







目录
布隆过滤器【布谷鸟过滤器】
布隆过滤器中有的,数据库中不一定有,布隆过滤器没有的数据库一定没有。
布隆过滤器就是一个二进制的数组。
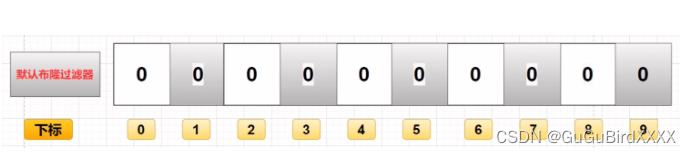
布隆过滤器的作用
就是判断这个数据是否存在这个数组里面,存在就是1 不存在就是0。
那么布隆过滤器是如何将数据用0和1进行表示的呢?
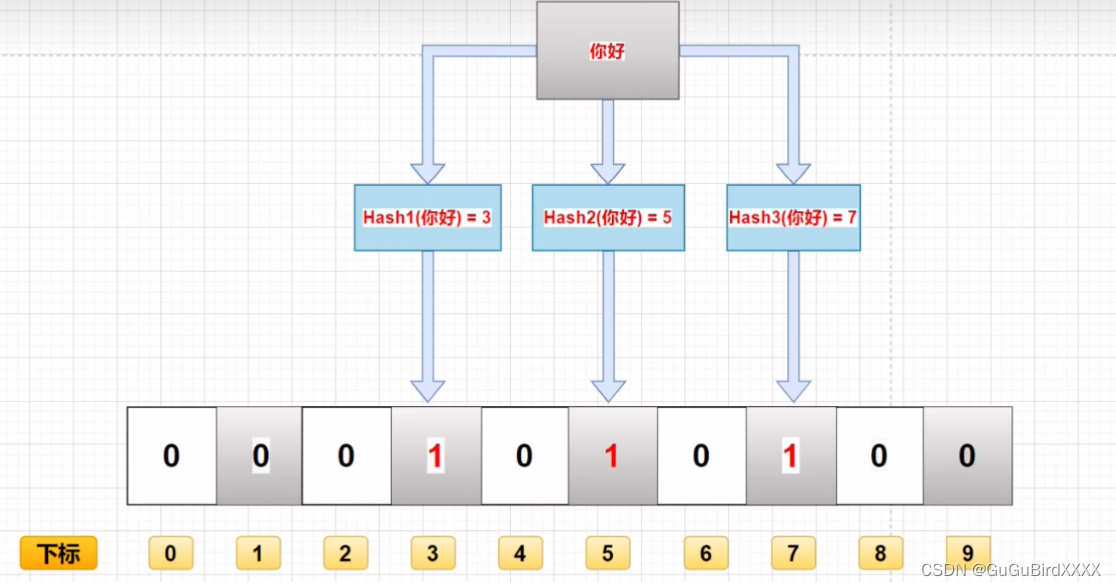
布隆过滤器如何进行存储?
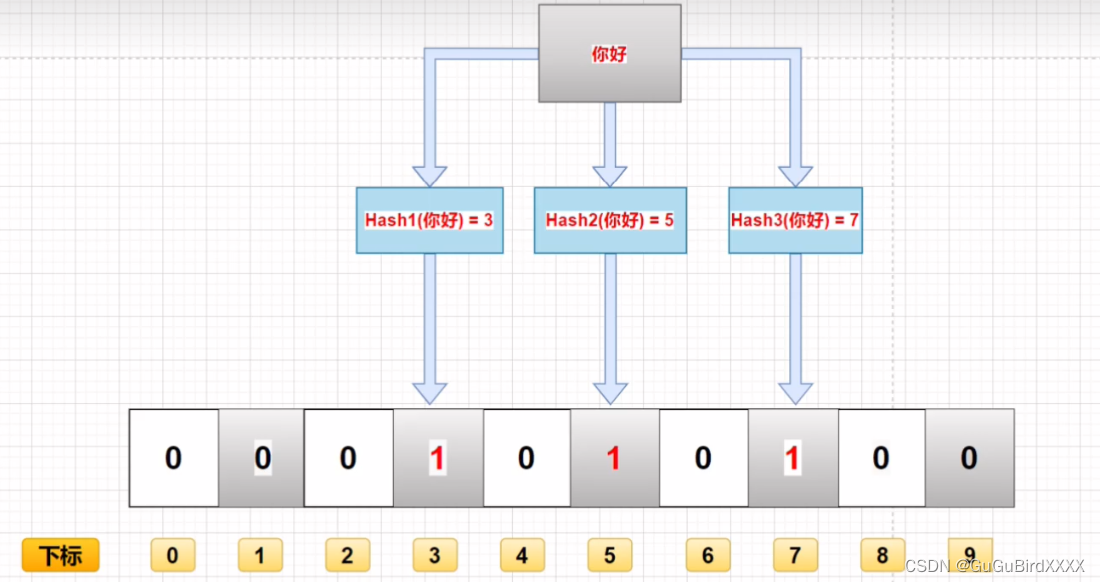
比如说我要把你好存储到数组中需要经历几个步骤呢?
