







1.推荐系统简介
1.1.互联网的发展
- 门户网站
- 搜索引擎
- 推荐系统
1.2.推荐系统
场景:
- 信息过载
- 用户需求不明
目标:
- 高效、持续的提供用户想要的内容
- 用户和内容生产者的留存和商业转化
评价指标:
准确度、满意度、覆盖度、信任度、 可扩展性、实时性、鲁棒性、商业目标、用户留存、多样性、惊喜性、新颖性
1.3显示反馈-隐式反馈
举例:
以抖音、B站等视频平台为例:
显示反馈:
收藏、下载、进入个人主页、关注、点赞、正向评论、观看评论、原声点击、标签点击、分享隐式反馈
播放时长、有效播放、播放完成率、完播
特点:
显示反馈:含义明确、量少(即时喜欢,不一定点赞)
隐式反馈:有噪音(挂机等)、量大
1.4推荐系统模块
释义: 推荐系统的算法能主要分为召回、排序两个大的部分,根据实际的物料库大小、模型效率、业务要求来设计推荐系统的更细的组成模块。
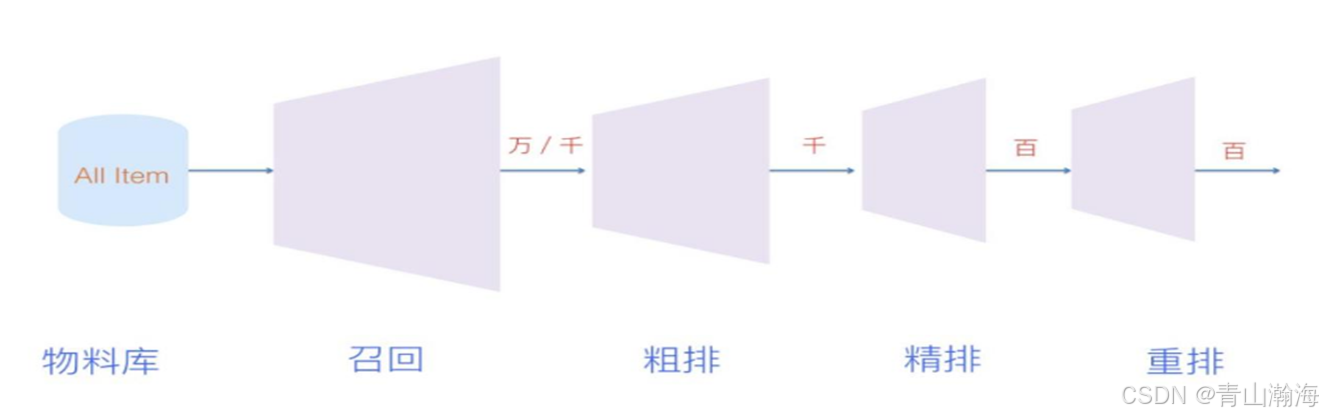
详细解析:
召回:就是从大量数据中,召回相关的材料,比如:冬天给客户推荐棉袜为例,电商平台:就是召回大量涉及棉袜和相关的商品排序:就是讲召回内容,按照与客户最匹配的顺序,讲信息排序后展示到客户面前的顺序。大型的推荐系统还会做的更细致,比如:粗排、精排、重排
2.1.粗排,一般是为了效率考虑,先粗步筛选掉部分匹配度不高的内容,再交由精排模型。
2.2.精排:就是将粗排内容,按照当前用户的习惯、节庆等整理的优先级由高到低的内容
2.3.重排:即在精排的基础上添加一些新的元素,即相关的,比如:精排全是冬天的服装,重排会根据相应策略,在其中插入一些:女生–暖宝宝、暖手袋等的产品。
2.召回策略
2.1基于内容的召回Content Based
2.1.1介绍
概念: 基于用户喜欢、点击查看的内容,推荐相似/关联内容。
