







目录
1、HashMap解决了什么问题?
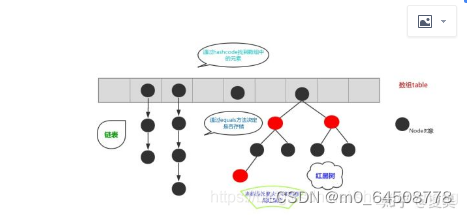
HashMap底层使用数组加(jdk1.7以前)链表(jdk1.8以后在链表节点不小于8的时候会调整为红黑树)的结构完美的解决了数组和链表的问题,
使得查询和插入,删除的效率都很高,每个元素节点都有一个next属性指向下一个节点
,这里由数组结构变成了数组+链表结构(图是别人的)
HashMap特点:
它是查询效率最高的数据结构,因为它是通过计算散列码来决定存储位置的,无论数据有多大,它的查询速度都是固定的。
2、怎么实现呢?
计算出键的hashcode,该值用来定位要将这个元素存放到数组中的什么位置,如果数组这个位置索引的地方是空的,直接将元素放进去就好了。如果已经有元素占据了索引该位置,需要使equals比较该位置的key和当前key是否相等。相等就覆盖,不相等就往链表后面加数据。
什么是hashcode:
在Object类中有一个方法:public native int hashCode();调用这个方法会生成一个int型的整数,我们叫它哈希码,哈希码和调用它的对象地址和内容有关
hashcode特点:
对于同一个对象如果没有被修改(使用equals比较返回true)那么无论何时它的hashcode值都是相同的,对于两个对象如果他们的equals返回true,那么他们的hashcode值也相等
根据hashcode的特点,用key的hashcode % 数组初始容量,在数组上确定唯一位置
初始容量大小和加载因子:
初始容量大小是创建时给数组分配的容量大小,默认值为16,加载因子默认0.75f,用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的两倍,专业术语叫做扩容。在做扩容的时候会生成一个新的数组,原来的所有数据要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能。
3、具体代码演示
定义一个Node节点类
import java.util.Map;
public class Node<K, V> implements Map.Entry<K, V> {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