首先布隆过滤器进行多个hash函数计算,然后计算出多个hash值(不止3个,任意多少个),然后将多个hash值映射到数组中,然后将数组中的0改成1,这样就存储到了数组中去了。
如果我要对 你好 这个值进行查询的时候,会将这个数据进行多个hash函数进行计算,然后计算出的hash值对应的数组下表中的数据都必须是1,才能证明你好这个数据存在数组中,只要一个不为1,就说明数组中不存在该数据。
这有两个关键点就是多个hash函数和数组中的二进制值都i是1才能证明这个数据存在、
那为什么要这样设计呢?
因为hash出来的结果取模后是有限的,所以在存储大量数据的时候,会有多条数据hash值相同,产生hash碰撞。从而采用多个hash函数进行计算,然后每条数据对应多个数组值映射的二进制值在数组中,以此来保证多个数据可以保存到有限的数组中且不会出现重复。
布隆过滤器如何进行删除的呢?

如果我们现在对你好和hello进行hash函数计算过后发现他们两个存储在数组中的位置都是一样的,这时候对下标为2的数据进行删除,就不知道删除的是hello还是你好,就会删除两条数据,二而且查询的时候也会出现这个问题。造成了误删,很难做到删除。
布隆过滤器的优点:
采用二进制数组组成的数据,占用的空间比较小。
它的查询和插入的速度是非常快的,因为是基于数组进行查询和添加,直接通过计算hash值找到对应的下标进行查询或者修改。所以它的时间复杂度是O(K)。
为什么是O(k)呢?
因为我们进行hash计算的时候这里有多个hash函数,这里的k表示的是hash函数的个数,如果只有1个的话时间复杂度为O(1).k个则为O(k)
=========================================================================
用到多个hash函数就是为了创建多个hash值填充到不同的数组下标处,加强命中的概率和减少缓存穿透的几率。