核心:
- 建立起每个内容的一种表示;比如向量、或者其他的方式,使得后续可以进行计算。
- 定义并计算内容的相似性/关联性
建立内容画像 item profile
2.1.2举例
电影推荐:
直观的可以理解到,通过下面的三个维度,就可以表示一个电影,从而计算两部电影的相似性:
- 电影的类型标签:动作、战争
- 电影的简介内容
- 电影的主演阵容
2.1.3 优缺点
优点:
1.不需要其他用户数据
2.可以很好的给有独特口味的用户推荐
3.能够推荐出冷门的内容
4.有较强的可解释性
缺点:
- 内容特征构建需要对内容的理解,有时很困难;比如金融产品等,本身产品的内容就专业且复杂,需要构建内容特征,就需要专业的人士
- 对于新用户不好推荐
- 始终在给用户推荐熟悉的东西,没有惊喜;并且会造成信息茧房;割裂观点。由于看到的都是同一类视频,加深观点。
- 没有利用其他用户的行为
2.2协同过滤Collaborative Filtering
简介: 利用兴趣相同、喜好相似的群体来为用户推荐产品。主要包含:UserCF、ItemCF、ModelCF;前两种下面会详细介绍;ModelCF是指:使用矩阵分解SVD等算法或模型预测缺失值。
2.2.1 UserCF
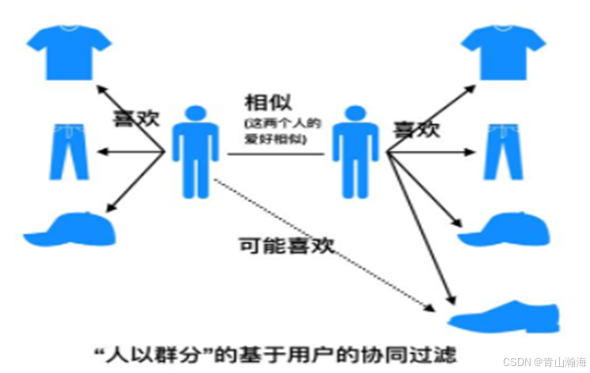
简介: 推荐相似用户喜欢的产品。
举例说明:

- 以看电影为例,即讲1-12个用户看的1-6部电影进行喜爱度打分;
- 通过喜欢分数,就可以构建对相似用户、相似兴趣进行分类。(分类的逻辑有多种,比如:高分相似、评分进行相似度计算等)
- 完成分类后,相似用户见,评分高,且未进行观看的,就可以进行推荐。
好处:
- 不需要对物理本身进行理解,
可以放到任意一种场景下,比如金融产品- 通过多维度的相似度,计算,
