






一.写在前面
在不久之前,我们尝试了使用selenium来批量爬取某音的视频,并且是成功了的,并且是能够做到可见即可爬的,但是呢这种方法的弊端也很多,其中最大的一个就是不能忍受的速度缓慢,它的爬取太慢了,因为你要让他慢慢往下滑,知道所有的视频全部显现出来,这太不舒服了,有没有另外的方法可以让我们快速爬取呢?有,那就是逆向它的XB参数,找到生成逻辑,然后模拟运行出来,利用我们自己生成的XB参数构建请求,把所有视频的URL全部抓取出来,再利用多线程或者异步进行爬取。关于这个XB参数是怎样找到它的加密逻辑的,我们这里并不提及,有兴趣的可以去看我之前的那个文章,里面有逆向XB的过程。
注意:本文章仅供学习交流。
二.分析查询字符串参数意义
我们来看这个关键请求的负载参数有哪些:
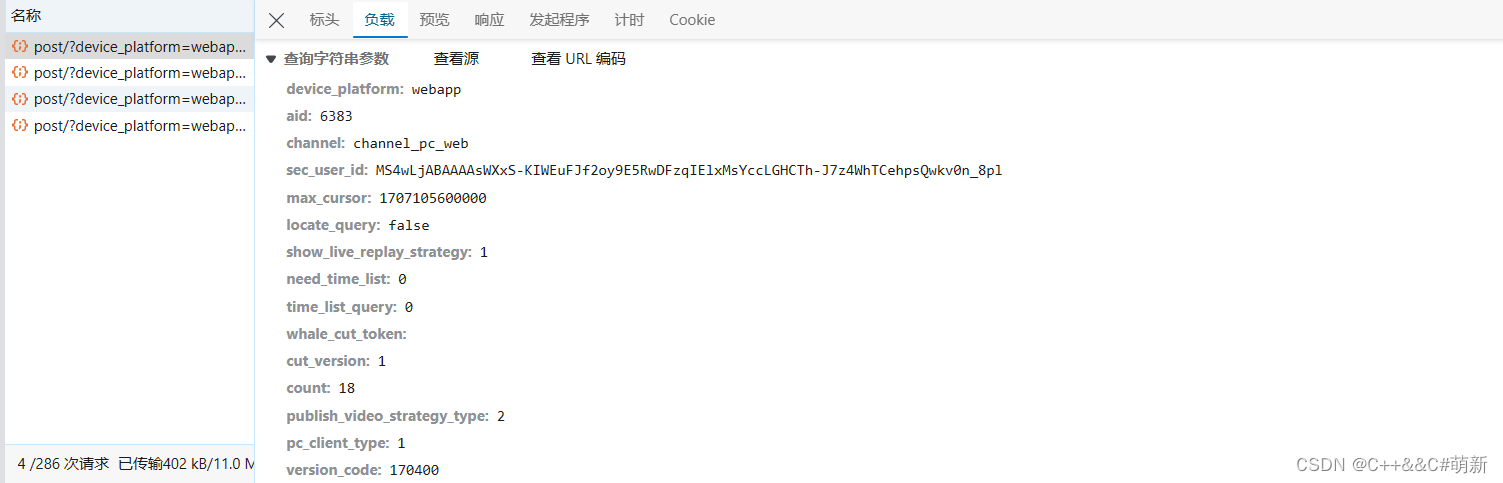 如果不知道为什么这是一个关键的请求的,也请去看看我的上一篇逆向XB的文章,这样你就会明白的,总之,我们能看到,这样的关键的请求不止一个,也就是说,如果我们要爬取所有的视频,就必定要构建多个这样的请求。我们来看看这些参数是什么意思。
如果不知道为什么这是一个关键的请求的,也请去看看我的上一篇逆向XB的文章,这样你就会明白的,总之,我们能看到,这样的关键的请求不止一个,也就是说,如果我们要爬取所有的视频,就必定要构建多个这样的请求。我们来看看这些参数是什么意思。
-
device_platform=webapp: 表示设备平台为 Web 应用。 -
aid=6383: 可能是某种应用或服务的标识符。 -
channel=channel_pc_web: 表示请求来自 PC Web 渠道。 -
sec_user_id=MS4wLjABAAAAsWXxS-...: 一个用户标识,可能是用户的唯一身份标识。 -
max_cursor=1707537600000: 用于指定请求的最大游标或时间戳。 -
locate_query=false: 可能是指示是否开启定位查询的参数,这里是关闭的状态。 -
show_live_replay_strategy=1: 控制直播重播策略的参数。 -
need_time_list=0和time_list_query=0: 控制是否需要时间列表以及时间列表查询的参数。 -
cut_version=1: 指定某种切割版本。 -
count=18: 请求的数量。 -
publish_video_strategy_type=2: 指定发布视频的策略类型。 -
pc_client_type=1: PC 客户端的类型。 -
version_code=170400和version_name=17.4.0: 应用版本的编码和名称。 -
cookie_enabled=true: 表示浏览器是否启用了 cookie。 -
screen_width=1536和screen_height=864: 屏幕的宽度和高度。 -
browser_language=zh-CN: 浏览器的语言设置。 -
browser_platform=Win32: 浏览器的平台。 -
browser_name=Edge和browser_version=121.0.0.0: 浏览器的名称和版本。 -
browser_online=true: 表示浏览器是否处于在线状态。 -
engine_name=Blink和engine_version=121.0.0.0: 浏览器引擎的名称和版本。 -
os_name=Windows和os_version=10: 操作系统的名称和版本。 -
cpu_core_num=8: CPU 的核心数量。 -
device_memory=8: 设备内存的大小。 -
platform=PC: 设备平台。 -
downlink=10: 下行速度。 -
effective_type=4g: 网络连接的有效类型。 -
round_trip_time=200: 往返时延时间。
加密的参数我这里就没有列出来了。我们主要来看max_cursor这个参数,大家看它的值,或许会觉得这可能是个时间戳,但是实际上并不是。我们首先可以思考一个问题,到底会发对少个这种请求呢?我们可以看到count参数,猜想每条请求应该会包含18条视频数据,然后我们在预览里面观察:
的确是18条视频数据。那么总共应该发送的请求数量应该就是总视频数量除以18了(向上取整)。那么每条请求之间是怎么确保视频信息没有重复呢?没错,就是靠max_cursor这个参数。在预览里面,我们还可以见到这个参数:
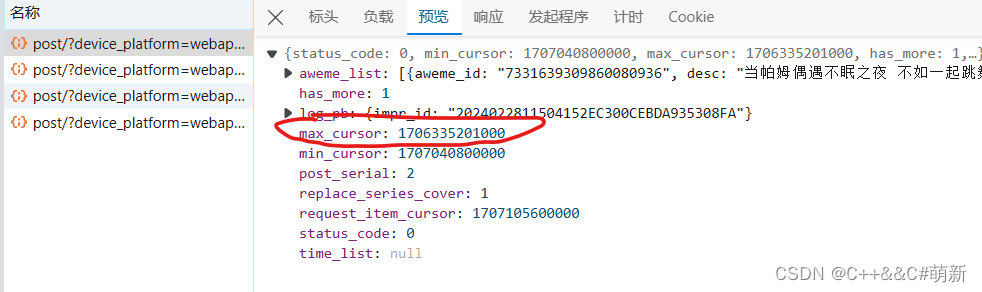
也就是说,返回的响应数据里面含有这个参数。那么它到底有什么用呢?我们可以再看看紧接着的下一条请求:

这下就清楚了,这一条请求的max_cursor值是来自上一条请求的响应数据max_cursor。那么第一条请求的max_cursor应该是多少呢?是0,我们可以让其为0,这样就代表了第一条请求的max_cursor值,然后我们构建下一条的max_cursor值只需要用到这条的响应数据就可以了。如此这般,包含全部信息的请求我们都应该能够构建出来了。
url_list=[]
def getAllVideo_url():
"""
这个函数用来获取所有视频的url地址,并存储在一个列表当中
:return: 没有返回值
"""
#这个base_url是第一个发送的请求
