






目录
1.什么是线程安全问题?
我们用一个例子来演示线程安全问题
class Counter{
public int count = 0;
public void add() {
count++;
}
}
public class SafeDemo1 {
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for(int i = 0;i < 50000;i++) {
counter.add();
}
});
Thread t2 = new Thread(() -> {
for(int i = 0;i < 50000;i++) {
counter.add();
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(counter.count);
}
}上面的这段代码的任务是用两个线程各自去调用Counter类里面的add方法5w次,方法里面的内容是将变量count进行自增操作。
按照我们的预期,最后输出count的的值一个是10w,但是结果却事与愿违。

经过多次测量,都没有达到10w的count,那么此时的代码里面的存在bug,而这个bug的源头就是出现了线程安全问题。
2.线程安全问题是如何出现的?
会出现线程安全问题的罪魁祸首就是--多线程的抢占式执行带来的随机调度。
如果使用单线程,那么代码的顺序就是固定的,结果也是唯一可以确定的。
而使用多线程,就意味着会出现抢占式执行,代码的执行顺序就是随机的,多变的,它可以衍生出无数种可能的执行顺序,因此多线程的结果就可能会出现多种情况,而作为一名程序员,我们需要让这无数种执行顺序的最终结果都是正确的。只要有一种情况下代码的执行结果不正确,那么就是出现了线程安全问题。
继续使用上面的例子,上面代码的主要任务就是对count进行自增操作,也就是count++,而++这个操作会被计算机拆分成三条指令:
(1)先将内存中的值读取到CPU的寄存器中:load
(2)把CPU寄存器里面的数值进行+1运算:add
(3)把得到的结果协会到内存中:save
这三条指令全部执行完,那么count的值就会++一次,也就完成我们的想要的效果。
而在多线程中,由于抢占式执行,执行的执行情况就会出现无数种情况,如下图:
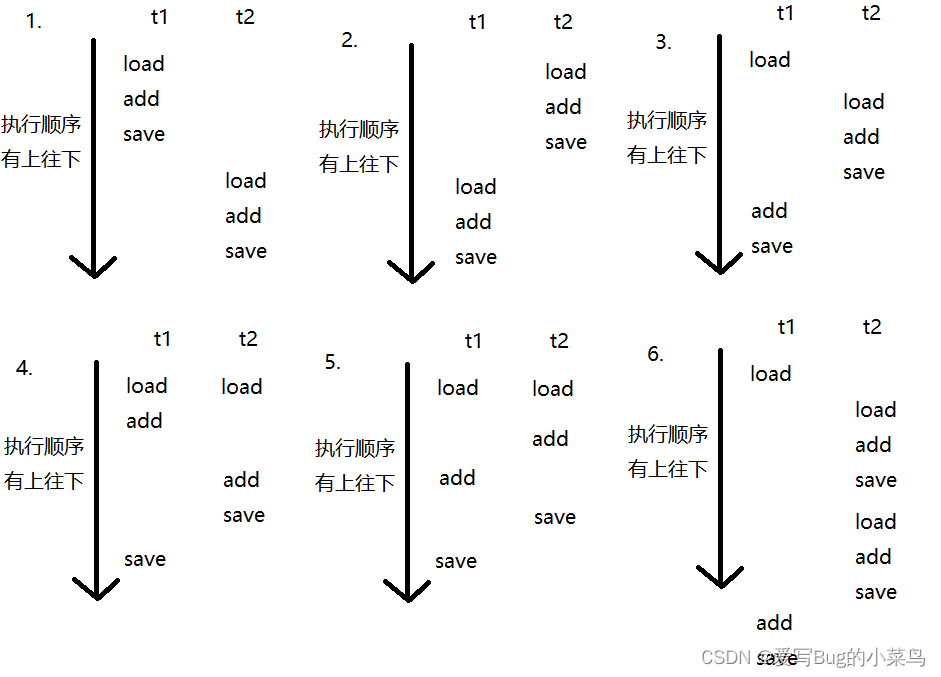 可能的情况有无数多种,上面只是一些可能的情况,而其中只有第一种和第二种情况是最正确的情况。
可能的情况有无数多种,上面只是一些可能的情况,而其中只有第一种和第二种情况是最正确的情况。
那情况3来举例:假如在情况3发生之前count的数值为0,那么此时t1线程获取到数值0,t2紧随其后回去到数值0,他们各自数据进行+1操作,然后t2线程率先返回,此时count的值为1,然后t1线程也进行返回,它返回的数值也是1,此时两次++操作,count值却值加了1,再如第6种情况,三次++操作只加了1,这也就很好的解释了为什么上面代码的结果总是无法达到10w。
当然也不能说上面的代码就是没办法达到10w,当所有的执行情况都是第一种或者第二种,那么得到的结果就是10w了,只不过这种情况出现的概率小的可怜。
3.线程安全问题出现的原因
(1)根本原因:系统的抢占式执行,随机调度。
(2)代码的设计问题:多个线程同时修改同一个变量。
(3)原子性(原子:不可被拆分的基本单位):如果操作是非原子的操作,那么就有可能会出现线程安全问题。
比如:++操作的load、add、save这些执行都是一个原子操作,是不可被拆分的。
如果++这个操作是原子的,那么上面的代码也就不会出现结果不正确的情况了(解决线程安全问题也是从这里入手的)
(4)内存可见性问题:比如一个线程在读,另一个线程在改(类似于事务的不可重复读),也可能会出问题。
(5)指令重排序(编译器优化出bug了):编译器可能会觉得你写的代码不够高效,擅作主张的将你的代码进行了调整(保持逻辑不变的情况下),来加快程序的执行效率。
也就是编译器自动调整了代码的执行顺序,可能会出现问题。
提到了出现线程安全的原因,那么如何解决线程安全问题呢?
