






目录
前言
下面要写的就是关于后端的部分了.
除了要写 Servlet 构建动态网页的技术.
还有一个很重要的,就是前后端沟通的桥梁.
也就是网页端和服务器这边如何进行数据交互,这个过程中涉及到了网络通信,也就涉及到一些具体的协议.那么就要涉及到 HTTP 协议.下面的重点就是 HTTP 协议.
HTTP 协议
什么是HTTP协议
前面有略微提到过 HTTP 协议.
HTTP 协议是一个应用特别广泛的应用层协议.
这样的应用层协议,也是需要下层协议的支撑!!
HTTP这个协议在传输层主要是基于TCP来实现的.
TCP是传输字节流的协议.只是把数据按照字节来传输而已.TCP并没有传输一个"结构化"的数据.
我们具体在写代码的时候,还是希望网络通信传的是结构化的数据,因此应用层协议,就是在干这件事情,就是把传输的字节流赋予一定的含义.
HTTP协议又可以认为是 应用层协议 中的典型代表.
HTTP协议主要有三个大版本(不算小版本)
HTTP 1(现在主流使用的版本) 基于TCP
HTTP 2(支持的不多) 基于TCP 主要引入的是安全性 (相当于HTTPS的加强版本)
HTTP 3(建设中) 基于UDP 主要是提高效率
HTTP(全称为"超文本传输协议")
超文本,指的是 "HTML" (超文本里面包含一些特殊的东西,图片,连接,音频,视频.....)
HTTP 最早就是为了下载 HTML
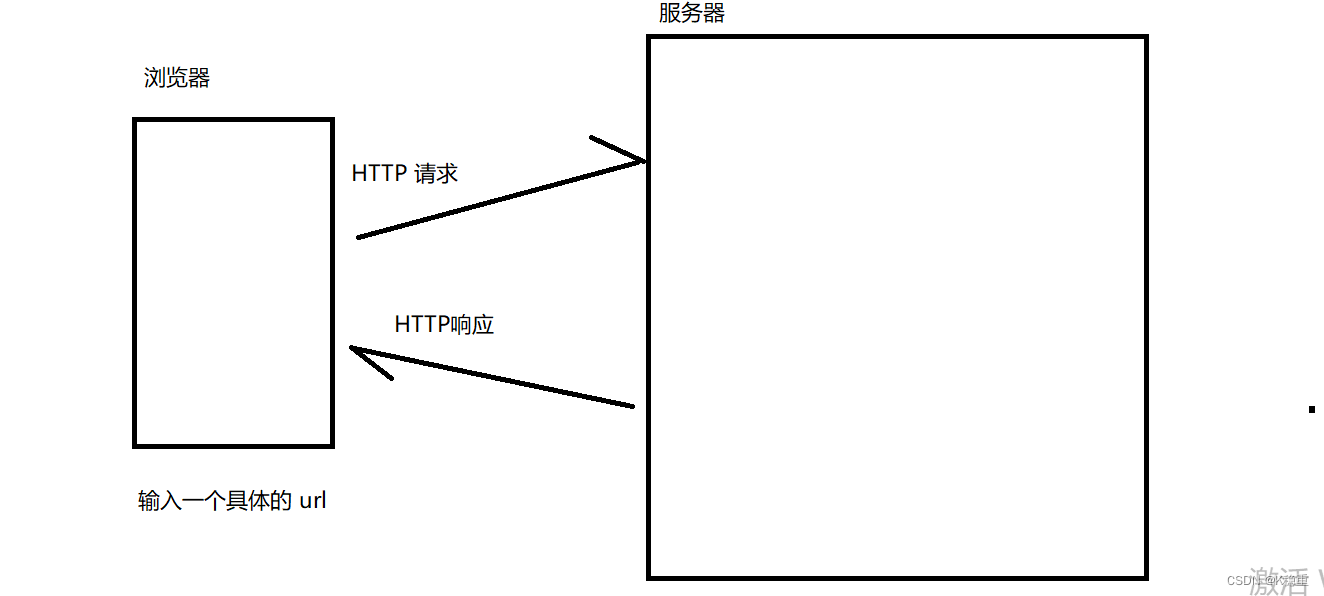
回顾一下应用层协议
使用网络是为了 "编程" 是为了,解决实际问题!!
在已知的这几个网络层次中,传输层,网络层,数据链路层,物理层 每个层次都有各自的使命
好比我现在要去淘宝买一个笔记本支架 .这个支架就要通过快递,逐渐送到我手上,这一整个物流系统,就相当于网络通信的下四层.这下四层就保证了包裹能够运到我手上.但是他们不管这个支架是不是能用.这几层协议只负责数据传输,而不能解决问题,我们的初心是为了解决实际的问题.作为一个程序猿,大部分的经历都在关注这个应用层协议!!!
为了解决当下的某个问题,应用层协议的请求都要传输哪些信息,按照啥格式传输.响应都要包含那些信息,按照啥格式传输.
除了自己设计协议之外,也有一些现成的应用层协议.对于现成的应用层协议来说,也要重点理解里面的 信息 + 格式.


理解 HTTP 协议的工作过程
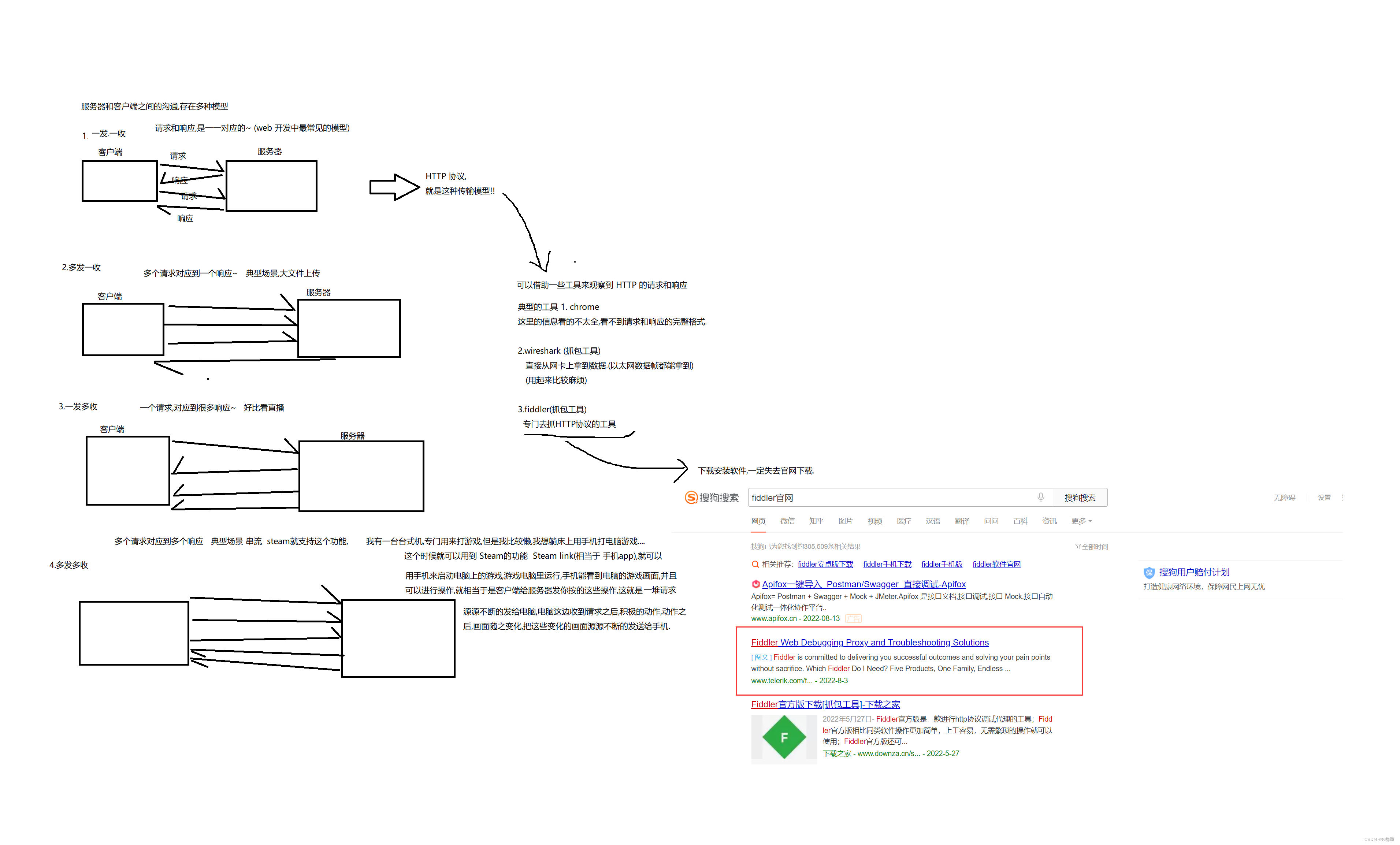
网络通信中,主要涉及到几个核心概念:
1.服务器 vs 客户端
2.请求 vs 响应
抓包工具的使用
以 Fiddler 为例. (下载地址: https://www.telerik.com/fiddler/)
HTTP协议,非常重要!!!
面试经常考 + 工作中经常用!!!
Fiddler 为啥能抓包?
对于这样的抓包工具来说萌骑士相当于是一个"代理".
因此,进行 HTTP 通信的详细信息
都 会被 fiddler 给获取到~
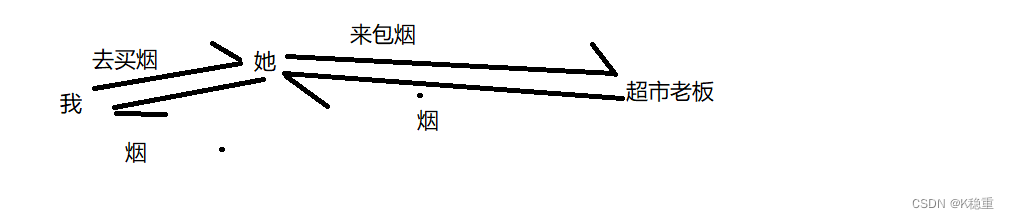
代理还有两个常见的术语:
正向代理
反向代理
这俩本质上都是代理,只是站在不同的角度来观察
正向代理这个是站在服务器的角度来观察.
反向代理这个是站在客户端的角度来观察.
举例:
我要去楼下小超市买包烟.
我就可以直接去超市,找到老板,完成买烟的动作.(不加代理)
但是我太懒了,不想动,我就指使我对象,我就派她去买烟.
站在超市老板(服务器的角度)
并不关心真实的客户端是她还是我,只是单纯的完成卖烟的这个动作就可以了.
她把握给隐藏起来了,服务器只能看到她,看不到真实的我.
这就是正向代理(站在服务器的角度,把客户端隐藏起来了)
反向代理(站在我的角度(客户端的角度))
我并不关心真实的服务器是超市老板还是他儿子.
超市老板的儿子把超市老板给隐藏起来了.客户端只能看到他儿子,看不到真实的老板.
站在客户端的角度,把真实的服务器给隐藏起来了.
以后访问到的很多服务器,其实都可能是反向代理.