base_url = "device_platform=webapp&aid=6383&channel=channel_pc_web&sec_user_id=MS4wLjABAAAAsWXxS-KIWEuFJf2oy9E5RwDFzqIElxMsYccLGHCTh-J7z4WhTCehpsQwkv0n_8pl&max_cursor=0&locate_query=false&show_live_replay_strategy=1&need_time_list=0&time_list_query=0&whale_cut_token=&cut_version=1&count=18&publish_video_strategy_type=2&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1536&screen_height=864&browser_language=zh-CN&browser_platform=Win32&browser_name=Edge&browser_version=121.0.0.0&browser_online=true&engine_name=Blink&engine_version=121.0.0.0&os_name=Windows&os_version=10&cpu_core_num=8&device_memory=8&platform=PC&downlink=10&effective_type=4g&round_trip_time=200&webid=7214703537787274789&msToken=mrmatvU-fZ10rREVP9M106uwYtZoFeuUhylNVqN7gzGGRUwoXECAh_ip05nF4gKJLaeluP9HfEJzRCrUu0AJVhSpXf13kQ-TPoqsWpjp7LLLP5JmQH8UG1-GO8qA019B"
#response返回的是json数据
response = getData(base_url)
while len(response["aweme_list"])>0:
#max_cursor是下一个请求中的参数,这里我们需要从上一个请求的响应中获取
max_cursor=response["max_cursor"]
for i in range(len(response["aweme_list"])):
#从json数据里面获取视频的url
url_list.append(response["aweme_list"][i]["video"]["play_addr"]["url_list"][0])
#请求下一条数据,需要先替换url的max_cursor参数
base_url=f"device_platform=webapp&aid=6383&channel=channel_pc_web&sec_user_id=MS4wLjABAAAAsWXxS-KIWEuFJf2oy9E5RwDFzqIElxMsYccLGHCTh-J7z4WhTCehpsQwkv0n_8pl&max_cursor={max_cursor}&locate_query=false&show_live_replay_strategy=1&need_time_list=0&time_list_query=0&whale_cut_token=&cut_version=1&count=18&publish_video_strategy_type=2&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1536&screen_height=864&browser_language=zh-CN&browser_platform=Win32&browser_name=Edge&browser_version=121.0.0.0&browser_online=true&engine_name=Blink&engine_version=121.0.0.0&os_name=Windows&os_version=10&cpu_core_num=8&device_memory=8&platform=PC&downlink=10&effective_type=4g&round_trip_time=200&webid=7214703537787274789&msToken=mrmatvU-fZ10rREVP9M106uwYtZoFeuUhylNVqN7gzGGRUwoXECAh_ip05nF4gKJLaeluP9HfEJzRCrUu0AJVhSpXf13kQ-TPoqsWpjp7LLLP5JmQH8UG1-GO8qA019B"
response = getData(base_url)getData函数能够将基础的url加装上XB加密参数,它的原理请看我的上一篇文章。这样我们就得到了所有的视频url,接下来只需要下载就可以了。
三.所有代码
from JS逆向抖音 import getData
import requests
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdm
import threading
num=0
mylock=threading.Lock()
header = {}
url_list=[]
def getAllVideo_url():
"""
这个函数用来获取所有视频的url地址,并存储在一个列表当中
:return: 没有返回值
"""
#这个base_url是第一个发送的请求
