






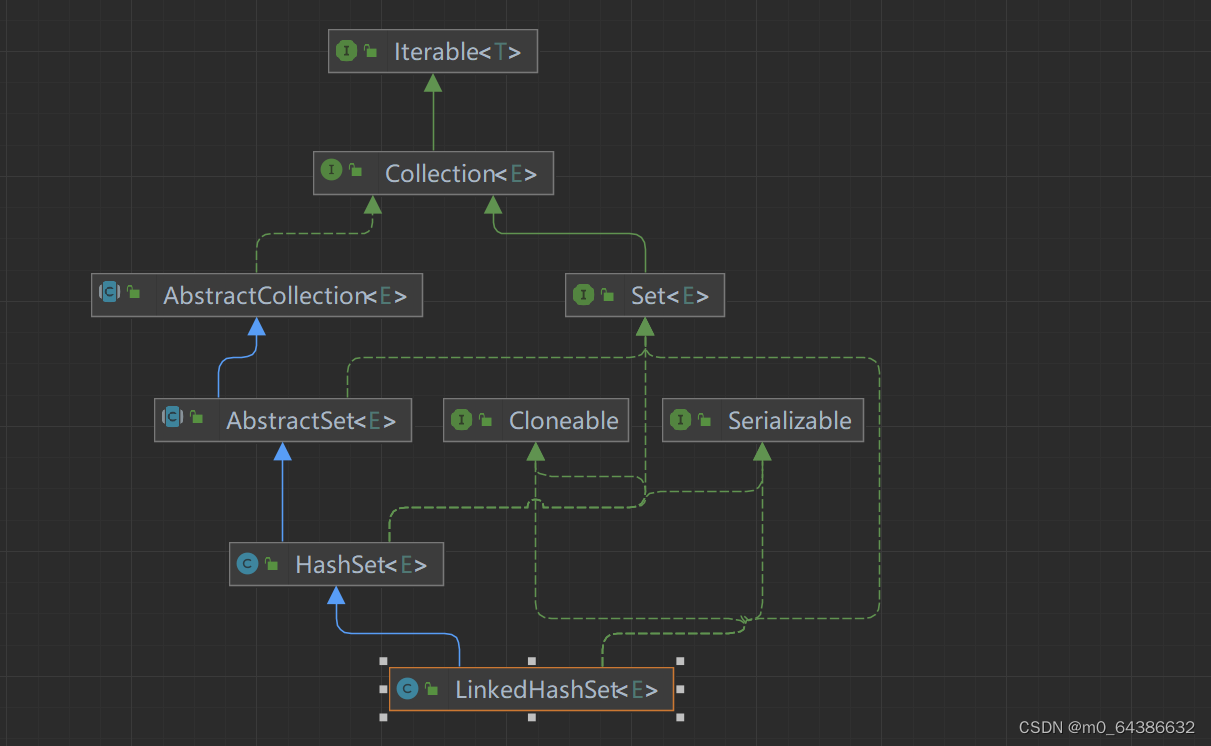
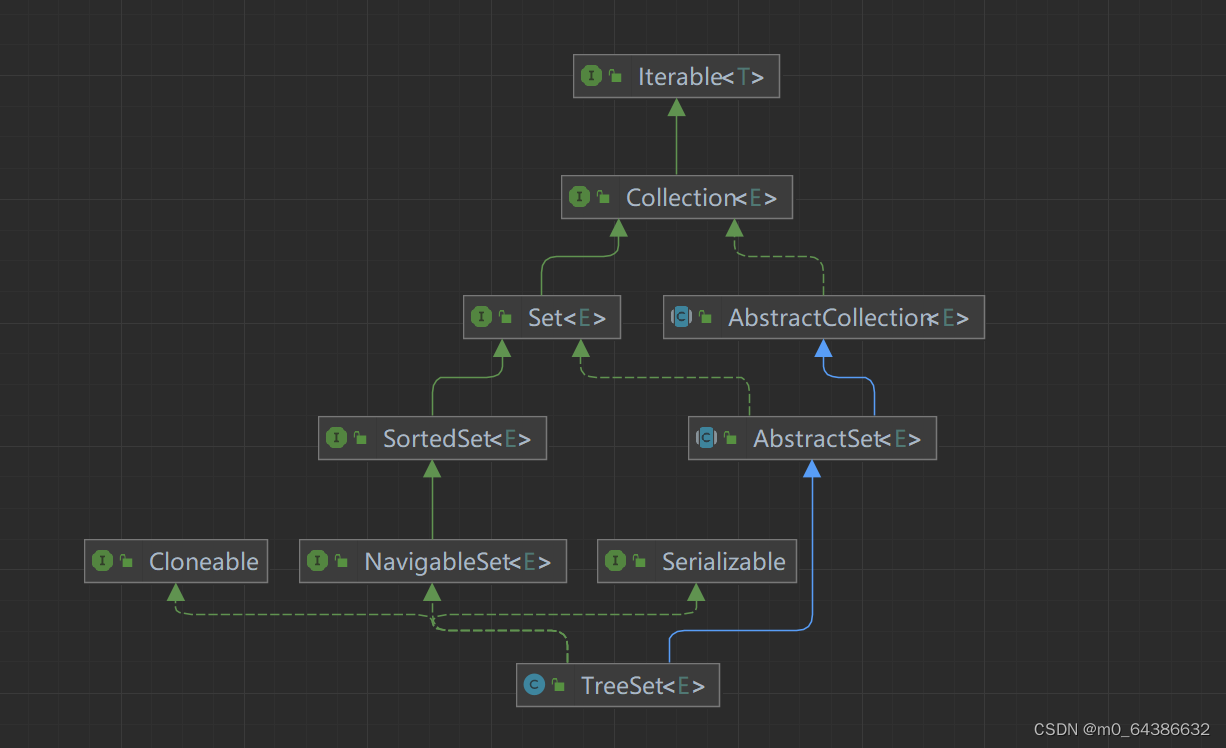
一、Collection接口的继承实现结构图(大致版)
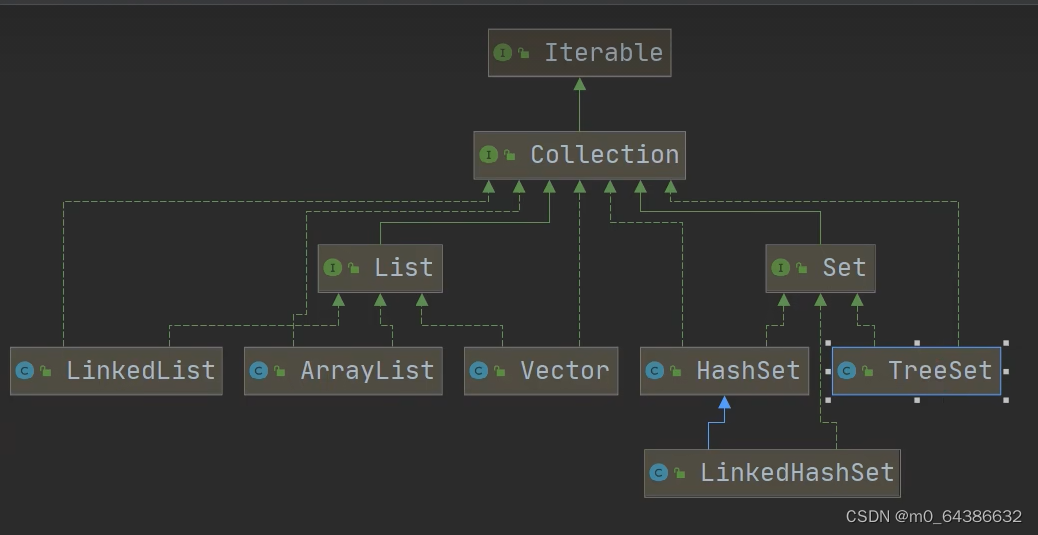
二、Collection接口实现类的特点
1.Collection实现子类可以存放多个元素,每个元素可以是任意类型。
2.Collection实现类有的可以存放重复元素(List),有的不可以存放重复元素(Set)。
3、Collection实现类有些是有序的(List),有些是无序的(Set,注意:LinkedHashSet是用双向链表实现存储的,可以保证存入和取出顺序一致)。
4.Collection接口没有直接的实现子类,是通过他的子接口Set和List来实现的。
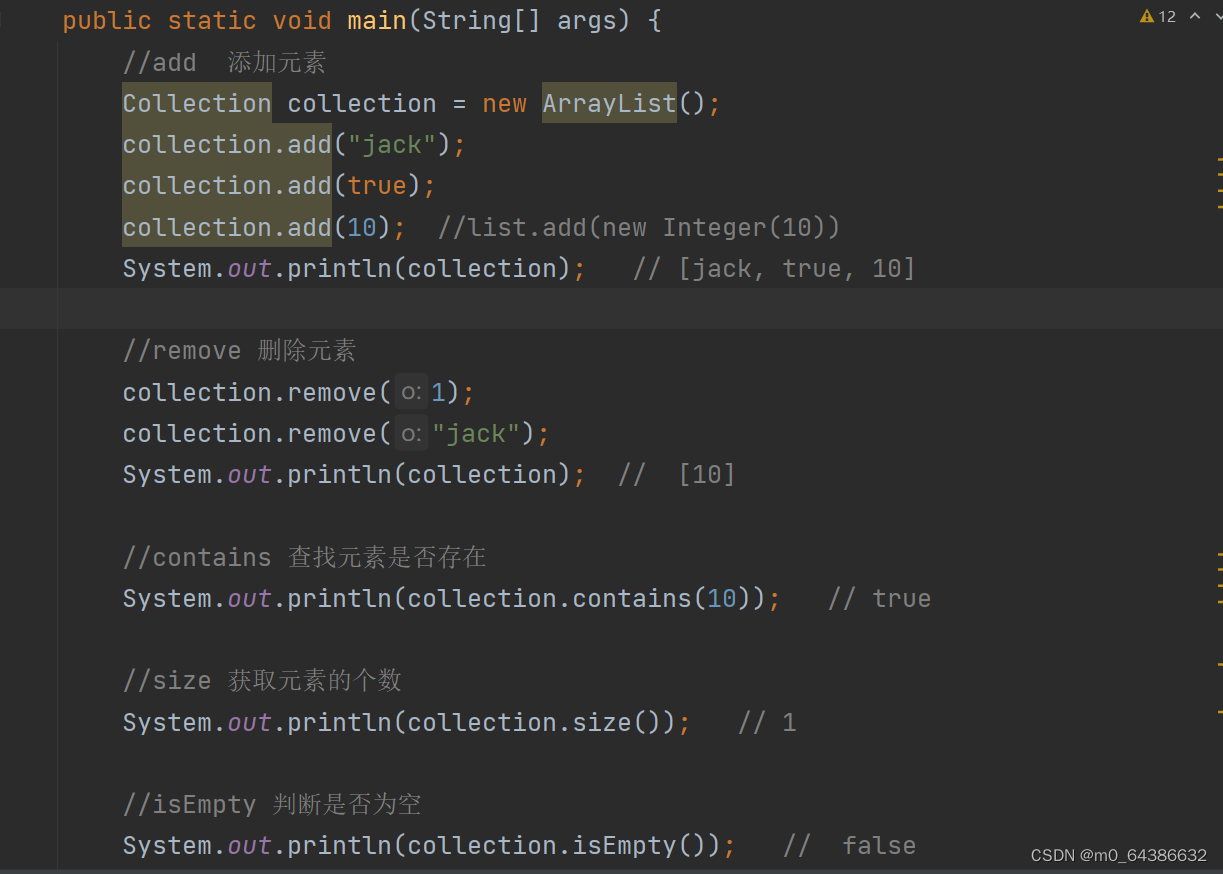
三、Collection接口常用方法

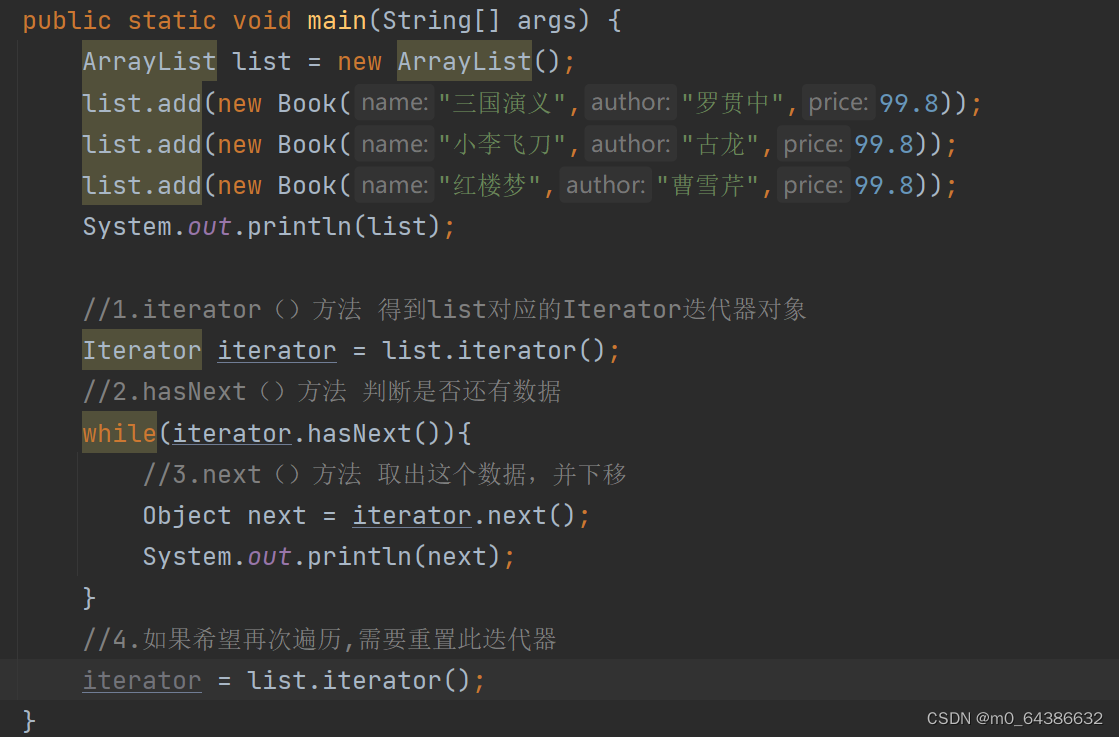
四、Collection接口的遍历方式
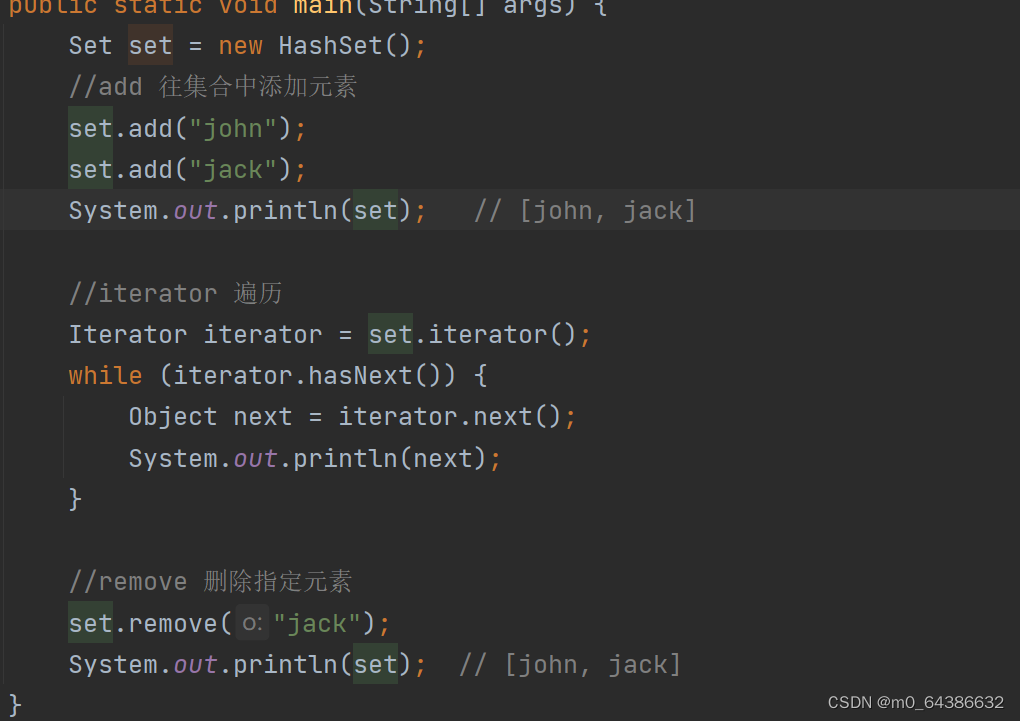
1.使用Iterator迭代器遍历(所有实现了Collection接口的集合类都有一个iterator()方法)
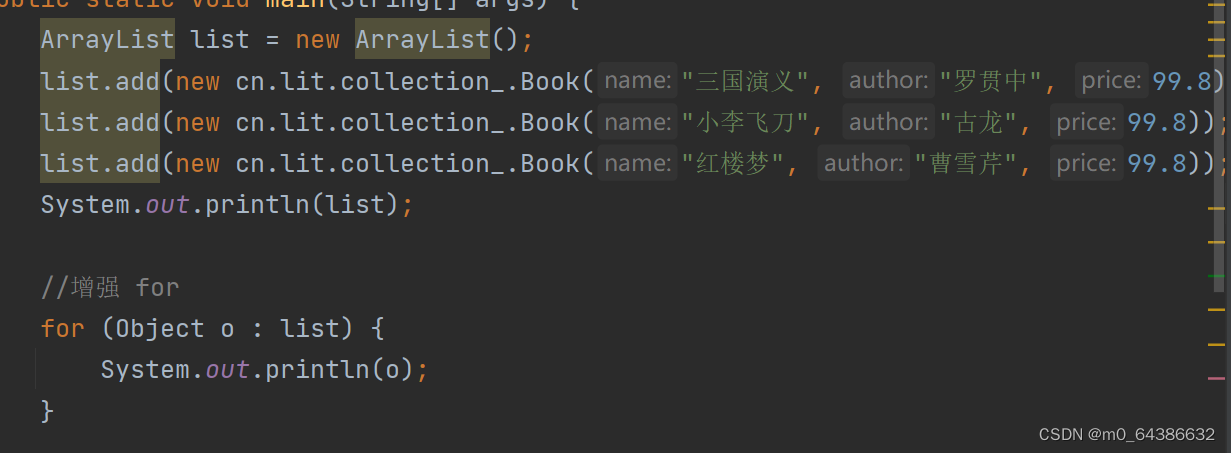
2.增强for循环遍历(简化版的Iterator,本质上一样)
五、List接口接口实现类特点
1.List集合实现类中元素有序(添加元素和取出元素的顺序一致),且可重复。
