







我努力、坚持、奋斗在这场看不见结果的漫长等待中,为了心中那美好而又遥远的理想与未来,于安逸和痛苦间艰难徘徊。我想在难不过坚持,我也坚信理想的花儿终会盛开在被汗水和时间灌透的土壤之上。
——致敬为了生活而努力的每一个人
目录
先谈一谈什么是线索化二叉树?
先看看百度百科给出的答案:

概念引入:
之前我们学过了普通二叉树的遍历,遍历二叉树就是以一定规则将二叉树中的结点排列成一个线性序列,得到二叉树中结点的先序、中序、后序序列。这实质上是对一个非线性结构进行线性化操作。也就是将二叉树这种结构用数组的方式遍历出来;
传统的二叉树一般都是以链式存储的结构来表示。这样,二叉树中的每个节点都可以用链表中的一个链节点来存储,每个链节点就包含了若干个指针。但是,这种传统的链式存储结构只能表现出二叉树中节点之间的父子关系,而且不能利用空余的指针来直接得到某个节点的在特定的遍历顺序(先序,中序,后序)中的直接前驱和直接后继。
通过分析传统的二叉树链式存储结构表示的二叉树中,存在大量的空闲指针。若能利用这些空指针域来存放指向该节点的直接前驱或是直接后继的指针,则可以进行某些更方便的运算。这些被重新利用起来的空指针就被称为线索,加上了这些线索的二叉树就是线索二叉树。
引入概念:线索化:对二叉树以某种遍历顺序进行扫描并为每个节点添加线索的过程称为二叉树的线索化。
线索化二叉树的定义:一个二叉树通过如下的方法“穿起来”:所有原本为空的右(孩子)指针改为指向该节点在中序序列中的后继,所有原本为空的左(孩子)指针改为指向该节点的中序序列的前驱。
想了解二叉树的各种遍历可以参考:
看个问题加深理解:
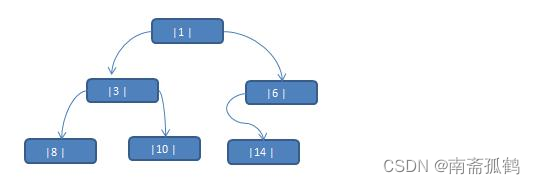
当我们对上面的二叉树进行中序遍历时,数列为 {8, 3, 10, 1, 6, 14 },这个过程就是对一个非线性结构进行线性化操作;这里产生了两个概念:前驱和后继
前驱: 一个结点的前一个结点,称为前驱结点,对应上面的数列——8就是3的前驱结点。
后继: 一个结点的后一个结点,称为后继结点,对应上面的数列——3就是8的后继结点。
在了解了前驱后继概念后,我们来说为什么要线索化二叉树?
我们可以通过以下三点来解释:
一、可以看出,在上图这个二叉树结构中,每个节点都有两个指针(left和right),分别用来指向左子节点和指向右子节点,但是:(关键来了)处于该二叉树最后一层的节点它们的 left 和 fight 都是null的,没有指向任何地方。这就造成了一定程度的浪费。那么我们能不能很好的把他们利用起来呢?此时线索化二叉树就来了。
二、如果上面的不够理解,我们还可以看出,在我们用任一序列遍历一个二叉树结构时,只能找到某个结点的左右孩子信息 。而不能直接得到该结点在任一序列中的前驱和后继的信息,而这种信息只有在遍历的动态过程中才能得到(只能在遍历完后某个节点后才可以得到这种信息),那么我们如何可以直接得到某个结点在任一序列中的前驱和后继的信息呢?为此引入线索二叉树来保存这些信息,使得可以在动态过程中得到的某个节点的前驱和后继的信息。
三、进行线索化的目的是为了加快查找二叉树中某节点的前驱和后继的速度。 那么在有N个节点的二叉树中需要利用N+1个空指针添加线索。这是因为在N个节点的二叉树中,每个节点有2个指针,所以一共有2N个指针,除了根节点以外每一个节点都有一个指针从它的父节点指向它,所以一共使用了N-1个指针。所以剩下2N-(N-1)个空指针。
使的每个结点(除第一个和最后一个外)在这些线性序列中有且仅有一个直接前驱和直接后继。
那么我们如何线索化二叉树呢?
我们获取某个节点的左右子节点时,是通过节点的本身属性 left 和 right 这两个指针获取的,我们可能就会想到,我们能不能再添加两个指针呢?让他们分别指向前驱和后继呢?可以,但是不够完美,如果再添加两个指针,指来指去很复杂,很容易混淆,而且很浪费内存,那我们该怎么办呢?(OK重点来了):之前我们不是发现在二叉树中绝对会有很多没有充分利用的left和right指针嘛,我们将他们利用起来,这样不就既可以减少内存的消耗还可以满足直接获取前驱后继信息的需求。这个想法简直太棒了!!!yyds
那么如何充分利用null指针呢?
要充分利用这些null指针,我们会想它够不够用啊?要不不够用怎么办?放心好吧,绝对够用!,那么一个二叉树结构中包含多少个null指针呢?
公式:2n-(n-1)=n+1
检验:上面呢个二叉树结构就有六个结点,它包含七个空指针域,符合n+1;
公式如何得出的:这是因为在N个节点的二叉树中,每个节点有2个指针,所以一共有2N个指针,除了根节点以外每一个节点都有一个指针从它的父节点指向它,所以一共使用了N-1个指针。所以剩下2N-(N-1)个空指针。
在n个结点的二叉树链表含有n+1个空指针域。利用二叉链表中的空指针域,存放指向该结点在某种遍历次序下的前驱和后继结点的指针(这种附加的指针称为"线索")这种加上了线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树(Threaded BinaryTree)。根据线索性质的不同,线索二叉树可分为前序线索二叉树、中序线索二叉树 和后序线索二叉树 三种,后面我们一一介绍:
线索化上面给出的二叉树后的结果:(示例中序)
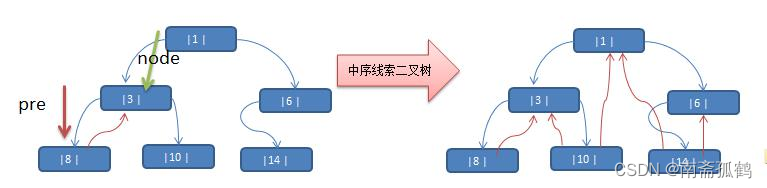
如果你思路清晰,会发现这里会出现一个问题:
