






首先导入相关的库

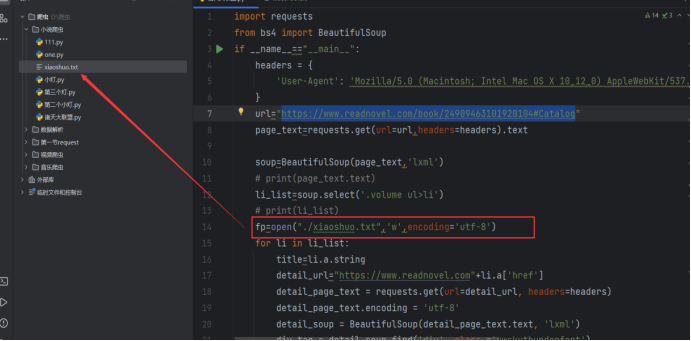
确认我们需要爬取的网站地址

Headers:是一个浏览器伪装,通常在使用爬虫给的时候我们需要一个浏览器伪装这样可以帮助我们将爬虫程序伪装成一个正常的浏览器访问,从而绕过一些网站的检测
Url:这个是我们需要爬取的网站网站地址
Page_text:这个时候我们调用resquest请求去获取页面的元素
解析网站的数据
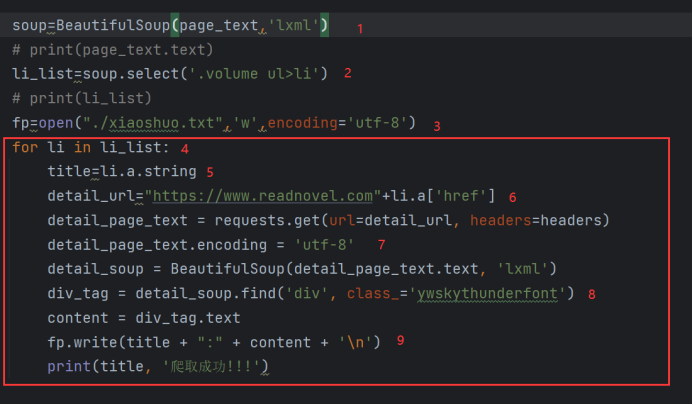
调用soup库的方法采取lxml页面解析的方法
Soup.select解析网站的css样式,可以看到小说的标题放在了ul li元素里
“>”这个元素可以定位到ul li下面内容,如果是需要跨越很多级去寻找,我们可以使用
“ ”空格来获取 例如:h3 li

打开一个叫“xiaoshuo.txt”的文件,写入内容,编码格式为UTF-8
title=li.a.string
获取li元素下的内容,在这里相当于获取小说章节的标题

5、detail_url="https://www.readnovel.com"+li.a['href']
这里新建一个url地址用来获取每个章节打开后的网址,在网站上我们获取的网址都是不全的,这里我们需要拼接出一个完整的网址,然后进行访问获取章节的内容

6、打开章节内容界面我们可以定位一下小说的内容在哪里,然后再次解析页面的数据
使用find查找css样式定位到小说内容的具体位置


7、保存我们爬取到的小说
fp.write(title + ":" + content + '\n')
将小说的章节作为内容标题
















 4503
4503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











