







1.介绍
Playwright 是一个用于自动化浏览器操作的开源工具,由 Microsoft 开发和维护。它支持多种浏览器(包括 Chromium、Firefox 和 WebKit)和多种编程语言(如 Python、JavaScript 和 C#),可以用于测试、爬虫、自动化任务等场景。
与 Selenium 和 pyppeteer 相比,Playwright 具有以下几个区别和优势:
多浏览器支持:支持所有主流浏览器。这使得开发人员可以根据需求选择最适合的浏览器进行自动化操作。(Playwright不支持旧版Microsoft Edge或IE11)
更快的执行速度:Playwright 通过使用浏览器的底层调试协议来进行操作,相比于 Selenium 和 pyppeteer,它具有更快的执行速度和更低的资源消耗。
可靠性和稳定性:Playwright 提供了更可靠和稳定的浏览器自动化操作,通过使用浏览器的原生 API 来模拟用户行为,避免了一些传统自动化工具的一些限制和不稳定性。
支持跨浏览器和跨平台:Playwright 可以在不同浏览器和不同操作系统上运行,这使得开发人员可以更方便地进行跨浏览器和跨平台的测试和自动化操作。
selenium是基于http协议,而Playwright是基于websocket协议。由于使用 HTTP 协议,Selenium 的性能相对较低。每次与浏览器进行通信时,都需要发送 HTTP 请求和等待响应。而Playwright使用 WebSocket 协议,Playwright 的性能会更高。WebSocket 的双向通信使得数据交换更高效,可以更快地获取页面内容和执行操作。
支持屏幕录制功能:根据屏幕录制指定生成相关操作代码(不推荐使用,看似是高大上的功能,其实是鸡肋)
在爬虫中使用 Playwright 的好处包括:
动态网页爬取:Playwright 可以模拟用户在浏览器中的操作,包括渲染 JavaScript、点击按钮、填写表单等,从而可以爬取包含动态内容的网页。
多浏览器支持:Playwright 支持多种浏览器,可以根据需求选择最适合的浏览器进行爬取,以确保爬取结果的准确性和一致性。
更高的稳定性和可靠性:Playwright 使用浏览器的原生 API 进行操作,避免了一些传统爬虫工具的一些限制和不稳定性,提供了更可靠和稳定的爬取能力。
总之,Playwright 是一个功能强大、跨浏览器、跨平台的浏览器自动化工具,相比于 Selenium 和 pyppeteer,它具有更快的执行速度、更高的稳定性和更广泛的浏览器支持,适用于多种自动化操作和爬虫场景。
python版本的Playwright官网文档:Installation | Playwright Python
跟爬虫最相关强大的功能,通过Playwright获取cookies绕过安全产品反爬(如:加速乐,瑞数,Akaman)也可以通过模拟登录获取cookies(这里模拟登录不包括屏幕录制)
2.环境安装
