






单表查询可能十几万行数据就是瓶颈,对于日益发展的网络科技,大型网站单日可能就会产生几十万,几百万行的数据,如果没有索引查询那么数据查询将会变得非常缓慢,可以说数据表都会对经常被查询的字段添加索引。
索引
索引用于快速找出在某个列中有一特定值的行。不使用索引,MySQL必须从第1条记录开始读完整个表,直到找出相关的行。表越大,查询数据所花费的时间越多。如果表中查询的列有一个索引,MySQL能快速到达某个位置去搜寻数据文件,而不必查看所有数据。
索引是一个单独的,存储在磁盘上的数据结构,使用索引可以快速找出某个或多个列中的特定值的行,对相关列使用索引是提高查询操作速度的最佳途径。
索引是在存储引擎中实现的,因此,每种存储引擎都不一定完全相同,并且每种存储引擎也不一定支持所有索引类型。
根据存储引擎定义每个表的最大索引数和最大索引长度。所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。大多数存储引擎有更高的限制。MySQL中索引的存储类型有两种,即BTREE和HASH,具体和表的存储引擎相关;MyISAM和InnoDB存储引擎只支持BTREE索引;MEMORY/HEAP存储引擎可以支持HASH和BTREE索引。
在一般的软件系统中,对数据库的操作还是以查询为主,当数据量比较大时,优化查询是为关键问题。
其实索引就是一种特殊的文件,它包含对数据表里面所有记录的引用指针,就像一本书的目录一样,索引可以增加查询速度。
索引是帮助mysql高效获取数据的数据结构;
索引存储在文件系统中;
索引的文件存储形式与存储引擎有关。
1、优点
大大加快数据的查询速度
2、缺点
1)创建和维护索引需要耗费时间;
2)索引需要占磁盘空间;
3)对表中的数据进行插入,删除和修改时,索引也需要动态维护,降低数据维护的速度。
索引优缺点:

3、设计原则
1)索引并非越多越好
2)避免对经常更新的表进行过多的索引
3)数据量少的表最好不使用索引
4)在不同值很少的列上不键索引,例如性别字段无须建索引
5)在频繁进行排序或分组的列上建索引
6)当唯一性是某种数据本身的特征时,指定唯一索引。(使用唯一索引需能确保定义的列的数据完整性,以提高查询速度)
4、索引的分类(了解)
1)普通索引和唯一索引