2.List集合中的每个元素都有其对应的顺序索引(索引从0开始)。
3.遍历方式有三种,迭代器、增强for循环、普通for循环。
3.List接口实现类常用的有ArrayList、LinkedList、Vector。
六、List接口常用方法

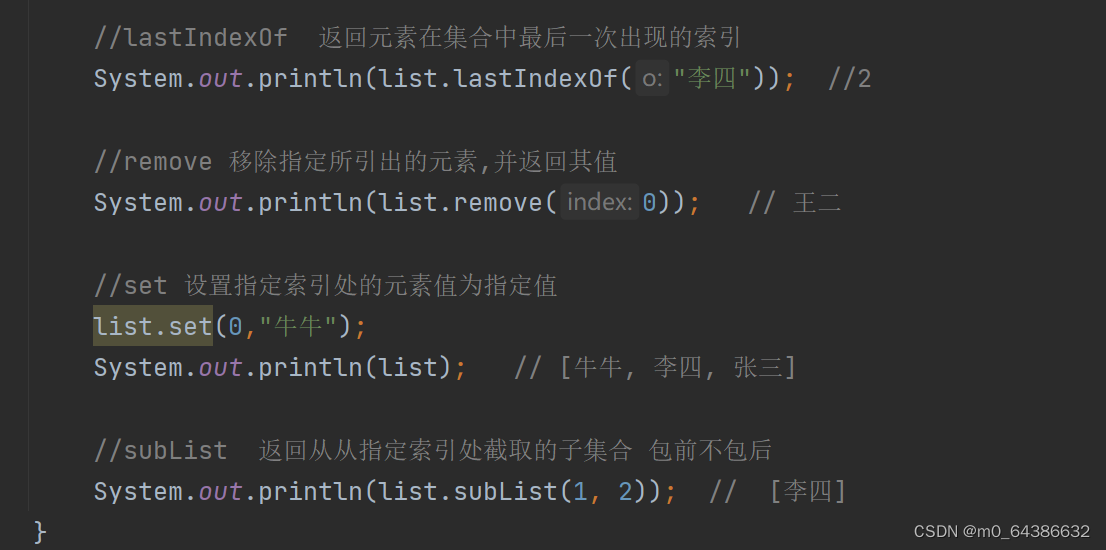
七、ArrayList特点(线程不安全)

1.ArrayList是由数组实现存储的。
2.ArrayList可以加入null,并且多个。
3.ArrayList基本等同Vector,但是ArrayList是线程不安全(执行效率高),多线程情况下不建议使用。
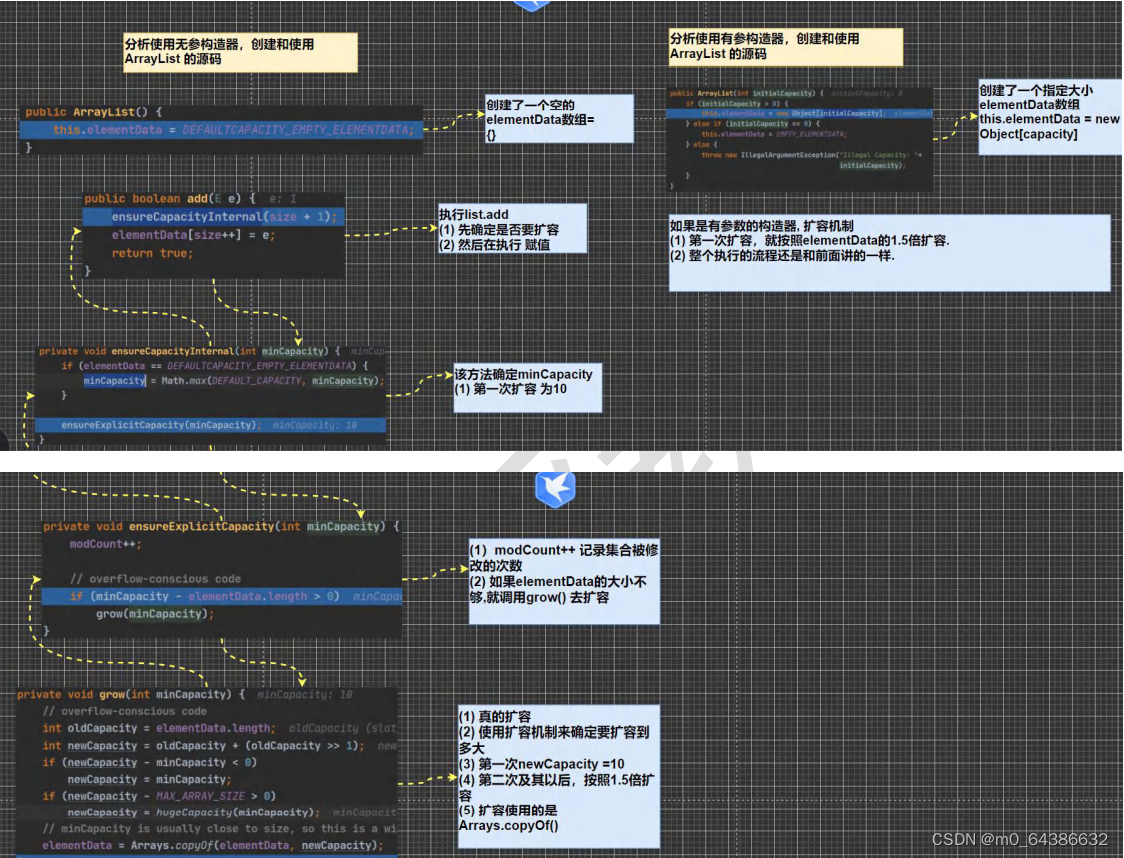
八、ArrayList底层操作机制(初始化、添加、扩容)
1.ArrayList中维护了一个Object类型的数组elementData(transient Object[] elementData;)。
2.ArrayList的三个构造器
3.当创建ArrayList对象时,如果使用的是无参构造器。则初始elementData容量为0,第一次添加元素时则扩容elementData为10,如果需要再次扩容,则扩容elementData为原来的1.5倍。
4.如果使用指定的大小的构造器,则初始elementData容量为指定大小,如果需要再次扩容则扩容elementData为原来的1.5倍。
九、Vector类特点(线程安全)
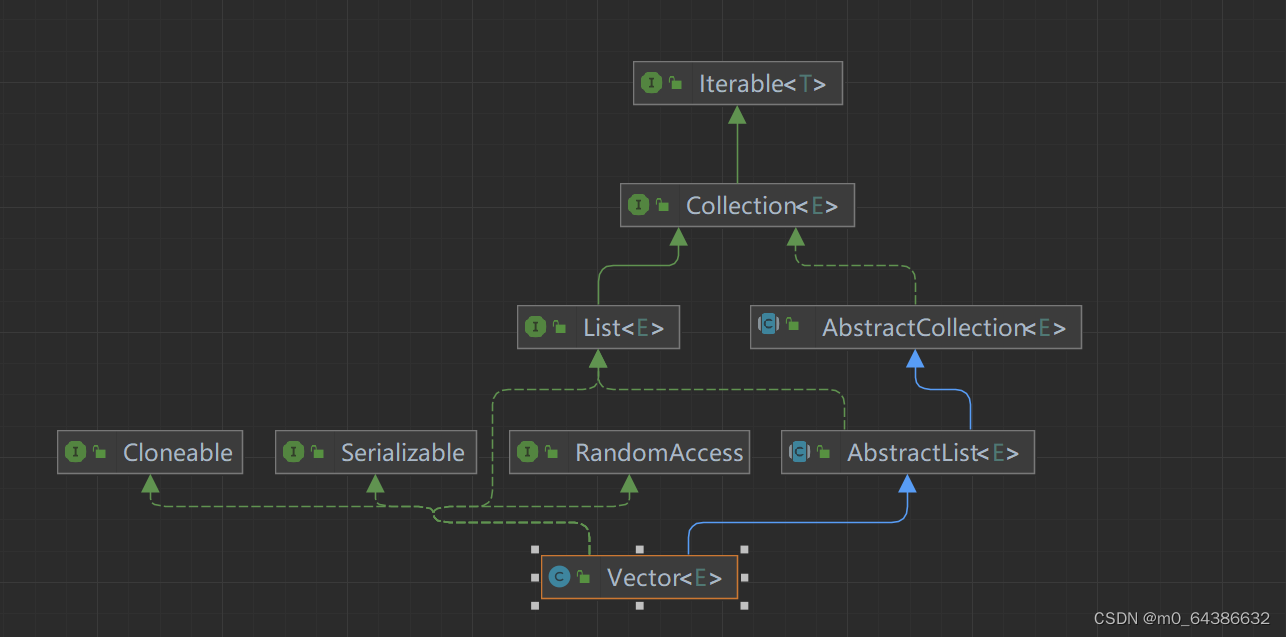
1.Vector是由数组实现存储的。
2.Vector是线程同步的,即线程安全。Vector的操作方法带有synchronized。