python版本:Python 3.8 或更高版本
安装playwright的python版本:pip install playwright
安装Playwright所需的所有工具插件和所支持的浏览器
playwright install(该步骤耗时较长)
3.屏幕录制
创建一个py文件,比如:main.py在终端中,执行如下指令:playwright codegen -o main.py可以通过如下设置,生成同步还是异步的代码:将屏幕录制生成的代码保存到main.py文件中。
效果如下:
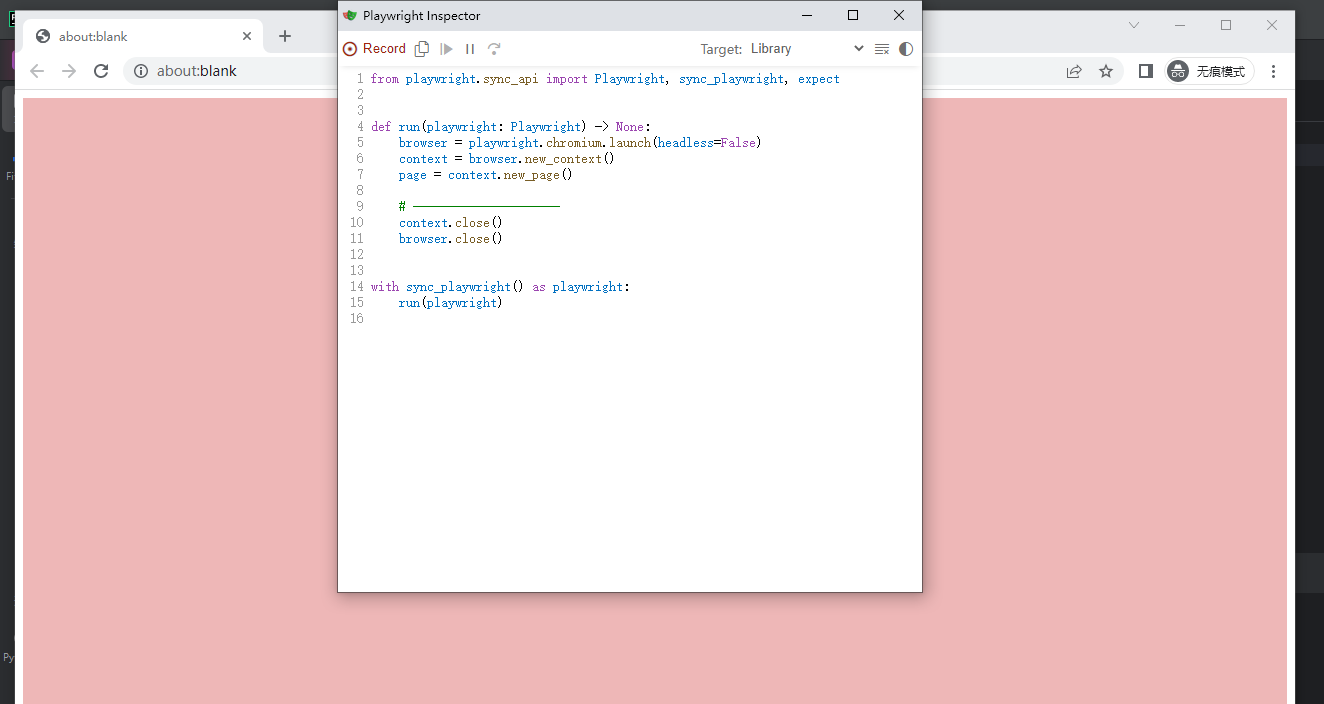
可以在这里设置异步代码还是同步代码
以这个模拟登录为例
录制你的行为动作
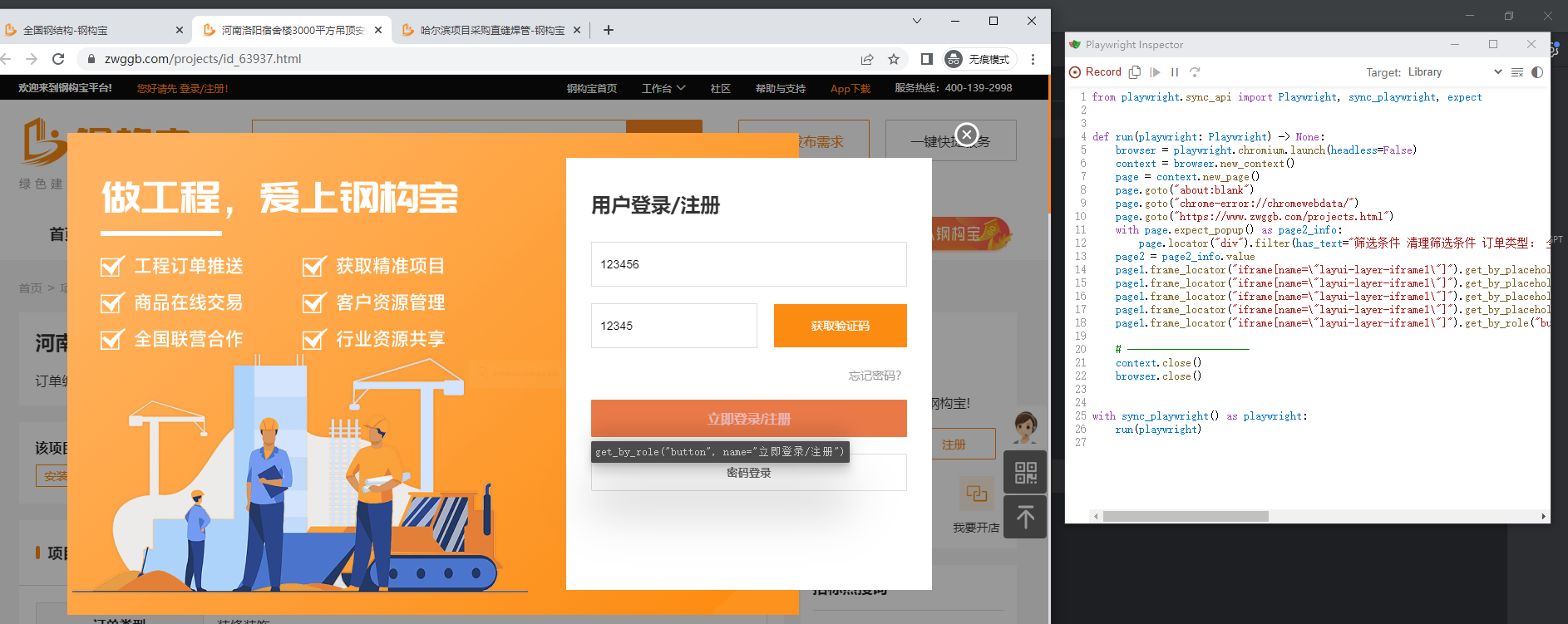 录制成功返回的代码
录制成功返回的代码
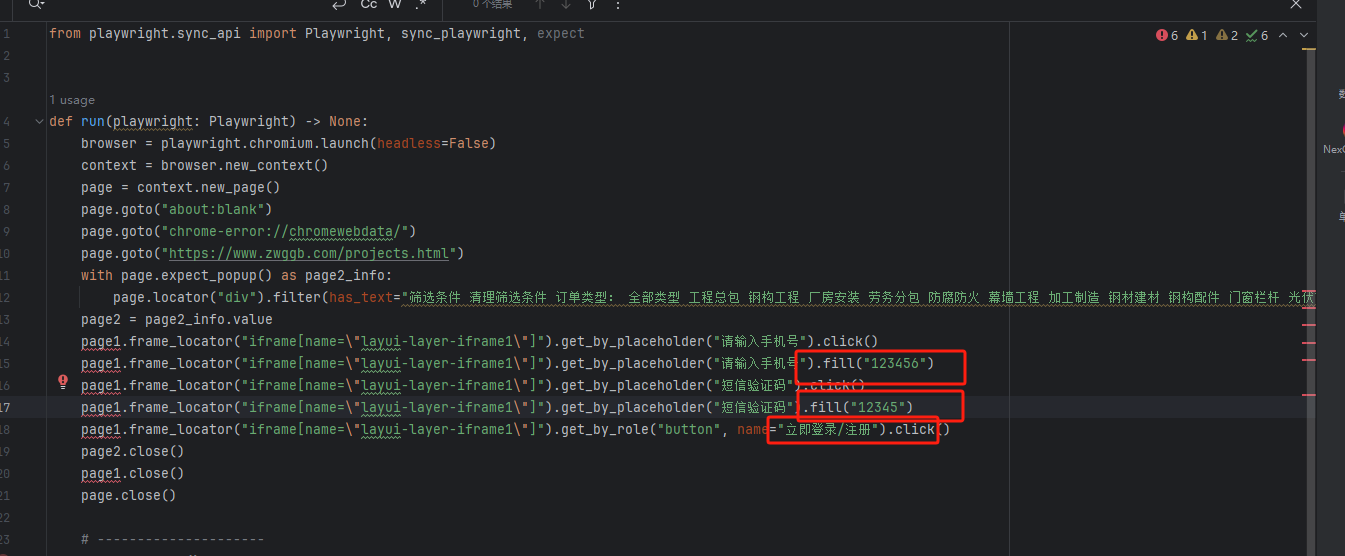 这个登录没有验证码,比较简单,有验证码就用不了录制功能,还有一些操作等等。
这个登录没有验证码,比较简单,有验证码就用不了录制功能,还有一些操作等等。
同时屏幕录制也支持手机端
playwright codegen --device="iPhone 13" -o main.py
支持的手机移动端设备如下
"Blackberry PlayBook", "Blackberry PlayBook landscape", "BlackBerry Z30", "BlackBerry Z30 landscape", "Galaxy Note 3", "Galaxy Note 3 landscape", "Galaxy Note II", "Galaxy Note II landscape", "Galaxy S III", "Galaxy S III landscape", "Galaxy S5", "Galaxy S5 landscape", "Galaxy S8", "Galaxy S8 landscape", "Galaxy S9+", "Galaxy S9+ landscape", "Galaxy Tab S4", "Galaxy Tab S4 landscape", "iPad (gen 5)", "iPad (gen 5) landscape", "iPad (gen 6)", "iPad (gen 6) landscape", "iPad (gen 7)", "iPad (gen 7) landscape", "iPad Mini", "iPad Mini landscape", "iPad Pro 11", "iPad Pro 11 landscape", "iPhone 6", "iPhone 6 landscape", "iPhone 6 Plus", "iPhone 6 Plus landscape", "iPhone 7", "iPhone 7 landscape", "iPhone 7 Plus", "iPhone 