普通索引时MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值;
唯一索引要求索引列的值必须唯一,但允许有空值。
如果是组合索引,则列值的组合必须唯一。
主键索引是一种特殊的唯一索引,不允许有空值。
2)单列索引和组合索引
单列索引即一个索引只包含单个列,一个表可以有多个单列索引。
组合索引是指在表的多个字段组合上创建的索引,只有 在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合。
3)全文索引
全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中擦汗如重复值和空值。
全文索引可以在CHAR,VARCHAR或者TEXT类型的列上创建。MySQL中只有MyISAM存储引擎支持全文索引。(从MySQL 5.6版本开始之后InnoDB开始支持)
4)空间索引
空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY,POINT,LINESTRING,POLYGON。
MySQL使用SPATIAL关键字进行扩展,使得能够用创建正规索引类似的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MyISAM的表中创建。
5、创建索引的方法
1)在创建表的同时声明索引,CREATE TABLE……
CREATE TABLE t1(id int,name char(30),index idx_id(id));2)在已存在表上利用修改语句创建索引,ALTER TABLE……
ALTER TABLE t1 ADD INDEX idx_name(name);3)在已存在表上创建索引,CREATE INDEX……
CREATE UNIQUE INDEX idx_id_name ON t1(id,name);#创建唯一索引4)通过图形界面添加索引
当然,如果是图形界面,还可以通过图形界面创建索引,比如在Windows上安装,那么还可以通过图形界面添加;
当然,了解即可,其实图形界面创建索引也就是封装了SQL语句而已。
6、查看索引
show index from 表名;#查看表的索引