还可以立体的建立客户群分类。
人以群分:
Item_scores = {}
for item in 候选物品集:
for sim_user in m个最相似的用户:
item_scores[item] += sim_user对item的评分 * sim_user与userA的相似度
2.2.2 ItemCF
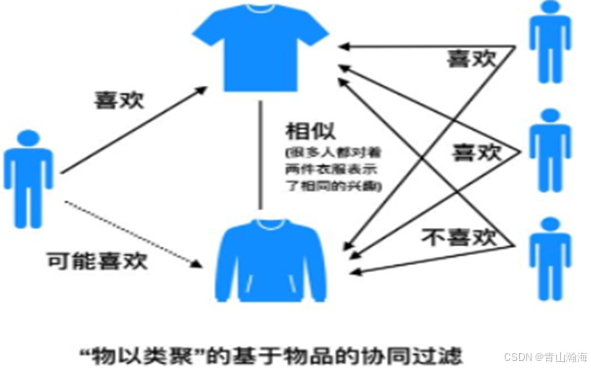
简介: 推荐与自己喜欢的产品相似的产品;本质还是通过不同的人,对产品的打分计算相似度,相似度相同的产品,就是应该是喜欢的,将产品进行推荐。
举例说明:
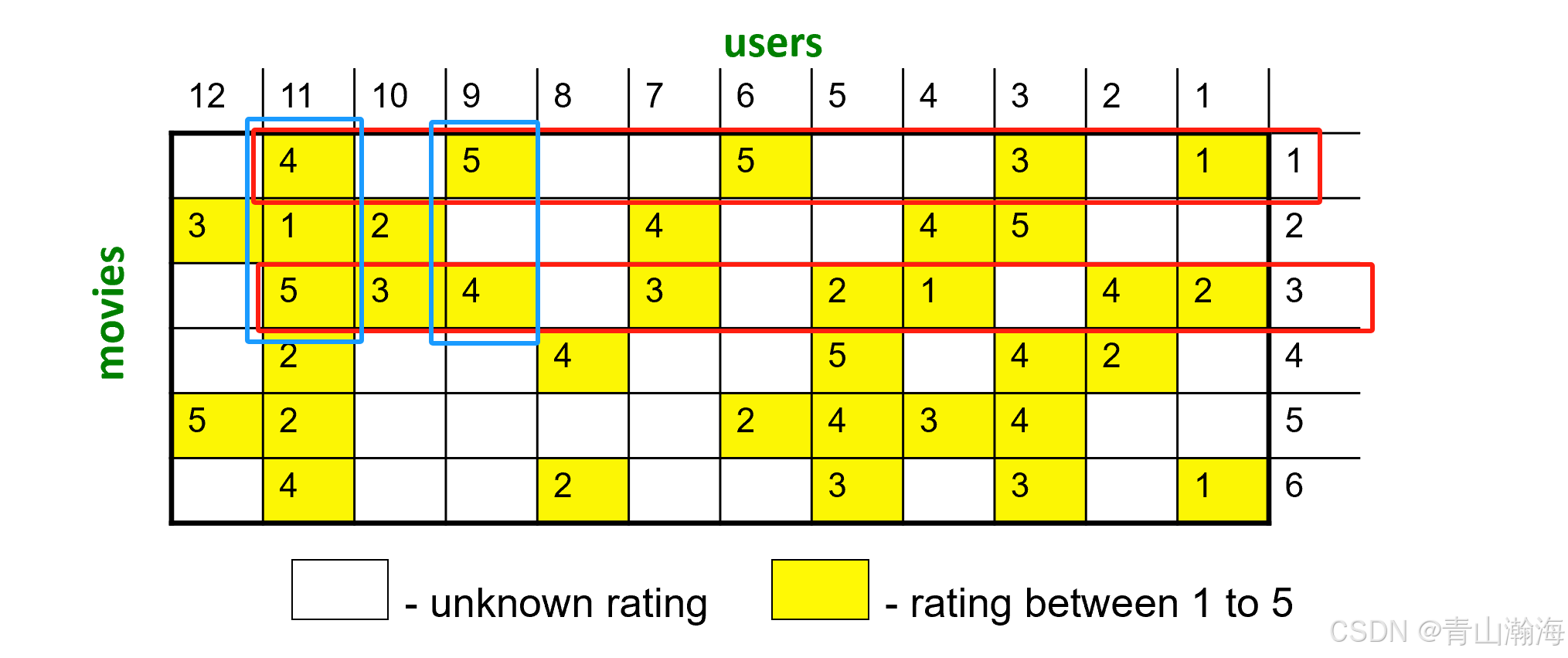
- 上面的产品1和3,根据用过的客户11、9都对他们进行打分,从而可以计算产品1、产品3的相似度。
- 对于用户6,对产品1也打高分,根据产品1、产品3相似,就会将产品3也推荐给用户6.
- 推荐的产品不一定是同一类别的产品,可以是衣服,推荐电子产品,
实质是根据相同的口味用户,喜欢的产品进行推荐
物以类聚
item_scores = {}
for item in 候选物品集:
for item_h in 用户喜欢物品集:
item_scores[item] += 用户对item_h的评分 * item与item_h的相似度
2.2.3 相似度度量的方法
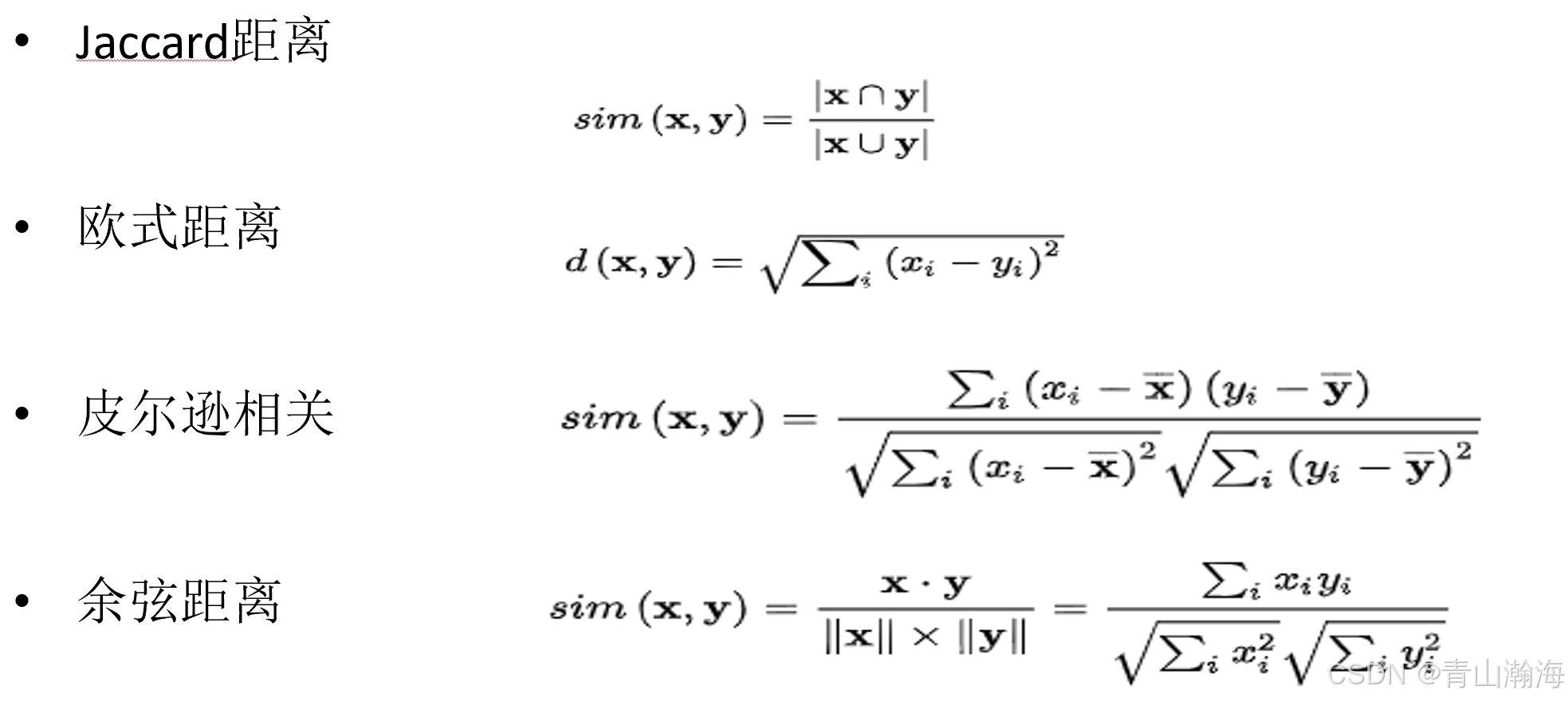
2.2.4 协调过滤优缺点
优点:
适用于任何内容的推荐,无需考虑物料特征,理解对应物理特征利用其他用户行为信息
缺点:
1.冷启动困难,开始时,没有那么多的丰富的标注或者数据
2.User-Item矩阵稀疏,本质也是没有那么多数据,
3.新的内容很难被推荐出来,因为观看它的信息太少,从而相似计算值太低