7 Plus landscape", "iPhone 8", "iPhone 8 landscape", "iPhone 8 Plus", "iPhone 8 Plus landscape", "iPhone SE", "iPhone SE landscape", "iPhone X", "iPhone X landscape", "iPhone XR", "iPhone XR landscape", "iPhone 11", "iPhone 11 landscape", "iPhone 11 Pro", "iPhone 11 Pro landscape", "iPhone 11 Pro Max", "iPhone 11 Pro Max landscape", "iPhone 12", "iPhone 12 landscape", "iPhone 12 Pro", "iPhone 12 Pro landscape", "iPhone 12 Pro Max", "iPhone 12 Pro Max landscape", "iPhone 12 Mini", "iPhone 12 Mini landscape", "iPhone 13", "iPhone 13 landscape", "iPhone 13 Pro", "iPhone 13 Pro landscape", "iPhone 13 Pro Max", "iPhone 13 Pro Max landscape", "iPhone 13 Mini", "iPhone 13 Mini landscape", "iPhone 14", "iPhone 14 landscape", "iPhone 14 Plus", "iPhone 14 Plus landscape", "iPhone 14 Pro", "iPhone 14 Pro landscape", "iPhone 14 Pro Max", "iPhone 14 Pro Max landscape", "Kindle Fire HDX", "Kindle Fire HDX landscape", "LG Optimus L70", "LG Optimus L70 landscape", "Microsoft Lumia 550", "Microsoft Lumia 550 landscape", "Microsoft Lumia 950", "Microsoft Lumia 950 landscape", "Nexus 10", "Nexus 10 landscape", "Nexus 4", "Nexus 4 landscape", "Nexus 5", "Nexus 5 landscape", "Nexus 5X", "Nexus 5X landscape", "Nexus 6", "Nexus 6 landscape", "Nexus 6P", "Nexus 6P landscape", "Nexus 7", "Nexus 7 