







前言
信息时代的高速发展让我们得以使用手机、电脑等设备轻松从网络上获取信息。但是,这似乎也是一把双刃剑,我们在获取到众多信息的同时,又可能没有太多时间去一一阅读它们,以至于“收藏从未停止,学习从未开始”的现象屡见不鲜。
这篇文章估计以后也会在收藏夹里面吃灰吧!
为了能够高效地处理巨大的文档信息,我在学习的过程中,接触到了 LDA 主题提取这个方法。经过学习,发现它特别有意思,它的主要功能是
能将众多文档进行主题分类,同时展示出主题词
当我发现这个功能之后,我便开始奇思妙想了,譬如我可以根据它的这个功能实现几个好玩的东西
- 分析写作平台上面的大 v 的文章,对其发表的作品进行主题抽取和可视化,从而找到平台上比较热门的主题或者说比较容易火的主题,从而对自己的写作产生一定的指导意义。
- 人工选出包含垃圾广告类的大量文章,然后训练 LDA 模型,抽取出它的主题,之后使用训练好的 LDA 模型去对自己收藏的大量文章进行主题概率分布预测,从而把包含大量垃圾和广告类的文章去掉,当然也可以抽取出自己最感兴趣的主题。
以上两点是个人根据需求出发,产生的想法,当然这两个想法经过我的初步验证,确实是有一定的实现可能性。
在这篇文章中,我将一步步教你怎么基于 Python,使用 LDA 对文档主题进行抽取和可视化,为了让你有兴趣地读下去,我先附上可视化的效果吧
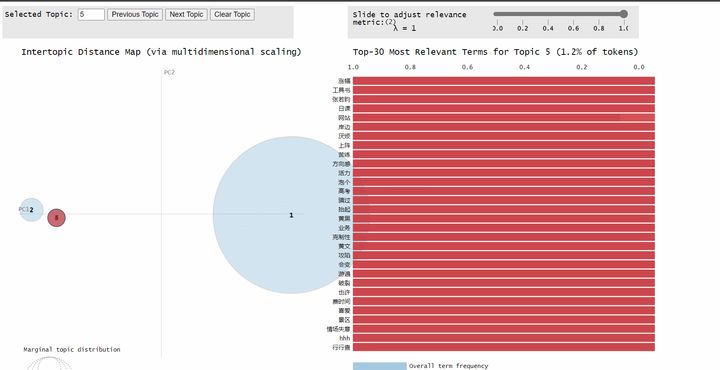
上图是我对知乎的一个百万粉大 V 的 218 个回答做 LDA 主题抽取并可视化的结果,可以看到她回答的主题非常地集中。
如果看了可视化效果之后,你感兴趣,那么就可以开始往下阅读了,当然你很赶时间的话,可以不用去阅读我是怎么一步步实现这个过程的,文末会给你附上完整的,可运行的代码。
开始之前
- Python版本要求
Python 3.7 及以上
2. 需要安装的库
tqdm
requests
retry
jieba
multitasking
pandas
pyLDAvis
bs4
sklearn
numpy
openpyxl
xlrd
库的安装方法是:打开 cmd(命令提示符或者其他终端工具),输入以下代码
pip install tqdm requests multitasking retry bs4 pandas pyLDAvis sklearn numpy jieba xlrd openpyxl输入完毕,按 Enter 键执行代码,等待 successfully 出现即可
预备知识
文本转向量
计算机是无法直接理解我们平常使用的文本的,它只能与数字打交道。为了能顺利让它可以理解我们提供的文本,我们需要对自己的文本进行一系列的转换,例如给文本里面的词进行标号,从而形成数字和词的映射。
LDA 主题抽取是基于统计学来实现的,为此我们可以考虑,给文档的词进行标号,同时统计其所对应的词频,依次构造一个二维的词频矩阵。这么说来其实是不够形象的。不过没关系,我将以下面的一个例子带你理解这一过程具体是什么。
假设有这么几段文本
今天 天气 很好 啊
天气 确实 很好我们可以发现,这两段文本中有一下几个词(不考虑单个字)
今天
天气
确实
很好如果我们分别统计每个词在每一个文档中的词频,那么我们可以将这些数据制成这样子的表格

这个怎么解释呢?请看上面的表格的第 2 行,如果用 Python 里面列表来表示,那么它是这样子的
[1,1,1,0]它对应的是
今天 天气 很好 啊这么一句话。当然这样子会不可避免地丢失一些跟序列相关的信息,但在单篇文档内容足够丰富的情况下,丢失这些信息还是 OK 的。
那么我们该怎么构造这么一个表格来数字化地描述每一篇文档呢?
这这里不得不引入 sklearn 给我们提供的好工具,下面上代码给你们展示一下
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
# 多个文档构成的列表
documnets = ['今天 天气 很好 啊','今天 天气 确实 很好']
count_vectorizer = CountVectorizer()
# 构造词频矩阵
cv = count_vectorizer.fit_transform(documnets)
# 获取特征词
feature_names = count_vectorizer.get_feature_names()
# 词频矩阵
matrix = cv.toarray()
df = pd.DataFrame(matrix,columns=feature_names)
print(df)代码运行输出
今天 天气 很好 确实
0 1 1 1 0
1 1 1 1 1注意,这每一行有 5 个数字,但后面的 4 个才是词频,第一个数字是文档的标号(从 0 开始)
如果你在 jupyter 里面运行,那么它会是这样子的