4.小众爱好不容易被发现
2.3基于统计信息/热门召回
即热搜事件等;示例:
- 1小时内高点击率
- 1小时内高点击率增长
- 高关注,高赞,高转发
- 热力榜单
2.4物料冷启动
问题场景:
- 无曝光导致无反馈,无反馈导致无曝光,就会进入恶性循环。
- 对于新出现的物料,应当主动分配一部分流量。
或者是根据统计原理,demographic特征(人口学特征)
1)用户注册信息
性别、年龄、地域
2)设备信息
定位、手机型号、app列表
3)社交信息
推广素材、安装来源
在创建账号时,会登记相关信息:
上述内容就会作为刚开始时,进行推荐的一些依据内容;其次,当前互联网企业间会有一些账户信息的同步,比如微信账号可以登录多个平台、阿里系等。
2.5运营手段等
简介: 由运营人员手动给出一些候选结果,属于一种强规则;在业务需要时使用。
释义: 比如说,投放广告等
2.6向量和模型召回
原理: 将用户信息和物料信息进行匹配训练出模型,对于下一个用户或者物料信息,就能通过模型输出匹配召回内容。或者说根据物料和用户,计算匹配分数。
示意图:
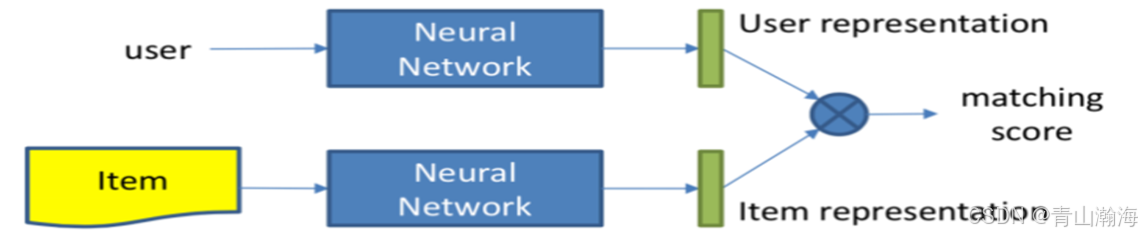
即将人和物料信息输入到网络,训练其对应的向量表示,计算相似分数。
3.特征工程
简介: 即寻找实体的特点,并进行数值化表示。比如:人的身高、喜欢浏览擦边视频等等,并将其数值化表示。
特征影响:
- 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。
- 特征越好,灵活性越强;即可以预测对象的不同维度,比如喜欢听的音乐、爱好的视频题材等。
- 特征越好,构建的模型越简单,即模型能够更简单、更快的捕捉到规律。
- 特征越好,模型的性能越出色
3.1离散特征
简介: 就是数值可以枚举的特征。
