







这里写目录标题
1.模型幻觉理解
模型幻觉是指,我们询问一个模型不知道的问题,模型会顺着我们说的话胡编乱造;其实这种现象恰恰说明,模型已经学习到了相关的知识,人类幼仔对其他人的问话,也存在幻觉问题,甚至更加严重,那这是否说明人工智能模型已经具备了一定的智能。
2.RAG
释义: RAG又叫Retrieval Augmented Generation,它的示例有很多,在网上找了一个图:
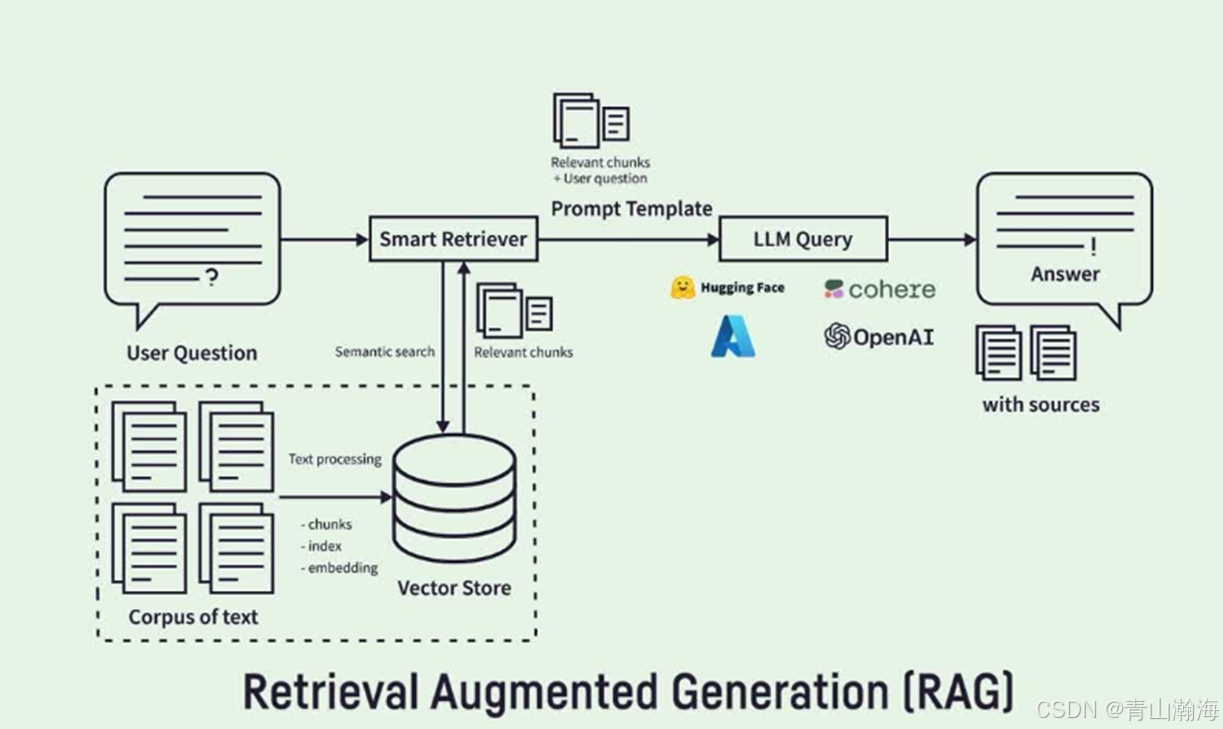
逻辑步骤:
- 首先将
知识进行处理,常见的方式是通过embedding转化为向量目的是后续进行检索,也就是说,后续采用的检索方案不一样,这里知识的处理也不一样,不一定要向量化或者用向量库检索。- 将用户的问题到知识中去检索,即将问题embedding向量化后,检索出相关的知识。
- 将检索的知识和用户问题,
结合提示词模板,交由大模型进行组织或者筛选处理。注意:在这个过程中,检索可以用向量、也可以使用传统的编辑距离、BM25、ES等方法。
2.1RAG优势
- 可扩展性:减少模型大小和训练成本,并能够快速扩展知识。
- 准确性:模型基于事实进行回答,减少幻觉的发生。