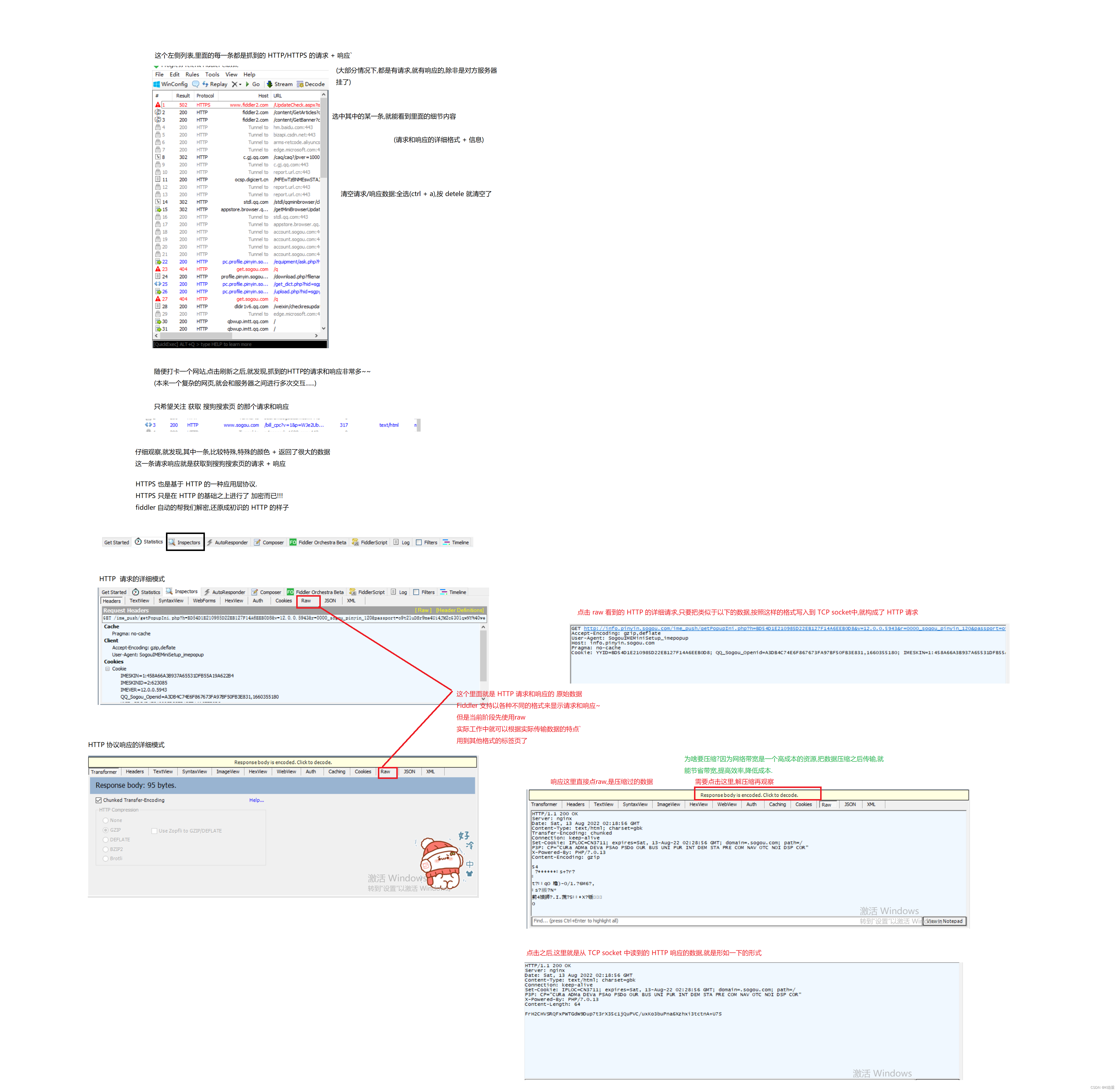

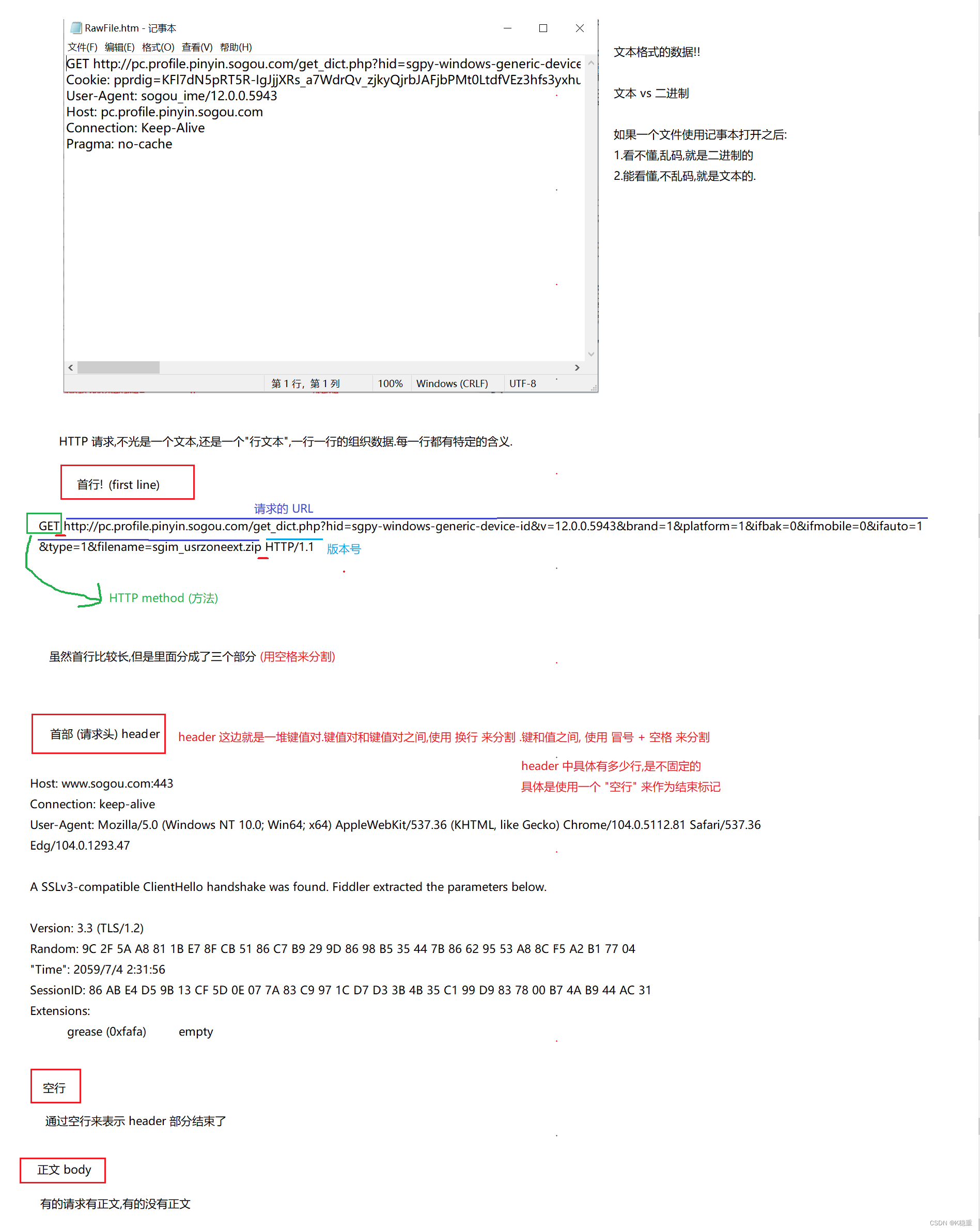
HTTP协议的详细格式 + 信息
HTTP请求的格式
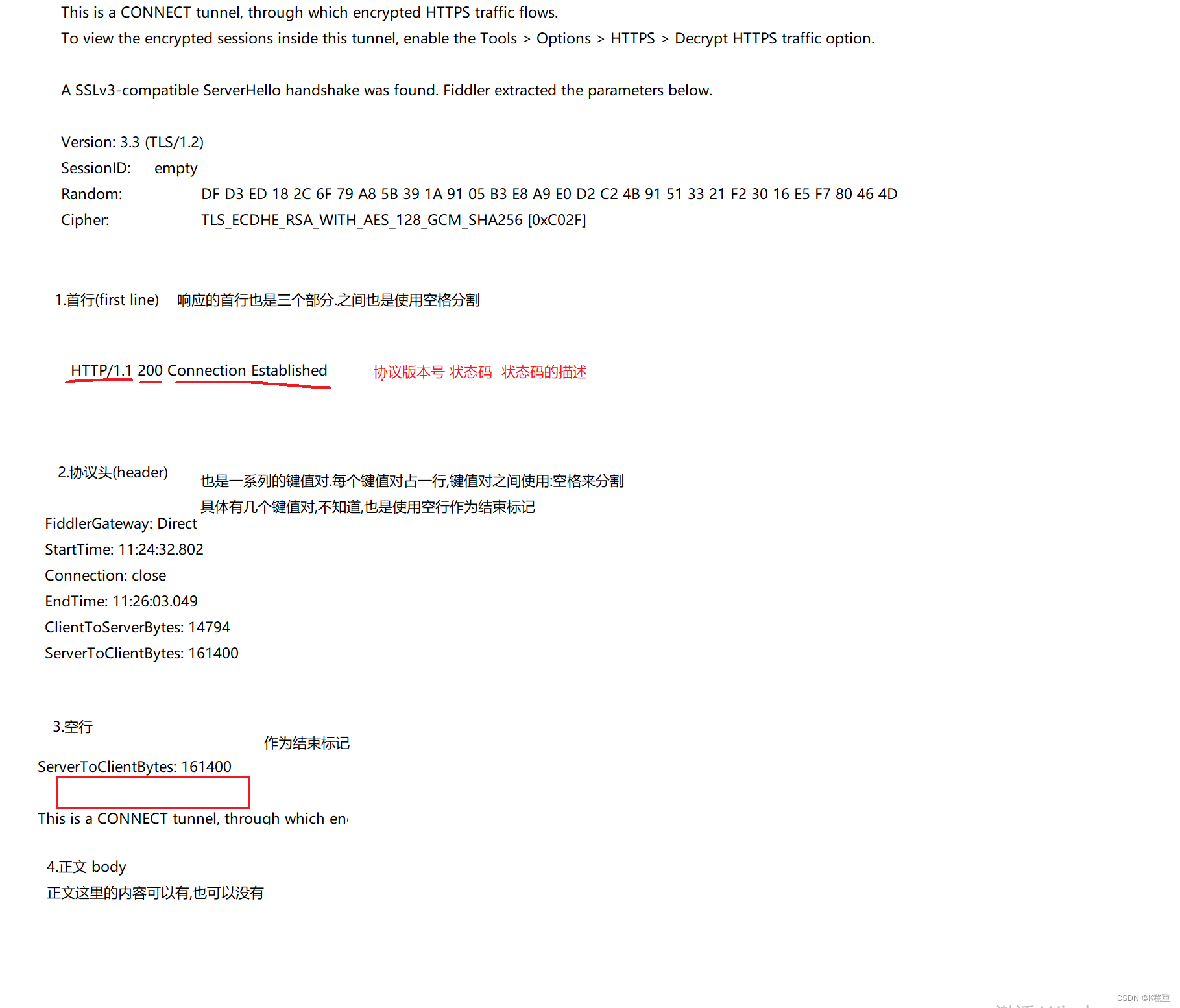
HTTP响应的格式
HTTP协议格式小结
HTTP 是一个文本协议
这个报文格式非常重要!
一定要背下来!!!
面试的时候一般不会直接考你这个报文格式.
主要就是为了实际工作中.还是经常会需要抓包的.抓包了之后,怎么分析结果.
就需要你对这个协议格式非常熟悉
HTTP协议的详细信息
URL
URL不仅仅是给HTTP服务的,还能够给很多协议提供服务.
比如:
HTTPS
FTP
JDBC:MySql://
file://
协议名后面的:// 这个是固定的内容~
URL 格式小结
1.协议名称:URL支持很多协议.
2.用户名密码:现在已经废弃了,不再使用.
3.服务器地址:可以是域名,也可以是IP地址
4.端口号:如果不写端口号,就会有一个默认值(浏览器自动加的).HTTP 默认值 80,HTTPS 默认值 443.
5.路径:表示服务器上面具体的哪个资源.
6.查询字符串:浏览器给服务器传递的一些参数.程序猿自定义的
7.片段标识:定位到页面中的某个部分.
URL 的初心就是用来区分一个网络上的唯一资源~~
①先通过 服务器地址,定位到一个具体的服务器
②再通过 端口号定位到一个具体的应用程序
③再通过 路径 定位到这个应用程序管理的一个具体资源.
④再通过 查询字符串,对这个具体资源的要求做出进一步的解释.
⑤最后通过 片段标识 来确定定位到这个资源的哪个部分
1
对于URL来说,这几个部分都不是必须要有的.