假如【hello和你好存储在数组中的位置都为2】现在我下标为2的这个数组中只存储了你好,那么这时候要存储hello,布隆过滤器就要判断这个hello是否存在这个数组之中,然后经过hash计算过后发现应该存储再下标为2的数组中,然后取出数组中的二进制数发现为1,说明已经存在,但是其实并不存在,这时候布隆过滤器就出现了误判的情况。
因为你好和hello hash值是相同的,对应的下标也是相同的,下标对应的二进制数据也hi一样的。所以也就出现了误判。几乎解决不了的问题,所以我们只能减少误判的概率。
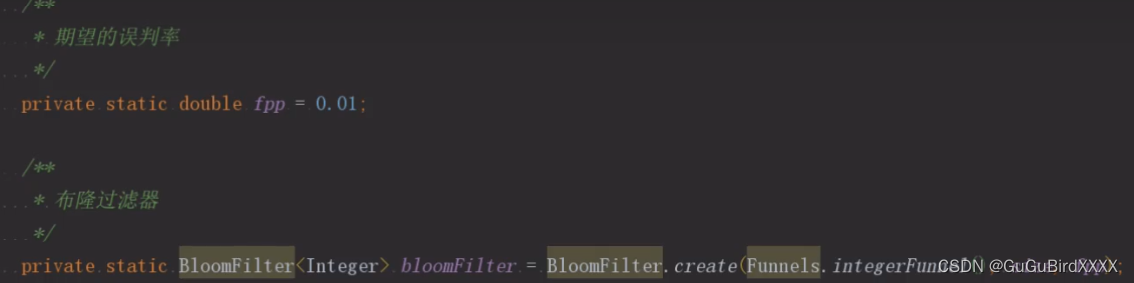
谷歌的Guava工具类已经帮我们写好了
然后我大概看了一下里面的代码 里面布隆过滤器创建的时候传入了3个参数,第一个参数是固定用法,后面需要传入size(表示需要存储多少个数据),fpp表示期望的误判律
然后里面可以进行测试,就是先往布隆过滤器中存入10000条数据,然后再用另外的1oooo条数据去判断这些数据是否存在于布隆过滤器中,然后发现大概又接近100条数据出现误判。
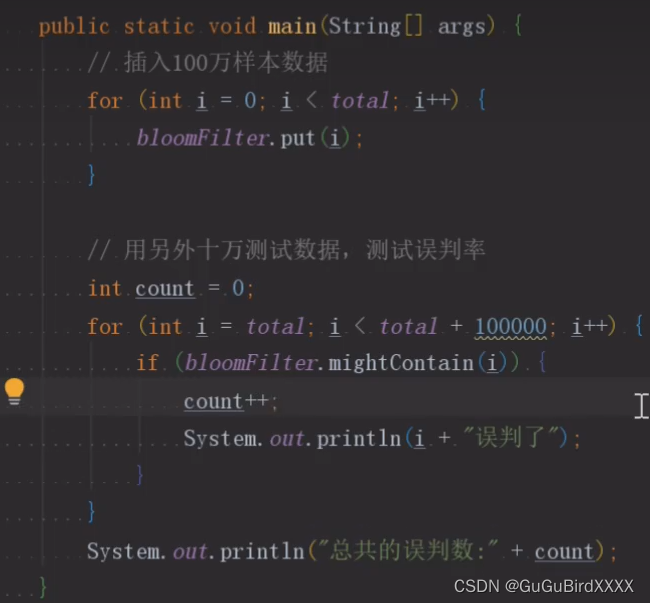
百分比跟设置的误判率差不多。
所以误判率越小,误判的个数就越少,计算的时间就越长。、
布隆过滤器误判率的底层原理是什么呢?
回到这个图
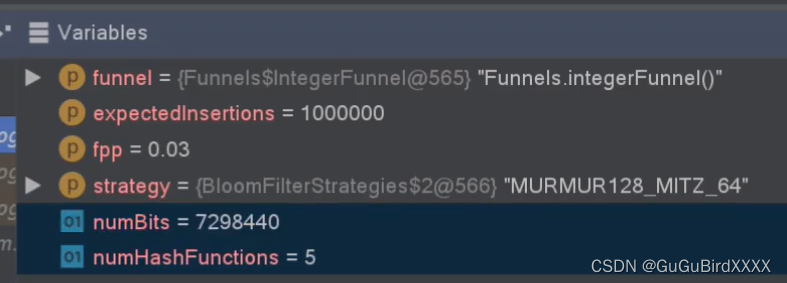
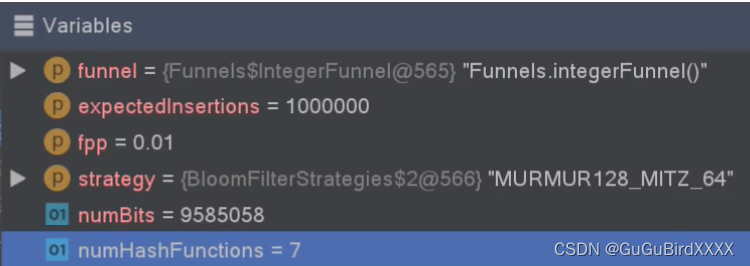
fpp【false positive probabilistic 】 误差率
numBits 数据占用的空间大小
numhashfunctions 就是hash函数的个数
由此,可以得出结论,误差率越小,hash函数的个数就越多,数据占用的内存就越大。
为什么会出现这个情况呢?
这就是为了避免出现误判的情况?