landscape", "Nokia Lumia 520", "Nokia Lumia 520 landscape", "Nokia N9", "Nokia N9 landscape", "Pixel 2", "Pixel 2 landscape", "Pixel 2 XL", "Pixel 2 XL landscape", "Pixel 3", "Pixel 3 landscape", "Pixel 4", "Pixel 4 landscape", "Pixel 4a (5G)", "Pixel 4a (5G) landscape", "Pixel 5", "Pixel 5 landscape", "Pixel 7", "Pixel 7 landscape", "Moto G4", "Moto G4 landscape" 敢兴趣的人可以去试试
4.基本操作
同步操作
from playwright.sync_api import sync_playwright #导入同步模块
#创建一个Playwright的管理器对象
with sync_playwright() as p: # p = sync_playwright()
#基于p创建一个浏览器对象(谷歌浏览器对象)
bro = p.chromium.launch(headless=False)
#创建一个浏览器页面
page = bro.new_page()
#在指定的页面中进行请求发送
page.goto('https://www.baidu.com')
#暂定2s中
page.wait_for_timeout(2000)
#获取访问页面的标题
title = page.title()
#获取页面的页面源码数据(重要=》可见即可得)
page_text = page.content()
print(page_text,title)
page.close()
bro.close()第一步创建管理器
with sync_playwrigth() as p:
第二步基于p创建浏览器对象,关闭无头模式
bro = p.chromium.launch(headless = False)
第三步创建浏览器页面
page = bro.new_page()
第四步请求发送
page.goto('https://www.baidu.com')
暂定2s中(切记不能用tiem.sleep)
page.wait_for_timeout(2000)
获取网页源码
page_text = page.content()
获得网页源码可以对页面数据进行数据提取。
异步操作
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
bro = await p.chromium.launch(headless=False,slow_mo=2000)
page = await bro.new_page()
await page.goto('https://www.baidu.com')