十、Vector底层操作机制(初始化、添加、扩容)
1.Vector底层也是一个Object数组(protected Object[] elementData;)
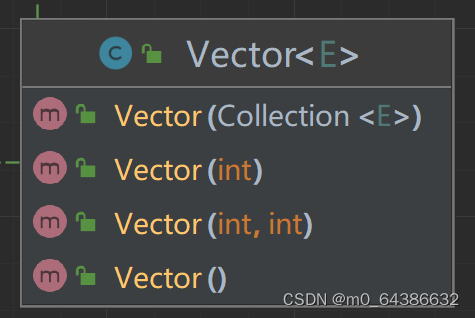
2.Vector的四个构造器
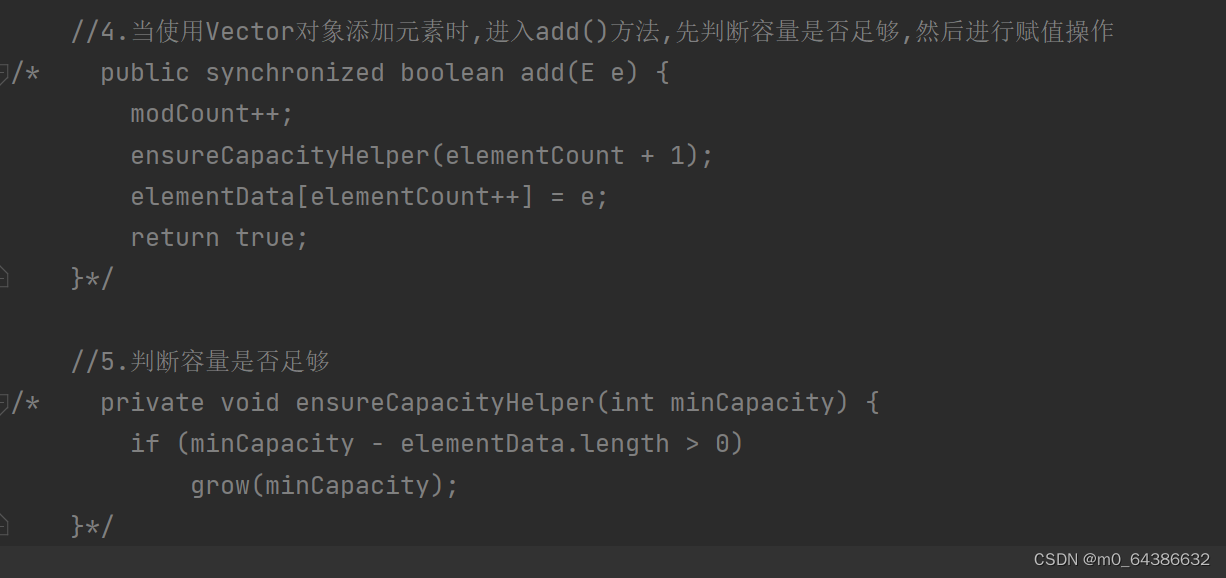
3.当创建ArrayList对象时,如果使用的是无参构造器。则初始化elementData容量为10,当需要扩容时,则扩容elementData为原来的2倍。
4.如果使用指定大小的构造器,则初始化elementData容量为指定大小。如果需要扩容,则直接扩容elementData为原来的2倍。
5.如果使用指定大小且指定每次扩容大小的构造器,则初始化elementData容量为指定大小。如果需要扩容,则扩容elementData为原来已经满的elementData大小加上指定的扩容大小。


十一、LinkedList特点(线程不安全)
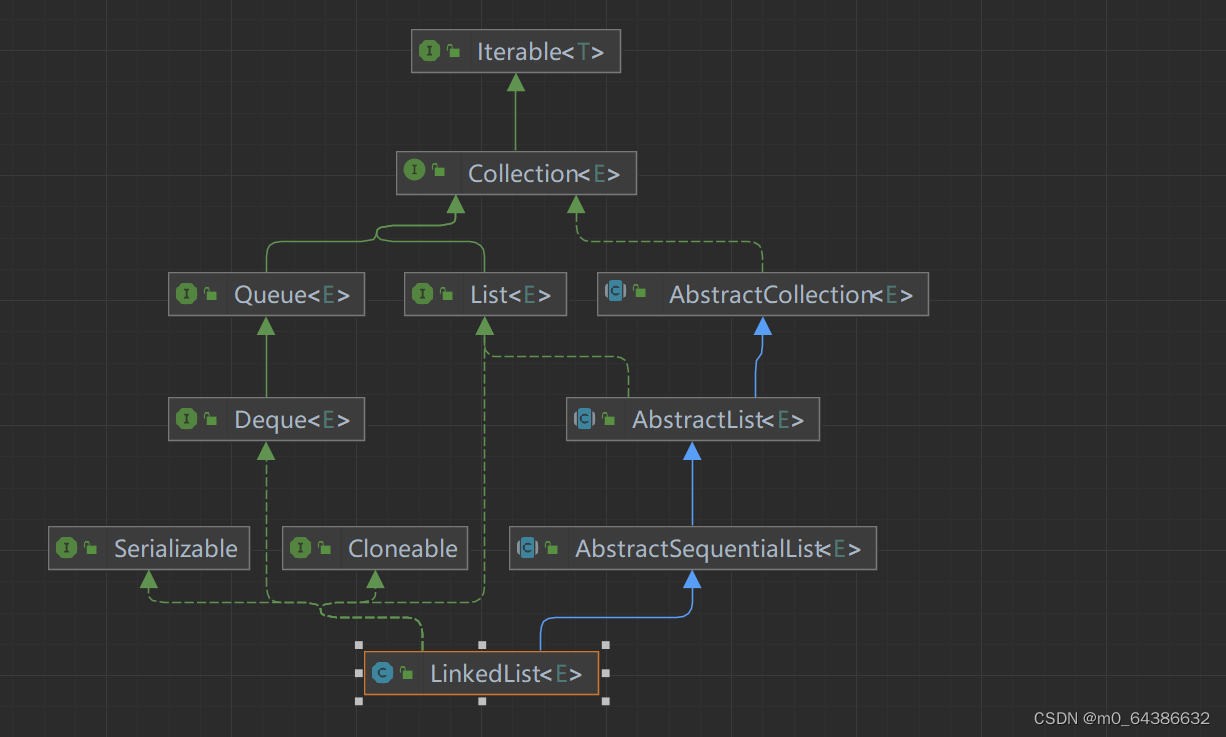
1.LinkedList是由双向链表来实现存储的。
2.可以添加任意元素,包括null。且可以重复。
3.线程不安全,没有实现同步。
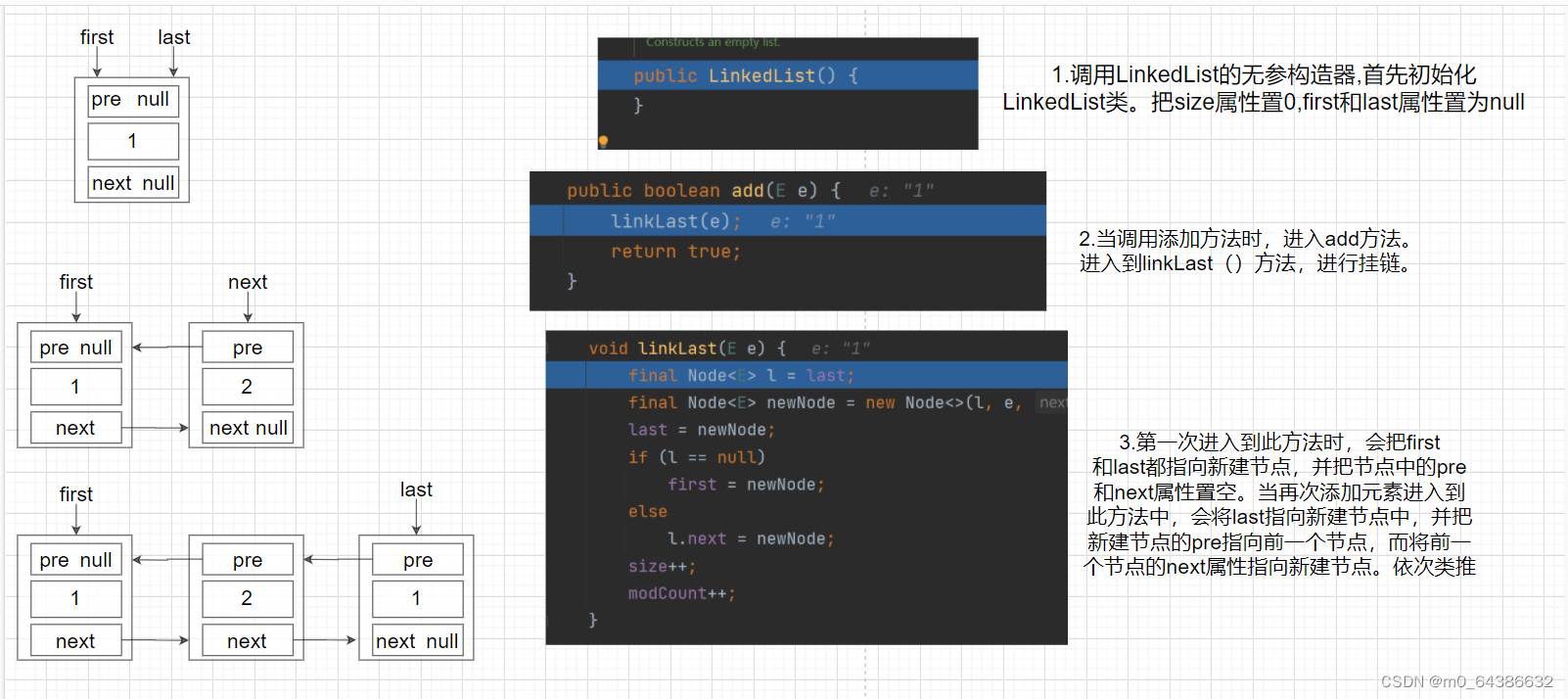
十二、LinkedList底层实现机制(初始化、添加、删除)
1.LinkedList底层是由一个一个的Node节点来实现存储的,里面维护了pre(指向前一个节点)、next(指向下一个节点)、item(节点数据)。

2.LinkedList类中维护了first、last、size。分别表示了指向首节点、指向尾节点、和节点数量.