误判就是因为他们算出的hash值是一样的。如果只有一个hash函数,算出hash值相同的概率就很大。
为了避免这个情况,就采用多个hash函数进行计算,hash函数越多,计算出的hash值就越多,锁对应数组中的二进制数据就越多
所以说在判断的时候,会判断这个数据经过hash函数计算对应数组中的二进制数据必须都是1才能判断这个数据存在于布隆过滤器当中,只要有一个不一样,就表示不存在。
所以再来理解为什么hash函数越多,数据占用的空间大小就越多。误差律就越小
hash函数越多,对应的hash值就越多,从而hash值对应数组中的二进制数据就越多,所以占用的空间就越大。
布隆过滤器是如何实现缓存穿透的?
缓存穿透就是一个请求需要查询某个数据,Redis缓存中没有这个数据,而且数据库也没有这个数据,从而导致大量请求打到数据库,导致数据库挂掉。
然后Redis中封装了了布隆过滤器直接get就可以了。
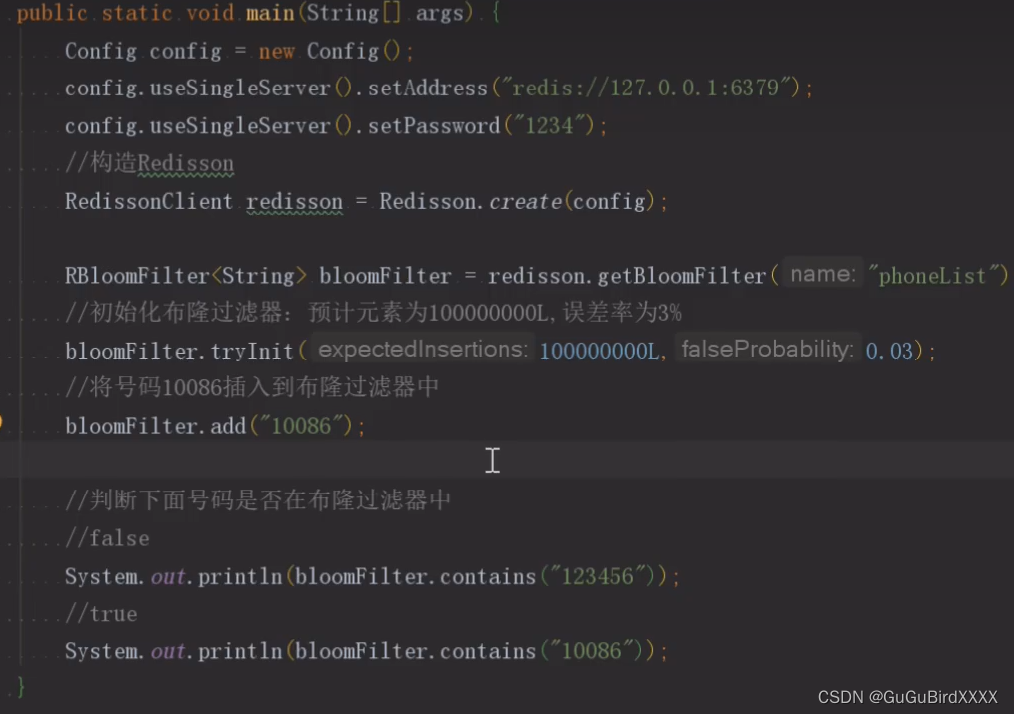
redis只能缓存一部分数据,数据不在redis有可能在数据库,布隆过滤器保存了全部的数据,数据不在布隆过滤器就大概率(因为会有误差率-但是过滤了一遍,布隆过滤器里面没有的,数据库一定没有。)不在数据库。这样当有大量不在数据库里的查询时就不用再查数据库了,没有布隆过滤器的话就是先查redis再查数据库,但是这些数据都不在数据库里,所以每次都要查数据库,这种情况相当于缓存失效了,所以叫缓存穿透。
总结
布隆过滤器就是将数据库中的所有数据进行布隆过滤器的字节数组当中,当请求进行查询的时候会先去布隆过滤器进行查询,经过hash算法计算出hash值然后查看对应的数组中的二进制数据是否都为1,如果都有1,则说明布隆过滤器中存在,就进行放行,然后请求就可以去缓存中进行查询或者去数据库进行查询。如果为0,说明布隆过滤器中一定没有。就不用再去数据库进行查询了。
所以布隆过滤器就可以解决一些非法请求,比如查询id=-1(数据库根本就没有id=-1)的数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