title = await page.title()
content = await page.content()
print(title,content)
await page.close()
await bro.close()
asyncio.run(main())5.元素定位
两种定位方式选择器(建议用Css选择器)
CSS语法结构:
page.locator('#kw')css id定位
page.locator('.s_ipt')css class定位
xpath语法结构:
page.locator('//*[@id="nav-searchform"]/div[1]/input')
page.locator('//*[@id="nav-searchform"]/div[2]')

![]()
page.locator('#kw').fill('Python教程')输入框为填充文本python教程
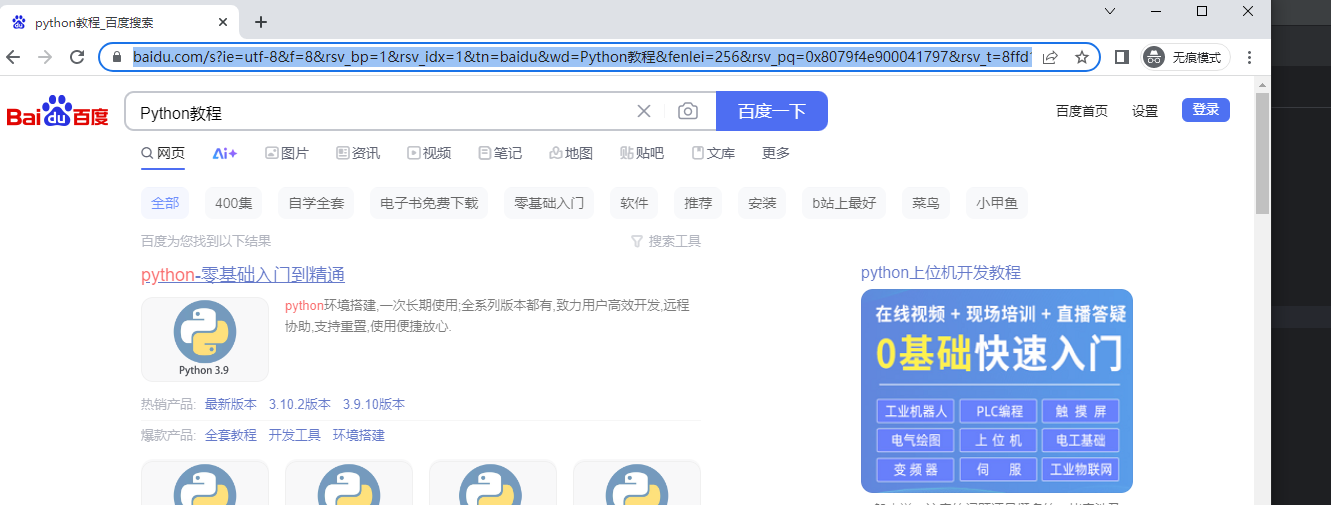
page.go_back()为返回

page.locator('#su').click()
定位id为su的按钮并点击

from playwright.sync_api import sync_playwright
with sync_playwright() as p:
bro = p.chromium.launch(headless=False,slow_mo=2000)
page = bro.new_page()
page.goto('https://www.baidu.com')
#定位到输入框,进行文本录入
page.locator('#kw').fill('Python教程') #id定位
# 定位搜索按钮,进行点击操作
page.locator('#su').click()
#后退操作
page.go_back()
page.locator('.s_ipt').fill('爬虫') # class定位
page.locator('#su').click()
page.go_back()
page.locator('input#kw').fill('人工智能') # 标签+属性定位
page.locator('#su').click()
page.go_back()
page.locator('#form > span > input#kw').fill('数据分析') #层级定位
page.locator('#su').click()
page.close()
bro.close()5.Context上下文
浏览器的上下文管理对象Context可以用于管理Context打开/创建的多个page页面。并且可以创建多个Context对象,那么不同的Context对象打开/创建的page之间是相互隔离的(每个Context上下文都有自己的Cookie、浏览器存储和浏览历史记录)。
from playwright.sync_api import sync_playwright