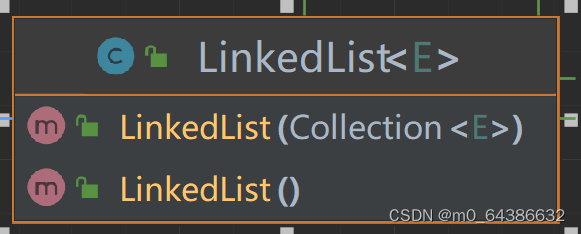
3.LinkedList的两个构造器。
十三、LinkedList底层实现机制(添加、删除)

十四、list集合的选择

十五、Set接口实现类特点
1.Set集合类中元素无序(添加和取出的顺序不一致,LinedHashSet除外),没有索引。
2.不允许添加重复元素(即添加两个相同元素只显示一个而且返回值为false,但不抛异常),因此只能包含一个null。
3.因为无索引,因此遍历方式不能使用普通for循环
4.常用实现类有HashSet、LinkedHashSet和TreeSet。
十五、Set接口常用方法
十六、HashSet特点(线程不安全)

1.HashSet底层是HashMap,而HashMap底层采用数组+单向链表+红黑树(java8)来实现存储。
2.HashSet不保证元素是有序的,是因为索引是根据hash运算后得到的。
十七、HashSet底层实现机制(初始化、添加)
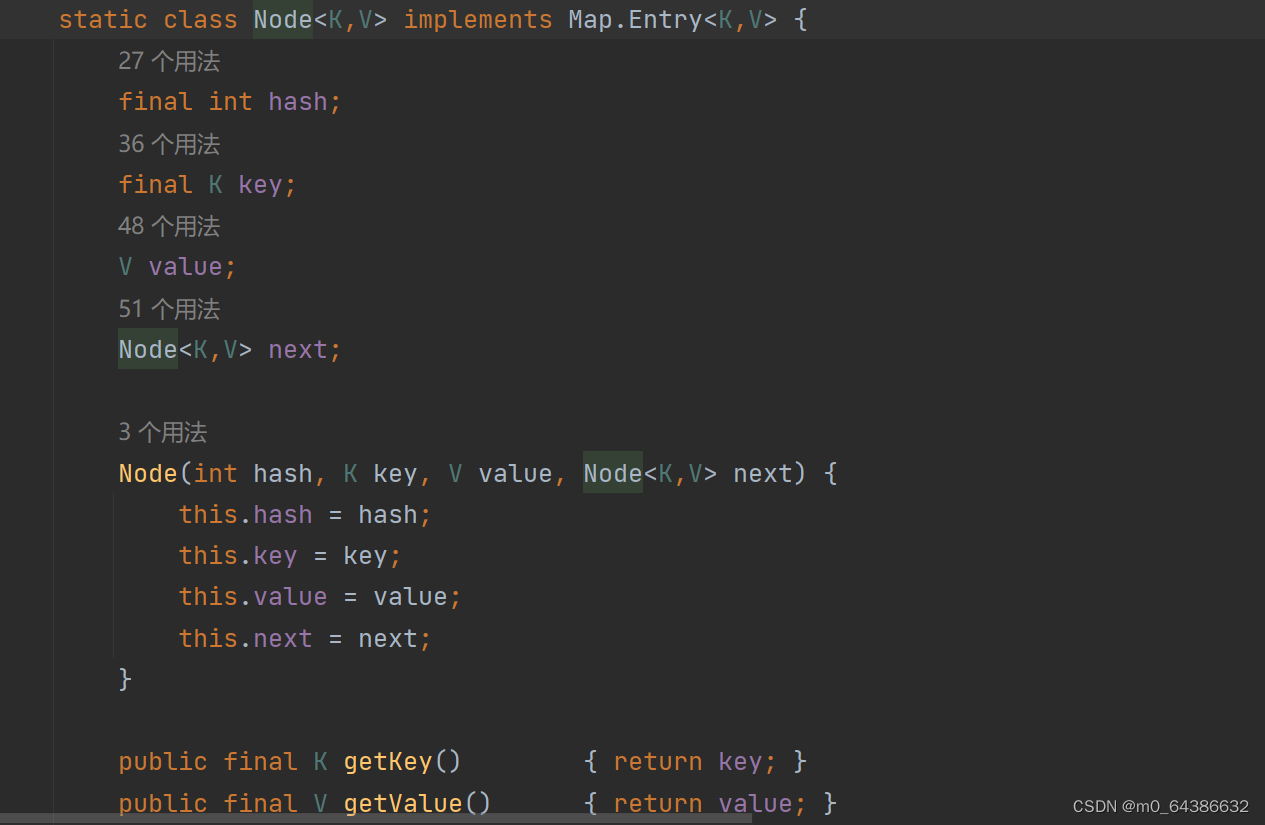
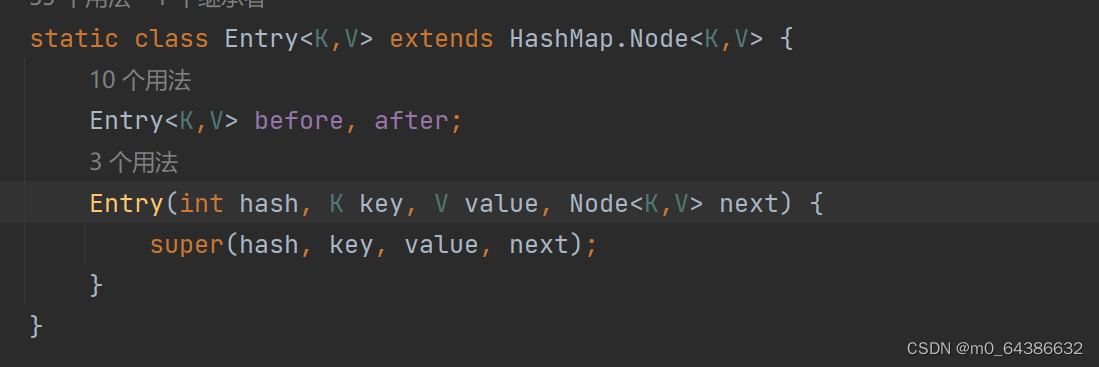
1.HashSet在调用构造器初始化时,会创建一个HashMap对象,而内部方法都是通过这个HashMap对象完成的。因此HashSet底层实际上是HashMap。而HashMap底层维护了一个Node<K,V>类型的数组(transient Node<K,V>[] table)。添加元素时,元素存放在Node节点的key中。Node是HashMap类中的一个内部类如下