有些部分是能够省略的~
协议名称是可以省略的
用户名密码,本来就不需要
服务器地址,也能省略
端口号也能胜率
路径也能省略
片段标识还是能省略




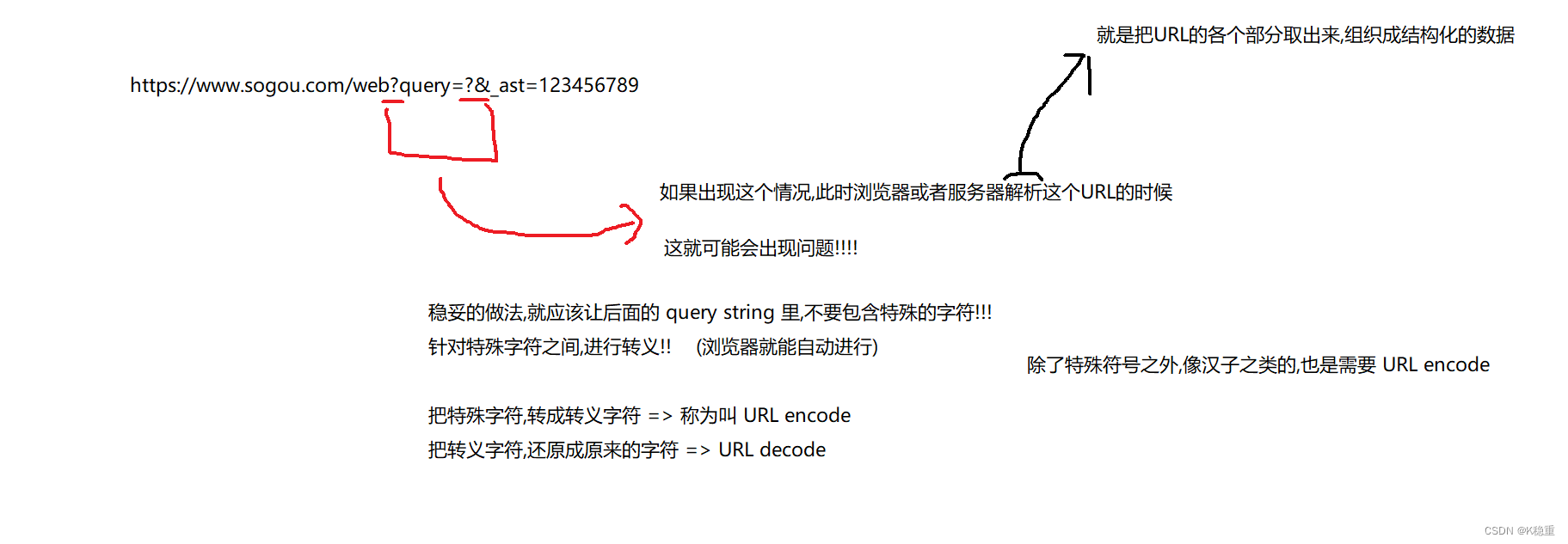
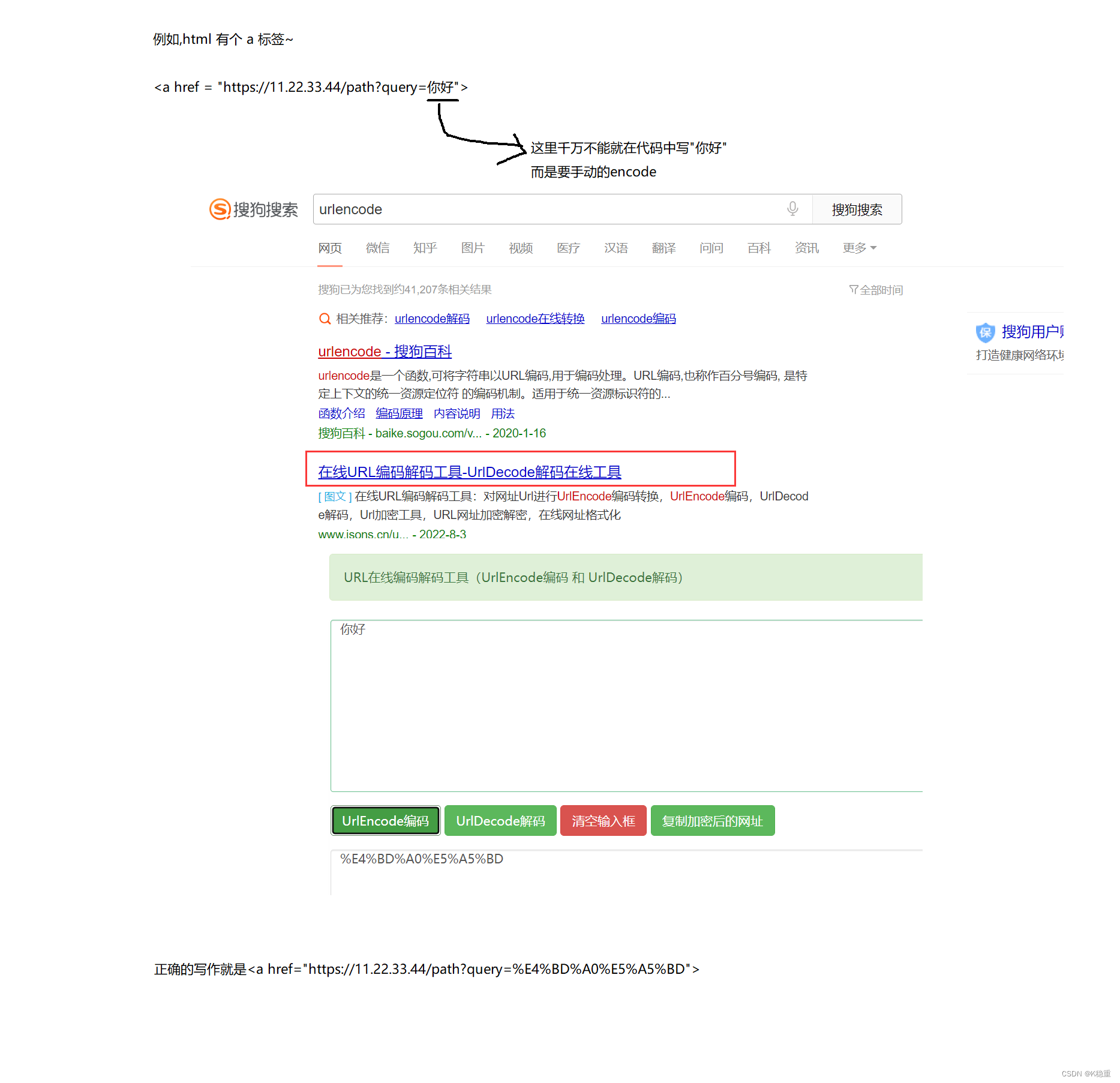
关于 URL encode
URL中有些东西是用户自定义的.典型的就是 query string
用户自定义的 query string 中,是可能存在一些特殊符号的!!
如果query string 中也包含了如上述的特殊符号,就可能导致浏览器/服务器解析 URL 的时候出错!!!
本来程序是判定 ? 后面是 query string.
结果你 query string 里也有个 ?
好比假如:
一定要重点注意,就是为啥要 url encode!!!
以及基本规则.
至于说实现一个 URL encode 的函数,就不必要~~
虽然浏览器会自动的对这里的特殊符号进行 encode ,但是有的时候,咱们手动构造的 URL ,不一定能自动 encode ~
稳妥起见,如果咱们需要自己 构造 URL,URL 里面带有特殊符号的时候,一定要手动的 encode.否则就可能请求发送失败

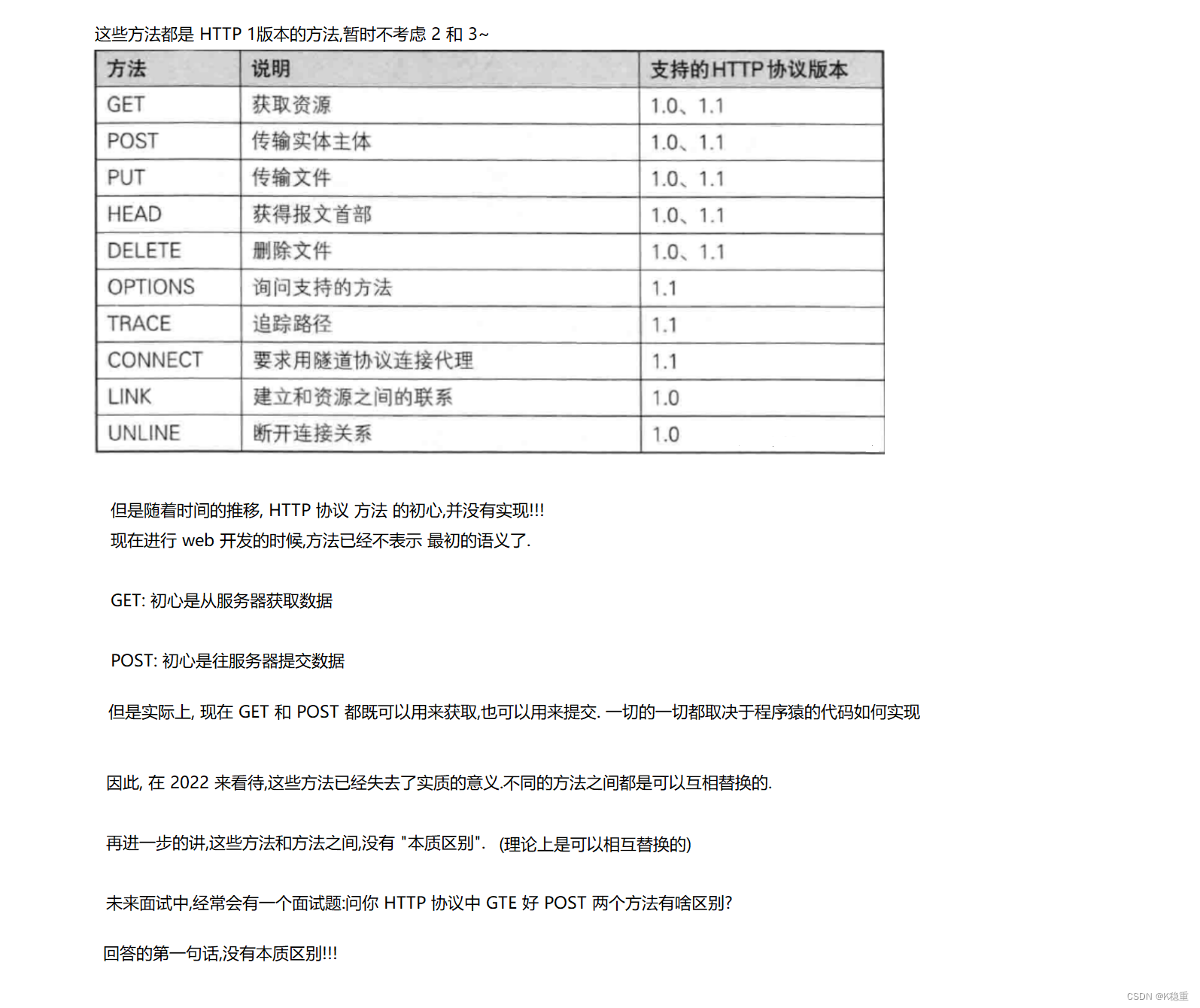
认识 "方法" (method)
关于请求中的"方法"
属于 HTTP 协议设计之初,一个"初心". 把请求根据功能,划分成不同的种类~~
举例:
有的时候,需要从服务器获取一些数据.用GET
有的时候,需要给服务器上传一些数据.用POST
有的时候,需要删除一下服务器的数据.用DELETE
有的时候,需要了解一下服务器的一些选项.用OPTIONS
.............
这些不同种类的请求,就用 "方法" 来进行区分.
换句话说方法诞生之初是有 "语义" 的.
方法中GET
最常使用的 HTTP 的方法
常用于获取服务器上的某个资源.
但是使用 GET 给服务器提交一个数据,是否可以??? 完全可以!!!
使用 GET 删除服务器的一个数据,是否可以?? 完全可以!!!
这不过这两个不是常见方法
哪些方式会触发 HTTP 请求:
1.直接在浏览器中输入 URL,就会触发一个 HTTP 请求
2.HTML 页面中的一些特殊标签,link(引入css),img(图片),script(引入js),a(超链接)也会触发 HTTP 的 GET 请求.
link(引入css),img(图片),script(引入js),这三个是页面加载是触发.
a(超链接),用户点击是触发.