#点击百度首页中左上角的全部链接,以打开多个不同的page页面
with sync_playwright() as p:
bro = p.chromium.launch(headless=False,slow_mo=1000)
#创建上下文管理对象
context = bro.new_context()
#基于上下文管理对象打开一个page页面
page = context.new_page()
page.goto('https://www.baidu.com')
#点击百度首页中左上角的全部链接,以打开多个不同的page页面
a_list = page.locator('//*[@id="s-top-left"]/a').all()
for a in a_list:
a.click()
#使用上下文管理对象获取浏览器打开的所有page页面
pages = context.pages
for sub_page in pages:
#遍历每一个page,打印起page标题
print(sub_page.title())
page.close()
bro.close()通过sub_page的title判断进行sub_page页面的切换和管理
from playwright.sync_api import sync_playwright
#封装页面切换的函数
def switch_to_page(context,title):
for page in context.pages:
if title == page.title():
#浏览器停留在此page页面
page.bring_to_front()
return page
#点击百度首页中左上角的全部链接,以打开多个不同的page页面
with sync_playwright() as p:
bro = p.chromium.launch(headless=False,slow_mo=1000)
#创建上下文管理对象
context = bro.new_context()
#基于上下文管理对象打开一个page页面
page = context.new_page()
page.goto('https://www.baidu.com')
#点击百度首页中左上角的全部链接,以打开多个不同的page页面
a_list = page.locator('//*[@id="s-top-left"]/a').all()
for a in a_list:
a.click()
#page页面的切换
select_page = switch_to_page(context,'hao123_上网从这里开始')
#在指定的page中进行相关操作
select_page.locator('//*[@id="search"]/form/div[2]/input').fill('测试测试')
select_page.locator('//*[@id="search"]/form/div[3]/input').click()