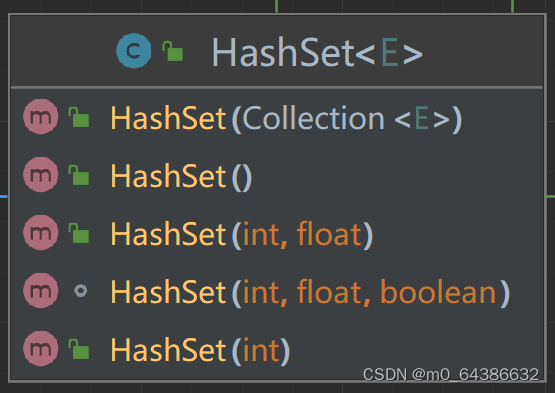
2.HashSet的五个构造器。
3.添加一个元素时,通过HashMap类中的hash方法先得到hash值,然后经过一系列算法得到索引值。找到存储数据的table,看table中此索引处是否已经存放的有元素。如果没有,则直接把添加的元素放到此索引处。如果有,则首先判断hash值是否相同,equals()比较然后判断是否是同一对象或后相同。如果条件成立,则放弃添加。如果条件不满足,则加入到已存在元素的后面。
5.在java8中,如果table索引处的一条链上的元素个数大于等于8,并且table的大小大于等于64,就会对table上该索引处的链表进行树化。

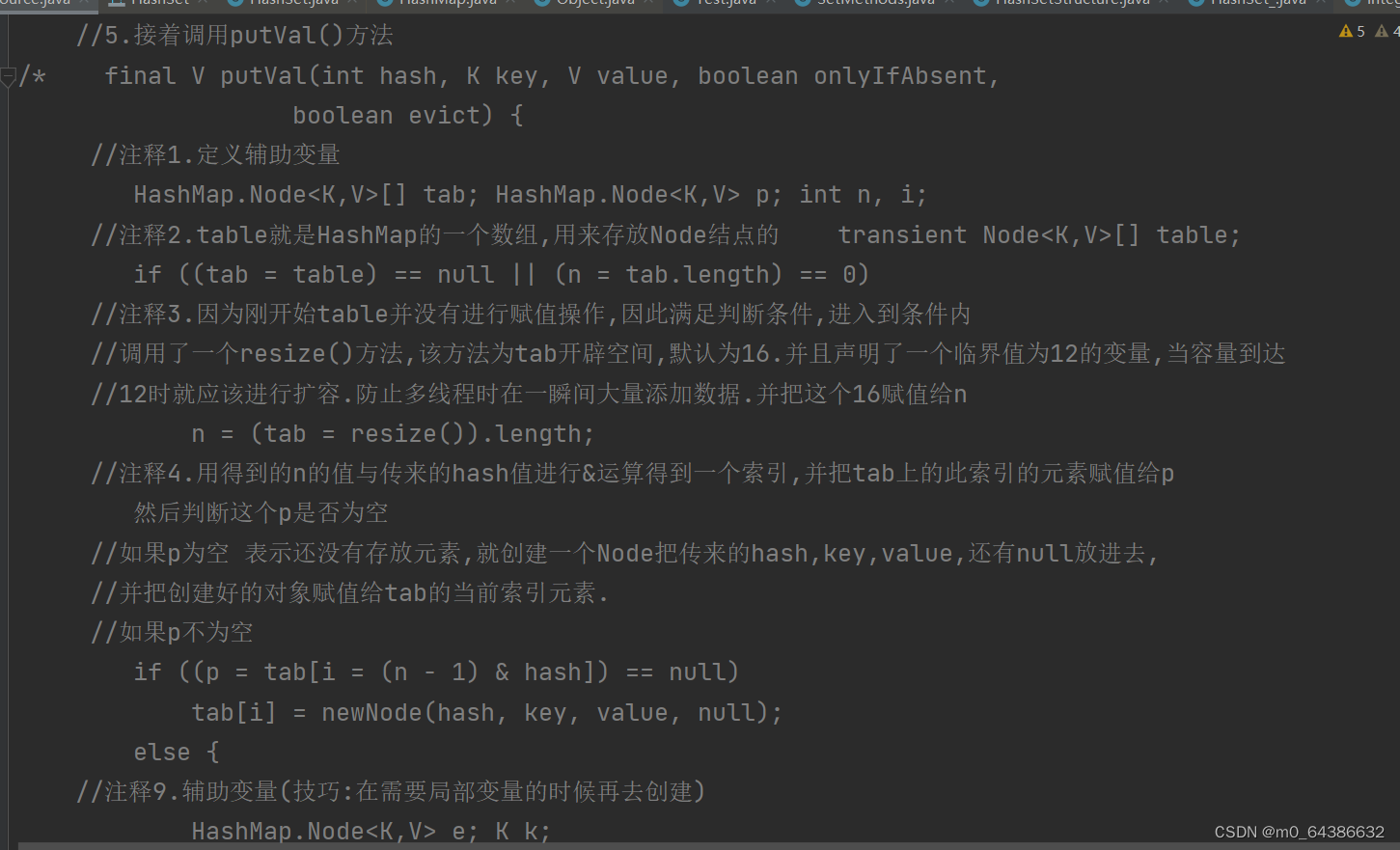
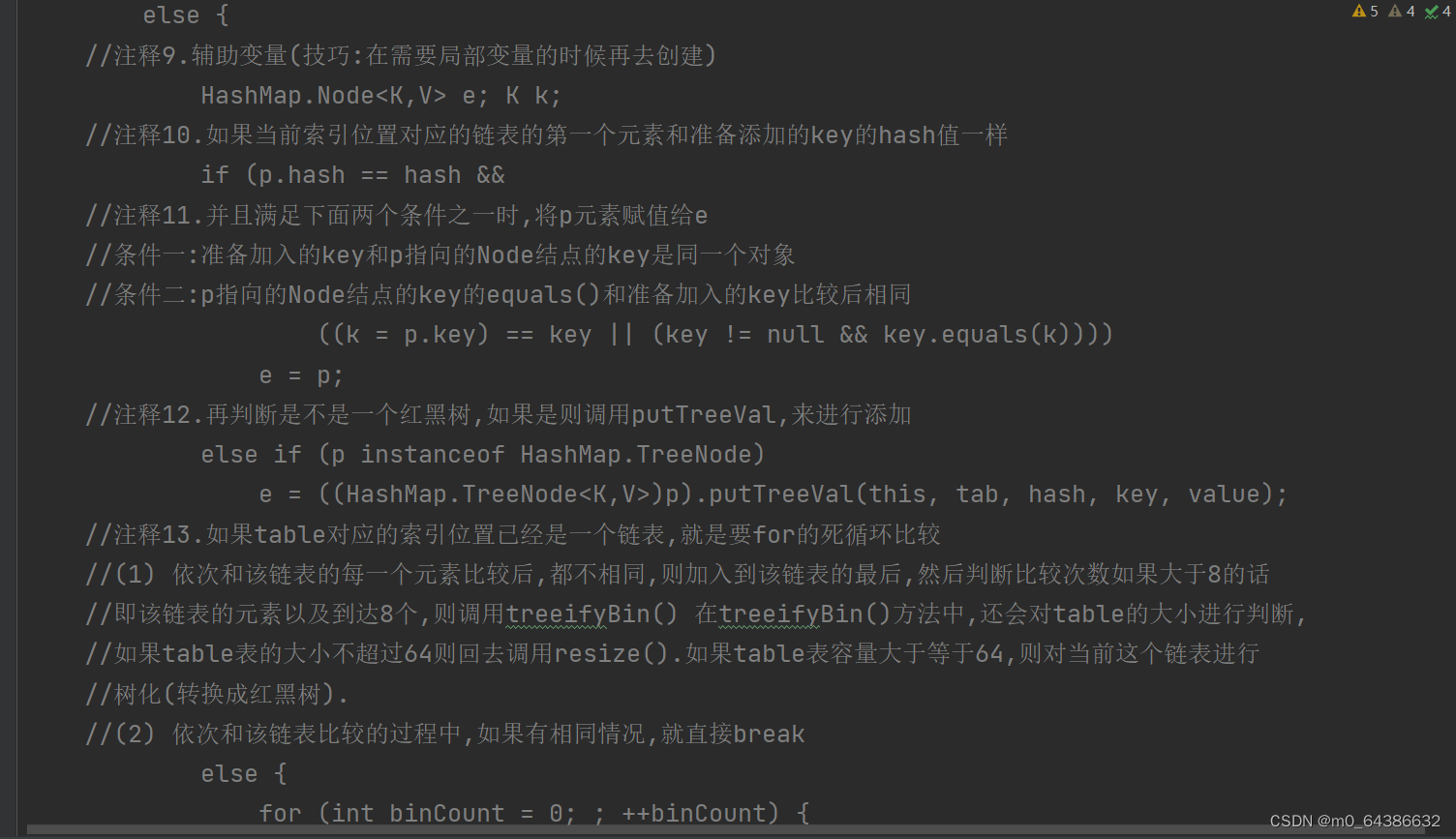
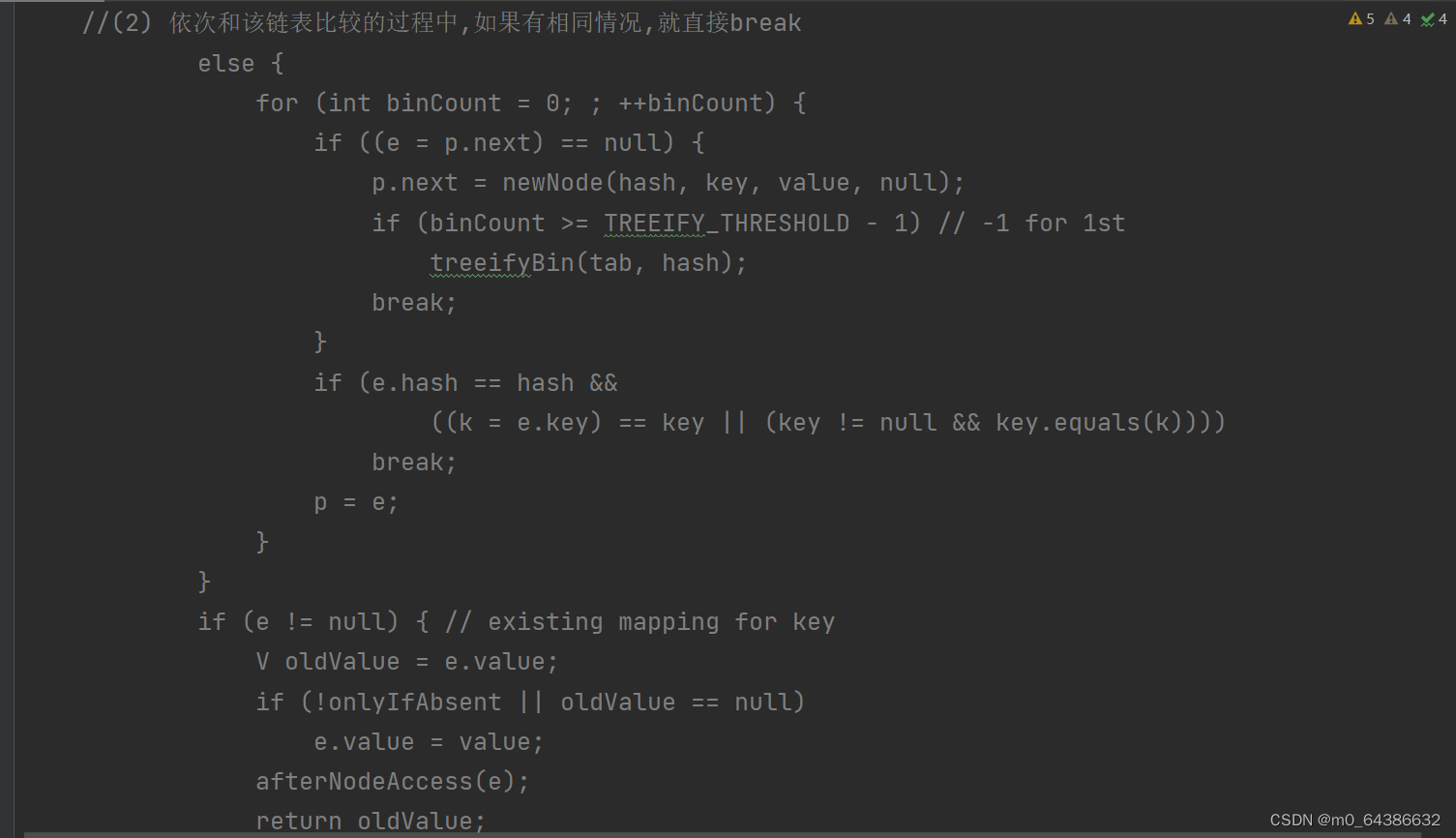

十八、HashSet底层扩容机制(扩容机制在源码的resise()方法)
1.HashSet底层是HashMap,第一次添加时,table数组扩容到16.临界值(threshold)是16*加载因子(loadFactor)是0.75 = 12。