1
GET 请求的特点:
首行的第一部分为 GET
URL 的 query string 可以为空, 也可以不为空.
header 部分有若干个键值对结构.
body 部分为空.(通常情况下,GET 的 body 为空~ 但是如果你自己构造一个body不为空的 GET请求,是否可以呢?完全可以!!!但是如果去抓一些包,看看其他网站的 GET 请求,就会发现,大家的 body 基本都是空的.GET 请求的 bady 是完全可以不为空的!! 为空是一种习惯上的做法)
1
关于GET请求的 URL 长度的问题:
注意!!! 关于 URL 的长度限制问题,网上的很多帖子的说法是错误的~
网上说:GET 的 URL 长度存在上限.上限具体是多少....给出过很多版本的数字~~1k,2k,1M....
长度的上限以谁为准>要以 RFC 标准文档为准!!! 这个才是最权威的
在 RFC 标准文档中, HTTP 协议, RFC 2616 标准 ~ 对于 URL 的长度是没有做出限制的~~
话又说回来,标准只是一份文件而已.实际开发的时候是要遵守标准,但是同时也要看别人是不是严格的遵守了标准.实际上有的浏览器/ HTTP 服务器,切实可能是不遵守标准~~
在早期 IE 的版本里,确实不支持长的 URL .现在我们使用的 chrome 浏览器,对于这个 URL 的长度是能够支持非常长的!!! 一般来说都不必担心这个长度问题~
POST 方法
HTTP 协议中,最常用的就是 GET ,其次就是 POST
啥时候会使用到 POST 请求?
最常见的情况,就是登录~~
使用 GET 完成登录,行不行?
完全是 OK!!
只不过咱们习惯是使用 POST 实现登录.
构造 POST 请求的方式也很多.
1.form
2.ajax
3.第三方工具
结合上面的讨论,就能看到, GET 和 POST 最明显的区别,就在于,程序猿自定义的数据,是习惯放在 query string 中,还是 body 中~~
但是这些都属于习惯用法而已. GET 把数据放到 body, POST 把数据放到 query string 也是完全可以的.
HTTP 协议中的各种方法之间(尤其是 GET 和 POST 之间) 没有本质区别!!!
然后细节上还是有点区别的~~
1.数据位置: GET 把自定义数据放到 query string POST 把自定义数据放到 body
2.语义区别: GET 一般用于 "获取数据",POST 一般用于提交数据.
3.幂等性: GET 请求一般会设计成 "幂等" 的. POST 请求一般不要求设计成 "幂等".
幂等:某个请求,执行一次,和执行多次,没啥区别.如果能做到这一点,就称为"幂等"的~~
在实际开发中,经常有关于 "幂等" 相关的探讨和要求.
举例:
支付宝有一个关键功能,查看账户余额~~这种"查看操作" 本身就是 幂等的~
发一次查看余额的请求和发多次查看余额的都一样,没啥区别,只要你不花,账户余额不会变.
支付宝里还有一个关键功能,转账~,这种操作,如果不进行限制,就不是幂等的~~
好比某次给超市老板转账,转账过程中(密码输入完了),结果卡了!!!我就取消重新再转一次.
像这种转账操作,也是需要设计成幂等的.要避免因为一些网络原因导致服务器这边请求收到多次,从而导致多次转账.....
一个简短粗暴的限制手段,给每次转账,分配一个唯一的身份标识,如果服务器收到多个相同身份标识,只执行一次转账~~
4.可缓存: GET 请求一般会被缓存, POST 请求一般不能被缓存~
同样也是取决于程序猿的设计.
缓存也是计算机圈子中一个非常常见的术语/机制
比如,如果进行一些复杂的计算,得到一些结果.
如果这个结果的计算过程代价太大,就可以把这样的结果缓存下来,下次直接使用,避免计算机重复计算了.
但是这个事情并不是绝对的,比如有些业务场景下,像搜索广告这种,虽然是 GET 请求,但是绝对不能缓存~~(每个请求一定都是要实时计算的)
这些东西都不是绝对的!!
这些规则都是可以被打破的!!
最终的结论还是那句话,叫做 POST 和 GET 没有本质区别!!
网上很多关于 POST 和 GET 区别的说法,都是错的!!!
例如一个典型的说法: POST 比 GET 更安全.完全是无稽之谈
以登录为例
一般网页要给服务器传递用户名 + 密码.
如果是 GET ,习惯上把数据放到 query string 里.
一提交,用户就能看到一个形如(http://www.baidu.com?user=aaa&password=123)
密码直接显示在 URL 这里了.
啊,有人就觉得这个太不安全了.
POST 是把数据放到 body 中,不会直接显示给用户.
于是有人就觉得,啊,这个就好安全~~
安全不安全和数据放在哪里没有任何关系.
要想安全那得加密,要是不加密,搁哪都没有用.
这个说法也是不科学的.
RFC标准中并没有描述, URL 的长度.
更何况 GET 也可以有 body ,POST 也可以有 URL
这个说法也是不科学的
URL里面一般是放文本.
body 里面可以放文本也可以放二进制
GET 也可以有 body
我们也可以针对二进制数据进行 URL encode , 就可以把数据通过 URL 来传递了.
其他方法
PUT 与 POST 相似,只是具有幂等特性,一般用于更新
DELETE 删除服务器指定资源
OPTIONS 返回服务器所支持的请求方法
HEAD 类似于GET,只不过响应体不返回,只返回响应头
TRACE 回显服务器端收到的请求,测试的时候会用到这个
CONNECT 预留,暂无使用
了解即可.
具体这个方法是干啥的,完全取决于程序猿代码怎么写.
不要拘泥于 HTTP 中最初的语义.



认识请求 "报头" (header)
请求的报头里面的键值对是有很多的.
这里的键值对有些是标准规定的,具有特定含义.
有些是用户自定义的.
只介绍一些典型的,其他的如果需要,自行研究.
Host
描述了主机的地址/端口号
地址可以是域名,也可以是IP
Host 这个东西,其实是和 URL 中表示的信息是重叠的.一般来说 Host 中的内容和 URL 中的地址是一致的.但是也不绝对.
Content-Length
表示 body 中的数据长度.单位是字节
如果没有 body(GET),此时就可以没有这个 Content-length
Content-Type
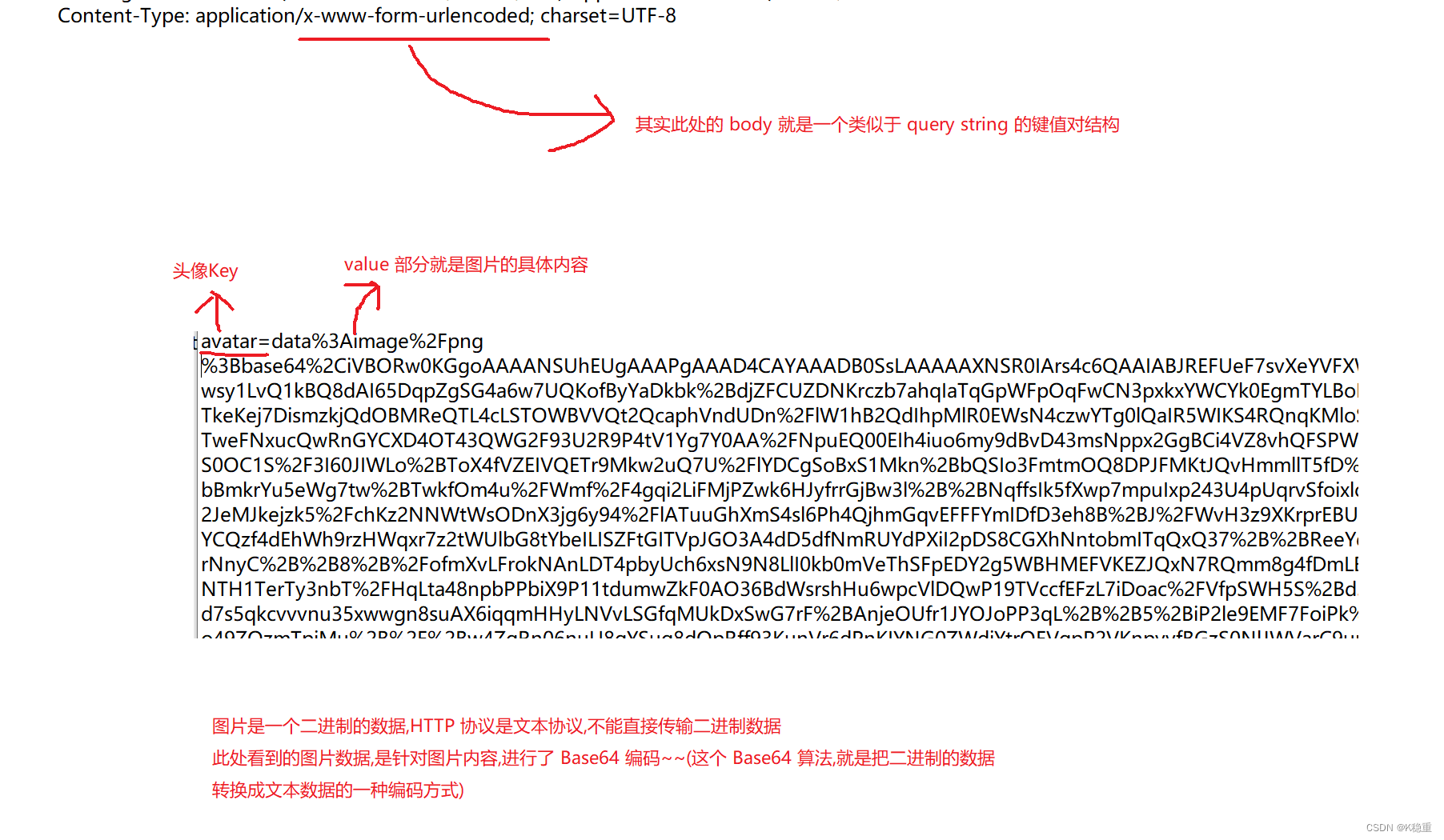
表示 body 中的数据格式的类型:
1.application/x-www-form-urlencoded: form 表单提交的数据格式.此时 body 的格式形如:
这种格式和 query string 是差不多的
表单就是 HTML 中的 form 标签.
包括 input texttarea 这些标签都是可以搭配 form 来使用.
form 效果就是和服务器进行交互,就能构造出 GET/POST 请求
2.multipart/form-data:
上传文件的时候,会涉及到这种格式.
3.application/json: body 按照 json 来组织.
请求中的 bady 的格式和响应中的 bady 的格式还不一样
User-Agent (简称 UA)
这是一个非常重要的字段
上古时代,那个时候的浏览器还是比较简单.最早的浏览器,只能显示文字~~不能显示图片,更不能支持各种多媒体.
随着时间的推移,就出现了一些浏览器,能显示图片.
又出现了一些浏览器,能显示多媒体
再出现一些浏览器,能够支持更丰富的交互(支持 JS 支持 flash....)
浏览器的升级是逐渐的过程.
同一时期,既存在这种只能显示文字的浏览器,又存在能显示图片的浏览器,还存在能显示多媒体的浏览器....
这对于我们的网站开发者来说,是个脑瓜子嗡嗡的问题.
于是聪明的程序猿就想到了两全其美的办法!!让浏览器访问网站的时候,自报家门!!(告诉服务器,我是哪个哪个浏览器的哪个版本)
服务器这边就知道了这个浏览器支持哪些功能,根据对方浏览器的不同买来决定返回一个啥样的页面.
随着时间的推移,到了现在,现代的浏览器,已经差别就不大了(尤其是 IE 被淘汰处理室舞台之后 )
此时 UA 已经失去了一个新的使命!!
可以用来区分,PC端还是移动端!!!
同一个网站,用 PC 和 手机 分别访问,看到的网页排版,可能不一样!!!
PC 和 手机 屏幕尺寸差别很大.
接下来这里如何进行区分呢?
其中一种办法,就是统计请求的 UA.
PC上的 UA 和 手机的 UA 是不一样的!!
手机要么是安卓(Android),要么是苹果(IOS).
同样是苹果系统,PC和手机是不一样的!!
PC 是 MAC 系统
ihpone 这边就叫 IOS
通过 UA 区分出手机还是电脑,来返回不同版式的页面,这是一种实现方式.这个方式劣势就是程序猿得维护两个版本的代码,(实际开发中这种做法挺少见的.UA 更多的是用来统计用户)
更主流的方式叫做"响应式布局".基于 CSS3 中的 "媒体查询"功能.媒体查询功能大概就是能够获取当前页面的宽度,根据宽度来决定样式,从而达到一份代码,适应多种不同宽度的屏幕.