上面仅仅依靠词频来构造矩阵,这样子显然是不合理的,因为一些常用词的频率肯定很高,但它却无法反映出一个词的重要性。
为此我们引入了 TF-IDF 来构造更能描述词语重要性的词频矩阵,TF-IDF 的具体原理本文就不介绍了。
TF-IDF 构造词频矩阵的 Python 实现代码如下
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 多个文档构成的列表
documnets = ['今天 天气 很好 啊','今天 天气 确实 很好']
tf_idf_vectorizer = TfidfVectorizer()
# 构造词频矩阵
tf_idf = tf_idf_vectorizer.fit_transform(documnets)
# 获取特征词
feature_names = tf_idf_vectorizer.get_feature_names()
# 词频矩阵
matrix = tf_idf.toarray()
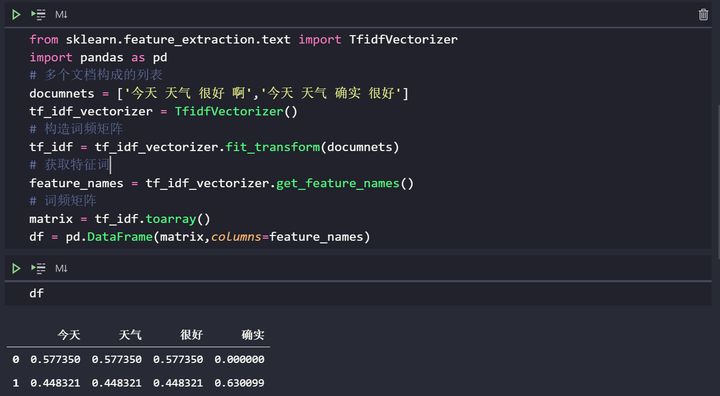
df = pd.DataFrame(matrix,columns=feature_names)代码运行输出
今天 天气 很好 确实
0 0.577350 0.577350 0.577350 0.000000
1 0.448321 0.448321 0.448321 0.630099如果你在 jupyter 里面运行,得到的结果应该是这样子的
文本分词
如果你自己观察我之前贴出的两短文本,你会发现那些文本中的词是之间总有一个空格。
但是对于中文文档而言,你指望它的词之间是用空格来分隔的就几乎不可能。
那么我为什么提供那样子的文本呢? 因为 sklearn 的词频矩阵构造器默认将文档识别为英文模式。如果你学过英语,不难发现单词之间通常是用空格来分开的。
可是我们的原始中文文档是无法做到这样子的。为此我们需要对中文文档事先进行分词,然后用空格把这些词拼接起来,最终形成英文那样子的句子。
说到分词,我们可以考虑比较有名的中文分词工具,比如我们要对下面这么一句话进行分词
今天的天气很不错分词的 Python 示例代码如下
import jieba
# 待分词的句子
sentence = '今天的天气很不错'
# 对句子分词,返回词组成的字符串列表
words = jieba.lcut(sentence)
# 输出词列表
print(words)
# 用空格拼接词并输出
print(" ".join(words))代码运行输出如下
['今天', '的', '天气', '很', '不错']
今天 的 天气 很 不错可以看到,我们很好地实现了中文句子转英文格式句子的功能!
当然,文档里面通常是有较多标点符号的,这些对我们来说意义不是很大,所以我们在进行分词之前,可以先把这些符号统一替换为空格。这一过程我就先不演示了。
后面的代码中会有这一过程的实现(主要原理是利用正则表达式的替换功能)
基于 TF- IDF 的 LDA 主题提取
在做主题抽取之前,我们显然是需要先准备一定量的文档的。上一篇文章中,我写了一个程序来获取知乎答主的回答文本数据,如果你用 excel 打开,会发现它长这样子(csv 文件)

为了让你能更好地获取它,我再次附上它的下载链接,你只需要用电脑浏览器打开它即可开始下载(如果没有自动下载,则可以按电脑快捷键 ctrl s 来进行下载,记得,最好把下载的文件放在代码同级目录!)
纯文本链接
https://raw.staticdn.net/Micro-sheep/Share/main/zhihu/answers.csv可点击链接
因为它是一个 csv 文件,而我们使用的编程语言是 Python,因此我们可以考虑使用 pandas 这个库来操作它 读取它的 Python实例代码如下
import pandas as pd
import os
# 下面的 url 是 csv 文件的远程链接,如果你缺失这个文件,则需要用浏览器打开这个链接
# 下载它,然后放到代码运行命令,且文件名应与下面的 csv_path 一致
url = 'https://raw.githubusercontents 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