2.如果table数组使用到了临界值的容量,就会扩容到16*2=32,新的临界值就是32*0.75=24。以此类推。
3.在java8中如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认为8)时,并且table的大小大于等于MIN_TREEIFY_CAPACITY()默认为64)时,就会对table上该索引处的链表进行树化(树化机制在treeifyBin()方法中)。如果链表元素达到了8,而table的大小没有达到64。则不会进行树化,而是进行table数组的扩容。
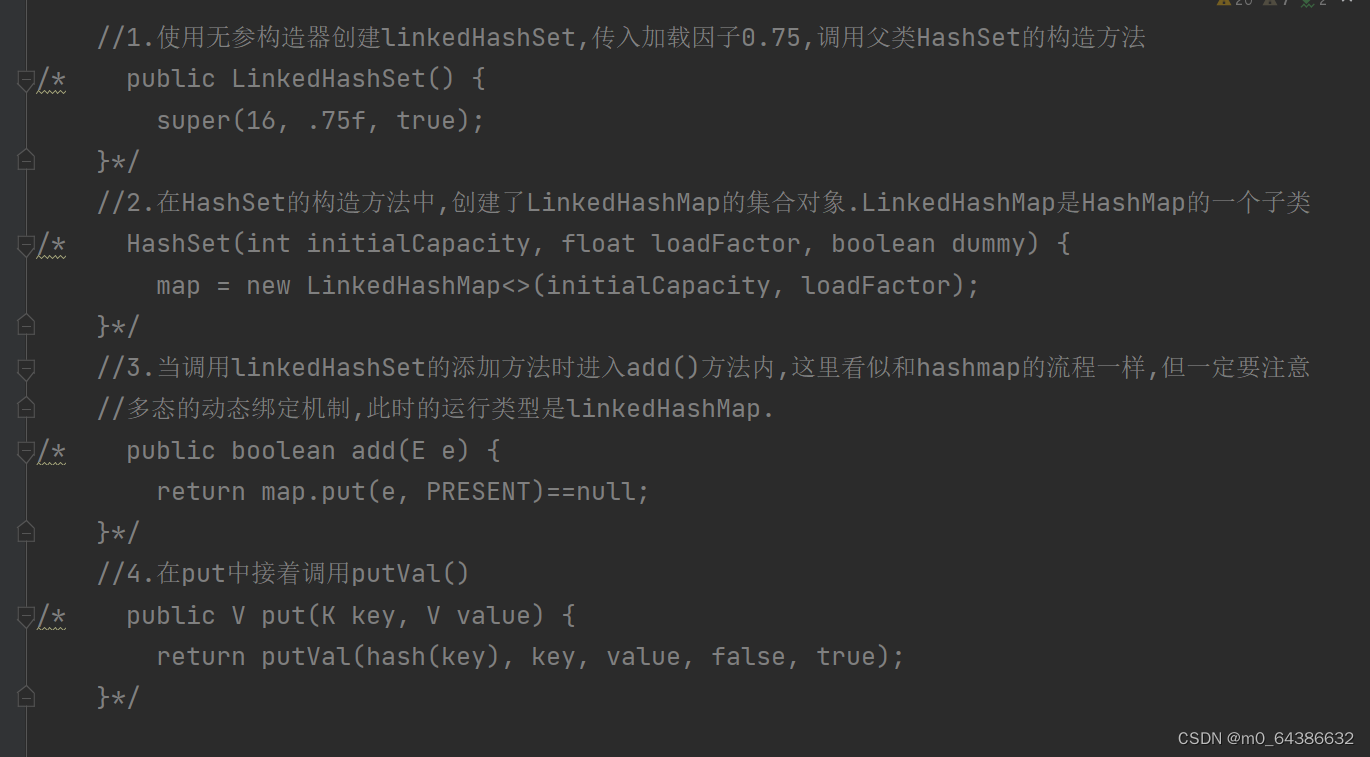
十九、LinkedHashSet特点(线程不安全)
1.LinkedHashSet底层时LinkedHashMap,而LinkedHashMap是由数组+双向链表+红黑树(java8)实现存储的。因此虽然没有索引值,但是插入和取出的顺序却是相同的。
2.LinkedHashSet不允许添加重复元素。
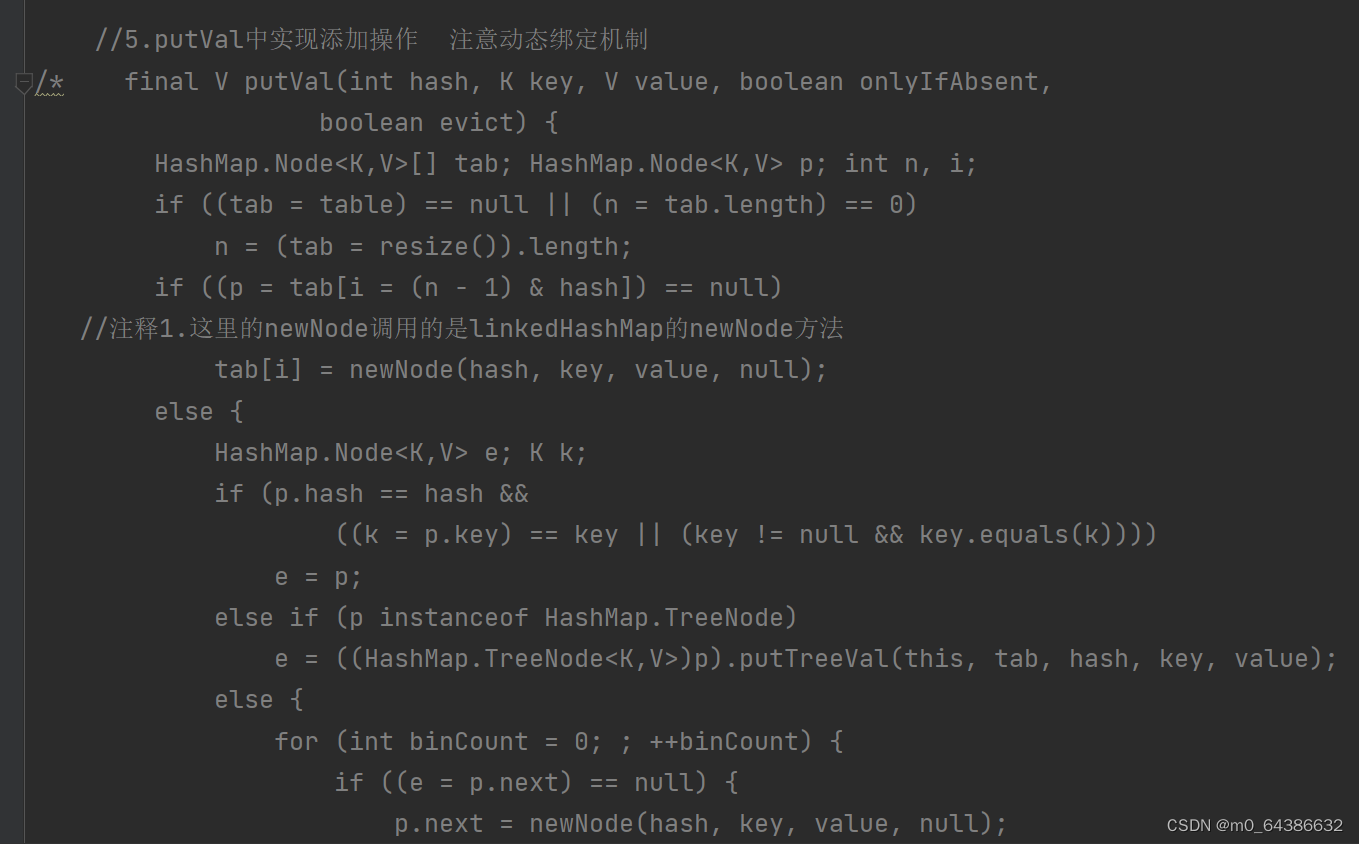
二十、LinkedHashSet底层操作机制(初始化、添加、挂链、扩容)