- 可控性:允许更新和定制知识。
- 可解释性:检索到的相关信息作为模型预测中来源的参考。
- 多功能性:RAG能够针对多种任务进行微调和定制,如QA、Summary、Dialogue等。
2.2RAG难点
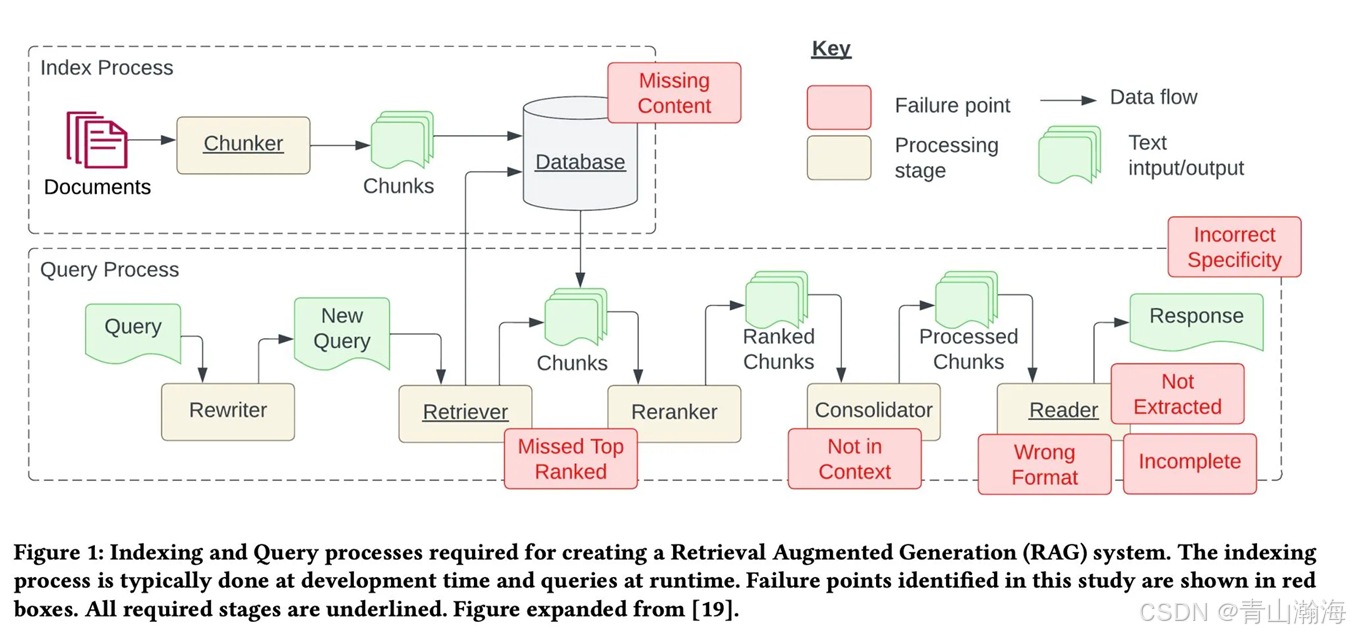
- Missing Content 没有问题相关的知识或者材料。
- Missed Top Ranked 与问题最相关的材料,没有被召回排到第一。有一些排序的模型,即增强。
- Not in Content 是指召回中,没有完整包含问题所需要的内容。
- Wrong Format 输出的数据格式不对。
- Incomplete 模型回答的内容不完整。
- Not Extracted 没有对知识进行抽取和整理,回答中包含原文的完整片段。
- Incorrect Specificity 输出存在不正确的情况,即和想要的答案不一致。
2.3RAG难点解决方案
2.3.1超长文本-MemWalker
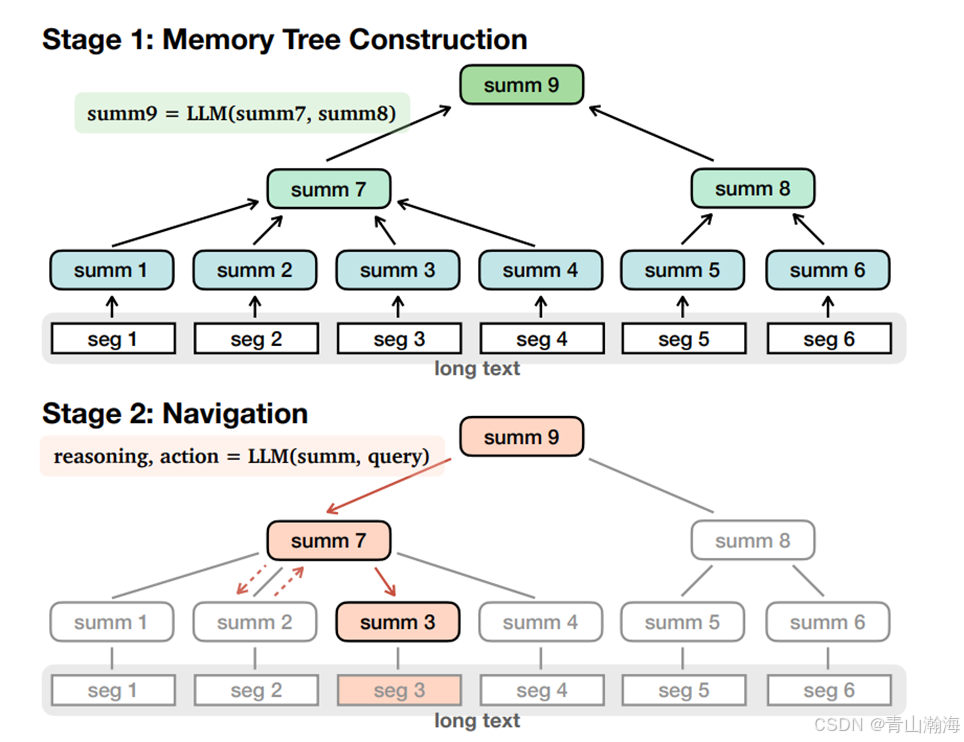
处理思路:
- 即首先将文本按照章节,或者段落,即一个最小的材料单元,进行总结