手机的浏览器,很多都支持"模拟 UA ",你可以切换 UA 为其他的值....就能够在手机上看到和 PC 端类似的网页`
Referer
表示当前这个页面是从哪来的(从哪个页面跳转过来的)
如果直接在浏览器中输入URL, 或者直接通过收藏夹访问页面时是没有 Referer 的.
通过搜索主页,跳转到搜索结果页就是带有 Referer
每个 HTTP 请求的 Referer 就是上个跳转之前的页面.
Referer还是非常非常有用的.
还有一个关键的事情.
某个广告主,他同时在多个平台上投放了广告.
广告主就要按照 Referer 来统计,并进行结算.
是否有可能有人把这个 Referer 给改了,从而导致广告主,统计错误?
完全有可能!!! 而且也完全有动机!!! 最有可能的就是 运营商!!!(电信,移动,联通)
HTTP 完全是明文,运营商又掌握了网络传输的基础设备.
这个时候就完全可以把本来是搜狗的流量,把 Referer 一改,改成自己的流量.(运营商也是有自己的广告平台的)
这就叫做流量劫持,这件事在 2014 年左右的时候,非常多!!!
显然,这种情况非常不合理,而且,还犯法!!!
上法院,告!!告肯定能赢,但是可能会"赢了官司,输了买卖" 当官司打赢了之后,已经过了好几年了,损了多少钱都不计其数了.大厂都有专门的服务团队,来搞这些事情.
因此当时各种广告平台都做了一件事,升级了 HTTPS(2015 年左右的)
Cookie
这个是 HTTP 请求报头中最难理解的一个字段.
Cookie 的值是一个字符串(程序猿自己定义的字符串).
Cooike 相当于浏览器这边进行本地存储的一种机制.
比如程序猿想让浏览器这边存一些信息,就可以使用 Cookie.
Cookie 还有一个特点, Cookie 能够在后续请求服务器的时候,自动的把之前保存的值给带上.
现在的浏览器,有很多的本地存储机制了.
现在网站也不完全依赖 Cookie .
1.LocalStorage: HTML5 开始引入的的一个机制.浏览器支持一种 "键值对" 方式来进行存储.通过 JS 提供了一组 API.来操作数据.这里保存的数据就会持久的存储下去.
2.IndexD8: 比较新的浏览器才支持的机制.浏览器内部集成了一个 "数据库" 支持类似于 SQL 的方式来进行操作数据.





认识请求 "正文" (body)
为啥都喜欢用 HTTP?
主要是因为 HTTP 扩展性太好了.非常方便程序猿基于这个协议来传输自定义的数据.
1. URL 中的路径
2. URL 中的 query string
3. header 中可以自定义键值对.
4. body中也可以自定义数据.
body 中放啥格式的数据都行.
但是有几种格式是比较常见的:
1.application/x-www-form-urlencoded
2.multipart/form-data
主要是用来上传文件
3.application/json
json 是一种非常常用的数据组织的格式, 学 JS 的时候,也就涉及过.(JS 中的对象,其实就是 JOSN 格式的前身)
JSON 火起来之前,大家主要是使用 XML 这样的格式来组织数据 ( XML,前面也写过,是非常啰嗦的)


HTTP 响应详解
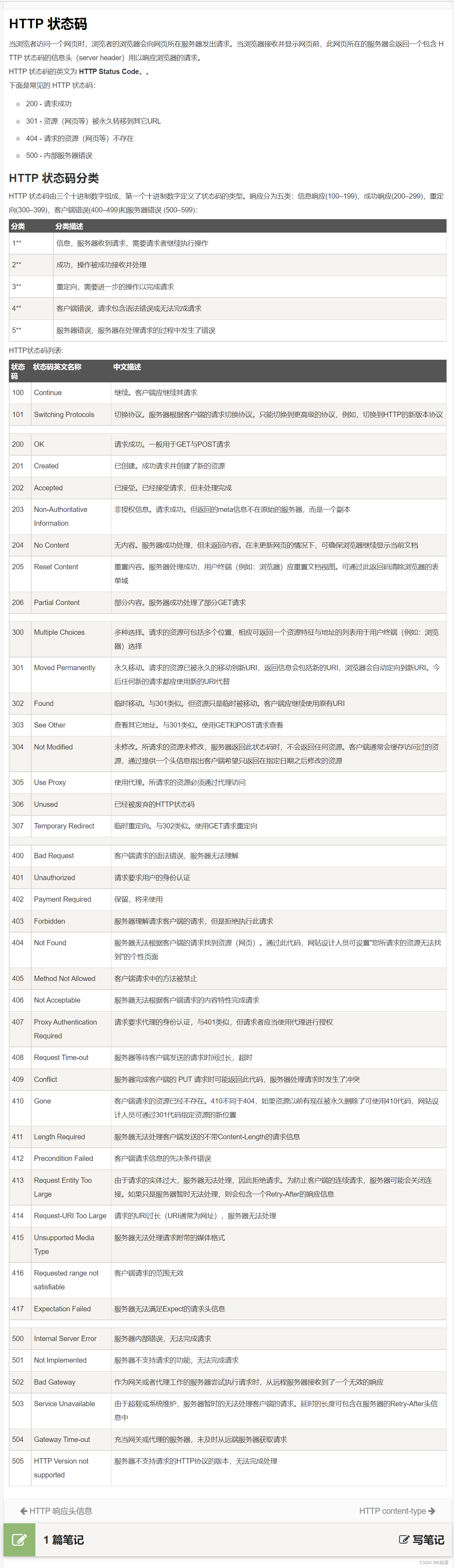
认识 "状态码" (status code)
状态码.表示了这次请求的"结果"
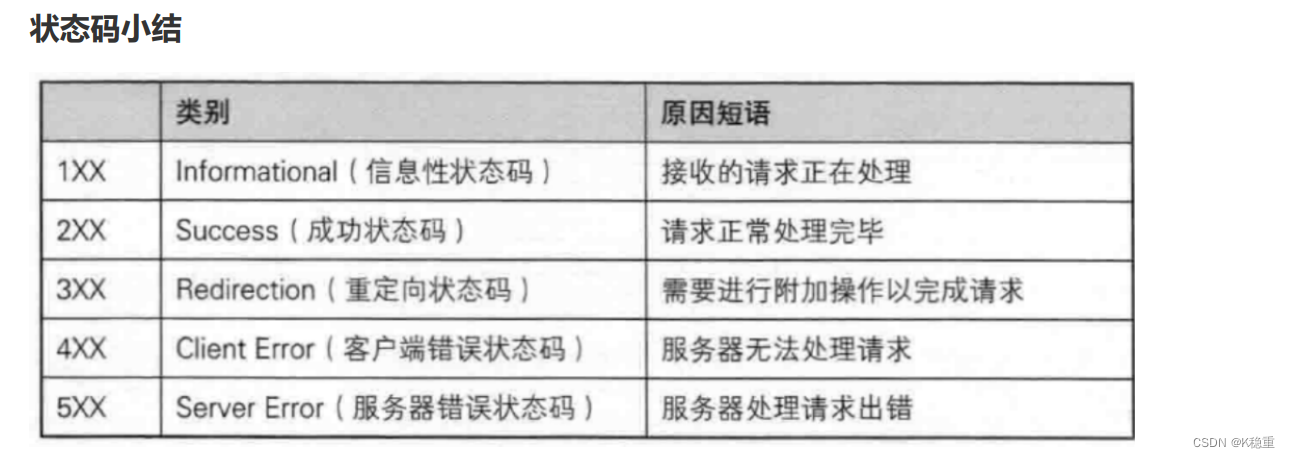
HTTP 中的状态码有很多
HTTP 中的状态码有很多~~不需要一一背下来,只需要认识几个常见的就可以了
以下为常见的状态码:
200 OK
表示访问成功
404 Not Found
表示没找到资源
每个请求都带有一个 URL ,URL 里面都有一个路径 /index.html 这种.
这就表示这次请求想要的资源是啥~~
如果要请求的资源人家服务器没有.就会出现 404 Not Found
有些网站 404 页面会做的比较好看一点.
403 Forbidden
表示访问被拒绝
一般来说因为没有权限所以被拒绝.
举例:
很多地方都涉及到用户名和密码校验过程.
一般这种密码错误之类的情况,错误提示一般是 forbidden,或者叫做 access denied
405 Method Not Allowed(后续再说)
表示这个方法服务器不支持
500 Internal Server Error
表示服务器挂了
在网络上这种情况非常常见.
尤其是在自己开发的时候,初学 Servlet / String 的时候,500就常伴左右.
像比较好的公司,做的都很好,很少会见到 500.
504 Gateway Timeout
当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的 情况.
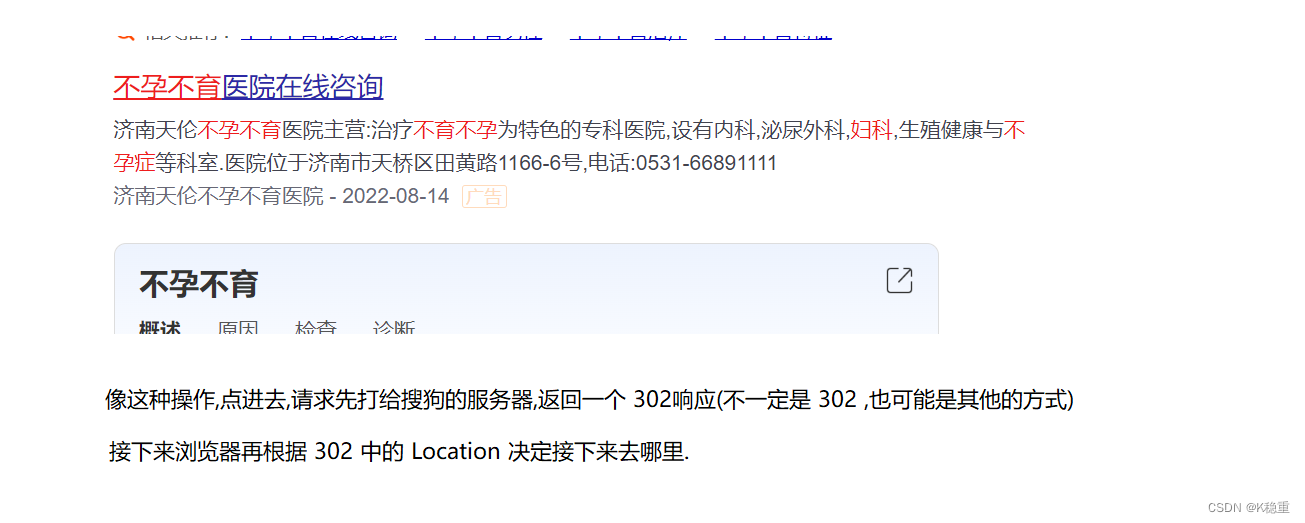
302 Move temporarily
临时重定向
重定向,是一个非常常见的计算机术语(结合上下文,不同的语境下面重定向指的意思是不一样的,当前的重定向特指的是 HTTP 协议中的重定向).
类似于 " 呼叫转移"
别人呼叫旧的号码,自动跳转接到新号码上.
别人访问旧的页面自动的跳转到新的页面.
这个就叫重定向.
像典型的 跳转/登录
Location 就表示接下来要跳转到哪个地址上
浏览器就会根据 Location 中记录的 URL ,立即访问 这个 URL
对于 302 这样的重定向响应来说,body 不是必须的.
这里的 body 就是一个简单的 html. 里面就只有一个a标签.
万一浏览器没有自动跳转,那么用户手动点击这个 a 标签也可以跳转.(用户的浏览器千差万别,有的浏览器(比较旧的浏览器) 不一定能跳转.)
301 Moved Permanently
永久重定向
意思就是说你第一次访问,301 和 302 都没啥区别.
但是后续在访问的时候,因为 302 是临时重定向,所以浏览器后续再访问,还是会重新访问旧的地址,但是如果是 301 的话,就会记住之前的访问结果,再访问就会直接访问新的地址.
1开头表示什么,2开头表示什么.......
一个经典面试题:
说一下 HTTP 协议中常见的状态码和含义~~
就是上述的内容.
注意这个问题的回答方式:
第一种:200, 404, 302 具体的状态码的含义
第二种:2xx, 3xx, 4xx 每一类的含义.