1.LinkedHashSet在调用构造器初始化时,会创建一个LinkedHashMap对象,而内部方法都是通过这个LinkedHashMap对象完成的。因此HashSet底层实际上是LinkedHashMap。而LinkedHashMap底层使用的还是父类HashMap中的Node<K,V>类型的数组(transient Node<K,V>[] table)。添加元素时,元素存放在Entry<K,V>节点的key中。而Entry类继承了HashMap的Node类。
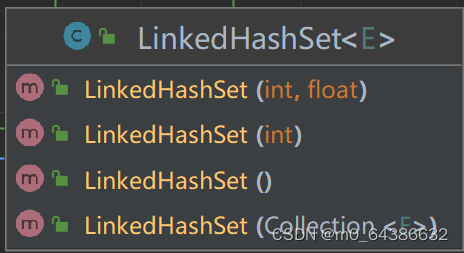
4.linkedHashSet的四个构造器.当我们通过HashMap(int initialCapacity)设置初始容量的时候,HashMap并不一定会直接采用我们传入的数值,而是经过计算,得到一个新值,目的是提高hash的效率。(1->1、3->4、7->8、9->16)
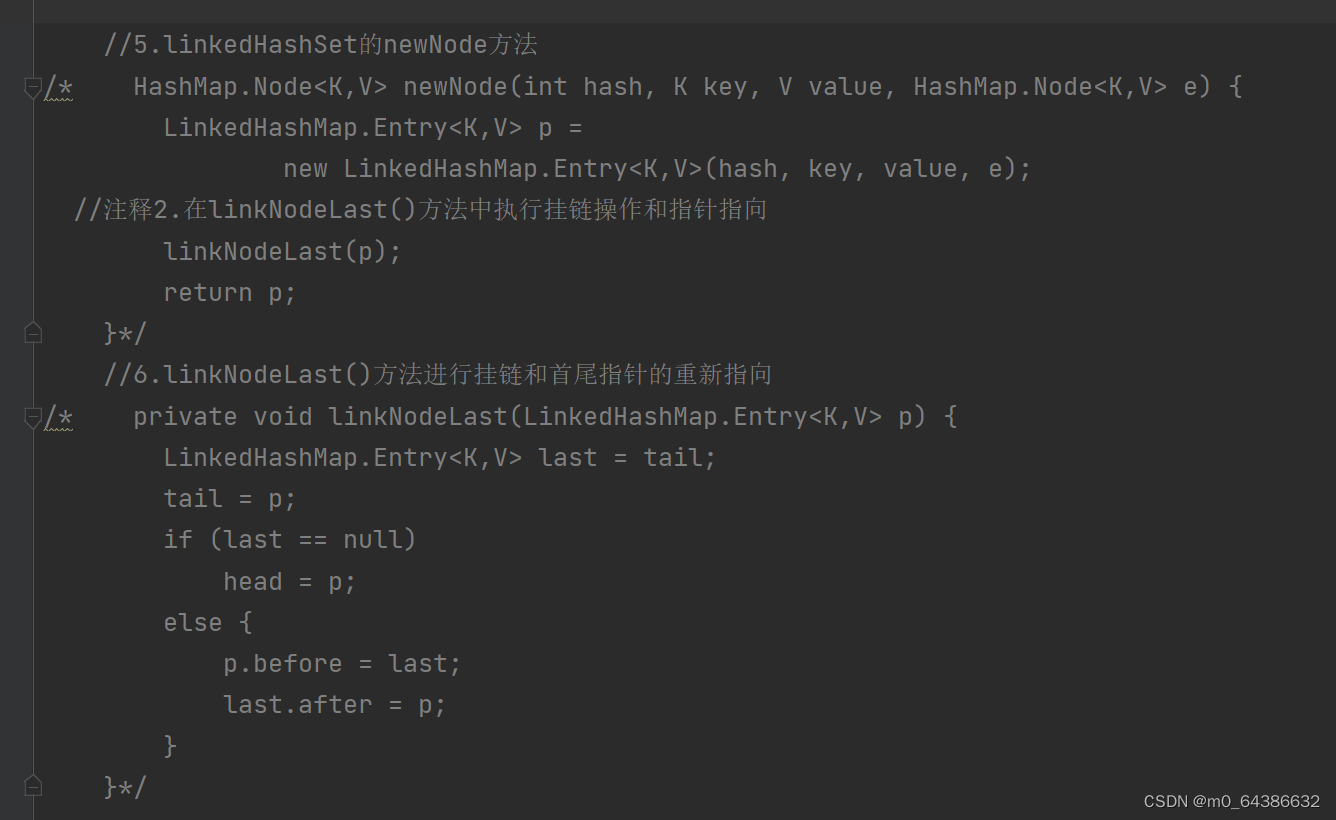
5.LinkedHashSet类中分别定义了head(transient LinkedHashMap.Entry<K,V> head;)和
tail(transient LinkedHashMap.Entry<K,V> tail;)指针属性,来分别指向添加元素时的第一个元素和最后一个元素。而Entry中的before和after属性分别表示此节点的上一跳节点和下一跳节点。
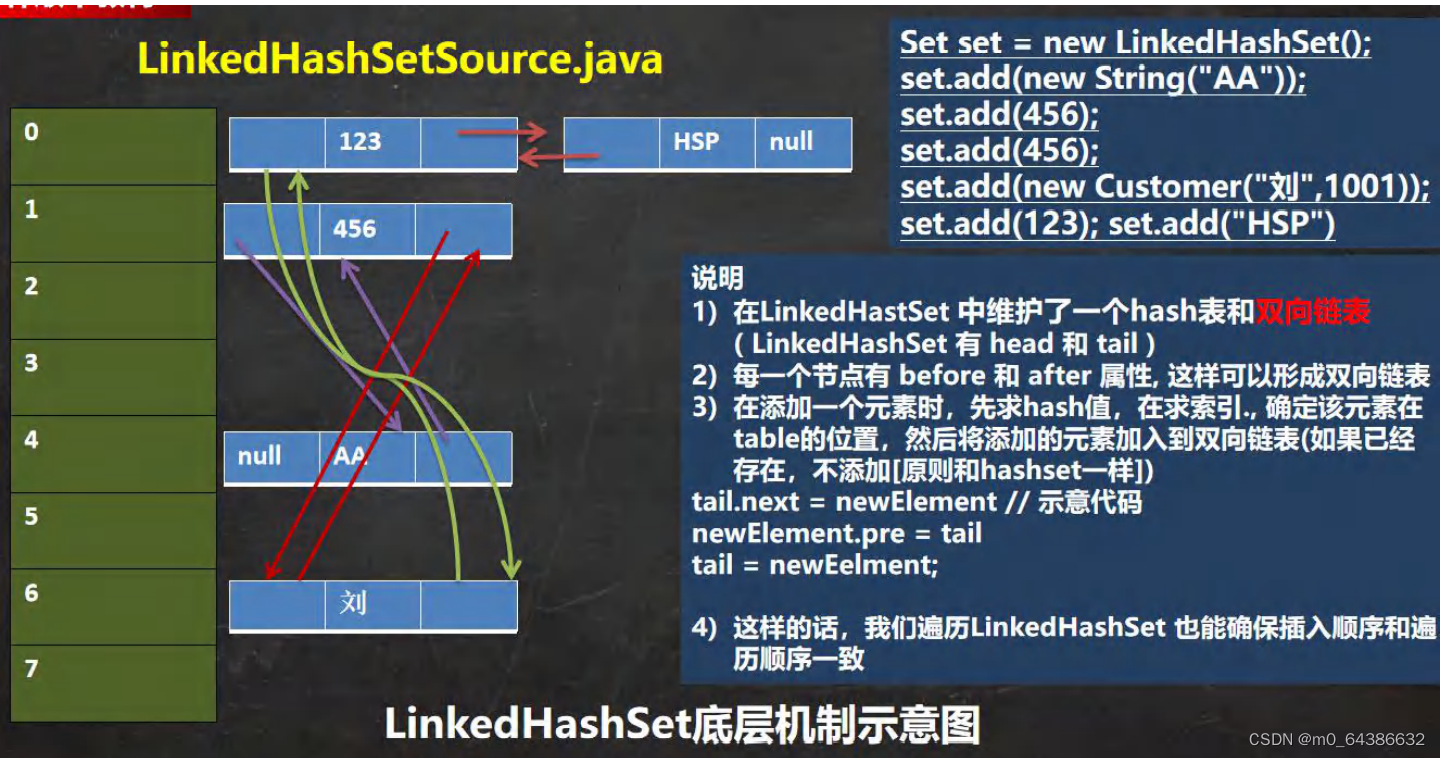
