种数据库事务并发控制机制,用于解决数据库并发问题。它通过为每个事务创建不同的数据版本来处理并发访问。这些版本使用事务的时间戳或标识来区分,并且允许多个事务同时读取和修改不同版本的数据,从而提高数据库的并发性能。
-
版本号管理:MVCC 基于多版本数据模型,每次数据库中的访问都会按时间戳或版本号生成一个快照。新的事务只能查看旧版本的状态,在当前事务执行期间,任何新数据的变化都会生成一个新的版本号,从而使得数据的访问和变化能够隔离。
-
快照读和当前读:MVCC 支持两种访问方式:快照读和当前读。在快照读中,事务会读取之前某个时间的数据版本,而在当前读中,则会读取最新的数据版本。在当前读中,如果其它事务正在写入或者修改数据,则当前读的事务会被阻塞,直到其它事务释放锁并提交事务。
-
乐观锁和悲观锁:MVCC 支持两种锁机制:乐观锁和悲观锁。悲观锁基于独占锁,即事务在读取和修改数据时会将所访问的数据加锁,避免其它并发事务对相同数据的读写操作。而乐观锁则基于版本号管理,事务在读取数据时不加锁,只是在提交数据时根据版本号比较数据的变化情况,以此来处理并发冲突。
-
事务隔离级别:MVCC 应用在数据库事务的并发控制中,需要对事务隔离级别进行处理。不同的隔离级别会影响 MVCC 的实现策略,例如在 Repeatable Read 隔离级别下,系统会在每次事务执行时生成一个可重复读快照,隔离当前事务和其它并发事务,避免事务之间出现脏读、不可重复读等问题。
总体来说,MVCC 的底层原理主要包括版本号管理、快照读和当前读、乐观锁和悲观锁和事务隔离级别等方面。通过在数据库中使用多版本控制技术,使得事务可以在并发操作时保持数据的一致性和完整性,同时提高了数据库的并发性能。
什么是丢失更新,如何解决?
丢失更新发生在两个事务同时都在做写操作的时候出现的。
丢失更新包括:第一类丢失更新(回滚丢失)和第二类丢失更新(覆盖丢失)
第一类丢失更新【回滚丢失】:
事务A和事务B两个事务同时对同一条数据进行写操作,事务B先完成了修改,此时事务A异常终止,回滚后造成事务B的更新也丢失了.

以上的例子很容易解释清楚第一类丢失更新,也就是 A事务回滚时,把已经提交的B事务的更新数据覆盖了。
第二类丢失更新【覆盖丢失】:
事务A和事务B两个事务同时对同一条数据进行写操作,事务B先完成了修改,事务A再次修改并提交,把事务B提交的数据给覆盖了。
如何解决丢失更新?
采用乐观锁或者悲观锁进行解决。
悲观锁和乐观锁是两种思想,用于解决多线程并发场景下数据安全的问题。
-
悲观锁,每次操作数据的时候,都会认为会出现线程并发问题(会同时对数据进行修改),一开始就会进行上锁,执行完成过后才会释放锁,线程安全,性能较低,适用于写多读少的场景
-
乐观锁,每次操作数据的时候,认为不会出现线程并发问题。不会使用加锁的形式而是在提交更新数据的时候,判断一下在操作期间有没有其他线程修改了这个数据,如果有,则重新读取,再次尝试更新(Retry),循环上述步骤直到更新成功 。否则就执行操作。线程不安全,执行效率相对较高,适用于读多写少的场景
悲观锁一般用于并发冲突概率大,对数据安全要求高的场景。【会进行加锁,不会出现线程安全问题。乐观锁在执行更新时频繁失败,需要不断重试,反而会浪费CPU资源】
乐观锁一般用于高并发,多读少写的场景【乐观锁不会进行加锁,其他线程可以进行同时访问,提高响应效率】
乐观锁的使用场景?
ES是采用的乐观锁,因为ES的使用场景为读多写少,基本上不会出现线程并发问题。
什么是分布式事务?
分布式事务指的是在分布式系统当中,其中的事务操作涉及到多个服务器,多个数据库,多个系统,这些操作要保证原子性,一致性,隔离性和持久性【要么同时成功要么同时失败】。
假设有一个跨部门合作的企业采购系统。该系统包括采购部门和财务部门的两个子系统,分别负责采购订单的创建和支付操作。每当采购部门创建订单时,财务部门需要批准并支付相应的款项。这里涉及两个不同的数据库和服务,需要保证跨部门的操作是原子性的。
那么如何实现分布式事务呢?又是如何进行选型的呢?