先回答1好,还是先回答2好,一定要先说第一种.


认识响应 "报头" (header)
响应报头的基本格式和请求报头的格式基本一致.
类似于 Content-Type , Content-Length 等属性的含义也和请求中的含义一致.
Content-Type
响应中的 Content-Type 常见取值有以下几种:
text/html : body 数据格式是 HTML
text/css : body 数据格式是 CSS
application/javascript : body 数据格式是 JavaScript
application/json : body 数据格式是 JSO
认识响应 "正文" (body)
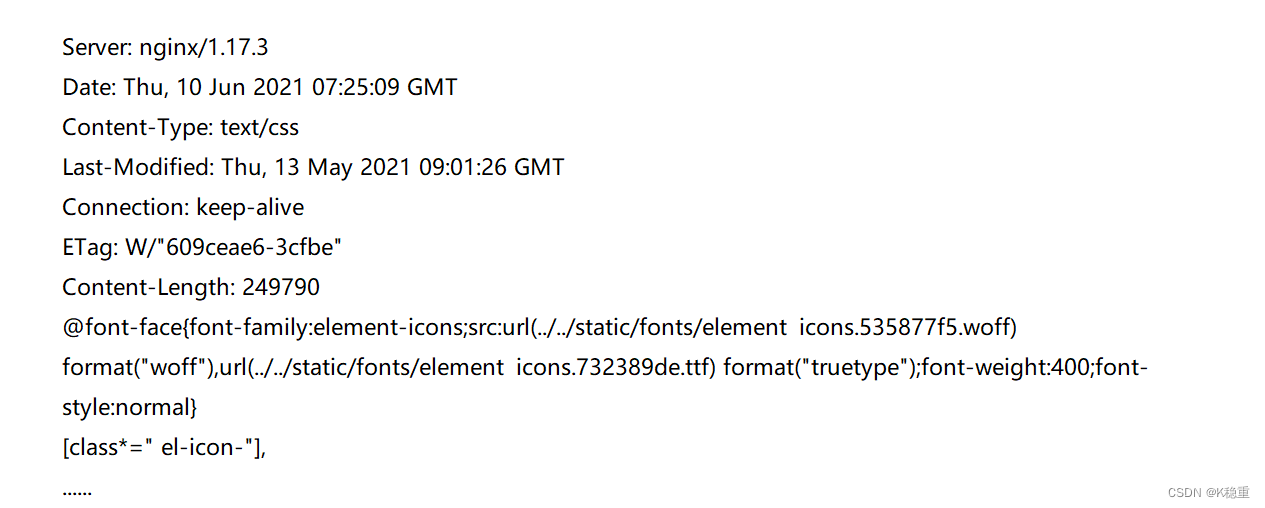
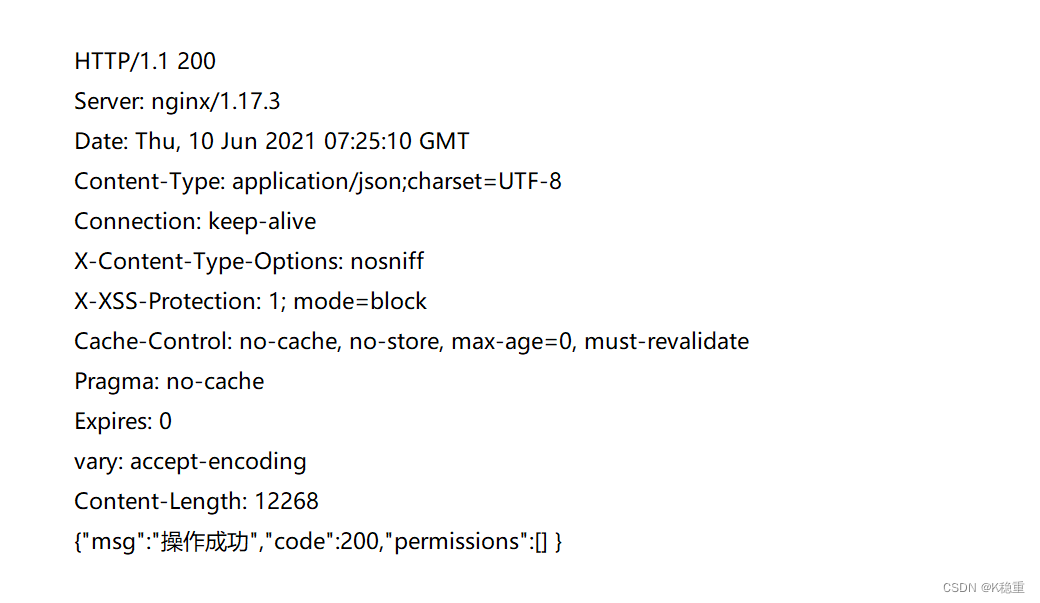
正文的具体格式取决于 Content-Type. 观察上面几个抓包结果中的响应部分
text/html
text/css
application/javascript
application/json


通过 form 表单构造 HTTP 请求
如何使用代码来构造 HTTP 请求.
在网页前端这里,构造 HTTP 请求,主要是 3 种方式.
1.直接在浏览器中输入 URL (构造了一个 GET)
2.使用 from 表单(可以构造 GET 和 POST)
3.使用 ajax. (可以构造各种请求)
也可以通过 Java 代码,基于其中的 Socket 来构造一个 HTTP 请求.
(任何能够访问网络的语言,都可以构造 HTTP 请求,字符串拼接)
form 表单构造 HTML 请求
我们是希望能够把用户输入的内容提交的服务器上
保存,打开浏览器
输入内容
点击提交
此时就跳转到百度的页面了
此时我们开一下抓包结果
打开

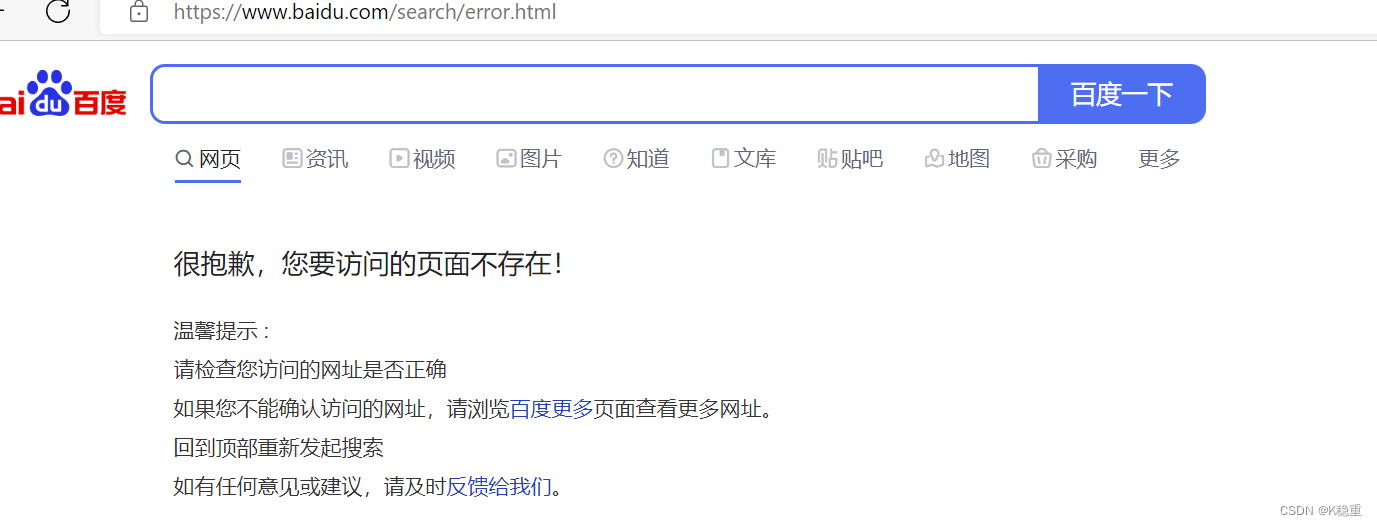
当前直接给百度提交请求,报读报错了.
很正常,毕竟百度没有支持像 userId,classId 这样的一些参数....
要想能够正确提交请求,就需要服务器进行配合.
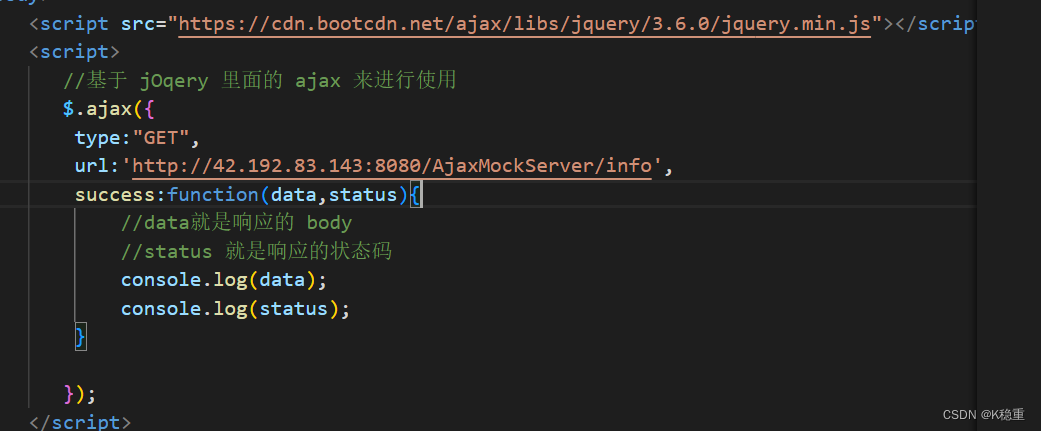
ajax构造请求. (可以构造各种请求)
在 JS 的原生代码中,就提供了 ajax 这样的功能
ajax 这个原生方法,其实是比较麻烦的.
此处更推荐第三方库,封装好的 ajax 方法来使用.
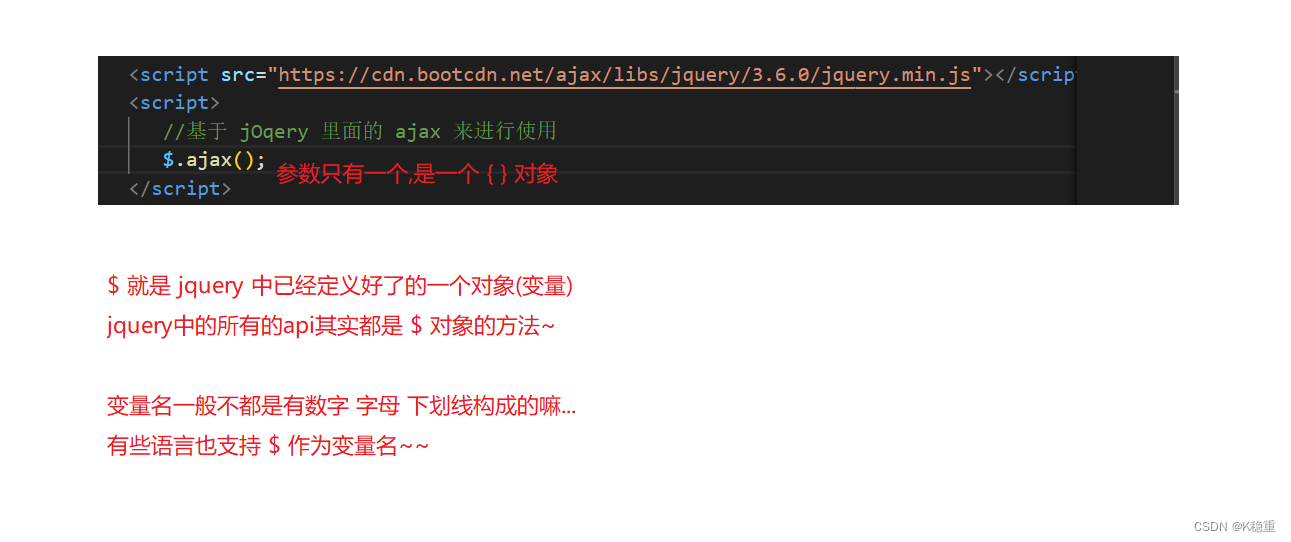
jQuery:这个是 JavaScript 中最知名,最广泛使用的第三方库之一.
jQuery 其实是一个功能很全面的库, 对 DOM API 进行了非常好的封装.