- 在最小单元中,按照一定的数量,比如前3章、前4章做总结得到第二层的总结
- 在第二层的基础上做更上层的总结,最后得到一个总结的的树,树的最小枝丫就是文章本身的片段。
- 在搜索时,即
从上往下,循环检索,判断最相关的总结,一直到枝丫,最后召回比较相近的文章片段本身。
2.3.2超长文本-Read-Agent
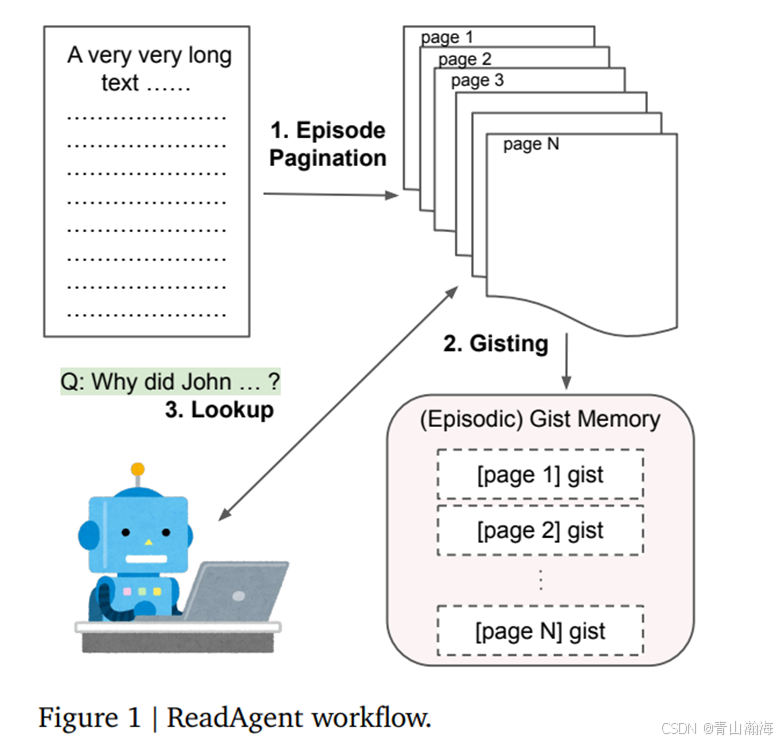
材料处理与检索思路:
- 将一个超长文本,按照一大段,一大段的交由大模型,去判断从哪里分段比较好,并且阐明原因,如果模型能力强,可以直接使用,如果要求较高,可以手动检测一次。
- 将已经标注分段的文章,进行拆分成对应段落。
- 将拆分的段落,循环交由大模型去进行内容总结。
- 将总结的内容,和用户的问题交由大模型,判断,需要重新读原文的那些章节,回答问题。
- 根据总结的序号,去找到对应的原文,结合问题和提示词,交由大模型进行问题回答。
2.3.3Corrective RAG
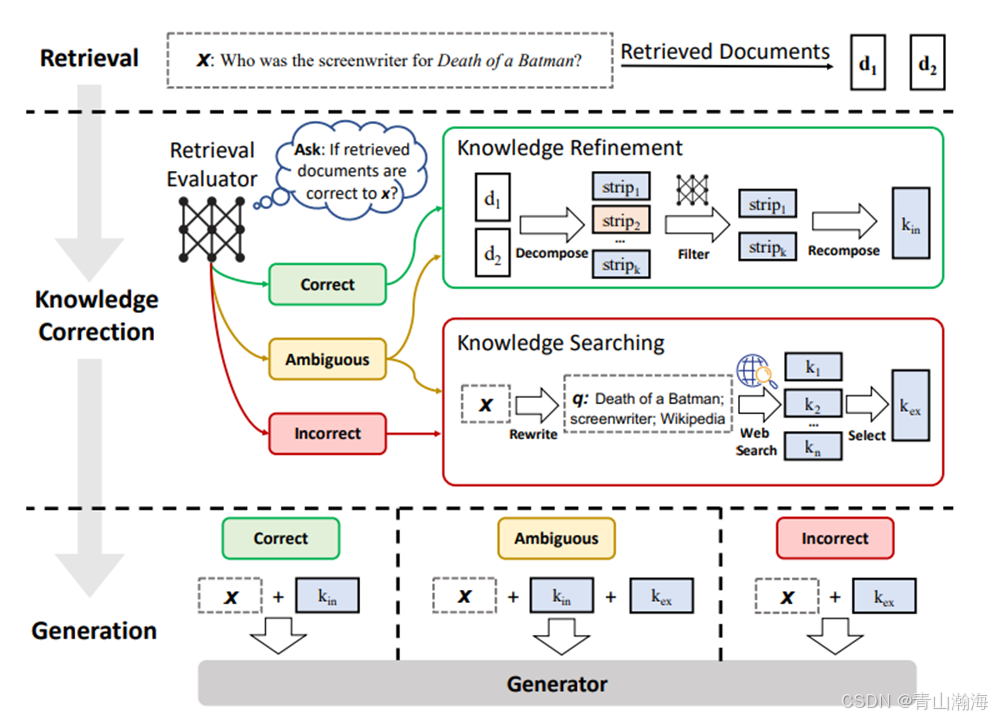
corrective rag是为了解决知识库回答的质量是否好,通过在线搜索来增强回答的结果。
- 首先根据问题到已有的知识库中召回相关内容。