常见的分布式事务实现方案,2PC/3PC,TCC,MQ最终一致性,最大努力通知等
2PC,它将整个事务流程分为两个阶段,P指的是准备阶段,C指的是提交阶段。它是一个阻塞协议,不适用于并发较高[因为需要等待参与者提交事务的状态],事务生命周期长的分布式事务。
TCC,它是基于补偿性事务的AP系统的一种实现,补偿也就是说先按照预定方案执行,如果失败了就走补偿方案。它可以自定义数据库操作的粒度(即数据统计的详细程度)。使得降低锁冲突【等待别的线程释放锁】,提高吞吐量(单位时间内成功地传送数据的数量),但是对应用的侵入性强,每个接口都需要实现try confirm cancel方法。改动成本高,实现难度大可以用在登录送积分,送优惠券等等场景
可靠消息最终一致性【rocketMQ】,系统A本地事务执行成功,并通知系统B执行,通常通过MQ实现。实现服务之间解耦,数据保持弱一致性,并且实时性要求不高的场景
最大努力通知【支付宝的支付结果通知,扣款通知】,是在不影响主业务的情况下,尽可能的保证数据的一致性,它适用于一些最终一致性敏感度低的业务,比如支付结果通知
什么是2PC?
2PC(二阶段提交)是一种常见的实现分布式事务的方式,它需要一个事务管理者(Coordinator)和多个参与者(Participant)节点之间的协作来完成。以下是2PC的执行流程:

2PC(Two-Phase Commit):
-
协调者/事务管理器(Coordinator):负责协调整个分布式事务的执行流程,向参与者发送请求,决定是否提交或回滚。
-
参与者(Participants):各个分布式事务的执行者,参与者执行本地事务的准备、提交或回滚操作,并将准备状态和结果通知协调者。
-
准备阶段(Prepare Phase):第一个阶段,在这个阶段,协调者向所有参与者发送准备请求,参与者执行本地事务的准备操作并通知协调者。
-
提交阶段(Commit Phase):第二个阶段,在这个阶段,如果所有参与者都准备好提交,协调者向所有参与者发送提交请求,参与者执行本地事务的提交操作。
-
回滚阶段(Rollback Phase):如果准备、提交中有任何一个步骤失败,参与者会执行回滚操作,撤销之前的事务操作。
但是也有很多缺陷:
性能问题: 同步请求,需要等待所有事务参与者执行完毕,事务协调器才能通知进行全局提交,最后才会释放资源。
事务管理器单点故障:一旦事务管理器(协调者)挂掉,导致参与者接收不到提交或回滚的通知。
丢失消息导致数据不一致:在提交阶段,如果事务管理器出现故障,一部分事务参与者收到了提交消息,另一部分事务参与者没有收到提交消息,造成数据不一致问题(就是通知了一部分提交失误了,然后事务管理器宕机了,造成数据不一致问题。)
面试回答:
2PC是实现分布式事务的一种方式,2PC包含两个阶段,准备阶段和提交阶段。准备阶段主要是事务管理器向所有参与者发送prepare命令,所有参与者将 undo(回滚日志) 和 redo(重做日志) 信息记入事务日志中,并进行执行本地事务,但未提交事务,并将执行结果(ok/error)返回给事务管理器,然后事务管理器根据返回的结果发送commit命令或rollback命令给所有的参与者,参与者根据事务管理器的命令进行提交或者回滚,并将确认消息发送给协调者,并释放事务处理过程中所是使用的资源,协调者获取到参与者返回的确认消息,决定事务的最终状态。
2PC代码举例说明:
下面为了更好的理解2PC如何解决分布式事务的,用一个简单的例子进行解释:
假设有一个在线支付系统,包括订单服务和支付服务。在用户下单并支付时,订单服务需要记录订单信息,支付服务需要处理支付操作。这两个操作需要在不同的服务和数据库中执行,为了保证一致性,可以使用2PC协议。
订单服务:处理订单的创建和记录。
// 订单服务代码示例
public class OrderService {
//Prepare阶段(准备阶段)
public boolean createOrder(int orderId) {
// 在数据库中记录订单信息
boolean success = recordOrderInDatabase(orderId);
return success;
}
//Commit阶段(提交阶段)
private boolean recordOrderInDatabase(int orderId) {
// 实际数据库操作,返回操作结果
}
}
支付服务:处理支付操作。
// 支付服务代码示例
public class PaymentService {
//Prepare阶段(准备阶段)
public boolean processPayment(int orderId, double amount) {
// 执行支付操作
boolean success = executePayment(orderId, amount);
return success;
}
//Commit阶段(提交阶段)
private boolean executePayment(int orderId, double amount) {
// 实际支付操作,返回操作结果
}
}
事务管理器:负责协调两个服务的分布式事务。
// 事务管理器代码示例
public class Coordinator {
public boolean performTwoPhaseCommit(int orderId, double amount) {
// 第一阶段:准备阶段
boolean prepareSuccess = prepare(orderId, amount);
if (prepareSuccess) {
// 第二阶段:提交或回滚
boolean commitSuccess = commit(orderId, amount);
// 第二阶段返回的结果
if (commitSuccess) {
return true;
} else {
//回滚
rollback(orderId);
return false;
}
} else {
return false;
}
}
private boolean prepare(int orderId, double amount) {
// 调用订单服务和支付服务,执行准备操作
}
private boolean commit(int orderId, double amount) {
// 调用订单服务和支付服务,执行提交操作
}
private void rollback(int orderId) {
// 调用订单服务和支付服务,执行回滚操作,将准备阶段创建的数据进行删除
}
}
在上面的示例中,事务管理器(Coordinator)负责协调订单服务和支付服务的两个阶段操作。在第一阶段,事务管理器(Coordinator)会调用两个服务的准备操作,以确保资源都准备好执行事务。如果准备成功,事务管理器(Coordinator)在第二阶段会调用提交操作,如果提交成功,整个分布式事务完成。如果任何一步操作失败,协调者会调用回滚操作,以保证数据一致性。
什么是TCC?