咱们就只介绍一下 jQuery 中的 ajax
JS 中如何安装引入第三方库?
在Java,可以使用 Maven, 从中央仓库下载
在 JS 世界中,也有类似的 东西, npm.(处理第三方库之间的依赖)
但是还有更简单的办法. JS 代码都是在服务器这边,被浏览器下载到本地之后,才执行的
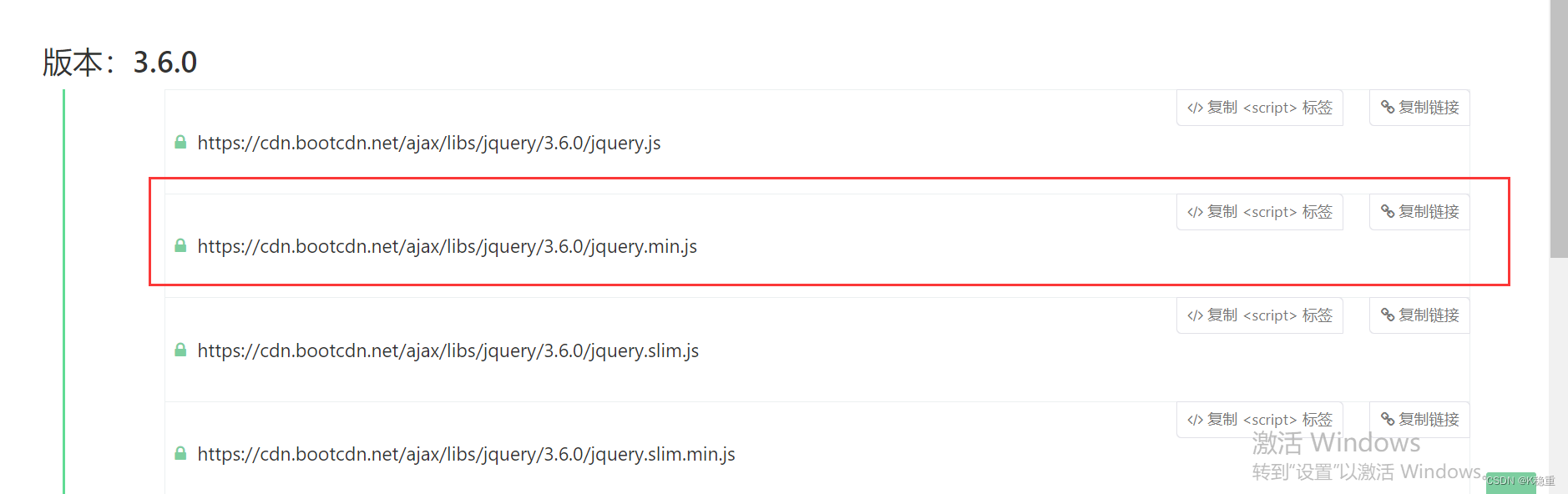
只要在网页代码中,引入 jquery 所在的网络地址,就能直接使用.
直接复制这个地址浏览器打开
这样就引入完了
在浏览器页面加载中,是可以同时发起多个 ajax 请求的.
此时这多个 ajax 请求相当于是一个并发执行的关系.
(和 Java 相比, JS 对于并发编程的支持是非常有限的)
在当前的网站开发中, ajax 是一种非常非常常用的方式.
1
ajax 中的"跨域" 问题
ajax 为了保证安全性,要求 ajax 请求的页面,和接收 ajax 请求的服务器,应该在通一个域名/地址下.
如果,发起请求的页面对应的域名(域名1),和 接收 ajax 请求的服务器的域名(域名2),如果域名 1和域名2 不相同就认为是一次跨域请求.





通过 Java socket 构造 HTTP 请求
HTTP 请求也是基于 TCP .
只不过就是在 TCP 的基础之上,按照 HTTP 约定的格式,构造一个字符串,并发送出去,即可.
核心就是"拼接字符串"
其他的应用层协议,也是如此.(也就是一个拼装字符串和解析字符串的过程)
HTTPS
HTTPS 是什么
2022年,大部分的网站,基本都是 HTTPS 浏览器也要求如果你不是 HTTPS 就会有一些提示.
HTTPS 是要比 HTTP 更安全的.
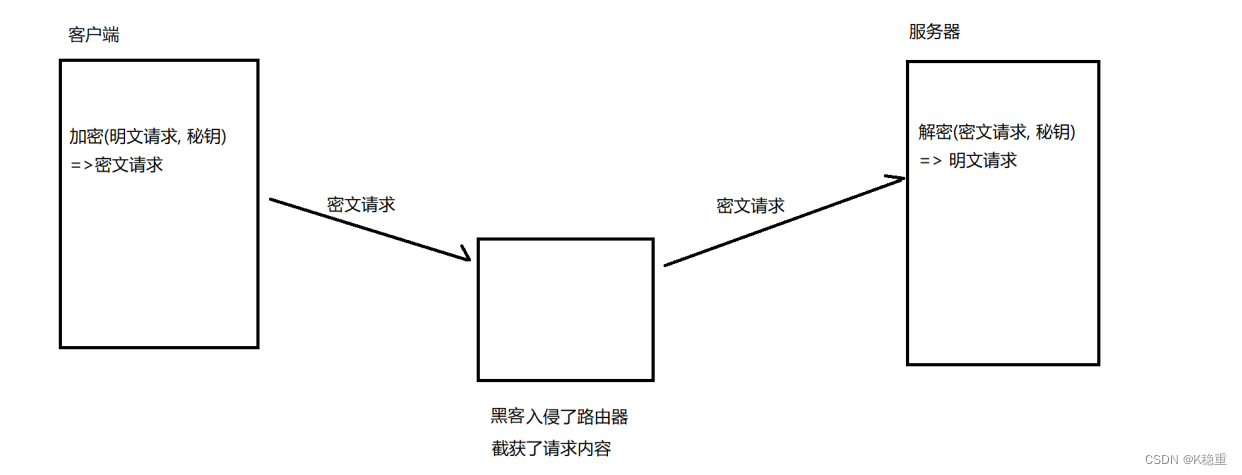
HTTP 是一个明文传输的协议~~
本来要传的是啥,实际就是啥.
一旦传输过程中,数据被第三方获取到了,可能就会造成一些重要信息的泄露.
HTTPS 就是在 HTTP 的基础之上,引入了一个 加密层(SSL/TLS)
加密是什么
明文:真正要传输的消息
密文:指的就是加密之后的消息
举例:
83 版 > , 有人要谋反干掉慈禧太后. 恭亲王奕䜣给慈禧递的折子. 折子内容只是扯 一扯家常, 套上一张挖了洞的纸就能看到真实要表达的意思. 明文: "当心肃顺, 端华, 戴恒" (这几个人都是当时的权臣, 后来被慈禧一锅端). 密文: 奏折全文
明文 => 密文 称为 "加密"
密文 => 明文 称为 "解密"
带窟窿的纸 对于加密和解密都至关重要.
称为密钥(yue 四声)
HTTPS的工作过程:
既然要保证数据安全, 就需要进行 "加密".
网络传输中不再直接传输明文了, 而是加密之后的 "密文".
加密的方式有很多, 但是整体可以分成两大类: 对称加密 和 非对称加密
对称加密:
加密: 明文 -> 密文 使用一个密钥
解密: 密文 -> 明文 使用用一个密钥
非对称加密:
加密: 明文 -> 密文 使用密钥1
解密: 密文 -> 明文 使用密钥2
密钥1 和密钥2 是不同的密钥(虽然这里密钥不同,但是存在关联关系的,这两个密钥是成对出现的.可以使用密钥1 加密,使用 密钥2 解密.也可以使用密钥2加密,使用密钥1 解密.)
通常会把其中的一个密钥给公开出去,别人就可以使用这个密钥来加密了.
自己留下另一个密钥,用来解密.
把公开出去的密钥称为"公钥"
把自己保留的密钥称为"私钥"
这里的公钥和私钥,就可以想象成现实生活中的信箱.
公钥就像信箱上的锁.
私钥就像这把锁的钥匙.
举例:
我给这几个熟悉的邮差每人发一把锁,钥匙我自己留着.
本来我的信箱是没有锁的.
邮差把信送过来之后,放到信信箱里,他就锁上了
我自己拿着钥匙下楼,才能打开这个信箱
进行加密操作,
首先我们能想到的加密方式,就是对称加密,对HTTP中传输的数据进行加密.
引入对称加密之后, 即使数据被截获, 由于黑客不知道密钥是啥, 因此就无法进行解密, 也就不知道请求的 真实内容是啥了.
但事情没这么简单. 服务器同一时刻其实是给很多客户端提供服务的. 这么多客户端, 每个人用的秘钥都 必须是不同的(如果是相同那密钥就太容易扩散了, 黑客就也能拿到了). 因此服务器就需要维护每个客户 端和每个密钥之间的关联关系, 这也是个很麻烦的事情
比较理想的做法, 就是能在客户端和服务器建立连接的时候, 双方协商确定这次的密钥是啥
但是如果直接把密钥明文传输, 那么黑客也就能获得密钥了~~ 此时后续的加密操作就形同虚设了.
能不能让客户端和服务器同时生成一样的密钥?
(办法也不是完全没有)
好比网银,在2010年左右的时候,当时在淘宝买东西,支付的方式还是支付宝 + 网银 + 手机充值卡.
去银行开通网银,会送一个U盾,有两种,一种是像一个 U 盘,插到电脑上的(硬件加密)
另一种,不用插电脑,上面带一个小窗口,还有个按钮.窗口上显示一个随机的6位数字(临时的密钥).
正确的手段,是针对这个对称密钥,进行加密.
所以就需要非对称加密来对对称密钥进行加密.
一个网站,生成一对公钥和私钥.
把公钥给公开出去,自己保留私钥.
客户端就先拿这个网站的公钥来对自己的 对称密钥 进行加密
然后传输密文给服务器,服务器拿私钥解密,也就得到了密钥的明文.
只要有了密钥,后续就可以直接使用对称加密来进行传输了.
对称加密,成本是比较低(机器资源消耗少),速度也是很快的
非对称加密,成本比对称加密高很多(机器资源消耗的多),速度也慢.
通过刚才这样的手段,确实可以更安全的进行数据传输.
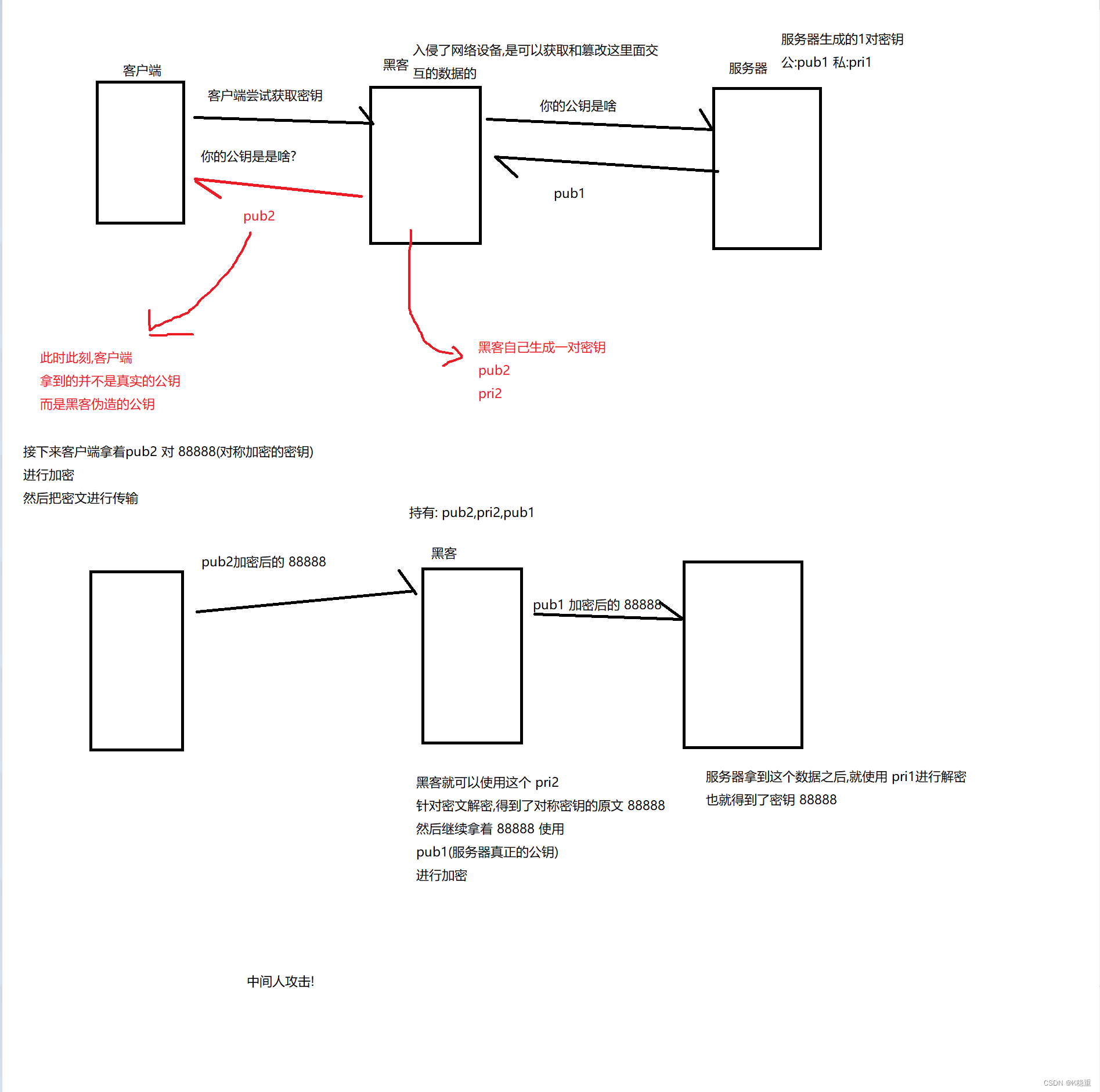
但是还是有点问题,客户端,是如何获取到公钥的
如何保证客户端获取到的公钥是真实可靠的,而不是黑客伪造的
任何人都可以生成一对 公钥和私钥. 网站服务器能生产,黑客也能一样能生成.