4.解决线程安全问题
4.1 synchronized锁
我们仍然使用上面的代码,这一次我们在add方法的前面加上一个synchronized,看一看有什么效果:
class Counter{
public int count = 0;
synchronized public void add() {
count++;
}
}
public class SafeDemo1 {
public static void main(String[] args) {
Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for(int i = 0;i < 50000;i++) {
counter.add();
}
});
Thread t2 = new Thread(() -> {
for(int i = 0;i < 50000;i++) {
counter.add();
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(counter.count);
}
}这是得到的结果:
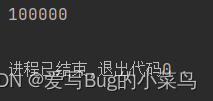
可以看到结果如愿以偿的达到了10w。
那么为什么加了synchronized之后就会正确的输出了呢?
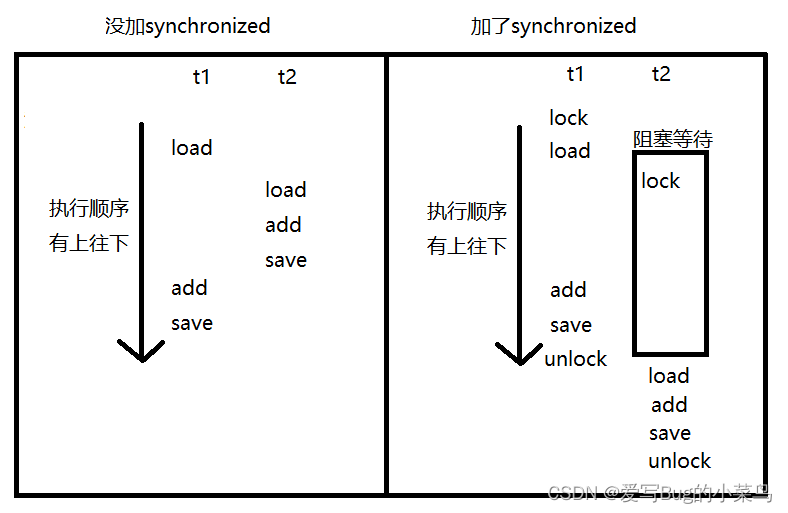
因为在add方法前面加上synchronized之后,当有线程去调用这个方法时,会对调用add方法的对象(也就是this)上锁,对象一旦被上了锁,此时这个对象就不允许再被其他的线程上锁了,而其他的线程再通过这个对象去调用add方法时,又无法躲开上锁的步骤,就会陷入线程的阻塞等待(BLOCKED),直到调用add的线程执行完了该方法,释放锁的时候,其他线程才可以对其上锁,也就相当于将这个方法包装成了一个原子。如下图:
4.2 synchronized的使用方法
(1)修饰普通方法:针对当前的类对象加锁
(2)修饰静态方法:针对类方法加锁
(3)修饰代码块:手动指定对象加锁,如下:
synchronized public void add() {
synchronized (this){
count++;
}
}总结一下就是:如果两个线程对同一个对象进行加锁,就会出现锁竞争(锁冲突),先来的线程能够获取到锁,另一个线程阻塞等待,等待到上一个线程解锁,它才能获取成功。
如果两个线程针对不同的对象加锁,此时不会发生锁竞争(锁冲突),两个线程都可以获取到自己的锁,不会发生阻塞等待。
5.死锁
5.1 什么是死锁
死锁就是线程进入锁的循环等待,一单程序中出现死锁,那么此时相对应的线程就会停止继续向下运行,就可能会导致出现很严重的bug。
死锁是很善于隐藏的,在开发的过程中,可能不经意间就会出现死锁代码,但是又不容易测试出来(有概率性)
5.2 可重入锁和不可重入锁
可重入锁:同一个线程可以针对同一个对象上多次锁。
如下代码:
synchronized public void add() {
synchronized (this){
count++;
}
}当线程去获取add方法时会对当前对象上锁,进入里面的代码块又会对当前对象上锁,也就连续上了多次,而代码里面用的synchronized锁以及ReentrantLock锁都是可重入锁。
不可重入锁:和上面的相反,即使是同一个线程也不可以对同一个对象上多次锁。
在Java中的synchronized锁以及ReentrantLock锁都是可重入锁,所以基本不用担心不可重入锁的问题
5.3 死锁的三个典型情况
(1)一个线程一把锁。一个线程连续加了两次锁,如果此时锁是不可重入锁,那么就会死锁。
(2)两个线程两把锁。线程1获取到锁A,线程2获取到锁B,此时线程1去获取锁B,线程2去获取锁A,就会出现死锁。
这种情况就好比:我将家钥匙锁车里了,车钥匙锁加家里了,而车和家都上了锁,此时哪个锁都打不开。
(3)多个线程多把锁。
我们用书上的一个经典例子来演示
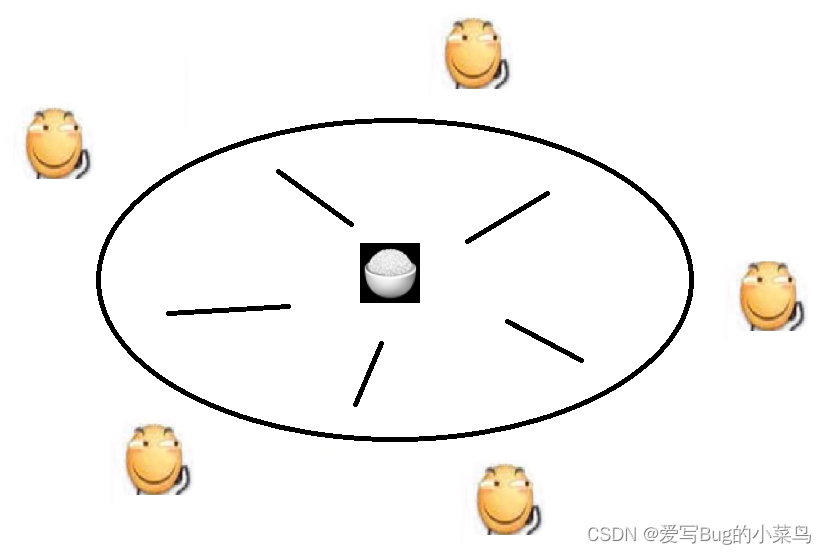