TCC的执行流程如下:
-
协调者/事务管理器(Coordinator):和2PC中的协调者类似,负责协调整个TCC事务的执行流程,但TCC更强调业务逻辑的控制。
-
参与者(Participants):执行TCC事务的服务,每个参与者都需要实现事务的三个阶段:Try、Confirm和Cancel。
-
Try阶段:在这个阶段,参与者执行预操作,锁定资源等,但不做实际的持久化。
-
Confirm阶段:在这个阶段,参与者执行实际的业务操作,确认事务的执行。
-
Cancel阶段:在这个阶段,如果有任何阶段失败,参与者执行回滚操作,撤销之前的预操作。
面试:
TCC是实现分布式事务的一种方式,它跟2PC都包含了事务管理器和参与者,但是它的参与者都需要实现事务的三个阶段:1尝试阶段,2确认阶段,3取消阶段。尝试阶段首先会尝试执行事务操作(锁定事务操作需要的资源),然后将事务操作结果返回给事务管理器,如果参与者全部返回成功,事务管理器则进入确认阶段,如果失败则进行取消阶段。参与者进入到准备阶段执行真正的事务操作,然后将执行结果返回给事务管理器,只要有一个参与者返回失败,则进入取消阶段,进行回滚事务,如果全部成功,则把事务标记为成功。
也有一定的缺陷:
1业务逻辑性更强,每个参与者都要实现事务的三个阶段,代码耦合度比较高。
什么是CAP理论 , 哪些技术用到AP,哪些用到CP?
CAP理论是分布式系统设计中的一个重要原则,它强调在分布式系统中,无法同时满足一致性(Consistency),可用性(Avaliability),分区容错性(Partition Tolerance),三个要素最多只能同时实现两点,不能同时兼顾。
分布式容错:指的是分布式系统某个节点或网路分区出现故障的时候,系统可以正常运行。
可用性:每次请求都会有响应【但是不会保证数据的一致性】。简而言之就是客户可以一直正常访问并得到系统地正常响应,不会出现访问超时等问题。
一致性:在分布式系统中,所有的节点在同一时间读取的数据都是一致的,进行写操作后再去进行获取应该获取到最新的值,数据的一致性。
分区容错性是分布式系统的核心关键,如果一个节点或网络分区出现故障,整体就挂掉了,这就不叫作分布式系统。
满足CP,也就是满足一致性和容错性,舍弃可用性,如果系统要保证数据地强一致性(必须等待数据同步才进行响应)就可以考虑。例如银行存款(一定要实时)
满足AP,也就是满足可用性和容错性,舍弃一致性,如果系统允许数据的弱一致性(最终一致性即可,获取的数据不是最新的,但最终是一致的)可以考虑。例如点赞数的显示(不一定要实时)
什么是Base理论?
Base理论是分布式系统设计的一种理念,分别代表:基本可用(Basic Available),软状态(Soft State),最终一致性(Eventually Consistency)。在分布式系统中某个节点或网络分区出现故障时,系统依然可以正常运行。允许在一段时间内数据不一致,但要保证数据的最终一致性。
- 基本可用(Basic Available):指的是在系统中,某个节点或网络分区发生故障时,系统仍然能够提供基本的使用;
- 软状态(Soft State):指的是在系统中,允许数据可以在一段时间内不一致的状态;
- 最终一致性(Eventually Consistency):指的是在系统中,数据最终会达到一致的状态。

















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