黑客就想到了一招,狸猫换太子
通过证书,来反制黑客伪造公钥这个事情
客户端和服务器连接的时候,客户端不是简单的索要公钥了,而是直接索要一个"证书"
公钥就包含在这个证书里面 .
然后客户端拿到证书之后,就可以根据这个证书中提供的信息,去第三方机构进行认证,来校验证书是否合法.证书如果合法,就可以新人其中公钥!!!
服务器开发者在搭建服务器的时候要去第三方机构来进行认证.申请证书.
小结:
HTTPS 传输过程
1.客户端先从服务器获取证书,证书中包含了公钥.
2.客户端对证书进行校验
3.客户端生成了一个对称密钥,使用公钥对对称密钥进行加密,发送给服务器.
4,服务器得到这个请求之后,使用私钥解密,得到堆成密钥.
5.客户端发出后续的请求,后续的请求都是使用这个对称密钥加密的.
6.收到的数据也都是使用这个堆成密钥解密的
这个过程其实描述的是 SSL/TLS的握手过程!!
但凡使用了 SSL/TLS 的协议/工具/组件,都是类似的握手过程
Tomcat
Tomcat 是什么
Tomcat 是一个 HTTP 服务器.
HTTP 协议,是用来前后端沟通的重要协议.
这里面就是涉及到
HTTP 客户端: 浏览器/可以通过代码来自己实现一个客户端
HTTP 服务器: 可以基于代码来自己实现一个服务器/也可以使用现有的服务器( Tomcat 就是最流行的一款现成的服务器)
能不能自己写一个 HTTP 服务器?
完全可以,基于 Socket API 来实现一套
下载安装
使用 8 就可以.
Tomcat 的版本不是随便来选的.
Servlet 的版本需要和 Tomcat 的版本配套.
现在使用 Toncat 8,后面 Servlet 使用版本 3.1.
Tomcat 是一个跑在 Java 上的程序.安装好 Tomcat 之前,一定要先安装好 JDK.
Tomcat 相当于是绿色软件,解压缩,直接就能使用.
Tomcat 本身也是跨平台的
下载好了之后解压缩到自己喜欢的目录
然后稍微介绍一下里面的内容
bin 里面还需要我们关注的东西:
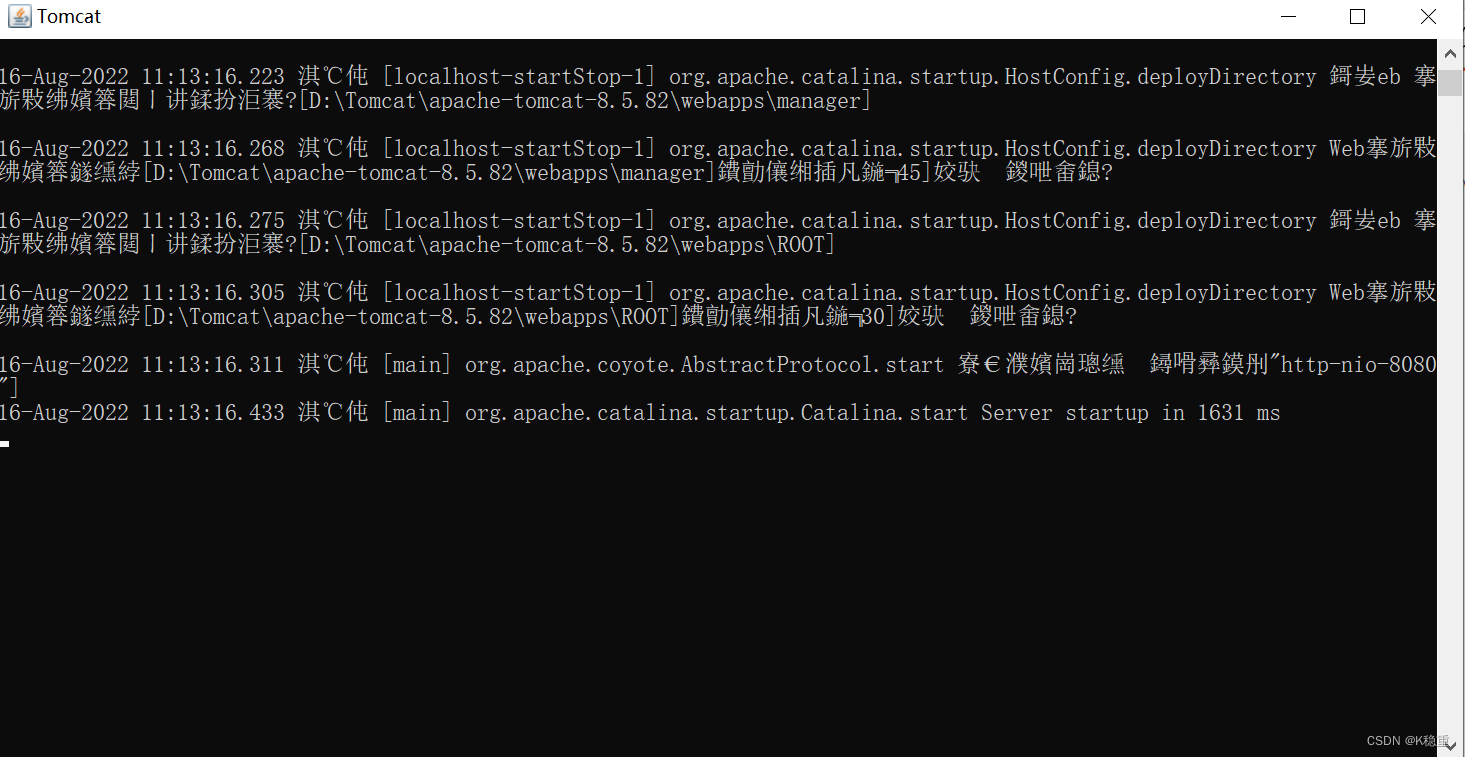
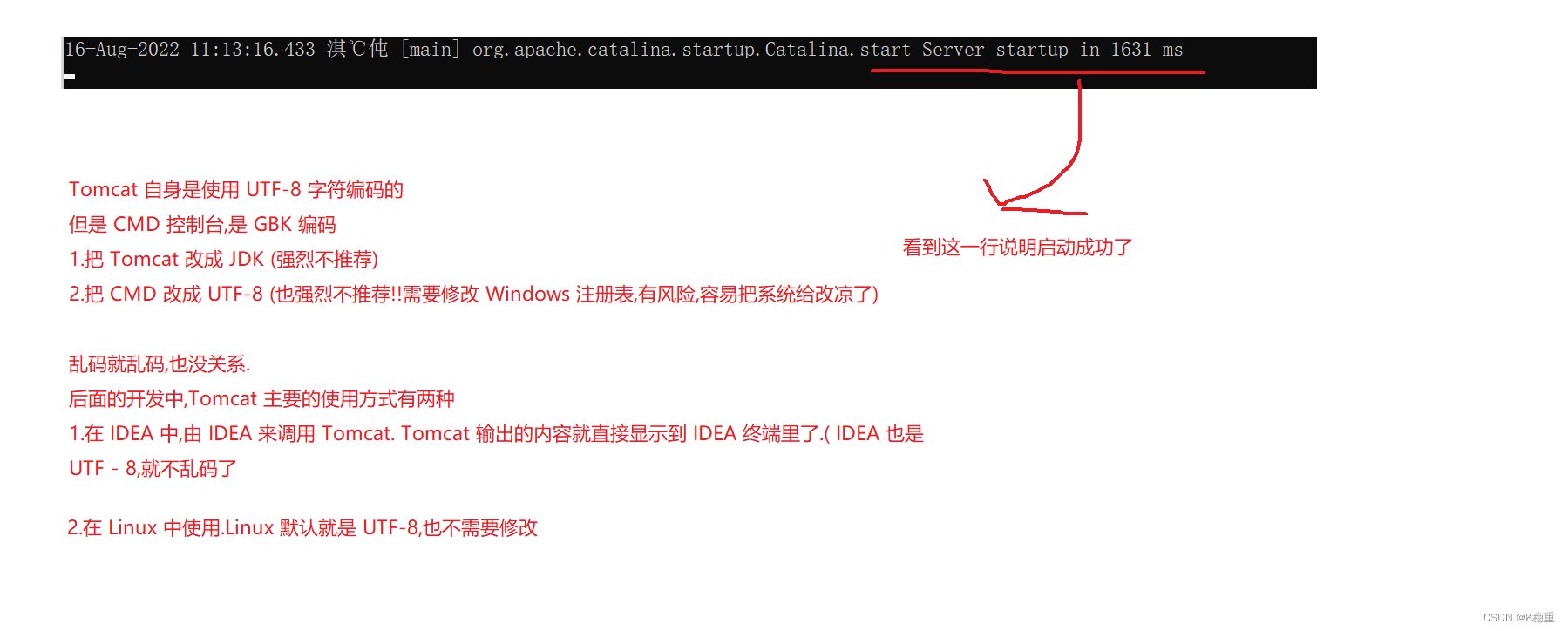
然后我们双击 start.bat就可以打开我们的汤姆猫了,打开之后是这样的一个界面
启动成功之后就可以去访问 Tomcat 的欢迎页面
浏览器里面输入一个新的 ip 地址 127.0.0.1:8080/index.html
使用 Tomcat 主要的目的是为了能够部署一个 webapp(网站)
一个网站里面的内容,可以分成两类
1.静态页面(纯前端的代码,不需要服务器生成数据)
2.动态页面(前后端搭配的代码.需要服务器生成数据)
对于静态页面的部署,只需要把页面给赋值到 webapps 目录中即可.
部署到 Tomcat,可以看到页面内容.是通过一个 URL ,通过网络来访问的.别人电脑上部署的 HTML,咱们也能访问.(尤其是 Tomcat在云服务器上,这个时候,部署上去的 HTML 就可以被所有人来访问了)
直接双击 html 文件,也能看到页面内容 相当于使用浏览器打开一个本地文件.如果这个文件是在别人的电脑上,就无法访问了.
一个真实的页面,不仅仅包含 html,还会包含一些 CSS, JS, 图片.....
部署页面,不仅仅是可以放到 ROOT 中,也可以在 webapps 这个目录中给当前的页面创建一个单独的目录.


















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