五个哲学家去吃饭,一共只有5根筷子,五个哲学家围成一个圈,每个哲学家的左右两边各有一根,此时5个哲学家同时拿起他们左手边的筷子,然后再去拿他们右手边的筷子,但是此时他们每个人右手边的筷子都已经被别人拿在手里,如果想要拿起右边的筷子就要等待他们右边的人放下筷子,于是就进入了循环等待状态,就是出现了死锁。
5.4 死锁的四个必要条件
(1)线程之间互斥使用锁。线程1获取到了锁A,如果线程1没有释放锁,此时其他线程不可以获取到锁A,如果要回去就要进入等待状态。
(2)线程之间不可抢占锁。线程1获取到了锁A,除非线程1主动释放了锁A,其他线程不可以强制获取到锁A。
(3)线程获取其他锁的时候不会释放原有的锁。线程1获取到锁A,线程1又去获取到了锁B,此时线程1会同时拥有锁A和锁B。
(4)线程进入循环等待。如同上面的2、3情况,线程1获取到了锁A,线程2获取到了锁B,此时线程1去获取锁B,线程2去获取锁A,就会陷入循环等待。
虽然列出来四个必要条件,但是实际上就只有一个条件,也就是循环等待。
因为1、2、3都是锁原有的特性,是对此做出调整的,因此,如果想要避免出现死锁,那么就需要在条件4身上下手。
5.5 如何避免死锁
首先来看一段死锁的代码
public class DeadLock2 {
public static void main(String[] args) {
Test1 lock1 = new Test1();
Test1 lock2 = new Test1();
Thread t1 = new Thread(() -> {
synchronized(lock1) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2) {
lock1.func();
}
}
});
Thread t2 = new Thread(() -> {
synchronized (lock2) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1) {
lock2.func();
}
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}这一段代码如果去运行会发现代码没有任何输出并且停滞不前,原因就是出现了死锁(情况2的死锁),那么如何去破解呢?
破解方法其实也很简单,我们可以对这些锁“标上序号”,并规定一个获取的规则:根据锁的序号去从小到大或者从大到小的顺序去获取。
根据这样的规则,让程序在获取锁的时候,按照自己规定顺序去获取,死锁的情况就迎刃而解了。
根据这个方法,我们对上面的代码进行修改后就可以整除运行了,如下:
class Test1{
public void func() {
System.out.println("获取到了两把锁");
}
}
public class DeadLock2 {
public static void main(String[] args) {
//将lock1 设置成锁1号,lock2设置成锁2号 让锁全部以从小到大的顺序去获取
Test1 lock1 = new Test1();
Test1 lock2 = new Test1();
Thread t1 = new Thread(() -> {
synchronized(lock1) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2) {
lock1.func();
}
}
});
//修改后
Thread t2 = new Thread(() -> {
synchronized (lock1) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2) {
lock2.func();
}
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}














 3157
3157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