show create table 表名;#查看表的设计7、索引测试
测试一:
创建quzijie表,测试主键字段,带索引的字段和不带索引的字段查询的区别:
CREATE TABLE quzijie
(
a int AUTO_INCREMENT,
b int,
c int,
INDEX idx_b(b),
PRIMARY KEY(a)
);
DELIMITER //
CREATE PROCEDURE num_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<80000 DO
INSERT INTO quzijie(b,c) SELECT rand()*80000,rand()*80000;
SET i=i+1;
END WHILE;
COMMIT;
END//
DELIMITER;
CALL num_insert();#注意,调用这一句需要1分钟~2分钟
#注意:DELIMITER //这一句的意思是将结尾符号改为//,当然这个是临时改的
不是永久改的,重启之后就还是以;结尾
#DELIMITER;这一句是将结尾的标记再改回来,变为;#注意,调用CALL num_insert()这一句需要1分钟~2分钟
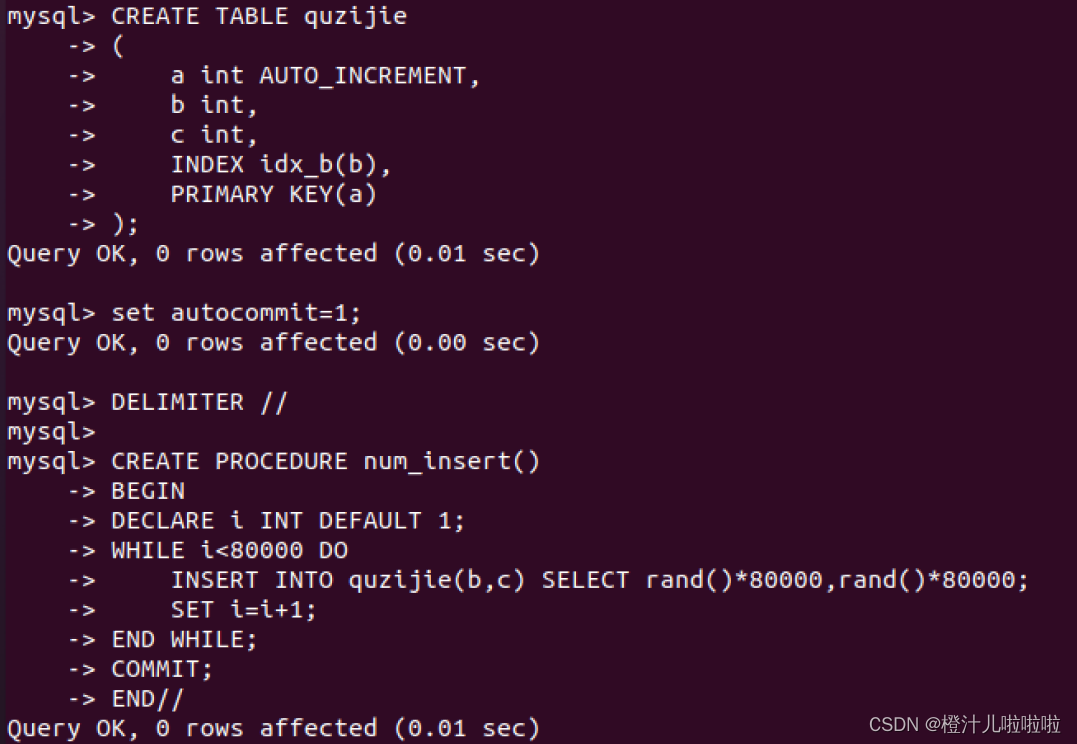

1)查询主键字段
SELECT* FROM quzijie WHERE a=5000;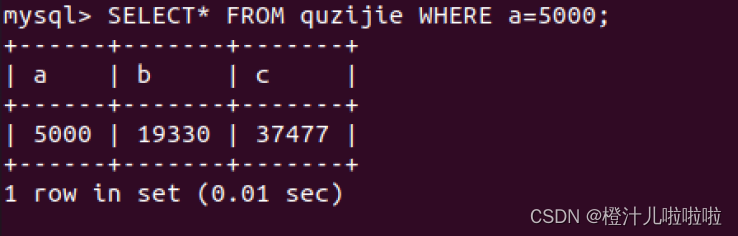
解释语句执行情况
explain SELECT * FROM quzijie WHERE a=5000;
explain补充:

2)查询带索引字段
SELECT * FROM quzijie WHERE b=5000;#b带索引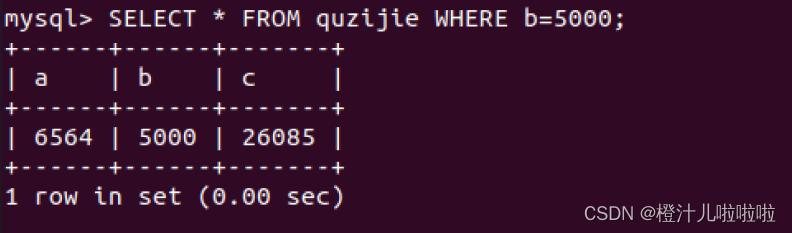
解释语句执行情况
explain SELECT * FROM quzijie WHERE b=5000;
3)查询不带索引字段
SELECT *FROM quzijie WHERE c=5000;#c不带索引
解释语句执行情况
explain SELECT * FROM quzijie WHERE c=5000;