base_url = "device_platform=webapp&aid=6383&channel=channel_pc_web&sec_user_id=MS4wLjABAAAAsWXxS-KIWEuFJf2oy9E5RwDFzqIElxMsYccLGHCTh-J7z4WhTCehpsQwkv0n_8pl&max_cursor=0&locate_query=false&show_live_replay_strategy=1&need_time_list=0&time_list_query=0&whale_cut_token=&cut_version=1&count=18&publish_video_strategy_type=2&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1536&screen_height=864&browser_language=zh-CN&browser_platform=Win32&browser_name=Edge&browser_version=121.0.0.0&browser_online=true&engine_name=Blink&engine_version=121.0.0.0&os_name=Windows&os_version=10&cpu_core_num=8&device_memory=8&platform=PC&downlink=10&effective_type=4g&round_trip_time=200&webid=7214703537787274789&msToken=mrmatvU-fZ10rREVP9M106uwYtZoFeuUhylNVqN7gzGGRUwoXECAh_ip05nF4gKJLaeluP9HfEJzRCrUu0AJVhSpXf13kQ-TPoqsWpjp7LLLP5JmQH8UG1-GO8qA019B"
#response返回的是json数据
response = getData(base_url)
while len(response["aweme_list"])>0:
#max_cursor是下一个请求中的参数,这里我们需要从上一个请求的响应中获取
max_cursor=response["max_cursor"]
for i in range(len(response["aweme_list"])):
#从json数据里面获取视频的url
url_list.append(response["aweme_list"][i]["video"]["play_addr"]["url_list"][0])
#请求下一条数据,需要先替换url的max_cursor参数
base_url=f"device_platform=webapp&aid=6383&channel=channel_pc_web&sec_user_id=MS4wLjABAAAAsWXxS-KIWEuFJf2oy9E5RwDFzqIElxMsYccLGHCTh-J7z4WhTCehpsQwkv0n_8pl&max_cursor={max_cursor}&locate_query=false&show_live_replay_strategy=1&need_time_list=0&time_list_query=0&whale_cut_token=&cut_version=1&count=18&publish_video_strategy_type=2&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1536&screen_height=864&browser_language=zh-CN&browser_platform=Win32&browser_name=Edge&browser_version=121.0.0.0&browser_online=true&engine_name=Blink&engine_version=121.0.0.0&os_name=Windows&os_version=10&cpu_core_num=8&device_memory=8&platform=PC&downlink=10&effective_type=4g&round_trip_time=200&webid=7214703537787274789&msToken=mrmatvU-fZ10rREVP9M106uwYtZoFeuUhylNVqN7gzGGRUwoXECAh_ip05nF4gKJLaeluP9HfEJzRCrUu0AJVhSpXf13kQ-TPoqsWpjp7LLLP5JmQH8UG1-GO8qA019B"
response = getData(base_url)
def downLoad(url,session,bar):
"""
这是一个普通的下载函数,传入一个url和一个会话
:param url:
:return:
"""
global num
response=session.get(header=header,url=url)
with open(f"D://JS逆向抖音星铁//{num}.mp4",'wb') as f:
f.write(response.content)
with mylock:
num+=1
bar.update()
if __name__=="__main__":
#先获取所有视频的url地址
getAllVideo_url()
for i in url_list:
print(i)
session=requests.Session()
bar=tqdm(total=len(url_list),desc="下载进度")
with ThreadPoolExecutor(max_workers=50) as t:
tasks=[t.submit(downLoad,url,session,bar) for url in url_list]

















 7819
7819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