page.close()
bro.close()未更新完
8.案例
案例一:绕过安全产品反爬
模拟获取瑞数cookies绕过反爬(这是个很好爬虫技巧,对于一些风控比较弱的安全产品防护,用此方法即可绕过反爬)
from playwright.sync_api import sync_playwright
def get_cookies_by_pw(url, headless=True):
with sync_playwright() as p:
browser = p.chromium.launch(
args=[
"--disable-blink-features=AutomationControlled",
"--user-agent=Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36"
],
headless=headless,
ignore_default_args=["--enable-automation"]
)
page = browser.new_page()
page.goto(url)
page.wait_for_timeout(3000)
cookie = page.context.cookies()
browser.close()
cookies = {}
for i in cookie:
cookies[i['name']] = i['value']
return cookies
江苏某某市场
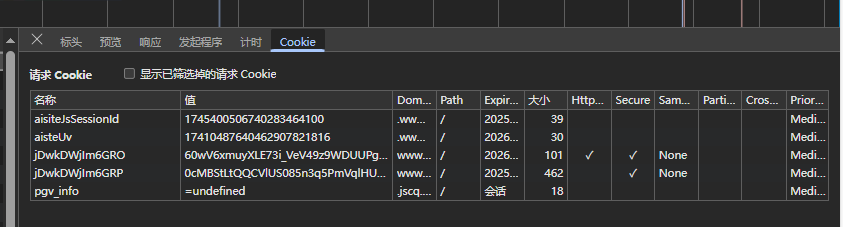
测试获取cookies成功

效验成功

测试cookies持久性,循环二十次,cookies依旧生效
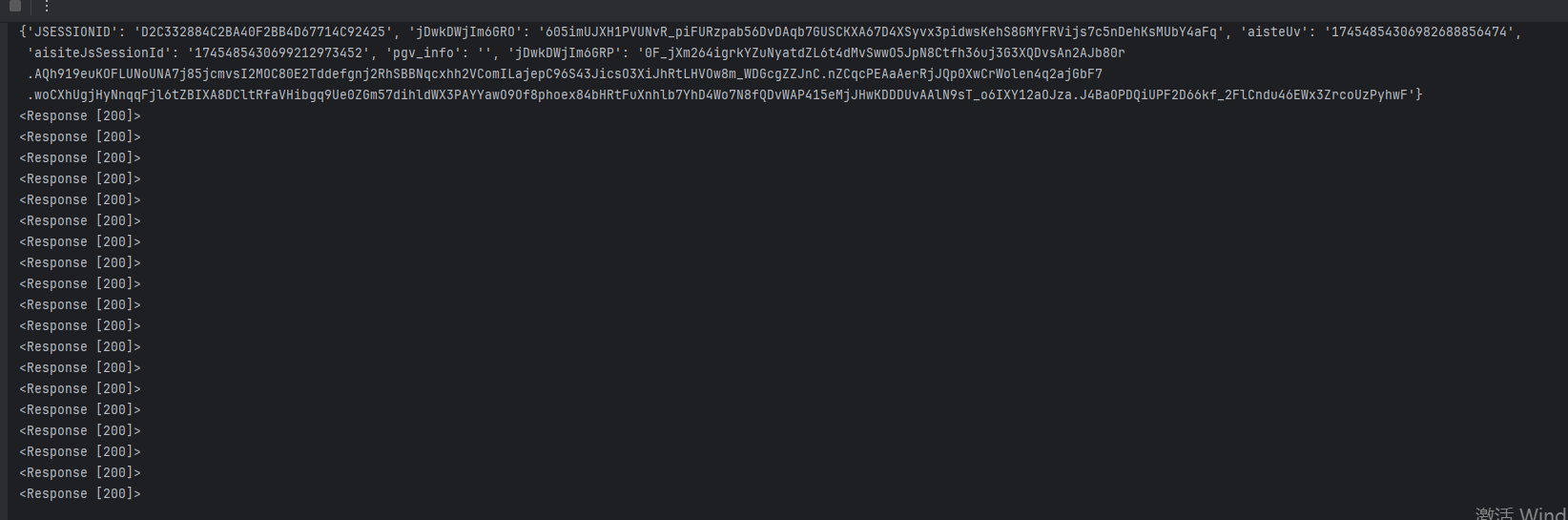
下一个案例风控很大
某某银行
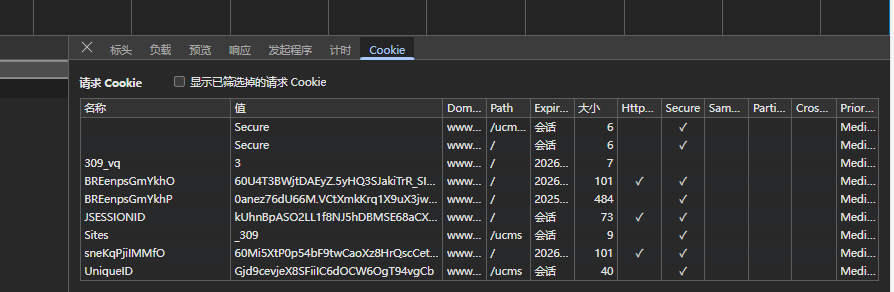
这个最好不要带,有些带了会请求失败,所以先测试一下。
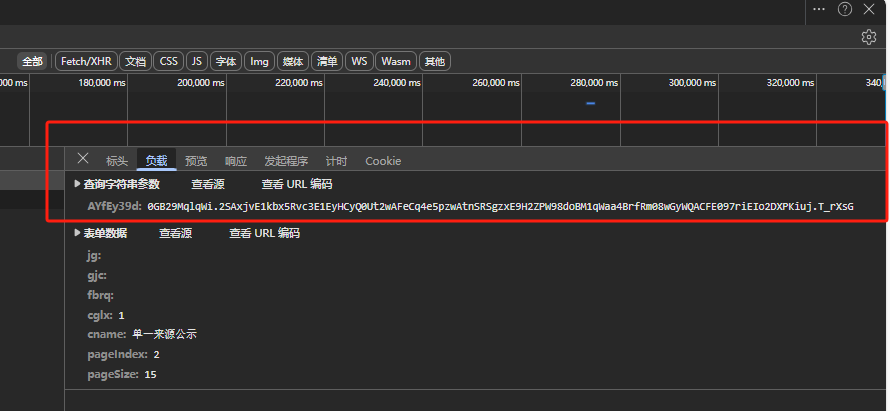
测试成功
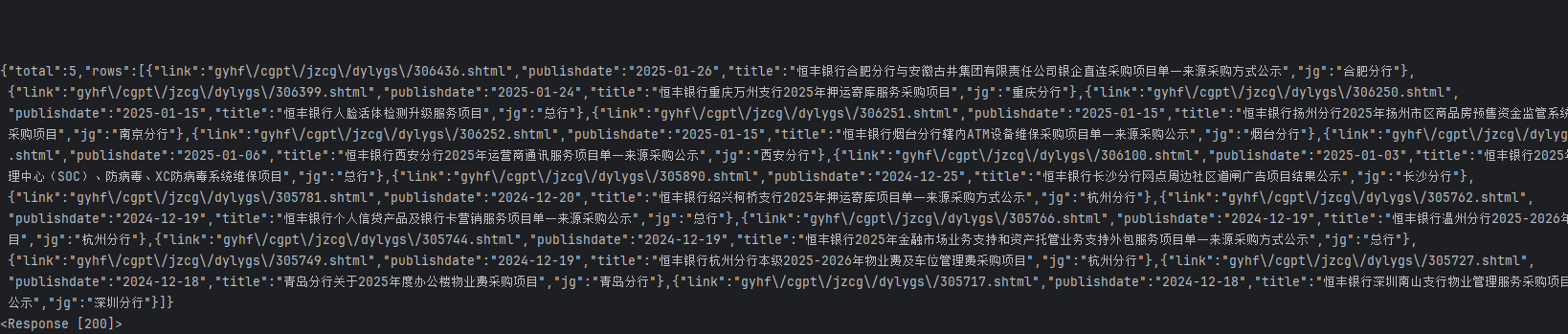
持久性测试 ,请求一次cookie即挂,不适用模拟
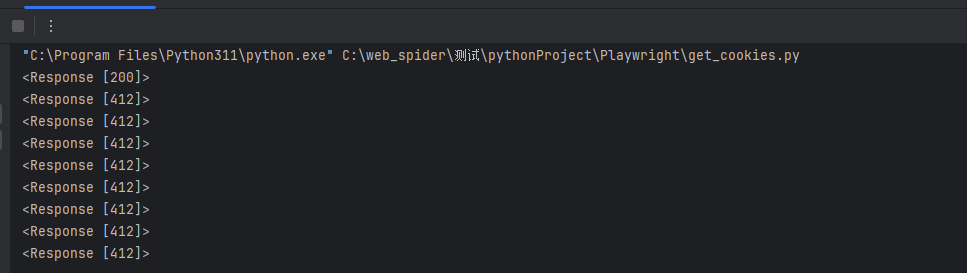
对于爬取大量数据,风控又没有那么强大,在设置一个响应状态码为412,再次模拟获取cookie,可以应急。
案例二:免api实现kimi机器人
模拟万岁!!!,虽然牺牲了一部分速度
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
bro = p.chromium.launch(headless=False, slow_mo=2000)
page = bro.new_page()
page.goto('https://kimi.moonshot.cn/')