比如: 性别、星座、颜色、商品、机器型号
3.1.1 特征处理 --编码
-
one-shot:
颜色 = {红,橙,黄,绿}
红 = [1, 0, 0, 0]
橙 = [0, 1, 0, 0]
黄 = [0, 0, 1, 0]
绿 = [0, 0, 0, 1] -
multi-hot:
电影标签:{悬疑,惊悚,科幻,爱情,动作,搞笑,纪实,古装}电影A: 古装,搞笑
[0, 0, 0, 0, 0, 1, 0, 1]电影B: 科幻,爱情
[0, 0, 1, 1, 0, 0, 0, 0] -
不同的离散特征进行结合等
3.1.2 特征处理 --向量化表示
类似于词向量的做法,解决类别过多的问题;每个特征值对应一个固定维度的向量
北京 -> [0.57, 0.18, 0.76, 0.23, 0.45, 0.98]
上海 -> [0.14, 0.92, 0.66, 0.21, 0.23, 0.79]
广州 -> [0.32, 0.85, 0.95, 0.35, 0.97, 0.14]
3.2 连续变量
简介: 即数值是一个范围
比如: 身高、时间、体重等
3.2.1 归一化
原因: 神经网络为代表的的模型对于数值是敏感的,过大的数值会对网络计算造成影响,通过归一化,将数值缩放到[0-1]之间有助于训练。
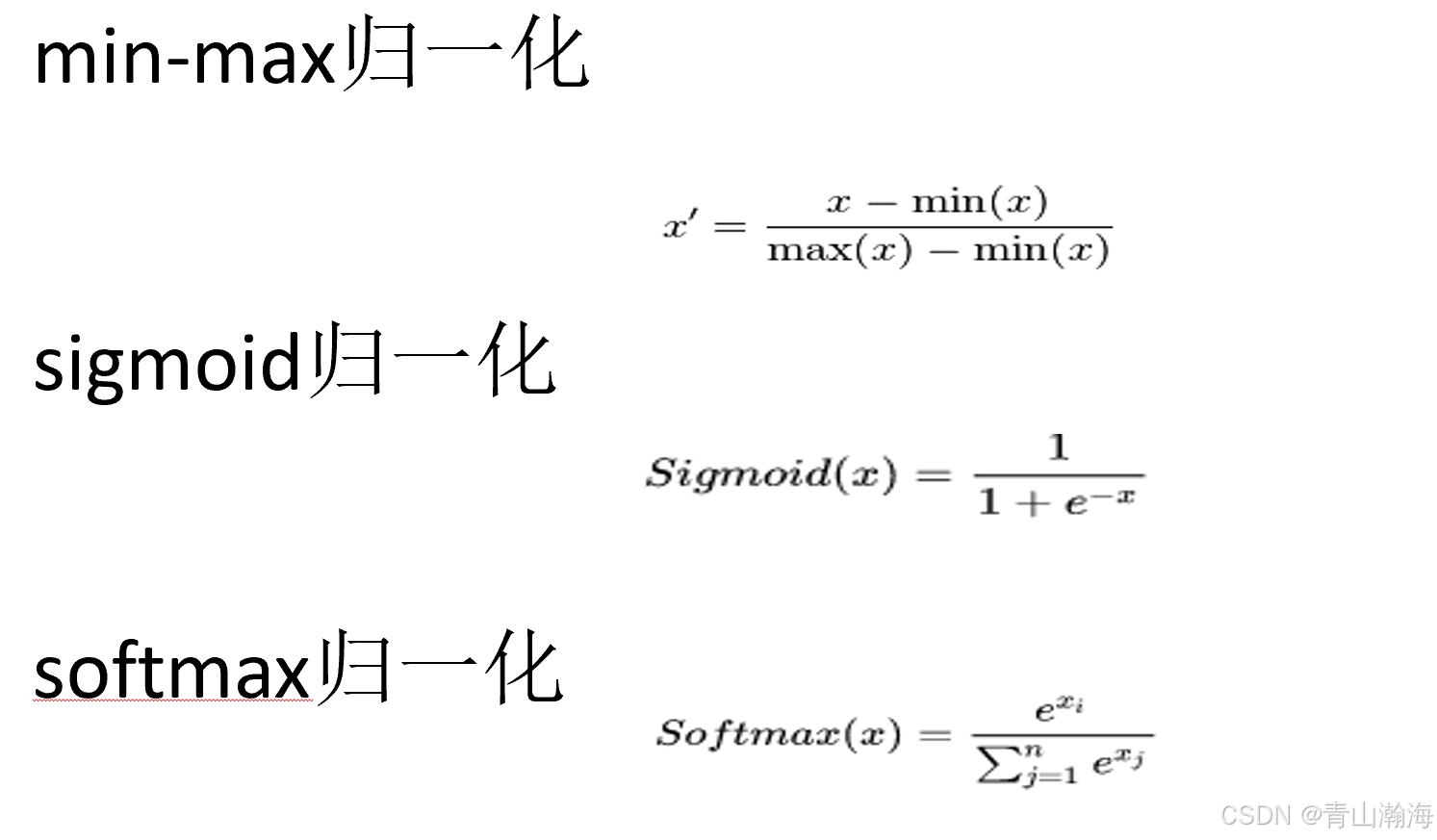
归一化的方法: 选择需要根据数据的分布结合归一化函数的特性来确定。比如:sigmoid在较大/或较小值时,结果变化很小,就不利于极值较多的数据,不利于数据的区分。
3.2.2标准化
原因: 得到的数据有可能都是大于1的、或者都是正数,为了便于训练, 将数据分布转化为均值为0,方差为1,有助于训练。使得数据分布均匀,且符合原有数据特征。

3.2.3离散化
简介: 将连续值转化为离散值,用处理离散特征的方式处理。