- 根据召回的内容和客户问题,交由模型(Retrieval Evaluator)去判断问题和召回内容的相关性。
- 判断结果为Correct时,则表示,召回结果可以回答问题,则将其交由大模型处理。
- 判断结果为Ambiguous时,则表示,不太确定,这个时候,则将问题再放到在线检索,得到检索的结果、和知识库召回结构、结合问题一起交由通用大模型。
- 判断结果为Incorrect时,则表示召回结果和问题无关,则将问题进行在线检索,将检索结果和问题交由通用大模型回答。
2.3.4self RAG
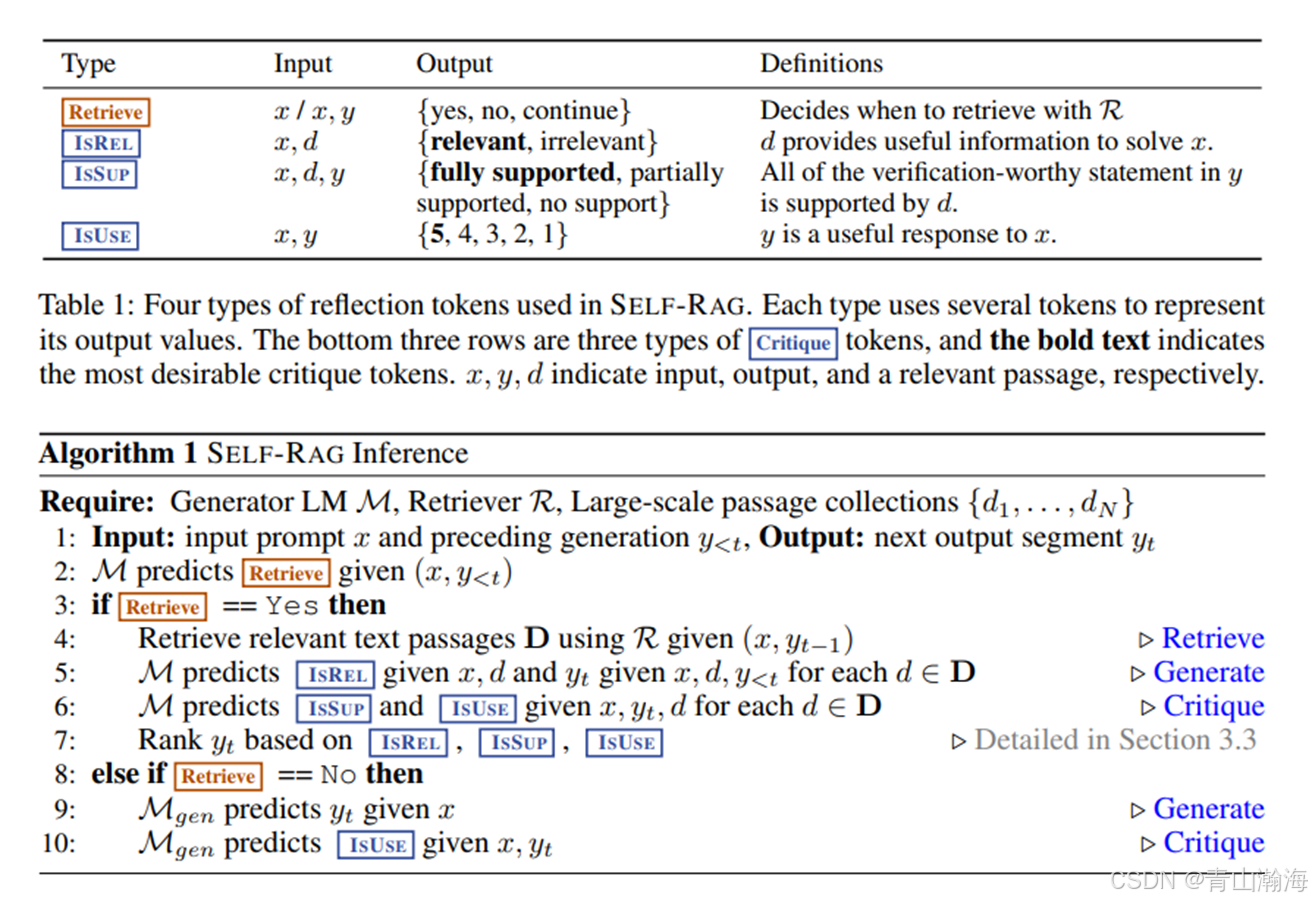
特殊的地方:
- 是否进行知识库内容召回是根据模型的回答情况而定的。
- 模型重度参与到RAG的数据处理、召回效果判断、结果输出这些重要环节。
释义:
- 将问题输入到模型中,让模型自己去判断需不需要到知识库召回内容,模型在输出答案时,如果输出了Retrieve,则表示需要召回,没有则继续输出,直到结束。
- 如果有Retrieve需要召回,则将已经输出的内容和问题一起交由召回模型进行知识召回。
- 将召回的内容,问题交由大模型判断IsREL相关性;