# 定位到输入框,进行文本录入
page.locator('.chat-input-editor').fill('用c语言写一个快排') # id定位
# 定位搜索按钮,进行点击操作
page.locator('.send-icon.iconify').click()
# 用于存储已经输出过的段落文本
output_history = set()
output_history1 = set()
while True:
paragraphs = page.eval_on_selector_all(
'.paragraph',
'elements => elements.map(element => element.textContent.trim()).filter(text => text.length > 0)'
)
paragraphs1 = page.eval_on_selector_all(
'.segment-code',
'elements => elements.map(element => element.textContent.trim()).filter(text => text.length > 0)'
)
# 将获取到的段落文本转换为集合,方便比较
current_paragraphs = set(paragraphs)
current_paragraphs1 = set(paragraphs1)
# 找出新的段落文本(不在历史记录中的)
new_paragraphs = current_paragraphs - output_history
new_paragraphs1 = current_paragraphs1 - output_history1
# 如果有新的段落文本,就输出它们
if new_paragraphs:
#给出说明
print(', '.join(new_paragraphs), end='')
# 更新历史记录
output_history.update(new_paragraphs)
if new_paragraphs1:
#这是给出代码
print(', '.join(new_paragraphs1), end='')
# 更新历史记录
output_history1.update(new_paragraphs1)
time.sleep(5) # 等待5秒后再次获取效果如下:
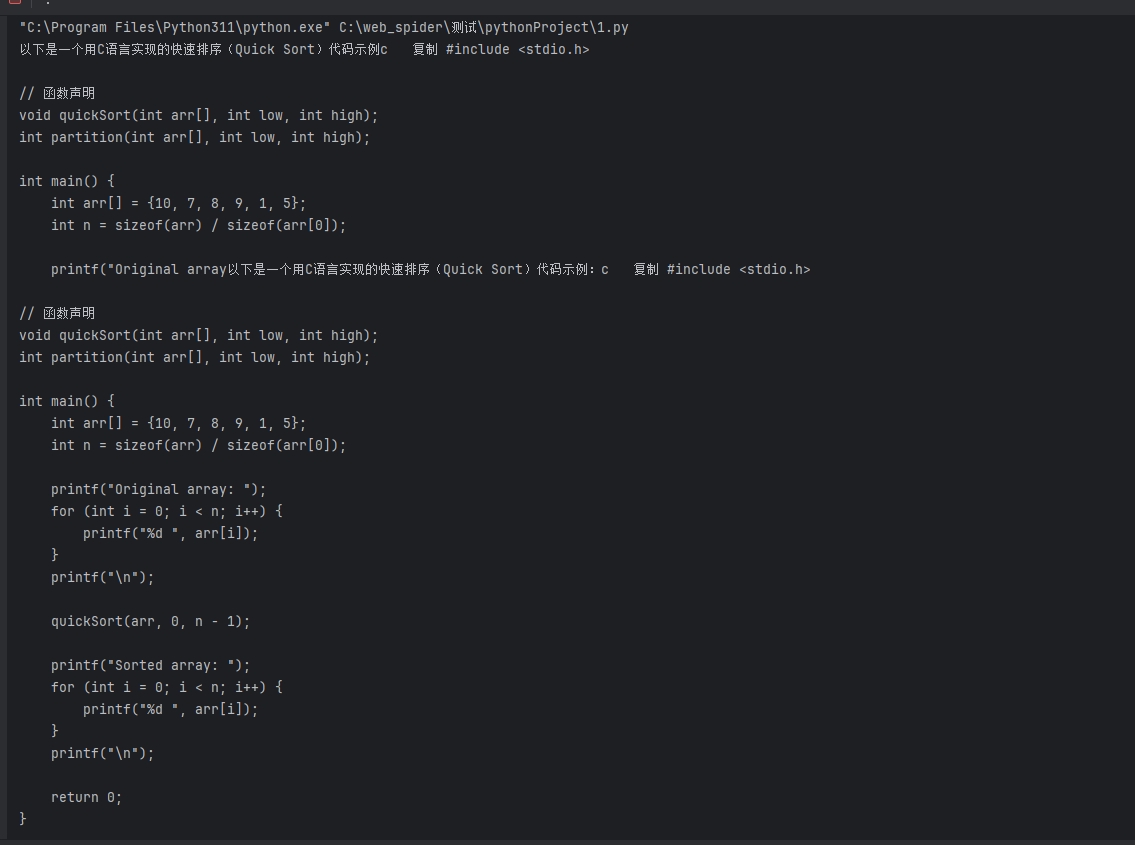
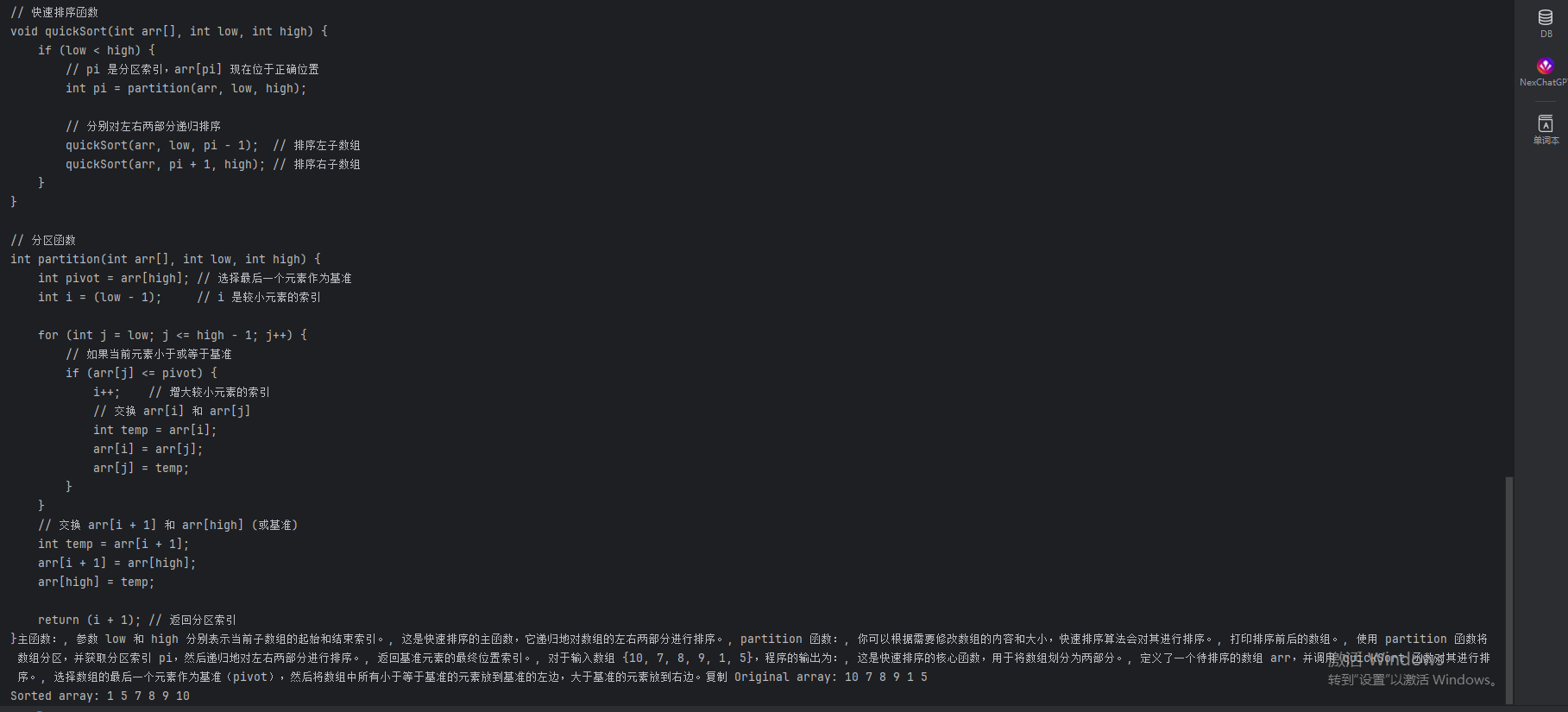
案例三:模拟登录获取cookie,免登录页面。
对于只能扫码登录的账号,可以通过以下方法分享账号
这种是可以事先通过扫码获取cookie,然后把脚本发给别人,别人即可免登录进入页面
待更新!!!!
案例四:过验证码
待更新!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