4)结论
索引能提高查询速度
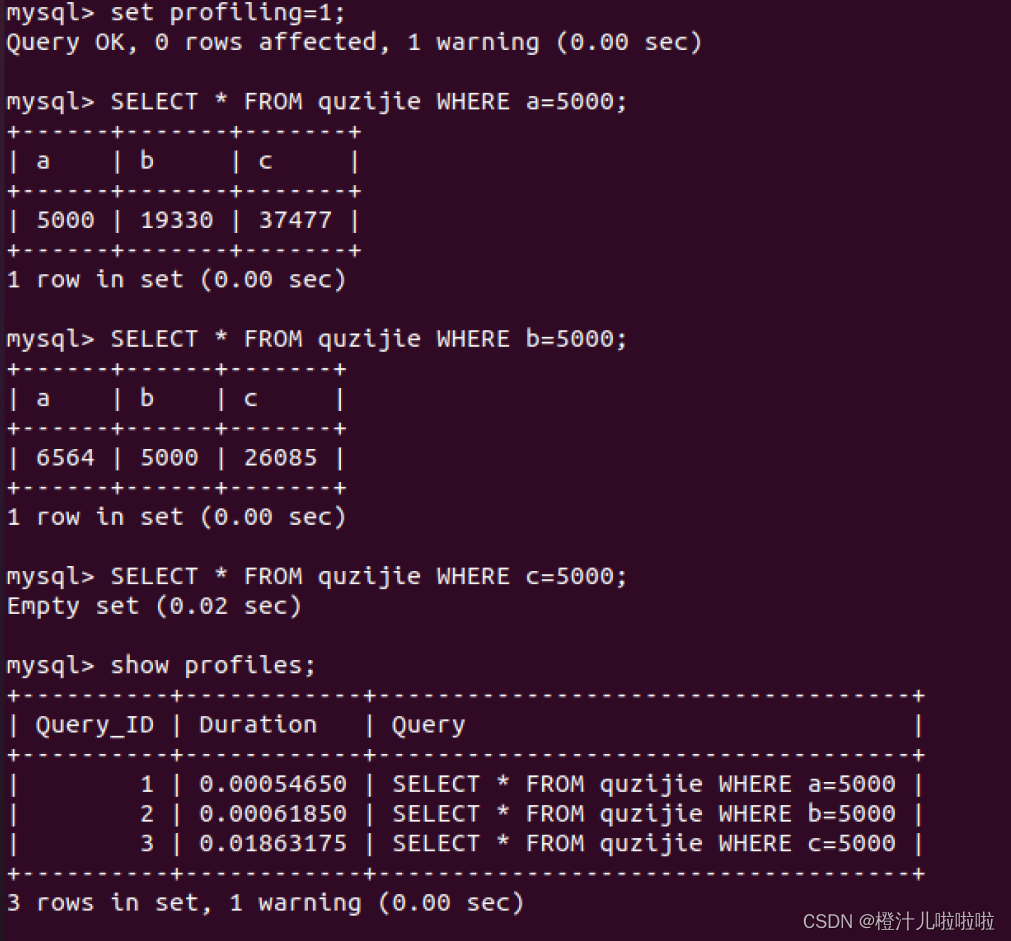
还有一个方法我们也可以得到这个结论,就是我们直接开启检测时间,如下:
set profiling=1; #开启运行时间检测
SELECT * FROM quzijie WHERE a=5000;
SELECT * FROM quzijie WHERE b=5000;#b带索引
SELECT * FROM quzijie WHERE c=5000;#c不带索引
show profiles; #查看执行的时间执行如下:
测试二:
测试索引对插入数据带来的负面影响;
在这里需要注意一下,由于受系统环境,插入数据的多少等影响,这个具体的插入时间是有所变化的,如果测试不出来,可以多插入一些数据对比一下就知道了我们要得到的结论:多一个索引插入数据的时间会增加。
8、删除索引
1)删除索引的语法
1.方法一:使用ALTER TABLE删除索引,语法规则如下:
ALTER TABLE 表名 DROP INDEX 索引名;2.方法二:使用DROP INDEX删除索引
DROP INDEX内部映射到ALTER TABLE语句,语法规则如下:
DROP INDEX 索引名 ON 表名;3.当然,也可以使用图形界面删除索引
2)示例
例如删掉quzijie表格的索引(字段为b,索引名为idx_b);
方法一:
#删除之前查看索引
show index from quzijie;
#删除索引idx_b
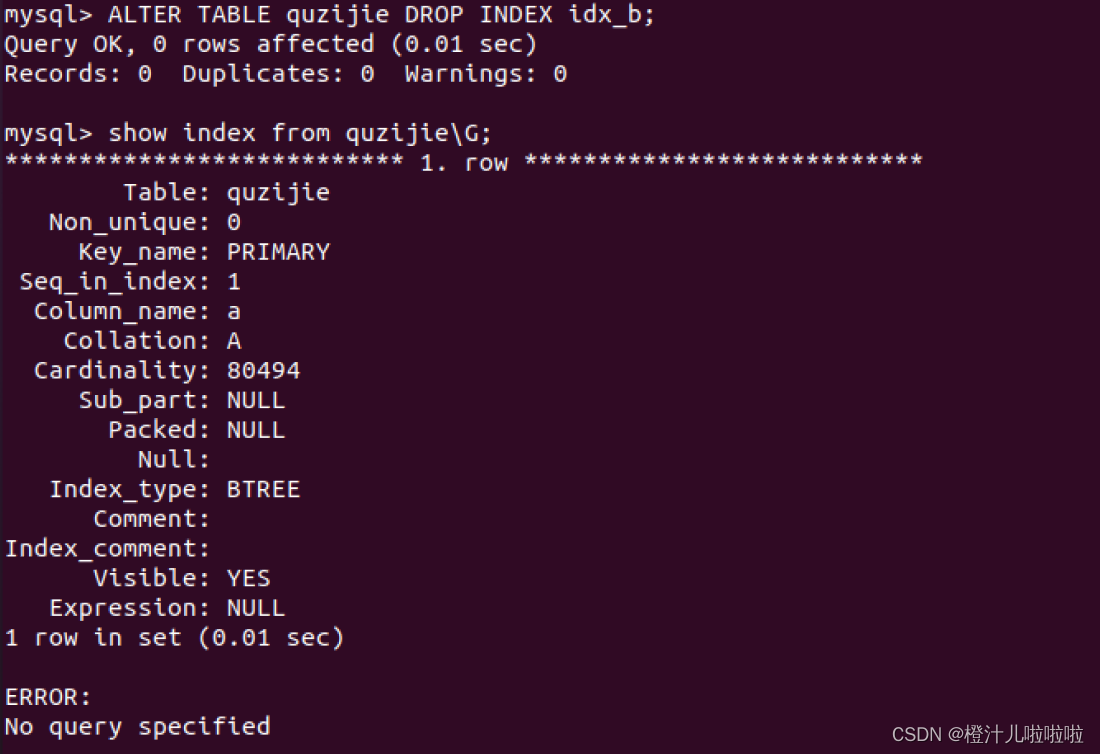
ALTER TABLE quzijie DROP INDEX idx_b;
#查看是否已经删除
show index from quzijie;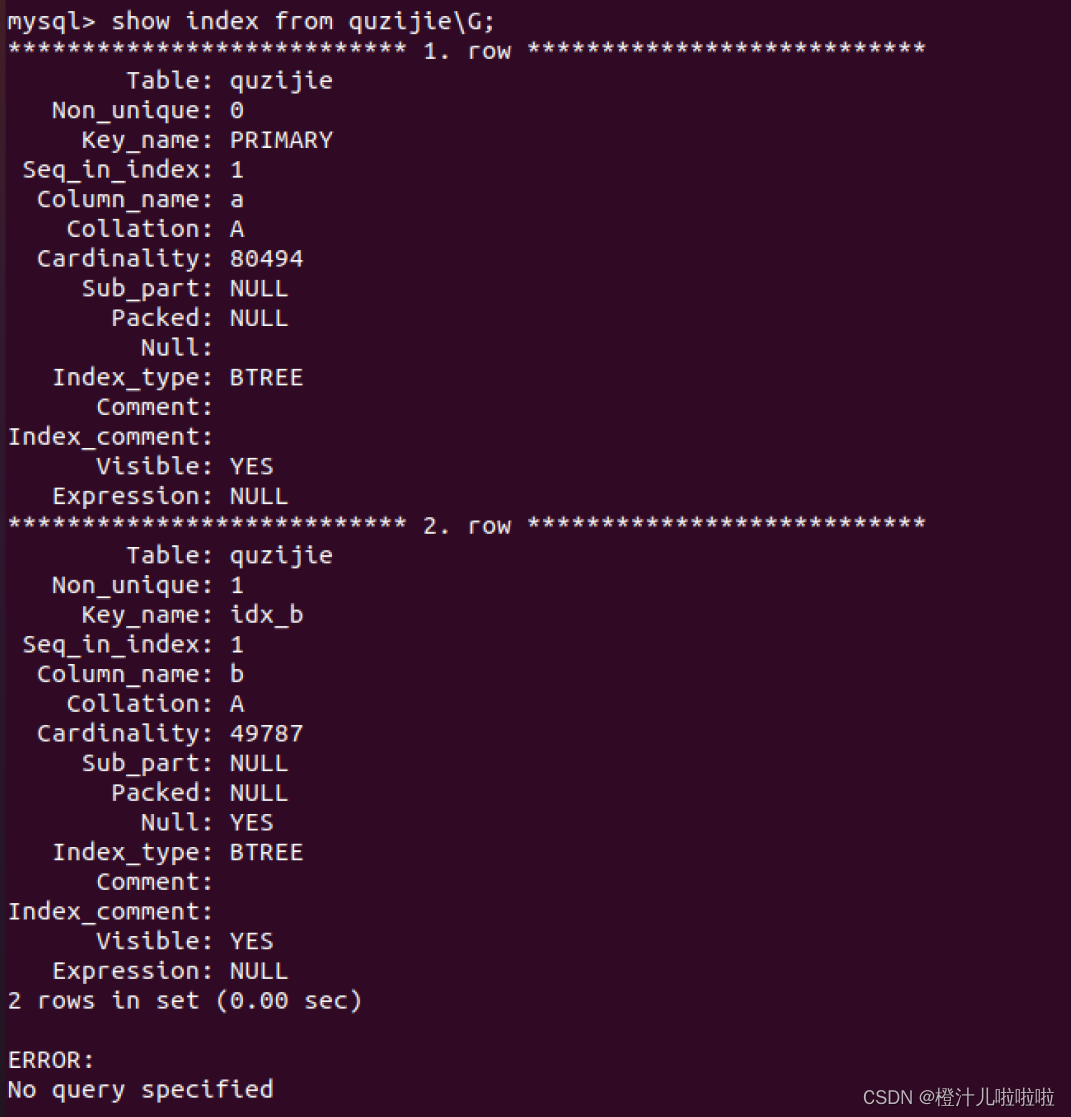
方法二:
#刚才已经删除了,重新增加索引idx_b
alter table quzijie add index index_b(b);
#查看索引
show index from quzijie;
#删除索引index_b
DROP INDEX index_b ON quzijie;
#查看是否已经删除
show index from quzijie;