原理: 例如身高对于一个人选择商品,在一定的区间内是没有太大影响的。1.81m、1.80m两个不同身高的人,在身高这个特征上面,没有什么区别。所以可以把一个小的区间内的数值,固定为一个,就变成离散的数据。
举例:
sample - 假设为10个人的考试成绩,取值0-1
[0.04, 0.05, 0.28, 0.44, 0.46, 0.78, 0.85, 0.86, 0.86, 0.89]
等频分割 - 将区间按样本数量换分成n段(按照上面的10个数值,给它按照频率赋值)
[0, 0, 1, 1, 2, 2, 3, 3, 4, 4]
等距分割 - 将区间依照数值平均划分成n段(按照上面的10个数值,给它按照区间划分赋值)
[0, 0, 1, 2, 2, 3, 4, 4, 4, 4]
按照信息熵选择切分点。通过算法对数据进行计算,即决策树的思路,找到最佳的点位。
注意: 特征工程的特征处理,要求算法人员对具体的业务有深刻的认知,才能做好。比如,计算人的购买力,那么不同收入段的人群的数量差距是非常大的。需要综合考虑,不同阶段甚至可以采取不同的方案去处理。
3.3.1组合特征
简介: 有相互关联的特征,显式的标识并且组合,有利于降低模型的学习难度,更快的找到并且适配规律。
举例:
颜色 = {红,橙,黄,绿}
红 = [1, 0, 0, 0]
橙 = [0, 1, 0, 0]
黄 = [0, 0, 1, 0]
绿 = [0, 0, 0, 1]
形状 = {圆形,方形}
圆形 = [1, 0]
方形 = [0, 1]
红圆形 [1, 0, 0, 0,1, 0]
橙方形 [0, 1, 0, 0,0, 1]
…
再比如:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