6.LinkedHashSet和HashSet的底层机制基本一样,除了LinkedHashSet是数组+双向链表需要进行挂链来保证插入取出顺序一致,
二十一、TreeSet特点(线程不安全)
1.TreeSet内部是一个TreeMap,而TreeMap底层是通过红黑树来存储数据的。
2.TreeSet在创建对象时可以通过传入一个比较器Comparator<E>对象来对添加的元素根据指定规则进行排序。
3.红黑树的每一个节点是一个Entry对象
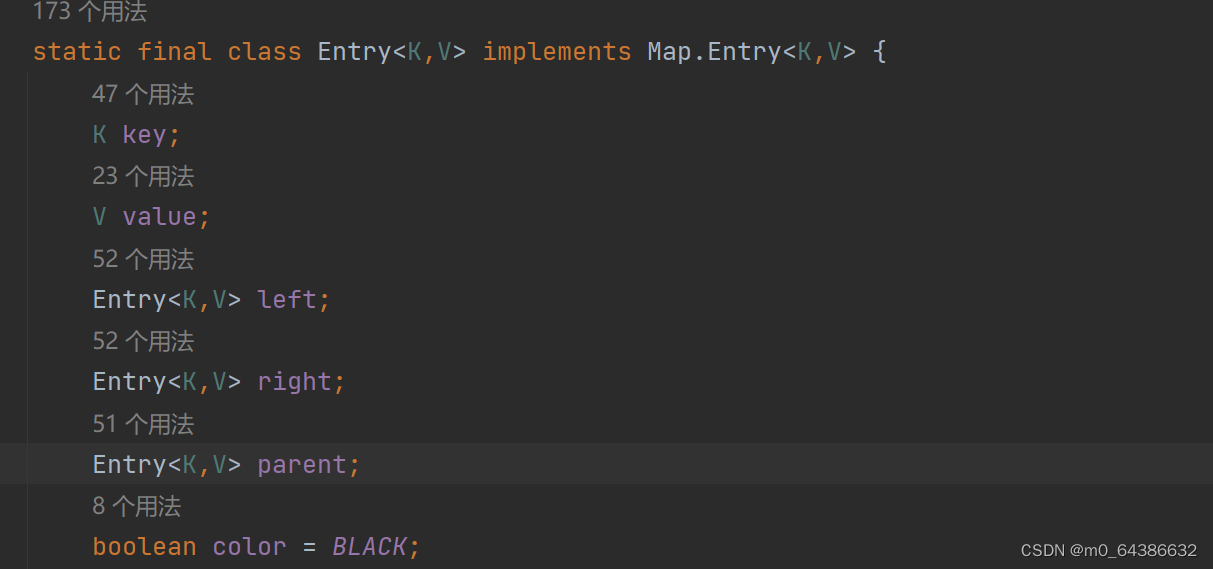
4.TreeSet的四个构造器
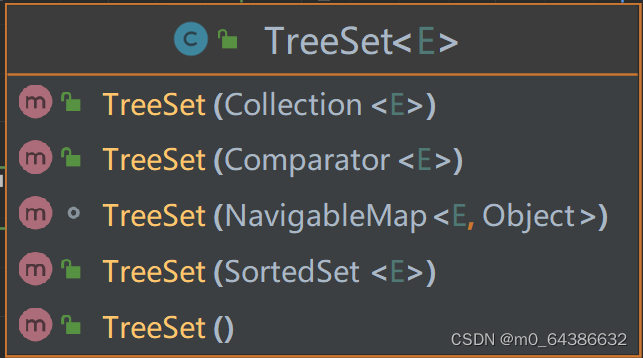
二十二、TreeSet的底层实现机制(初始化、添加)

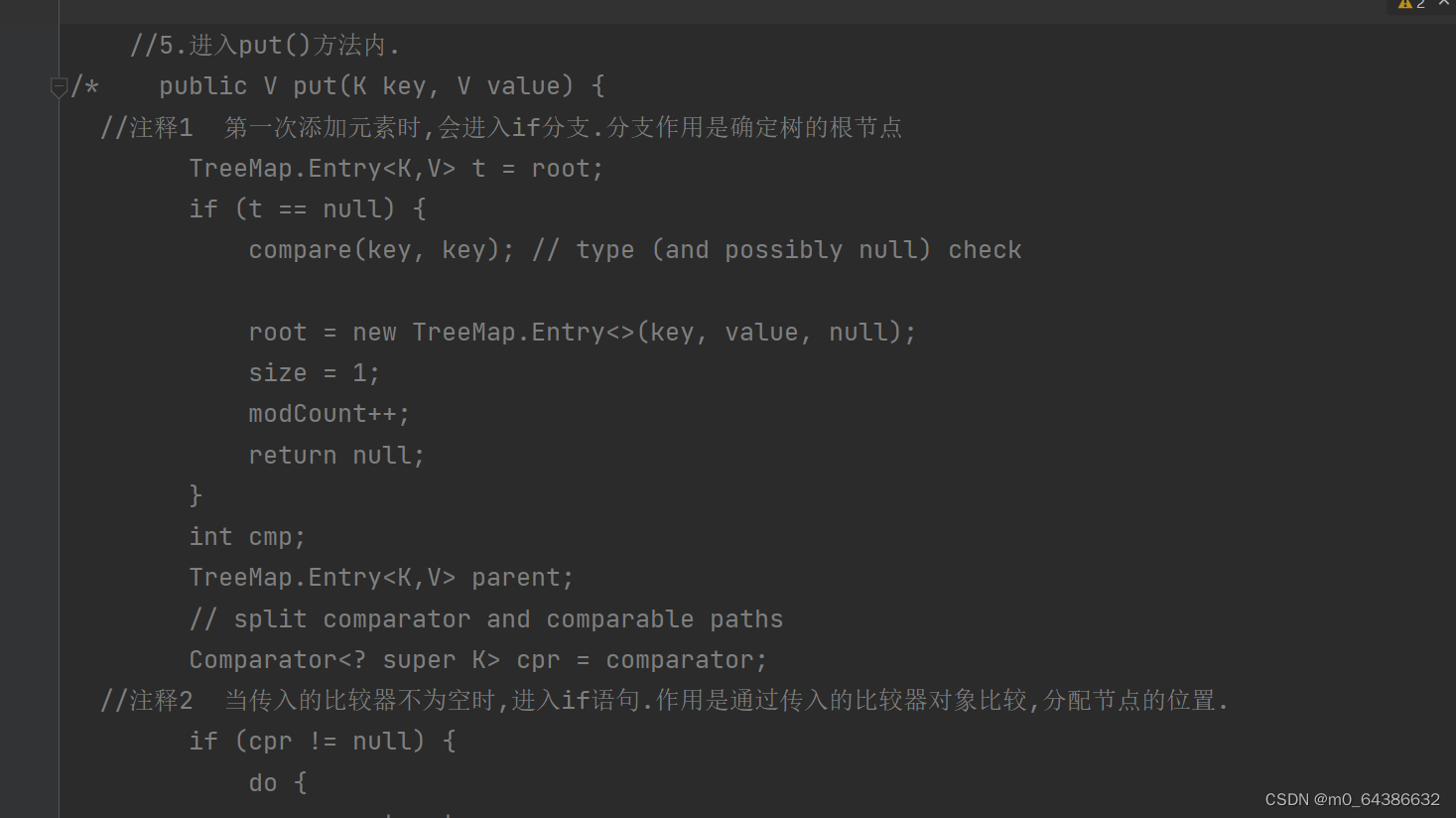

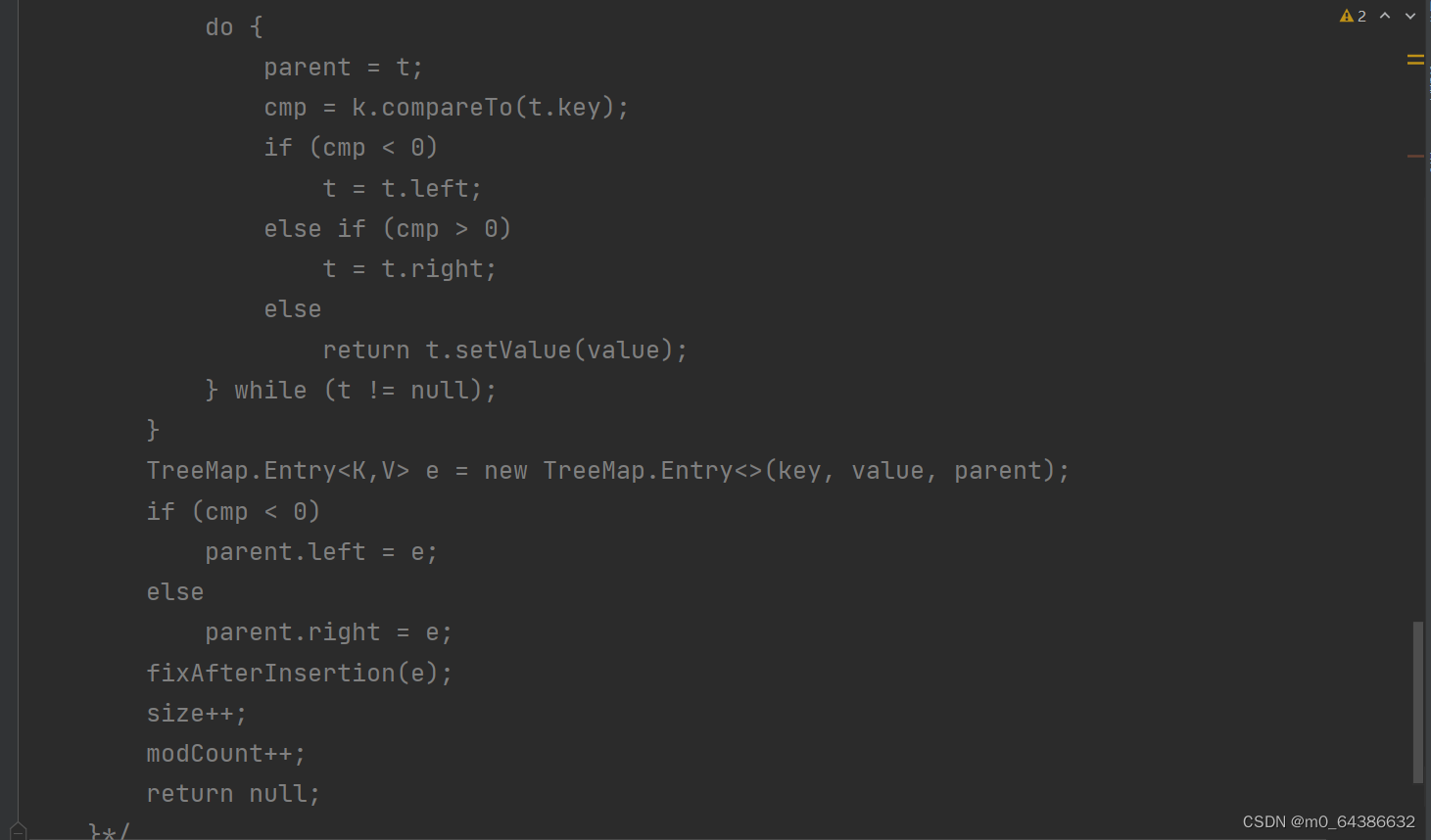
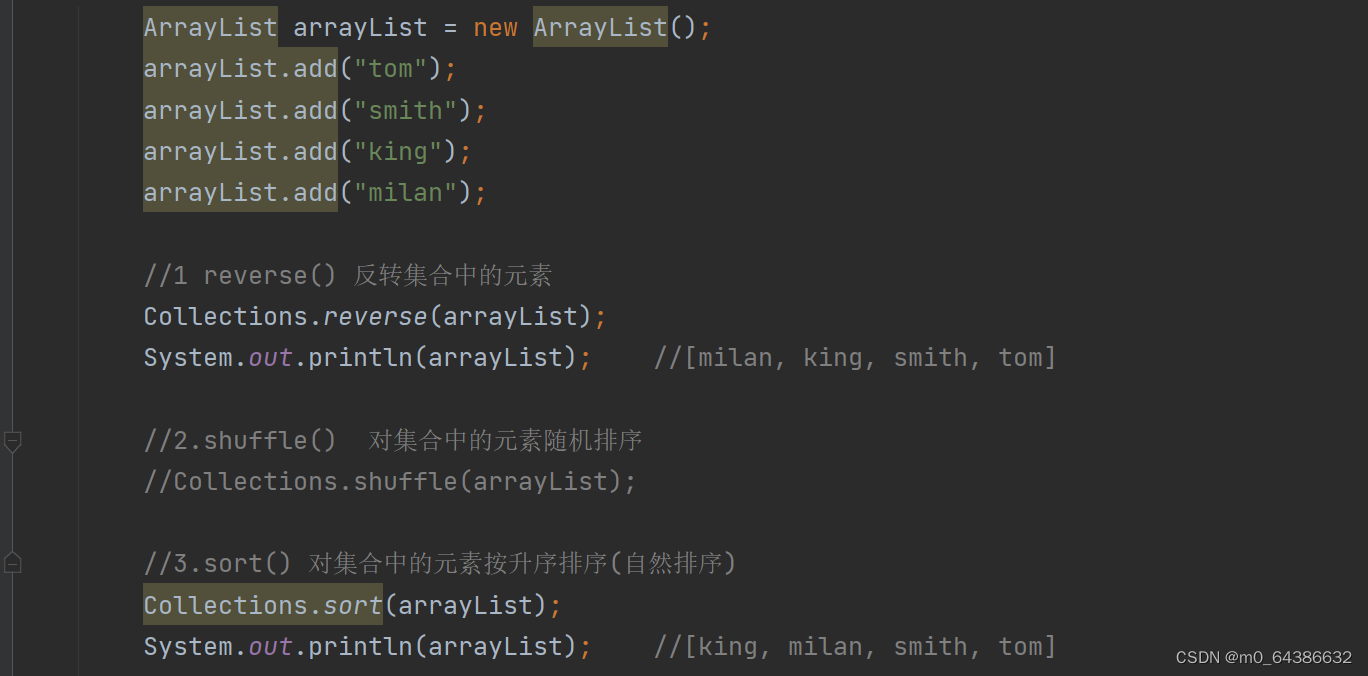
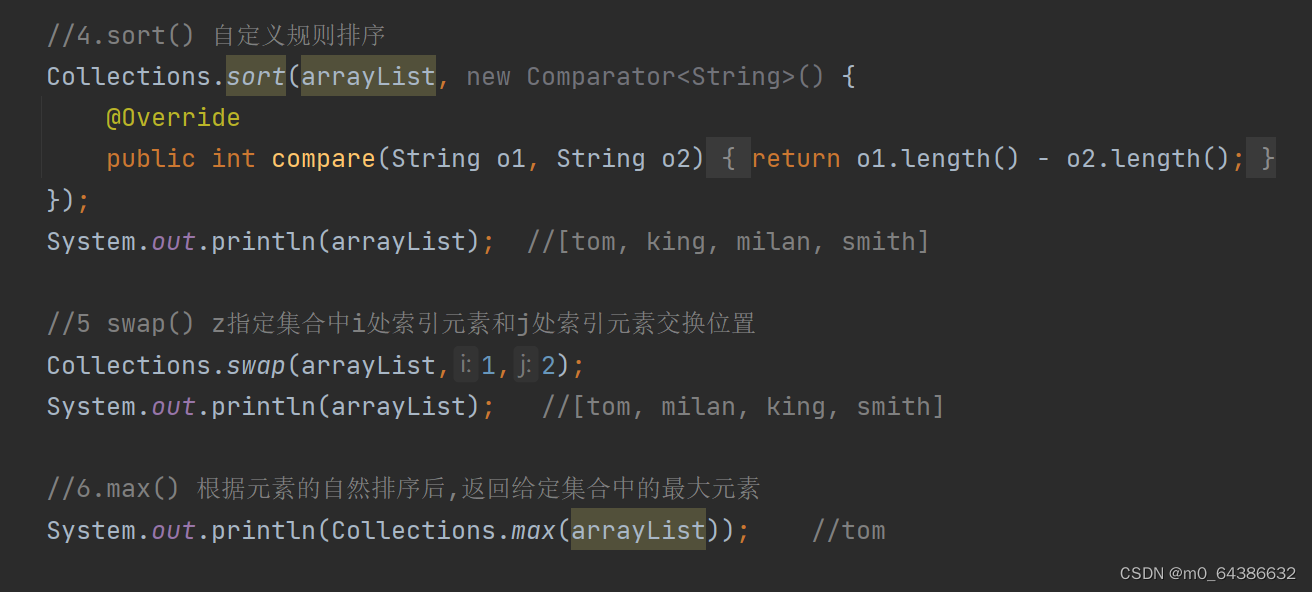
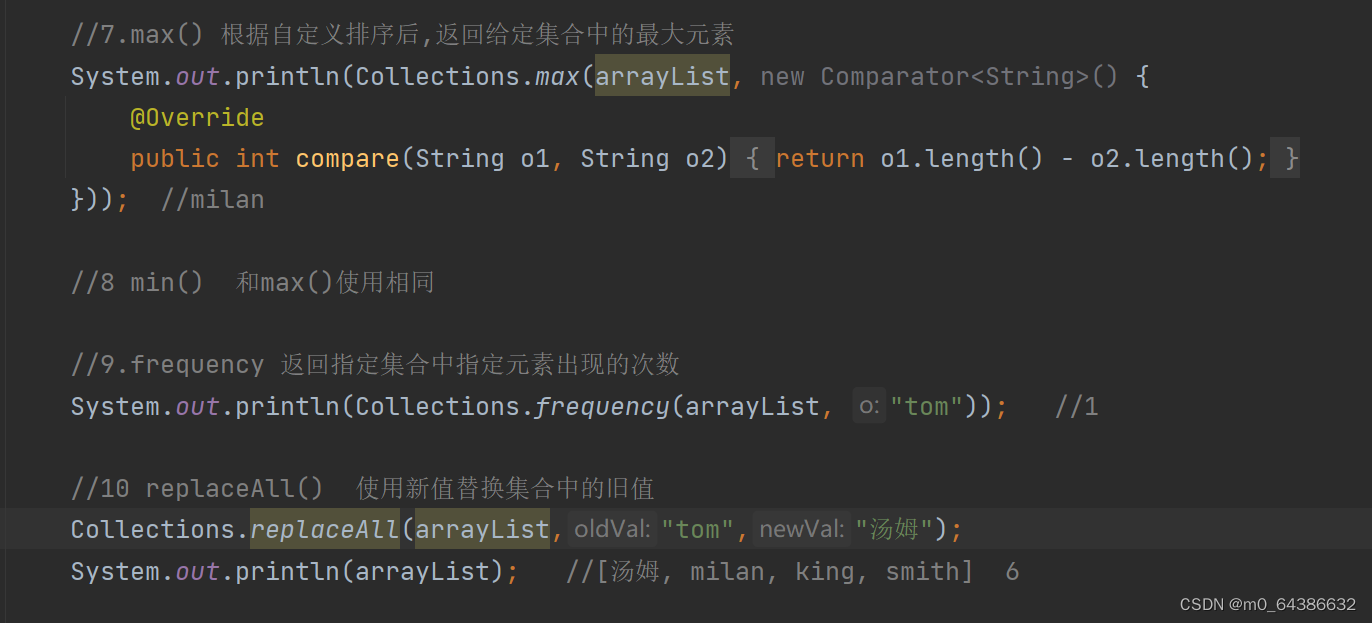
二十三、Collections工具类常用方法















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