- 将召回内容、生成内容、问题交由大模型判断IsSup,对问题的回答支持程度;
- 将召回内容和最后的输出内容,交由大模型判断IsUSE,判断可用性。
2.3.4Power of Noise

简介: 文章有提出一个特别反直觉的结论,即召回的信息中,如果包含几翩与当前问题无关的内容,则大模型的回答会更好一些。
- 将召回的内容分为四个级别:Gold Document 即包含问题的清晰准确答案的材料。Relevant Documents 即包含答案且但是答案并不是直接给出,比较隐晦,需要一定推理的材料。Related Document 不包含答案,但与问题相关的材料,比如背景等。Irrelevant Document 与答案和问题完全无关的内容。
3. RAG优化技巧
3.1召回源
1.多路召回: 稀疏召回、语义召回、字面召回
问题: 多路召回有截断和召回分数的对齐问题。
解决:在召回后,进行一个重排序,精简召回数,提示召回质量。
2. embedding模型、重排序模型、生成模型对系统回答的指标情况做进行微调。
3.2 效果评估
RAG效果评估主要是针对:检索和生成两个环节
3.2.1 检索
- MRR,平均倒排率
- 前K项的Hits Rate命中率
- NDCG排序指标
3.2.2 生成
- 量化指标: Rouge-L;文本相似度、关键词重合度
- 多样性:能否生成多种合理正确的答案
- 人类评估:对模型的回答做质量、准确性、连贯性的评分。
3.3 RAG幻觉
有两类幻觉:
1.生成结果和数据源不一致
2.问题超出大模型的认知
原因1:训练数据和源数据不一致、数据没有对齐、编码器理解能力的缺陷、解码器策略错误的原因
原因2:用户的问题不在语言模型的认知范围内
解决思路:
- 引入更精准的知识库、消除虚假数据源、减少数据偏差
- 纠偏规则,比如ReAct思想,让大模型对输出结果反思
- 集成知识图谱,做召回不仅做向量匹配,还要考虑图谱三元组,通过知识图谱的结构化来增强模型的推理能力
边界case:
- 知识库没有的问题,做准入判别,判断是否需要回答(大模型+prompt/二分类模型);让模型在这个情况下输出一个兜底话术。
- 减少幻觉,对于会随着时间变化问题,让模型给定一个固定的回答,或者不回答。
- 格式不正确:即模型输出的内容,没有办法正确的解析,设置代理大模型,在解析内容失败时,让代理大模型直接生成输出内容的总结。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