9、索引的结构选择b+树
B+树索引就是传统意义上的索引。这是目前关系型数据库系统中查找最为常用和最为有效的索引。
(InnoDB存储引擎下索引使用的数据结构是b+树)
B+树索引的构造类似于二叉树,根据键值(Key Value)快速找到数据。
注意:B+树中的B不是代表二叉(binary),而是代表平衡(balance),因为B+树是从最早的平衡二叉树演化而来,但是B+树不是一个二叉树。
为什么不使用更快速的hash表?
因为:1)hash存储需要将所有的数据文件添加到内存,它是空间换时间,这个太浪费空间了;
2)如果是等值查询,hash很快,但实际工作中范围查找更多而非等值查询。
所有hash并不适用于索引结构。
10、什么情况下不适用索引
(1)表记录太少
官方数据500-800万条记录之后性能才开始下降,实际中也就是300万条之后性能下降,所以表的数据如果太少就几万条,那么是不需要建立索引的,MySQL完全就可以应对。
(2)经常增删改的表
为什么经常增删改的表不适合建立索引呢?因为建立了索引虽然提高了查询速度,但却会降低更新表的速度,如对表进行insert,update和delete。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据建立索引。
(3)注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
假如一个表有10万行记录,有一个字段只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表的这个字段建立索引一般不会提高数据库的查询速度。
索引的选择性是指索引列中不同值的数目与表中记录数T的比值,范围从1/T到1之间。
比如一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99;
一个索引的选择性越接近于1,这个索引的效率就越高。
索引的选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查询时过滤掉更多的行。
唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