我们利用二叉树中的一些未被完全利用的节点的left和right去指向前驱和后继,我们原先设计left和right的初衷是指向左右子节点,这样就会出现一些节点的left和right指向的是左右子节点,一些是指向前驱和后继,那我们如何区分二者呢?
我们试做如下规定:若结点有左子树,则其left域指示其左孩子,否则令left域指示其前驱;若结点有右子树,则其right指示其右孩子,否则令right域指示其后继。为避免混淆,尚需给实体类加两个属性,增加两个标志域leftType 和rightType
如果leftType == 0表示指向的左子树,如果是1则表示指向的前驱结点
如果rightType == 0表示指向的右子树,如果是1则表示指向的后驱结点
线索化二叉树能干什么?
线索二叉树能线性地遍历二叉树,从而比递归的中序遍历更快。使用线索二叉树也能够方便的找到一个节点的父节点,这比显式地使用父亲节点指针或者栈效率更高。这在栈空间有限,或者无法使用存储父节点的栈时很有作用(对于通过深度优先搜索来查找父节点而言)。
基础说完了,我们来看看代码实现吧:
中序线索化二叉树:
大体步骤:
先线索化左子树——》在线索化当前结点——》在线索化右子树
处理后继结点时,是先把本结点储存为pre结点,然后到下一个节点后,让pre结点指向本节点,这是整个线索化的核心。(对应代码理解这句话,先看代码!!!)
public void threadedNodes(Node node){
//如果node为null,不能进行线索化
if (node == null){
return;
}
//第一步,线索化左子树
threadedNodes(node.getLeft());
//第二步:线索化当前节点
//处理当前节点的前驱节点
if (node.getLeft() ==null){
//让当前节点的左指针指向前驱节点
node.setLeft(pre);
//修改当前节点的左指针的类型,当前左指针指向的不再是左子树,而是前驱节点
node.setLefType(1);
}
//处理后继节点
if (pre != null &&pre.getRight() ==null){
pre.setRight(node);
pre.setRightType(1);
}
//很重要的一行代码,每处理一个节点,让当前节点是下一个节点的前驱
pre = node;
//第三步:线索化右子树
threadedNodes(node.getRight());
}先序线索化二叉树:
大体步骤:
在线索化当前结点——》先线索化左子树——》在线索化右子树
再处理先序线索化时,如果考虑不周会出现死循环,例如:在代码中pre始终指向node的前一节点,如果操作不当,会出现pre.left=node;node.right=pre;这样就形成了一个死循环。这样干说很难理解,你可以先自己敲一遍代码,然后自己推导一下,就清楚了。(对应代码理解这句话,先看代码!!!)
//先序线索化二叉树
public void PreOrderThreadedNodes(Node3 node) {
if (node == null) {
return;
}
if (node.getLeft() == null) {
node.setLeft(pre);
node.setLefType(1);
}
// 如果pre的left结点为node(当前) 则不能把pre的right结点设为node(当前) 否则下面的“preThreadedNodes(node.getLeft())”会出现死循环
if (pre != null && node.getRight() == null && pre.getLeft() != node) {
pre.setRight(node);
pre.setRightType(1);
}
pre = node;
//* node.getLeftType()==0是为了避免出现死循环
//* 因为若当前结点是左叶子结点 在上面的node.setLeft(pre);已经把node的left设为了pre 而node是pre的左子结点
// * 那么preThreadedNodes(node.getLeft())又会进入同一个结点 这样无限循环
if (node.getLefType() == 0) {
PreOrderThreadedNodes(node.getLeft());
}
PreOrderThreadedNodes(node.getRight());
}后序线索化二叉树:
大体步骤:
先线索化左子树——》在线索化右子树——》在线索化当前结点
值的注意的是在第二个if判断中,node.serPigthType(1);(标记了***)
public void LastOrderThreadedNodes(Node3 node) {
if (node==null){
return;
}
LastOrderThreadedNodes(node.getLeft());
LastOrderThreadedNodes(node.getRight());
if (node.getLeft()==null){
node.setRightType(1);//***
node.setLeft(pre);
}
if (pre!=null&&pre.getRight()==null){
pre.setRightType(1);
pre.setRight(node);
}
pre=node;
}















 6515
6515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









